
基于非易失性内存的LSM-tree存储系统优化
2021-03-14 00:43余阳胡卉芪周煊
华东师范大学学报(自然科学版) 2021年5期
关键词:机器学习
余阳 胡卉芪 周煊

摘要:随着大数据时代的到来,金融行业产生的数据越来越多,对数据库的压力也越来越大.LevelDB是 谷歌开发的一款基于LSM-tree架构的键值对数据库,有写入快和占用空间小的优点,被金融行业广泛应 用.针对LSM-tree架构的写停顿、写放大、对读不友好等缺点,提出了一种基于非易失性内存和机器学习 的L0层的设计方法,能够减缓甚至解决上述问题.实验结果表明,该设计能够实现较好的读写性能.
关键词:非易失性内存;机器学习;LSM-tree架构
中图分类号:TP392 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.004
Optimization of LSM-tree storage systems based on non-volatile memory
YU Yang, HU Huiqi, ZHOU Xuan
(School of Data Science and Engineering, East China Normal University, Shanghai 200062, China)
Abstract: With the advent of the big data era, the financial industry has been generating increasing volumn of data, exerting pressure on database systems. LevelDB is a key-value database, developed by Google, based on the LSM-tree architecture. It offers fast writing and a small footprint, and is widely used in the financial industry. In this paper, we propose a design method for the L0 layer, based on non-volatile memory and machine learning, with the aim of addressing the shortcomings of the LSM-tree architecture, including write pause, write amplification, and unfriendly reading. The proposed solution can slow down or even solve the aforementioned problems; the experimental results demonstrate that the design can achieve better read and write performance.
Keywords: NVM; machine learning; LSM-tree architecture
0引 言
近年來,以LevelDB和RocksDB为代表的LSM-tree (log-structured merge tree)存储引擎凭借其 良好的写性能被应用于多种数据库设计中.随着金融、互联网等行业的不断发展和成熟,在人工智 能、大数据、云计算等新技术的带动下,数据源不断增加,导致数据的绝对数量和产生速率都在以惊 人的速度膨胀.根据微软[1]和戴尔易安信主导的研究表明,2020年全球共产生了 40 ZB以上的数据. 因为LSM-tree架构具有写放大和对读不友好的缺点,巨量的数据也给这个技术带来了不小的挑战.
最近几年出现的非易失性内存(Non-Volatile Memory,简称NVM,也被称为Persistent Memory, 即PMEM,目前落地的产品是Intel的AEP)被认为是一种继Solid State Disk (简称SSD)之后的新 一代存储设备,是具有“革命性”的存储产品,会大幅提升数据存储的性能.与计算、网络产生的延迟相比,存储的延迟往往是非常高的.然而由于存储单元数量有限,可供能源有限,插槽数量有限,使得 继续提高Dynamic Random Access Memory (简称DRAM)的大小不太可能.所以探索NVM在低时 延和高吞吐的系统中的应用变得非常重要.
LSM-tree架构使用数据量指数递增的不同层来维护层内有序的数据.为了更好地理解基于 LSM-tree的键值对存储,我们通过实验评估了 Google开发的基于DRAM-SSD的主流键值对存储 LevelDB[3],发现其在大量数据并发写入的情况下出现了以下缺点:一是写停顿,即磁盘中的数据合并 速度慢,导致内存中的数据无法写入磁盘,使得用户的写入指令无法执行,产生写停顿,这违背了运营 数据库的可预测和稳定性能的设计目标.二是写放大,即已经写入磁盘的数据在合并时会被读出来并 重新排序写入磁盘,这样的排序和读写磁盘会消耗大量CPU时间和SSD带宽,大大增加前台的查询 时延.三是由于L。层的数据并没有维护一个全局的范围,所以随着L。层的数据增加,查询消耗在 L0层上的时间会随着数据量线性增加.
传统的DRAM-SSD的存储结构设计是为了利用DRAM的高性能和SSD的持久化能力以尽量低 的成本提供相对高效的数据库服务,其中的高性能部分主要是由DRAM的低时延和高吞吐所保证的, 由于LSM-tree的架构特性在Minor Compaction的时候存在DRAM到SSD的突发性高负载,这个时 候能够快速完成Compaction释放内存以处理新的请求对数据库整体的性能至关重要,而这个过程主 要受制于L。层的写性能,所以用有高写入性能的NVM做L。层对数据库的整体性能理论上会有比较 大的提升,由于Major Compaction不涉及DRAM到可持久化设备的这个过程,所以影响相对较小, 考虑到经济因素,除了 L。层外的持久化层还是用SSD.
