
CPU-GPU异构环境下的大规模商品知识查询处理
2021-03-14 20:42方创新宋浩林煜明周娅
华东师范大学学报(自然科学版) 2021年5期
方创新 宋浩 林煜明 周娅

摘要:知识图谱是将无结构的知识进行结构化表示和组织的有效途径,已经成为支持众多智能应用的基 础设施.然而,与商品相关的知识通常呈现出海量性、异质性和层次性的特点,这对现有基于关系模型和图 模型的知识查询处理方法提出了挑战.针对商品知识的这些特点,本文设计与实现了一种利用CPU和 GPU协同计算的商品知识查询处理方法.首先,为了充分发挥GPU的并行计算能力,提出了一种基于稀 疏矩阵的商品知识存储策略,并针对商品知识进行存储优化;其次,根据稀疏矩阵的存储结构设计了一种 查询转换方式,将SPARQL查询转化为对应的矩阵计算,并将连接查询算法扩展到GPU上进行加速.为 了验证所提出方法的有效性,我们在LUBM数据集和一个半合成的商品数据集上进行了一系列的实验.结 果表明,本文提出的方法,不仅在海量商品知识下相对于现有RDF查询引擎在检索效率上有较大提升,而 且在通用的RDF标准数据集上也能取得较好的检索性能,并验证了 GPU加速查询处理的有效性.
关键词:商品知识;异构环境;RDF数据;查询处理
中图分类号:TP392 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.014
Query processing of large-scale product knowledge in a
CPU-GPU heterogeneous environment
FANG Chuangxin, SONG Hao, LIN Yuming, ZHOU Ya
(Guangxi Key Laboratory of Trusted Software, Guilin University of Electronic Technology,
Guilin Guangxi 541004, China)
Abstract: Knowledge graphs are an effective way to structurally represent and organize unstructured knowledgeare; in fact, these graphs are commonly used to support many intelligent applications. However, product-related knowledge is typically massive in scale, heterogeneous, and hierarchical; these characteristics present a challenge for traditional knowledge query processing methods based on relational and graph models. In this paper, we propose a solution to address these challenges by designing and implementing a product knowledge query processing method using CPU and GPU collaborative computing. Firstly, in order to leverage the full parallel computing capability of GPU, a product knowledge storage strategy based on a sparse matrix is proposed and optimized for the scale of the task. Secondly, based on the storage structure of the sparse matrix, a query conversion method is designed, which transforms the SPARQL query into a corresponding matrix calculation, and extends the join query algorithm to the GPU for acceleration. In order to verify the effectiveness of the proposed method, we conducted a series of experiments on an LUBM dataset and a semisynthetic dataset of products. The experimental results
收稿日期:2021-08-07
基金項目:国家自然科学基金(62062027, U181126(4);广西自然科学基金(2018GXNSFDA281049, 2020GXNSFA A15901(2);广西创新驱动发展专项资金(桂科AA1904600(4);桂林市重点研发计划(202001030(4);桂林电 子科技大学研究生教育创新计划资助项目(2021YCXS07(5);广西可信软件重点实验室研究课题 (kx20202(1)
通信作者:林煜明,男,教授,硕士生导师,研究方向为海量数据管理和知识图谱.E-mail: ymlin@guet.edu.cn
showed that the proposed method not only improves retrieval efficiency for large-scale product knowledge datasets compared with existing RDF query engines, but also achieves better retrieval performance on a general RDF standard dataset.
Keywords: product knowledge; heterogeneous environment; RDF data; query processing
0引 言
知识图谱是利用图模型来描述知识和建模事物间关联关系的大规模语义网络,是大数据时代知 识表示的重要方式之一,也是众多智能应用的基础支撑设施.例如,基于金融知识图谱的会计欺诈风 险识别[1]、金融产品推荐等.这种结构化的知识表示能够将实体信息表达成更接近人类认知世界的 形式,通过知识图谱能够更好地组织、管理和理解互联网上的信息.大部分知识图谱使用资源描述框 架(Resource Description Framework, RDF)来描述事物和关系,是一种以三元组形式来描述网络资源 信息的表示方式,其格式为“(主语,谓语,宾语)”,其中主语、宾语也称为实体,谓语也称为关系,简言 之,RDF就是一种描述实体间关系的表示方法.而SPARQL (Simple Protocol and RDF Query Language) 则是W3C (World Wide Web Consortium)专门定义于访问和操作RDF数据的结构化查询语言,以 实现针对大规模RDF数据的查询与检索.目前,针对大规模RDF数据的查询处理主要包括基于关系 模型(如Jena[3]和RDF-3X[4]等)和基于图模型(如gStore[5]和AMBER161等)两类方法.
