
基于高光谱红边位置提取的水稻叶绿素反演研究
2021-02-13 07:21:04曹英丽江凯伦刘亚帝于正鑫于丰华
沈阳农业大学学报 2021年6期
曹英丽,江凯伦,刘亚帝,于正鑫,肖 文,于丰华
(沈阳农业大学信息与电气工程学院/辽宁省农业信息化工程技术中心,沈阳110161)
在水稻生产中,水稻植株的叶绿素含量是反映其营养胁迫、光合能力和健康状况的重要生化指标之一,也是决定水稻产量和品质的关键要素[1]。无人机高光谱遥感技术能够对水稻的叶绿素含量进行大规模的连续监测,实现优化资源利用和控制水稻健康生长,获得更好的水稻产量。
高光谱遥感监测主要是通过提取作物冠层反射率信息构建光谱特征参数,对作物的叶片叶绿素含量、氮素、叶面积指数等生物量进行反演,其中红边位置(red edge position,REP)是绿色植被反射光谱中较为明显的光谱特征参数[2],与作物的叶绿素含量密切相关[3]。相比于受胁迫和不健康的植物,具有较高叶绿素含量的健康植物的REP会向更长的波长移动(红移)[4]。由于REP对中高密度植被的敏感性更高,因此广泛用于作为监测大田作物生物量的光谱特征参数,例如玉米叶绿素含量[5]、冬小麦叶绿素含量[6]、马铃薯植株氮浓度[2]、油菜叶氮含量[7]和小麦冠层氮浓度[8]等。
高光谱REP提取算法主要包括:最大一阶导数(MFD)[9]、线性四点插值(LI)[10]、线性外推法(LE)[11]、多项式拟合(PF)[12]、拉格朗日插值(LAG)[13]和倒高斯模型(IG)[14]等方法。MFD是从反射光谱中提取REP最常用的方法,但是此方法提取的REP数据在700nm和725nm呈双峰分布,并且出现不连续现象[11]。一些算法倾向于从反射光谱数据中提取连续REP,例如,通过IG方法提取的REP与针叶树叶绿素含量有显著的相关性[14]。DAWSON等[13]提出了LAG方法,然而仅当一阶导数光谱可用时,基于LAG和IG的方法才适用[14]。CHO等[11]定义了从4个坐标波段的一阶导数光谱中提取REP的LE方法,以减轻双峰特征对叶绿素和REP之间相关性的不稳定性影响。DARVISHZADEH等[15]通过LE方法提取的REP能够精确地模拟意大利马杰拉国家公园的草地叶绿素含量和叶面积指数。PF技术使用高阶曲线拟合光谱,将REP定位为反射光谱的最大一阶导数,PU等[12]表明用PF方法拟合的反射率曲线几乎接近红边区域的实际光谱特性。GUYOT等[10]定义了LI方法,并表明该方法是从反射光谱数据中提取REP的一种更实用和更合适的方法,只需要4个波段和一个简单的插值计算可得到REP。这些提取REP的算法已被证明在监测几种植物的叶绿素[5-6]、氮[7-8]和叶面积指数[15-16]方面表现出良好的效果。
基于无人机光谱遥感影像的作物营养监测模型的构建方法主要包括机器学习和经验统计回归方法[17]。以机器学习模型为代表的有反向传播神经网络(BPNN)、支持向量机(SVM)、极限学习(ELM)等,纪伟帅等[18]利用无人机低空遥感技术,通过构建6个特征光谱指数建立多元线性回归、SVM、BPNN 3种棉花花铃期的SPAD值反演模型,其中BPNN模型的决定系数达到0.758,实现对棉花长势的监测。于丰华等[19]采用PCA提取水稻高光谱特征,利用粒子群优化后的ELM建立水稻氮素含量反演模型,决定系数达到0.838,为农用无人机精准施肥提供模型基础。毛博慧等[20]采取遗传算法对冬小麦冠层高光谱特征参数寻优,利用最小二乘SVM预测冬小麦叶绿素含量,为后续施肥管理提供依据。经验统计回归模型更多应用在研究光谱植被指数和作物的生理化参数的关系中,董超等[21]通过无人机采集冬小麦多光谱影像数据获得6种植被指数,建立小麦冠层SPAD值的线性、二阶多项式、对数、指数和幂函数模型,反演冬小麦不同施氮水平的状况。高林等[22]利用大豆的多光谱和高光谱数据获取5种植被指数,结合地面实测LAI构建线性、对数、幂、指数、二次多项式等回归模型,为精准农业研究提供理论研究。本研究通过无人机遥感系统采集的水稻冠层高光谱图像数据,对比分析MFD、LI、PF、LE、IG、LAG共6种算法从高光谱反射率数据中获取的REP,然后使用5种统计回归方法(线性回归、对数曲线回归、乘幂曲线回归、指数曲线回归、二次多项式回归)和两种机器学习方法(BPNN、ELM)量化不同REP与水稻叶绿素含量之间的关系,从而建立能够监测水稻冠层叶绿素含量的反演模型,研究结果将有助于建立水稻田大规模的监测技术,为水稻叶绿素的无损、快捷、大规模诊断提供依据。
1 材料与方法
1.1 试验设计
试验于2019~2020年6~9月进行,地点在沈阳农业大学北方粳型超级稻成果转化基地(118°53′E,38°43′N,平均海拔40m),试验设计4个施氮水平:N0对照(0kg·hm-2)、N1(150kg·hm-2)、N2(240kg·hm-2)、N3(330kg·hm-2);2019年种植5个粳稻品种:V1(399)、V2(盐丰47)、V3(桥润粳)、V4(美丰稻)、V5(盐粳糯66),共20个小区;2020年种植V1-V3和V5,4个粳稻品种,2019年小区分布图如图1。

