
异构环境下Spark动态资源调度策略研究
2021-02-14 03:14吴仁彪贾云飞
中国民航大学学报 2021年6期
吴仁彪,刘 备,贾云飞
(中国民航大学天津市智能信号与图像处理重点实验室,天津 300300)
传统的单机处理模式不再满足越来越多的机构处理其海量数据,Spark 以内存计算、通用和可扩展性等优势成为目前主流的大数据计算框架[1]。集群硬件设备的不断更新、损耗及计算需求的扩大,会导致Spark 集群中的节点性能差异较大,使得集群异构。异构是指集群节点因CPU 等不同硬件的性能差异而导致其自身处理能力出现差异。如果仍用现有的资源调度策略,在集群异构且资源约束的环境下会导致集群节点的负载失衡,影响作业执行效率。Spark 资源调度策略是影响集群执行效率的关键之一,因此,研究Spark集群异构环境下高效、合理的资源调度策略具有重要意义。目前,国内外针对资源调度优化的研究主要着眼点于以下两方面。
(1)通过优化资源调度,提高集群的运行效率是研究的热点之一。杨志伟等[2]在Spark 默认调度策略基础上,通过分布式集群监视系统Ganglia 获取异构集群节点负载及资源利用率,动态调整节点的优先级,提高了集群的执行效率。Cheng 等[3]提出一种动态资源下考虑作业完成期限的Hadoop 作业调度(RDS,resource and deadline-aware Hadoop job scheduler)算法,RDS 通过考虑未来资源的动态变化,减少作业未在截止时间完成造成的损失。冯兴杰等[4]通过建立异构Hadoop 集群节点硬件参数和动态信息两个节点性能评价指标,度量节点优先级并改进Hadoop 资源管理器的公平调度算法,提高了Hadoop 集群的执行效率。胡亚红等[5]将文献[4]的方法运用到异构Spark 集群的默认调度策略中,提出了一种基于节点优先级的Spark 动态自适应调度算法,缩短了Spark 作业的执行时间。随着机器学习算法的快速发展,众多研究人员将遗传算法[6-7]、粒子群算法[8-9]和蚁群算法[10-11]等运用在资源调度中并对多目标进行优化,且上述算法应用到集群资源调度中能够取得较好的效果。
(2)随着集群规模的扩大,集群能源的消耗问题是研究的另一热点。大量的能源消耗不仅导致集群运行维护成本增加,还会产生大量的二氧化碳,造成一定的环保问题。因此,有必要研究如何在不违反服务水平协议的前提下,优化资源调度以减少集群的能源消耗[12]。Grozev 等[13]提出了一种虚拟机资源调度算法,通过利用虚拟机实时迁移技术,将虚拟机合并到较少的物理节点上,从而降低集群的能源开销,提高资源利用率。