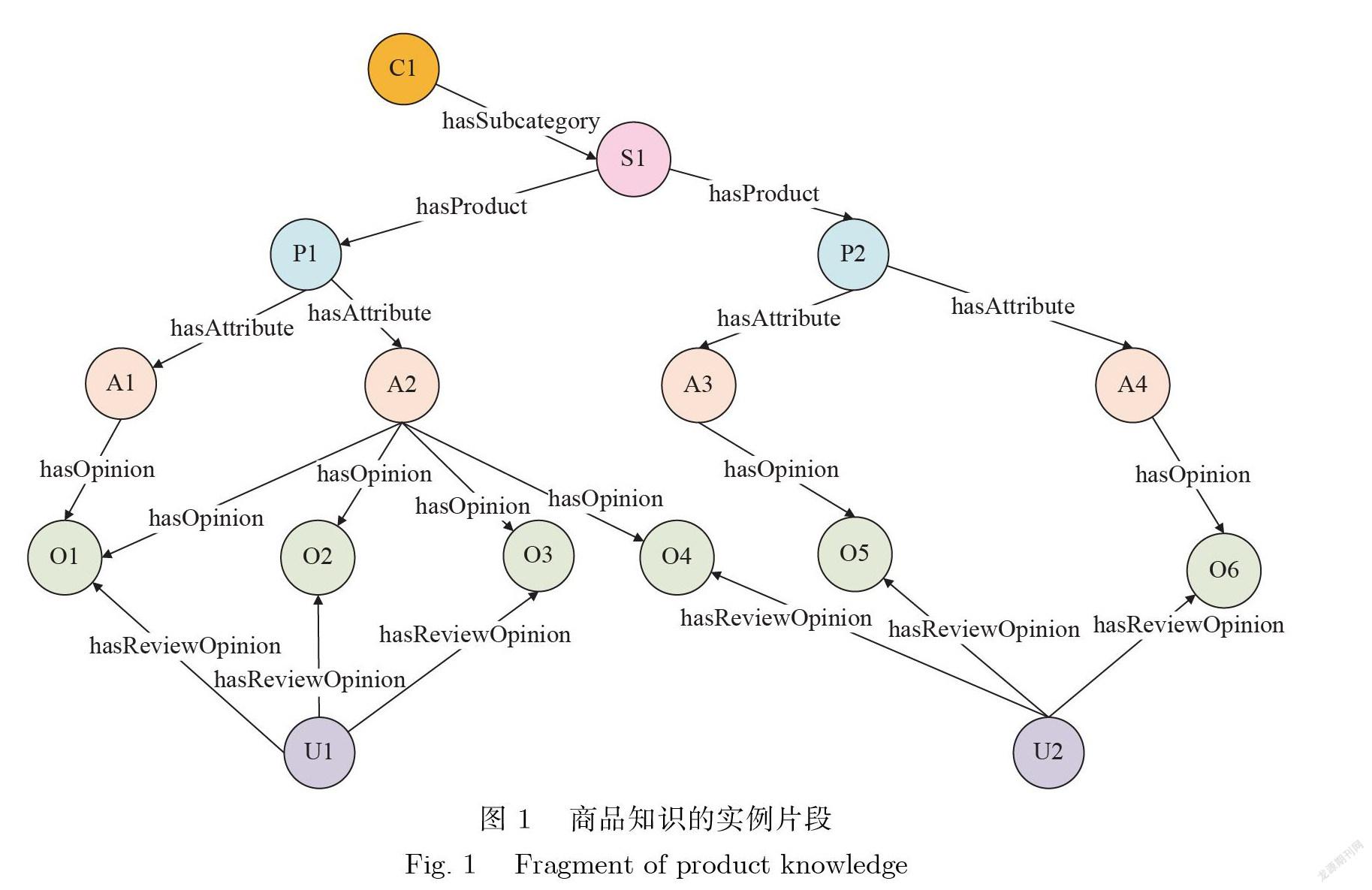
另一方面,商品知识由于具有异质性、冗杂性、海量性等特点,使得原生的商品知识数据并不是 结构化的,难以通过传统的知识图谱形式进行组织与管理.现实的应用中有一些知识图谱具有层次化 的结构,层次化结构对知识数据从深度和广度上进行了衍生,可以从一般概念引导到更细粒度的知识, 因此,商品知识数据适合使用层次化的知识图谱进行构建.然而现有的RDF知识查询方法对具有这 种结构的知识图谱进行查询处理时不能很好地利用其层次结构特点进行存储和查询优化.本文主要 是针对具有层次化组织结构的知识图谱进行查询优化的研究,特别是对具有该结构的商品知识数据 的检索提出了一种查询优化的方法.我们所研究的商品知识,是一种具有5层结构的知识图谱用户 层、用户观点层、商品属性层、商品实例层、商品分类层),其特点在于每一层实体的属性类型都是类 似的,层与层之间的实体使用同一类型的关系来联系,商品知识的实例片段如图1所示.例如,图1中 包含了如下事实:用户U1对商品P1的属性A1持有O1的观点,P1是一种S1类型的商品,S1类型商 品是C1类型商品的子类,等等.