图1 水稻试验小区分布图Figure 1 Distribution of rice plots
1.2 数据采集
1.2.1 无人机高光谱图像采集 无人机采用深圳大疆创新公司M600 PRO六旋翼无人机,搭载四川双利合浦公司GaiaSky内置推扫式机载高光谱成像系统采集高光谱图像,高光谱成像传感器采集的波段范围为400~1000nm,采样间隔为0.45nm,在400~1000nm的光谱范围内产生1345个波段。去除了光谱上下边界上的两个波段,得有效波段1343个。无人机高光谱成像系统如图2。

图2 无人机高光谱成像系统Figure 2 Hyperspectral imaging system of UAV
在数据采集过程中,高光谱图像的采集时间选定每次试验11∶00至12∶00之间进行。数据采集时间为晴天或多云天气(云量小于20%),太阳光强度相对稳定。无人机飞行高度为50m,一幅高光谱场景图像对应的覆盖面积为400m2。所有的高光谱图像都是在水稻生育期获得的。利用ENVI5.3+IDL软件对采集到的高光谱数据进行处理和提取。在处理过程中,首先采用光谱角度映射器(SAM)去除噪声,通过计算每个感兴趣区域的平均光谱,得到每个试验小区的高光谱信息。
水稻田间冠层数据获取试验时间范围主要涵盖水稻生长中的分蘖期、拔节期和孕穗期3个时期。人工地面采集数据作为无人机高光谱数据的地面真值,采集时间与高光谱图像数据采集时间同步。在每个试验小区中间长势均匀区域随机选取4穴水稻作为该小区的样本点。共有效采集240份水稻样品,每份样品取50片冠层叶片放入密封袋中,储存在温度约为4℃的移动冰室中。使用手持差分GPS装置RTK测量采样点的地理坐标信息,无人机高光谱成像系统获取的高光谱遥感图像包含每个像素的GPS信息,将地面数据一一对应到HSI数据中具有相同GPS坐标的像素。采用移动平均滤波器(moving average filter)对试验小区获取的400~800nm的反射率光谱数据进行降噪平滑处理(滤波系数为0.2),降低噪声对叶绿素含量反演精度的影响,处理后水稻冠层高光谱曲线如图3。

