
基于ES-Redis的航班延误可视化系统
2021-02-14 03:14屈景怡陈旭阳张雄威
中国民航大学学报 2021年6期
屈景怡,陈旭阳,鞠 澎,刘 芳,张雄威
(1.中国民航大学天津市智能信号与图像处理重点实验室,天津 300300;2.中国民用航空华北地区空中交通管理局天津空管分局,北京 100621)
2019年民航业发展统计公报指出,本年度全行业完成旅客周转量11 705.30 亿人公里,比上年增长9.3%。国内航线完成旅客周转量8 520.22 亿人公里,比上年增长8.0%,国际航线完成旅客周转量3 185.08亿人公里,比上年增长12.8%。逐年增长的航班旅客运输量反映了民航业的蓬勃发展,同时航班数量的不断增长产生了海量的航班数据,这些数据的存储,处理要求时效性、准确性与可靠性,如何管理并利用好海量的航班数据已成为亟待解决的问题。通过利用航班数据辅以大数据技术,开发了一套面向空管部门的航班延误可视化系统。
空中交通管制(简称空管)部门存储结构化数据多采用Oracle、SQL Server 等关系型数据库,此类数据库技术最为成熟,拥有良好的事务性,能够很好地支持结构化数据存储,因此,使用具有代表性的关系型数据库MySQL 进行数据存储。由于航班数据量较大且具有扩展性,MySQL 数据库的数据读取速度随数据量扩增越来越慢,无法保障系统的实时性,因此,考虑使用大数据的相关技术减轻系统的运行压力。
Redis 数据库作为高效的非关系型数据库,是基于内存实现的,在数据处理性能方面,Redis 要优于绝大多数数据库,具有提升Web 系统的响应速度和人机交互体验的能力。文献[1-3]分别将Redis 用于高性能智能快递柜管理系统、农田物联网云存储系统与面向小文件的分布式存储系统,这些都验证了Redis 作为Web 系统数据缓存的有效性与可靠性。文献[4]使用Redis 集群方式对身份数据进行存储,减轻系统运行压力,但该方法只能存储结构简单的数据,对于结构复杂的大规模数据集并不适用。为此,近年来国内学者对高性能、支持结构复杂数据存储的数据库进行研究:文献[5]提出使用HBase 数据库存储结构复杂的航空大数据,并依托SolrCloud 搜索引擎实现了基于Web界面的航班实时追踪;文献[6]以MongoDB 集群为基础,以ES(elasticsearch)分布式搜索引擎对数据库系统进行检索加速,设计了一套分布式大数据存储方案,满足了实时性需求。但HBase、MongoDB 等数据库数据类型单一、对数据库事务支持有限,且与现有空管关系型数据存储模式兼容性较差,需要将数据从空管部门数据库导入其中。文献[7]通过给MySQL 数据库加装ES 搜索引擎的方式提升系统性能,在兼顾关系型数据库事务特性的同时,保证对原有MySQL 数据库存储模式的兼容性,文中还使用Redis 数据库对热点数据进行备份,进一步提升了系统性能,但并未使用Redis 缓存替换策略优化系统,未考虑到由于Redis 数据库完全基于内存实现而过多占用内存增加系统运行负担,不设置缓存上限与清理策略会导致缓存失效等问题。
