
一种大流量报文HMAC-SM3认证实时加速引擎*
2021-02-03 04:08李丹枫赵国鸿
计算机工程与科学 2021年1期
李丹枫,王 飞,赵国鸿
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
随着互联网普及率的提高,人类社会越来越依赖以IP为核心的互联网基础设施。然而,网络核心架构在设计初期未能充分考虑密码安全问题,网络IP报文通信面临着源地址欺骗、内容篡改、报文注入和DDoS等威胁。使用消息验证码MAC(Message Authentication Code)正是保证信息真实认证和完整性的一种高效解决方案[1]。
消息验证码是经过特定加密算法生成的一段二进制码。通信双方在收发消息时,利用提前共享的密钥通过加密算法计算出该消息的验证码,在共享密钥未泄露的前提下,消息验证码可保证通信双方消息来源可靠且未被篡改。计算MAC的加密算法通常基于密码杂凑算法[2],即基于Hash的消息验证码HMAC(Hash-based MAC)算法。杂凑算法可将任意长度的明文映射为固定长度的杂凑值且过程不可逆,是验证消息完整性的通用手段。目前常用的国际标准杂凑算法包括SHA-2系列(SHA-256,SHA-384和SHA-512)和SHA-3。我国于2010年公布了具有完全自主知识产权的SM3密码杂凑算法[3],可以为HMAC内部核心算法的安全性提供有效支撑。
目前关于SHA系列算法的研究较多,而关注SM3算法的研究较少,相关研究大多停留在算法硬件实现效率提高上,例如通过开发SM3算法的流水化[4]进行优化,但没有将流水技术进一步拓展到HMAC-SM3中,更缺乏将SM3应用到自主网络报文验证的相关研究。核心网络流量大、流认证密钥维护量大、要求延迟低,需要高性能SM3加速引擎和多流报文及密钥管理系统支撑。
本文首次提出并设计面向大流量网络报文的HMAC-SM3实时加速引擎方案,通过大流量报文-密钥对输入输出管理和SM3计算核流水处理,能够实时完成大流量报文HMAC计算任务。设计了基于存储地址的报文-密钥对快速存储匹配技术,开发了多报文乱序哈希下的有序输出架构,并通过展开SM3的轮计算设计了流水化的SM3子模块,可在同一时刻进行64条报文-密钥对的HMAC-SM3计算。实验表明,本方案在Stratix IV平台上最高时钟频率为172.41 MHz,平均吞吐量为65.18 Gb/s,在相同平台Cyclone IV上是现有的串行HMAC-SM3验证方案[5]吞吐量的34.86倍。
本文第2节分析国内外相关工作,第3节介绍HMAC算法和SM3算法,第4节阐述加速引擎设计方案,第5节为实验分析,最后在第6节进行小结。
2 相关工作
决定HMAC算法安全性和实现效率优劣的关键在于杂凑函数的选择。在安全性方面,SHA-2算法是SHA-1算法的摘要输出加长版本,计算方式未有本质区别,而后者已于2005年被破解[6],虽然至今尚未出现对SHA-2有效的攻击,但其安全性仍不断受到质疑[7 - 9]。在此背景下,美国国家标准与技术研究院NIST(National Institute of Standards and Technology)于2015年批准发布了SHA-3算法,安全性得到了提高[6,10]。对标国际标准,我国自主提出SM3算法,其安全性相关数据已由文献[11,12]量化给出。
SM3密码杂凑算法作为中国标准,急需高效的自主可控实现与应用。文献[12]在XILINX Virtex-5平台上对比了SHA-256、SHA-512、SHA-3和SM3的实现效率,其中SM3的FPGA实现面积最小,吞吐量面积比仅次于SHA-3,总体效率与SHA-256相当。文献[4]对SM3算法实现了流水化展开,并通过发掘算法计算步骤中的流水潜能,缩短了SM3单轮计算周期,实现了73.54 GB/s的高吞吐量。文献[5]将SM3与HMAC相结合并在FPGA上仿真实现,由于采用串行SM3验证核,吞吐量仅为1.02 GB/s,无法满足大流量的网络报文验证需求。
目前尚未有将SM3密码杂凑算法应用到核心网络多发大流量报文实时认证的研究。本文提出的带有多流消息及其认证密钥存储、调度和处理设计的HMAC-SM3实时加速引擎能够满足大流量网络环境中报文的实时认证需求。
3 算法介绍
3.1 HMAC算法
HMAC算法是一种带密钥的消息鉴别码算法,用于校验数据完整性和来源合法性,适用于任何安全体系结构、进程或应用的安全服务。美国联邦信息处理标准FIPS(Federal Information Processing Standards)对HMAC算法过程的定义为:
HMAC(K0,text)=
H(K0⊕opad,H(K0⊕ipad,text))
(1)
其中,K0为通信双方提前共享的密钥,H为Hash函数,text为待验证数据,opad和ipad为算法定义的常数。FIPS标准中给出的HMAC算法流程如图1所示。