此外,随着商品知识规模的不断增大,用户对知识查询的响应速度要求也在不断提高,但是现有 的RDF知识查询系统的通用性对商品知识检索性能提升形成了阻碍,没有充分地考虑商品知识图谱 结构的特点.基于关系模型的知识查询系统查询性能较好,但对系统存储性能有较大要求;而基于图 模型的知识查询处理引擎则过度依赖知识数据的图结构,在进行商品知识检索时查询性能较低.因此, 希望能针对我们的商品知识数据,或者说对具有这种层次结构的知识图谱检索提出一种查询优化方 法.此外,随着硬件技术的不断发展,GPU (Graphics Processing Unit)的功能逐渐从图形计算领域衍 生拓展到通用計算领域,利用CPU (Central Processing Unit)和GPU的协同计算进行查询处理也成 为提高数据检索性能的一个突破口 .本文以大规模商品知识数据为研究对象,以提升商品知识检索的 性能为目标,提出一种高效可扩展的符合商品知识层次结构的查询处理技术,实现了一种基于CPU- GPU协同计算的商品知识查询处理方法,并在公开的标准数据集和半合成的商品数据集上验证了所 提出方法的有效性.总体而言,本文的主要贡献如下:
(1)对于具有层次化组织结构的知识图谱,如本文所研究的商品知识图谱,提出了一种基于稀疏 矩阵的存储策略,并依据层次化的结构特点进行存储优化;
(2)根据稀疏矩阵的存储结构设计了一种查询转换方式,将SPARQL查询转换为矩阵操作,并将 连接查询算法扩展到GPU上进行加速;
(3)在一个标准数据集和一个半合成数据集上验证了提出方法的有效性.实验结果表明,我们的 方法不仅在大规模的商品知识查询上具有较明显的优势,而且也对通用知识的查询处理具有实用性.
本文的组织结构如下:第1章简要描述了相关的工作;第2章主要介绍所设计的查询系统的总体 框架;第3章详细介绍了基于稀疏矩阵的知识表示;第4章对基于稀疏矩阵的查询转换方式及其优化 进行了详细的阐述;第5章对实验结果进行分析和讨论;第6章对本文进行总结.
1相关工作
根据RDF数据存储和查询方式的不同,目前RDF数据的查询系统主要分为两类:基于关系模型 的查询系统以及基于图模型的查询系统.
基于关系模型的查询系统通过关系型数据库对数据进行管理.Jena[3]使用一张巨大的表来分别存 储S、P、O值,并将SPARQL查询转换为SQL查询,但由于在执行连接查询时需要大量执行自连接 操作,所以查询代价很大.RDF-3X[4]则是通过将S、P、O的全排列都进行了存储,用于加速连接查询, 但也导致存储空间显著增加.S2RDF[8]将RDF数据划分成若干个关系表,借助Spark对RDF数据进 行存储和查询.BitMat[9]通过对RDF每个元素进行编号,并建立位图索引来收集候选查询,不过也面 临着大量空间浪费的问题.这类查询系统在存储具有层次化结构的知识数据时,不能有效利用其结构 特点进行优化.我们的方法针对这类数据的稀疏性,以及知识数据层与层之间只有一类谓语这一特点, 降低了索引矩阵的存储维度.
基于图模型的查询系统则是将SPARQL查询处理转换为子图匹配问题,能够对RDF数据中的语 义信息进行保留和查询.gStore[5]通过将谓语编码成二进制串并构建VS*-tree来辅助查询,查询处理 性能较关系型查询系统要高效.Kim等[10]在RDF数据图上结合深度优先和广度优先算法得到SPARQL 查询点的候选区域,并按照一定的匹配顺序找到查询的最终解.AMBER[6]则是将RDF数据和 SPARQL查询表示成多图,虽然复杂查询中的表现优于基于关系的系统,但几乎不可扩展.Zouaghi等 提出了一种基于图的RDF管理系统的优化策略,利用关系数据库的优势来描述图查询的逻辑结构[11]. Manolescu提出了一种结构化的遍历策略,通过寻找相似结构的节点组来搜索RDF图[12].这类基于图 模型的方法主要采用子图同构算法来完成查询,避免了连接操作.但由于缺乏并行性,这类查询系统 计算量都比较大,频繁的遍历操作造成了大量耗时.而我们针对存储结构设计了可以并行执行连接操 作的方法,可有效降低查询耗时.