综上,设计的航班延误可视化系统整合了MySQL数据库的事务性、优越的数据统计能力和ES 分布式搜索引擎与Redis 数据库的高效检索能力,提出了一种ES-Redis 数据处理模式,并在此基础上实现了一种基于ES-Redis 的缓存替换算法Hybrid,进一步提升了系统的可用性与实时性。此外,在前人研究基础上,对现有的航班延误预测算法进行封装,并使用Socket 技术实现航班延误预测功能的开发。
1 需求分析
航班延误可视化系统面向空管部门开发,安装在中国民用航空华北地区空中交通管理局(简称空管局)空管中心塔台、流量管理室及运管中心,如图1所示,该系统包括5 个部分:
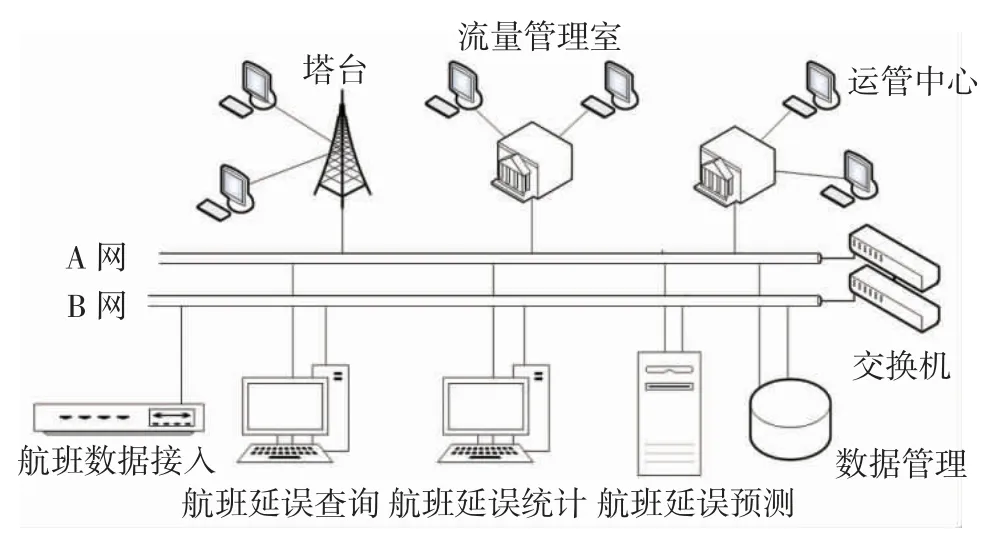
图1 航班延误可视化系统设计Fig.1 Design of flight delay visualization system
1)航班数据接入
系统数据的导入采用离线方式,由系统前端提供数据导入接口;
2)航班延误查询
为用户提供秒级响应的数据快速检索功能;
3)航班延误统计
为用户按日、月、年统计各机场的航班延误信息;
4)航班延误预测
利用历史航班数据对深度学习算法进行训练的基础上,使用Socket 套接字技术实现航班延误预测;
5)数据管理
数据管理模块负责接收空管局传递的航班数据,对其进行解析及校核后存储在数据库系统中,数据管理模块可以对系统数据提供管理功能:录入、更新、删除。
该系统是面向大数据开发的航班延误可视化系统,要求页面响应时间在1 s 以内。
2 总体设计
2.1 系统框架设计
系统采用B/S 架构实现,使用SpringBoot[8]整合的方式实现前、后端共同开发,极大简化了系统开发流程。系统前端使用超文本标记语言(HTML)、层叠样式表(CSS)、JavaScript 语言封装库(JQuery)整合可视化组件Echarts 进行开发。系统后端使用SSM(Spring+SpringMVC+MyBatis)框架开发,采用MVC(model view controller)设计模式实现,利用SpringMVC 的高内聚、低耦合特性实现业务模型与页面的分离,提高了代码的复用性。系统使用MySQL 作为数据库、Redis 作为缓存数据库、ES 作为MySQL 数据库的搜索引擎。整体架构如图2所示。
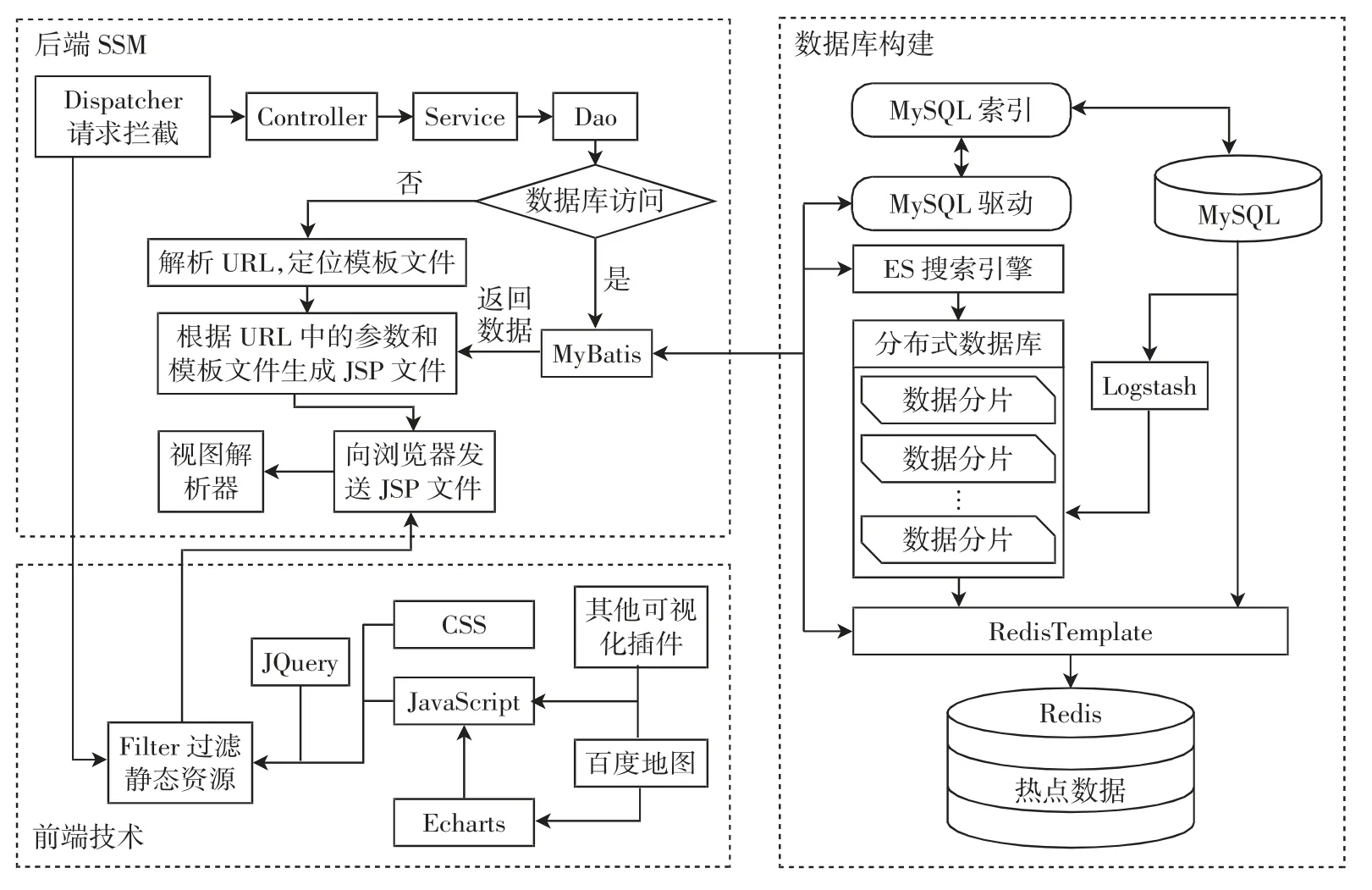