本文以LSM-tree架构的上述缺点为出发点,引入NVM组成DRAM-NVM-SSD的混合存储减缓 甚至解决了上述问题.
本文的主要贡献如下:
(1)在DRAM和SSD的LSM-tree存储架构中,增加了 NVM层,并且设计了相对离散的结构,使 用类似内存池的技术给其分配空间;
(2)在NVM层上使用Learned Index技术,用学习到的索引模型预测数据的位置,加快数据在 NVM上的查找;
⑶弃用LSM-tree架构中传统的Major/Minor Compaction模式,采用渐进式的Compaction.
1 研究背景
本章介绍有关NVM和LSM-tree架构的背景,阐述目前LSM-tree架构和NVM的相关研究工作.
1.1非易失性内存
服务提供商一直都在追求更快的数据库访问.他们旨在不提高总拥有成本(TCO)的同时,提供给 用户更好的服务和体验.随着新型存储介质的开发和出现,例如相变内存[4]、忆阻器3D XPoint[6]和 STT-MRAM['使用NVM增强存储系统成为一个比较经济的选择.NVM是一种可字节寻址的、可持 久化的、低时延的存储介质.它被认为有望提供类似DRAM的读写性能,类似磁盘的持久化能力,并 以更低的价格提供比DRAM更大的空间.与SSD相比,NVM有望提供百分之一的读写延迟和10倍 以上的带宽[8].
NVM可以用作通过PCIe接口访问的可持久化存储设备,也可以用作通过内存总线访问的主内 存[9].现有研究[10]表明前者只能实现边际性能的改善,浪费了 NVM作为存儲介质的高性能.对于后者, NVM可以取代或者补充DRAM作为单极存储器系统[10]、NVM-SSD系统[11]或DRAM-NVM-SSD混 合系统[101.特别地,由于以下3个原因,使用DRAM-NVM-SSD混合存储被认为是一种使用NVM比 较有前景的方法.首先,NVM有望在接下来的数年中与大容量SSD共存.其次,DRAM依然有比NVM 低3倍的读写延迟和高5倍的带宽.最后,混合系统平衡了总拥有成本和系统性能.所以我们的系统 将专注于把NVM作为可持久化内存,高效地运用在DRAM、NVM和SSD组成的混合系统中.
1.2 LSM-tree 架构
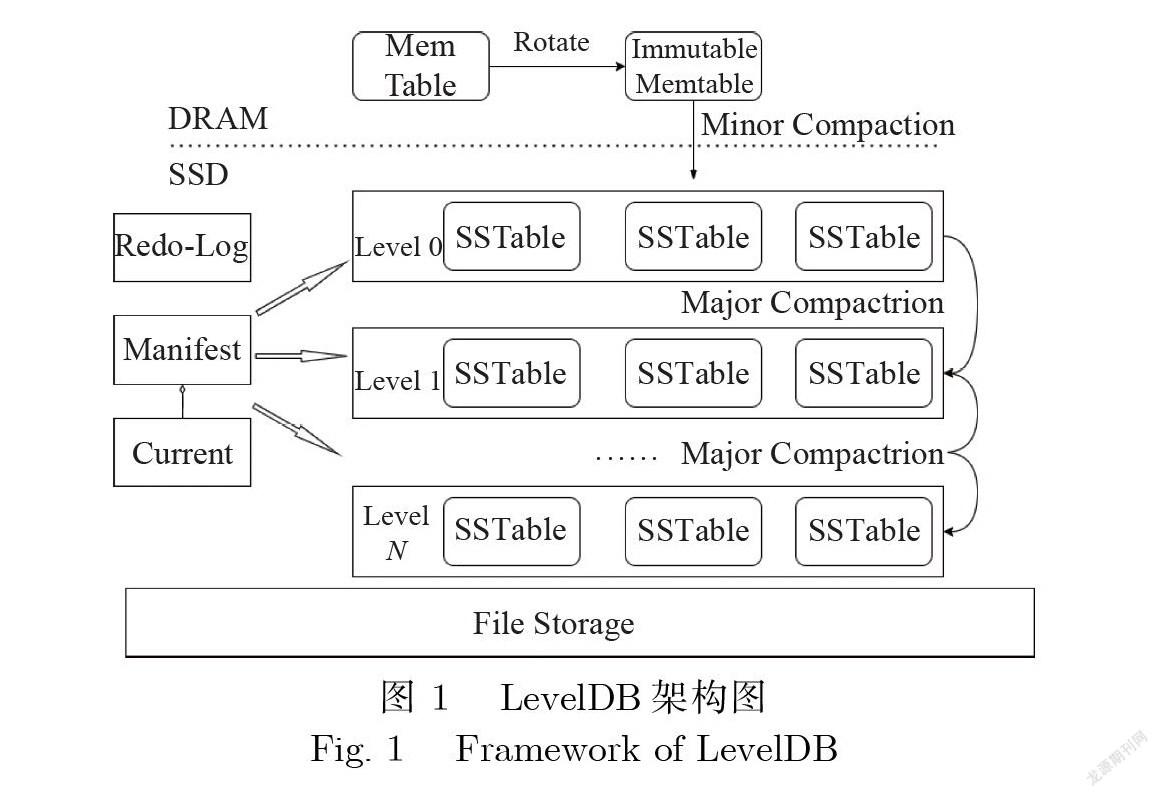
LSM-tree[12]架构通过分层设计充分利用存储设备的高顺序写带宽.图1是LevelDB的架构图,是 一种基于DRAM-SSD的LSM-tree架构的键值数据库.它拥有防止DRAM中数据丢失的redo日志, 防止数据受系统崩溃的影响.
