
针对命名实体识别的数据增强技术
2021-03-14 20:46:32马晓琴郭小鹤薛峪峰杨琳陈远哲
华东师范大学学报(自然科学版) 2021年5期
马晓琴 郭小鹤 薛峪峰 杨琳 陈远哲


摘要:近年来,深度学习方法被广泛地应用于命名实体识别任务中,并取得了良好的效果.但是主流的命名 实体识别都是基于序列标注的方法,这类方法依赖于足够的高质量标注语料.然而序列数据的标注成本高昂, 导致命名实体识别训练集规模往往较小,这严重地限制了命名实体识别模型的最终性能.为了在不增加人 工成本的前提下扩大命名实体识别的训练集规模,本文分别提出了基于EDA(Easy Data Augmentation)、 基于远程监督、基于Bootstrap(自展法)的命名实体识别数据增强技术.通过在本文给出的FIND-2019数 据集上进行的实验表明,这几种数据增强技术及其它们的组合能够低成本地增加训练集的规模,从而显著 地提升命名实体识别模型的性能.
关键词:命名实体识别;数据增强;EDA;远程监督;Bootstrap
中图分类号:TP311 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.002
Data augmentation technology for named entity recognition
MA Xiaoqin1, GUO Xiaohe1, XUE Yufeng1, YANG Lin2, CHEN Yuanzhe3
(1. Information and Communication Company, State Grid Qinghai Electric Power Company,
Xining 810008, China; 2. Shanghai Development Center of Computer Software Technology,
Shanghai 201112, China; 3. School of Data Science and Engineering, East China
Normal University, Shanghai 200062, China)
Abstract: A named entity recognition task is as a task that involves extracting instances of a named entity from continuous natural language text. Named entity recognition plays an important role in information extraction and is closely related to other information extraction tasks. In recent years, deep learning methods have been widely used in named entity recognition tasks; the methods, in fact, have achieved a good performance level. The most common named entity recognition models use sequence tagging, which relies on the availability of a high quality annotation corpus. However, the annotation cost of sequence data is high; this leads to the use of small training sets and, in turn, seriously limits the final performance of named entity recognition models. To enlarge the size of training sets for named entity recognition without increasing the associated labor cost, this paper proposes a data augmentation method for named entity recognition based on EDA, distant supervision, and bootstrap. Using experiments on the FIND-2019 dataset, this paper illustrates that the proposed data augmentation techniques and combinations thereof can significantly improve the overall performance of named entity recognition models.
收稿日期:2021-08-24
基金項目:国家自然科学基金(U1911203, U1811264, 61877018, 61672234, 6167238(4);中央高校基本科研业务费 专项;上海市核心数学与实践重点实验室资助项目(18dz2271000)
第一作者:马晓琴,女,高级工程师,研究方向为用电信息系统检修维护.E-mail: xqm8651?126.com 通信作者:杨琳,女,高级工程师,研究方向为IT治理、数据治理及数据资产化.
E-mail: yangl@sscenter.sh.cn
Keywords: named entity recognition; data augmentation; EDA; distant supervision; Bootstrap
0引 言
命名实体识别(Named Entity Recognition, NER)旨在通过模型自动地识别出一段自然文本中所 包含的实体,在金融科技领域有着广泛的应用.例如,识别出时事新闻中的人名、地名、机构名,能够 为后续的金融分析任务提供特征支持.由于实体表述十分繁杂多样,往往无法穷举所有可能的实体 (不存在一个词典能够把所有人名都涵盖起来),所以命名实体识别是一个艰难的任务.
近年来,得益于深度学习的发展与兴起,命名实体识别任务在大量训练数据的支持下取得了良好 的性能.但是,命名实体识别任务的数据标注成本很高,一句话需要标注多个实体,且往往存在歧义和 嵌套的情况,导致标注时需要详细斟酌.所以,标注一条NER数据的时间往往是文本分类等其他自然 语言处理任务的数倍.现在有许多词嵌入方法能够在大规模的无监督文本上进行预训练来提高小数 据量下模型的泛化性能,但是其含有的监督信息极其有限,因此模型的性能远远没有达到贝叶斯最优 误差.以隐藏单元数为100的Bi-LSTM + CRF模型为例,可以根据“10x规则”(https://medium.com/ @malay.haldar/how-much-training-data-do-you-need-da8ec091e956)做个简单的数据量估计:网络中 LSTM的参数个数约为2 x 4 x 1002 = 80000 (2个方向的LSTM,分别有4个门控单元,对应8个权 重矩阵).因此,这个网络的样本数量至少要超过80000 x 10 = 800000才能够接近饱和.然而在现实 业务场景中,命名实体识别任务的样本规模一般都在几千至几万的量级内,很难达到“10x规则”所要 求的饱和数据量.