近几年,利用新型硬件(特别是GPU)来加速RDF数据的查询是一个研究的热点.MapSQ[13]是一 个基于MapReduce的SPARQL查询处理框架,它首先通过CPU完成SPARQL子查询,然后利用 GPU执行子查询结果的连接操作.Tran等人将查询计划转化为一系列有利于GPU计算的原语操作 (如排序、归并等)|14]. TripleID-Q叫将编码后的RDF三元组装载到GPU的全局内存中,通过大量 GPU线程并行搜索需要的主体、谓词和客体.然而,RDF数据图的规模不断增大导致查询性能逐渐 降低,并且可拓展性变差.gSMat|16]则使用基于谓语的索引矩阵来存储数据,但是在连接查询的过程 中需要借助辅助数组来完成查询,而且无法用于缺失谓语的SPARQL查询.Wukong+G[1M吏用GPU 的高并行性和大内存带宽来加速处理具有大量中间结果的SPARQL查询.MAGiQ |18]则是使用矩阵 来处理异构环境下的SPARQL查询,但是由于该方法是构建了一个由所有实体组成的二维矩阵,在 面对稀疏性比较大且具有层次化结构的知识图谱时,这种存储方式会造成大量的空间浪费,而我们的 方法则是依据谓语来划分RDF数据,从而减少单个矩阵的大小,并且构建每个谓语索引矩阵的实体 只与对应的谓语相关.
2系统的整体架构
本文所设计的面向大规模商品知识的查询系统的整体架构如图2所示,该系统主要分为3个层 次,其核心功能主要在系统层.其中对于商品知识数据构建过程的主要模块是:RDF解析器、矩阵构 建器,而商品知识数据检索过程的主要模块是:SPARQL解析器、查询处理器.此外,还有一个提供数 据持久性的RDF矩阵和映射字典模块.
(1)RDF解析器:负责处理商品知识RDF数据文件,并对其中的主语、宾语及谓语构建与ID值 的双向映射.原生三元组和ID形式的三元组集合都将保存于映射字典中;
(2)矩阵构建器:主要将RDF解析器中得到的ID形式的三元组集合构建稀疏矩阵.依据谓语索 引来构建0/1矩阵,行列标签分别为三元组的主语和宾语.实现细节可见第3章;
(3)SPARQL解析器:该模块解析输入的SPARQL查询语句,并对查询语句进行预处理,以便查 询处理器执行查询;
⑷查询处理器:负责处理SPARQL查询任务,主要分为CPU计算与CPU-GPU计算两种查询模 式.具体实现细节见第4章;
(5) RDF矩阵及映射字典:当商品知识图谱数据有所更新时,如增加、删除等操作,将更新后的三 重映射关系以及稀疏矩阵进行同步更新和迭代,以保证全部RDF数据的完整性.
在接下来的章节中,我们将主要介绍矩阵构建器模块和查询处理器模块的实现细节,即基于稀疏 矩阵的知识表示方法以及基于稀疏矩阵的查询转换与处理.
3基于稀疏矩阵的商品知识表示
由于互联网上的商品知识数据大多以非结构化的形式存在,且这些数据具有一定的数据异质性 与冗杂性,这使得统一管理难度较大.因此,本文是在文献[7]所设计的商品知识组织结构的基础上, 对商品数据集的存储策略以及查询优化进行研究,通过分层的方式聚集同类型的数据,这有利于商品 知识数据的维护、检索以及推荐等.如图1所示,商品知识的实例片段大体上可以分为这几层结构:商 品分类层、商品实例层、商品属性层、用户观点层、用户层等,并根据不同层与层之间的关系,使用相 对应的谓语进行联系.
基于商品知识这类具有层次化组织结构的知识图谱,我们考虑使用稀疏矩阵进行知识表示.在读 取完RDF数据后,我们为三元组中的实体(主语、宾语)与关系(谓语)构建了与数字ID的双向映射, 从而将操作从字符串三元组转换为数字三元组,减少存储空间的同时也降低了数据I/O的耗时.商品 知识表示的转换过程如图3所示.
用S、P、O分别表示主语、谓语、宾语,将经过数字编码后的三元组按照S、P、O三个维度构建 一个知识数据立方体,如图3(a)所示.整个数据立方体的数值用0/1表示,假设存在编码后的三元组 (?巧,Ofc),则该三元组在数据立方体中的值为1;否则对应位置的值为0.
假设有一个查询三元组,通过索引Pi和巧即可以在数据立方体中定位到查询变量?^的 值.但是由于RDF数据集稀疏性较大,而且实体的数量会远多于关系的数量,这将导致存储数据立方 体的空间过大,因此需要将数据立方体进一步切分来优化存储效率.在优化的过程中,还需要考虑如 何使得存储的结构有利于连接查询操作.基于图模型的查询处理主要利用基本图模式匹配(Basic Graph Pattern)的思想,也就是基于子图匹配来完成查询处理,其特点主要是对每条查询三元组的实 体进行连接,形成一个查询图,从而在整个RDF数据形成的数据图中找到匹配的查询子图.这说明在 进行连接查询时其本质是对查询实体的连接,因此数据立方体的切分应当按照谓语(即维度P)进行 切分,从而保留主语和宾语的维度以便进行实体的连接,如图3(b)所示.数据降维后形成谓语索引的 S-O矩阵,对于RDF三元组(?巧,O&)的查询,可以通过索引谓语巧对应的S-O矩阵并定位到(?ofc) 来确定该三元組是否存在,从而保证降维后的三元组查询仍然具有高效性,如图3(c)所示.
