
基于可变形卷积神经网络的人体动作识别*
2021-02-03 04:08王雪娇
计算机工程与科学 2021年1期
王雪娇,智 敏
(内蒙古师范大学计算机科学技术学院,内蒙古 呼和浩特 010020)
1 引言
人体动作识别是计算机视觉领域中一个具有巨大潜力的研究方向,其在监控系统、智能家居和虚拟现实[1 - 4]等领域均具有重要的研究价值。与简单的图像识别不同,人体动作识别会受到许多因素的影响,例如背景杂乱、影像采集设备各异、人体动作数据库类别不足等。目前国内外常用的人体动作识别方法主要有传统机器学习方法和深度学习方法。
在传统人体动作识别方法中,广泛使用手动设计特征进行识别,例如HOG/HOF等[5]。文献[6]设计了一种新的动作识别方法,将得到的行为特征送入向量机中以训练模型。但是,传统方法在真实场景的数据集上的识别准确率不太高,也得不到很好的识别结果[7]。近些年,深度学习受到了人体动作识别领域的关注。卷积神经网络(CNN)是深度学习中常用的模型,通过对输入图像进行卷积池化等步骤,实现对图像的识别。2012年的Alex Net网络[8]将CNN结构变得更深。2015年提出的Inception v2网络[9]则是将CNN变得更宽。文献[10]将视频数据的时间和图像信息都送入CNN中,但双流网络的效果并不理想,而且消耗了大量的内存和训练时间。文献[11]为了提高微小动作的识别准确率提出了一种新的投影策略,将图像投影到多个笛卡尔平面,以保留更多行为信息。文献[12]将CNN的卷积核变成3D,在卷积核中加入了时间维度,提高了准确率,同时也增加了训练难度。文献[13]将CNN与长短期记忆网络(LSTM)相结合来提高识别的准确率。文献[14]提出了可变形的卷积神经网络DCN(Deformable Convolutional Networks),其与普通卷积网络相比有着更加灵活的位置形变能力。文献[15]将可变形部件模型DPM(Deformable Part Model)与CNN相结合,提高了行人检测的准确率。文献[16]为了学习图像中的不稳定卷积特征而对池化层进行了改进,实验验证结果较好。虽然卷积神经网络在图像识别时提高了准确率,但是在人体动作识别过程中,容易丢失前期特征信息。
综上所述,本文在可变形卷积神经网络(DCN)的基础上融合改进的DPM来进行人体动作识别,将传统机器学习与深度学习相结合,提高人体动作识别的准确率和检测速度。
2 可变形卷积神经网络
可变形卷积神经网络DCN提出通过可变形卷积和可变形感兴趣区域池化来提高卷积神经网络对几何形变的适应能力,这2种方法都是基于在卷积池化过程中对卷积核采样位置信息做更进一步不规则偏移的想法,偏移量均通过增加新模块得到,不需要额外的监督。可变形卷积即在普通卷积的采样位置添加一个偏移量。可变形池化是为候选感兴趣区域的每个bin位置添加一个偏移量,偏移量则是通过附加的一层全连接得到。新增模块后的可变形卷积神经网络仍旧可以使用标准反向传播算法进行训练。具体结构说明见4.1节。
普通卷积与可变形卷积的对比如图1所示。其中,卷积核大小均为3×3。图1a表示普通卷积,3×3卷积核为形似于矩形的9个点;图1b和图1c表示可变形卷积,在图1a的基础上加一个偏移量(箭头),图1b表示在可变形卷积中增加了偏移量(箭头指向点);图1c展示了可变形卷积可以翻转角度的特殊情况。

Figure 1 Traditional convolution and deformable convolution图1 普通卷积与可变形卷积的对比图
3 可变形部件模型
可变形部件模型(DPM)是一种基于人体部件的识别检测系统。识别人体动作的模型DPM由根滤波器、部件滤波器和滤波器之间的相对位置构成。一般情况下根滤波器的分辨率较低,部件滤波器的分辨率较高。假设每个目标都指定了模型中每个滤波器在特征金字塔中的位置, 用z=(t0,…,tm)表示DPM识别模型,其中,m为滤波器数量,可自行设定,ti=(xi,yi,li)表示第i个滤波器所在位置的坐标(xi,yi)和层数li。
总测试窗口的得分如式(1)所示:


