
曰志结构合并树的查询优化技术
2021-03-14 04:51:21孙家博蔡鹏
华东师范大学学报(自然科学版) 2021年5期
孙家博 蔡鹏


摘要:针对基于日志结构合并树(Log Structured Merge Tree, LSM-tree)的数据库查询性能较差的问题, 目前的研究工作主要集中在利用索引和缓存技术提升LSM-tree的查询性能.本文主要从以下几个方面对 LSM-tree的查询优化技术进行了综述.第一,介绍了 LSM-tree的基础架构,分析了影响查询的因素.第二, 分析了当前的LSM-tree查询优化技术,包括索引优化技术和缓存优化技术.第三,分析了索引和缓存技术 是如何提升基于LSM-tree的数据库查询性能的,并总结了一些现有的研究工作.最后,总结并给出了未来 可能的研究方法.
关键词:日志结构合并树;索引;缓存
中图分类号:TP392 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.009
Query optimization technology based on an LSM-tree
SUN Jiabo, CAI Peng
(School of Data Science and Engineering, East China Normal University, Shanghai 200062, China)
Abstract: Given challenges with poor query performance for databases using LSM-trees, the present research explores the use of index and cache technologies to improve the query performance of LSM-trees. First, the paper introduces the basic structure of an LSM-tree and analyzes the factors that affect query performance. Second, we analyze current query optimization technologies for LSM-trees, including index optimization technology and cache optimization technology. Third, we analyze how index and cache, in particular, can improve the query performance of databases using LSM-trees and summarize existing research in this area. Finally, we present possible avenues for further research.
Keywords: LSM-tree; index; cache
0引 言
隨着金融领域数字化和信息化程度的不断发展,交易量不断增长,同时交易场景也越来越复杂, 并且数据也迎来了爆发式的增长,而数据库作为基础数据存储的基础设施,对其产生了新的挑战.传 统数据库已经无法很好地满足数据密集型应用的数据存储需求,而KV存储由于其简单性、高吞吐量 和可伸缩性,已经成为数据密集型应用的数据存储设施的重要组成部分,并且作为存储引擎应用许多 领域中.例如,文献[1-4]中已经成功应用在媒体领域,还有应用于电子商务领域的亚马逊Dynamo151、 虚拟货币领域[6]、数据流和日志处理领域[7-10]、图数据库[11-12]、地理空间数据库[13]、文件系统[14-15]以及硬 件存储系统116-171等领域.
KV存储主要的底层设计有哈希存储、B树(B+树)[18]和LSM-tree[19]等.LSM-tree作为KV存储结构最流行的底层设计之一,已经应用在 BigTable[2Q]、LevelDB[21]、RocksDB[22]、Cassandra[23]、HBase[24]、 AsterixDB[25]和Dynamo[5]等KV数据库中.通过利用LSM-tree将数据先写入内存,然后顺序写入磁 盘的特性,这些系统获得了非常优秀的写性能.然而由于LSM-tree的特殊结构,这些基于LSM-tree 的KV数据库的数据查询性能往往不是很理想.LSM-tree是由多层结构组成的,在执行查询操作时, 为了找到目标数据,需要逐层遍历进行检查,会产生较大的查询开销,并且这个过程会产生严重的读 放大问题.因此,在尽可能保证写性能的情况下优化LSM-tree查询性能是非常必要的.
目前,索引和缓存技术是数据库系统中最常见的查询优化技术.索引能够快速定位到需要查找的 数据所在的位置,通过这种方式可以有效地减少磁盘I/O,以此来提升数据库的查询性能.除了利用 索引快速确定数据的位置,还可以利用缓存技术将磁盘中的经常被访问到的数据缓存到内存中.查询 这部分数据时可以直接从内存中读取,而不需要访问磁盘,能够有效地提升数据库的查询性能.
本文将从以下几个部分展开:第1章介绍LSM-tree的基础结构,分析其插入、合并、查询过程以 及查询过程所存在的问题;第2章介绍基于索引技术对LSM-tree的查询优化,以及总结现在已有的索 引优化方案;第3章介绍LSM-tree基于缓存技术的查询优化,并总结目前已有的优化方案及其优缺点; 第4章总结全文并给出LSM-tree查询优化未来可能的研究方向.
1LSM-tree基础结构与分析
传统的同步更新存储结构,例如B+树,在新的数据更新到来时会直接覆盖旧值.这种结构中存储 的数据是最新版本的值,并且作为多路查找树,在执行查询操作时能够快速确定目标数据的位置,有 利于查询操作的执行.然而,由于在插入和更新数据时会产生随机读写操作,并且可能会造成B+树结 构的改变,这些原因导致同步更新索引结构并不适合大规模数据写入的场景.与之相对应的是异步更 新存储结构,这种结构中比较具有代表性的是LSM-tree.在更新数据时,不会直接覆盖旧值,而是选 择直接插入一条新数据,这种设计可以利用顺序I/O来提升数据库的写性能.但是在这种情况下,同 一个数据可能存在多个版本,给数据库的查询性能带来了不利影响.