综上,针对异构Spark 集群在资源约束条件下,根据集群节点的负载变化动态调度资源方面的研究较少。直接修改源代码是优化Spark 资源调度策略最直接、有效的方式。将集群节点的静态负载和运行时的动态负载信息作为异构集群节点负载的评价指标,在集群分配资源时,基于负载大小对集群节点的顺序进行更新调整,实现资源动态分配,从而改进Spark 资源调度策略。
1 异构Spark 集群节点负载评价
在异构环境下,为保障作业的完成时间,提高集群执行效率,需要准确衡量各节点的负载大小,从而选出合适的节点进行资源分配。有效的评价指标是资源调度优化的基础,节点负载情况不仅受节点静态负载的影响,同时也受节点动态负载的影响。
1.1 节点静态负载
传统节点负载评价方法将CPU 核数、内存及磁盘等硬件参数作为衡量节点性能的指标。随着集成电路技术的发展和制作工艺水平的提高,几年前的单核CPU 和当前单核CPU 的计算能力存在巨大差距,相同大小的内存、磁盘等硬件性能也不可同日而语。文中选取SparkPi、WordCount 和K-means 3 组实验分别在单个Worker 节点上执行,3 组实验充分利用了集群单个节点的计算处理能力。首先,为了避免其他因素的影响,保证实验结果的有效性,每组实验在Worker 节点执行m 次,得到3 组实验的平均执行时间;然后,累加计算得到3 组实验的总平均执行时间;最后,对总平均执行时间进行归一化处理,归一化的结果表示节点的静态负载。
SparkPi 实验是运用蒙特卡洛法计算出圆周率π值,主要利用服务器的CPU 资源。WordCount 实验是对大规模的文本文件数据进行拆分和处理,最后进行词频统计,该实验在处理数据的过程中利用了服务器的CPU 和内存资源。K-means 是一种经典的聚类算法,Spark 集群通过K-means 实验对数据进行聚类分析,迭代结果在内存中反复读写,主要利用服务器的内存资源。通过SparkPi、WordCount 和K-means 3 组不同类型的实验,综合衡量服务器的硬件性能。
(1)每组实验在Worker 节点的平均执行时间表示如下
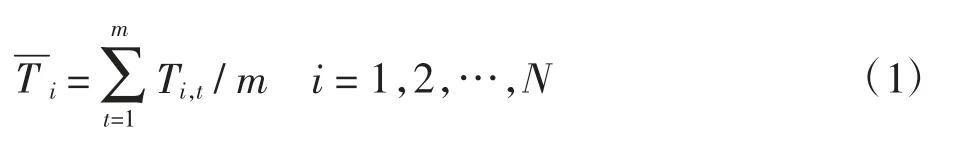
式中:m 为每组实验在Worker 节点的执行次数;Ti,t表示第i 节点第t 次的执行时间;N 为集群的Worker 节点数量。
(2)3 组实验的总平均执行时间归一化的结果表示Worker 节点静态负载,即
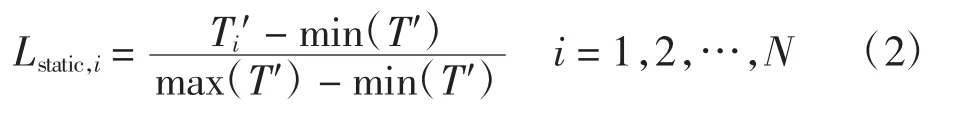
式中:Lstatic,i表示第i 节点的静态负载;Ti′表示第i 节点3 组实验的总平均执行时间,T′={T1′,T2′,…,TN′};min(T′)表示T′中最小的元素值;max(T′)表示T′中最大的元素值。