(1)
其中
(dxi,dyi)=(xi,yi)-(2(x0,y0)+vi)
(2)

4 人体动作识别系统
4.1 可变形卷积网络结构
传统的卷积操作使用的卷积核均为固定的形状,一般为矩形,可变形卷积为每个卷积采样点增加了一个偏移量使卷积窗口根据感兴趣区域进行卷积,如图2所示。标准卷积在识别人体时窗口形状为规则矩形,而可变形卷积网络的窗口形状则可以根据物体实例进行变化。以卷积核为3×3大小的二维卷积举例,M表示有效感受野:
M={(-1,-1),(-1,0),…,(0,-1),(1,1)}
(3)
在输入特征图x上采样后,对每个采样点加上偏移量再与权重w相乘并求和。对于输出特征图上的位置P0,可变形卷积表示为:
(4)
其中,偏移量参数{ΔPn|n=1,…,N},N=|M|,Pn表示M中任一位置,ΔPn只是对输入层像素有一定的影响,并不影响权重w,所以w和ΔPn都需要进行训练。

Figure 2 Example comparison of normal convolution and deformable convolution图2 普通卷积和可变形卷积的实例对比
图3在普通卷积的基础上增加了一层卷积层,得到偏移量offset,也就是式(4)中的△Pn,产生的offset有横纵坐标2个方向。

Figure 3 Structure of deformable convolution图3 可变形卷积结构示意图
图3先通过一个增加的卷积层(conv)得到可变形卷积的偏移量offset,然后偏移量在卷积核中进行位移,完成可变形的卷积。其中x为输入特征图,y为输出特征图,感兴趣池化将特征图划分为k×k个bins(k是自由设定的参数,本文设为7),bin中第i行,第j列(0≤i,j≤k)的可变形感兴趣池化表示为:
(5)
其中,Q0是bin中左上角的点,Qn表示bin中的任一位置,nij表示bin中的像素数量,ΔQij为偏移量。可变形池化网络结构如图4所示。