图3 高光谱反射率平滑降噪处理Figure 3 Hyperspectral reflectance smoothing and noise reduction
1.2.2 叶片叶绿素含量测定与高光谱 将水稻样品送回
实验室后,从样品中选出充分展开的叶片,剪碎后相互混合均匀,称取0.4g置于200mL混合溶液中,混合溶液由体积比9∶9∶2的丙酮、乙醇和蒸馏水3种溶液配置而成。将含叶混合物的溶液在实验室遮光环境温度约为20℃下静置,待叶样品呈全白色后,利用分光光度计进行比色,分别测定D663nm和D645nm,按式(1)计算水稻样品的叶绿素含量(Chl)[23-24]。
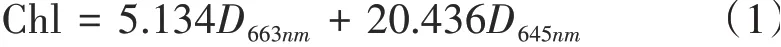
本研究进行6次试验数据采集,共收集有效数据样本230个。在数据集的划分中采用5折划分方法,将数据划为5等分,选择1个分区作为测试集,剩下的4个分区作为训练集,因此训练集和测试集共有5组(图4),表1显示了其中一组的数据统计特征。
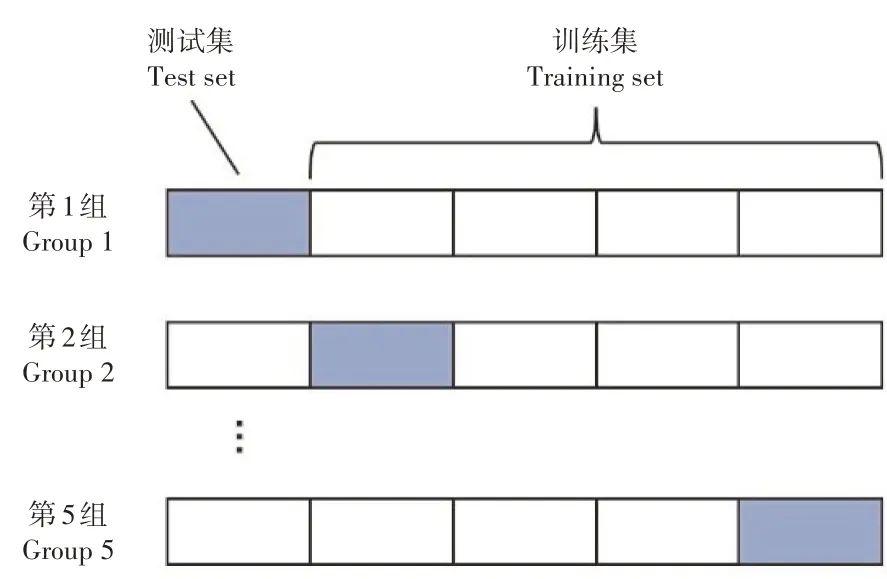
图4 数据5折划分Figure 4 Data partition in 5 fold
由表1可知,除样本量外,训练集和测试集具有相似的统计特性。另外,变异系数大于50%,说明叶绿素含量数据具有较高的离散性。在叶绿素含量整体样本中,其最大值和最小值分别为99.70mg·L-1和2.60mg·L-1,其变幅计算为97.10mg·L-1,样本的叶绿素含量变异系数为50.83%,均值为53.197mg·L-1,标准差为27.04,根据Lilliefors检验[25],p=0.4032>0.05,显著性概率值说明该叶绿素样本数据符合正态分布,满足叶绿素含量的反演要求。

表1 水稻叶片叶绿素含量统计结果Table 1 A statistical table of chlorophyll content in rice leave
1.3 红边位置(REP)提取方法
1.3.1 最大一阶导数法(MFD)在最大一阶导数法[9]中,REP由反射光谱在红边区域的最大一阶导数对应的波长来确定。利用反射光谱的一阶差分变换计算一阶导数,即:

式中:FDR为在波长i处的光谱反射率的一阶导数值,i位于波长为j和j+1之间的中点;Rλ(j)和Rλ(j+1)分别为波长为j与j+1处的光谱反射率;Δλ为波长为j和j+1之间的差值。
1.3.2 线性四点插值法(LI) 线性四点插值法[10]将红边处的反射率曲线简化为一条直线,利用波长为670nm和780nm的反射率确定拐点处反射率,700nm和740nm处的反射率通过线性插值来估计拐点波长。它仅使用4个波段(670,700,740,780nm)通过两步简单的计算来确定REP。
计算拐点处的反射率(Rre):

式中:R为光谱反射率。
计算红边波长即红边位:

1.3.3 线性外推法(LE)线性外推法[11]计算REP为一阶导数远红外区(680~700nm)和近红外区(725~760nm)光谱外推的两条直线交点所对应的波。
远红外直线(Far-red line):

近红外直线(NIR line):