该方法较好地解决了异构集群节点中CPU、内存及磁盘等硬件型号不同导致传统性能评价指标不能很好适用的问题。SparkPi、WordCount 和K-means 的平均执行时间长短更充分展现出了硬件性能差异。
1.2 节点动态负载
Spark 是基于内存处理的计算框架,主要利用CPU和内存进行计算。节点负载会随着集群运行状态动态变化,因此,需要实时关注集群资源使用情况以获取相关信息。为了准确反映节点负载的动态变化,选取了CPU 利用率、内存利用率和任务竞争程度3 个指标。
通过Linux 系统提供的一个内存文件系统proc来进行节点数据信息的采集。proc 提供了一个基于文件的Linux 内部接口,其中的数据随时间不断变化,可用于确定系统中各种不同进程的状态。
(1)选取Linux proc/stat 命令采集的CPU 用户态时间(user)、低优先级的用户态时间(nice)、核心态时间(system)及空闲时间(idle)的累加和作为Worker 节点CPU 运行总时长,第i 节点第k 次计算的CPU 运行总时间表示为
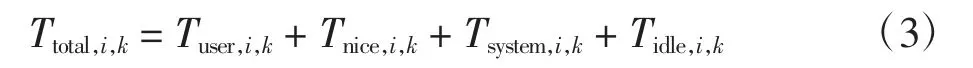
式中Tuser,i,k、Tnice,i,k、Tsystem,i,k、Tidle,i,k分别表示第i 节点第k 次采集的用户态时间、低优先级的用户态时间、核心态时间及空闲时间。再根据相邻两次采集的数据计算出当前的CPU 利用率,第i 节点第k 次计算的CPU利用率表示为
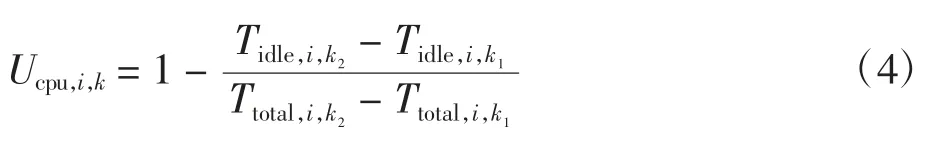
式中:Tidle,i,k1和Tidle,i,k2分别表示第i 节点相邻两次采集到的空闲时间;Ttotal,i,k1和Ttotal,i,k2分别表示第i 节点相邻两次计算的CPU 运行总时间。
(2)选取Linux proc/meminfo 命令采集的总共可用的内存大小(memtotal)和未使用的内存大小(memfree)计算出Worker 节点的内存利用率,第i 节点第k 次计算的内存利用率表示为
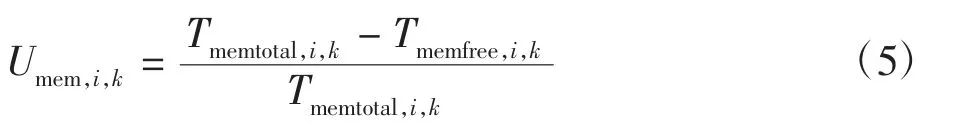
式中Tmemtotal,i,k和Tmemfree,i,k分别表示第i 节点第k 次采集的总共可用的内存大小和未使用的内存大小。
(3)集群在执行任务的过程中,节点的任务队列会随着时间变化,选取Linux proc/loadavg 命令采集的1 min 时的任务队列的平均长度计算出Worker 节点的任务竞争程度,第i 节点第k 次计算的任务竞争程度表示为