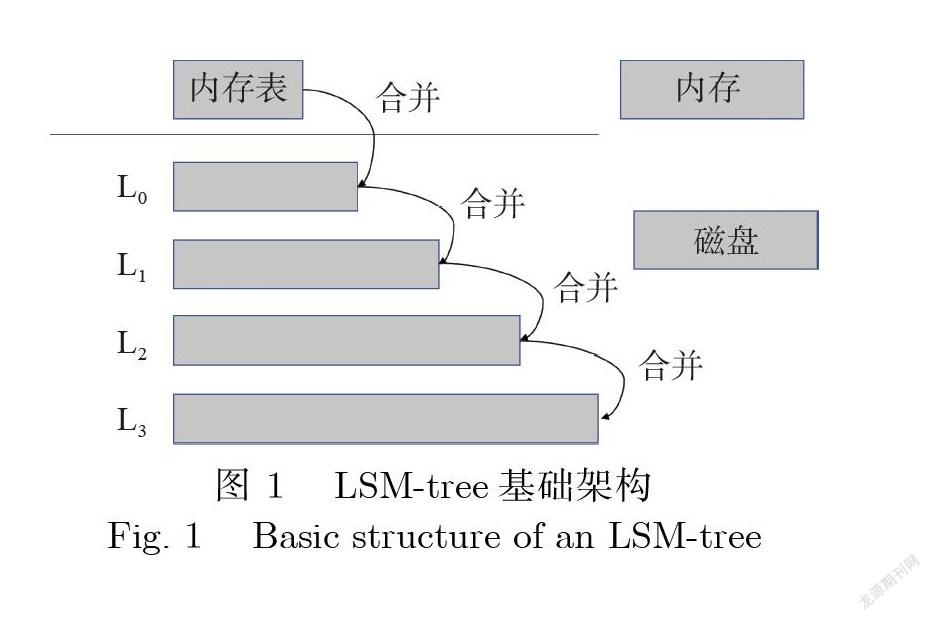
随着金融领域数字化和信息化程度的不断发展,数据规模越来越大,数据产生的速度也越来越快, 对数据库的数据写入速度要求也越来越高.而传统的同步更新存储结构针对大规模数据写入场景的 性能表现并不理想,ONeil等[19]在1996年提出了 LSM-tree结构作为数据库的底层存储结构,这种存 储结构为数据库带来了非常优秀的写性能.LSM-tree作为异步更新存储结构的代表,主要包含内存组 件和磁盘存储组件两个部分,如图1所示.内存组件在实现时被分为两个部分:活跃的内存表和不可 更改的内存表,主要用来存储新插入的数据.磁盘存储组件是多层存储结构,并且每层的数据文件都 是有序存储.在目前比较流行的LSM-tree存储引擎中,例如LeveDB和RocksDB,均采用了有序的文 件表(SSTs),将每层的文件分成许多有序的小文件.
LSM-tree是以插入一条新数据的方式来实现插入和更新操作.新插入的数据首先写入活跃的内 存表中,当活跃内存表的大小达到设定阈值时,会转换为不可变的内存表,并通过刷盤操作将数据顺 序地写入磁盘上的L。层.当L。层的大小到达设定的阈值或满足其他条件时,将会触发合并操作,将 LO层的部分文件合并到Li层,同样Li层也会在一定条件下合并到L2层,以此类推,直到数据合并到 最后一层.每层能够容纳的文件大小一般是以固定的倍数增长,默认情况下,相邻层之间大小比值是 10.在合并过程中,将会对数据进行排序.由于LSM-tree采用的是数据追加的方式更新和删除数据, 因此,在这个过程中还会删除不需要的旧版本数据或者被标记为删除的数据.
通过以上过程,LSM-tree能够实现非常优秀的写性能.由于LSM-tree采用异步更新的方式,相同 主键的数据也许会在不同层的文件中存在多个版本.为了保证能够有效地查询到最新数据,LSM-tree 一般采取以下措施:①当数据写入内存中时,如果内存中存在主键相同的数据,会覆盖掉内存中旧版 本的数据,只保留最新的数据;②当数据发生合并时,如果参与合并的文件中存在相同主键的数据,合 并过程中会清除旧版本的数据,只保留新版本的数据.通过以上方式能够实现在逐层查询数据时,查 找到的第一个目标数据就是当前最新版本的数据.
