
融合社会关系的社交网络情感分析综述*
2021-02-03 04:08张祖凡甘臣权
计算机工程与科学 2021年1期
张 琦,张祖凡,甘臣权
(重庆邮电大学通信与信息工程学院,重庆 400065)
1 引言
社交网络情感分析又称意见挖掘,通过利用自然语言处理技术挖掘社交网络中用户的观点、态度和情感[1 - 3]。许多研究学者对社交网站中的内容进行了情感分析[4],并挖掘了社交网络上用户的情感和潜在的观点。目前该研究有着广阔的应用场景,比如企业可以准确获取客户对于产品的反馈信息[5,6],根据反馈信息进一步提高产品质量,制定更高效的产品推广方案;政府通过舆情监督可以对公共事件做出快速应答,并利用社交网站上的社会关系数据进行情感分析,实现对互联网用户的情感疏导。目前对于内容长且正式的文本进行情感分析取得了较为满意的结果,但是社交网络中的文本较短、语法不规则、语言表达形式丰富且包含较多的数据噪声,加剧了词汇稀疏问题,因此传统的文本情感分析方法用于社交网络中的情感分析时性能急剧下降。但是,社交网络中包含许多其他有价值的信息,比如用户间交互产生的社会关系信息[7 - 9]、微博文本内容包含的多种表达形式等。利用用户间的社会关系可以生成对用户的个性化推荐[10 - 13],预测个体用户、群体的情感或行为[14 - 18]。除此之外,许多学者将社会关系与社交网络情感分析结合起来[19 - 25],根据用户间的关系强度建立情感之间的联系,可以提高对语义模糊博文情感分析的准确率或是模拟出社交网络中用户的情感变化、行为与决策选择。如何利用社交网络自身的特点进行情感分析成为值得研究的课题。
本文根据对用户间社会关系的研究和社交网络情感分析2个主要方面展开介绍,论文结构如下:第2节介绍了社会关系的研究和应用,主要包括社会关系的定义、影响社会关系的因素及社会关系的度量方法和应用;第3节详细阐述了对社交网络进行情感分析的方法和常用数据集;第4节描述了融合社会关系的社交网络情感分析的研究进程;第5节描述了研究趋势与展望;最后一节进行了总结。
2 社会关系的研究和应用
社会关系属于社会学中的关系社会学范围,用于定义2个或多个个体之间的关系类别,根据个体的行为判断个体之间的关系。目前主要识别的社会关系有组关系 (Groups)、亲属关系 (Kinship)、活动与交互关系 (Activities and Interactions)和具体的关系 (Detailed Relationship)[26]等,如图1所示。由于本文主要探讨社交网络中人与人之间的社会关系,所以这部分内容主要介绍社会关系中的活动与交互关系。
社交网络平台的蓬勃发展使得用户间的交流越来越频繁,用户间的社会关系也越来越紧密。人们不再局限于对内容的分享,还会受到情绪间的感染和传播,这种影响会沿着用户关系网不断地扩散,进而对用户的行为和情感状态产生影响。根据社交网络上用户间丰富的交互信息,可以分析出用户间的社会关系,利用用户间的社会关系信息可以实现对用户的个性化推荐、预测用户的行为以及进行舆情监督,因此研究用户之间的社会关系有着重要意义。

Figure 1 Social relationship classification diagram图1 社会关系分类图
2.1 社会学理论
随着社交网络平台的发展,已有许多研究表明和证实了依据社会学理论可以对社交网络上的信息进行有效的分析,该理论也被广泛应用于社交网络的情感分析中,比如社会学中的同质性[27]、情绪感染[28]和社会影响[29]等。当处于某种情感状态时,人们一般不会将情绪隐藏起来,而是倾向于表达情感[30],所以社交网络平台上蕴含着丰富的情感信息。
(1)社会同质性。
社会同质性是指人们倾向于与自己相似的人做朋友,在现实生活中具有相似兴趣爱好的人更容易聚集到一起。Leskovec等人[7]通过对4个大型社交网络平台进行分析,证明了社会同质性的存在。文献[27]的进一步研究表明,在社交网络中具有相似属性的用户有着相似的行为表现,而且用户更倾向于与自己相似的人成为朋友。此外,Bollen等人[31]对具体的社交网络平台Twitter进行了分析,结果表明Twitter上的用户对幸福感也存在同质性现象,即用户更倾向于与具有相似幸福感的人进行交互。
