
面向混合异构架构的模型并行训练优化方法*
2021-02-03 04:08郭振华陈永芳赵雅倩
计算机工程与科学 2021年1期
高 开,郭振华,陈永芳,王 丽,赵雅倩,赵 坤
(1.浪潮电子信息产业股份有限公司高效能服务器与存储技术国家重点实验室,山东 济南 250000; 2.广东浪潮大数据研究有限公司,广东 广州 510000)
1 引言
深度神经网络(DNN)推进诸多机器学习任务的进步,其中包括语音识别、视觉识别和语言处理等。BigGan、Bert和GPT2.0 等最新成果表明,DNN 的模型越大,任务处理的表现就越好,而该结论也在过去的视觉识别任务中得到了验证,这表明模型大小与分类准确性之间存在很强的关联性。与此对应的是,各个公司推出了各种类型的加速器设备用来加速训练神经网络模型,Intel和XILINX分别推出了高效能的FPGA设备,Google推出了一系列的TPU(Tensor Processing Unit)加速板卡。目前最先进的图像模型早已达到 TPUv2 可用内存的极限,单一类型的板卡已经无法用来训练很大的模型,因此,迫切需要一种高效、可扩展的基础设施,以实现大规模的深度学习训练,并克服当前加速器内存受限问题,进而可以扩展到多种类型的加速器设备上,能够充分使用混合异构集群中存在的多种类型且性能不一的设备。
为了在多个计算设备之间部署深度学习DL(Deep Learning)模型以训练大型且复杂的模型,数据并行DP(Data Parallel)是应用最广泛的并行化策略,但是如果数据并行训练中的设备数量不断增加,设备的性能不一,设备之间的通信开销就会成为瓶颈。此外,对于性能分布不均的设备群,训练时每个步骤都需要给性能不同的设备分配不同的批处理大小,这种不均衡会导致精度损失,即需要更长的训练周期以收敛到期望的精度[1]。这些因素会影响数据并行整体训练时间,并且会影响某些设备的运行效率。
除了DP,还可以利用模型并行性MP(Model Parallel)来加速模型训练。模型并行首先把整个模型按照一定的策略划分到各个设备上,然后通过设备间的相互通信来解决特征数据传输问题。Gpipe[2]是一种典型的模型并行训练框架,它根据设备的性能和模型每一层的计算量大小按照相应比例为各个计算设备配置模型,然后依次按照设备顺序并行流水地进行训练。这种方法可解决数据并行中的精度损失问题,但同样会因为设备群中设备数量增加带来流水线过长和通信瓶颈问题。同时,在混合异构平台中,模型并行训练时需要更加精细地划分模型,因此如何在性能分布不均的设备上划分模型,以及如何高效地建立设备间的流水都成为了重要的研究热点问题[3]。
2 基于Gpipe框架的模型并行训练
简单来说,Gpipe 是一款分布式机器学习库,基于同步随机梯度下降与流水并行技术进行模型并行训练,适用于由多个连续层组成的任意 DNN。最重要的是,Gpipe 可以使研究人员在不调整超参数的情况下部署更多的加速器,以训练大规模模型,由此有效扩展了性能。
为了实现跨加速器的高效训练,Gpipe 先按照加速器对模型进行按层划分,然后将每个批次的训练示例拆分为更小的微批次。通过在微批次中执行流水管理,加速器得以并行流水运行。此外,梯度将在微批次中持续累积,以免分区的数量影响到模型的质量。
Gpipe框架中采用的模型并行策略是按照模型每层的计算量均等地分到各个计算设备上(如图1a所示),然后在各个设备上依次进行模型的前向反向计算(如图1b所示)。从图1b可以看到,每个时刻只有一个设备在执行计算任务,其他设备都处在空闲状态,这样会造成极大的资源浪费。为了解决这个问题,Gpipe通过把每一个批次的数据划分成更小批次的方法,使得每个小批次在设备间流水执行,尽可能地使所有设备都能够同时并行计算(如图1c所示)。Gpipe一般是通过总的批处理总量除以设备数来得到更小的批次。对于具有单一类型设备的异构平台,Gpipe的模型并行划分策略和微批次流水的方法都具有较好的性能。但是,对于混合异构平台,由于一些设备性能分布差距过大,均等的模型划分策略和微批次划分方法都不能充分利用集群中设备的性能。