数据查询操作主要分为点查询和范围查询两种类型.在LSM-tree中,对于点查询,首先会从内存 中查找,如果内存中存在目标数据,则直接返回;如果内存中不存在目标数据,则在磁盘中逐层查找, 直到找到目标数据或者判断数据不存在.范围查询的目的是找到目标范围内所有的最新数据,这个过 程会遍历LSM-tree每层的文件,最后合并每层的查询结果并返回目标数据.
LSM-tree由于其非常优秀的写性能已经获得了广泛的实际应用,如Amazon^ Chrome[21]、 Facebook126-271、LinkedIn和阿里巴巴|28-29].但是,由于在LSM-tree数据库中同一·个数据可能存在多个 版本,并且由于分层结构,在执行查询时需要逐层遍历,特别是范围查询需要合并不同版本的记录来 返回正确的查询结果,这个过程极大地影响了 LSM-tree的查询性能.针对LSM-tree查询性能较差的 问题,许多研究人员提出了多种方法来优化和提升LSM-tree的查询性能.目前主流的LSM-tree查询 优化技术可以分为两种:一种是基于索引的查询优化技术,另一种是基于缓存的查询优化技术.
2基于LSM-tree的索引查询优化技术
数据库执行查询操作时确定目标数据的位置是非常重要的一步,同样也会产生较大的性能开销. 因此,快速地确定目标数据所在的位置,可以减少查询过程中对磁盘中数据的读写开销,将能够有效 地提升数据库的查询性能.通过对数据库中的数据建立索引,能够实现不用扫描整个数据表就能快速 确定目标数据的位置,因此,通过使用索引能够有效地提升数据库的查询性能.目前,在LSM-tree中 具有代表性的查询优化索引是布隆过滤器(Bloom Filter).
2.1布隆过滤器
布隆过滤器[301是Burton H. Bloom在1970年提出的一种概率数据结构,其通过利用位数组表示 一个集合,能够快速地判断一个元素是否属于这个集合.如图2所示,布隆过滤器对插入的数据主键 使用多个哈希函数映射到位数组的多个位置,并将对应位置的值置为1.在查询数据时,布隆过滤器使 用哈希函数检查位数组中对应位置的值.如果值为1,则可能存在;如果不为1,则一定不存在.这种情 况下,可能会出现将不属于该集合的元素误认为属于该集合.例如图2(c), z虽然不存在,但布隆过滤 器会判断z在集合中,即出现误判.但是布隆过滤器不会把属于该集合的元素误认为不属于该集合.
布隆过滤器的误判率是P=(l-e-表示哈希函数的数量,m表示位数组的大小,n表示集 合中元素的个数[31].利用布隆过滤器能够快速判断目标数据是否在当前文件中,但出现误判时,会对 磁盘产生额外的访问开销,影响查询性能.因此,降低误判率是针对布隆过滤器优化的一个重要方向.
当= fln2时,布隆过滤器的误判率最低,并且当集合中元素个数n—定时,位数组的大小m越大,布 隆过滤器的误判率P越低.但是位数组越大,占用的内存空间越多,因此,如何在误判率和存储空间占 用之间取得平衡也是一个重要的优化方向.
2.2索引优化技术
为了提升LSM-tree的点查询性能,许多基于LSM-tree的数据库引擎[21-22]在内存中使用布隆过滤 器对磁盘中的数据建立索引.当查询数据时,会在访问某个数据文件之前,先通过布隆过滤器检查目 标数据是否存在对应的数据文件中.如果布隆过滤器检查不存在,则跳过这个数据文件,以此减少对 磁盘数据的访问开销;否则,访问磁盘并读取相应的数据文件,然后通过查找算法在该数据文件中查 找目标数据,如果找到目标数据则返回,若没找到,即出现误判,则继续查找其他数据文件.
在使用布隆过滤器查询过程中出现误判会增加额外的数据访问开销.文献[32]中提到LSM- tree 最壞情况下 (即目标数据在数据库中不存在的情况) 的查询开销与 LSM-tree 所有层上的布隆过滤 器的误判率之和成正比.目前,大多数基于LSM-tree的数据库存储引擎[21-23]中实现的布隆过滤器,其 磁盘中每个文件对应的布隆过滤器的误判率都是相同的.通过2.1节中的分析能够知道,在数据数目 一定的情况下,想要降低布隆过滤器的误判率,就需要分配更多的内存空间给位数组.LSM-tree中的 层数越高,存储的数据越多,特别是最后一层,存储着大部分的数据,因此,对应的布隆过滤器占用的 内存空间也较大.如果同时降低每层对应的布隆过滤器的误判率,将会占用大量的内存空间.