图2 航班延误可视化系统整体架构Fig.2 Overall structure of flight delay visualization system
2.2 数据库设计
数据库是航班延误可视化系统的基础,航班数据采用关系型数据库MySQL 进行存储。存储在其中的数据主要分为3 个部分5 张表,如图3所示,即原始航班数据部分1 张表、航班延误统计部分3 张表(包括以日、月、年为单位的统计表)及用户数据部分1 张表。
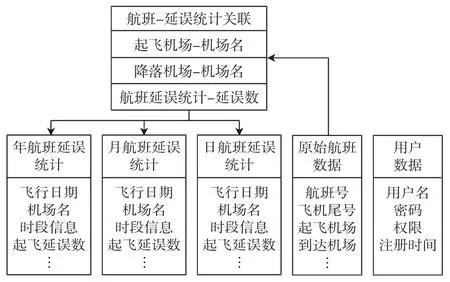
图3 数据存储结构Fig.3 Structure of data storage
原始航班数据包括:航班号、飞机尾号、起飞机场、到达机场、飞行日期、起飞/降落延误时间、数据更新时间等14 列内容。日、月、年航班延误统计表分别存储以小时、日、月为统计单位的航班延误统计结果。以日航班延误统计为例,统计数据包括:飞行日期、机场名、时段信息(0~23 点)、起飞/降落航班数量、延误架次、延误率、平均延误时长、无延误航班数量(延误时长≤15 min)、轻度延误航班数量(延误时长16~30 min)、中度延误航班数量(延误时长31~60 min)、高度延误航班数量(延误时长61~120 min)、重度延误航班数量(延误时长>120 min)等。用户数据表包括:用户名、密码、权限、注册时间。上述各表均使用InnoDB 的储存引擎进行存储,添加Int 类型、自增、主键类型的Id 列。为了节省存储空间,除主键列的其他数据列都使用可变长度的字符串类型定义。
MySQL 数据库中存储数据的主要查询需求来自航班延误统计模块,该模块统计数据需要进行大量的SQL 查询。面对大数据量的检索需求,提高MySQL 数据库响应速度的主要策略是在数据库中建立索引。
本系统使用联合索引(多列索引)的方式对起飞机场、航班执行日期、航班实际起飞时间、航班起飞延误时间、降落机场、航班实际降落日期、航班实际降落时间、航班降落延误时间8 个检索条件建立索引。在数据库中建立起飞与降落统计两个联合索引,具体如表1所示。
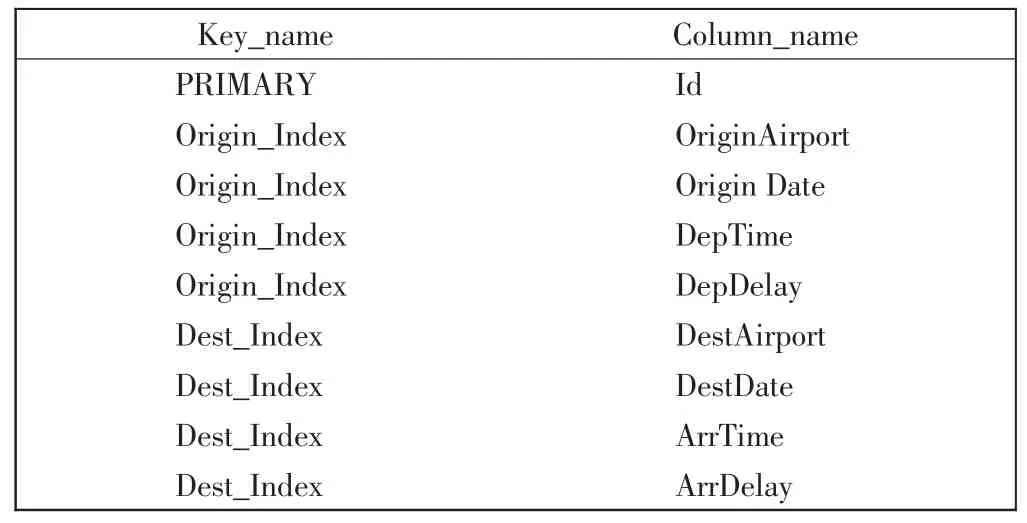
表1 Flight 表索引设计Tab.1 Index design of the Flight table
3 系统实现的关键技术
3.1 基于Socket 的航班延误预测
通过对深度学习算法进行封装,使用套接字对已经训练好的航班延误预测模型进行调用,设置系统后端为客户端,算法端为服务器端。系统后端通过Spring配置注解的方式在系统启动与结束时控制算法端的启动与关闭。系统启动后,算法端监听由可视化系统后端发送过来的请求,系统前端获取用户上传的航班排班信息,航班数据经过系统后端的数据解析后上传到算法服务器,然后将航班数据发送给航班延误预测模块进行数据的编码、预测,最终预测出各航班的延误等级,结果由Socket 返回系统后端,并将预测结果返回给系统前端界面,最终存储在数据库中。航班延误预测界面如图4所示。
