
MobileNetV2神经网络处理器的设计方案比较*
2021-02-03 04:08陈泳豪萧嘉乐
计算机工程与科学 2021年1期
陈泳豪,萧嘉乐,粟 涛
(中山大学电子与信息工程学院,广东 广州 510006)
1 引言
现如今,最新的移动终端电子设备往往会使用到神经网络处理器。诸如移动电话和平板电脑等消费类设备的更新周期短,其现行的产品策略是专注于一种成熟优质算法的硬件实现,这样可以使电路性能更好。作为专为移动端和嵌入式端深度学习应用而设计的网络,MobileNet[1,2]在面对需高速响应的批量预测需求时,能够做到精度高、速度快,是移动终端中理想的神经网络算法。
Google团队自2017年以来先后提出MobileNet的V1~V3 3个版本,而本文主要关注MobileNetV2(版本2)及其瓶颈模块。文献[3]针对MobileNetV2的实现,设计了矩阵乘法引擎MME(Matrix Multiplication Engine),以及既可以进行逐点(Pointwise)卷积,也可以进行逐层(Depthwise)卷积的计算方块结构。文献[4]针对特征图(feature map)在片内片外传输的大量时间延迟,引入了新的计算思路,提出了卷积层融合(Layer Fusion)的思路。现有的加速器研究中,既有针对可分离卷积的专用结构[5,6],也有动态可重构加速器[7]方面的研究。
本文的创新点如下所示:本文将在卷积层融合、矩阵乘法引擎及其计算方块结构这2个现有设计之上进行创新和优化,针对MobileNetV2中的瓶颈模块,提出一个新的硬件加速器架构设计,其具有根据瓶颈模块位置不同,重新组织流水结构和动态分配计算力的能力。新的架构设计对应着新的设计空间,其中有很多结构参数对加速器的性能有巨大影响,而这些参数的选择是一个问题。与现有优化方式[8 - 12]更多关注循环展开(Unrolling)、储存组织(Memory Organization)和量化(Quantization)等不同,本文关注Layer Fusion最佳深度、可配置方块厚度等5个参数。这些参数的组合形成了上述的设计空间,而本文将在此空间内寻找最优的设计方案;同时也试图在各参数对硬件表现的贡献与影响上寻找规律与共性,以尝试为以后的相关设计研究给予一些启发。因此,与文献[8]类似,本文更关注空间搜索式的顶层优化。在方法上,本文采取软件模拟器遍历寻优加硬件行为仿真验证的探索方式。
2 由可配置方块组成的流水作业结构——“6Q结构”
2.1 深度可分离卷积与线性瓶颈模块
标准卷积行为在进行卷积操作时是在空间和通道2个维度同时进行的。MobileNetV1[1]引入了深度可分离卷积(Depthwise Separable Convolution),其关键是将空间和通道2个维度的卷积操作分开,进而形成了空间维度的逐层卷积和通道维度的逐点卷积2个部分。具体来说,它将标准卷积分成了2步:3×3的逐层卷积和1×1的逐点卷积。这种分解方式可以明显地减少计算量。而MobileNetV2[2]则在此基础上,为了弥补3×3的逐层卷积在低维空间提取特征效果较差的缺点,在逐层卷积前多加入了一个1×1的逐点卷积,来完成对卷积神经网络中的特征图进行升维的任务,于是形成了逐点卷积-逐层卷积-逐点卷积的结构,并且在第2个逐点卷积的末尾把激活函数ReLU6去掉,此结构被称为反转残差模块及线性瓶颈结构(下文简称为瓶颈模块)。这一基本模块使MobileNetV2变得更高效,准确率也提高了。整个MobileNetV2网络由多个这样的瓶颈模块组成。
2.2 卷积层融合与计算方块的引入