Monkey[32-33]是一个基于LSM-tree的KV存储引擎,在给定内存资源的条件下,能够实现更新 和查询开销的最佳平衡.为了减小LSM-tree所有层上的布隆过滤器误判率之和,Monkey不再保持 LSM-tree中每层对应的布隆过滤器误判率都相同,而是设置每层的误判率与其数据量成正比,并且一 般情况下上层的数据访问频率更高,通过给最上层的布隆过滤器分配更多的内存空间降低对应的误 判率,在总内存资源一定的情况下实现所有层的布隆过滤器误判率之和最小.
一般情况下,查询操作会频繁访问某些数据,或者随着时间的改变,不同数据被访问的频次也会 发生改变.针对这个问题,Elasticbf[34]设计了一种可根据数据冷热程度动态调整的布隆过滤器管理方 案.与传统方案中每个文件构造一个布隆过滤器并分配^个哈希函数不同,Elasticbf为磁盘上的每个 文件构造了 ^个布隆过滤器,并为每个布隆过滤器分配fc/r个哈希函数.同时,为了减少对内存资源的 占用,Elasticbf将部分布隆过滤器存储在磁盘上,并根据数据的冷热程度动态调整磁盘和内存中的布 隆过滤器.实验表明,在使用相同内存的情况下,针对不同工作负载,Elasticbf能够有效地减少布隆过 滤器误判带来的读写开销.
布隆过滤器主要针对点查询进行优化,对于范围查询优化效果并不理想.LevelDB[21]和RocksDB[22] 使用前缀布隆过滤器优化范围查询,但是只能处理有共同前缀主键的范围查询,范围查询性能并不理想.
文献[35]提出了一*种新的数据结构 SuRF (Succinct Range Fliter),是基于 FST (Fast SuccinctTries)构建的一种能够支持点查询和范围查询的数据结构.FST采用LOUDS-DS编码字典树,该字典 树上层节点较少,由访问频繁的热数据组成;下层包含大部分的节点,由冷数据组成.LOUDS-DS采 用层内有序的布局,利用这个特点,LOUDS-DS能够有效地支持范围查询.如图3所示,Full Tire能够 准确查找每一条数据,但是会占用大量的内存资源.为了平衡过滤器的误判率和所需的内存资源, SuRF采用了剪枝字典树,并提出了不同的优化方案.SuRF-Base只存储能够识别每个主键的最小长 度的主键前缀,但是这种方法对于主键前缀相似度较高的场景会带来较大的误判率.例如,实验表明, 对于邮件地址作为主键的数据会带来将近25%的误判率.为了降低SuRF-Base的误判率,SuRF-Hash 为每个主键增加了一些散列位,查询时通过哈希函数映射到对应位检查目标数据是否存在.实验表明, SuRF-Hash只需2?4个散列位就可将误判率降低至1%.虽然SuRF-Hash能够有效地减低误判率, 但是并不能提高范围查询的性能.与SuRF-Hash不同的是,SuRF-Real在每个主键前缀的后面存储 n个主键位增加主键的区分度,在降低误判率的同时提升了点查询和范围查询的性能,但是由于有些 主键的前缀区别较小,SuRF-Real的误判率不如SuRF-Hash低.SuRF-Mixed结合了 SuRF-Hash和 SuRF-Real的优点,能够有效地支持点查询和范围查询.
Rosetta[36]使用一组分层排列的布隆过滤器对每个主键的二进制前缀建立索引,然后将每个范围 查询转换为多次布隆过滤操作.这种方式能够通过主键的二进制前缀快速判断目标范围是否存在,并 且可以降低LSM-tree中每层的布隆过滤器误判率,能够有效地减少查询时对磁盘的访问次数.
为了提升LSM-tree的范围查询性能,与使用过滤器方法不同的是,REMIX[37]对全局数据建立有 序的索引.在执行范围查询操作时,REMIX主要有以下优化:①通过二分查找快速定位目标数据; ②查询数据时避免主键的比较;③跳过不在查询路径上的文件.通过这些优化,REMIX能够有效地提 升系统查询性能.
2.3总结
布隆过滤器能够有效地提升LSM-tree的查询性能,但是查询过程中产生的误判会带来额外的磁 盘读写开销.Monkey通过给不同层的布隆过滤器分配不同的内存资源,减小了布隆过滤器的误判率 总和.但是Monkey针对每一层的布隆过滤器分配的资源是固定的,无法根据工作负载自动调整布隆 过滤器的布局.而Elasticbf能够根据数据的冷热程度来动态调整布隆过滤器的内存资源分配,针对热 点数据较集中的情况,Elasticbf能够有效地提升查询性能,但是对于热点数据较分散的情况,Elasticbf 带来的性能提升并不明显.