(2)情绪感染。
人们通常通过面部表情、声音的起伏和姿势的反馈去感染他人的情绪,这种现象在社会科学中被认为是情绪的感染。情绪感染在人际关系中有着重要的作用,它可以潜移默化地促进行为的同步性和对他人情感的追踪。情绪感染理论最早由Hatfield等人[8]提出,该理论将情绪感染定义为人们倾向于自动模仿和同步他人的表情、发音、姿势和动作。张茗等人[32]还进一步证明了微信中也存在着情绪感染,而且感染后的情绪强度与用户间关系的亲密程度有关。
(3)社会影响。
当今社会人们之间的交互活动越来越频繁,在人与人之间频繁互动的过程中人们不可避免地相互产生影响,通过这种相互影响,使得人们不断地调整自身行为以与朋友保持一致性,随着时间的增长,人们与他们的朋友越来越相似,这称为社会间的影响作用。Bond等人[9]对2010年Facebook上6 100万人对美国国会选举投票的行为进行了研究,结果表明网站上的信息不仅影响了接收到它们的用户,还影响了用户的朋友,以及朋友的朋友,验证了社会影响会对用户的决策行为产生影响。文献[33]对社交网站上个体评分和评论行为进行了研究发现,积极和消极的社会影响产生了不对称的羊群效应,也表明了社会影响会改变用户的看法和观点。
以上研究表明,人的情感会受到周围环境和他人的影响,相似的人倾向于相似的情感趋向、相似的观点和相似的行为,如何挖掘社交网络中的社会学特性是一个值得深入研究的课题。
2.2 社会关系强度的度量方法
根据社会学理论,用户之间存在着某种社会关系,这种社会关系影响着人们的情绪表达和行为选择,如何度量用户间的社会关系强度是运用社会关系解决问题的关键。用户在注册社交网络账号信息时,需要设置个人信息,比如名字、年龄、出生日期、居住地、受教育程度和兴趣爱好等。根据社会同质性理论,信息相似度高的用户倾向于聚集到一起,对同一事件趋向于发表相同的观点。除了根据用户设置的个人信息可以找到相似的朋友之外,当用户在社交网络上浏览内容信息时,也会受到其他用户的情绪感染或社会的影响,当用户对博文内容表示赞同时,会产生点赞、转发和评论等行为,通过这些行为进一步加强了用户间的社会关系强度。根据社交网络上的信息,许多学者对社会关系强度的度量展开了研究。
文献[10]构建了社会信任模型,通过利用用户的个人信息进行相似性度量,特别考虑了用户间的兴趣相似度,用于图书推荐。Akcora等人[34]分别从网络相似度和个人资料属性进行用户间相似性的度量,其中,网络相似度是指2个用户分别与其他用户的网络连接结构的相似度。
由于用户在社交网络上可以通过多种交互行为建立社会关系,片面考虑用户间的相似性并不能准确度量出用户间的关系强度,在此基础上许多学者考虑了更多的因素用于关系强度的度量。陈增等人[35]从位置、时间和用户等多方面对社会关系进行了度量。文献[36,37]利用了用户的个人信息和交互活动计算不同用户间的关系强度。除此之外,文献[38]针对微信朋友圈的特点,提高了关系强度计算结果的准确性,并根据相似度和交互活动计算目标用户和他的微信朋友圈朋友之间的关系强度,综合考虑用户资料信息、微信订阅、点赞、评论、回复和收藏等多种影响因素。Lin等人[39]提出了一种基于信任传播策略和直接关系强度的加权社会网络图中关系强度的计算方法,通过关系路径的长度、关系路径的数量和关系路径的边权(直接关系强度)估计间接关系的强度,综合直接关系强度和间接关系强度来表示社交网络中2个用户之间的关系强度,此方法充分估计了社交网络中任意2个用户之间的关系强度。史殿习等人[40]根据日常轨迹、语义位置和语义标签3个因素度量了朋友之间的关系强度,该方法实现了对朋友间关系强度的度量。