为了解决神经网络加速器中需要将特征图在片外存储空间和片上缓冲区(Buffer)之间频繁地传输,导致乘加单元空闲,进而造成效率低下的问题,文献[4]充分利用了卷积神经网络特征图之间在平面方向严格的局部区域对应关系,提出了卷积层融合(Layer Fusion)的思路,通过创建相邻卷积层的对应局部区域的融合关系,使得使用跨卷积层的数据流成为可能。具体来说,针对每一次卷积计算,该方法首先对输入特征图从平面方向进行等面积区域划分(不影响通道方向);然后直接把该局部区域作卷积运算得到输出特征图,并将其传给下一次卷积;以此类推,直到计算完平面方向的全部区域。其中产生的特征图缓存在Kb级别,同时也避免了片内片外的传输延迟。考虑到MobileNetV2的瓶颈模块对特征图先升维再降维,形状类似一个纺锤体,头尾的通道数少,中间的通道数多,容易造成存取的时间消耗,所以非常适合套用卷积层融合的思路。
但是,瓶颈模块中逐点卷积和逐层卷积是2种不同类型的卷积,若要在加速器中利用卷积层融合,则还需要乘法阵列的适配。文献[3]提出了一种可以自由切换于1×1的逐点卷积和3×3的逐层卷积之间的乘法阵列结构(Multiplier Array),以下将其称为“计算方块”,其厚度是32层,每1个时钟周期可以执行3×3×32=288次乘法运算。计算方块包含在矩阵乘法引擎(MME)结构中,矩阵乘法引擎能够执行MobileNetV2涉及的所有CNN运算。MME相当于常规CNN加速器的处理单元PE(Processing Element)阵列设计[10],具体来说,每一个MME中除了核心部分计算方块以外,还含有32片行缓冲区(每一片对应着计算方块的1个通道)、1个加法树块、1个归一化块、1个ReLU激活函数块和1个池化计算部分。在不同的卷积类型下,行缓冲区可对应地为计算方块输入数据,加法器树可对应地对乘积求和。文献[3]配置了4个MME,也就是4个计算方块。
2.3 卷积层融合与可配置方块组成的流水作业结构
在硬件加速器设计上采用卷积层融合和计算方块的思路,以充分发挥它们的优点。在不增加乘法器需求的条件下,本文将尝试把通道数目减少,以此来获得更多方块。针对不同的瓶颈模块、不同的卷积行为,设计不同的方块分配方法,目的是使得总耗时最少。也就是说,这些方块不仅如文献[3]那样拥有卷积功能的可配置性,而且还有独立工作和组合工作的可配置性。以下将这些方块称为“可配置方块”。当然,为保证其计算效果,亦需为其配置上文所述的MME内其他计算模块内容。
在配置了足够多方块以后,事实上就已经把卷积层融合这一长过程按照不同的卷积层分成了多个子过程,其中,1个子过程就是卷积层融合的1个卷积层。容易发现,卷积层融合中上一子过程的结果是下一子过程的前提。而不同批次卷积层融合的同一位置处的子过程与子过程之间呈现并行关系,这就使得计算部件有了复用的可能性。于是,在配置了一定数量的可计算方块的前提下,可以考虑将卷积层融合配置为一种“流水作业”实现结构,这能够进一步大幅提升加速器性能。下面将参与卷积层融合的卷积层称为融合型,将不参与的卷积层称为独立型,并将参与卷积层融合的且彼此相连的多个卷积层看作一个整体,称为一个融合卷积群。
融合型卷积与独立型卷积其实各有优劣,针对MobileNetV2的不同网络位置,应该用不同的卷积策略,以扬长避短。容易发现,计算方块执行逐点卷积比逐层卷积更耗时。假设只用一个计算方块,并令可配置方块的厚度Qc=32,在17个瓶颈模块中,pointwise_conv_1(逐点卷积)、depthwise_conv(逐层卷积)、pointwise_conv_2(逐点卷积)之间的时钟消耗比较如图1所示。

Figure 1 Comparison of clock consumption of convolutions in bottleneck图1 瓶颈模块内部3次卷积时钟消耗比较
针对这个情况,有2种思路:(1) 既然可配置方块数量充足,可以通过主动规划可配置方块的分配方式,在融合卷积群里,为逐点卷积多配置一些计算方块,逐层卷积相应地少配置点,尽量拉平流水作业结构内不同流水级之间的耗时差异,使融合卷积群的总计算耗时最少;(2) 某些卷积可以用独立型卷积,因为这意味着没有流水级,可以把所有的可配置方块都分配给它们。