Monkey和Elasticbf能够有效地提升LSM-tree的点查询性能,然而对于范围查询表现并不是十 分理想.SuRF能够支持点查询和范围查询,但是在插入新数据时需要重建整个数据结构,会带来较大 的性能开销.Rosetta使用多个布隆过滤器,支持范围查询的同时也降低了误判率,但是Rosetta不能 有效地支持长范围查询,并且多次过滤操作增加了查询开销.使用过滤器方法提升查询性能时,降低 误判率会带来较大的资源占用和性能开销.使用过滤器方法进行范围查询时,需要探查每层的数据, 并且由于LSM-tree的多层结构,数据可能存在多个版本,还需要对每层的查询结果进行合并,因此, 这些开销是无法避免的.REMIX通过对全局数据建立有序的索引,避免了过滤操作,能够有效地减少 探查和合并查询结果的开销.但是在插入新数据时,与SuRF类似,REMIX也需要重建其索引结构, 这同样会带来较大的性能开销.
3基于LSM-tree的缓存查询优化技术
3.1缓存及其管理策略
在計算机系统中,由于CPU、内存和磁盘之间存在着巨大的性能差异,当CPU处理数据时需要 从内存中加载数据,如果每次处理时都需要从内存中加载数据,那么将造成CPU资源的浪费,并会对 系统性能产生严重的影响.因此,在计算机系统中引入了数据缓存机制,通过将部分数据缓存到 CPU的cache中,能够有效地减少CPU从内存中加载数据的等待时间.同理,在数据库系统中,当查 询到来时需要从磁盘读取相关的数据,由于磁盘I/O速度较慢,这个过程会消耗较多的时间,影响数 据库的查询性能.而通过缓存将磁盘上的部分数据缓存到内存中,在内存中直接访问这些数据将会有 效地提升数据访问速度.
应该将哪些数据缓存到内存中并如何管理这些数据对数据库系统来说也是非常重要的.目前数 据库中常见的缓存管理策略有:最近最久未使用算法(Least Recently Used, LRU)[38]和最少使用算法 (Least Frequently Used, LFU)|39].
在实际的查询过程中,最近被访问过的数据,接下来被访问的可能性也很高.因此,将最近被访问 过的数据缓存到内存中能够有效地提升查询性能.最近最久未使用算法(LRU)就是基于这种思想设 计的一种缓存替换策略,其主要过程是:
(1)访问新数据时,将新数据插入到链表头部;
(2)当缓存中的数据被访问时,将数据移到链表头部位置;
(3)插入新数据时,如果缓存空间已占满,将清除链表尾部的数据.
最近最久未使用算法(LRU)只考虑最近被访问的数据最有可能在将来被继续访问,但是最近访 问的在将来不一定仍被继续访问.而一般情况下,被访问最频繁的数据在将来最可能被访问,这也是 最少使用算法(LFU)的基本思想.最少使用算法的主要策略是:
(1)访问新数据时,此时该数据被访问1次,将该数据插入链表尾部;
(2)链表中的数据被访问时,该数据访问次数加1,并对链表重新排序;
(3)插入新数据时,如果缓存空间已占满,清除链表尾部访问频率最低的数据.
3.2缓存优化技术
目前,在LSM-tree中为了减少查询过程中对磁盘数据的读取,大都使用了缓存技术.表缓存中缓 存了磁盘文件的索引信息,加快了对磁盘上表的查找速度.块缓存和键值对缓存通过在内存中缓存磁 盘上的部分数据,查询时可以直接从内存中读取这些数据,能够有效地提升数据库的查询性能.
虽然缓存优化技术有效地提升了 LSM-tree的查询性能,但是由于LSM-tree的多层结构以及不同 层间的合并操作,当内存表中的数据写入磁盘中或者磁盘中不同层间的文件产生合并操作时,会导致 内存中缓存的数据无法使用,出现缓存失效问题.如图4所示,由于L0层和L1层合并后产生了新的 数据块,原来缓存中的数据将会失效.当出现缓存失效时,只能去磁盘上查询和读取目标数据.这种情 况显然会降低LSM-tree的查询性能,甚至出现数据库性能的剧烈抖动.因此,尽可能减小缓存失效问 题的影响对于优化LSM-tree的查询性能非常重要.
目前,很多研究人员针对利用缓存优化技术提升LSM-tree的查询性能提出了不同的方案.这些方 案根据其技术特点可以分为3种类型:优化合并策略、利用机器学习方法预取数据和采用多种缓存 形式.
3.2.1优化合并策略
LSM-tree缓存失效问题主要是由内存中的数据刷到磁盘中和磁盘中不同层间的合并操作引起的, 因此,针对LSM-tree的合并策略进行优化来减小缓存失效是非常重要的一个研究方向.