为了解决数据匮乏的问题,统计机器学习领域最常用手段是数据增强(Data Augmentation)技术. 目前,数据增强技术在各个统计学习领域里都有广泛应用.例如,在计算机视觉的相关任务中,常用的 数据增强技术包括对图像进行缩放、平移、旋转、白化等操作,可以将一张图片样本扩展成多张图片 样本.在语音处理相关任务中,常用的数据增强技术则有时域扭曲、时域遮罩、频域遮罩等[1],将声波 在频域和时域上加入噪声.在自然语言处理中,数据增强在文本分类任务中也有广泛的应用,最具代 表性的就是EDA方法[2],其将自然语言数据进行随机的替换、交换、插入、删除.但是,目前没有专门 针对命名实体识别这一任务而定制的数据增强技术,现有的数据增强技术对于命名实体识别任务的 数据扩展性有限.
本文针对基于序列标注的NER任务,分别提出了基于EDA、基于远程監督、基于Bootstrap的数 据增强方法,来解决命名实体识别任务中的数据匮乏问题.第1章首先介绍命名实体识别任务的技术 背景;第2章详细介绍提出的基于命名实体识别任务的数据增强方法的完整流程和技术细节;第3章 通过实验来证明数据增强方法的有效性,并分析模型的优化上界;最后,总结全文.
1相关工作
命名实体识别技术作为自然语言理解技术中的重要一环,已经经历了几十年的长足发展,且在各 行各业有着广泛的落地场景.例如,金融新闻中的公司机构识别,法律文书中的法律名、人名识别,医 疗文本中的疾病名、药物名识别,等等.随着数据驱动的机器学习、深度学习技术开始兴起,数据增强 技术成为一项必不可少的前处理步骤,显著提升了各个任务模型的泛化性能.
1.1命名实体识别
早期的命名实体识别大多是基于规则的方法,其中最具代表性的方法有基于词汇规则的方法[3]、 基于短语规则的方法以及基于上下文模板的方法这类方法需要通过语言学家对命名实体规则进 行总结归纳,在某些强规则相关的特定领域文本能够取得还不错的性能.但是这类方法的缺点也显而 易见:人工总结的规则往往泛化性能有限,无法涵盖所有情况.因此,这类方法在大多通用领域文本下 的性能较差.
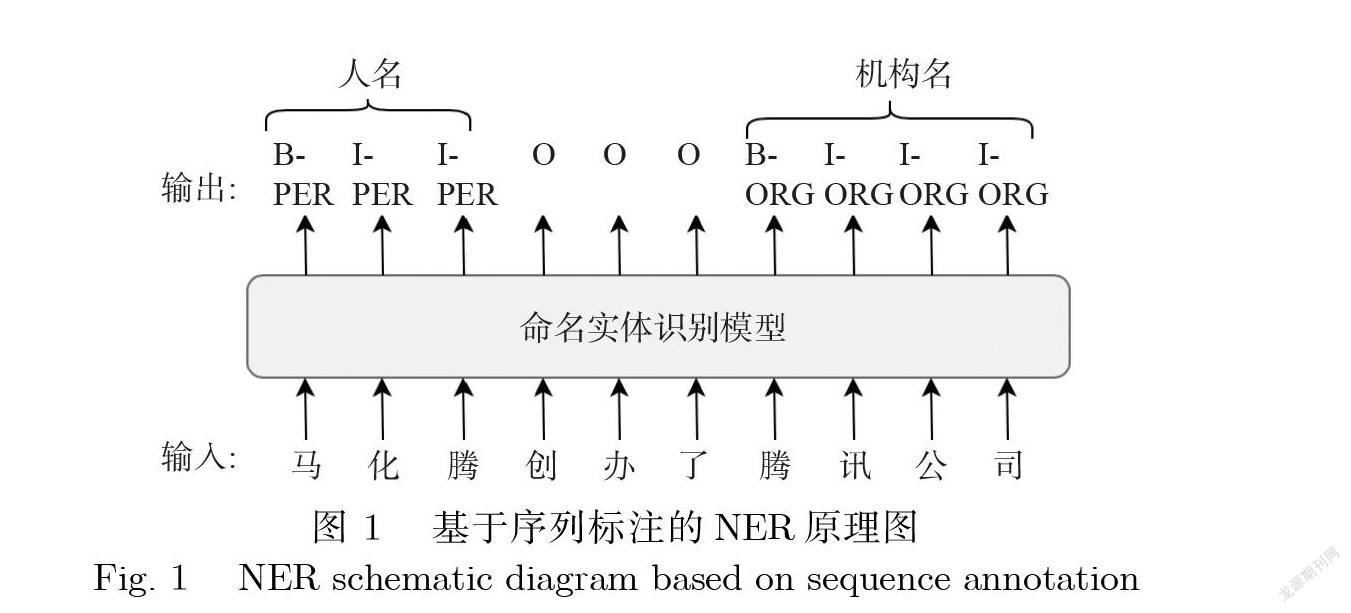
近年来,命名实体识别开始采用序列标注的建模方式,即将句子序列输人NER模型当中,模型输 出等长的标注序列,表示唯一^的一^组实体识别结果.常见的序列标注法有“BIO”法和“BIOES”法.本 文中默认使用“BIO”法,即“B”代表实体的开头,“I”代表实体的内部,“O”代表非实体部分,如图1 所示.