式中:Ltask,i,k表示第i 节点第k 次采集的任务队列的平均长度;Ncpu,core,i表示第i 节点CPU 核数。
(4)选取CPU 利用率、内存利用率和任务竞争程度表示Worker 节点动态负载,则第i 节点第k 次计算的动态负载表示为
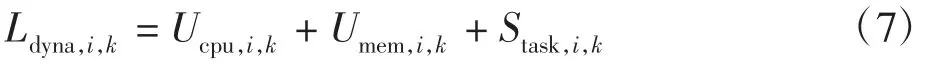
1.3 节点负载
综合考虑节点静态负载和动态负载作为节点负载的评价指标,异构集群第i 节点第k 次计算的负载表示为
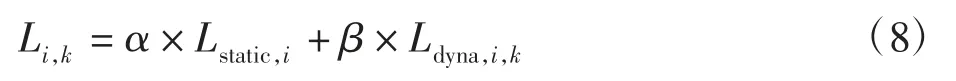
式中α、β 分别表示节点静态负载和动态负载的权重,α+β=1。
此异构Spark 集群节点负载评价策略不用在集群中安装Nanglia 就可获取到Worker 节点的数据信息,不会额外消耗集群资源,直接通过Linux 命令获取Worker 节点的数据信息,延迟较小。
2 Spark 资源调度策略描述
2.1 默认资源调度策略
Standalone 是Spark 计算框架的默认资源调度器[14],合理的资源分配是集群高效运行的基础。Spark 计算框架复杂,资源调度中重要流程如图1所示。
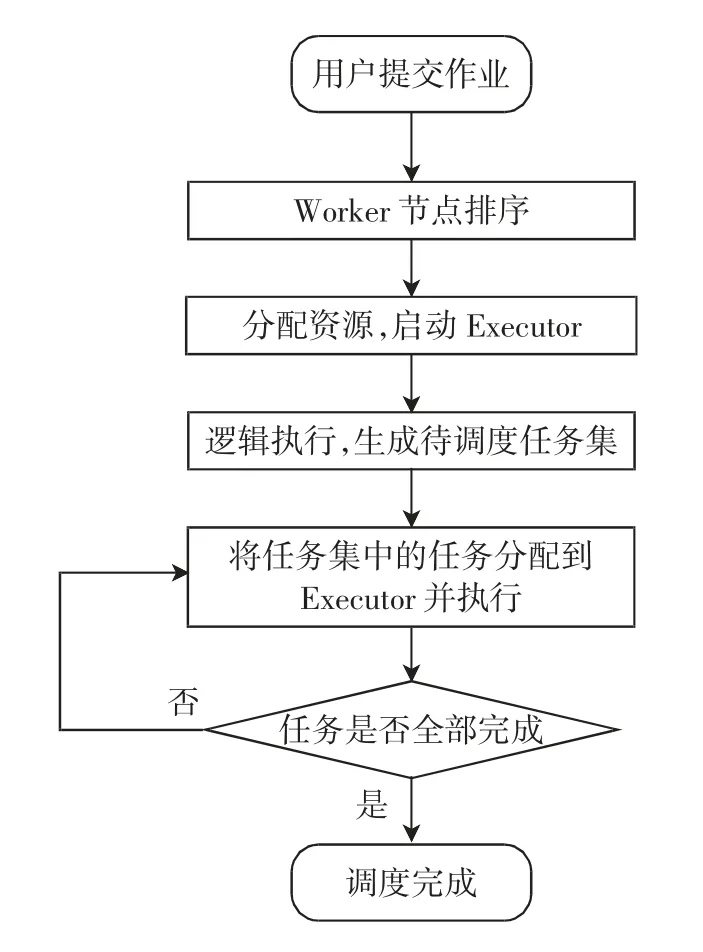
图1 资源调度流程图Fig.1 The flow chart of the resource scheduling
Spark 集群在Standalone 调度下,当多个用户提交应用程序(Application)到集群中运行,按提交时间顺序对Application 进行排序。Master 节点在集群中根据Worker 节点剩余CPU 核数从大到小排序。默认分配规则先进先出取出队列第一个Application,按照Worker 节点顺序筛选满足资源的节点启动执行器(Executor),剩余排队的Application 在剩余资源中再次筛选。Spark 默认资源调度策略基于集群节点同构的理想化设计,只考虑节点CPU 使用情况,没有考虑集群异构性及节点当前内存使用情况。这种资源调度策略在执行CPU 密集型作业时具有很高的效率,但执行内存密集型作业时很可能造成CPU 配置高且内存配置较低的节点内存经常处于满负载状态,而CPU 配置较低且内存配置高的节点内存经常处于饥饿状态。
2.2 Spark 动态资源调度策略设计架构