文献[40]提出了使用专门的合并服务器来处理数据合并操作.数据存储服务器能够更充分地利用 资源处理当前的工作负载,并通过预热算法替换数据存储服务器缓存中的数据来减小缓存失效问题. 这种方法将合并后与缓存中数据块有重叠的数据加载到缓存中,在新合并的数据块中的数据仍会被 频繁访问的情况下,将会实现较好的查询性能.
SM-tree[41]是LSM-tree的一种变体,与LSM-tree不同的是,SM-tree磁盘上的每层数据不再是有 序排列的.SM-tree通过降低磁盘上数据合并的频率来减小缓存中的数据失效问题,但是这种方法存 在两个问题:一是由于每层数据不是有序排列的,降低了范围查询的性能;二是对于频繁更新的负载, 由于数据无序并且合并频率低,会存在大量重复的数据,占用大量的存储空间.
3.2.2机器学习预取数据
Leaper[42]利用机器学习方法预测未来可能被访问到的数据并将其预取到缓存中.Leaper主要由 学习器、收集器和预取器组成.当存储引擎开始运行后,Leaper中的收集器会不断地更新统计信息; 学习器根据工作负载的变化周期性地训练预测模型,并将训练结果输出给预取器;预取器根据学习器 和收集器生成的结果以及刷盘和合并操作等特征将未来可能继续访问的热数据预取到缓存中.实验 表明,Leaper能够有效地降低合并操作造成的缓存失效问题,并提高数据查询性能.
3.2.3多种缓存形式
LSbM-tree[43]通过在磁盘的每一层建立合并缓存区存储经常被访问的数据来避免合并时带来的缓 存失效问题.在具体实现中,LSbM-tree将磁盘上合并缓存区的数据直接映射到位于内存的缓存中,对 于频繁访问的数据可以直接在合并缓存区中查找,并且通过降低合并缓存区中数据的合并速率来降 低缓存中的数据失效问题.由于LSbM-tree的合并缓存中只存储了部分频繁访问的数据,因此,不能 有效地提升长范围查询性能,并且磁盘中的合并缓存会增加额外的存储空间开销.
AC-Key[44]使用了 key-value、key-pointer 和 block 这 3 种缓存形式.key-value 缓存键值数据对, key-pointer缓存主键值和指向数据的指针,block缓存文件中的块数据.AC-key通过key-value和key- pointer 缓存加速点查询, block 缓存加速范围查询, 并通过自适应算法根据工作负载调整不同缓存的 大小和比例,在给定内存大小的情况下,能够有效地提升缓存命中率,并提升LSM-tree的查询性能.
文献[45]提出了使用不同粒度的缓存提升LSM-tree查询性能的方法.在LSM-tree中,不同层的 数据合并频率是不同的,一般情况下,层数越低数据合并频率越低.为了降低缓存失效问题,粗粒度缓 存选择缓存低层中频繁访问的数据来加快查询速度;细粒度缓存通过缓存最近经常被访问的键值对, 并采用同步更新的方式降低缓存失效问题,能够减少查询时对磁盘的访问,以此提高查询速度.
3.3总结
目前,针对LSM-tree的缓存失效问题,工业界和学术界提出了很多优化方法.表1是其中一些现 有的优化方法以及对应方法存在的不足之处.
4结论
目前,随着数据规模的不断增加,对数据库写入的速度要求越来越高,面对这些场景和需求, LSM-tree以其优秀的写入性能得到越来越多的应用.但是,由于其特殊的分层结构和内部合并操作, 查询性能并不理想,因此,很多研究人员针对LSM-tree的查询提出了很多优化方案.
本文主要介绍了 LSM-tree的基础结构和LSM-tree相关的主要查询优化技术:索引和缓存优化技 术,调研总结了索引和缓存技术在LSM-tree查询中存在的不足及目前针对这些问题的相关研究工作.
针对LSM-tree的查询优化,未来的研究方向可以从以下几方面出发.
(1)提高缓存命中率.缓存能够有效提升查询性能,但是由于在LSM-tree中数据从内存写入磁盘 和磁盘中不同层间的数据合并操作,造成缓存失效问题,降低了缓存命中率.可以考虑利用机器学习 方法根据工作负载和LSM-tree内部的操作特点,预测未来可能访问的数据并將其预取到缓存中,从 而降低缓存失效问题.
(2)LSM-tree范围查询优化.目前,大多数查询优化方法主要是针对LSM-tree点查询进行优化, 对范围查询的优化较少,而LSM-tree由于多层结构,不同层间存在重复的数据,对范围查询更不友好. 过滤器方法优化范围查询无法避免对数据的探查与探查结果的合并开销,并且不适合长范围查询场 景,REMIX对数据建立全局索引能够避免这些开销,但是插入新数据时索引重构开销较大.因此,将 两者优势结合在一起是一个非常值得研究的方向.