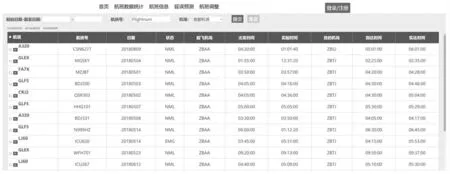
图4 航班延误预测界面Fig.4 Interface of flight delay prediction
3.2 基于Echarts 的航班延误可视化
航班延误统计模块通过配置启动加载项的方式,在首次启动时统计组件按日、月、年为单位统计数据库内的航班数据。
以日统计为例:统计模块以小时为单位进行航班日延误统计,包括起飞/降落航班数量、延误架次、延误率、平均延误时长及5 类延误等级的航班数量,统计结果直接写入MySQL 数据库的日航班延误统计表中。
系统启动后,由系统后端监听实时数据流,当航班数据进行更新时,调用航班延误统计模块对更新数据进行统计。为了保证MySQL 数据库性能,系统将统计结果先更新入Redis 数据库进行缓存,每隔一段时间对MySQL 数据库中的航班延误统计数据表进行更新。
界面的前、后端数据交互采用AJAX(Asynchronous JavaScript and XML)异步请求后端完成,流程如图5所示。系统后端对航班延误数据统计完成后,将统计结果存入MySQL 数据库中,当系统前端访问航班延误统计页面时,由前端先准备好DOM 容器,并选择合适的Echarts[9-10]统计实例,接着初始化实例,然后通过AJAX从MySQL 数据库读取并解析好统计数据,最后配置可视化组件参数,生成统计图表。航班延误数据统计界面如图6所示。
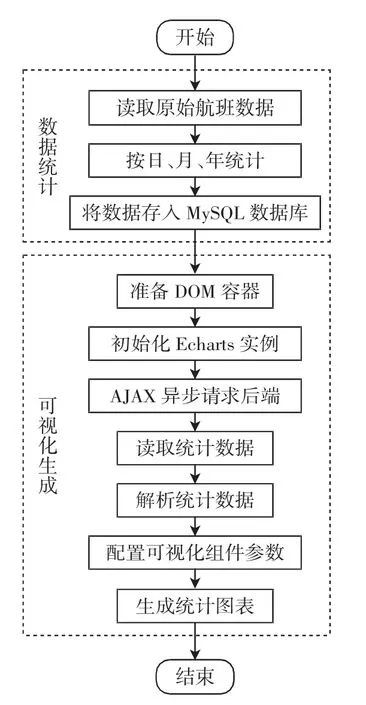
图5 航班延误数据统计流程Fig.5 Statistical analysis process of flight delay data
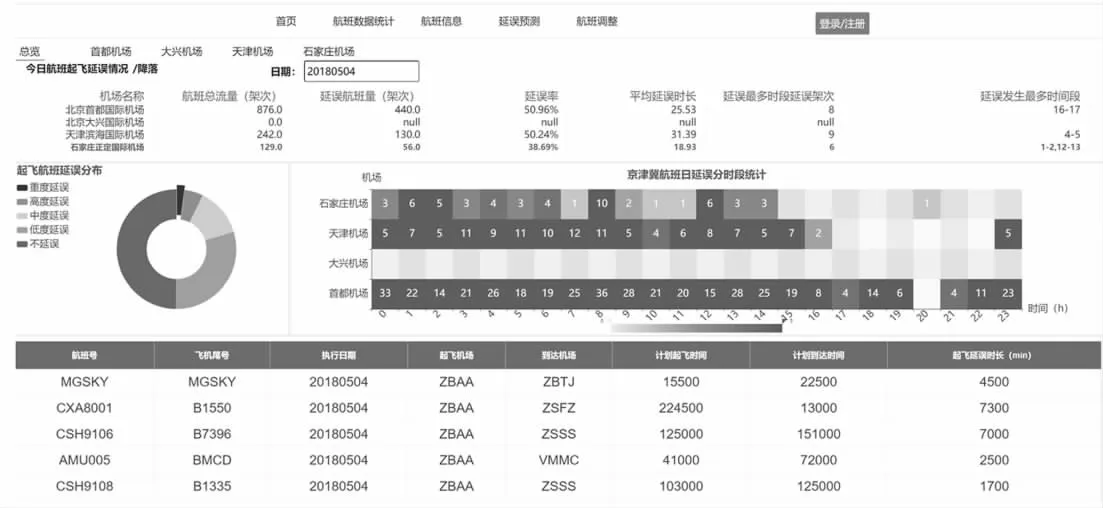
图6 航班延误数据统计界面Fig.6 Interface of statistical analysis of flight delay data
3.3 基于Redis 的缓存实现
为进一步提高系统的运行速度,减少系统延时,需要将系统中常用数据存入缓存。系统接受查询请求后会优先检测缓存内有无所需数据,如果无缓存记录,再去查询数据库,这样降低了MySQL 数据库的访问频率,提升系统的访问效率,降低数据库的压力,提高系统性能。