大多数的关系强度评估方法将所有的交互活动混淆在一起,没有考虑到相同用户之间的关系强度在不同的活动领域会有显著的差异,测量在不同活动领域的关系强度似乎更合理,也更加符合现实情况。Ju等人[41]提出了一种新的度量在线社交网络关系强度的模型,该模型针对特定活动领域利用余弦相似度计算个人信息属性的相似性,利用Jaccard系数计算关注公众号的相似度,利用用户间的交互时间线、语言间的情感相似度等因素计算微博用户间的关系强度。文献[42]提出了一个基于3个信息源的通用框架来衡量不同用户在不同活动领域的关系强度:用户个人信息的相似性、用户名的共现性和交互活动。Zhao等人[43]提出了一个衡量不同用户之间关系强度的通用框架,不仅考虑了用户的个人资料信息,还考虑了交互活动和活动领域。
2.3 社会关系的应用
社会关系在一些研究中得到了广泛的应用。比如,社会关系被应用于推荐系统[10-13]。由于相似的用户有着相同的偏好或行为习惯,通过构建用户间的关系模型,在图书、电影等方面实现对用户的个性化推荐。除了利用社会关系生成对用户的个性化推荐,研究者们还利用社会关系对用户情感的变化趋势和行为的决策进行了研究:Zeng等人[19]通过消息发出部门的威信力、用户主观判断能力和情绪感染等因素刻画出用户对于社会事件反应的情感变化趋势;文献[14]提出了交互感知传播网络,通过考虑各种交互因素,比如不同社会角色之间的影响程度、不同话题间的交互和情感之间的感染交互,预测了用户在这些因素影响下传播消息的概率;文献[15]提出了Social Tie Channel模型,根据邻居节点的影响、内容的内在属性等因素,以较高的精度预测了用户分享内容的概率。进一步,一些研究将社会关系从对个人层面的影响上升到对群体行为演化过程的预测[16 - 18],并根据社会学理论模拟了政治集会、发生火灾或爆炸情况下人的移动方向和行为选择。此外,还有研究通过用户间的相似性、交互频率和交互结果的情感趋向构建社会关系,以此为基础实现了对设备到设备通信中资源的最优分配[44]。
以上研究表明:社会关系在用户个性化推荐、情感趋势和行为预测、资源分配等方面的研究发挥了重要的作用,为研究融合社会关系的社交网络情感分析奠定了基础。
3 社交网络情感分析
融合社会关系的社交网络情感分析的另一关键问题就是对情感进行分析,其中主要包括对情感分析方法的选择和对社交网络数据集的采集,下面进行详细的介绍。
3.1 情感分析的方法
在融合社会关系的社交网络情感分析中,对用户间的社会关系进行准确度量后,利用用户间的社会关系对特征数据进行扩充,最后进行情感的分析。所以,对情感分析方法的选择对情感分析的准确率有着重要的影响。表1列举出了常用的社交网络情感分析方法的优势和不足,下面对常用的社交网络情感分析方法进行具体的介绍。
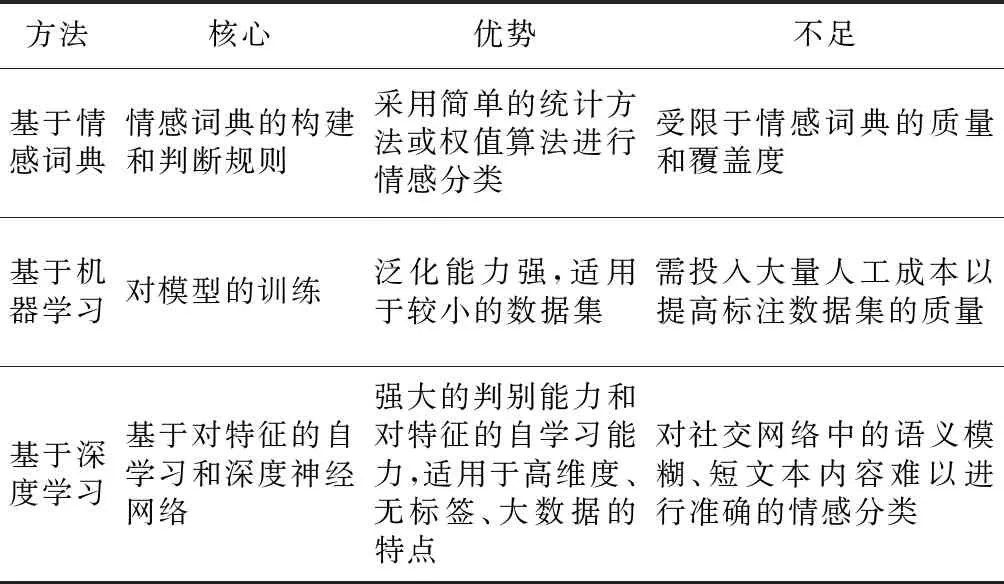
Table 1 Comparison of sentiment analysis methods in social networks 表1 社交网络情感分析方法对比
(1)基于情感词典和机器学习的情感分析方法。
基于情感词典的情感分析方法,是在标注极性或极性分数单词的基础上,通过比对情感文本中包含的极性情感词,然后采用权值算法或简单统计的方法进行情感分类。由于此方法不需要训练数据,因此被广泛应用于传统的文本情感分析中[45]。在社交网络中也普遍采用基于情感词典的方法,SentiStrength是适用于社会媒体的一种算法,该算法以包含社交网络中经常使用的单词和短语的词汇库[46]为基础,可以对非正式文本的情感进行有效识别。在此基础上,Hutto等人[47]在2014年提出了一种基于词库和语法规则的文本情感识别方法Vader,该词库包括由人工标注的Twitter中常用的情感词,判定了情感极性和强度,同时考虑了语法规则对情感判别的影响。Saif等人[48]进一步开发了一种适用于Twitter情感分析的以情感词典为基础的方法SentiCircles,该方法考虑了词汇在不同语境下的共现模式,对词汇极性和词汇得分进行了更新。
