
面向领域知识图谱的实体关系联合抽取
2021-03-14 20:54付瑞李剑宇王笳辉岳昆胡矿
华东师范大学学报(自然科学版) 2021年5期
付瑞 李剑宇 王笳辉 岳昆 胡矿


摘要:文本数据中的实体和关系抽取是领域知识图谱构建和更新的来源.针对金融科技领域中文本数据 存在重叠关系、训练数据缺乏标注样本等问题,提出一种融合主动学习思想的实体关系联合抽取方法.首 先,基于主动学习,以增量的方式筛选出富有信息量的样本作为训练数据;其次,采用面向主实体的标注策 略将实体关系联合抽取问题转化为序列标注问题;最后,基于改进的BERT-BiGRU-CRF模型实现领域实 体与关系的联合抽取,为知识图谱构建提供支撑技术,有助于金融从业者根据领域知识进行分析、投资、 交易等操作,从而降低投资风险.针对金融领域文本数据进行实验测试,实验结果表明,本文所提出的方法 有效,验证了该方法后续可用于金融知识图谱的构建.
关键词:领域文本;领域知识图谱;实体关系联合抽取;主动学习;序列标注 中图分类号:TP391 文献标志码:A DOI: 10.3969/j.issn.1000-5641.2021.05.003
Joint extraction of entities and relations for domain knowledge graph
FU Rui, LI Jianyu, WANG Jiahui, YUE Kun, HU Kuang
(School of Information Science and Engineering, Yunnan University, Kunming 650500, China)
Abstract: Extraction of entities and relationships from text data is used to construct and update domain knowledge graphs. In this paper, we propose a method to jointly extract entities and relations by incorporating the concept of active learning; the proposed method addresses problems related to the overlap of vertical domain data and the lack of labeled samples in financial technology domain text data using the traditional approach. First, we select informative samples incrementally as training data sets. Next, we transform the exercise of joint extraction of entities and relations into a sequence labeling problem by labelling the main entities. Finally, we fulfill the joint extraction using the improved BERT-BiGRU-CRF model for construction of a knowledge graph, and thus facilitate financial analysis, investment, and transaction operations based on domain knowledge, thereby reducing investment risks. Experimental results with finance text data shows the effectiveness of our proposed method and verifies that the method can be successfully used to construct financial knowledge graphs.
Keywords: domain text;domain knowledge graph; joint extration of entities and relations; active learning; sequence labeling
0引 言
隨着海量数据处理和人工智能技术的快速发展,以数据密集型为主导的研究范式为推动各领域
收稿日期:2021-08-05
基金项目:国家自然科学基金(U180227(1);云南省重大科技专项(202002AD080002-1-B);云南省青年拔尖人才计划 (C619303(2);云南省教育厅科研基金(2020J000(4)
通信作者:岳昆,男,教授,博士生导师,研究方向为数据与知识工程.E-mail: kyue@ynu.edu.cn
数字化转型提供了新的研究思路.知识图谱(Knowledge Graph, KG)作为一种用图模型描述知识和建 模世界万物之间关联关系的方法,通过一系列形如〈头实体,关系,尾实体〉的三元组对知识进行结 构化表示[1],为跨领域知识融合提供了解决方案.近年来,在搜索引擎、推荐计算和智能问答[4]等 KG下游应用的驱动下,以及DBpedia[5]、YAGO[6]和Freebase[7]等跨领域知识库的诞生,研究人员对 从非结构化数据源特别是文本数据中挖掘高质量的领域知识产生了极大兴趣[8].例如,随着金融科技 进入智能时代,面对大规模、多来源、不规则的金融文本数据,通过构建金融领域KG能够高效利用 各个数据之间的联系,实现金融与信息科技深度融合,为预测市场趋势、支持政府监管市场、防范金 融风险提供智能化解决方案[9].
实际上,大量的文本数据是KG构建和领域知识更新的来源,如何有效地从文本数据中抽取实体 和关系,是KG构建、更新和推理的重要基础.例如,金融领域对数据依赖性较大,对数据分析的准确 性要求很高,股票的价格可以视作市场对金融新闻和事件的反映,通过有效分析相关金融新闻和事件 文本数据,并将其表征为结构化知识,能够直观有效地展示金融领域覆盖实体之间关联对股票价格的 影响,对用户做出明智的投资决策至关重要.从这个角度来说,只有高质量的金融知识图谱中的知识 有实际应用价值.因此,本文研究从领域文本数据识别命名实体和联合抽取实体关系的方法,为领域 KG的构建和增量更新提供技术支撑.
领域文本数据是对特定领域知识的描述和记录,具有以下特点.
(1)领域文本数据的标注样本极其缺乏,对数据的标注往往需要专家的指导和协助,导致标注语料 库的构建成本极高.因此,如何以尽可能少的标注样本量实现模型训练,是本文研究面临的挑战.
(2)领域文本数据中实体分布密度高且实体间存在重叠关系.数据实例围绕主实体展开具体描述, 如一个金融数据实例描述一家公司的创始人、股东、注册地址等信息,一个公司实体同时与创始人、 股东等实体存在关系.因此,如何有效地抽取领域文本数据中实体和实体间的重叠关系,是本文研究 面临的另一个挑战.