针对以上不足,设计出基于异构集群节点负载的Spark动态资源调度策略,以包含2 个Worker 节点的集群为例,设计架构如图2所示。其中:Worker 节点中的节点动态负载指标收集模块负责获取每个Worker节点的CPU 利用率、内存利用率和任务竞争程度3 个指标的实时数据,通过Spark 的RPC(remote procedure call)将收集的数据以心跳方式传输到Master 节点;Master 节点中的节点负载计算存储模块负责获取Spark 配置文件spark-defaults.conf 中的节点静态负载,将传输的数据代入节点动态负载公式,得到节点的动态负载,再根据节点的静态负载和动态负载数据计算出节点负载。当需要分配资源时,Master 节点将Worker 节点根据负载值由小到大进行排序,优先选择队列靠前且满足运行条件的Worker 节点开辟资源。Worker 节点序列调整的频率与Spark 的心跳频率有直接关系。为保证Worker 节点序列能准确、迅速地根据节点负载值动态调整,本策略将Spark 源代码中的心跳频率由默认的15 s 调整到3 s,提高了资源分配时节点的适配性。
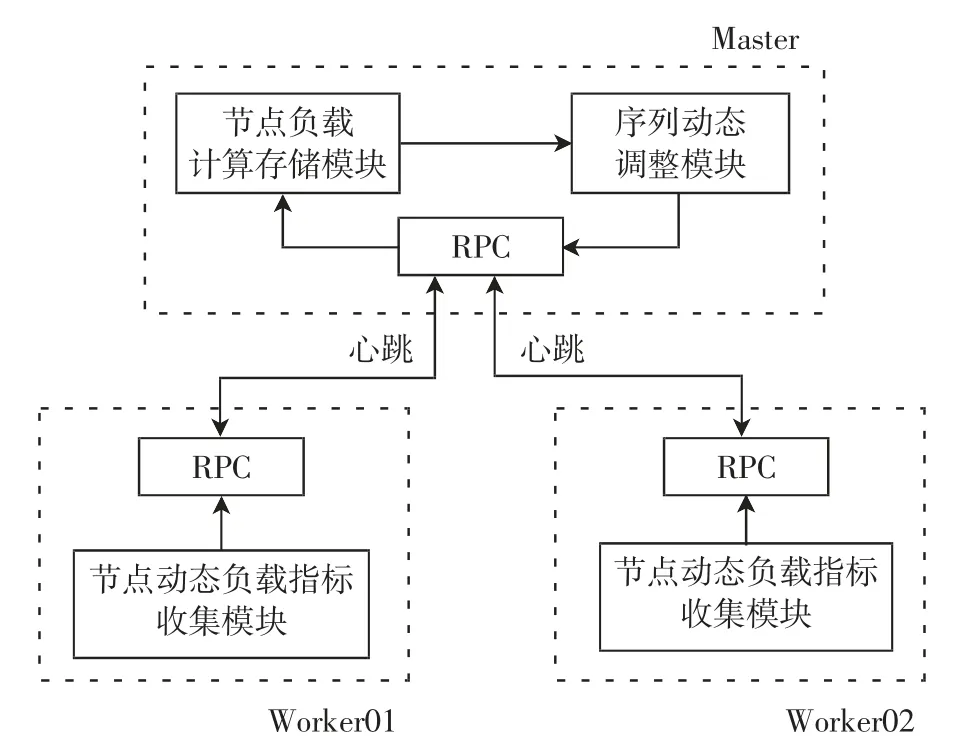
图2 Spark 动态资源调度策略设计架构Fig.2 The design architecture of spark dynamic resource scheduling strategy
2.3 Spark 动态资源调度策略模块实现
直接修改Spark 源代码实现基于异构集群节点负载的Spark 动态资源调度策略。Spark 源代码默认资源调度策略涉及的主要的类和特质如图3所示,修改之后进行多次调试、验证,最后部署到Spark 集群中运行。
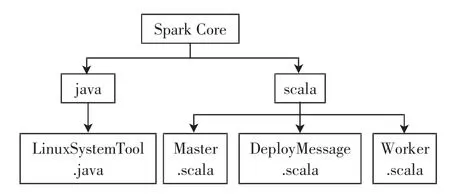
图3 源码模块实现框图Fig.3 Implementation diagram of source code module
LinuxSystemTool 类实现以下功能:①通过采集/proc/stat 文件中当前i 节点的Tuser,i,k、Tnice,i,k、Tsystem,i,k及Tidle,i,k4 个参数值,然后设置线程睡眠1 s(Thread.sleep(1 000)),再次采集上述4 个参数值,将前后两次采集值代入式(3)和式(4),可得到当前i 节点的CPU 利用率;②通过采集proc/meminfo 文件中当前i 节点的Tmemtotal,i,k和Tmemfree,i,k参数值,代入式(5)可得到当前i 节点的内存利用率;③通过采集/proc/loadavg 文件中1 min 时的任务队列的平均长度,代入式(6)可得到当前i 节点的任务竞争程度。
在Master 类中,读取配置文件spark-defaults.conf中的节点静态负载,将静态负载与节点IP 地址进行映射。通过负载计算公式和心跳传输的动态负载指标,计算出实时的节点负载值。根据节点负载值大小对节点进行由小到大排序,确定节点的优先级。