MyBatis 原生缓存分为一级缓存与二级缓存2 种:一级缓存是会话级别的缓存,MyBatis 默认开启一级缓存,在同一次会话内,相同查询条件会触发一级缓存并从缓存获取数据;二级缓存是映射文件级别的缓存,同一映射文件的不同会话共用二级缓存,二级缓存开启后缓存触发的顺序变为先查询二级缓存再查询一级缓存,数据库的插入与更新操作会自动触发缓存清理。二级缓存是面向映射文件开发的,不同的映射文件处理同一张数据库表会发生数据脏读。
Redis 是将所有的缓存数据存储在内存中,内存数据由定时清除算法或缓存替换算法管理,避免了脏读问题。
系统选用基于内存实现的高性能非关系型缓存库Redis 作为二级缓存,支持字符、链表、集合、有序集与哈希类型多种数据结构。相比MyBatis 的二级缓存,Redis 还支持数据的持久化操作,可以将存储在内存中的数据保存到硬盘上。为了保证数据一致性,当MySQL数据库中的数据进行更新、插入、删除操作后,需要及时清除Redis 缓存内容。
Redis 数据库还支持集群化,本系统采用主、从复制的集群化方案,主节点通过主、从备份将数据同步到从节点。该方案实现了Redis 的读、写分离,主节点只关注写入数据操作,从节点提供数据的读取功能,实现了Redis 的负载均衡。当一个节点出现宕机时,其他节点不会受到影响,大大提升了系统的稳定性与并发性。
3.4 基于ES 的搜索引擎部署
系统使用Redis 数据库作为缓存数据库,未命中的缓存查询仍会从MySQL 数据库中获取数据。MySQL数据库现存数据体量大且逐年增加,航班数据检索开销较大,使用ES 搜索引擎接管MySQL 数据可以极大缩短未命中缓存条件下的数据检索时间。
3.4.1 ES 搜索引擎
ES 搜索引擎是基于Lucence[11]倒排索引实现的。当数据导入ES 中,ES 会对存储内容进行分词,并为每个分词的字段建立存储位置、文档号码等信息的倒排索引。ES 的倒排索引是基于内存实现的,查询数据时先根据分词获取数据存储位置,再进行磁盘的搜索,这样的检索模式与MySQL 数据库的B+Tree 索引相比大大降低了检索数据时磁盘I/O 开销。为了节约倒排索引在内存中的存储空间,提升检索性能,ES 系统还会对倒排索引表进行压缩[12]。
3.4.2 数据导入
系统使用SpringBoot 对数据存储各模块进行整合,MySQL 数据库中的航班数据通过Logstash 插件导入ES 中。在使用Logstash 插件导入数据的基础上开发增量数据同步功能。Logstash 插件随系统同时开启,监听MySQL 数据库中原始航班数据表中的Id 列与数据更新时间列,原始航班数据表中发生更新、插入、删除操作时会相应地更新MySQL 数据库,并触发Logstash插件进行数据同步,增量同步数据流图如图7所示。
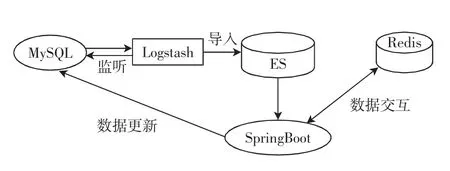
图7 增量同步数据流Fig.7 Data flow of incremental synchronous data