主动学习算法[10]旨在针对模型主动参与样本选择的情形,优先标注并训练那些相对有价值的样 本,从而达到以尽可能少的标注样本量达到模型预期性能的目标.为了从领域文本数据中选取待标注 样本,本文提出一种基于主动学习的待标注数据采样方法,用以筛选出富有信息量的样本,从而降低 标注成本.
为了有效地抽取实体和实体间的重叠关系,本文提出一种考虑主实体的序列标注策略,将实体关 系联合抽取问题转化为序列标注问题.基于双向长短期记忆网络(Bidirectional Long Short-Term Memory, BiLSTM)[11]可同时获取上下文信息并存储记忆,从而被广泛地应用于基于序列标注的实体 关系联合抽取任务;但是基于BiLSTM改进的双向门控循环单元(Bidirectional Gated Recurrent Unit, BiGRU)[12]不仅具备长时序依赖能力和更快的运行效率,而且简化了 BiLSTM复杂的结构.为缓 解BiGRU模型在訓练过程中出现的过拟合问题以及梯度爆炸问题,本文通过改进BiGRU提出 BiGRU*.首先提出TaLU激活函数替换传统GRU的双曲正切(tanh)激活函数,从而解决因tanh函 数的软饱和性而导致的梯度消失问题;其次,结合层标准化(Layer Normalization, LN)技术,使模型 在没有发生严重梯度爆炸的情况下提高网络性能,从而获得改进的GRU*,最后使用BERT-BiGRU*- CRF序列模型来对金融领域文本数据集进行实体关系联合抽取.
综上所述,本文的工作主要包括以下几个方面.
(1)针对垂直领域数据缺乏的问题,融合主动学习思想,提出一种基于主动学习的待标注数据采样 方法.通过评估样本的价值与样本的相似性来选择标注样本,从未标注数据池中增量地采样出富有信 息的样本.
(2)通过将实体识别和关系抽取两个子任务联合起来,并将其建模为序列标注,提出一种基于 BERT-BiGRU*-CRF的实体关系联合抽取模型,用于对垂直领域文本的实体和关系同时进行抽取.
(3)基于金融领域和少数民族领域文本数据对本文提出的方法进行实验测试和性能分析,实验结 果表明,本文提出的基于BERT-BiGRU*-CRF的实体关系联合抽取方法,效果均优于其他传统的序 列标注模型.
1相关工作
传统的实体关系抽取一般采用流水线方法,该方法将命名实体识别和关系抽取分成两个独立的 子任务,在实体识别已经完成的基础上直接进行实体之间的关系抽取.例如,文献[13]和文献[14]首 先识别文本中的实体,然后抽取出文本中实体之间的关系.尽管流水线方法更加灵活且易于建模,但 实体识别阶段产生的错误将传播到关系抽取阶段,影响关系抽取的性能,将实体识别与关系抽取分开 执行,忽略两个子任务之间的联系,若识别到的实体间不存在语义关系,无法剔除冗余实体对.
相比传统的流水线方法,实体关系联合抽取方法采用一个联合模型同时识别出实体和关系类型. 根据建模对象不同,实体关系联合抽取方法分为参数共享和序列标注两类.参数共享方法是分别对实 体和关系进行建模,例如,Miwa等[15]采用参数共享的方式来对实体和关系进行联合提取,将BiLSTM 与树状LSTM用于文本的建模任务,BiLSTM完成对实体的提取,树状LSTM实现对于关系的分类, 通过两个模型的互相堆叠来实现参数的共享.序列标注方法将实体与关系联合抽取任务转换成序列 标注问题,基于实体关系的联合标注策略进行建模,直接得到实体-关系三元组.例如,Zheng等[16]首 次提出一种特殊的标注方案,将实体关系联合抽取问题转化为序列标注问题,并在通用领域的知识抽 取中取得了较好的效果,但无法解决重叠关系问题.为了能更好地解决可能存在的实体关系三元组重 叠问题,Zeng等[17]提出了一种基于复制机制的端到端神经网络模型,采用了一种编码器解码器架构 的实体关系抽取模型,首先完成对关系的提取,然后通过复制机制,依次复制主实体和客实体,解决了 实体关系重叠的问题,但该模型未考虑实体对之间存在多种关系的问题.
主动学习是一种用于机器学习的训练数据筛选方法,相较于人工操作,它只需花费较少的时间即 可自动找到富有信息量的样本来构建更好的数据集,进而以较低的标注代价实现模型较高的性能.研 究者们依据不同的样本选择标准开发出一系列主动学习的方法,Houlsby等[18]提出了一种贝叶斯不一 致主动学习算法,其中采样函数通过训练样本关于模型参数的互信息来进行不确定性度量.Tang等[19] 提出一种自定步长的主动学习方法,该方法一方面考虑了样本的信息量和代表性,选取的样本对模型 的改进具有较高的潜在价值;另一方面,利用样本的易用性,使模型能够充分利用样本潜在价值.近年 来,随着深度学习模型的发展,主动学习也应用于序列标注任务.Tran等[20]针对Twitter数据进行命 名实体识别问题,提出了一种将自学习和主动学习相结合的方法,降低了标注成本.Shen等[21]通过将 主动学习与一种基于深度学习的轻量级命名实体识别模型相结合,减少25%的训练数据量.虽然上述 方法在解决样本标注问题上取得了很大进展,但这些方法往往只关注低置信度的不确定样本,未能综 合考虑样本的价值与代表性.