写操作.数据首先写入磁盘,作为数据库恢复的Redo-Log;然后写入内存中的MemTable, MemTable由跳表实现,维护数据的有序性.数据的写入到此结束.当MemTable写满后,转变成不可 写入只可读取的 MemTable (Immutable MemTable);再将 Immutable MemTable 写入磁盘中的 L0 层,格式变为SSTable,这一过程称为Minor Compaction;当L0层数据达到阈值时,与L:层进行合并, 这一过程称为Major Compaction;磁盘中的每一层数据到达阈值后均向下进行Major Compaction.
在LSM-tree架构中,存在3种类型的写停顿.插人停顿:如果MemTable在Immutable MemTable 刷盘完成前被填满,所有写入LSM-tree的操作都会停止.刷盘停顿:如果L0层有许多的SSTable并 且达到了大小限制,则会阻止刷盘.合并停顿:太多的等待执行合并的任务阻塞了前台的操作,导致写 停顿.
L。层的每个SSTable文件内部的键值对是有序的,但文件之间是无序的甚至会有交集;L1层及以 上每一层的数据都是全局有序的,并且保证每一层的SSTable文件之间是没有交集的.
执行一次 Major Compaction,首先确定 L,层参加 Compaction 的 SSTable (被称为 Victim SSTable) 和 Lz+1 层中与 Victim SSTable 范围有交集的 SSTable (被称为 Overlap SSTable)作为 Compaction 的 初始输入.落入这个扩大后的范围的^层的其他SSTable被反向选择,从而确定了全部输入.将之前 选择的所有SSTable使用外部归并排序的方式写回到Lw层.由于L0层是未排序的,并且L0层中的 每一个SSTable的key范围都很大,所以几乎会选择Lq层和L1层中的所有SSTable来进行排序,导 致了全量的写放大.
读操作.读数据首先查询MemTable,然后查询Immutable MemTable,最后是L0层到Ln层中的 SSTable.由于LO层没有维护全局有序性,在LO层可能会查询多个文件.
1.3LSM-tree研究现状
现有的基于LSM-tree架构的提升包括:减少写放大、提高内存管理水平、支持自动优化、用混合 存储优化LSM-tree架构等.在这些工作中,随机写性能是一个被共同关注的点,因为受Compaction 影响,随机写会导致写停顿和写放大.下面讨论工作中最相关的3类:减少写放大,处理写停顿和使用 NVM.
减少写放大.PebblesDB[13]受到跳表启发,使用了 guard来维护一层的局部有序性;Lwc-tree[14]提 供了追加写数据合并元数据的轻量级Compaction; WiscKey[15]将键从值中分离出来,仅在Compaction 的过程中合并键,因此降低了写放大.但是其缺点是使垃圾回收和范围查询变得复杂,并且只从较大 的值中收益;LSM-trie[16]通过使用基于hash范围的Compaction来均摊Compaction的额外开销;VT- tree[17]以数据碎片为代价,使用额外的一层来重定向数据以避免重复处理使数据有序;TRIAD[18]通过 在内存,磁盘和日志之间创建协同工作来减少写放大;MatrixKV[19]在LO层上维护了一个逻辑上和 L)层的SSTable对应的key范围映射,减少了 Compaction时L0层的输入大小.