式中:m和c为直线的斜率和截距。在交点处,这两条直线有相等的λ(波长)和FDR值。因此,REP即交点处的λ值,可表示为:

线性外推法利用4个波段来计算REP,其中2个固定波段:680nm和760nm(表示红边区域的上下界),通过使用远红外与近红外区域的不同波段组合得到的REPs与叶绿素含量的相关性强度来确定另外2个波段。
1.3.4 多项式拟合法(PF)多项式拟合法[12]是利用5次多项式函最小二乘拟合到对应于红边区域反射率的波长之间的反射光谱。

式中:λ为从670~780nm中连续的249个波段。REP由近似源谱的函数的最大一阶导数来确定的,一阶导数利用一阶差分变换计算得出。
1.3.5 倒高斯模型(IG) 红边反射率的光谱形状近似于倒高斯函数的一半。因此,使用倒高斯模型[13]来拟合红边区域的反射率,反射率方程表示为:

式中:Rs为近红外区光谱反射率最大值;R0为红光区光谱反射率最小值;λ为波长;λp和σ分别为光谱参数和高斯模型偏差系数,REP由这两个参数确定。

式中:λp和σ可利用线性拟合法计算出,式(3)可变换为:

式中:B()
λ为关于λ的线性方程,因此通过线性回归可计算出与倒高斯模型两个参数相关的最佳拟合系数a0和a1,λp和σ可表示为:

1.3.6 拉格朗日插值法(LAG)拉格朗日插值法[14]利用光谱反射率的最大一阶导数对应的波长以及相邻的两个波段进行插值计算得到REP。
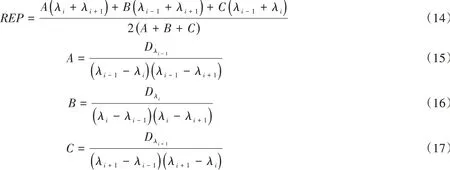
式中:Dλ为波长λ的光谱反射率的一阶导数值;λi为最大一阶导数对应的波长;λi+1和λi-1为相邻上下的两个波段。
1.4 叶绿素反演模型的建立与评价
本研究利用6种红边位置提取方法,从水稻冠层高光谱反射率数据中获取REP作为反演模型的输入,对于反演模型的建立使用5种统计回归算法(线性回归、对数曲线回归、乘幂曲线回归、指数曲线回归和二次多项式回归),以及两种非线性的机器学习方法[反向传播神经网络(BPNN)和极限学习机(ELM)]。
反向传播神经网络(BPNN)属于一种前馈网络,具有自学习和自适应的优点[26-27]。BPNN基于梯度下降策略,根据实际输出值和目标输出值之间的误差进行参数调整。训练是通过在每个循环结束时反复更新权值来进行的,直到所有训练样本的平均平方和误差最小化,并且在指定的误差范围内。更多细节可以参考[28]。BP NN结构为1-10-1,即输入层和输出层为1个神经元,隐含层的神经元个数为10,设定学习速率为0.01,最大确认失败次数为6,最小性能梯度为10-6,最大训练次数为1000次。
极限学习机(ELM)[29]是一种新型的单隐含层前馈神经网络,它与传统的单隐含层前馈神经网络相比,能够有效克服传统神经网络因采用梯度下降法进行训练而导致陷入局部极值的缺点,并且具有处理速度快、泛化能力强、易于实现等优点[30]。ELM输入层和隐含层的连接权值、隐含层的阈值可以随机设定,且设定完后不再调整,而BPNN在训练过程中需要不断反向去调整权值和阈值,ELM在保证学习精度的前提下,比BPNN学习算法速度更快、泛化能力更强。
对于模型的评价,使用五折交叉验证法:5组测试集的决定系数(R2)、均方根误差(RMSE)、绝对误差(MAE)的各均值作为模型的评价参数,3种参数的计算公式为:

式中:y^i、yi和yˉ分别为水稻叶绿素含量的预测值、观测值、平均值;n为样本的数量。通过比较不同模型的评价参数,最终选择最佳的水稻冠层叶绿素反演模型。
2 结果与分析
2.1 水稻光谱红边区及红边位置分析
在230个叶绿素(Chl)含量样本中,将叶绿素含量按从小到大顺序排列,选取第1~76个叶绿素样本对应的47条光谱反射率曲线求平均得到的一条光谱曲线作为低Chl含量光谱,同理分别将第77~153和第153~230的叶绿素样本对应的光谱反射率曲线计算得到中、高Chl含量光谱,3种水平的叶绿素平均含量分别为90.1612,53.5189,15.3215mg·L-1,其对应的光谱反射率在红边光谱区(680~780nm)变化曲线如图5。在704~780nm可以观察到相比于低、中Chl含量光谱,高Chl含量光谱表现出更低的反射率,原因是叶绿素含量越高,吸收的红光越多[20]。
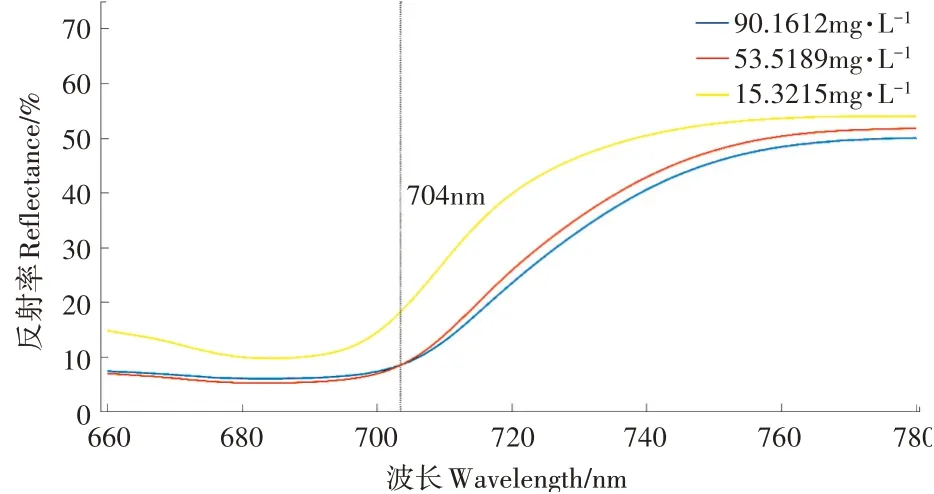
图5 不同叶绿素含量下的光谱红边区反射率Figure 5 Reflectance of the red edge region of the spectral under different chlorophyll contents
低、中、高Chl含量光谱曲线的一阶导数值由光谱反射率的数值梯度与光谱波长的数值梯度的比值计算得到,在红边光谱区(680~780nm)变化曲线如图6。在波段685~714nm区,3种Chl含量水平的光谱反射率明显上升,叶绿素含量越低,反射率上升程度越高,这是因为叶片内部散射增加的原因[20]。
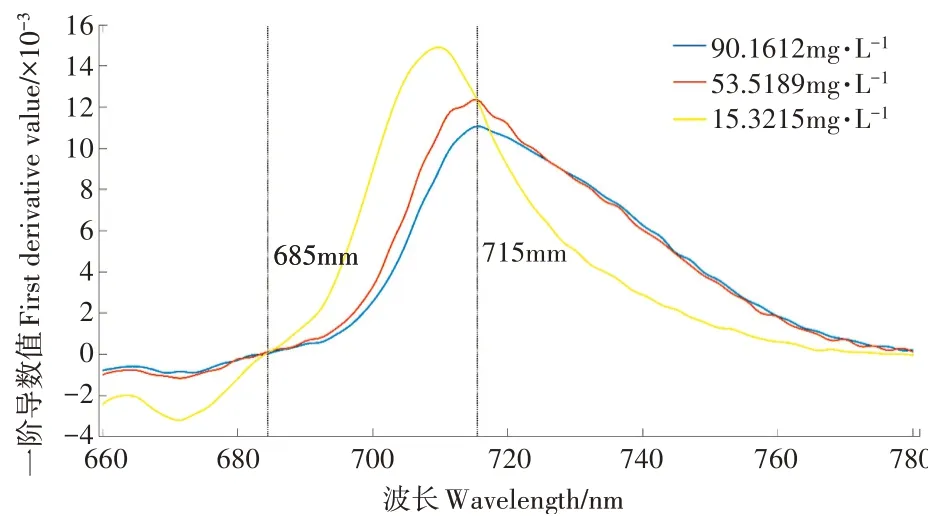
图6 不同叶绿素含量下的光谱红边区反射率的一阶导数值Figure 6 The first derivative value of the reflectance in the red edge region of the spectrum under different chlorophyll content
6种不同的方法所提取红边位置的频率直方图如图7,相关的统计信息如表2。可以看出MFD所提取的红边位置主要分布在700~730nm,而LAG所提取的红边位置分布与其类似,并且统计参数也相接近,这是因为LAG是基于MFD利用一阶导数最大值对应波段与其相邻的波段进行内插;LI提取的红边位置变幅较大,主要分布在700~750nm,LE提取的红边位置涵盖了红边区域,经过检验,两种方法提取的红边位置都符合正态分布,p分别为0.46和0.50,并且LI和LE所提取的红边位置与水稻叶绿素含量皮尔逊相关系数高于其他4种方法,分别为0.71和0.70。LE中除固定的两个波段外,另两个波段由远红外和近红外内不同的波段组合得到,不同组合波段下通过LE提取红边位置,计算其与水稻叶绿素数据的皮尔逊相关系数最大值来确定最优的波段组合,图8为不同波段组合下计算得到的皮尔逊相关系数图,可以看出在近红外远红外691~700nm和731~760nm下的波段组合得到的相关系数值较大,最大值对应的横纵坐标即对应所求的2个波段,分别为699.5nm和731nm,波段的组合会因不同作物的和光谱反射率的变化而改变,应根据作物的改变去寻找更为适合的组合波段[18]。PF提取的红边位置主要集中分布在720nm附近,部分分布于780nm,皮尔逊相关系数最小,为0.28;PF与MFD的原理相似,都是寻通过找红边区域反射率的最大一阶导数值对应的波段确定红边位置,不过PF的红边区域反射率是由五次多项式拟合原反射光谱得到,目的是为了减少一阶导数不连续性的影响,而分布在780nm附近的红边位置是由于所拟合的部分多项式函数在770~780nm出现极值。IG所提取的红边位置值主要分布在715~730nm,标准差最小,为3.58。6种方法提取的红边位置的均值都接近720nm,LI和LE所提取的红边位置与水稻叶绿素数据的相关性高于其他4种方法;其中PF提取的红边位置过于集中,在730~770nm出现不连续,且与叶绿素的相关性低。