2实体关系联合抽取
2.1相关定义
定义1领域文本数据集D {d1, d2, · · · , dn} (n > 1)是蕴含实体集五和关系集^的句子集合,其 中,di (1 ? i ? n)表示一个蕴含实体和关系集合的句子,E表示乃中描述领域知识的实体集合,^表 示丑中实体间的关系集合.
例 1 针对句子“Paul Allen, who come from Seattle, founded Microsoft in 1975 in Albuquerque.”,可得到实体集合{_PaMMZZen, Microso/尤,与实体间的关系集合{/ownders, _pZace_/OMnded}.
定义2领域KG G=(尽fi)是描述领域实体之间关系的有向图,其中,五表示领域KG中实体 对应的节点集合,表示实体关系对应边的集合,G中任意两个节点构成的有向边表示为一个三元组 (h, r,t) (h,t G E,r G R).
给定领域文本数据集乃,领域KG G = (E,fi)的构建可通过对乃进行实体关系抽取来获取对应E 中实体和fi中关系的三元组集合,再将三元组中的实体和关系映射为节点和边,进而构建领域KG.
2.2标注策略
本节讨论面向主实体的序列标注策略.首先将文本中主实体的关系标签固定为“MAIN”,然后将 与主实体存在关系的实体的关系标签设置为两个实体间的关系类型,最后通过标签匹配直接获取三 元组,从而实现对重叠关系的抽取.
面向主实体的序列标注策略的标签由实体边界、关系类别和实体位置3个部分组成,具体描述 如下.
(1)实体边界对于实体边界标签,本文采用“BIFSO”标注方式来表示单字在实体中的位置信息, B表示此元素在实体的头部,I表示此元素在实体的中部,F表示此元素在实体的尾部,S表示此元素 为单个实体,O则表示该元素不属于任何实体.
(2)关系类别关系类别标签由该垂直领域预先定义的关系类别来确定,对于一个围绕主实体展开 描述的句子,定义一种新的关系标签类型“MAIN”,將主实体关系类别标签表示为固定关系类别 “MAIN”.
(3)实体位置实体位置由数字“1”和“2”来标识,“1”表示该实体为三元组中的头实体,“2”表示该 实体为三元组中的尾实体.
例2 例1中的句子围绕主实体“Microsoft”展开,因此将“Microsoft”关系类别标签标注为固定 标签“MAIN”,句子包含(Microsoft, founders, Paul Allen)和(Microsoft, place_founded, Albuquerque) 2个三元组,其中“founders”和“place_founded”为预先定义的金融领域关系类别.根据上述标注策略, 句子序列中每个字都被赋予相应的标签,非实体用O来标注,如图1所示.
为了准确且高效地获取标注序列中的实体关系三元组,采取如下的实体关系三元组匹配规则.首 先根据实体边界获得实体,并根据最邻近原则确定实体关系.当实体关系类别为非“MAIN”时,分别 向前向后查找与之距离最近、关系类别与之相同且实体位置不同的实体来组成实体关系三元组;当实 体关系类别为“MAIN”时,则查找前后两个方向上实体位置不同的能与之匹配的实体来组成实体关系 三元组.通过上述步骤,实体关系联合抽取问题能够被转化为序列标注问题.
2.3改进的GRU*
由于GRU神经网络使用的双曲正切激活函数会导致网络在训练过程中出现梯度消失,因此,本
文设计一种新的激活函数TaLU来替换GRU候选状态的双曲正切激活函数.具体而言,针对神经元x , 由于ReLU函数在x处于正区间时不会出现神经元饱和问题,而t双曲正切函数在x反向传播过程中 不会出现由于梯度为0而导致权重不更新的问题.因此,TaLU函数在x > 0时,采用ReLU函数解决 由于双曲正切函数的软饱和性而导致的梯度消失问题;在x < 0时,采用tanh函数解决ReLU函数因 不更新权重而导致的神经元死亡问题.TaLU激活函数见式(1).
在模型训练中,由于缺乏训练数据会出现模型过拟合问题.为此,对GRU的输入序列做层标准化 处理,即针对输入激活函数前的每个小批量块(mini-batch),将非线性变换前的激活值重新规范化,在 改善TaLU适应性的同时起到缓解梯度爆炸、加速训练、正则化作用.
最后,为提升模型性能,本文将GRU神经元的tanh函数替换为TaLU激活函数,并对GRU神经 元的输入序列进行LN处理,改进的GRU神经元GRU*内部结构如图2所示.