减少写停顿.SILK[20]引入了一个I/O调度器,它通过推迟刷盘和Compaction时间到低负载的时 候来减轻写停顿对用户的写影响;bLSM[21]提出了一种新的合并调度程序,用来协调多个级别的压缩; KVell[22]使得每一项键值在磁盘上乱序,从而减轻了基于NVMe SSD键值存储的写停顿,这不适用于 通用的SSD的系统.
使用NVM优化LSM-tree架构.SLM-DB[23]针对具有NVM-SSD存储的系统提出了单级的LSM- tree.它使用NVM上的B+树来索引SSD上面的单层LSM-tree以提供快速讀.这个方法引入维护 B+树和LSM-tree —致性的额外消耗;MyNVM[24]利用NVM作为块设备来减少基于SSD的键值存储 的DRAM使用;NoveLSM[10]和NVMRocks[9]采用了在NVM上的持久化可变内存表.然而,可变的 NVM内存表仅仅在某种程度上减少了访问时延,同时产生了更严重的写入停顿的负面影响; MatrixKV维护了 L。层上SSTable之间的偏序关系,从而减少了 L。层上整体的查找时延.
2问题分析
NVM能提供比SSD快100倍的读写速度和高10倍的带宽,但是传统的LSM-tree架构中的软件 栈能否完全利用NVM的硬件优势?为了理解在LSM设计中使用NVM的影响,我们使用NVM替换 SSD,来存储SSTable,分析读写数据的性能差异.数据的总大小是16 GB,单个键值对的大小是4 kB, 单个SSTable的大小是8 MB.图2比较了对SSTable进行顺序读、随机读、顺序写和随机写的吞吐量.
如图2所示,尽管NVM硬件提供了相对于SSD更快的读和写,但是顺序读和随机读时延相对 SSD仅仅减少了二分之一;顺序写时延仅仅减少为原来的六分之一.这个结果说明当前的LSM- tree 架构并没有充分利用 NVM 硬件的优势, 而且花费了大量的软件开销.我们之后来说明这些软件 开销的来源.
写操作时延.主要有3处:一是在数据写入内存表之前,为了避免机器故障或者断电引起的数据丢 失,首先会将数据及它的校验和写入磁盘的时延;二是数据写入MemTable的时延;三是合并带来的尾 时延,LSM-tree架构中,Minor Compaction需要将Immutable MemTable的数据写入磁盘,并序列化为 SSTable的格式,如果Minor Compaction耗时较长,会导致MemTable无法写人.Major Compaction需 要占用大量CPU资源和磁盘带宽,会拖慢所有的前台请求.两种Compaction操作都会导致写人时延.
图3显示了 4 kB,8 kB,16 kB这3种大小数据的3种写操作时延.如图3所示,数据合并在时延中占比 最大,达到了 79%;写日志占了总写入时延的21%;写入内存表的速度很快,几乎不用考虑它的时延.
读操作时延·主要分为两处:一是读内存,包括读取MemTable和Immutable MemTable.二是读 磁盘,从低往高读取每一层的SSTable文件.首先读SSTable文件中的索引,找到数据在SSTable文 件中的位置,再将找到的数据块拷贝到内存中,反序列化为内存格式,再在数据块中查找具体数据. 图4分析了读4 kB、8 kB和16 kB这3种大小的数据的读时延占比.对于小的值,查找SSTable占据 了主要时延;随着值大小的增加,反序列化和数据拷贝的占比逐渐增加.
总结· LSM-tree架构的读和写因为没有充分利用NVM的可字节寻址、低时延和高带宽的优势, 在软件上的性能损失过大.写操作的开销主要来自Compaction和日志更新,而读操作主要是SSTable 查找和反序列化.减少这些软件开销对发挥NVM的硬件优势非常重要.由于NVM可以随机访问和 高带宽低时延的特性,因此使用NVM作为L0层可以充分利用其硬件特性.对于写,由于不像读写粒 度是较大的page传统的可持久化存储设备,NVM是可以随机访问的,所以可以在Compaction的时 候边遍历边写入NVM,也不用构造page和序列化压缩之类的工作.对于读,也可以跳过对index block 和data block的查找以及换入换出cache的代价,直接对数据项进行二分查找,并且也没有反序列化 的过程.
3具体实现
为了解决合并带来的写时延问题,将LO层放在NVM上,希望利用NVM高效的读写速率和更高 的带宽,加速Immutable MemTable写入磁盘的过程.为了解决LO层文件之间无序、读时延高的问题, 我们针对LO层的文件实现了学习索引,能够更快地得到数据在LO层文件中的位置.架构如图5 所示,L0层存储在NVM上,L1层到匕。层存储在SSD上,针对L0层实现学习索引.
