
结合通道注意力的特征融合多人姿态估计算法
2021-02-04 13:51黄晨,高岩
小型微型计算机系统 2021年1期
黄 晨,高 岩
1(华东师范大学 软件工程学院,上海 200333) 2(华东师范大学 计算机学院,上海 200333)
1 引 言
人体动作识别作为人类行为智能分析领域一项基础而困难的任务在智能监控系统、人机交互[1]、游戏控制和智能机器人等多个领域具有广泛的应用.人体动作识别就是借助摄像头或其他传感器设备,在复杂背景、不同人群的前提下对人体做出的动作进行快速、准确的识别,而人体姿态估计是人体动作识别的基础.因此,对人体姿态估计方法进行研究具有十分重要的现实意义.
人体姿态估计[2]是将检测到的如颈,肘和膝等人体关键点联系以对人体姿态进行估计.近年来,随着深度学习方法的流行,产生了许多基于单人姿态估计的研究成果,CMU的Yaser Sheikh研究小组提出了卷积姿态网络[3](Convolutional Pose Ma-chine,CPM),首次对人体骨架关键点信息显式建模,通过输出热力图(Heatmap)按Channel寻找最大响应点.同时,由于行人检测算法的提升,出现了如Faster RCNN[4],YOLO[5]等许多优秀的检测模型,使得多人姿态估计算法的研究成为主流.按照实现流程的不同,可将多人姿态估计算法分为自底向上(Bottom-Up)和自顶向下(Top-Down)两类算法.Bottom-Up类方法是先检测所有关键点再将关键点按照所属人体目标进行组装,最有代表性的当属2016年COCO比赛冠军-OpenPose.OpenPose[6]是基于CPM组件来搜索图像中所有骨架关键点的位置,并采用肢体亲和场(Part Affinity Fields,PAF)方法对关键点进行组装.Top-Down类方法是先进行人体目标检测,然后将截取的目标分别进行单人姿态估计.旷视科技提出了CPN网络[7],其是一种由粗到细(Coarse-to-Fine)的网络结构,充分利用了单人上下文信息.相比Bottom-up类方法,Top-Down类方法有两点优势:1)对人体目标检测的召回率更好;2)基于单人目标进行姿态估计时的关键点准确度更高,但是在人数较多的时候,Top-Down速度上会处于劣势,这就需要采用更轻便,高效的人体目标检测器来提升检测速度.
本文提出了一种Mobile-YOLOv3人体检测器和多尺度融合网络相结合的Top-Down类多人姿态估计算法.首先,采用Mobile-YOLOv3作为人体检测器,将原YOLOv3模型主干网络中的常规卷积结构替换为深度可分离卷积结构(Depth-wise Separable Convolutions)以提升人体目标检测速度.然后以经典U型网络为基础,嵌入了基于通道注意力机制的多尺度特征融合模块,对融合后的关键特征通道信息进行筛选,提高了姿态估计准确度.最后在COCO数据集上的试验结果验证了文中多人姿态估计算法的有效性和优越性.
2 编码-解码U型网络
编码-解码U型网络[8]包含图像下采样编码和上采样解码两个阶段,根据输出层和损失函数的不同,可分别用于语义分割,人体姿态估计等图像任务上,网络模型如图1所示.
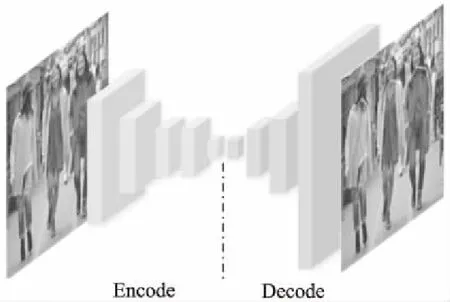
图1 编码-解码U型网络结构Fig.1 Coding and decoding U-shaped network structure
下采样编码阶段是通过连续的堆叠池化层或步长大于1的卷积层来实现图像特征的提取,越靠近底部的特征尺度越小,语义信息越丰富.像素级图像任务需要网络的输出结果接近于原图尺度,于是在经过下采样特征提取之后需要进一步对特征进行上采样解码,常用的上采样基础模块有插值法[9]和反卷积.
文献[10]提出用于人体姿态估计的堆叠沙漏网络(Stacked hourglass Network,SHN),其是由一系列称为“沙漏(Hourglass)”的基础网络结构堆叠而成,沙漏结构实质上也是一种U型网络,最低得到4×4的尺度.下采样采用的是卷积串联Max-Pooling的模式,上采样采用最近邻插值结合跨层连接,其结构如图2所示.