2.4基于BERT-BiGRU*-CRF的实体关系联合抽取模型
完成对领域文本数据的实体关系标注后,将数据作为BERT-BiGRU*-CRF实体关系联合抽取模 型的输入进行训练,进而对每个句子的标签序列进行预测.针对领域文本数据具有存在关系的实体对 之间的距离较远的特点,采用BERT[22]模型将输入的句子序列转换为词向量表示,所获得的词向量不 仅隐含上下文词级特征,还能有效捕捉句子级别特征.为更好地捕捉句子较长距离的双向语义依赖, 扩展GRU*模型,使用BiGRU*模型来充分捕获上下文信息.针对BiGRU*因未考虑标签之间的关联 而导致输出非法标签的问题,基于条件随机场(Conditional Random Field,CRF)为预测标签添加约 束条件,进而获得最佳标签序列.
模型整体架构如图3所示,包括BERT表示层、BiGRU*编码层和CRF解码层.首先基于BERT 表示层将输入文本映射为句子序列的词向量表示.为了构建BERT表示层的输入,将数据中每个句子 表示为长度为^的序列,即d = (w1, w2, · · · , wl),然后将d中的每个单词叫wi (1 ? i ? l)使用BERT表示 层映射成维数为m的词向量,最终转换成如下词向量表示序列:
V = (v1, v2, · · · , vl), vi ∈ Rm (1 ? i ? l) (2)
接下来,将BERT表示层的输出F作为BiGRU*编码层的输入,针对每次新输入到BiGRU*编码 层的词向量序列V,通过正向GRU*和反向GRU*的编码得到隐藏层状态为c,将隐藏层状态向量c 经过一个全连接层夂维度映射为序列总标签数目k,作为CRF解码层的输入,描述如下:
Cin = L (c) G Rlxk. ⑶
最后采用CRF模型来捕获前后文标签之间的依赖关系,通过标签转移概率和约束条件得到文本 的标签序列.
2.5基于主动学习的待标注数据采样
在主动学习中,如何选择富有信息量的样本对模型性能的提升至关重要,主动学习的过程关键在 于建立一个判断待标注样本“信息量”的标准.因此,为了以较低的标注成本保证实体关系联合抽取模 型的性能,结合领域文本数据特点,提出一种基于主动学习的待标注数据采样方法,通过综合评估样 本的价值与样本间的相似性来选择具有代表性的待标注样本,样本间的相似性评估能够辅助去除冗 余样本,以更少的标注样本获得最优的关系抽取模型.
由于实体关系联合抽取任务最终可归结为关系分类问题,因此,提出基于样本的分类概率来评估 样本的价值.本文采用CNN来对样本进行分类,通过设置不同大小的卷积核能有效提取样本的局部 关键信息.本文采用“一维卷积层一最大池化层一全连接层一分类层”的结构模式,添加dropout层, 防止模型训练过程中出现的过拟合、过度参数化等现象.
首先预定义g个样本所属的领域关系类别,将领域文本数据集乃中的每一个样本A经过 BERT特征编码层获取特征向量Ft接下来,将特征向量作为CNN的输入提取特征,获得样本 分配到每个类别的概率.最后,将选择样本所属类别概率值最大的两个值P/和P,2之间的差值作为选 择样本的价值指标,计算方法见式(4).若和之间的差值越小,越无法确定待标注样本%所属的 类别,表明对%的分类很困难,即样本的价值越高.本文所提出样本的价值计算公式如下:
针对因只考虑样本的价值而导致的冗余样本问题,本文提出通过衡量样本的相似性来去除冗余 样本.事实上,样本通过BERT模型生成的特征向量包含丰富的领域语义信息,为此,本文提出通过 计算特征向量之间的余弦相似度来获取样本间的相似性,样本表和dj之间的相似性由式(5)计算:
主动学习是一个不断循环学习的过程,在训练过程中,为选择领域文本数据集乃中的待标注样本, 首先,通过式(4)选取D中价值最高的样本集合;然后通过式(5)评估集合中样本间的相似性 并去除冗余样本,从中选择有代表性的样本集合并由专家进行标注.训练过程中,新标注的样 本集合被不断添加到训练集Aram中,使用Aram对实体关系联合抽取模型重新进行训练,不断更新模型参数,进而提高模型性能.
2.6领域KG的构建
通过以上的实体关系联合抽取模型和主动学习方法,可从领域文本乃中得到构建领域KG G的 三元组集合T = {?h, r, t? |h, t ∈ E, r ∈ R} .首先,融合主动学习思想,选择并标注D中价值较高和具有
代表性的样本认,将认添加到训练集中.然后利用对BERT-BiGRU*-CRF实体关系联 合抽取模型进行迭代训练,并使用训练好的BERT-BiGRU*-CRF模型抽取D中的三元组集T =
{?h, r, t? |h, t ∈ E, r ∈ R},从而构建领域KG.上述思想见算法1.