图7 6种不同方法提取红边位置的频率统计直方图Figure 7 Frequency statistical histograms of red edge locations from 6 methods

表2 6种不同方法提取红边位置统计Table 2 The statistics of red edge position from 6 method
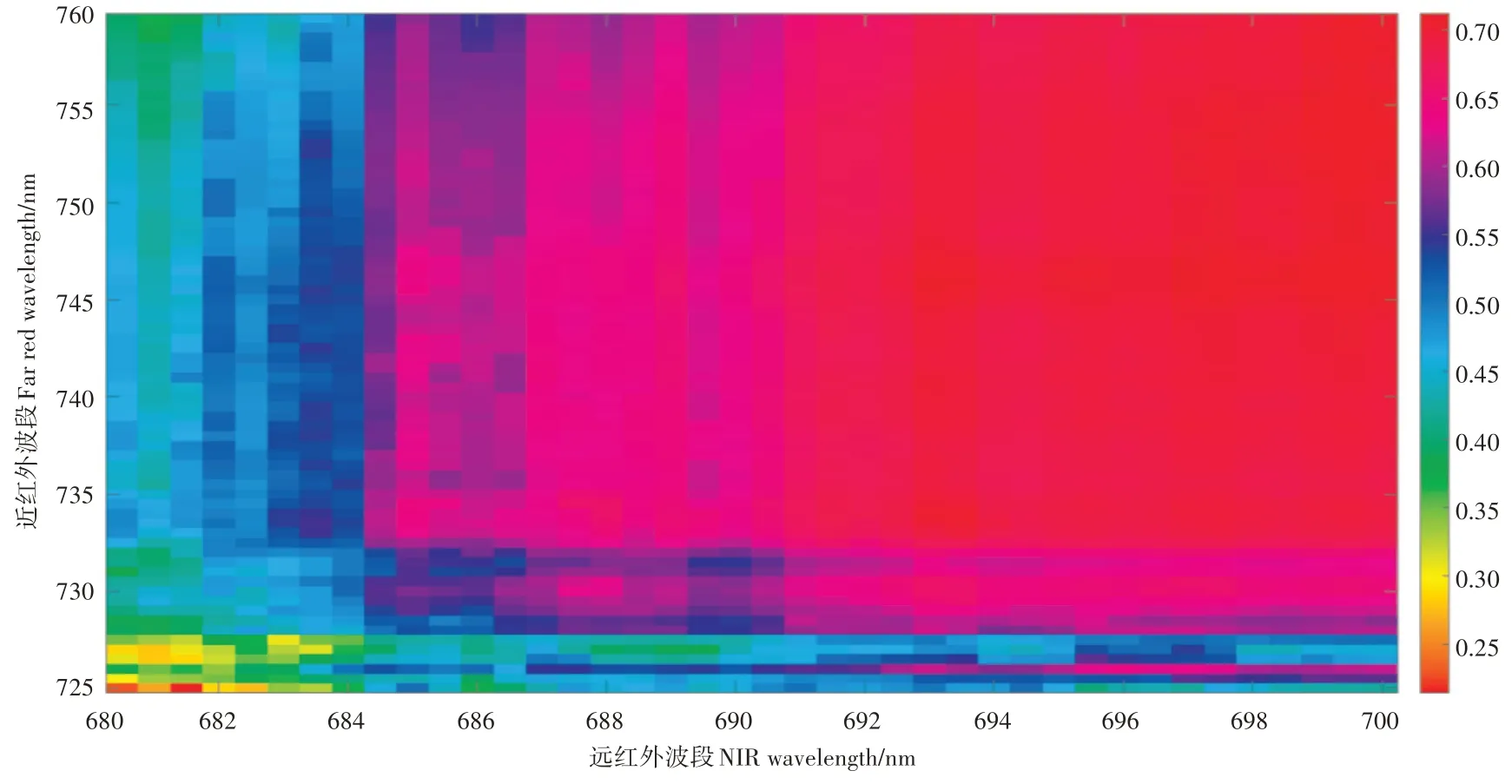
图8 LE不同组合波段与叶绿素含量相关性系数图Figure 8 Diagram of correlation coefficient of different LE combination bands and chlorophyll concentrations
2.2 基于红边位置的水稻冠层叶绿素含量监测模型的检验
2.2.1 统计回归模型结果 对6种红边位置提取算法分别建立线性模型、对数曲线模型、乘幂曲线模型、指数曲线模型和二次多项式模型,各模型的评价参数以及p值如表3。

表3 基于统计回归方法的叶绿素含量反演模型信息Table 3 Chlorophyll inversion model information for different statistical regressions
可以看出LE-对数曲线模型精度最高,测试集R2、RMSE、MAE的均值分别达到0.763,9.249,11.253,p=0.016<5%,具有95%的置信区间(CI)的回归系数,LE方法提取的REP和叶绿素含量存在显著对数回归关系;其次是LI-线性模型,测试集R2、RMSE、MAE的均值分别达到0.695,10.106,11.237,p_value=0.032<5%,LI方法提取的REP和叶绿素含量同样存在显著线性回归关系。整体来看,相同提取REP技术下的线性模型、对数曲线模型以及二次多项式模型更优于乘幂曲线模型和指数曲线模型,R2值都高于后两者,乘幂曲线模型、指数曲线模型的R2值偏小,均低于0.35,RMSE和MAE值偏大,该类模型不能够很好的解释REP和叶绿素的关系。在6种REP提取算法中,由LI和LE所提取的REP相比其余4种方法更能反映叶绿素含量关系,相同统计回归算法下所建立的模型的性能优于后者。