3.5 基于ES-Redis 的多条件关联查询算法
在系统部署上述缓存系统与搜索引擎基础上,利用ES 搜索引擎与Redis 数据库缓存对航班数据进行多条件关联查询,将多条件查询的请求参数标记为Q(QO,QF,QT,QD),其中:QO 表示起飞机场;QF 表示航班号;QT 表示航班执行日期;QD 表示降落机场。根据查询面板获取的查询参数,使用过滤器对数据进行条件搜索。针对过滤器查询策略提出一种查询算法,系统查询流程如图8所示,算法描述如下。
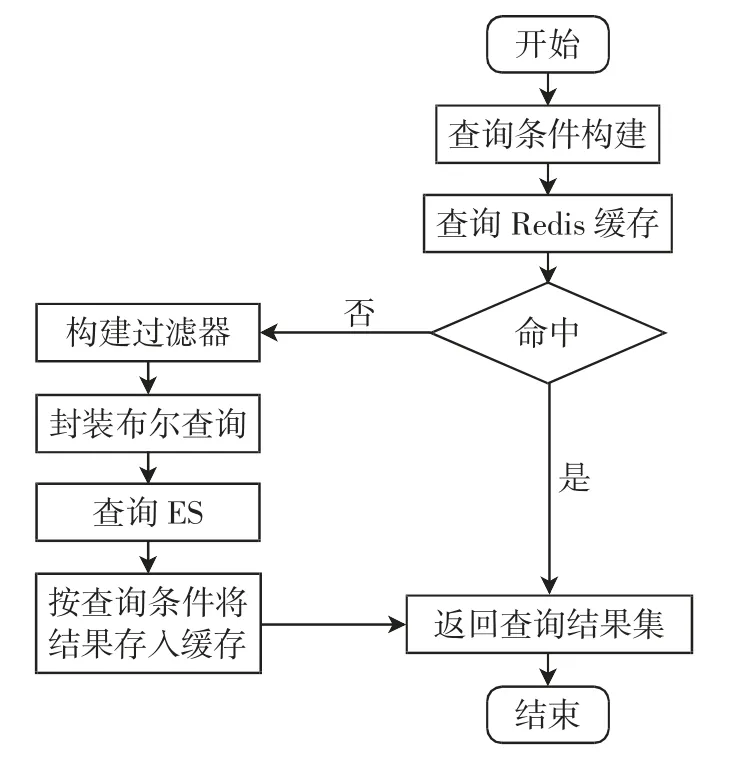
图8 系统查询流程Fig.8 Process of system query
输入查询条件Q(QO,QF,QT,QD)
输出航班数据结果集合
算法过程:
(1)先判断查询条件是否为空,将空的查询条件剔除,将剩余非空查询条件进行整合,整合结果(QO+QF+QT+QD)作为关键字对Redis 数据库中缓存内容进行搜索;
(2)若查询缓存的结果为空,则转向步骤(3);若查询缓存结果非空,则返回查询结果集,算法结束;
(3)将多个查询条件分别构建过滤器,并将过滤器封装入布尔查询中;
(4)使用布尔查询检索搜索引擎ES;
(5)按照查询条件作为关键字,将查询结果存入缓存,并返回查询结果集,算法结束。
4 基于ES-Redis 的缓存替换
系统使用的ES-Redis 检索模式尚有缺陷,由于Redis 数据库是完全基于内存运行的,过多的缓存数据会导致内存溢出,进而导致系统缓存失效,因此,设置缓存容量上限尤为关键。当系统到达缓存上限时,Redis 会根据缓存替换策略对缓存内的数据进行替换、删除操作。
4.1 Hybrid 算法介绍
Redis 数据库原始的缓存替换策略[13]有最近最久未使用(LRU,least recently used)算法、最近最少使用(LFU,least frequently used)算法及随机替换(random)算法。上述算法实现简单、容易调用,只需在Redis 数据库的配置文件中直接配置即可,但都没有考虑对象的大小与获取复杂程度等信息。相比而言,Hybrid算法的替换标准是根据缓存对象的使用频率、大小、获取复杂程度等信息计算缓存对象价值,数据的保留意义更大,可提升系统运行效率。Hybrid 算法缓存价值计算如下

式中:Fi为缓存对象Ri的缓存价值,价值越小被替换的概率越大;Cs为客户端与服务器连接的时间,这里表示从ES 中获取数据的损耗时间;C1与C2为固定常数;bs为服务器带宽;Si为缓存对象Ri的大小;fi表示缓存对象Ri的访问次数。