Figure 1 An example of Gpipe working principle图1 Gpipe 工作原理示例
图1a是模型并行训练中序列模型划分示例。其中,Fk为第k个部分的前向计算,Bk为第k个部分的后向计算,依赖于Bk+1的输出和Fk的输出。图1b是传统的模型并行训练的前向反向过程。由于网络存在顺序性,每次都只有一个加速器处于活动状态。 模型并行策略导致严重的设备利用不充分问题。
图1c是Gpipe 将输入的小批次拆成更小的微批次,使不同的加速器可以同时在单独的微批次上运行。
3 混合异构架构下模型并行划分映射策略
Gpipe所提供的模型并行流水训练一般适用于性能均等的加速设备,比如Google在一系列TPUv2芯片上实现了模型的划分和并行流水训练[4]。Gpipe中使用的模型划分策略是按照模型中每一层计算量和设备的计算性能进行均等划分。而对于混合异构平台,通常每台设备上都部署了多种类型的加速芯片,比如GPU、FPGA和TPU设备等。当设备群中出现性能不一的多种类型设备时,每种设备的计算能力和通信带宽的不一致给网络模型的划分带来很大的问题[5],网络模型就不能简单地按层进行划分。模型并行训练时需要同时利用多种类型的加速芯片,如何在多种性能分布不均的设备上部署模型以及合理地建立设备间的流水是急需解决的问题。
在混合异构架构下,设备的性能通常会有很大的差异性,比如设备群的FPGA设备(如图2a所示),通常情况下FPGA设备只能承担某一层的计算量,甚至某些性能过低的FPGA设备无法承担一层的计算量,因此需要更加精细的模型并行训练时模型划分方法。为了解决设备性能分布不均带来的模型划分困难,本文提出了一种层级并行和通道并行混合的模型划分策略。

Figure 2 Model parallel training method based on Gpipe图2 基于Gpipe框架的层级模型并行
本文以混合异构平台中有2个GPU设备和2个FPGA设备为例说明层级并行和通道并行的模型混合并行策略。由于使用的FPGA设备的性能要低于GPU设备的性能,首先把2个FPGA设备合并成1个设备,然后在合并后的3个设备上用传统的层级划分策略进行模型划分,即按照每层的计算量和设备的计算力按比例把网络模型按层划分到每个设备上(如图3a所示)。按层级划分完成模型划分之后,再把划分到2个FPGA设备上的网络层按卷积核通道数在2个FPGA设备上按计算能力进行均等划分(如图3b所示)。如果2个FPGA设备的性能均等,那么划分到每个设备上的通道数是一致的。

Figure 3 Model parallel training of hierarchy parallel and channel parallel图3 层级并行与通道并行混合的模型并行
这种混合层级并行和通道并行的划分策略有2个方面的优点:(1)混合并行策略对网络模型的划分是更加精细的,模型的划分粒度不仅仅局限在以层级为单位的划分,而是精细到了以通道为单位,这种混合划分策略能够更充分地利用不同类型设备的性能。(2)混合并行划分策略可以减少混合异构中设备流水线的长度(如图2c和图3c所示),为第4节模型并行训练时流水线的建立提供了便利。

Figure 4 Idle time of model parallel pipeline training when device number is 3 and micro-batch-size is 4图4 模型并行训练流水过程中设备空闲时间(设备数量为3,微批次数量为4)
4 流水线的优化与微批次的自动调节
Gpipe框架是通过把批次划分成更小的微批次来实现设备间的并行流水训练,划分后的批次大小B=M/K,其中M为原批次大小,K为设备数量。图4阐明了设备数量K为3,微批次数量为4时设备间流水效果。
通过图4的流水过程分析可以得到,训练过程中有一半以上的时间至少有1个设备处于空闲状态,因此这样的流水效果没有充分利用设备的性能,反而在流水线建立上的时间占比很大[6]。为了缩短流水线建立的时间,传统的模型并行算法通常是通过划分更小的微批次来掩盖流水线建立的时间。一般情况下,当划分的微批次数量越多,设备间的流水效果会更好,当划分后的微批次数量N>4×K,K为设备数量,流水线的建立时间就会占比很小。同时,如果混合异构平台中设备数量巨大,就需要划分更多的微批次来达到较好的流水效果。显而易见的是,批处理总量是不变的,当划分的微批次数量越多,每次每个设备处理的批量大小就会越小。若设备每次处理的批量大小远小于设备的处理能力的时候,通常也会无法充分利用该设备的性能资源。
如何根据流水线长度和设备的处理能力来确定微批次的大小和数量就是一个急需解决的问题,本文根据以下2个原则来确定如何选择微批次的划分数量。
4.1 原则1:化零为整,减小流水线的长度
在模型并行训练中,当设备数量增多时,通常流水线的长度也会随之增加,因此花费在流水建立的时间占比也会增大。而且混合异构架构下设备的类型多种多样,通常会有很大的性能差异性(如图5所示),这些差异性会给设备间流水的建立带来通信瓶颈问题。
为了解决上述问题,本文提出一种混合异构架构下多设备合并的策略,通过合并一些性能较低的设备使合并后的设备的性能分布均匀(如图6所示)。设备合并采用通过循环遍历设备性能然后合并性能较低的2个设备的方式。假设第i个设备的性能记为Pi,整个设备群中设备的性能分布用平均差来刻画,如式(1)所示:
(1)
算法1设备合并方法device_merge()
输入:设备性能集合{Pi,…,Pn}。
输出:合并后的设备性能集合{Pi,…,Pk}。
while(1)
{
{Pi,…,Pn}=Sort({Pi,…,Pn});
Pn-1=Pn-1+Pn;
Output {Pi,…,Pn-1};
Break;
}
n=n-1;
}
经过设备合并之后的设备群流水线长度缩短了(如图6所示),各设备性能差别很小或者已经没有差别。在完成设备合并之后需要进行模型的划分和映射,采用3.1节中的层级并行和通道并行混合划分策略,首先根据合并之后设备的性能和模型各层的计算量按比例进行划分;然后在合并的设备上根据通道数目和设备性能按比例进行划分。本文提出的这种设备合并方法能够和第3节提到的混合并行策略完美地结合在一起,不仅缩短了流水线的长度,而且还缓解了设备群中的性能较低设备的通信压力。