图2 沙漏模块结构Fig.2 Hourglass module structure
为了避免梯度下降时出现梯度消失的问题,SHN网络在训练过程中采用了中间监督(Intermediate Supervision)方法,每个沙漏结构在训练过程中的输出结果都会与训练集标注的关键点热力图计算均方误差,网络总损失即为所有沙漏输出的均方误差之和.在推理阶段则直接使用最后一个沙漏结构的输出作为最终网络预测结果.
本文提出的姿态估计网络的基础结构同属于U型网络,再采用多阶段不断堆叠基础模块的方式形成粗到细(Coarse-to-Fine)的完整网络结构.
3 多人姿态估计模型
本文提出的自顶向下多人姿态估计模型包括人体目标检测和姿态估计两部分,整体流程如图3所示.

图3 自顶向下方法流程Fig.3 Top-down method flow
首先对YOLOv3目标检测模型进行改进,将原YOLO v3模型主干网络中的常规卷积结构替换为深度可分离卷积结构以提升人体目标检测速度,并减少输出通道数,在专业行人检测数据集上进行重训练.其次,提出的姿态估计模型中设计了基于通道注意力机制的多尺度融合模块,高分辨率特征学习肢体关键点位置信息,低尺度特征学习肢体连接关系,改进了常规U型网络中只有同尺度上通道互连的缺点,进一步提高了姿态估计准确率.
3.1 Mobile-YOLOv3模型
图像卷积操作是深度学习中图像处理算法的(Convolutional Neural Networks,CNN)的基础,通过卷积核的滑动,提取出整张图片的特征.常规卷积过程在特征通道数过大情况下,卷积核的参数数量会非常庞大,从而计算效率较低.
不同于常规卷积中每个卷积核对图片各通道同时进行操作,深度可分离卷积(Depth wise Separable Convolution)是采用不同卷积核对多通道图片中的不同通道分别进行卷积,整个卷积操作分解为分离卷积过程和点卷积过程两步进行.假设有通道数为C的W×H×C的图片,卷积核3×3 (设Pad=1,Stride=1),通过分离卷积操作分别得到每个通道的特征图(Feature Map).
常规卷积过程的参数和深度可分离卷积过程的参数量分别如式(1)和式(2)所示:
P1=3×3×C×K
(1)
P2=3×3×C+1×1×K
(2)
常规卷积过程和深度可分离卷积过程的乘法运算量分别如式(3)和式(4)所示:
C1=H×W×C×K×3×3
(3)
C2=H×W×C×3×3+H×W×C×K
(4)
通过对比式(1)和式(2),式(3)和式(4),深度可分离卷积过程不论是在参数量还是乘法运算量上都远远小于常规卷积过程,故采用深度可分离卷积结构有利于网络模型的轻量化,对后续人体关键点检测速度的提高具有很大的提升作用.
YOLOv3[11]人体目标检测算法在保证检测精度的同时,检测速度相比于其它深度学习目标检测算法有了非常大的提升.文中为了进一步提高人体目标检测的速度,将2.1节介绍的深度可分离卷积过程应用到YOLOv3模型中,将Darknet-53结构中的常规卷积层替换为深度可分离卷积层,以减少网络模型的计算量.
3.2 通道注意力的多尺度融合网络
姿态估计网络中不同尺度的特征信息都有重要意义,其中高分辨率的特征信息较好的保留了局部信息,用于姿态关键点位置的检测;低尺度的特征信息则包含整个目标的全局信息,能够推理关键点之间的连接关系.
在网络中引入多尺度融合模块将高分辨率表征信息和低尺度提取的语义特征信息在通道维度上进行融合,使低尺度特征图上也能获得高分辨率局部信息,而高分辨率特征也能融合全局推理信息.高、中、低3种不同尺度输入的融合结构图如图4 所示.