(3)针对非主键查询优化.目前,针对非主键的查询场景越来越多,而LSM-tree查询优化方法大 都是针对主键类型的查询优化.对非主键的查询,特别是多个条件下的范围查询场景,如何进行优化 是一个重要的研究方向.
[参考文献]
[1]ARMSTRONG T G, PONNEKANTI V, BORTHAKUR D, et al. Linkbench: A database benchmark based on the facebook social graph [C]//Proceedings of the 2013 ACM SIGMOD International Conference on Management of Data. 2013: 1185-1196.
[2]ATIKOGLU B, XU Y, FRACHTENBERG E, et al. Workload analysis of a large-scale key-value store [C]//Proceedings of the 12th
ACM Sigmetrics/Performance Joint International Conference on Measurement and Modeling of Computer Systems. 2012: 53-64.
[3 ] CAO Z, DONG S, VEMURI S, et al. Characterizing, modeling, and benchmarking rocksDB key-value workloads at facebook [C] //18th USENIX Conference on File and Storage Technologies (FAST 20). 2020: 209-223.
[4 ] BU Y, BORKAR V, JIA J, et al. Pregelix: Big(ger) graph analytics on a dataflow engine [J]. Proceedings of the VLDB Endowment, 2015, 8(2): 161-172.
[5]DECANDIA G, HASTORUN D, JAMPANI M, et al. Dynamo: Amazon's highly available key-value store [J]. ACM SIGOPS Operating Systems Review, 2007, 41(6): 205-220.
[6]RAJU P, PONNAPALLI S, KAMINSKY E, et al. Mlsm: Making authenticated storage faster in ethereum [C]//10th USENIX Workshop on Hot Topics in Storage and File Systems (HotStorage 18). 2018.
[7]CAO Z, CHEN S, LI F, et al. LogKV: Exploiting key-value stores for event log processing [C/OL]// 6th Biennial Conference on Innovative Data Systems Research (CIDR1(3). 2013. http://cidrdb.org/cidr2013/Papers/CIDR13_Paper46.pdf.
[8 ] CHEN G J, WIENER J L, IYER S, et al. Realtime data processing at facebook [C]//Proceedings of the 2016 International Conference on Management of Data. 2016: 1087-1098.
[9 ] KONDYLAKIS H, DAYAN N, ZOUMPATIANOS K, et al. Coconut palm: Static and streaming data series exploration now in your palm [C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 1941-1944.
[10]KONDYLAKIS H, DAYAN N, ZOUMPATIANOS K, et al. Coconut: Sortable summarizations for scalable indexes over static and streaming data series [J]. The VLDB Journal, 2019, 28(6): 847-869.
[11]DGRAPH. Badger Key-value DB in Go[EB/OL]. [2021-08-23]. https://github.com/dgraphio/badger.
[12]KYROLA A, GUSSTRIN C. GraphChi-DB: Simple design for a scalable graph database system—on just a PC [EB/OL]. (2014-03-0(4) [202108-23]. https://arxiv.org/pdf/1403.0701.pdf.
[13]ALSUBAIEE S, CAREY M J, LI C. LSM-based storage and indexing: An old idea with timely benefits [C]//Second International ACM Workshop on Managing and Mining Enriched Geo-spatial Data. 2015: 1-6.
[14]SHETTY P J, SPILLANE R P, MALPANI R R, et al. Building workload-independent storage with VT-trees [C]//11th USENIX Conference on File and Storage Technologies (FAST 1(3). 2013: 17-30.
[15]JANNEN W, YUAN J, ZHAN Y, et al. BetrFS: A right-optimized write-optimized file system [C]//13th USENIX Conference on File and Storage Technologies (FAST 1(5). 2015: 301-315.
[16]VINCON T, HARDOCK S, RIEGGER C, et al. Noftl-kv: Tackling write-amplification on kv-stores with native storage management [C]//Extending Database Technology. 2018: 457-460.
[17]DAYAN N, BONNET P, IDREOS S. GeckoFTL: Scalable flash translation techniques for very large flash devices [C]//Proceedings of the 2016 International Conference on Management of Data. 2016: 327-342.
[18]COMER D. Ubiquitous B-tree [J]. ACM Computing Surveys (CSUR), 1979, 11(2): 121-137.
[19]ONEIL P, CHENG E, GAWLICK D, et al. The log-structured merge-tree (LSM-tree) [J]. Acta Informatica, 1996, 33(4): 351-385.
[20]CHANG F, DEAN J, GHEMAWAT S, et al. Bigtable: A distributed storage system for structured data [J]. ACM Transactions on Computer Systems, 2008, 26(2): 1-26.
[21]Google. Leveldb[EB/OL]. [2021-08-23]. https://leveldb.org/.