Figure 5 The pipeline training before device combined when device number is 5 and micro-batch-size is 4图5 设备合并前的流水效果图(设备数量为5,微批次数量为4)
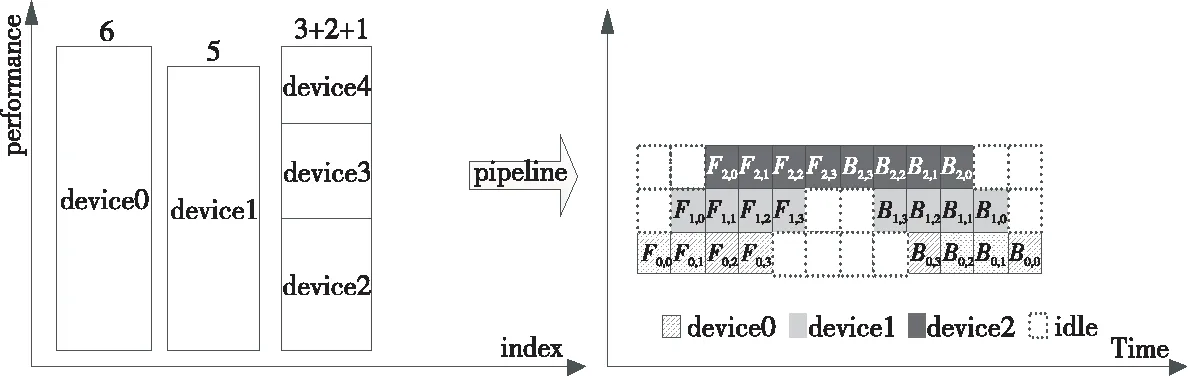
Figure 6 The pipeline training after device combined when device number is 5 and micro-batch-size is 4图6 设备合并后的流水效果图(设备数量为5,微批次数量为4)
4.2 原则2:负载均衡,自动调节微批次
在经过上述设备合并之后模型并行训练需要建立设备间的流水,本文采用Gpipe框架中微批次划分的方法使得各小批次在设备间流水执行。Gpipe框架中微批次划分方法是总的处理批次大小除以设备数量。这种方法通常不能完全利用设备性能或者流水建立的时间占比很大,为了缓解这个问题,本文提出根据流水线的长度和设备性能来动态地进行微批次划分。首先,计算得到合并后每个设备的传输带宽和计算能力;然后分析批次的划分对流水建立时间占比和设备利用率的影响。图7是2个设备时微批次的划分数量大小对流水建立时间占比和设备性能利用率的影响曲线。

Figure 7 Influence of pipelining bubble time and device effective with the number of micro-batch图7 微批次的划分数量对流水建立时间和设备利用率的影响
假设流水建立时间对整个训练时间的影响为Ppipe(batch_num),设备利用率损失为Dloss(batch_num),则batch_num需要满足以下条件:
min(Ppipe(batch_num)+Dloss(batch_num))
(2)
满足式(2)的batch_num能够使设备间的流水效果和设备的利用率达到一个均衡的状态,进而整个系统的性能达到最优状态。本文采用二分查找方法找到batch_num最优解的。假设总的处理批量大小为Batch_size,混合异构平台中的设备最大处理批次为Batch_device,流水线长度为Pipe_num。流水线建立的时间占比为:
(3)
设备利用率损失为:
(4)
通常式(4)计算得到batch_num,划分后的微批次由式(5)计算得到:
(5)
为了防止计算得到的micro_batch不为整数,对每个micro_batch进行±1微调,使其都为整数且相加等于总的批处理大小。
表1以ResNet50模型为例说明了流水线的长度与Batch_size如何进行选择。每次处理的总批量为256,混合异构平台中以8个GPU为例,每个GPU处理的最大Batch_size为64。通过二分法查找得到表1的划分结果。