Figure 1 Flowchart of HMAC algorithm图1 HMAC算法流程
3.2 SM3算法
SM3是我国发布的一种基于分片迭代结构的密码杂凑算法,它将长度l不超过264比特的消息m经过预处理、消息拓展和迭代压缩3个步骤,生成256比特杂凑值。
算法1SM3
输入:长度为l的比特序列m。
输出:256比特杂凑值。
步骤1(预处理):在消息的末尾添加一个比特“1”和k个“0”,其中k是满足l+1+k≡448 mod 512的最小的非负整数,将长度为l的二进制表示以64位比特串的格式添加至消息末尾,最后把填充后的消息m′按512比特进行分片:m′=B(0)B(1)…B(n-1),其中n=(l+k+65)/512。
步骤2(消息拓展):
(1)将消息分片B(i)划分为16个字W0,W1,…,W15;
(2)定义置换函数
P1(X)=X⊕(X<<<15)⊕(X<<<23);
FORj=16TO67
Wj←P1(Wj-16⊕Wj-9⊕(Wj-3<<<15))⊕(Wj-13<<<7)⊕Wj-6
ENDFOR
(3)FORj=0TO63
W′j=Wj⊕Wj+4
ENDFOR
步骤3(迭代压缩):设A、B、C、D、E、F、G、H为8个32位寄存器,迭代过程Vi+1=CF(V(i),B(i)),0≤i≤n-1,压缩函数CF描述如下:
(A,B,C,D,E,F,G,H)←V(i);/*将V(i)的值平均分为8个部分,并按照从高到低的顺序分别存入A~H中*/
FORj=0TO63
SS1←((A<<<12)+E+(Tj<< SS2←SS1⊕(A<<<12); TT1←FFj(A,B,C)+D+SS2+W′j; TT2←GGj(E,F,G)+H+SS1+Wj; D←C; C←B<<<9; B←A; A←TT1; H←G; G←F<<<19; F←E; E←P0(TT2); ENDFOR Vi+1←(A,B,C,D,E,F,G,H)⊕V(i); 其中,V(0)设置为初始值7380166f4914b2b917244 2d7da8a0600a96f30bc163138aae38dee4db0fb0e4e,置换函数P0(X)=X⊕(X<<<9)⊕(X<<<17),布尔函数 FFj(X,Y,Z)= GGj(X,Y,Z)= 最终输出的Vn即为256比特杂凑值。 加速引擎系统设计可分为消息缓存(Message Buffer)、输入调度(Message Dispatch In)、SM3计算、输出调度和输出排序(Output Reorder)等5个模块,整体实现如图2所示,输入报文-密钥对,加速引擎系统按输入报文顺序输出对应的HMAC计算结果。报文Data与密钥Key经RAM缓存后进入输入调度模块,该模块按HMAC步骤生成需要进行SM3计算的参数组(Message,Abstract),同时通过控制单元生成一个包含本次HMAC执行步骤码、初始缓存地址的信号,与SM3计算结果一同输入输出调度模块,用于同步本次计算的状态信息。输出调度模块根据HMAC执行步骤码识别HMAC算法完成度,判断将本轮SM3结果和初始缓存地址输出至输出排序模块或回传至输入调度模块准备下一轮SM3计算。输出排序模块根据初始缓存地址对收到的HMAC值进行排序输出,完成计算并回收地址。 Figure 2 Structure of acceleration engine图2 加速引擎结构 需要说明的是,网络报文进行SM3计算时需切割为若干个512比特数据包并按SM3算法要求填充,本文将切割填充放在了加速引擎系统外部执行,即默认输入的报文均为若干组带2比特首尾标志位的共514比特的分片数据包。 缓存模块通过FIFO(First In First Out)存储器缓存外部输入的认证密钥,并由一个地址管理FIFO给出空闲的密钥存储RAM(Random Access Memory)地址,控制密钥流入RAM。系统初始化时,向地址管理FIFO顺序写入密钥存储RAM的所有地址,表示全部RAM空闲。当接收到密钥后,由地址管理FIFO弹出空闲地址,将密钥写入RAM的对应地址中,完成密钥装载。使用密钥时,地址信息将作为本条密钥生命周期里的唯一标识,跟随密钥一同传输。