此外,在图1中也侧面反映了不同位置瓶颈模块处需要的运算量差异。在网络的起始和结尾处附近的运算量是相对较大的。
2.4 “6Q结构”及探究目的
本文将重点考虑上述“流水作业”的加速器结构的具体设计参数的取优问题。将MobileNetV2从前往后,每2个瓶颈模块作为1组进行考虑。MobileNetV2中一共有17个瓶颈模块,本文讨论前面16个,将其分成8组。在每组瓶颈模块中去探究:可配置方块应该设置多厚的厚度;什么地方应该用融合型卷积,什么地方应该用独立型卷积,且对于使用融合型卷积的层,应做几层深度流水作业结构最优,以及是否应该设计“打通”2个瓶颈模块的卷积层融合;在该种卷积层融合方式下,对应网络不同位置的瓶颈模块,应该把特征图分割成多少等份为最优;在该种卷积层融合方式、该种特征图分割方法下,应该为每一层的卷积分配多少可配置方块为最优。
这些需要探索的问题,组成了本文所述的设计空间。为寻找此设计空间内的最优参数组合,即最优的设计方案,并探索背后的规律,本文提出一个分析框架——“6Q结构”:
(1) 以2个瓶颈模块(即包含6次卷积)为1组进行考虑,命名为BN2。设每一次卷积为Q,于是有Q1、Q2、Q3、Q4、Q5、Q6。显然,Q1、Q3、Q4、Q6必然是1×1 逐点卷积,Q2、Q5必然是3×3逐层卷积。在BN2中,设定任意2~6层可以融合起来。考虑到计算资源有限,所以在此不考虑将更多层融合起来的设计。
(2) 每一个Q都存在4种工作可能,分别是作为融合型卷积的起始层、中间层、结尾层或作为独立型卷积层。
(3) 在所有方案中所有可配置方块的层数之和均为统一固定值,本文设为120。
(4) 可配置方块彼此之间的厚度是相同的,以Qc表示(在同一设计方案内Qc为单一固定值)。可配置方块总量为Q_all/Qc。在Q作为独立型卷积时,全部可配置方块都为它服务。在Q作为融合型卷积时,需探索可配置方块的最优分配方式。
2.5 “6Q结构”锁定的设计空间
以下详细解释各参数的含义,这些参数之间的可能性组合,组成了本文所述的设计空间。
(1)Qc:每个方块的厚度(包含多少层3×3乘法器层)。方块厚度越厚,其1个时钟周期能完成的乘法数量Qc*9就越大;相应地,因为所有方块的“总厚度”固定(120层),因此在该Qc配置下的方块总数量Q_all(=120/Qc) 就会越少。在设计空间中,给予了Qc7个值,分别为4,6,8,10,12,15,20。注意到它们都是120的公约数。
(2)BN2:如前所述,BN2的取值是0~7,也就是说考虑8个BN2,即前16个瓶颈模块,如表1所示。在MobileNetV2中,不同的瓶颈模块有着不同的长宽、不同的输入输出通道数、不同的升维系数,总体而言,如同其它卷积神经网络一样,特征图的长宽是逐渐缩小的,而通道数是逐渐增加的。于是,BN2的取值指定了6Q结构正在网络的哪一段位置进行计算,也就绑定了MobileNetV2不同位置处的瓶颈模块的网络结构参数。


Figure 2 Allocation diagram of configurable blocks under different coefficients of Fuse and Q_num图2 Fuse系数、Q_num系数与可配置方块的分配示意图(以32种融合方案中的2种来举例)
(4)tile:tile的意义是应该把特征图分割成多少份为宜。本文采用的分割方法是将正方形的平面分割成一个个等宽的长方形,长方形的长为M,宽为(M/tile)。例如,对于长宽为56×56的特征图,假如tile=4,那么切分完后,每一份的长宽变为(56/4)×56=14×56。同为一融合卷积群的层必然是按照同一种分法去切分的,所以它们共享一个相同的tile参数,如图3所示。tile行为只在xy平面进行切分,不影响通道方向。每个BN2下可选择的tile参数组成一个数组tile_poss[](tilepossibility),如表1所示。对应着MobileNetV2的网络结构,不同BN2处的tile参数不尽相同,M越大,可供选择的tile参数就相对越大,目的是为了更好地探索怎样选取tile更合适。另外需要说明的是,例如若其宽为7时,除以2不能得到整数,所以实际操作会先为其补一行0,使得宽变为8,再去除以2。