在DeployMessage 特质中添加MachineInfo 类,类中包含节点CPU 核数、CPU 利用率、内存利用率和任务竞争程度4 个参数。将样本类MachineInfo 添加到心跳Heartbeat 类参数中。
在Worker 类中,通过修改HEARTBEAT_MILLIS变量,将心跳频率由默认的15 s 调整到3 s,提高节点负载实时更新频率。心跳触发时,通过调用Linux SystemTool 类收集节点动态负载指标。
将修改后的Spark 源代码通过Maven 进行编译,编译生成的spark-core.jar 文件与集群所有节点的spark-core.jar 文件进行替换,实现上述基于异构集群节点负载的Spark 动态资源调度策略。当集群扩展时,只需要将增加的节点静态负载与对应的IP 地址添加到spark-defaults.conf 中,无需重新修改、编译sparkcore.jar 文件。此策略具有良好的可扩展性。
3 实验分析
通过实验得到Spark 集群中Worker 节点静态负载,并确定节点的静态负载和动态负载的权重,分别取值为0.4 和0.6。将基于异构集群节点负载的Spark动态资源调度策略(简称改进调度策略)与默认资源调度策略进行比较,分析策略的优缺点。
3.1 实验环境
通过安装VMware 虚拟机(VM)来构建异构Spark集群,每台VM 作为集群的1 个节点,共3 个节点。部署的Spark 集群包括1 个Master 节点和2 个Worker节点。集群相关配置参数如表1所示。
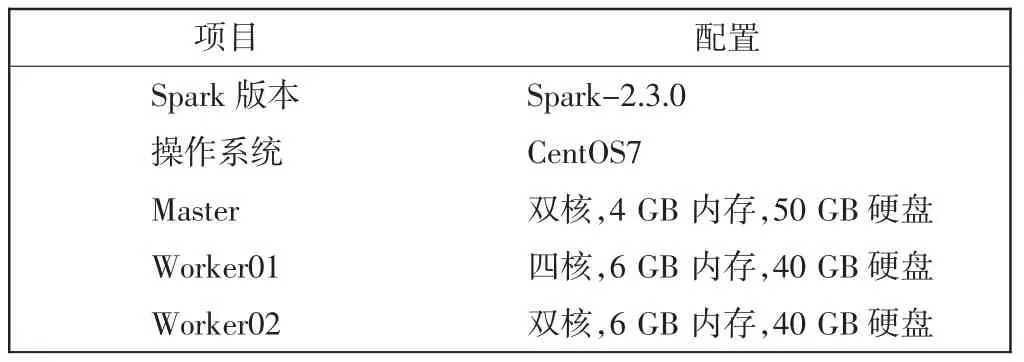
表1 集群相关配置Tab.1 Cluster related configuration
3.2 节点负载实验结果分析
利用SparkPi、WordCount 和K-means 3 组实验,测试集群中每个节点的性能。每个Worker 节点都分别执行2 000 次随机选点的SparkPi 实验、1 GB 数据量的WordCount 实验和1 GB 数据量的K-means 实验,为程序分配节点的所有资源。实验重复10 次,3 组实验执行时间如图4所示。
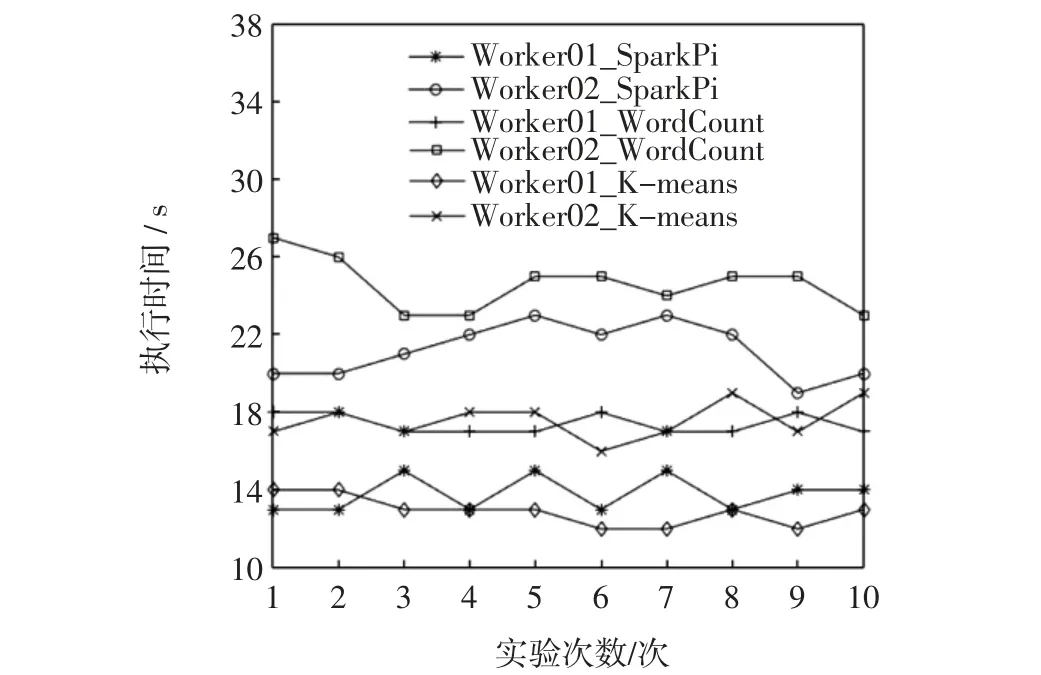
图4 3 组点节负载实验执行时间Fig.4 Three groups of node load experiments execution time
由图4可看出,相同实验每次的执行时间稍有波动,为保证结果的可靠性,取每组执行时间的平均值。根据式(1)和式(2)得到Worker 节点静态负载值。3 组实验平均执行时间充分反映出节点的硬件性能,节点的硬件性能制约着作业的完成时间,因此,节点的静态负载是集群资源调度的关键指标。