算法1领域KG构建
输入:领域文本数据集D ,训练模型的迭代次数凡pOch 输出:领域KG
变量:实体关系联合抽取模型的训练集从ram
1:计算D中样本的价值和相似性,并标注价值较高和具有代表性的样本
2: Strain 气~ Ds
3: b ^ 0
4: While b < #epoch do //訓练 BERT-BiGRU*-CRF 模型
5: For each Strain in Dtrain do
6: ^ ^ BERT (dtrain) //将句子序列转化为词向量表示
7: —BiGRU*(y) //学习句子上文语义特征
8: CRF(Qn) //获取句子的标签序列
9: End for
10: bh b+1
11: End while
12:使用训练好的BERT-BiGRU*-CRF模型抽取数据集D中的三元组集T = {〈^r,0lM G E,r G fl}
13: Return G = (E, fl)
若领域文本数据集D中包含n个样本,则步骤5—9的时间复杂度为O(n).若训练模型的迭代次 数为 Nepoch 次,即While循环执行Nepoch 次,则算法1的时间复杂度为O (n . Wepoch).
3实验与结果分析
3.1实验设置
3.1.1数据集
为验证本文所提出的模型在垂直领域上实体关系联合抽取的有效性,分别采用英文的金融领域 数据集和中文的少数民族领域数据集作为实验数据集.《纽约时报》(The New York Times, NYT)数据 集包含150篇来自《纽约时报》的商业文章,由Riedel等[23]通过将Freebase知识库中的关系与《纽约时报》语料库对齐而生成.按照其中实体与关系的类别,筛选出其中2043条与金融领域密切相关的语句 作为本文使用的金融领域数据集,用以检验本文提出的模型在金融领域实体关系抽取的表现.同时, 从近十年人民网发布的少数民族新闻数据和百度百科、维基百科(中文)中筛选出1864条相关数据, 并使用本文的标注策略进行标注,作为少数民族领域数据集并验证本文方法在该领域的表现.对上述 两个数据集按照7 : 2 : 1的比例随机划分训练集、测试集和验证集.两个数据集的具体信息如表1所示.
3.1.2对比模型
BERT-BiLSTM-CRF+RBert首先采用BERT模型生成词向量,然后使用BiLSTM-CRF进行实 体识别,最后使用BERT作为编码器并连接全连接神经网络进行关系分类.
BiLSTM-CRF首先使用Word2vec[24]语言模型生成词向量,然后使用BiLSTM进行双向编码来预 测标签序列,最后利用CRF对BiLSTM的输出进行解码以完成关系分类.
BiGRU-CRF首先使用Word2vec语言模型生成词向量,然后用BiGRU循环编码以获取输入序 列的特征,最后通过CRF输出概率最大标签序列.
BERT-BiLSTM-CRF将BiLSTM-CRF序列标注模型的Word2vec词向量编码模型替换为BERT 预训练语言模型.
BERT-BiGRU-CRF将BiGRU-CRF序列标注模型的Word2vec词向量编码模型替换为BERT 预训练语言模型.
3.1.3评价指标
在评价领域实体关系联合抽取结果时,若实体边界被模型标记正确,则认为实体识别结果正确; 若实体边界及所属关系类别均标记正确,即三元组抽取正确,则判定关系抽取结果正确.所有实验结 果为3次测试结果取平均值以消除随机影响.通过采用实体关系联合抽取任务中通用的评价指标,即 通过准确率((Precision, P)、召回率(Recall,R)均以及F1值(F1
-score)这3项指标来评价模型的性能,并 将巧值作为评价模型性能的综合性指标.P = Np/NF R = Np/NA F1 = (2 × P × R)/(P + R),其中Np为抽取的正确三元组数量,为抽取的三元组数量,Wa为测试集中标记的三元组数量.
3.1.4实验环境
CPU 为 Intel(R) Core(TM) i7-10700K @3.80 GHz, GPU 为 NVIDIA Titan V,内存为 128 GB,编 码语言为 Python3.7,采用 Tensorflow2.1.0 框架.
3.1.5实验参数
在模型训练过程中,经过多次实验微调,设置的主要超参数值如表2所示.
3.2实验结果与分析
3.2.1金融领域实体关系联合抽取的有效性
为了验证本文提出的BERT-BiGRU*-CRF模型在金融领域数据集上的有效性,按照面向主实体 的标注策略来标注数据集,并进行不同模型的对比实验,测试命名实体识别、关系抽取两个任务的准 确率、召回率以及巧值,具体结果如表3所示.
可以看出,本文提出的BERT-BiGRU*-CRF模型在实体识别和关系抽取任务上都取得最高的 巧值,说明该模型能有效地抽取金融领域的实体和关系.相较于BERT-BiGRU-CRF模型,巧值在命 名实体识别任务和关系抽在取任务上分别提升了 1.32%和0.66%,综合性能BiGRU*-CRF模型优于 BiGRU-CRF模型,验证了 BiGRU*模型的有效性.同时,基于Word2vec编码方式的BiGRU*-CRF模 型在命名实体识别和关系抽取任务上的综合巧值分别为69.28%和43.07%,優于BiGRU-CRF模型 所对应的巧值,也验证了 BiGRU*-CRF模型的有效性.
相较于基于BERT的流水线方法在命名实体识别和关系抽取的巧值(分别为71.46%和40.75%), 实体关系联合抽取模型在关系抽取任务上模型性能有较大提升,其关系抽取结果的巧值增加了 7.93%,说明实体关系联合抽取方法能有效利用命名实体识别和关系抽取任务间的语义联系,能进一 步高效抽取重叠关系.以上实验结果表明,与传统的词向量模型相比,BERT预训练语言模型能更好 地提取语义特征,具有更好的抽取效果.