此外,在本文的存储方案中,以0/1的矩阵值来表示实体之间是否存在某一关系,如图3(d)所示. 主语和宾语同为查询实体,具有相似的属性,因此在进行数字编码时将两者归在一块进行处理,这也 是常见存储方法的处理思路.假设整个数据集的实体数量为Mo,谓语数量为飾,则数据降维后的空 间复杂度为O(飾· ^1。).这相比于原始的数据立方体的存储效率虽然有提高,但是存储空间并没有降 低.一种比较直接的优化思路是将主语和宾语进行拆分,考虑商品知识具有层次化的组织结构特点, 这类知识图谱的特点是层与层之间的实体通过同一类型的有向边进行连接.因此,与一个谓语相关性 比较强的应当是相邻层的实体.对于谓语索引的S-O矩阵,可以利用这一特点进行降维.单个S-O矩 阵的维度由原来的W|O更改为M · Wo,即维度大小由与这一谓语相关性更强的主语和宾语决定,而不 是全部实体.
举例来说,根据图1中的谓语hasAttribute和谓语hasOpinion构建对应的谓语索引矩阵如图4所 示.图4(a)将所有商品和属性实体用关系hasAttribute进行汇总和索弓丨,比如商品P1具有A1和A2 属性,商品P2具有A3和A4属性;图4(b)则是将属性和用户观点实体用关系hasOpinion进行汇总和 索引,描述的是对于某一属性有哪些用户的观点.矩阵的横轴将由该关系所有的主语表示,纵轴由该 关系所有的宾语表示,并可以通过矩阵转置调换主语与宾语的位置关系.这种表示方式能够很好地利 用商品知识图谱的层次化结构特点,从而有效地降低存储空间.
4基于稀疏矩阵的查询转换
本章主要介绍基于稀疏矩阵的知识表示方法的查询处理,将按照3个部分进行介绍:查询处理、 查询预处理、基于GPU的查询优化.
4.1 查询处理
对于简单查询、不涉及连接查询的情况,可以直接通过查询三元组已知的元素来匹配查询变量. 对于有谓语的查询,则可以直接通过谓语索引到对应的S-O矩阵,从而直接匹配到需要查询的变量. 例如,假设 SPARQL 查询语句为 “SELECT ?x WHERE {P1 < hasAttribute > ?x.}”,即查询商品 P1 的所有属性,则可以直接对谓语hasAttribute矩阵进行操作,通过定位到P1所在的列向量,所有标识 为1的属性都为商品P1的属性.简单查询的转换过程如图5所示,最终商品P1具有的属性有A1和A2.而对于未给定的谓语的查询,可以遍历谓语索引矩阵,通过判断是否含有符合要求的主语/宾语来 确定最终要查询的谓语是什么,遍历谓语索引矩阵的时间复杂度为O(飾),其中飾为谓语的数量.
然而在真实的查询处理过程中,连接是复杂查询的核心操作.由于谓语索引矩阵的行和列分别由 主语和宾语构成且值为0或1,其中1表示某个主语与宾语所对应的实体存在谓语所对应的关系,0则 表示不存在.通常,矩阵相乘类似于一种连接过程,但矩阵相乘与连接查询有一个本质的不同,即查询 过程存在语义的转换,不同的语义查询结果不能进行合并,而矩阵相乘则会将行和列的值相乘后直接 相加,因此无法保存谓语索引矩阵中的语义关系.但可以从这种连接过程中得到启发,具有相同连接 变量的查询三元组,或者说具有相同连接实体的索引矩阵,可以按照对应实体的维度进行对齐,并对 相应行/列的元素进行位与操作.
为此,我们定义一种矩阵操作?,该运算的含义为:在进行矩阵维度的对齐后,进行行列扫描的过 程中将对应位置的每个元素进行位与操作;即当两个谓语索引矩阵需要进行连接运算时,当且仅当两 个矩阵需要连接的三元组的对应位置为i时,两个三元组的存在关系才能进行传递,表现为结果矩阵 中的值也为1.例如,对于存在连接操作的SPARQL查询“ SELECT ?yWHERE{?x
4.2查询预处理
由4.1节对复杂查询运算的介绍可知,查询三元组的排列顺序对查询语句能否按顺序执行构成直 接影响.因此,在执行查询之前还需要对查询进行预处理,即构思一种查询三元组的重排列方案,使得 在连续执行连接查询时,尽可能保证查询三元组之间存在可以连接的实体.