Figure 4 Structure of deformable pool of interest图4 可变形感兴趣池化的结构示意图
特征图先经普通的感兴趣区域池化得到候选感兴趣区域,然后感兴趣区域经过新加的全连接层(fc)得到感兴趣区域的偏移量。
可变形卷积网络与普通卷积网络的输入输出相同,只是在训练中,新加的用于学习偏移量的卷积层和全连接层的权重被初始化为零。
4.2 改进的可变形部件模型
通过实验发现,随着部件滤波器的增加,虽然检测准确率提高了,但会导致运行速度变慢。本文为了提高实验效果,需要寻求部件滤波器个数与运行速度之间的平衡点。如图5所示,传统的DPM部件模型数为5个时,在自搜集的人体动作数据集上的准确率为83.75%,当部件滤波器数增加到8个时,准确率达到了95.67%,人体动作识别的精度提高了11%以上。但是,滤波器数达到8个以上时,准确率提升不再明显,也给实验带来了一定的计算难度。所以本文将DPM中的部件模型增加为8个[17]。
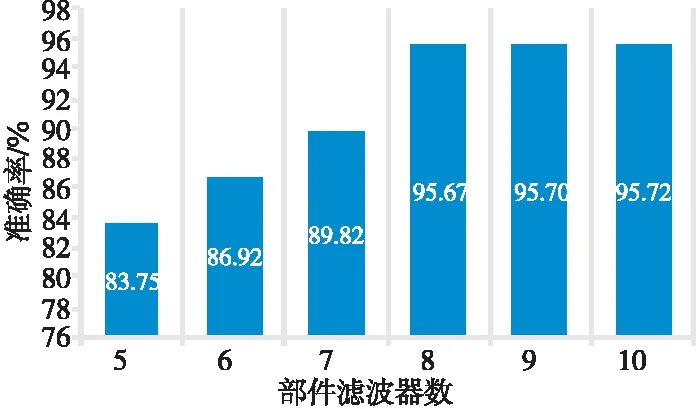
Figure 5 Relationship between component filter and experimental accuracy图5 部件滤波器和实验精度之间的关系
DPM在人体动作识别中常把人体分为5部分,分别为头、左上身、右上身、腿和脚。本文增加3个模型后变为头部、左肩部、右肩部、左腹部、右腹部、腿部和左右脚。改进的点是将原先的左上身进一步分为左肩和左腹;右上身分为右肩和右腹;脚部分为左右脚。细分之后的模型可以更准确地识别比较类似的动作,比如跑步和踢足球等。
为了解决DPM人为设计特征工作量过大的问题,本文在DPM模型中融入分支定界BB(Branch and Bound)算法来进行人体定位。分支表示将整个图像划分为若干个小区域,分别计算出每个分支在小区域内的得分值;定界是为每个区域设定最优解函数界限,并自动找出该区域内的最大值。BB算法得到的区域最大值可以作为识别人体动作的感兴趣区域。
传统的DPM识别人体动作大约需要的时间为11 s。融合BB算法并将滤波器个数增加为8个后,DPM检测速度提高了3倍左右,大概只需要3.8 s就可以得到结果。从实验数据看出,传统DPM需要的时间较长,结合BB算法后,能快速得到图像中的函数最大值,同时去除了大部分不可能的假设目标动作,从而有效地提高了检测速度。
改进的DPM识别人体动作的步骤如下所示:
步骤1提取特征。DPM采用方向梯度直方图(HOG)来进行特征提取。
步骤2DPM建模。式(1)为DPM的语义模型,而建模就是通过式(1)的语义模型来建立结构模型。DPM结构模型由一个根滤波器和几个部件滤波器组成。本文经过实验证明,将部件滤波器由5个增加为8个可以有效提高人体动作的检测准确率。
步骤3DPM模型训练。首先初始化根滤波器。在BB算法确定的感兴趣区域中用根模型扫描,将分数最高的确定为根滤波器的位置。然后初始化部件滤波器。根据部件滤波器与根滤波器的位置关系确定部件滤波器的位置,在确定了一个部件后再继续寻找下一个部件的位置,直到确定了所有部件滤波器的位置。最后不断地更新DPM,直到准确率提升小于0.01。
步骤4利用训练好的模型来对数据集中的动作进行识别和分类。
4.3 特征融合
本文提出可变形卷积神经网络和DPM模型的特征图实现对人体动作的分类。卷积神经网络虽然检测速度与精度都优于传统机器方法,但存在着低层特征提取准确率不高的问题。将改进的DPM与可变形卷积网络提取的特征图在可变形池化层之前进行融合,可以有效地提高卷积神经网络低层特征提取的精度,从而提高全局网络的识别准确率。本文系统的结构如图6所示,将预处理后的数据集分别输入到可变形卷积网络和改进的DPM模型中,可变形卷积网络得到候选感兴趣区域后融合DPM得到特征图,将融合后的特征图作为可变形感兴趣池化的输入,最后利用全连接层来判断动作的类别。
本文识别系统共有4个步骤:
步骤1利用改进的DPM获取人体部件。将数据集预处理后输入到网络中,DPM依次进行特征提取、建模和训练模型的步骤。DPM进行人体动作检测时应用BB算法可以在全局图上快速得到最优解,从而使DPM模型可以更快获得感兴趣区域。

Figure 6 Flowchart of the recognition system in this paper图6 本文识别系统流程图
步骤2可变形卷积网络提取特征。与可变形部件模型选用同样的数据集作为输入。先经过3个卷积块(包含普通卷积层和池化层)获得低层特征;然后将特征图通过2层可变形卷积块(包含普通卷积层、可变形卷积层和池化层)后输入区域建议网络RPN(Region Proposal Network)来获得候选感兴趣区域R。用反向传播算法对参数进行优化,同时也能防止过拟合。
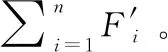
步骤4输入数据集中的训练集来对模型进行训练,之后分别将测试集和验证集数据输入训练好的模型得出实验结果。
5 实验与结果分析
5.1 实验环境和数据集
本文识别系统使用的硬件有NVIDIA GPU,操作系统为Windows 10。在PyCharm中结合TensorFlow来保证实验的运行。
本文选用了人体动作识别中主流的2个数据集:MPII数据集和MSCOCO Person Keypoints 2017数据集(以下简称MSCOCO数据集)。这2个数据集都是在不同的场景下收集的图像,场景包含许多复杂情况下的人体动作,比如拥挤、尺度变化、遮挡和旋转等,把MPII数据集中含有注释的帧分成多种动作类别,如跑步、滑雪和踢足球等,并用未加注释的帧作为测试集。对MSCOCO数据集也采用类似的预处理方法,MSCOCO数据集常见的动作类别有演讲、打网球、冲浪和做饭等在复杂场景下的动作。
5.2 实验训练过程和实验结果
网络的前向传播阶段,先用训练集作为样本输入设计好的模型中,图像从输入层逐层采样到输出层。网络的反向传播阶段,通过计算实际输出图像与原始图像的误差来更新权重,重复该过程直至误差小于预先设定的值。本文实验的损失函数为交叉熵函数。
实验准确率定义为:
(6)
其中,t为准确率,数据集中目标的动作类别为Ci,S为数据集中的场景数。
表1和表2分别是在MPII数据集和MSCOCO Person Keypoints 2017数据集上的实验结果。由于将传统方法与CNN结合的识别系统较少,所以对比实验主要选用了基于卷积神经网络的动作识别中表现较好的识别系统。