基于序列标注的建模方式,数据驱动的机器学习方法开始被引人命名实体识别任务当中,常见的 方法包括基于支持向量机的方法'基于隐马尔可夫模型的方法' 以及基于条件随机场的方法[8].这类 方法能够从大量人工标注的监督数据中,根据指定的目标函数来自动学习文本到标注的复杂映射关 系,从而避免了人工总结规则的过程,且效果显著好于基于规则的方法.其中,基于条件随机场的方法 能够学习到标签之间的前后约束关系,例如“BIO”序列中“O”不能直接转移到“I”.
随着深度学习技术的兴起,采用神经网络来提取文本特征的建模方式开始逐渐取代传统的机器 学习方法,成为命名实体识别任务的新范式.常见的方法包括基于卷积神经网络(CNN)的方法[9]、基 于循环神经网络(RNN)的方法[10]以及基于变换器(Transformer)的方法[11-12].其中,卷积神经网络善 于学习文本的n-gram局部特征,循环神经网络善于学习文本时序特征,变换器善于学习文本的长距 离依赖.当前的主流方法也常常会将这几类神经网络进行组合,例如,基于CNN + LSTM的方法能够 同时学习局部依赖和时序依赖[13],基于图卷积网络的方法能够学习结构化的语法特征[14],基于Lattice LSTM的方法能够避免分词误差[15].
针对小数据量的命名实体识别场景,引人无监督的词嵌人表征也是一个常见的做法,旨在利用一 个大规模的无监督语料库来提前学习词间的语义关系,并将其迁移到小数据量的监督任务上来提高 性能.经典的词嵌人方法有Word2vec[16]、Glove[17]、Fasttext[18],这类方法主要通过统计词的共现信息 来学习到词之间的相似性先验.近年来,基于预训练语言模型的动态词嵌人方法也开始被广泛应用, 其能够解决词语在不同上下文中一词多义的问题,典型的技术有ELMo[19]、Flair[20]、BERT[21]、GPT- 2[22]、GPT-3[23]等.但是,这类技术受制于无监督数据的储备和计算资源的规模,普通的学术机构或个 人往往无法负担模型预训练的成本.
1.2数据增强
数据增强方法的主要目标是,在不增加人工标注成本的前提下,通过增加合理的噪声来提升模型 的鲁棒性.数据增强的过程也等价于增大了训练数据量,因此,在少数据量的场景下对模型性能的提 升有很大帮助.数据增强的方式依赖于输人数据本身和目标任务的特性,过度或者不合适的数据增强 反而会损伤模型的性能.例如,对于字符识别任务,对字符图片进行轻微的随机旋转是合适的,但是如 果旋转角度过大,则会产生许多错误标签样本(如字母“P”旋转180度后会变成字母“d”),导致训练后 模型的性能下降.
在文本分类任务中,EDA[2]是一个常用的数据增强方法,其设计了一系列简单的操作来为自然语 言数据加入噪声,从而提高模型的鲁棒性.EDA方法中提出了 4种基本操作:①同义词替换,即将文 本数据中的某些词随机替换为其同义词;②随机插入,即在文本数据中的随机位置插入随机的词; ③随机交换,即随机挑选文本数据的词对进行位置交换;④随机删除,即随机删除文本数据中的词. EDA方法在文本分类任务中取得了良好的性能,但是并不适用于命名实体识别任务,因为随机插入、 随机交换、随机删除都有可能破坏命名实体的合法性,使数据集出现谬误.