对于本文所研究的商品知识图谱,或者说这类具有层次化组织结构的知识图谱,根据图1所示的商品知识表示实例可知,在读取原始三元组数据时,可以依照谓语关系按照层与层之间分布的这一特 点,在构建谓语与数字ID的双向映射的过程中,保留谓语ID按顺序排列的规则,即按照谓语出现的 层次顺序从上往下(或者从下往上)去存储.根据这种谓语的排列规则,两两相邻的谓语索引矩阵一定 存在相连接的实体.
根据这一谓语存储规则,在进行查询预处理时,依据谓语映射过来的数字ID的顺序可以对查询 三元组进行重排列,从而保证在进行实际的查询过程中连接查询执行的连贯性,即连续执行连接查询 不会出现中断的情况.如果重排后发现查询三元组的实体存在不连续的情况,则说明该查询语句不存 在连接查询,从而可以判断该查询为简单查询,为之后的查询优化做准备.
4.3基于GPU的查询优化
通常而言,矩阵运算这种数据密集型的运算十分适合使用并行的方式进行处理,因此对于矩阵的 索引以及基于矩阵的连接查询也自然适合使用GPU进行加速运算.经过查询三元组重排后,可以保 证对于需要连续执行的连接查询存在可以进行相连接的实体.SPARQL查询由多个子查询三元组构 成,因此对于每条查询三元组,在对应的谓语索引矩阵中的查詢也可以使用并行的方式加速计算.而 对基于矩阵的连接查询,使用并行计算的方式也可以大大降低整个查询的计算耗时.对基于GPU的 查询优化采用如下几个步骤:
1.将每条查询三元组要查询的索引矩阵传输到GPU中,使用并行方式计算各查询的结果,并将 每条查询三元组的查询结果放入全局内存中,尽可能降低数据传输耗时;
2.在执行连接查询时,依据重排后的查询三元组顺序,依次对每条查询三元组的查询结果执行连 接运算,直到所有查询被执行完并得到最终的查询结果.每次连接查询后得到的结果矩阵大小由输入 矩阵的行/列决定.由于连接查询的中间结果会被频繁读写,所以每次得到的中间结果也会放入全局 内存中,但是上一次的查询中间结果会在下一次查询计算完成后被覆盖,这是为了尽量减少GPU 内存的占用.此外,在执行连接查询的过程中,随着查询条件的增多,本质上是对查询变量限制条件的 增加,因此中间结果的大小不会随着查询的增多而导致维度的增加;
3.将最终的计算结果传输回CPU中,并将查询变量对应的值作为最终的查询结果进行输出. 根据以上的查询步骤,我们期望在整个查询过程中充分利用GPU的并行性能,并尽量减少数据传输耗时.
5实 验
本章主要是评估我们的查询系统在标准数据集和商品知识数据集上的查询性能.我们的方法主 要是针对具有层次化结构的知识图谱进行了优化,但与此同时,也验证了我们的方法对于通用的知识 数据具有适用性.
5.1实验环境
实验的硬件环境为单台Intel(R) Core(TM) i7-8700 @ 3.20GHz的计算机,拥有16 GB DDR3内存 和 1 TB 普通硬盘,其中 CPU 型号为 3.20 GHz, GPU 型号为 NVIDIA GeForce GTX 1060 (1280SIMD, 6 GB显存),操作系统为Ubuntu 18.04 (64位),CUDA版本为9.0,使用C++11作为开发环境.此外, 为了增强实验结果的可靠性,对每轮的查询实验执行10次并将查询耗时取平均作为实验结果.
5.2标准数据集LUBM上的實验对比和讨论
为了验证基于稀疏矩阵的查询转换方式的有效性,实验对比采用了 6种不同数据量的LUBM数 据集(http://swat.cse.lehigh.edu/projects/lubm/),并使用该数据集自带的标准SPARQL查询语句进
行验证.这6个数据集的一些统计信息如表1所示.
LUBM数据集自带的6个标准SPARQL查询语句为Q1到Q6,对于我们的方法分别记录了 CPU 下和CPU-GPU协同下的查询响应时间,主要是为了验证我们的查询方法在标准数据集上的适用性. 实验结果如表2所示.
其中 Q1 为一个简单的查询(SELECT ?x WHERE {?x
5.3商品知识数据集上的实验对比和讨论
根据目前大多数电子商务网站中商品的组织,从Amazon上获取了商品的分类信息构建成商品知 识图谱中的商品分类层次,并将人工合成用户的观点信息整合到商品知识图谱中.每个用户遵从正态 分布随机挑选商品并发表评论,而用户评论中随机数量的观点知识也同样符合正态概率分布,该数据 集的一些统计信息如表3所示.