3.1基于非易失性内存的L。层实现
数据在NVM上的组织格式称为NVMTable,如图6所示,根据存储内容的不同,NVMTable 被分为3种Block: Super Block,保存文件的兀信息;Meta Block,标记某个key或者value在Entry Block中保存的是真正的数据还是指针;Entry Block,存储键值数据对,或者指针对.
Super Block是每个NVMTable的第一·个Block,共有5个数据:Magic Number,判断当前文件格 式是否为NVMTable; File Number,文件号;File Type,文件类型;NB Entry,文件中键值对的数量; CRC64,文件校验码.
每个Entry Block存储8个键值对,一个key后面紧跟着它的value,可能是数据也可能是指向数 据的指针.Entry Block的数量#为ceil (键值对总数/8).
每个Meta Block存储1024个键值对是否内联的位图信息.例如,对于键值对X,如果在Entry Block中保存的是真正的数据,则KeyInlineX和ValueInlineX为True;如果保存的是指向X的指针, 则 KeyInlineX 和 ValueInlineX 为 False. Meta Block 的总数 #为 ceil (键值对总数/1 02(4).
将数据写入NVMTable发生在Minor Compaction的时候,通常会创建一个NVMTable文件和一 个Container文件,其中Container文件是从Redo-log修改而来.对于要写入的键值对,首先判断其key 和value的长度是否小于32 B,如果小于32 B,则为内联数据,直接将数据写入Entry Block中;否则 将Container文件中对应的数据的指针写入Entry Block中.向Entry Block写入数据时,同时在内存 中创建Meta Block, —·边确定Meta Block的位图信息,一·边向Entry Block写入数据.待NVMTable不 再有数据写入,把内存中的Meta Block给追加到文件末尾,最后更新文件头部的Super Block,完成写入.
为了减少数据的存储空间,还对数据进行了前缀压缩.Container文件并不会为每一对键值对 都存储完整的key值,而是存储与上一个key不同的部分,避免了 key存储重复内容.每次用前缀压 缩存储若干个键值对后,设置检查点,重新记录一条完整的key,避免了读取某个key恢复路径过长的 问题.
3.2学习索引的实现
随着Minor Compaction次数越来越多,L0层的文件数也越来越多,由于L0层文件内部有序,文 件之间无序,系统读操作需要查找的文件数也随Minor Compaction的次数线性增加.所以需要实现 一种索引,来快速定位数据所在的文件及所在文件中的具体位置.
我们采用学习索引来定位一个key在LO层中的位置.首先对每一个NVMTable独立学习一个索 引模型,创建key到数据位置的近似映射,然后从近似映射的位置开始与目标key比大小,向前或者 向后线性查找到正确的位置.假设LO层一共有#个NVMTable,学习索引的平均误差为R 256 B中 平均有夂个元素,Seek的复杂度为而传统LSM-tree中的Seek复杂度为O(W x log2(M)), 如果要让学习索引的查找路径快于传统的路径,那么需要U/冗小于lOg2(M),所以模型的拟合尽量符 合真实分布变得非常重要.
学习索引的模型选择的是Piecewise Geometric Model (PGM)索引125],它是一種多层结构,每一层 代表有不同错误率下界的分段简单线性回归.图7是一个PGM索引的样例.第一层数据被划分为 3个分区,每个部分由一个简单的线性模型(/i, 石)代表.通过构造,每个线性模型在其相关的部分
以提前设置好的误差值预测key的位置.第一层的分区边界被视为它们自己的排序数据集,并且一个 有误差值下界的分段函数由这个数据集计算得到.重复这个过程直到顶层的PGM足够小.
一个分段线性回归方程使用一组点 p0, p1 , · · ·, pn将数据分为n + 1个段.线性回归分段函数被表示为:
每个在PGM索引里的回归都是使用固定误差.这种回归能够简单地被当作一个近似索引来使 用.PGM索引递归实施这些技巧,首先使用底层数据构建分段回归模型,然后使用第一个回归的分割 点来构建另外一个固定误差的分段回归.key查找是执行查找每一个回归模型,直到找到底层数据 为止.
PGM索引是从底层往上构建的:首先选中一个误差边界,然后用一个最小的线性分段模型达到 这个误差边界.重复这个过程直到分段模型比阈值更小.