最后,输出排序模块输出计算完毕的HMAC值时,表示一条密钥已使用完毕,加速引擎系统会将该密钥地址回传至缓存模块的地址管理FIFO,说明该地址下的密钥已无效,完成密钥卸载和地址释放。 Figure 3 Schematic diagram of message storage address allocation图3 报文存储地址分配示意图 存储报文时,缓存模块采用了(基址,拓展地址)的二维地址分配方式。如图3所示,加速引擎系统分配报文存储地址时,以报文对应的认证密钥地址为基址,再为报文存储RAM分配额外的5比特拓展地址,使每个报文有独立的25*514比特的存储空间,在满足了TCP/IP网络协议下的最大长度报文存储的同时,通过基址比对保留了密钥与报文的对应关系。 分析SM3算法可知,对于报文的每个分片都需要进行64轮迭代压缩计算,并且前一个分片的最终迭代压缩计算结果会作为参数参与下一个分片的计算,即同一报文的分片在计算SM3杂凑值时存在数据相关,故只能开发不同报文之间的流水化潜能。本方案中SM3计算模块流水结构如图4所示。 Figure 4 Pipeline structure of SM3 computation module图4 SM3计算模块流水结构示意图 T1周期开始时,报文Message1的第1块分片M1_1输入SM3计算模块的0号计算单元Unit0,在T1周期内进行第1轮迭代压缩。T2周期开始时,M1_1第1轮迭代压缩计算结果进入1号计算单元Unit1,在T2周期内进行第2轮迭代压缩,同时另一报文Message2的第1块分片M2_1进入Unit0进行第1轮迭代压缩计算。以此类推,后续T3~T64周期开始时均有不同报文的分片输入Unit0,同时Unit(n)的计算结果输入Unit(n+1)进行下一轮迭代压缩计算。直至第64个周期后,M1_1分片的64轮迭代压缩计算完毕,计算结果在下一计算周期T65与Message1的下一分片M1_2一同回传至Unit0开始新一轮的迭代压缩计算。 考虑到SM3算法有64轮迭代压缩计算,本计算模块通过对每一轮迭代压缩设置独立的计算单元,使得在输入数据量足够的前提下,SM3模块可以同时进行64组SM3计算。除最初63个周期外,每一个计算周期结束后都有一个分片完成整个迭代压缩计算并将结果输出,从而让整个SM3计算模块的流水化性能达到饱和。 SM3计算模块整体结构如图5所示。 Figure 5 Overall structure of SM3 computation module图5 SM3计算模块整体结构示意图 图5中消息拓展逻辑Expend_n和计算逻辑SM3_n共同组成一级计算单元。计算逻辑按照SM3算法中迭代压缩部分的算法设计,不作过多介绍。消息扩展逻辑用于生成SM3算法中的Wj和W′j。在SM3算法中,Wj生成了68次,前16次直接从输入报文Message中截取得到,后52次需计算生成;W′j生成了64次,通过Wj与Wj+4按位异或计算得到。然而,SM3算法的第n轮迭代压缩计算中仅用到了相对应的参数Wn与W′n,故基于本模块的流水线结构可对SM3算法模块进行优化,各级计算逻辑无需等待所有的Wj、W′j生成完毕,只需得到对应的Wj、W′j参数便可开始计算。分析SM3算法可知,在第0~11轮中,Wj、W′j可直接从输入的Message中截取得到;自第12轮开始,Wj仍可直接从输入的Message中截取得到,每轮仅需计算出一个新的Wj+4用于计算W′j,并将Wj+4附于Message之后,同时去除Message头部等长的比特,输入下一轮消息拓展逻辑,之后的消息拓展逻辑重复同样的操作,直至循环的最后一轮。优化后的SM3算法模块将计算逻辑与Wj、W′j生成逻辑并列执行,缩短了计算时间。 网络报文长短不一,基于本方案的流水验证机制,可能存在后传入的短报文由于分片较少,会先于先传入的多分片长报文完成HMAC计算的情况。本方案出于通用性考虑,未对HAMC输出结果作更多标识,只将输出顺序作为输出与输入的唯一对应关系,故需要对HMAC计算结果进行排序处理。由前文阐述可以看出,消息缓存模块所分配的初始缓存地址即包含了收到数据的顺序信息,故可根据该地址进行排序。