在Hybrid 算法基础上,引入缓存对象Ri的最后访问时间Ti来清理长时间未被使用的缓存对象,但由于Ti因子数值相差较大,对缓存价值影响过大,因此,引入lnTi因子,降低算法对Ti的依赖性。应用缓存替换算法的对象主要是常用的检索数据,缓存对象的大小相对固定,故此将式(1)改进为

4.2 Hybrid 缓存价值集设计
算法设计面向的数据对象是用户数据与热点数据,存储信息大小相对固定,因此,引用缓存价值集来存储缓存对象,分别将数据检索信息与用户信息存储在缓存价值集Or与Ou中。为Redis 数据库设置缓存容量也可转变为设置缓存价值集的存储数据容量上限。
以存储热点数据检索信息为例,缓存对象与缓存价值集的设置如下。
缓存对象Ri包括的信息如下:①缓存对象的Key;②从ES 获取数据所耗时间Cs;③缓存对象Ri的访问次数fi;④缓存对象Ri的最后访问时间Ti;⑤缓存对象Ri的缓存价值Fi;⑥缓存对象Ri的缓存内容。
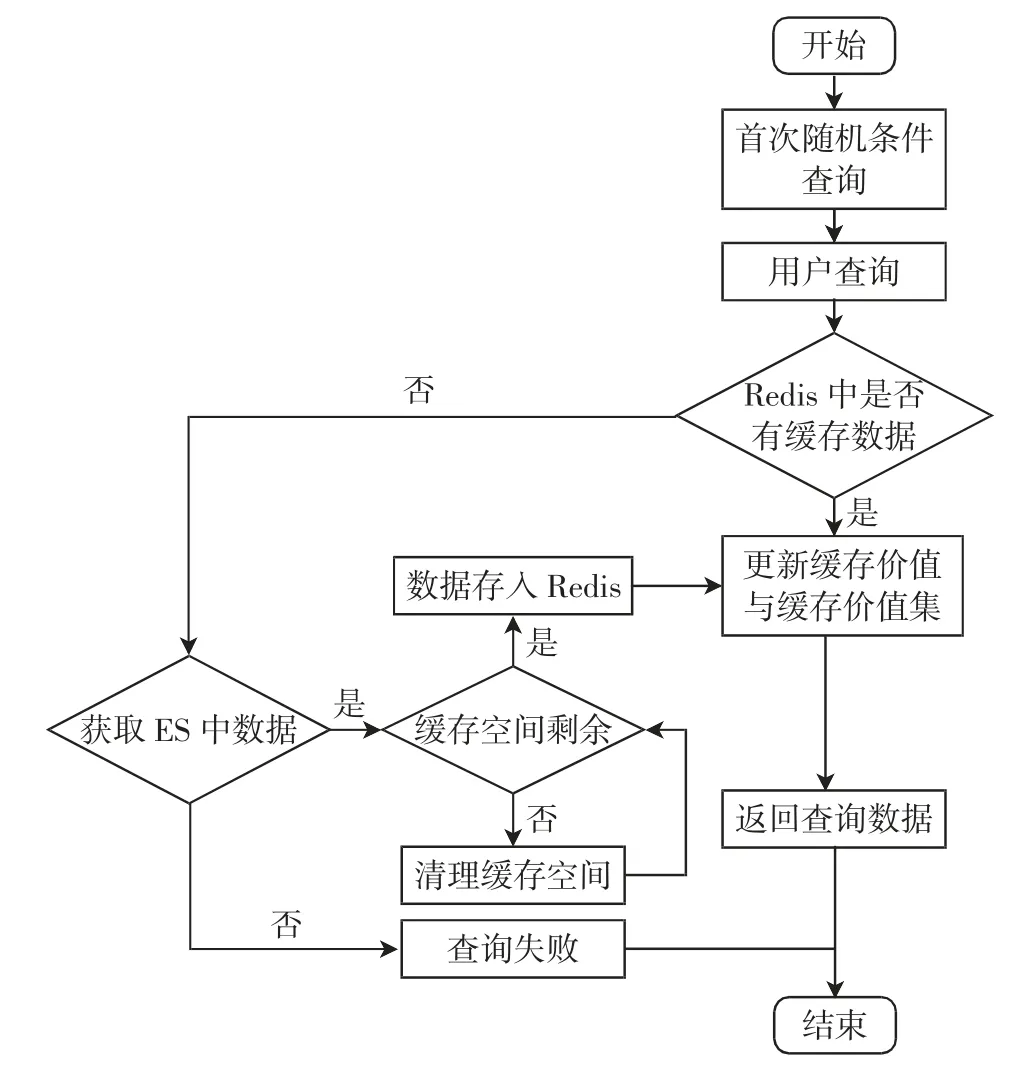
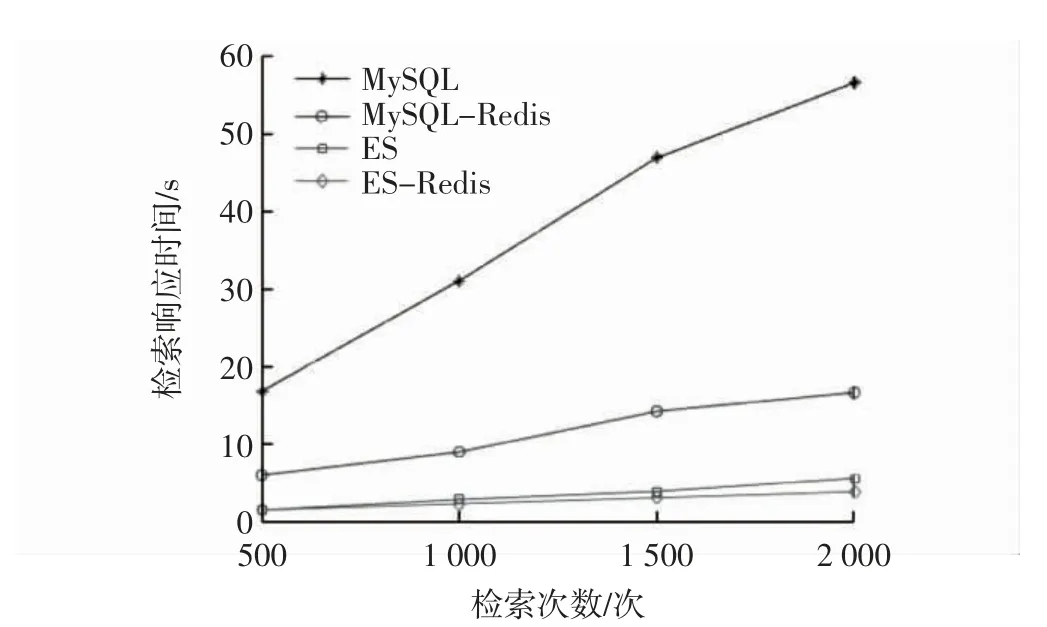
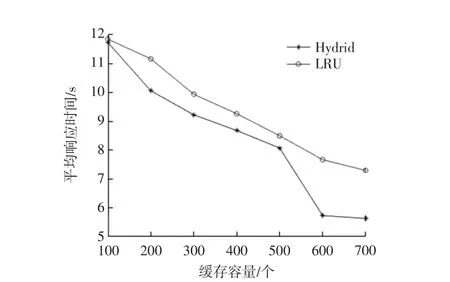
缓存价值集包含所有缓存对象,是以缓存对象Ri的Key 按照缓存价值从小到大的集合,其表示为Or={R1,R2,…,Ri},其对应的缓存价值F1 算法执行流程如图9所示,具体流程如下: 图9 Hybrid 算法执行流程Fig.9 Execution process of Hybrid algorithm (1)由于Redis 数据库存在首次查询时缓存未进行热备份导致检索缓慢的问题,因此,系统启动后,在系统后端构建随机条件进行首次检索; (2)当用户查询数据时,先判断Redis 数据库中是否有缓存数据,若缓存中有数据则更新缓存价值与缓存价值集,并返回查询数据,转步骤(4),否则转向步骤(3); (3)从ES 中进行数据检索,若未查询到,返回查询失败信息,转步骤(4);否则系统检索数据后,判断缓存价值集是否有缓存空间,如果有则存入其中,如没有清理缓存空间,从缓存价值集中剔除价值小的对象并将本次所查数据存入Redis 数据库中,最后更新缓存价值与缓存价值集并返回查询数据,转步骤(4)。 (4)算法结束。 设置MySQL、MySQL-Redis、ES、ES-Redis 4 组实验对象,在相同的运行环境下设置500~2 000 次的随机数据查询,设置Redis 数据库的缓存容量为700。根据系统的响应速度来对比MySQL、MySQL-Redis、ES、ES-Reids 4 种数据检索模式下的系统性能,实验结果如图10所示。 