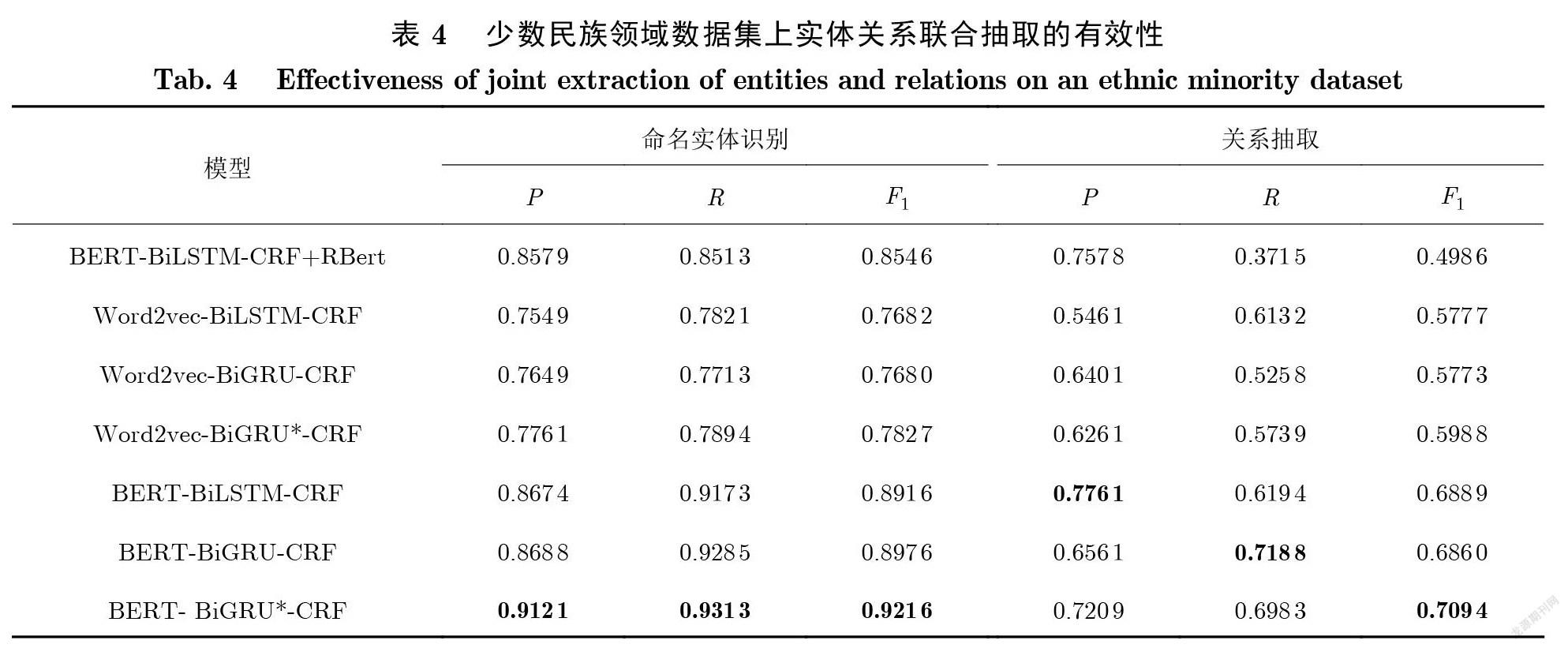
3.2.2少数民族领域实体关系联合抽取的有效性
为了验证本文提出的BERT-BiGRU*-CRF模型在少数民族领域数据集上的有效性,按照本文的 面向主实体的标注策略进行数据集,并进行不同模型的对比实验,测试命名实体识别、关系抽取两个 任务的准确率、召回率以及巧值,结果如表4所示.
可以看出,本文提出的BERT-BiGRU*-CRF模型在实体识别和关系抽取任务上同样取得最高的 巧值,表明所提出的模型同样适用于少数民族领域.相较于BERT-BiGRU-CRF模型,巧值在命名实 体识别任务和关系抽在取任务上分别提升了 2.4%和2.34%,表明BiGRU*-CRF模型的综合性能优 于BiGRU-CRF模型,说明改进的GRU神经元能提升实体关系联合抽取任务的效果.同时,基于 Word2vec编码方式的BiGRU*-CRF模型在命名实体识别和关系抽取任务上的巧值,高于BiGRU- CRF模型对应任务的巧值,也验证了 BiGRU*-CRF模型的有效性.
虽然流水线方法的准确率较高,但召回率偏低,导致朽值只有49.86%,通过对预测结果的分析发 现,流水线方法很难预测重叠关系,而少数民族领域数据集具有实体分布密集、重叠关系多的特点,是 导致流水线模型召回率偏低的主要原因.而BERT- BiGRU*-CRF模型能够达到69.83%的召回率,远 优于基于BERT的流水线方法.基于BERT编码方式的BiGRU*-CRF模型较基于Word2vec編码的 模型巧值在命名实体识别任务上提升了 13.89%,关系抽取任务上提升了 11.06%,表明加入BERT预 训练语言模型能够显著提升实体关系抽取效果.