3.3渐进式的 Compaction
LO层和Li层的key范围的重叠是引起写放大的主要原因.如果这些重复的key范围能够累积到 一定的数量再进行Compaction,那么多次写放大累积到一定程度会合并为一次写放大,从而减少了写 放大的总大小.渐进的Compaction方法如图8所示,即在LO层上的全局地址空间上维护许多个定长 的地址空间,并且使用内存池的方式维护空闲空间,根据内存表刷盘到非易失性内存上的地址分布, 维护不同定长的地址空间的最近使用情况.如果出现非易失性内存不够用的情况,那么触发内存清理 的步骤,清理步骤的主要目标是选择一个或者多个定长地址空间内的数据进行淘汰,选择的优先级从 高到低,首先是没有与Li层有交集的地址空间,其次是最近没有写入数据的地址空间,最后是数据量 多的地址空间.
如果某个地址空间的数据越来越多,会对读越来越不友好,同时维护一个全局的每个地址空间的 最大数据个数,如果超过这个数,就触发强制回收.
4实验评估
在LevelDB上,验证修改LO层的设计后其读写性能是否得到提升.
4.1实验环境
将修改后的LevelDB部署在单机环境中,使用的Linux内核版本为x86_64 Linux 5.11.16-arch1- 1,硬件配置为:Intel Xeon Gold 6240R @ 96x 4 GHz 型号 48 核心 96 线程的 CPU,128 GB 的 DRAM, 512 GB 的 NVM,1 TB 的 NVMe 接口的 SSD.
4.2前缀压缩的空间利用率
实验目的:测试使用NVM前后的空间利用率.
实验设置:将10000000条随机的key、大小为256 B、value为空的数据分别插入到原本的SSTable 文件和Container文件中.
實验结果:在关闭压缩后检查点间隔相同的SSTable上所有数据所占空间为82.3 MB,在使用前 缀压缩后为71.5 MB,压缩比为1.15 : 1,除了空间上的优势,在NVM上的格式少了很多meta信息, 比如index block, filter block等,降低了实现的难度.
4.3写性能
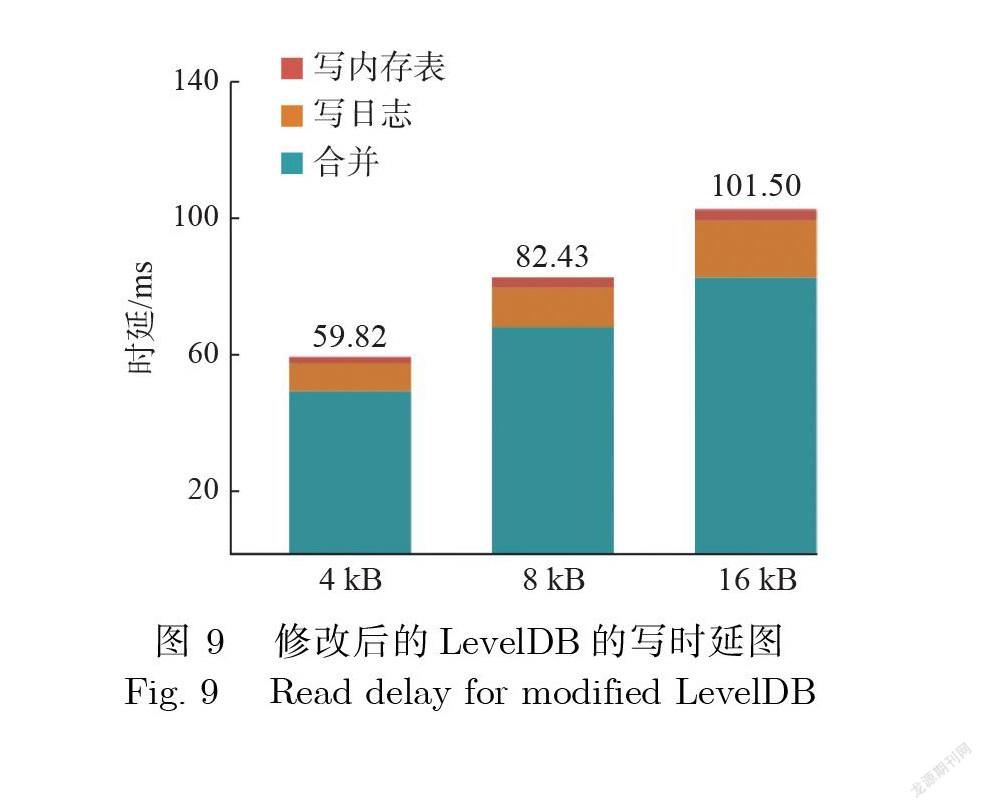
实验目的:测试不同数据大小下,修改后的LevelDB的写性能.