3.3 有效性实验结果分析
本节实验分成两种:实验1 是CPU 密集型作业,选择计算π 值的SparkPi 实验;实验2 是内存密集型作业,选择聚类算法K-means 实验。测试改进调度策略与默认调度策略对两种不同作业的执行效果,实验执行10 次,取执行时间的平均值。两种实验的参数设置如表2所示。

表2 参数设置Tab.2 Parameter settings
实验1SparkPi 实验分为两组,分别将程序重复提交到集群中2 次和3 次,提交间隔为5 s,测试多个CPU 密集型作业向集群申请资源执行时,集群资源的分配情况和作业平均执行时间。实验在Standalone 集群模式下执行,结果如表3所示。
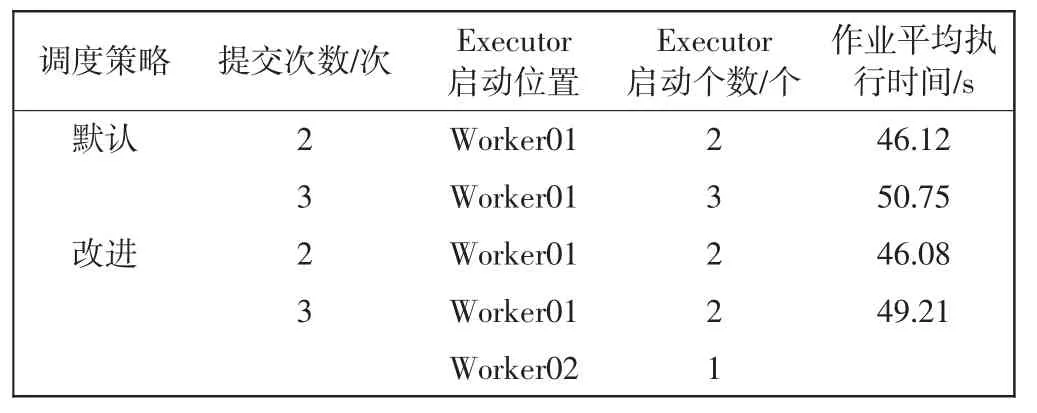
表3 SparkPi 实验结果Tab.3 Experimental results of SparkPi
表3中Executor 的启动位置和启动个数表示集群已启动资源的分布情况。分析表3结果可知,集群异构的情况下,默认调度策略在分配资源时存在负载失衡的情况。根据本组实验结果显示和对Spark 源代码研究分析可得:默认调度策略对使用CPU 计算的作业具有很好的执行效率;在一般情况下,改进调度策略和默认调度策略在执行CPU 密集型作业时效率相当;当默认调度策略出现多个作业集中在单个节点的情况时,改进调度策略能够一定程度上缩短作业执行时间。
实验2K-means 实验提交方式同实验1,该实验是为了验证默认调度策略在分配资源时只考虑了CPU的使用情况,没有考虑此类内存密集型作业内存的使用情况,当用户以一定时间间隔提交多个内存密集型作业向集群申请资源时,造成资源分配不均,影响作业执行时间,同时分析改进调度策略在此情况下是否能得到更好的效果。实验使用1 GB 数据量,K-means 实验结果如表4所示。
分析表4结果可知,集群异构的情况下,当单个作业占用的内存较大时,基于剩余CPU 核数考虑的默认调度策略会导致集群负载严重失衡,改进调度策略则能取得良好的效果。当重复提交2 个作业时,改进调度策略作业平均执行时间缩短了7.97%。当重复提交3 个作业时,此时默认资源调度下节点间负载已经极度不均衡,改进调度策略作业平均执行时间缩短了13.40%。
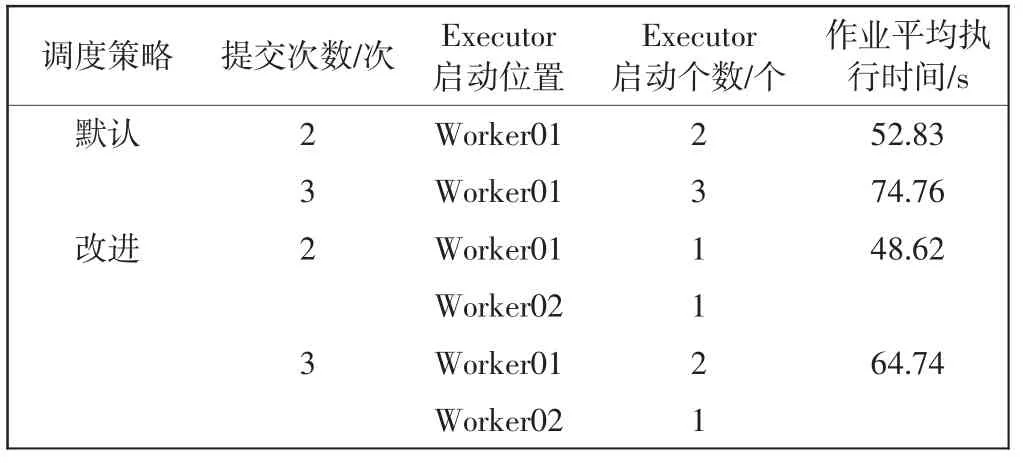
表4 K-means 实验结果Tab.4 Experimental results of K-means
3.4 可扩展性实验结果分析