Table 1 Result of micro-batch on ResNet50 with hybrid heterogeneous devices表1 混合异构架构下ResNet50的划分结果
5 实验
首先,本文对比在混合异构平台上模型并行算法与数据并行算法在精度上的差别,以标准的ResNet50模型在单个GPU上训练的精度(图8中的Original)为基准,分别对比了数据并行和模型并行在混合异构平台中的表现。实验采用2种不同型号(2个NVIDIA Tesla V100和2个NVIDIA Tesla M4)的GPU设备,这2种型号的GPU设备在性能上有一定的差别。实验环境如下所示:
CPU:2路Intel(R)Xeon(R) CPU E5-2690 v3 @ 2.60 GHz(每个CPU包含12个物理core,24个thread cores);FPGA:Inspur F10S板卡x1;GPU:NVIDIA Tesla V100 ×2 NVIDIA Tesla M4 ×2;RAM:629 GB;OS:CentOS Linux release 7.6.1810 (Core);Kernel version:3.10.0-514.el7.x86_64;输入图像:ImageNet2012。
为了充分利用每个设备的性能,在数据并行时,给不同型号的GPU设备设置的Batch_size是不一样的,例如,NVIDIA Tesla V100每次处理的Batch_size设置为128,NVIDIA Tesla M4每次处理的Batch_size设置为64。在使用本文模型进行并行训练时,首先把2个NVIDIA Tesla M4合并成一个设备,使流水线长度减小为3;然后用层级并行和通道并行的混合并行策略把ResNet50模型分配到各个设备上;最后选取合适的微批次划分(32×4),使整个设备群的流水状态达到平衡。通过实验发现,模型并行训练方法可以弥补混合异构架构中数据并行训练时出现的精度损失问题,如图8所示,数据并行训练算法训练过程前期精度波动较大,通常需要更多的训练周期才能达到相同的精度Top-1 accuracy,如图9所示。

Figure 8 Accuracy of data parallel and model parallel on hybrid heterogeneous platform图8 混合异构架构下数据并行算法 与模型并行算法的精度(Epoch=90)

Figure 9 Accuracy curve of data parallel and model parallel on hybrid heterogeneous platform图9 混合异构下精度收敛曲线对比
然后,与Google提出的Gpipe模型并行流水算法在单异构和混合异构平台上的性能表现进行对比。与传统的模型并行流水算法(Gpipe)相比,通过本文方法优化之后的模型并行流水算法性能得到了相应的提升。本文基于Gpipe与TensorFlow实现了ResNet50的模型并行流水训练,并且成功地部署到CPU、GPU和FPGA设备上进行训练。本文分别在完全由GPU组成的单异构训练环境和由GPU与FPGA共同组成的混合异构训练环境进行了实验验证。通过本文模型划分策略和批次大小调整以后,单异构环境下ResNet50模型的训练性能比Gpipe框架提升了3%~4%,如图10所示。对于由GPU和FPGA组成的混合环境,由于FPGA设备性能的限制,只把模型的最后2层放到了FPGA设备上。实验表明,混合异构环境下经过本文提出的混合并行策略和批次划分方法优化之后,比传统的模型并行流水算法的性能加速比提升了7%左右,如图11所示。

Figure 10 Speedup of Gpipe and our method on single heterogeneous platform图10 单异构环境下性能加速比

Figure 11 Speedup of original and our method on hybrid heterogeneous platform图11 混合异构环境下性能加速比
6 结束语
本文提出了2种适用于混合异构架构平台的模型并行训练优化方法。首先针对混合异构平台中设备性能的差异性提出了混合层并行和通道并行的模型划分策略,相比简单的层并行方法,这种策略对模型的划分更加精细,能够更加充分地利用设备性能。然后本文给出了一种动态划分微批次的方法,该方法中的2个原则能够使设备间流水线的建立和设备利用率达到平衡,进而能够最大限度地减小流水线建立的时间占比和提高设备的利用率。相比于数据并行方法,本文提出的模型并行方法能够解决数据并行在混合异构架构中因设备性能分布不均带来的精度损失问题。相比传统的模型并行算法(Gpipe)具有更好的加速比,在单一类型设备的异构平台上的训练性能加速比提升4%左右,在混合异构平台的训练性能加速比相比没有使用优化方法之前能够提升7%左右。
猜你喜欢
小学教学研究(2022年5期)2022-04-28
文苑(2020年10期)2020-11-07
小学科学(学生版)(2020年2期)2020-03-03
天津诗人(2017年2期)2017-11-29
中国洗涤用品工业(2017年2期)2017-04-16
电信科学(2016年11期)2016-11-23
通信电源技术(2016年6期)2016-04-20
中国资源综合利用(2016年9期)2016-01-22
视野(2015年6期)2015-10-13
福建人(2015年10期)2015-02-27