此外,也有一些从其他领域迁移到自然语言处理领域的数据增强方法,最具代表性的有:从计算 机视觉领域引入的文字混合(Mixup for Text)方法[24],从生物信息学引入的实例交叉扩展方法[25].这 类方法均利用了跨领域任务之间的共性,并根据目标任务的特点对方法进行了适配性修改.
近年来,一些针对命名实体识别这一特定任务的数据增强技术也开始被提出.例如,Dai等[26]引 入了一些词替换的随机操作来增加训练语料多样性;Chen等[27]在半监督NER任务中引入了基于局 部可加性的数据增强;Keraghel等[28]针对单一领域提出了针对性的数据增强方法.目前,这类方法存 在以下缺陷:①引入噪声过大,主要由于一些随机替换规则的不合理性,以及存在误差率;②一般只适 用于单一特殊场景,如Keraghel等[28]的方法只适用于汽车工业领域,不具有较强的通用性.
2命名实体识别数据增强技术
本章将系统性地提出针对命名实体识别的数据增强技术,主要包括基于EDA、基于远程监督、基 于Bootstrap的数据增强的方法.其中,基于EDA的方法主要关注如何动态地为数据加入合理的噪声; 基于远程监督的方法主要关注如何根据实体库与无监督文本来自动生成监督样本;而基于Bootstrap 的方法则重点关注模型如何通过迭代回标数据来实现自我更新.
2.1基于改进EDA的NER数据增强
为了适应NER任务,将EDA方法进行了改进,将原有的4种操作进行了以下修改,防止原始的 EDA操作破坏NER数据的合法性:
(1)同义词替换,将标注数据中的某些词随机替换为其同义词(该操作无变化);
(2)随机插入,向标注数据中的某个非实体部分中随机插入词语;
(3)随机交换,将标注数据中非实体部分的随机两个词进行交换;
(4)随机删除,将标注数据中非实体部分的随机词删除.
在原始的EDA的4个操作的基础上,为NER任务以及中文文本定制了 6种额外的数据增强操作.
(1)实体替换:随机将标注数据中的若干命名实体替换为其他同类型的命名实体,旨在丰富命名 实体表述的多样性.
(2)实体遮罩:随机将标注数据中的某些命名实体的每个词嵌入替换为随机向量,旨在强化对命 名实体上下文的模板槽的学习.
(3)词切分:随机将标注数据中的词语进行细粒度切分,旨在强化对不同分词结果的鲁棒性.
(4)词拼接:随机将标注数据中相邻的两个词组合成一个词,其中需要防止实体部分和非实体部 分的词发生组合,旨在强化对不同分词结果的鲁棒性.
(5)句换位:以句号等分隔符为分句依据,随机交换同一个样本中或两个样本之间的两个句子,旨 在丰富样本的长距离上下文内容.
(6)短句生成:随机取某个样本中包含至少一个命名实体的短句子生成新样本,旨在提高缺乏上 下文信息的短文本NER的性能.
基于EDA的NER数据增强方法主要通过向数据中添加合理的噪声,来模拟模型未来可能遇到 的复杂多样的样本.因此,相比于可能破坏语句通顺性的传统EDA方法,提出的改进EDA方法能够 在基本不损失数据标注正确率的前提下,显著提升文本语义空间的覆盖度,从而提升NER模型的泛 化性能.
2.2基于遠程监督的NER数据增强
虽然EDA方法能够显著地增强NER模型的鲁棒性,但是其语义空间有限:仅是对原始样本集加 入少量噪声,大部分样本的语义空间和句式并没有得到扩展,即标注样本在全样本空间中的覆盖率较 低且基本保持不变.因此,提出了基于远程监督的NER数据增强方法,从另一个角度对数据集进行扩 增,通过引入大量的无监督样本,然后使用脚本对其进行自动NER标注.这样大量的无监督样本就转 化为了大量的监督样本,从而大大增加了模型的训练量.远程监督的具体流程见算法1.