基于不同技术提取的REP不同模型,由表3可知,除指数模型外在红边波段皆是增函数,可以说明的是与叶绿素含量较低相比,较高叶绿素含量的REP会向较长波长移动,即红移,另外基于LI的线性回归结果说明该方法提取的REP与叶绿素含量存在一定的线性关系,这与ANSAR等[16]研究发现一致。LE-对数曲线模型和LI-线性模型可以满足水稻叶绿素的诊断,两者都是利用四个相应的波段计算求出红边位置,对于LE-对数曲线模型,REP由4个波段(680,699.5,731,760nm)外推的两条直线的交点所确定,其中699.5nm和731nm这两个波段由红边内的波段组合和叶绿素含量的最大相关系数确定,而对于LI-线性模型,只需4个波段(670,780,740,780nm)的反射率通过简单的两步计算[式(3)和式(4)]来直接计算得出红边位置。
2.2.2 机器学习建模方法结果 在机器学习建模方法中,同样利用六种红边位置作为模型输入量,BPNN和ELM的模型参数结果如表4。可以看出,以LI和LE方法提取的红边位置,在两种模型中表现优于其他4种REP提取方法,这与回归建模的结果一致,LE-ELM模型测试集R2、RMSE、MAE的均值分别达到0.781,8.375,9.828,LI-ELM模型测试集R2、RMSE、MAE的均值分别达到0.702,9.794,9.339。两种建模方法比较,ELM模型的预测精度优于BPNN模型,并且由于ELM的特定超参数随机设定后不再调整,使其学习速度更快。PF和IG方法提取的红边位置在两种建模方法中的精度最低,该两种红边位置不能够很好地反演叶绿素含量的。值得注意的是机器学习算法在叶绿素反演中更优于回归算法,这是因为机器学习算法通过牺牲可解释性来获得更高的预测能力。