Table 1 Network structure parameters of MobileNetV2 and the definition of BN2 and tile_poss表1 MobileNetV2的网络结构参数及BN2和tile_poss的定义

Figure 3 Convolution group of Layer Fusion图3 融合卷积群
(5)Q_num:对于每一个BN2而言,Q_num也为一个含有6个元素的数组,元素从前到后分别对应Q1~Q6。Q_num的含义是,Q1~Q6中的每一个在工作时,有多少个可配置方块能够被分配给它进行计算。对于参与卷积层融合的层而言,它们中的每层(即每个Q)都将分配到Q_all个方块中的一部分(至少1个),具体的分配数量将影响到融合型卷积层的计算时间。因此,Q_num受到Qc和Fuse参数的制约。对于独立型卷积层而言,既然它们都是本层独立计算完毕才到下一层,所以它们将被分配到所有方块,也就是Q_all个方块。
(6)bandwidth_fm和bandwidth_w:分别代表特征图缓存的传输带宽和权重乒乓缓存的传输带宽。二者在模拟中将取相同带宽,且均采用128位或64位AXI总线。
在表1中,M、N、T、P、S是MobileNetV2的网络结构参数。M是特征图平面方向的长宽,例如112是指112×112。N是特征图的通道数,在每个瓶颈模块里,输入第1次逐点卷积、输入逐层卷积、输入第2次逐点卷积的特征图的通道深度分别是N、TN、TN。T是升维系数。P是输出特征图的通道数。S是stride系数。每个BN2下可选择的tile参数组成1个数组tile_poss[]。
图4展示了实现处于融合卷积群这一状态的硬件架构。图4中只示意地画出了4个Q的情况,但如前文所述,实际上图中的所有可配置方块资源处可以动态地为计算方块区分配出1~6个Q。每一个Q与其前、后紧连着的分块特征图缓存(Tile Feature Map Buffer)形成紧密的数据传递关系,三者可以看作一个小整体。图4中包含了4个小整体的情况,它们也就是抽象出来的4个流水级。
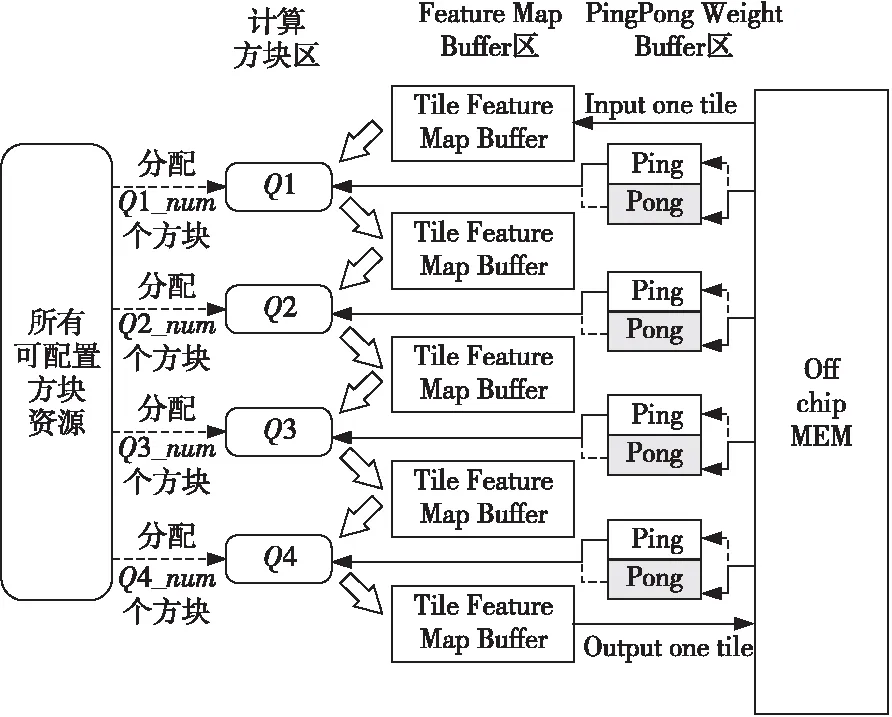
Figure 4 Architecture for the convolution group of Layer Fusion图4 融合卷积群状态下的硬件架构图
3 软件模拟器在设计空间中的寻优
3.1 软件模拟器的作用与价值
软件模拟器综合考虑以上的Qc、BN2、Fuse、tile、Q_num、bandwidth_fm、bandwidth_w等参数,结合MobileNetV2的网络结构,通过用于计算时钟消耗的算法,以每个BN2为单位,计算理论上的时钟消耗。
用数学方式表述如下:以p代表设计空间中的所有点,s代表设计空间中的一个具体的点,即s∈p。将上述参数的组合设为输入X,于是有Xp,Xs;把以BN2为时钟消耗分析单元的算法作为函数F(x);设Y代表输出,于是有Yp,Ys,由于这些参数的组合可能性非常多,因此设计空间比较大,即p非常大。软件模拟器首先将会遍历此设计空间内所有的可能性p,将这些可能性的参数组合作为输入Xp,计算其对应的输出Yp=F(Xp)。然后在Yp中按照控制变量法,选取一系列最优结果Ys=F(Xs)。这些点s对应的Xs所组成的集合 {Xs|s∈p且Ys=F(Xs)为控制变量下的一系列最优解},也就是最优参数组合所组成的集合,本文将从其中提取有参考价值的设计规律。