Spark 集群增加Worker03 节点,节点硬件配置为双核、4 GB 内存和40 GB 硬盘。Worker03 节点的3 组实验执行时间如表5所示,可求得该节点总的平均执行时间为64.5 s。
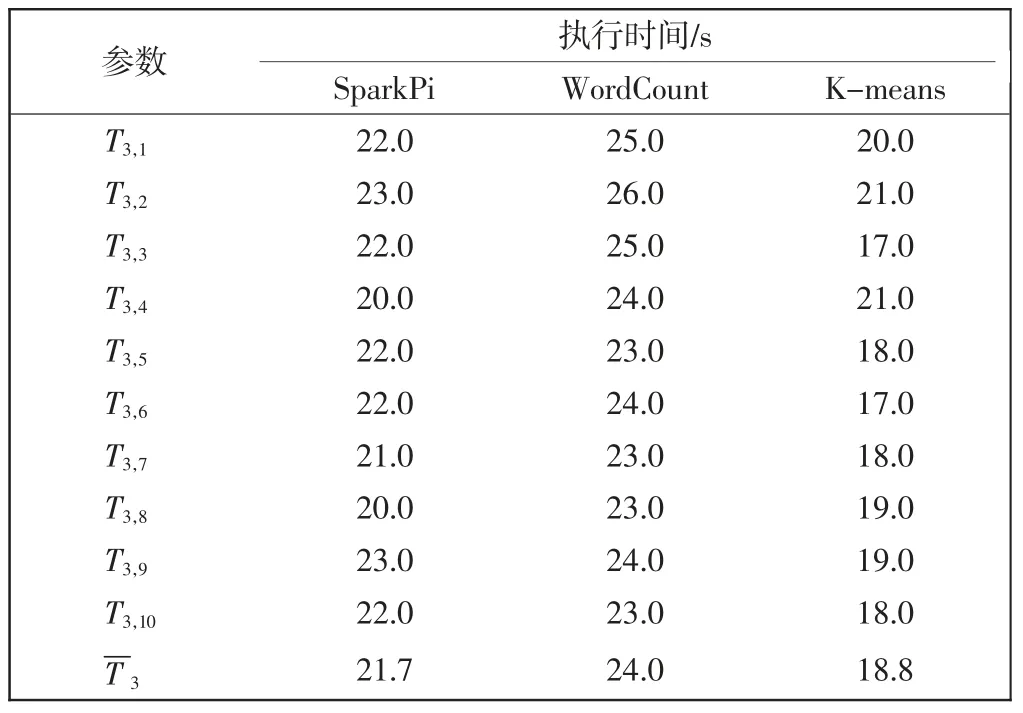
表5 3 组可扩展性实验执行时间Tab.5 Three groups of scalability experiments execution time
Spark 集群执行K-means 实验,参数设置、数据集和提交方式同实验2。该组K-means 实验的可扩展性实验结果如表6所示。
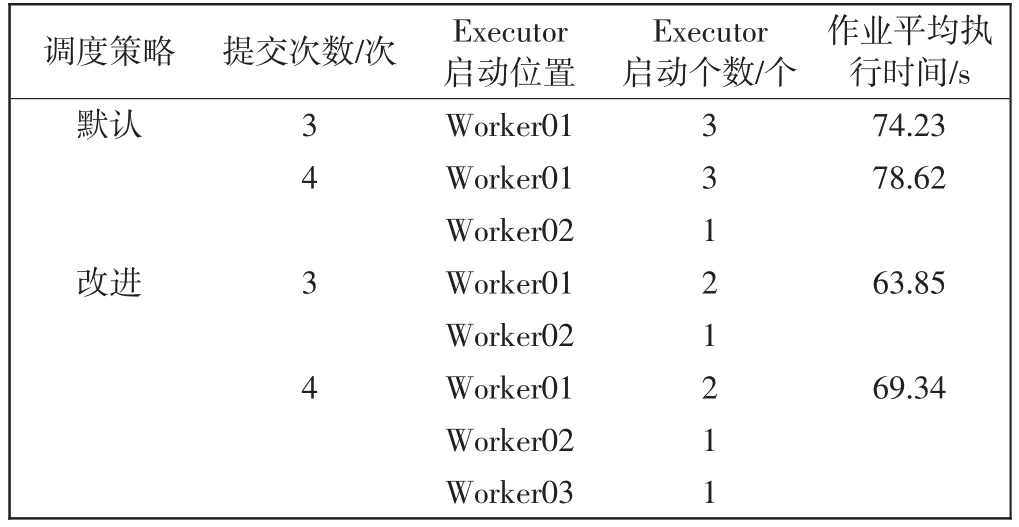
表6 可扩展性实验结果Tab.6 Experimental results on scalability
分析表6结果可得,当集群节点增加时,改进调度策略同样可以有效缓解集群负载失衡问题且缩短了作业平均执行时间,验证了改进调度策略的可扩展性。
综上,实验验证了默认调度策略存在不足,而改进调度策略不仅适用默认调度的应用场景,且在用户执行多个内存密集型作业场景中取得更好的效果,缩短了作业平均执行时间,提高了集群的工作效率,同时具备较好的可扩展性。
4 结语
通过研究Spark 的资源管理器Standalone,对传统衡量节点性能的方法进行优化。综合考虑节点静态负载和动态负载确定了异构集群节点负载评价指标,在获取节点动态负载方面,此策略没有添加集群监控组件,而是通过Linux 的内存文件系统proc 实现,不会额外消耗集群资源。根据异构集群节点负载评价指标计算出节点实时负载,优先选取负载低的节点分配资源,实现集群资源的动态调度。从源代码层级对Spark资源调度策略进行改进,并搭建异构Spark 集群进行实验,结果表明:Spark 集群中加入此改进调度策略,在集群负载均衡方面取得较好效果;在特定场景下,提高了作业执行效率,证明了策略的有效性和可扩展性。下一步工作要在源代码的基础上,进一步改进Spark 任务调度,将任务调度策略与改进的资源调度相结合,使得调度策略更具有普适性。
猜你喜欢
中国交通信息化(2022年7期)2022-10-27
计算技术与自动化(2022年2期)2022-07-04
小学教学研究(2022年5期)2022-04-28
纺织科学研究(2021年6期)2021-07-15
电脑报(2019年31期)2019-09-10
当代陕西(2019年13期)2019-08-20
福建基础教育研究(2019年11期)2019-05-28
信息化建设(2019年2期)2019-03-27
知识就是力量(2017年2期)2017-01-21
电脑爱好者(2015年21期)2015-09-10