表4 反向传播神经网络和极限学习机的叶绿素含量反演模型信息Table 4 BPNN and ELM chlorophyll content inversion model information
3 讨论与结论
本研究利用无人机采集的水稻冠层高光谱数据,建立了估算水稻叶绿素含量的反演模型,能够对水稻叶绿素含量进行快速准确的监测。为此,比较了6种常用的红边位置(REP)提取算法,对从高光谱反射率中提取的REP进行分析和比较。其次,利用5种统计回归方法(线性回归、对数曲线回归、乘幂曲线回归、指数曲线回归、二次多项式回归)和两种机器学习方法(BPNN、ELM),研究红边位置与地面所测量的水稻叶绿素含量的关系,最终选取基于红边位置水稻叶绿素含量的最佳反演模型。
水稻冠层叶绿素含量高光谱红边特性分析结果表明,红边区域(680~727nm)观察到水稻冠层表现出更敏感的光谱响应:低叶绿素含量的近红外光谱区(660~727nm)反射率较高、高叶绿素含量的REP出现红移。水稻叶绿素含量统计回归模型结果表明,LE-对数曲线模型表现出良好的叶绿素预测性能,测试集R2、RMSE、MAE均值分别达到0.763,9.249,11.253,构成波段组合的另2个波段为699.5nm和731nm,REP分布范围涵盖红边区域(660~780nm),该模型能够较准确反演水稻叶绿素含量。LI-线性模型模型测试集R2、RMSE、MAE均值分别达到0.695,10.106,11.237,该方法计算简单,可为水稻叶绿素检测仪的开发提供理论依据。水稻叶绿素含量机器学习反演模型中,以LI和LE所提取的红边位置作为特征输入,相比与其他4种REP提取方法表现出更好的预测效果,在BPNN模型中,以LE提取的REP作为模型输入,测试集R2、RMSE、MAE均值分别为0.699,10.818,10.427。对于ELM模型,其中LE-ELM模型和LI-ELM模型的测试集R2、RMSE、MAE均值分别为0.781和0.702,8.375和9.794,9.828和9.339,满足对水稻叶绿素含量的反演要求,LE-ELM模型在所有模型中,其预测精度最高,能够有效准确地评估水稻叶绿素含量。与BPNN算法相比,ELM有着预定义的网络架构,不需要手动调整参数,有更快的学习速度、更高的泛化性能。
猜你喜欢
ELLE世界时装之苑(2024年5期)2024-05-14 09:45:39
印制电路信息(2022年11期)2022-11-30 03:40:58
海洋通报(2022年4期)2022-10-10 07:40:26
光谱学与光谱分析(2022年4期)2022-04-06 03:44:38
阅读(科学探秘)(2020年8期)2020-11-06 06:22:48
中国果业信息(2019年1期)2019-01-05 17:41:42
生物学教学(2017年9期)2017-08-20 13:22:32
电子器件(2017年2期)2017-04-25 08:58:37
高师理科学刊(2016年8期)2016-06-15 20:27:45
西藏科技(2015年4期)2015-09-26 12:12:58