[22]Facebook. Rocksdb [EB/OL]. [2021-08-23]. https://rocksdb.org/.
[23]Apache. Cassandra [EB/OL]. [2021-08-23]. http://cassandra.apache.org/.
[24]HBase [EB/OL]. [2021-08-23]. https://hbase.apache.org/
[25]ALSUBAIEE S, BEHM A, BORKAR V, et al. Storage management in AsterixDB [J]. Proceedings of the VLDB Endowment, 2014, 7(10): 841-852.
[26]BEAVER D, KUMAR S, LI H C, et al. Finding a needle in haystack: Facebook's photo storage [J]. OSDI, 2010(10): 1-8.
[27]MATSUNOBU Y, DONG S, LEE H. MyRocks: LSM-tree database storage engine serving Facebook's social graph [J]. Proceedings of the VLDB Endowment, 2020, 13(1(2): 3217-3230.
[28]HUANG G, CHENG X, WANG J, et al. X-Engine: An optimized storage engine for large-scale E-commerce transaction processing [C]//Proceedings of the 2019 International Conference on Management of Data. 2019: 651-665.
[29]CAO W, LIU Z, WANG P, et al. PolarFS: An ultra-low latency and failure resilient distributed file system for shared storage cloud database [J]. Proceedings of the VLDB Endowment, 2018, 11(1(2): 1849-1862.
[30]BLOOM B H. Space/time trade-offs in hash coding with allowable errors [J]. Communications of the ACM, 1970, 13(7): 422-426.
[31]KIRSCH A, MITZENMACHER M. Less hashing, same performance: Building a better Bloom filter [J]. Random Structures & Algorithms, 2008, 33(2): 187-218.
[32]DAYAN N, ATHANASSOULIS M, IDREOS S. Optimal bloom filters and adaptive merging for LSM-trees [J]. ACM Transactions on Database Systems, 2018, 43(4): 1-48.
[33]DAYAN N, ATHANASSOULIS M, IDREOS S. Monkey: Optimal navigable key-value store[C]//Proceedings of the 2017 ACM International Conference on Management of Data. 2017: 79-94.
[34]LI Y, TIAN C, GUO F, et al. Elasticbf: Elastic bloom filter with hotness awareness for boosting read performance in large key-value stores [C]//2019 USENIX Annual Technical Conference (USENIX ATC'19). 2019: 739-752.
[35]ZHANG H, LIM H, LEIS V, et al. Surf: Practical range query filtering with fast succinct tries [C]//Proceedings of the 2018 International Conference on Management of Data. 2018: 323-336.
[36]LUO S, CHATTERJEE S, KETSETSIDIS R, et al. Rosetta: A robust space-time optimized range filter for key-value stores [C]//Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020: 2071-2086.
[37]ZHONG W, CHEN C, WU X, et al. {REMIX}: Efficient Range Query for LSM-trees [C]//19th USENIX Conference on File and Storage Technologies (FAST' 2(1). 2021: 51-64.
[38]O'NEIL E J, O'NEIL P E, WEIKUM G. The LRU-K page replacement algorithm for database disk buffering [J]. Acm Sigmod Record, 1993, 22(2): 297-306.
[39]TAILOR P, MORENA R D. A survey of database buffer cache management approaches [J] . International Journal of Advanced Research in Computer Science, 2017, 8(3): 409-414.
[40]AHMAD M Y, KEMME B. Compaction management in distributed key-value datastores [J]. Proceedings of the VLDB Endowment, 2015, 8(8): 850-861.
[41]JAGADISH H V, NARAYAN P P S, SESHADRI S, et al. Incremental organization for data recording and warehousing [J] . VLDB, 1997, 97: 16-25.
[42]YANG L, WU H, ZHANG T, et al. Leaper: A learned prefetcher for cache invalidation in LSM-tree based storage engines [J]. Proceedings of the VLDB Endowment, 2020, 13(1(2): 1976-1989.
[43]TENG D, GUO L, LEE R, et al. LSbM-tree: Re-enabling buffer caching in data management for mixed reads and writes [C]//2017 IEEE 37th International Conference on Distributed Computing Systems (ICDCS). 2017: 68-79.
[44]WU F, YANG M H, ZHANG B, et al. AC-Key: Adaptive caching for LSM-based key-value Stores [C]//2020 USENIX Annual Technical Conference (USENIX ATC' 20). 2020: 603-615.
[45]LI X, XU G, FAN H, et al. Improving read performance of LSM-tree based KV stores via dual grained caches [C]//2019 IEEE 21st International Conference on High Performance Computing and Communications, IEEE 17th International Conference on Smart City, IEEE 5th International Conference on Data Science and Systems (HPCC/SmartCity/DSS). 2019: 841-848.
(責任编辑:张晶)