图10 各数据检索模式下检索响应时间Fig.10 Response time of data retrieval in each mode 从图10中可看出:原始的MySQL 数据检索模式性能最差,从加装Redis 缓存到使用ES 分布式搜索引擎后,数据检索效率又有一定提升,在使用文中的ESRedis 数据检索模式后,检索效率最高,相比于简单的MySQL 数据检索模式,ES-Redis 数据检索模式效率最多高10 倍以上。 以检索京津冀地区三大机场(北京首都国际机场、天津滨海国际机场、石家庄正定国际机场)一年内每天的航班信息为例。设置缓存查询命中失败后从ES中进行数据查询,查询数据的SQL 语句一共有365 ×3=1 095 种,随机查询语句对数据进行2 000 次访问,缓存初始容量为100。设置实验组LRU(Redis 数据库自带缓存替换算法,按照最近最久使用进行替换数据)与Hybrid 两组,分别使用LRU 与Hybrid 算法进行5次查询数据测试,记录从数据库获取数据的平均响应时间。实验结果如图11所示,可看出,由于Hybrid 算法考虑了对象获取的复杂程度,会使系统查询响应速度进一步提升。 图11 缓存容量与平均响应时间关系Fig.11 Relationship between cache capacity and average response time 设计并实现了基于ES-Redis 的航班延误可视化系统,主要介绍了需求分析、总体设计、系统实现的关键技术与ES-Reids 缓存替换算法实现。首先,对深度学习算法进行了模型封装,并使用Socket 技术实现模型调用;然后,使用MySQL 统计语句对航班延误数据进行统计,并使用Echarts 可视化技术对统计结果进行展示;再使用Redis 数据库缓存技术与ES 搜索引擎提升系统检索响应速度,在此基础上提出了一种基于ES-Redis 的数据多条件检索算法,实现了航班数据检索的快速响应,通过实验对比了MySQL 与ES-Redis等4 种模式的数据检索效率,证明了该算法的有效性;最后,着重介绍了基于ES-Redis 缓存替换的实现,量化并分析了分别使用原始LRU 算法与Hybrid 算法对系统性能的影响,用实验证明了Hybrid 算法的可行性。4.3 Hybrid 算法执行流程
5 实验结果
5.1 数据检索性能对比
5.2 Hybrid 缓存替换算法性能分析
6 结语
猜你喜欢
计算机与网络(2022年2期)2022-03-17
金桥(2021年10期)2021-11-05
金桥(2021年9期)2021-11-02
金桥(2021年8期)2021-08-23
金桥(2021年7期)2021-07-22
疯狂英语·新阅版(2020年11期)2020-12-21
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
科学与财富(2017年28期)2017-10-14