实验设置:key自增模拟金融业务下数据库生产环境中主键自增的常见场景,分别测试4 kB, 8 kB, 16 kB这3种不同大小的value的写时延,每种大小的数据分别生成10万条测试数据,测试数据属于 均匀分布.L0层的文件数量上限为10.
实验结果:如图9所示,可以发现总体写时延相对图3没有修改的情况都降低了 30%左右.由于 写内存表和写日志的路径基本没有变化,但是内存表持久化的过程由DRAM到SSD变为了 DRAM 到NVM,所以减少的大部分时延都是来自合并.
4.4读性能
实验目的:测试不同数据大小下,修改后的LevelDB的读性能.
实验设置:key在数据范围内使用高斯分布,模拟金融业务下数据库访问中存在查询热点的情况, 分别测试4 kB, 8 kB, 16 kB这3种不同大小的value的读时延,每种数据分别生成10万条测试数据, 测试数据属于均匀分布,之后生成在测试数据范围内均匀分布的10万条查询.
实验结果:如图10所示,可以发现总体读时延相对图4没有修改的情况都降低了 50%左右.将 LO层放在NVM上,缩短了 LO层的查询路径,由于CPU可以直接读取NVM上的数据,所以省略了 图4中的数据拷贝和反序列化,而图4中的数据拷贝和反序列化流程时间占了整体查询流程的一半, 同时查找学习索引也比传统SSTable的二分查找更快.
4.5学习索引性能
实验目的:测试使用学习索引后,从单个SSTable文件中定位到某个key的时间.
实验设置:主键长度设置为16 bit,主键为自增,矩阵库使用的是Eigen[26],高精度库使用的是 gmp[27],精度设置为1000.主键的检查点间隔为16,使用由检查点作为训练集训练出来的模型来预测 输入主键对应的检查点的位置.
实验结果:通过向量乘法得到预测检查点编号的时间固定为5.7叫,理论上学习索引的查询时延 不会随着key的增加而增加,但是如表1所示,查询的时间是增加的,可以认为学习索引的预测随着 精度不够越来越不准,造成在线性查找正确的检查点上花费了更多时间,在key数量较多的时候查询 时间可能会有劣势,所以理论上学习索引应该是固定代价,但是实际工程上的实现因为模型难选择和 计算精度不够难以在大规模数据上应用.
5 结论
本文提出了一个针对高并发,高吞吐场景下的基于NVM的LSM-tree架构,该结构充分利用了 NVM可字节寻址、可持久化能力和大容量的优点.本文基于LevelDB实现了上述设计,通过实验证明,将NVM 引入LSM-tree架构能有效地降低读写时延.目前的设计只针对离散型的SSTable进行了测试,并未对 不同的SSTable格式做实验.如何选择SSTable的不同形态及其收益也是值得探讨和关注的问题.
[参考文献]
[1]EL-SHIMI A, KALACH R, KUMAR A, et al. Primary data deduplication—large scale study and system design [C] //2012 USENIX Annual Technical Conference. USENIX Association, 2012: 285-296.
[2]SHILANE P, HUANG M, WALLACE G, et al. WAN-optimized replication of backup datasets using stream-informed delta compression [J]. ACM Transactions on Storage, 2012, 8(4): 1-26.
[3]GOOGLE INC. LevelDB [EB/OL]. [2019-06-20]. https://github.com/google/leveldb.
[4]BHASKARAN M S, XU J, SWANSON S. Bankshot: Caching slow storage in fast non-volatile memory [J]. ACM SIGOPS Operating Systems Review, 2014, 48(1): 73-81.
[5]STRUKOV D B, SNIDER G S, STEWART D R, et al. The missing memristor found [J]. Nature, 2008, 453(719(1): 80-83.
[6]IZRAELEVITZ J, YANG J, ZHANG L, et al. Basic performance measurements of the intel optane DC persistent memory module
[EB/OL]. (2019-03-1(3) [2021-06-12]. https://arxiv.org/pdf/190305714v1.pdf.
[7]DRISKILL-SMITH A. Latest advances and future prospects of STT-RAM [C]//Non-Volatile Memories Workshop. 2010: 11-13.
[8]CAULFIELD A M, DE A, COBURN J, et al. Moneta: A high-performance storage array architecture for next-generation, non-volatile memories [C] //2010 43rd Annual IEEE/ACM International Symposium on Microarchitecture. IEEE, 2010: 385-395.