算法1基于远程监督的NER数据增强算法
输人:种子数据集X;外部实体库戽无监督语料库r 输出:远程监督数据集X'
1:若X非空,提取X中所有实体得到额外实体集合尽 2: E = EU Ex
3:将E中所有实体作为模板集合,构建AC自动机Ma。
4:使用Mac在r中进行实体匹配,找出所有完全匹配的实体区间列表S= {〈L1,R1〉,〈L2,R2〉,…},其中Li,和Ri尾分别表示T中第i个匹配成功的起始位置和终止位置
5:对S中的每个区间在r的相应位置标注“BI”标签,其余部分标注“O”标签,得到远程监督数据集X
6: Return X
该过程中涉及了 AC自动机(Aho-Corasick Automaton),能够快速地对文本进行多模板匹配,效 率要远高于暴力匹配与多次KMP匹配.基于远程监督的数据增强方法实现简单,并且支持NER任务 的冷启动:即使在没有任何监督样本的情况下也能够构造出新的监督数据.
2.3 基于Bootstrap的NER数据增强
在实际应用场景中,远程监督方法也存在着一个重要的缺陷:基于远程监督数据集训练出的 NER模型的召回率普遍偏低.原因一方面在于,开放域中可能出现的命名实体数量巨大,如人名显然 是穷举不完的,相比之下,拥有的实体库规模非常有限;另一方面在于,同一个实体的表述方法也复杂 多变,经常存在别名、简称、全称的不同表述方式.因此,远程监督方法很难将无监督文本中的实体标 注完整,会遗漏很多实体库之外的实体表述.
针对远程监督方法存在的问题,提出了基于Bootstrap的NER数据增强算法.相较于远程监督直 接做字符串完全匹配,Bootstrap方法先使用种子数据集对模型进行初步训练,然后通过模型自身的 迭代回测,不断地扩大数据集规模,从而实现模型的自我更新.Bootstrap的具体过程见算法2.
相较于远程监督方法,Bootstrap方法具有更高的召回率,能够更好地识别出自然语言场景下各 种复杂的实体表述.需要注意的是,Bootstrap迭代次数要控制在一定范围内,否则可能发生“语义漂 移”,即种子模型的预测结果会有一定的错误率,当使用错误样本进行迭代训练时,将导致模型的错误 随着迭代次数的增加而逐渐放大.因此,在真实的业务场景下,Bootstrap方法必须要保证种子数据集 的质量,并且需要对精度变化曲线进行监控,当精度提升逐渐放缓后即可停止迭代,从而避免语义漂 移的发生.
算法2基于Bootstrap的NER数据增强算法
输入:种子数据集X;验证集无监督语料结束阈值s 输出:Bootstrap数据集X
1:使用X训练NER模型,并在上计算模型初始得分s 2:将C顺序打乱,均分为C1, C2,…,Q 3: For i=1 一n do
4: 使用M预测语料Ci,得到带标注语料;
5: X7 = X U X,
6: 使用X'训练NER模型,并在XW1计算模型得分^
7: If s' - 5 < ? then
8: Break
9: Else
10: X= X, s = S
11: End if
12: End for 13: Return X
3实验效果与分析
本节主要对提出的3种NER数据增强技术的性能进行评测和对比.通过一系列谨慎评估,尝试 回答以下研究问题.
研究问题1: EDA数据增强方法对NER的性能有多大提升?
研究问题2:远程监督数据增强方法对NER的性能有多大提升?
研究问题3: Bootstrap數据增强方法对NER的性能有多大提升?
研究问题4:上述3类数据增强方法是否能够组合共用?对NER的性能有多大提升?
在接下来的部分,首先在实验设置部分介绍数据集和实验设置,然后依次回答上述的研究问题.
3.1数据集和实验设置
为了方便比较,3种方法均在FIND-2019数据集上进行测试.FIND-2019数据集的文本来源为 2016—2018年的上市公司新闻,训练集有7235条句子,测试集有2534条句子,其中的实体类型只有 机构(ORG),主要包括各个行业领域的上市公司与非上市公司.模型的性能评价指标采用F1指标,即 准确率和召回率的调和平均数.
选用ID-CNNs-CRF[9]作为实验的基准模型,模型详细结构如图2所示.
其中,嵌入层采用了 Fasttext[18],并在爬取的约100万句金融语料上进行预训练.使用AdamW算 法对神经网络进行优化[29], batchsize设置为32,学习率为1e-4.此外,在嵌入层和空洞卷积层的输出端 加入了 Dropout, dropout rate为0.25;模型整体加入了 L2正则化,正则化系数为1e-5.从训练集中额 外分离了 10%的数据作为验证集,每组结果均采用训练过程中验证集的metric(巧)最高的checkpoints 作为最终模型结果参与测试集上的实验.