机器学习方法也被应用于情感分析领域。首先需要建立一个训练集,并根据用户情绪对数据进行标记;然后从训练集中提取一系列特征,将其输入到分类器方法中,常用的分类方法有朴素贝叶斯NB (Naive Bayes)、支持向量机SVM (Support Vector Machine)和随机森林 (Random Forest)等;最后通过分类器对未标记数据进行情感倾向性判定。基于机器学习的方法的流程如图2所示。林江豪等人[49]提出了一种利用朴素贝叶斯分类器对收集的热门微博话题和酒店评论进行文本情感分类的方法。此外,机器学习方法也被用于区分推文内容的正负极性,文献[50]提出了一种改进分类的方法,通过利用SentiWordNet和NB提高了推文分类的准确性。朴素贝叶斯具有复杂度低、训练过程简单等优点,从而被广泛应用于文本情感分类任务中,但也存在数据稀疏性问题。Torunoglu等人[51]为了解决稀疏性问题,提出了一种基于Wikipedia的语义平滑方法,实验结果表明该方法提升了朴素贝叶斯的性能,对推文情感分析的准确率甚至超过了支持向量机。

Figure 2 Flow chart of sentiment analysis based on machine learning图2 基于机器学习的文本情感分析流程图
从上述分析可知基于情感词典和机器学习的方法被广泛应用于对社交网络的情感分析中,基于情感词典的情感分析方法易于理解,对情感分类的计算较为简单,然而分类准确率受限于情感词典的构建和判断规则的质量,限制了该方法使用的广度。基于机器学习的方法与基于情感词典的方法相比,有较强的泛化能力,并且适用于较小的数据集,但是对模型的训练效果依赖于被标注数据集的质量,获取高质量的数据集需要投入大量的人工进行数据标记。所以,基于机器学习的方法需要依靠大量人工获取标记数据,以获取较高的分类准确率。
(2)基于深度学习的情感分析方法。
常用的神经网络模型主要有长短期记忆网络LSTM(Long Short-Term Memory)、卷积神经网络CNN(Convolutional Neural Network)及其变体等。LSTM包含输入门it、遗忘门ft和输出门Ot3个门控单元,其中输入门决定当前时刻的输入信息和前一时刻更新的状态;遗忘门决定需要遗忘的不必要信息;输出门决定要从细胞单元输出的部分。通过门控控制,实现了信息的选择性流动,使得LSTM获得了长期记忆,可以捕获文本间的长期依赖关系,从而可以根据上下文信息预测下文出现的单词的概率。CNN是一种前馈神经网络,其结构图如图3所示:输入层的输入为多维数据,比如二维的词向量表示;卷积层通过多个卷积核对输入数据的卷积运算实现对信息特征的提取;池化层对卷积层生成的特征进行选择和过滤,以提取关键特征;全连接层可将生成的特征图转化成向量形式,以便于输出层计算相应的概率值。由此可知CNN可以有效地提取出文本中的信息特征。

Figure 3 Structure diagram of CNN
图3 CNN结构图
随着在计算机视觉领域的成功应用,深度学习成为近年来的研究热点。不同于依赖带标签数据的数目和特定的领域范围的机器学习方法,基于神经网络自动提取特征的深度学习方法在自然语言处理领域被广泛应用,比如词嵌入 (Word Embedding)首先使用深度学习从大量文本数据中学习单词的向量表示,然后用于文档的表示
[52]
;Tang等人
[53]
利用远距离监督收集推文,并从中学习情感特定词嵌入,然后通过3个神经网络学习情感特定词嵌入的特征,从而对Twitter的推文内容进行情感分类;段宇翔等人
[54]
提出一种基于LSTM-CNNs的情感增强模型,对新浪微博文本的情感极性进行了分析;进一步地,文献[55]提出一种利用深度学习对网络文本进行细粒度情感分析的方法;Alharbi等人
[56]