软件模拟器采用Python实现,其主要任务是大批量计算所有可能的参数组合下对应的所有结果,并进行数据分析。为了验证软件模拟器计算时钟消耗算法的正确性,本文也设计了硬件行为仿真器,其目的是验证软件模拟器的算法逻辑是否正确,保证软件模拟器结论的有效性。硬件行为仿真器的仿真结果与讨论将在下一节详细叙述。
3.2 F(X)的算法实现
3.2.1 融合型流水作业结构
利用流水线的时间消耗计算公式:设每个任务最长段需要时间tmax,每个融合卷积群经过tile分割后的1个分块作为1个批次,完成1批融合卷积群分块所需的时间为t,完成n批融合卷积群分块所需的时钟消耗T-pipeline为:
T-pipeline=(n-1) *tmax+t
(1)

Figure 5 Pipeline diagram of Q units图5 Q单元流水作业示意图
将融合型卷积的单个融合卷积群分块批次的特征图的输入时间、输出时间分别用Tfm_i、Tfm_o表示。将融合卷积群中的每一个Q执行时的时钟消耗依次用T_QI、T_QII、T_QIII、…、T_QLast表示。显然,在实际实现逻辑上,需要把单个融合卷积群分块批次的特征图的输入部分与第1个Q绑定,输出部分与最后1个Q绑定,否则流水作业无法正常工作。此外,为保证特征图信息不会丢失,在将其输入计算单元进行卷积计算时,需要额外把紧贴着特征图切割线的那一行也数据也输入进去。
因此,综合考虑式(1)和融合型的特征图传输特点,计算单个融合卷积群内部所有融合卷积群分块批次的总时间消耗,即单个融合卷积群实际上的总时钟消耗(用Tlf表示)的计算式为:
Tlf=(tile-1) * max[(Tfm_i+T_QI),
T_QII,…,(T_QLast+Tfm_o)]+
(Tfm_i+T_QI)+T_QII+…+(T_QLast+Tfm_o)
(2)
Q单元流水作业示意图如图5所示,通过此图可以直观地理解式(2)。
3.2.2 独立型卷积
事实上,无论将独立型卷积的计算分成多少批,对时间花费并不会产生本质的影响。即使将一个独立卷积行为分成了n批进行计算,由于计算行为是简单的串联关系,并没有并行的流水行为,若忽略交接处的O(n)级别的时钟误差,其时钟总消耗与n=1的情况下并无差异。虽然事实上对于加速器的实现来说n>1,但为了便于计算,本文将采用n=1的假设来进行软件模拟。所以,对于一个独立型卷积层,其时钟消耗为:
T_solo=Tfm_i_solo+T_Q_solo+Tfm_o_solo
(3)
其中,Tfm_i_solo和Tfm_o_solo代表特征图的片内外传输时间,T_Q_solo是Q执行时的时钟消耗。
3.2.3 可配置方块的计算逻辑
Q1、Q3、Q4、Q6是1×1逐点卷积,Q2、Q5是3×3逐层卷积。可配置方块针对给予的特征图进行卷积,需要做完3层运算遍历,按照优先级分别为核遍历、通道遍历和平面遍历,如表2所示,其中Ceil()函数是指向上取整函数。设定其进行逐点卷积的时候,Q_num个方块负责Q_num条不同的1×1卷积核;进行逐层卷积的时候,Q_num个方块一起做平面方向遍历。因此,卷积核数量除以同时参与的可配置方块数量Q_num可得到核遍历数,其中,由于逐层卷积本身的特性,不需要核遍历;特征图通道数除以可配置方块厚度Qc可得到通道遍历数;至于平面方向的遍历,逐层卷积逐点跳动或隔点跳动,逐点卷积则一次可计算特征图中的9个点。若可配置方块每跳动一个位置为单个操作,则3层遍历相乘得到运算遍历的总操作量,再乘上单个操作的耗时clk_param,可得到对应卷积种类的计算时间。clk_param需要看单个操作的设计,例如按照取1个时钟周期、乘1个时钟周期、加法树1个时钟周期、存数据1个时钟周期来算,则clkparam=4。

Table 2 Traversal operation logic for convolutions using configurable blocks表2 利用可配置方块对Pointwise和Depthwise 2种类型卷积的遍历运算逻辑
3.2.4 权重乒乓缓存输入输出的计算规则