3.2 EDA数据增强性能测试
对传统EDA方法与改进的EDA方法在基准模型上的巧指标进行比较.统一控制各种操作中的随机比例,例如,对于同义词替换操作,随机比例为10%,即代表挑选语料中10%的词语做同义词替 换.此外,改进的EDA操作是在线进行的,即在NER模型训练过程中的每个batch都会在线进行 EDA的随机操作,确保同一个样本在每个epoch被增强后都不相同.EDA性能在FIND-2019数据集 上的评估结果如表1所示,表格第一行的百分比代表随机比例,提出的改进EDA分别包含了简化版 (包含改良EDA的前4种操作)与完整版(包含改良EDA完整的10种操作).由于EDA方法的性能 提升有限,因此,为了增加实验结果的可信度,从0%至50%的数据增强过程将重复5次,表1中的数 据均为5次实验的均值.
从表1中可以看出,原始EDA在NER任务中不但很难提升性能,甚至会导致模型性能的大幅下 降.其主要原因在于,原始EDA操作存在与NER任务规则相悖的地方,这会在增广的数据中引人较 大误差,从而使模型性能发生偏移.而改进的EDA方法则能够显著提升NER的性能,其中完整版的 改进EDA算法的性能要优于简化版,因为其对数据进行了更精细的增广,使得新生成的数据更贴近 现实分布,从而提升模型的泛化性能.此外,在使用EDA方法时需要控制随机比例,不宜将随机比例 设置得过高,否则会导致被增强后的数据变化过大,从而导致训练集与测试集的语义分布发生显著差 异,进而影响模型在测试集上的性能.
3.3远程监督数据增强性能测试
对远程监督方法的数据增强性能进行对比测试.无监督语料同样来自上市公司新闻,实体列表的 来源主要有FIND-2019训练集中出现的所有实体表述,以及从互联网上得到的公司名录、机构名录, 并将它们的简称、别名、全称一并加人实体列表.基于得到的实体列表,分别测试了远程监督方法在 冷启动场景(训练集只有远程监督数据)和数据增强场景(训练集包含原始训练集+远程监督数 据)下的巧指标,如表2所示.表2第一行的数据代表训练集中加人了多少远程监督的数据,每 100%代表额外加人了 7235条数据,即FIND-2019训练集的原始大小.同样地,表2中的数据为5次 重复实验的均值.
由表2可以看出,远程监督构造的数据集在一定程度上能够模拟真实场景下的数据,但是其标注 的质量还是与人工标注有所差距.在冷启动场景下使用了 500%的远程监督数据集训练的模型,其 巧仍然比仅用人工标注的数据集训练的模型要低约12%.在普通的数据增强场景下,加入100%的远 程监督数据集能够在一定程度上提高模型的泛化性能,但是当远程监督数据集的比例过大时,其低质 量的标注会将人工标注的数据的比例降低,从而对模型的性能提升起到反作用.造成上述现象的原因 在于,远程监督方法所依赖的实体模板匹配方法本身存在较大误差,且误差往往大于人工标注.因此, 在数据增强场景中,少量的远程监督数据作为噪声能一定程度提升模型性能,但是一旦这部分数据占 比过高,会使模型去拟合一个错误的分布,从而弱化模型在真实分布上的效果.
3.4 Bootstrap数据增强性能测试
本小节对Bootstrap的数据增强性能进行测试.无监督语料同样来自上市公司新闻,种子数据集 即为FIND-2019的训练集.图3展示了 NER模型的巧随着Bootstrap不断迭代的变化曲线,其中每 次迭代往数据集中添加3600条Bootstrap标注数据,大约为FIND-2019训练集的一半大小.
由图3可知,随着Bootstrap不断迭代,NER模型的巧呈现先增后减的趋势,与远程监督方法的 变化趋势类似.但是Bootstrap方法的巧峰值要显著高于远程监督方法,达到了约56.5%. Bootstrap 大约迭代4次,即大约增加了两倍的训练集规模后,模型的巧达到峰值,随后模型开始发生语义漂移, 性能开始急剧下降.