图4 多尺度合并与通道注意力融合模块结构Fig.4 Module structure of multi scale merging and channel attention fusion
图4中,整个融合模块分为多尺度合并和通道注意力融合两个阶段,第一阶段是不同尺度的特征在Channel维度上的合并,融合时的下采样模块采用的是步长为2的3×3卷积核,上采样模块是采用最近邻插值方法.
融合特征的不同Channel对该尺度检测的重要性不同,故在多尺度合并之后引入通道域注意力机制(Channel-Wise Attention),使模型可以学习不同Channel特征的重要程度.
深度学习中的注意力机制来源于人类视觉中注意力特点,即人类可以专注于观察某一事物,而忽略无关对象[12].通道注意力本质上是建立显式模型来重新定义Channel间的关系,即对不同Channel进行特征重标定,加强有用信息而弱化无关信息.
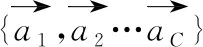
(5)

(6)
目标函数Ls模型参数θ的梯度如式(7)所示:
(7)
为了增强对输入向量的非线性表达能力,整个通道注意力机制的聚合过程可以分为3个步骤.首先,通过全局池化层将特征图提取出包含各通道全局信息的1×1×C特征向量,如式(8)所示:
(8)
其中,W、H和C分别为特征图的长、宽和通道数,fc为特征图每个格点的值.
然后,利用全连接操作对全局池化层得到的特征向量进行缩放,参数优化完后再通过全连接层恢复维度,对应输入向量的权重,如式(9)所示:
s=σ(ω1δ(ω2g))
(9)
其中,ω1和ω2为全连接层权重,σ为ReLU激活函数.δ为Sigmoid激活函数.
最后,将经过两个全连接层得到的权重乘回输入向量中,得到该尺度下融合之后的结果.
由SHN网络结构启发,文中完整姿态估计网络采用分阶段堆叠多尺度融合模块的方式.从输入到输出分为3个阶段,各个阶段内网络特征的尺度数目呈依次增加的形式,如第1阶段只有2种尺度特征,第2阶段包含3种尺度,依次递增直到最后第3阶段包含4种尺度.从上往下特征图的尺度依次减半,通道数倍增,如图5所示.

图5 完整姿态估计网络结构Fig.5 Complete network structure of pose estimation
考虑到骨架网络不需要单位像素级精细度的要求,最后输出层的特征维度为输入尺寸的4倍下采样,通道数为17,对应COCO数据集的17个骨架关节点,每个通道上最大响应位置即为该关节点预测位置.
4 实验结果与分析
实验的硬件环境为i7-9700处理器,RTX2080Ti显卡.
4.1 人体目标检测实验
文中提出的自顶向下多人体姿态估计方法分为人体目标检测和姿态关键点估计两部分,文献[13]采用SSD-512作为人体目标检测器,相比于使用FasterRCNN,将姿态关键点估计精度提升了6.9%,可见高效的人体目标检测器对整个多人姿态估计方法至关重要.
将Mobile-YOLO v3模型在PascalVOC、COCO数据集上重新进行训练,最后在Caltech人体目标数据集上测试,为了进一步评估文中改进的人体检测器性能,与YOLOv3、tinyYOLOv3(YOLOv3轻量版,速度更快精度稍差)进行对比,评价行人检测器的指标有:
1)查准率(Precision):正确被检测出的目标数与总检测数之比.
2)召回率(Recall):正确被检测出的目标数与总有效目标数之比.

图6 人体目标检测器 P-R曲线Fig.6 P-R curve of human target detector
Precision-Recall是一组矛盾度量指标,将设定的检测阈值调低必将使得Precision升高,同时伴随Recall值下降.当设定多组不同阈值便可得到P-R曲线,所有检测模型均在同样数据集训练同样轮次,得到P-R曲线如图6所示.
P-R曲线下方面积即检测器的平均准确率AP值,显然曲线位置越高同样的召回率下查准率也越高,即意味着该检测模型的效果越好,从图中可以看出本文提出的Mobile-YOLOv3模型效果与原版YOLOv3模型效果十分接近.另外,由于人体目标检测只是人体姿态估计的一个预筛选环节,故对检测速度提出要求,不同检测器的权重大小、检测速度以及准确率如表1所示.