除了特征图,卷积运算前需要先从片外存储中获取的还有权值参数。本文采用权重乒乓缓存输入输出的方案[3,8],其目的是使权重的片外输入不会成为速度的瓶颈。将缓存(Buffer)分成左右2个功能完全一样但行为彼此互补的子缓存区,当左边的权值缓冲区输出用于卷积的数据时,右边的权值缓冲区将从外部存储器中加载数据,以供下一步使用,以此类推。
可配置方块在特征图中的遍历方式决定了每次更新权值数据之间的间隔时间。若此间隔时间大于权值数据的传输时间,则不会被后者拖慢;否则,在遍历过程中,方块将因为要等待权值的到位而不能工作。软件模拟器将会考虑这一条件。权值数据在可配置方块中的装配方法如下所示:
(1)逐层卷积:Q_num(在独立型卷积中,Q_num即Q_all)个装载有相同权值内容的可配置方块同时做平面遍历。方块每步跳动1格。平面遍历完毕时,更新权值数据。每次更新的权值数据量为Qc* 9。
(2)逐点卷积:在一个可配置方块里装的数据,是将同一条核的Qc长度部分截取并重复3*3=9次而得到的。不同方块对应不同核。方块每步跳动3格。每次更新的权值数据量为Q_num*Qc。
3.3 模拟结果
软件模拟器遍历了设计空间中一共75 196 680种设计,输出结果为csv格式数据(文本型表格),遍历输出结果有36.2 GB。篇幅所限,仅展示利用软件模拟器在bandwidth_fm=bandwidth_w=64位情况下所得的Xs集,如表3所示。
3.4 数据分析与总结
通过对结果数据的分析,本文总结得出以下结论:
(1) 最佳流水深度与BN2的值、带宽、Qc厚度均有关。总体而言,BN2越小、带宽越小、Qc越小,最佳流水深度越大。具体来说,对于BN2=0,带宽为64时,当Qc<10时,最佳流水方案是6层深的流水,即以每2个瓶颈模块为1个融合卷积群,而当Qc≥10时,以每个瓶颈模块为1个融合卷积群为最佳;带宽为128时,较小的Qc同样偏好6层深的流水,中等Qc(Qc=8,10,12)偏好以每个瓶颈模块为1个融合卷积群,较大的Qc(Qc=15,20),则偏好Fuse=[3,2,1,3,1,0]的方案。紧接着的BN2(BN2=1,2),带宽为64时,偏好于以每个瓶颈模块为1个融合卷积群,带宽为128时,偏好2层深的流水搭配独立型卷积。在BN2较大的地方(BN2=3,4,5,6),2层深的流水搭配独立型卷积的表现是最佳的,普遍比3层深度好。在BN2最大的地方(BN2=7),就不适合进行卷积层融合了,独立型卷积表现最佳。总体而言,在特征图的长宽较大、通道较浅的地方,适合流水结构;在特征图的长宽特别小、通道特别深的地方,不适合流水结构。

Table 3 Parts of Xs set given by software simulator (bandwidth_fm=bandwidth_w=64)表3 软件模拟器所得Xs集的部分结果 (bandwidth_fm=bandwidth_w=64)
(2) 最优的tile参数一般为能被M(特征图宽度)整除的最大二次幂。
(3) 如前文所预料,对于Q_num系数,逐点卷积需要的可配置方块数量确实都大于逐层卷积的,具体的数量配置可参考图5。
(4) 在2种带宽下,Qc对8个BN2总耗时的影响如图6所示。使用全独立型卷积(即Fuse=[0,0,0,0,0,0])的结果作为对照,可以看出卷积层融合对减少总耗时的贡献。在Qc研究范围内,总耗时随Qc增加呈现先降后升的趋势。在每一组情况下,Qc=8均表现为最优的厚度。

Figure 6 Relationship between total time consumption and Qc图6 总耗时与Qc的关系