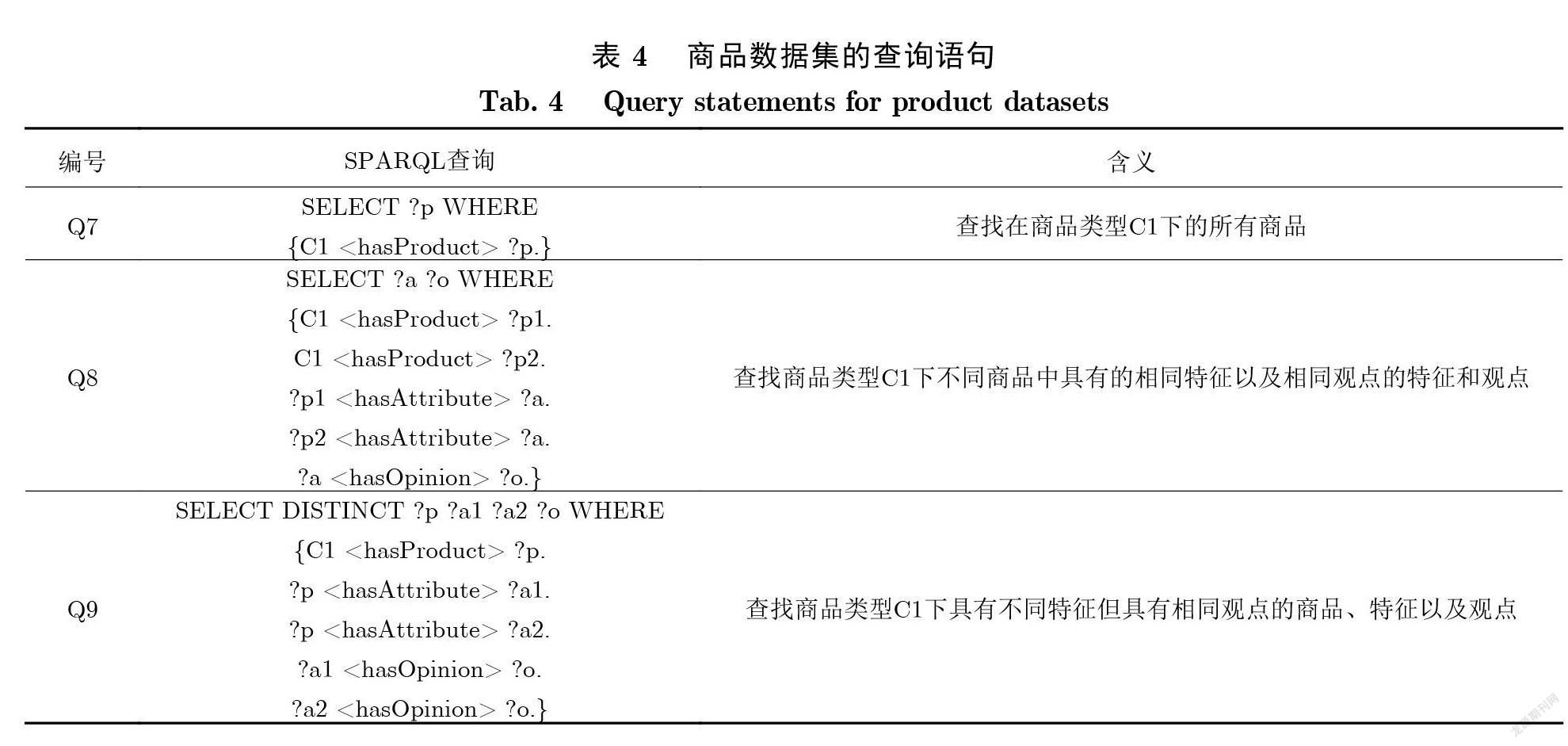
针对商品数据集,设计了 3个SPARQL查询语句,如表4所示,其中Q7为遍历式查询,Q8为链 式查询,Q9为环式查询.
在具有层次化结构的商品知识图谱上与常用的知识图谱查询系统RDF-3X和gStore进行对比, 其中设计的各查询语句在数据集AmazonDataset1、AmazonDataset2、AmazonDataset3上的运行时间 结果如表5所示.
实验结果显示,在三类商品知识数据的查询中,得益于CPU-GPU异构环境下的计算优势,我们 方法的平均查询时间比RDF-3X和gStore的平均查询时间短.即使是简单查询语句Q7,由于数据量 足够大,所以查询性能的优越性也得以体现;而且随着数据量和查询复杂度的进一步提升,我们提出 方法的查询效率提升也更加明显.