Table 1 Comparison of accuracy on MPII dataset表1 MPII数据集上准确率对比

Table 2 Comparison of accuracy on MSCOCO dataset表2 MSCOCO 数据集上准确率对比
文献[18,19]的识别系统都是在普通卷积上检测出人体后再识别动作,文献[19]的识别系统准确率提高是因为将CNN网络变得更深。文献[20]的识别系统则是利用普通卷积网络将人体关节点识别出后再分析人体的位置。本文也采用文献[18]的方式,但是将可变形卷积与改进的DPM结合来识别人体动作,从表1数据中看出本文识别系统准确率更高。此外,由于本文结合了BB算法,所以在运算速度上也有了较大的提升。相同实验条件下普通识别系统处理单幅图像需要1.43 s,而本文识别系统仅需0.2 s左右。
在MPII数据集上,选取了部分动作类别的混淆矩阵,如图7所示。由图7可以看出,本文识别系统对有明显特征的动作识别比较容易,比如跑步、踢足球等,但对复杂动作的识别稍微不足,比如瑜伽和跳舞就比跑步和踢足球更容易混淆,因为瑜伽动作种类繁多并且和跳舞有很多相似之处。

Figure 7 Confusion matrix on MPII dataset图7 MPII数据集混淆矩阵
由表2可以看出,本文识别系统在复杂场景下也有较好的实验效果,比全卷积网络[22]的准确率更高;文献[21]的识别系统虽然增加了人体上的追踪点,但效果却不太理想;多级堆叠沙漏网络[23]可以提取出更深层的特征,今后本文可以尝试与文献[23]的识别系统结合来获得深层信息。
图8为MSCOCO数据集中部分动作类别的混淆矩阵。MSCOCO中多为复杂的动作,所以准确率比MPII数据集上的准确率低。如图8所示,自拍和打电话一般都是相似的手持移动设备动作,比较容易混淆;吃饭和喝水一般为坐着的动作,也容易发生误检。但是,姿势不同的动作,例如自拍和做饭,本文识别系统的误检率可以低于1%甚至达到0。

Figure 8 Confusion matrix on MSCOCO dataset图8 MSCOCO数据集混淆矩阵
6 结束语
本文为了提高复杂场景下人体动作识别的准确率,提出了改进的DPM和可变形卷积网络结合的识别系统。融入了BB算法和增加了部件滤波器的DPM对人体动作识别的准确率较高,但计算量太大,使得检测速度变慢,而可变形卷积网络模型在低层特征提取时准确率较低,所以本文在DCN的基础上结合了传统识别算法DPM,提高了CNN特征提取准确率,也提高了人体动作识别的速度。但是,本文提出的识别系统在实际应用中还存在遮挡识别准确率低(如滑雪常被树木遮挡动作)和复杂动作的漏检误检等问题,今后将在可变形卷积网络中融入沙漏网络模型,利用堆叠沙漏网络模型中复用全身关节来提高单个关节的识别准确率,进一步提升人体动作识别的准确率。
猜你喜欢
地理空间信息(2022年3期)2022-04-01
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
制造技术与机床(2018年9期)2018-09-19
制造技术与机床(2017年7期)2018-01-19
测绘工程(2017年3期)2017-12-22
海外华文教育(2017年6期)2017-08-07
系统工程与电子技术(2016年7期)2016-08-21
水电站机电技术(2016年1期)2016-02-28
火控雷达技术(2016年2期)2016-02-06