(5) 流水作业结构的缓存需求与流水深度(Fuse系数)、tile、BN2、数据精度均有关。最大需求处的缓存需求量即为需要为加速器设置的缓存大小。数据精度为int8下,根据计算,对于权重乒乓缓存,最大需求出现在BN2=7,当Fuse=[0,0,0,0,0,0],tile=[1,1,1,1,1,1],需求为158 Kb;对于特征图,最大需求出现在BN2=0处,当Fuse=[3,2,2,2,2,1],tile=[16,16,16,16,16,16],需求为3.5 Mb。如采用其他精度,只需把缓存需求乘以对应的扩大倍数即可。与现有设计[3]相比,大大减少了对特征图缓存的需求。
4 硬件行为仿真模拟器
4.1 行为仿真的功能
所谓行为仿真,就是指按照实际加速器的流水逻辑设计一个硬件行为模拟器,这个行为模拟器的流水作业行为与实际的加速器是一样的,但是不会作实际的卷积计算,所以其目的只是从时间层面更实际地去模仿实际加速器的用时。把卷积的计算遍历替换为计数器的计数,卷积每个遍历循环需要多少个时钟周期,就让计数器记录多少个时钟周期,这样行为仿真就可以在行为上、用时上都较为充分地去模仿实际的加速器。
行为仿真有2个功能:其一是验证软件仿真算法的正确性;其二是针对硬件具体实现代码可以观察具体的握手信号延迟。不同的代码逻辑写法会有不一样的握手信号延迟差异,它由具体实现决定。在写出具备实际意义的握手信号后,将硬件仿真得到的误差值反馈给软件模拟器,假如消除该误差后,二者几乎一致,则可以认为软件模拟器能够很好地模拟出硬件行为仿真器的行为与时间消耗,也能够说明实验数据的实用性。
4.2 行为仿真结果
行为仿真模拟了Fuse=[3,2,1,3,2,1]和Fuse=[3,1,0,0,3,1]下的2系列方案。表4展现bandwidth_fm=bandwidth_w=128位、数据精度为int8下的部分行为仿真结果。经过代码对比,发现软件模拟器与硬件行为仿真器结果的差值,只是tile系数、Fuse系数和独立型卷积的分批数量n(见3.2.2)这3者的函数,与网络结构参数M、N、T、P、S或Q_num等其他参数均无关,这说明了该差值正是握手信号延迟差异的积累。在消除该差值后,软件模拟器的计算结果与硬件模拟器均可以做到完全一致。这验证了软件仿真算法的有效性。
5 结束语
本文针对MobileNetV2的硬件设计方案,结合

Table 4 Results comparison between software simulator and hardware behavior simulator (clks)表4 软件模拟器与硬件行为仿真器的结果比较 (clks)
卷积层融合和可配置方块,提出一个可以根据瓶颈模块位置不同而重新组织流水结构及动态分配计算力的新加速器架构设计,并针对其设计空间提出了“6Q结构”的探索框架。经过对参数设计空间p的遍历,得到了最优参数集Xs,并总结了其设计规律。针对提出的设计空间,本文的结论是,Qc=8为研究范围内最优的可配置方块厚度;最优的tile参数一般为能被M(特征图宽度)整除的最大二次幂;随着特征图的长宽减小、通道变长,最优的流水结构深度由深变浅。与现有的同类加速器设计相比,融合型卷积搭配独立型卷积的方案可以在速度和缓存需求之间取得一个很好的平衡。此外,对于类似的较大的设计空间,本文建议采用软件模拟加硬件行为仿真验证的手段,十分高效。本设计将为类似的硬件实现提供启发与帮助。在今后的工作中,可以将本文已有的思路适当发散,进行更多与处理器自动设计相关的研究。
猜你喜欢
小学生学习指导(低年级)(2022年9期)2022-10-08
小哥白尼(趣味科学)(2021年6期)2021-11-02
数学小灵通·3-4年级(2021年5期)2021-07-16
故事作文·高年级(2021年4期)2021-05-06
小哥白尼(神奇星球)(2021年11期)2021-03-08
科普童话·学霸日记(2020年4期)2020-05-06
中国环境监察(2016年11期)2016-10-24
中国卫生(2016年1期)2016-01-24
中国卫生(2015年4期)2015-11-08
装备环境工程(2015年5期)2015-02-28