6总结
知识图谱已经成为众多智能应用的基础支持设施,面向大规模的知识数据提供高效的查询处理 是一个重要的问题.商品知识具有层次化结构的特点,现有的RDF知识查询系统在查询处理过程中 并没有充分考虑这种特点.本文针对大规模的商品知识图谱,提出了一种基于矩阵的存储方式,并依据层次化的组织结构特点进行了存储优化.同时,基于矩阵的存储方式有利于使用并行方式加速查询 的计算过程,本文设计了一种基于稀疏矩阵的查询转换方式,并将连接查询算法扩展到GPU上进行 加速.我们与常用的RDF查询引擎RDF-3X和gStore在标准数据集和商品知识数据集上进行了查询 性能对比.实验表明,文中提出的查询处理方法在大规模商品知识图谱上相对于对比方法具有较明显 的优势,同时在标准数据集上的实验表明,提出的查询处理方法也适用于通用知识数据的处理,并验 证了通过GPU提升大规模知识查询处理效率的可行性.
然而,GPU内存的大小仍然是制约其并行计算性能的主要因素.因此,在未来的工作中我们将针 对这一问题进一步优化存储结构,并且针对更大数据量的商品知识查询需求,还将研究在分布式环境 中CPU-GPU协同的知识查询处理.
[参考文献]
[1]陈强,代仕娅.基于金融知识图谱的会计欺诈风险识别[J].大数据,2021, 7(3): 116-129.
[2]TAKEDA A, ITO Y. A review of FinTech research [J]. International Journal of Technology Management, 2021, 86(1): 67-88.
[3 ] LEE K, LIU L. Scaling queries over big RDF graphs with semantic hash partitioning [J]. Proceedings of the VLDB Endowment, 2013, 6(1(4): 1894-1905.
[4]NEUMANN T, WEIKUM G. The RDF-3X engine for scalable management of RDF data [J]. The VLDB Journal, 2010, 19(1): 91-113.
[5]ZOU L, OZSU M T, CHEN L, et al. gStore: A graph-based SPARQL query engine [J]. The VLDB Journal, 2014, 23(4): 565-590.
[6]INGALALLI V, IENCO D, PONCELET P, et al. Querying RDF data using a multigraph-based approach [C]// International Conference on Extending Database Technology (EDBT 2016). 2016: 245-256.
[7]黃涛贻,李优,未浩,等.大规模商品知识的组织和查询优化[J].计算机工程与应用,2020, 56(2(1): 154-163.
[8 ] SCHTZLE A, PRZYJACIEL-ZABLOCKI M, SKILEVIC S, et al. S2RDF: RDF querying with SPARQL on Spark [J]. Proceedings of the VLDB Endowment, 2016, 9(10): 804-815.
[9]ATRE M, CHAOJI V, ZAKI M J, et al. Matrix Bit loaded: A scalable lightweight join query processor for RDF data [C]// Proceedings of the 19th International Conference on World Wide Web (WWW 2010). 2010: 41-50.
[10]KIM J, SHIN H, HAN W S, et al. Taming subgraph isomorphism for RDF query processing [J]. Proceedings of the VLDB Endowment, 2015, 8(1(1): 1238-1249.
[11]ZOUAGHI I, MESMOUDI A, GALICIA J, et al. Query optimization for large scale clustered RDF data [C]// Proceedings of the 22nd International Workshop on Design, Optimization, Languages and Analytical Processing of Big Data. 2020: 56-65.
[12]MANOLESCU I. Exploring RDF graphs through summarization and analytic query discovery [C] // Proceedings of the 22nd International Workshop On Design, Optimization, Languages and Analytical Processing of Big Data. 2020: 1-5.
[13]SONG J, PENG P, FENG Z, et al. MapSQ: A plugin-based MapReduce framework for SPARQL queries on GPU [C]// WWW18 Companion. 2018: 81-82.
[14]TRAN H N, CAMBRIA E, DO H G. Efficient semantic search over structured web data: A GPU approach [C]// International Conference on Computational Linguistics and Intelligent Text Processing (CICLing 2017). 2017: 549-562.
[15]CHANTRAPORNCHAI C, CHOKSUCHAT C. TripleID-Q: RDF query processing framework using GPU [J]. IEEE Transactions on Parallel and Distributed Systems, 2018, 29(9): 2121-2135.
[16]ZHANG X, ZHANG M, PENG P, et al. A scalable sparse matrix-based join for SPARQL query processing [C] // International Conference on Database Systems for Advanced Applications (DASFAA 2019). 2019: 510-514.
[17]WANG S, LOU C, CHEN R, et al. Fast and concurrent RDF queries using RDMA-assisted GPU graph exploration [C]// Proceedings of the 2018 USENIX Conference on Usenix Annual Technical Conference (USENIX ATC18). 2018: 651-664.
[18]JAMOUR F, ABDELAZIZ I, CHEN Y, et al. Matrix algebra framework for portable, scalable and efficient query engines for RDF graphs [C]// Proceedings of the Fourteenth EuroSys Conference. 2019: 1-15.
(责任编辑:林晶)