因此,Bootstrap方法存在性能上界的主要原因在于:①Bootstrap方法标注了新的文本数据,从 而增加了训练集输入端的文本分布的多样性,且文本多样性随着迭代次数增加而增加,由于文本空间 会逐渐饱和,因此文本多样性的提升速度是递减的;②Bootstrap方法引入了少量错误的标注数据,这 些错误的标注数据会影响后续模型效果,从而使得剩下的迭代中引入更多的错误标注,即标注错误随 着迭代次数增加而增加,且错误的增加速度也是递增的;③文本多样性的递增和標签错误的递增呈现 动态平衡,即在达到性能上界前,文本多样性的提升速度高于标签错误的提升速度,模型性能总体呈 现提升的趋势;而在达到性能上界之后,文本多样性的提升速度开始低于标签错误的提升速度,模型 性能就开始呈现衰减的趋势.
3.5数据增强方法组合与性能对比
事实上,提出的3种数据增强方法之间从逻辑上是可以兼容的.本节将通过实验来对3种数据增 强方法以及它们的组合之间进行性能对比.通过以下方式对数据增强方法进行两两组合或三者组合 (EDA均采用完整改进版本).
(1)EDA +远程监督:首先使用远程监督方法生成规模更大的训练语料,然后在新的语料上进行 EDA处理.
(2)EDA + Bootstrap:首先使用Bootstrap方法生成规模更大的训练语料,然后在新的语料上进 行EDA处理.
(3)远程监督+ Bootstrap:使用远程监督和Bootstrap生成各自的数据增强语料,同时将其加入 原始语料中得到规模更大的训练语料.
(4) EDA +远程监督+ Bootstrap:首先使用远程监督和Bootstrap生成各自的数据增强语料,同 时将其加入原始语料中得到规模更大的训练语料,然后在新的语料上进行EDA处理.
将数据增强方法进行组合后,将EDA的随机比例、远程监督的添加数据量、Bootstrap的迭代次 数都看作超参数,通过网格搜索枚举所有可能的超参数组合,对每个超参数组合重复5次实验求其平 均的巧指标,得到平均朽指标最高的超参数组合.表3展示了 3种数据增强方法的各种组合方式的 最优性能对比,其中bestEDA、bestDIS、bestBS*别表示EDA、远程监督、Bootstrap在各种组合方式下 的最优超参数取值,评价指标依旧选用巧指标.
从表3中可以得到以下结论:①仅看单个数据增强方法对巧的提升,Bootstrap方法> EDA方 法 > 远程监督方法;②考虑数据增强方法的组合个数对巧的提升,3个方法组合 > 两个方法组合> 单个方法;③随着数据增强方法的组合个数的增加,各方法的最优超参数值呈现降低趋势,这是因为 数据中的随机噪声也随着多个方法的组合而叠加,从而使得语义漂移在超参数值较低时就提前出现.
4 結论
本文主要介绍了针对序列标注NER模型的数据增强技术,分别介绍了基于EDA的数据增强技 术、基于远程监督的数据增强技术、基于Bootstrap的数据增强技术的算法流程,并分析这些方法的 优缺点.最后通过在FIND-2019数据集进行实验,分别证明了 3种方法以及方法组合的有效性,并且 对其中的重要参数进行了敏感性分析,对实际运用这些数据增强方法起到了指导性作用.
[参考文献]
[1]PARK D S, CHAN W, ZHANG Y, et al. Specaugment: A simple data augmentationmethod for automatic speech recognition [EB/OL]. (2019-12-03)[2021-08-24]. https://arxiv.org/abs/1904.08779. [ 1 ]
[2]WEI J W, ZOU K. Eda: Easy data augmentation techniques for boosting perfor-mance on text classification tasks [EB/OL]. (2019-08-25)[2021-08-24]. https://arxiv.org/pdf/1901.11196.pdf. [3]WEISCHEDEL R. BEN: Description of the PLUM system as used for MUC-6 [C]// Proceedings of the 6th Conference on Message Understanding. 1995: 55-69.
[4]ABERDEEN J, BURGER J, CONNOLLY D, et al. MITRE-Bedford: Description of the ALEMBIC system as used for MUC-4 [C]//Proceedings of the 4th Conference on Message Understanding. 1992: 215-222.
[5]HOBBS J R, BEAR J, ISRAEL D, et al. SRI international fastus system MUC-6 test results and analysis [C]// Proceedings of the 6thConference on Message Understanding. 1995.
[6]MAYFIELD J, MCNAMEE P, PIATKO C. Named entity recognition using hundreds of thousands of features [C]// Proceedings of the Seventh Conference on Natural Language Learning. 2003: 184-187.
[7]RABINERLR, JUANGB-H. An introduction to hidden Markov models [J]. IEEE Assp Magazine, 1986, 3(1): 4-16.