[9]LI J, PAVLO A, DONG S. NVMRocks: RocksDB on non-volatile memory systems [EB/OL]. [2021-06-20]. http://istc-bigdata.org/ index.php/nvmrocks-rocksdb-on-non-volatie-memory-systems/.
[10]KANNAN S, BHAT N, GAVRILOVSKA A, et al. Redesigning LSMs for nonvolatile memory with NoveLSM [C]//2018 USENIX Annual Technical Conference. USENIX Association, 2018: 993-1005.
[11]WU M, ZWAENEPOEL W. eNVy: A non-volatile, main memory storage system [J]. ACM SIGOPS Operating Systems Review, 1994, 28(5): 86-97.
[12]JAGADISH H V, NARAYAN P P S, SESHADRI S, et al. Incremental organization for data recording and warehousing [C]//Proceedings of the 23rd VLDB Conference. 1997: 16-25.
[13]RAJU P, KADEKODI R, CHIDAMBARAM V, et al. Pebblesdb: Building key-value stores using fragmented log-structured merge trees [C]//Proceedings of the 26th Symposium on Operating Systems Principles. 2017: 497-514.
[14]YAO T, WAN J, HUANG P, et al. A light-weight compaction tree to reduce I/O amplification toward efficient key-value stores [C]//Proceedings of the 33rd International Conference on Massive Storage System Technology (MSST). 2017: 1-13.
[15]LU L, PILLAI T S, GOPALAKRISHNAN H, et al. Wisckey: Separating keys from values in SSD-conscious storage [J]. ACM Transactions on Storage, 2017, 13(1): 1-28.
[16]WU X, XU Y, SHAO Z, et al. LSM-trie: An LSM-tree-based ultra-large key-value store for small data items [C]//2015 USENIX Annual Technical Conference. USENIX Association, 2015: 71-82.
[17]SHETTY P J, SPILLANE R P, MALPANI R R, et al. Building workload-independent storage with VT-trees [C]//11th USENIX Conference on File and Storage Technologies. USENIX Association, 2013: 17-30.
[18]BALMAU O, DIDONA D, GUERRAOUI R, et al. TRIAD: Creating synergies between memory, disk and log in log structured key- value stores [C]//2017 USENIX Annual Technical Conference. 2017: 363-375.
[19]YAO T, ZHANG Y, WAN J, et al. MatrixKV: Reducing write stalls and write amplification in LSM-tree based KV stores with matrix container in NVM [C]//2020 USENIX Annual Technical Conference. USENIX Association, 2020: 17-31.
[20]BALMAU O, DINU F, ZWAENEPOEL W, et al. SILK: Preventing latency spikes in log-structured merge key-value stores [C]//2019 USENIX Annual Technical Conference. USENIX Association, 2019: 753-766.
[21]SEARS R, RAMAKRISHNAN R. bLSM: A general purpose log structured merge tree [C] //Proceedings of the 2012 ACM SIGMOD International Conference on Management of Data. 2012: 217-228.
[22]LEPERS B, BALMAU O, GUPTA K, et al. KVell: The design and implementation of a fast persistent key-value store [C]//Proceedings of the 27th ACM Symposium on Operating Systems Principles. New York: Association for Computing Machery, 2019: 447-461.
[23]KAIYRAKHMET O, LEE S, NAM B, et al. SLM-DB: Single-level key-value store with persistent memory [C]//17th USENIX Conference on File and Storage Technologies. USENIX Association, 2019: 191-205.
[24]EISENMAN A, GARDNER D, ABDELRAHMAN I, et al. Reducing DRAM footprint with NVM in Facebook [C]//Proceedings of the Thirteenth EuroSys Conference. 2018: 1-13.
[25]FERRAGINA P, VINCIGUERRA G. The PGM-index: A fully-dynamic compressed learned index with provable worst-case bounds [J]. Proceedings of the VLDB Endowment, 2020, 13(10): 1162-1175.
[26]EIGEN. [EB/OL]. [2019-06-20]. https://eigen.tuxfamily.org/.
[27]GMP. [EB/OL]. [2019-06-20]. https://gmplib.org/.
(責任编辑:林晶)
猜你喜欢
电子技术与软件工程(2016年22期)2016-12-26
时代金融(2016年27期)2016-11-25
科教导刊(2016年26期)2016-11-15
活力(2016年8期)2016-11-12
科学与财富(2016年28期)2016-10-14
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年12期)2016-06-14
科教导刊·电子版(2016年10期)2016-06-02
科教导刊·电子版(2016年10期)2016-06-02
电脑知识与技术(2016年3期)2016-04-07