结合表3和表4, BERT-BiGRU*-CRF模型在金融领域数据集和少数民族领域数据集上都分别取 得了最高的巧值,说明BERT-BiGRU*-CRF模型针对领域文本的实体关系联合抽取任务的优越性.
3.2.3重叠关系抽取的有效性
为了测试本文提出的BERT-BiGRU*-CRF模型能否有效抽取领域文本中的重叠关系,分别在金 融领域数据集和少数民族领域数据集上进行实验,对比不同模型对于重叠关系抽取的准确率、召回率 以及巧值,结果如表5所示.
可以看出,在两个领域数据集上,本文提出的BERT-BiGRU*-CRF模型对于重叠关系的抽取都 取得了最高的巧值,而流水线方法对于重叠关系抽取的准确率和召回率远低于实体关系联合抽取模 型,表明流水线方法很难预测重叠关系.基于BERT编码方式的BiGRU*-CRF模型较基于Word2vec 编码的模型,其巧值在金融领域数据集上提升了 5.66%,少数民族领域数据集上提升了 8.46%,表明 加入BERT预训练语言模型能够根据单词的上下文信息来获得动态的词向量,使用自注意力机制获 得双向的语义特征,进而大幅提升了重叠关系抽取的有效性.
3.2.4基于主动学习的待标注数据采样方法性能评估
为验证本文所提基于主动学习的待标注数据采样方法的有效性,针对金融领域数据集和少数民 族领域数据集,分别以完整的标签训练集和通过待标注数据采样筛选获得的训练集,评估实体关系联 合抽取模型的关系抽取性能,结果如表6所示.可以看出,随着标注样本的增加,模型整体性能不断提 升.在金融领域数据集上,当获得全部标注数据的60%,并对模型重新进行训练时,模型性能与使用完 整标签训练集训练后的模型性能非常接近;在少数民族领域数据集上,当获得全部标注数据的50%, 并对模型重新进行训练时,模型性能与使用完整标签训练集训练后的模型性能非常接近.实验结果证 明了本文所提基于主动学习的待标注数据采样方法的有效性.
3.2.5参数影响
统一设置batch_size为32, GRU单元数量为256,测试dropout变化对综合评价指标巧值的影 响,如表7所示.分别将金融领域数据集和少数民族领域数据集上的dropout值设置为0.4和0.5, batch_size统一设置为32,测试GRU单元数量变化对综合评价指标巧值的影响,如表8所示.
在BERT-BiGRU*-CRF模型中,增加模型GRU单元数量,会在一定程度上改善模型性能,但随 着GRU单元数量不断增加,模型会出现过拟合问题以及提高模型训练成本的问题.通过加入 dropout可以减弱深层神经网络的过拟合效应,但dropout越大,舍弃的信息越多,模型性能也会慢慢 降低.因此,选定合适的GRU单元数量以及dropout值可有效提升BERT-BiGRU*-CRF模型性能以 及缓解由于训练样本过少带来的过拟合问题.从表7和表8可知,在金融领域数据集和少数民族领域 数据集上,关系抽取任务的dropout分别为0.5和0.4时,巧值达到最高;同时GRU单元数量为256 时,BERT-BiGRU*-CRF模型实体关系联合抽取的巧值达到最高,此时整个模型达到最优.
综上,本文提出的BERT-BiGRU*-CRF模型针对不同垂直领域数据集,在实体关系联合抽取任 务上巧值相较于其他方法均达到最高,说明了本文模型的综合性能优越.在不同领域的关系抽取任 务上,相较其他同类方法巧值均能达到1%?3%的提升,模型性能稳定,说明了 GRU改进策略的优异性.不同编码方式下的实验结果,也验证了 BERT编码方法的合理性.
4总结与展望
为获取构建领域知识图谱的实体关系三元组集,本文以金融科技领域为代表,提出一种融合主动 学习的实体关系联合抽取模型,采用一种面向主实体的标注策略,将实体关系联合抽取问题转化为序 列标注问题,并且基于BERT-BiGRU*-CRF模型实现了对于领域文本的实体关系抽取任务.实验结 果证明,本文所提出的模型能够有效地抽取领域文本数据中实体和实体间的重叠关系,但是,本文的 模型主要适用于抽取实体间存在的一对多重叠关系,而对于实体间多对多重叠关系的抽取效果不够 理想.因此,未来工作考虑通过改进面向主实体的标注策略,从而进一步提高对于实体间多对多重叠 关系抽取的准确率.同时,下一步工作考虑爬取并处理实际的金融文本数据,并采用本文所提出的实 体关系联合抽取模型来构建金融领域知识图谱.
[参考文献]
[1]刘峤,李杨,段宏,等.知识图谱构建技术综述[J].计算机研宄与发展,2016, 53(3): 582-600.
[2]LI J, WANG Z, WANG Y, et al. Research on distributed search technology of multiple data sources intelligent information based on knowledge graph [J]. Journal of Signal Processing Systems, 2021, 93(2): 239-248.
[3]铙子昀,张毅,刘俊涛,等.应用知识图谱的推荐方法与系统[J/OL].自动化学报,2020. (2020-07-09)[2021-08-05]. https://doi.org/ 10.16383/j.aas.c200128.