在输出排序模块中设置寄存器Current_Address,用于记录当前应输出HMAC值的消息对应的初始缓存地址的基址部分,该寄存器初始化时设为0。当输出排序模块收到上游模块传来的HMAC值和初始缓存地址时,将初始缓存地址的基址部分与Current_Address中的值进行比对,若相同则直接输出,Current_Address中的值自增加1;否则以基址地址存入排序RAM,并将该地址的值有效位置1,待Current_Address中的值指向该地址时再输出。 本节采用Verilog硬件描述语言,使用Quartus Prime与Modelsim搭建编译仿真软件环境,分别在Stratix IV和Cyclone IV平台上基于本方案编译生成仿真系统,验证前文所述功能。 向仿真系统内依次输入2,5,10段514 bit数据包及其对应的64 bit密钥,以2 bit首位标志位区将其分为3个网络报文包,测试多个网络报文连续输入情况下系统功能的正确性。仿真结果显示,系统分别于第313,546和932个时钟周期输出正确计算结果。继续向系统内依次输入10,2,5段514 bit数据包及其对应的64 bit密钥,测试计算量大的长报文需先输出结果的情况下系统功能的正确性。仿真结果显示,系统分别于第921,924和925个时钟周期输出正确计算结果。上述实验表明,本方案能够完成实时认证和有序输出。 为测试本方案在网络环境中的延迟和吞吐量,向系统输入10 000组报文,当输入的网络报文平均分片数量为1~32时,每组报文的平均延迟如图6所示。不同平均分片情况下系统吞吐量变化如图7所示。由图6和图7可知,网络报文经过本系统的平均延迟与报文平均分片数量大体呈线性关系,而吞吐量随着报文平均分片数量增多而增大,但增长趋势逐渐缓慢,最终趋于平稳。 Figure 6 Packet average delay with different number of segments图6 报文平均延迟随分片数量变化趋势图 Figure 7 Average throughput with different number of segments图7 平均吞吐量随分片数量变化趋势图 经仿真,本设计方案最高时钟频率达到了172.41 MHz(基于Stratix IV平台),在此时钟频率下平均延迟为129.15 ns,平均吞吐量可达到65.18 Gb/s。与其他文献中的设计实现结果的对比如表1所示。从表1中可以看出,通过应用流水化技术,相同条件下本方案吞吐量是串行HMAC-SM3吞吐量的34.86倍。 本文提出了一种在FPGA平台上进行大流量网络报文HMAC实时认证的方案,通过SM3流水化机制、报文-密钥对快速存储匹配技术和有序输出架构,实现了网络报文的高效验证。实验结果表明,在大流量报文环境中,本方案的实现性能优良,可在高速网络HAMC认证相关应用场景发挥良好的作用。SM3计算模块每5个时钟周期才能输出一个计算结果,是本方案的瓶颈,故在下一步的工作中,可设置多个SM3计算模块,通过多核并行方式进一步提高本方案的吞吐量。 Table 1 Comparison of implementation performance 表1 实现性能对比
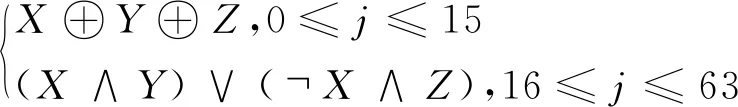

4 加速引擎系统设计
4.1 总体结构

4.2 报文-密钥对快速存储匹配

4.3 SM3计算模块流水设计与优化


4.4 报文输出排序
5 功能验证与实验分析


6 结束语

猜你喜欢
词学(2022年1期)2022-10-27
数学物理学报(2020年5期)2020-11-26
文苑(2020年10期)2020-11-07
广东通信技术(2020年10期)2020-10-26
火控雷达技术(2018年4期)2019-01-15
天津诗人(2017年2期)2017-11-29
集装箱化(2017年4期)2017-05-17
集装箱化(2016年11期)2017-03-29
集装箱化(2016年12期)2017-03-20
视野(2015年6期)2015-10-13