[8]LAFFERTY J D, MCCALLUM A, PEREIRA F C N. Conditional random fields: Probabilis-tic models for segmenting and labeling sequence data [C]// Proceedings of the Eighteenth International Conference on Machine Learning. 2001: 282-289.
[9]STRUBELL E, VERGA P, BELANGER D, et al. Fast and accurate entity recognitionwith iterated dilated convolutions [EB/OL]. (2017-07-22)[2021-08-24]. https://arxiv.org/pdf/1702.02098.pdf.
[10]HUANG Z, XU W, YU K. Bidirectional LSTM-CRF models for sequence tagging [EB/OL]. (2015-08-09)[2021-08-24]. https://arxiv.org/pdf/1508.01991.pdf.
[11]VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need [C]// Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
[12]YAN H, DENG B, LI X, et al. TENER: Adapting transformer encoder for named entity recognition [EB/OL]. (2019-12-10)[2021-08-24]. https://arxiv.org/abs/1911.04474v2.
[13]CHIU J P, NICHOLS E. Named entity recognition with bidirectional LSTM-CNNs [J]. Transactions of the Association for Computational Linguistics, 2016(4): 357-370.
[14]CETOLI A, BRAGAGLIA S, OHARNEY A D, et al. Graph convolutional networks for named entity recognition [EB/OL]. (2018-02-14)[2021-08-24]. https://arxiv.org/pdf/1709.10053.pdf.
[15]ZHANG Y, YANG J. Chinese NER using lattice LSTM [EB/OL]. (2018-07-05)[2021-08-24]. https://arxiv.org/pdf/1805.02023.pdf.
[16]MIKOLOV T, SUTSKEVER I, CHEN K, et al. Distributed representations of words and phrases and their compositionality [C]//Preceedings of ACL. 2013: 3111-3119.
[17]PENNINGTON J, SOCHER R, MANNING C. Glove: Global vectors for word representation [C]// Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2014: 1532-1543.
[18]BOJANOWSKI P, GRAVE E, JOULIN A, et al. Enriching word vectors with sub- word information [J]. Transactions of the Association for Computational Linguistics, 2017(5): 135-146.
[19]PETERS M E, NEUMANN M, IYYER M, et al. Deep contextualized word representations [EB/OL].(2018-03-22)[2021-09-01].https://www.researchgate.net/publication/323217640_Deep_contextualized_word_representations.
[20]AKBIK A, BLYTHE D, VOLLGRAF R. Contextual string embeddings for sequence labeling [C]// Proceedings of the 27thInternational Conference on Computational Linguistics. 2018: 1638-1649.
[21]DEVLIN J, CHANG M W, LEE K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding [EB/OL].(2019-05-24)[2021-08-24]. https://arxiv.org/pdf/1810.04805.pdf.
[22]RADFORD A. Language models are unsupervised multitask learners [EB/OL]. (2019-02-19)[2021-09-01]. https://d4mucfpksywv. cloudfront.net/better-language-models/language-models.pdf.
[23]BROWN T B, MANN B, RYDER N, et al. Language models are few-shot learners [EB/OL]. (2020-07-22)[2021-08-24]. https://arxiv.org/abs/2005.14165v2.
[24]GUO H, MAO Y, ZHANG R. Augmenting data with mixup for sentence classification: An empirical study [EB/OL]. (2019-05-22)[2021-08-24]. https://arxiv.org/abs/1905.08941.
[25]LUQUE F M. Atalaya at TASS 2019: Data augmentation and robust embeddings for sentiment analysis [EB/OL]. (2019-09-25)[2021-08-24]. https://arxiv.org/abs/1909.11241.
[26]DAI X, ADEL H. An analysis of simple data augmentation for named entity recognition [EB/OL]. (2020-10-22)[2021-08-24].https://arxiv.org/abs/2010.11683.
[27]CHEN J, WANG Z, TIAN R, et al. Local additivity based data augmentation for semi-supervised NER [EB/OL]. (2020-10-04)[2021-08-24]. https://arxiv.org/abs/2010.01677.
[28]KERAGHEL A, BENABDESLEM K, CANITIA B. Data augmentation process to improve deep learning-based NER task in the automotive industry field [C]//2020 International Joint Conference on Neural Networks (IJCNN). 2020: 1-8.
[29]LOSHCHILOV I, HUTTER F. Fixing weight decay regularization in adam [EB/OL]. (2019-01-04)[2021-08-24]. https://arxiv.org/abs/
1711.05101v1.(責任编辑:张晶)