表1 人体目标检测器效率性能对比Table 1 Efficiency and performance comparison of human target detectors
从表1中可以看出,本文改进的检测模型采用深度可分离卷积层作为基本卷积结构,极大减小了卷积权重参数和运算量,相比原版YOLOv3模型精度有稍许下降,但网络推理检测时间仅为其5%,同时比同一速度量级的tinyYOLOv3在平均准确率上有19.2%的提升,综合性能最佳,可以为后续人体姿态关键点检测提供高精度的实时目标输入.
4.2 通道注意力的多尺度融合网络
采用COCO人体关键点数据集[14]来评估文中所提网络结构的性能,COCO数据集由超过200000张样本图片组成,包含250000个人体目标及17个标注的姿态关键点.先将检测到的人体目标图像裁剪缩放到488×288分辨率再输入网络,在训练过程中采用了如旋转、水平翻转等数据扩增方法,使用Adam方法更新网络参数,总共迭代训练20000轮,前10000轮的学习率设置为10-3,后续训练的学习率下降到10-4.
文中所提多人姿态估计方法在包含多人体目标图像上的关键点检测结果如图7所示.
从图7中可以看出,即使输入图像包含诸如多人物、非正常直立姿态以及模糊遮挡等情况,文中所提方法仍能较好的检测出人物姿态的关键点.姿态估计算法的定量度量方法是计算算法模型的平均准确度(Average Precision,AP)值,人体姿态估计的AP值是综合了不同关键点类型和人体大小尺寸的归一化结果,如对于膝盖一类的大范围关键点和眼睛一类的小范围关键点,相同绝对偏差计算得到的误差百分比将会有很大区别.

图7 多人姿态估计结果图Fig.7 Result pictures of multi-person pose estimation
关键点检测的准确度(Precision)计算如式(10)所示:
(10)
其中,TP为检测正确的目标数,FP为错误检测的目标数.
姿态关键点相似性指标OKS定义如式(11)所示:
(11)
其中,di为估计的关键点与真实关键点的欧氏距离,vi为该关键点是否遮挡的标志,s为目标尺寸,ki是每个关键点的乘积常数.AP为OKS分别取(0.55 0.6…0.9 0.95)值时所有准确度的平均值.
首先验证文中设计的通道注意力多尺度融合模块的性能,设置3种不同网络结构:不使用融合模块、仅使用多尺度合并、多尺度合并加上通道注意力融合.对3种网络分别进行训练,得到结果如表2所示.

表2 不同网络结构的结果Table 2 Results of different network structures
表2第2种结构为所示文献[15]的姿态估计模型,仅在最后特征输出阶段采用了基于注意力的融合方式,对估计结果的精度提升有限;第3种结构为HRNET[16]模型,该模型将不同尺度特征直接在通道维度上进行拼接,而本文模型在融合阶段加入了通道注意力机制,在全局语义信息中心突出了关键点的位置信息,网络运算量仅提升了约4.2%,姿态估计的AP值提升了1.1,有效提升了姿态估计准确度.
在不同输入分辨率下,与堆叠沙漏网络 (Stacked Hourglass Network,SHN)、级联金字塔网络 (Cascaded Pyramid Network,CPN)的比较如图8所示.

图8 不同输入分辨率对模型性能影响Fig.8 Effect of different input resolutions on model performance
从图8可以看出,相比其他姿态估计模型,本文所提模型在越低的输入分辨率上提升越明显,主要是由于文中模型的多分辨率融合网络结构使得任一子网络都能始终保留原始输入分辨率信息,从而丰富了局部特征提高了关键点检测准确度.
5 结束语
多人二维姿态估计是视频人体动作识别的关键技术.文中提出了一种Mobile-YOLOv3人体检测器和多尺度融合网络相结合的多人姿态估计算法.将原YOLOv3模型主干网络中的常规卷积结构替换为深度可分离卷积以提升人体目标检测速度.姿态估计模型中设计了基于通道注意力机制的多尺度融合模块,其中高分辨率特征学习肢体关键点位置信息,低尺度特征学习肢体连接关系,进一步提高了姿态估计准确率.试验结果表明:相比于SHN和CPN算法,本文提出的多人姿态估计模型在COCO数据集上姿态估计平均准确度在最高448×288分辨率时提高了4.7和3.7.
文中提出的姿态估计网络采用多阶段堆叠多尺度融合模块的方式进行搭建,结构设计灵活,文中采用3阶段网络结构时在速度与精度上取得了较好的效果.实际工程应用中,可根据任务需求增减网络阶段数,如在对精度要求不高的任务环境下(摔倒检测等大幅度体态改变),可采用2阶段网络结构以提高检测速度.
猜你喜欢
农业工程学报(2022年12期)2022-09-09
社会科学战线(2022年7期)2022-08-26
建材发展导向(2022年3期)2022-04-19
建材发展导向(2022年2期)2022-03-08
北京航空航天大学学报(2021年9期)2021-11-02
北京航空航天大学学报(2021年9期)2021-11-02
计算机系统应用(2021年9期)2021-10-11
广东教育·高中(2017年10期)2017-11-07
新高考·高一物理(2015年5期)2015-08-18
中国信息化周报(2015年1期)2015-04-09