[4] LU X, PRAMANIK S, ROY R., et al. Answering complex questions by joining multi-document evidence with quasi knowledge graphs [C]//Proceedings of the 42nd International ACM SIGIR Conference. NewYork: ACM, 2019: 105-114.
[5]LEHMANN J, ISELE R., JAKOB M, et al. DBpedia - A large-scale, multilingual knowledge base extracted from Wikipedia [J]. Semantic Web, 2015, 6(2): 167-195.
[6] MAHDISOLTANI F, BIEGA J, SUCHANEK F. YAGO3: A knowledge base from multilingual Wikipedias [C/OL]//Proceedings of the 7th Biennial Conference on Innovative Data Systems Research. 2015. [2021-08-05]. https://suchanek.name/work/publications/ cidr2015.pdf.
[7] BOLLACKER K, COOK R, TUFTS P. Freebase: A shared database of structured general human knowledge [C] //Proceedings of the 22nd AAAI Conference on Artificial Intelligence. California: AAAI, 2007: 1962-1963.
[8] ELHAMMADI S, LAKSHMANAN L, NG R, et al. A high precision pipeline for financial knowledge graph construction [C]//Proceedings of the 28th International Conference on Computational Linguistics. Berlin: Springer, 2020: 967-977.
[9] YANG Y, WEI Z, CHEN Q, et al. Using external knowledge for financial event prediction based on graph neural networks [C]// Proceedings of the 28th ACM International Conference on Information and Knowledge Management. Beijing: ACM, 2019: 2161-2164.
[10]龍军,殷建平,祝恩,等.主动学习研究综述[J].计算机研究与发展,2008(S(1): 300-304.
[11]HOCHREITER S, SCHMIDHUBER J. Long short-term memory [J]. Neural Computation, 1997, 9(8): 1735-1780.
[12]CHO K, MERRIENBOER B, GULCEHRE C, et al. Learning phrase representations using RNN encoder-decoder for statistical machine translation [J]. Computer Science, 2014: 1724-1734.
[13]ZENG D, LIU K, LAI S, et al. Relation classification via convolutional deep neural network [C] //Proceedings of the 25th International Conference on Computational Linguistics. Pennsylvania: ACL, 2014: 2335-2344.
[14]XU Y, MOU L, GE L, et al. Classifying relations via long short term memory networks along shortest dependency paths [C]//Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing. Pennsylvania: ACL, 2015: 1785-1794.
[15]MIWA M, BANSAL M. End-to-end relation extraction using LSTMs on sequences and tree structures [C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. Pennsylvania: ACL, 2016: 1105-1116.
[16]ZHENG S, WANG F, BAO H, et al. Joint extraction of entities and relations based on a novel tagging scheme [C] //Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics. Pennsylvania: ACL, 2017: 1227-1236.
[17]ZENG X, ZENG D, HE S, et al. Extracting relational facts by an end-to-end neural model with copy mechanism [C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. Pennsylvania: ACL, 2018: 506-514.
[18]HOULSBY N, HUSZaR F, GHAHRAMANI Z, et al. Bayesian active learning for classification and preference learning [EB/OL]. (2011-12-2(4) [2021-08-05]. https://arxiv.org/pdf/1112.5745.pdf.
[19]TANG P, HUANG S. Self-paced active learning: Query the right thing at the right time [C] //Proceedings of the 33rd AAAI Conference on Artificial Intelligence. California: AAAI, 2019: 5117-5124.
[20]TRAN V, NGUYEN N, FUJITA H, et al. A combination of active learning and self-learning for named entity recognition on Twitter using conditional random fields [J]. Knowledge-Based Systems, 2017, 132: 179-187.
[21]SHEN Y, YUN H, LIPTON Z, et al. Deep active learning for named entity recognition [EB/OL]. (2018-02-0(4) [2021-09-08]. https://arxiv.org/pdf/1707.05928.pdf.
[22]JACOB D, CHANG M, LEE K, et al. BERT: Pretraining of deep bidirectional transformers for language understanding [C] //
Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics. 2019: 4171-4186.
[23]RIEDEL S, YAO L, MCCALLUM A K. Modeling relations and their mentions without labeled text [C]//Proceedings of the 2010
European Conference on Machine Learning and Knowledge Discovery in Databases. Berlin: Springer, 2010: 148-163.
[24]郁可人,傅云斌,董啟文.基于神经网络语言模型的分布式词向量研究进展[J].华东师范大学学报(自然科学版),2017(5): 52-65.
(责任编辑:张晶)
猜你喜欢
军事文摘(2022年17期)2022-09-24
智能计算机与应用(2022年6期)2022-06-23
少年文艺·我爱写作文(2021年2期)2021-01-11
计算机世界(2020年50期)2020-01-15
青年生活(2019年23期)2019-09-10
21世纪商业评论(2018年3期)2018-03-02
创业邦(2017年12期)2017-12-29
中学生数理化·高一版(2017年2期)2017-04-25
数学学习与研究(2017年3期)2017-03-09
计算技术与自动化(2014年1期)2014-12-12