提出了合并用户行为的卷积神经网络模型,将40种用户行为(用户发表各种情感推文的概率、用户的朋友数、推文转发数等)作为训练特征对推文的情感进行了有效的分析。最近的研究
[57,58]
进一步将用户的个性化信息或用户社会关系与文本表现整合起来,提高了模型的有效性。
从以上分析中可知,基于深度学习的情感分析是一种基于对特征自学习和深度神经网络的方法,深度学习强大的判别能力和对特征自学习的能力使得其在处理高维度、无标签的大数据时表现出强大的优势,但是对社交网络中语义模糊的短文本内容难以进行有效的训练,从而影响情感分析的准确率。
3.2 社交网络的数据集
在利用机器学习和深度学习进行文本情感分析时,需要依靠足够的带有情感标签的文本信息进行数据训练,然后根据训练结果预测出未标记情感信息文本的情感极性。现有许多针对社交网络的数据集,除了包含丰富的情感极性信息,一些社交网络数据集还包括社交网络上的信息,比如文本内容的话题、文本ID等。为了获取社交网络上更加丰富的社会关系信息,一些研究者通过API (Application Programming Interface)或者网络爬虫的方式获取社交网络上的数据资源,进行更加深入的研究。下面介绍对经常使用的社交网络数据集和通过API或网络爬虫获取的数据集:
(1)OMD(Obama-McCain Debate)数据集[59]。该数据集包含2008年9月26日Barack Obama和John McCain总统辩论期间发布的3 269条推文,每条推文的情感标签都是通过Amazon Mechanical Turk标注的,情感极性包括积极、消极、混合和其他情感,每一条推文至少有3个土耳其人手动标记推文的标签。
(2)HCR(Health Care Reform)数据集[60]。该数据集由Speriosu等人[60]收集,其中的推文内容涉及2010年3月发生在美国的医疗改革事件,手动标注了数据集的5种情感:积极、消极、中性、不相关和不确定。该数据集共涉及9个主题,每条推文内容都对应其中的一个主题。
(3)STS(Stanford Twitter Sentiment)数据集[61]。Go等人[61]通过Twitter API获取Twitter数据,创建了40 126条包含情感极性的推文集合,情感标签极性为积极和消极。
(4)Sanders Analytics Twitter Sentiment Corpus[62]。该语料库包含5 513条推文,涉及4个话题:Apple、Google、Microsoft和Twitter。语料库中每个条目包含推文ID、推文所属的话题类别和手动标记的情感标签。
除了以上处理好的数据集,为了获得社交网络上更丰富的信息,一些研究者通过API接口或网络爬虫获取数据信息。文献[63]通过新浪微博的搜索API自动访问消息和响应更新时间,获取了新浪微博上的内容信息和更新时间。Zeng等人[19]利用数据收集工具Octopus获取新浪微博中的信息,对含有关键词的内容进行检索,包括用户名、用户ID、发布内容、评论点赞的数量和其他基本信息属性,并将数据保存到Excel表格中。除了对新浪微博进行数据抓取,对Facebook、Twitter等国外社交网站同样可以使用相同的方法进行数据抓取。比如文献[64]使用Facebook Graph API提取了Facebook中的内容和相关信息(发表时间、点赞、分享、评论的数目)。文献[65]从LiveJournal网站中爬取了包含帖子内容、用户间朋友关系和关注关系的数据集,并根据爬取的数据集预测社交网络中网民的情感。
4 融合社会关系的社交网络情感分析
社交网络情感分析旨在从社交媒体网站上发布的信息中提取其中的情感信息。融合社会关系的社交网络情感分析主要通过利用用户间的社会关系构建发布内容之间的联系,对数据进行扩充,以更精准地分析情感。与传统的情感分析相比,社交网络对内容长度的限制、语句内容的随意性以及用户间情绪、行为的相互影响使得对社交网络的情感分析更具挑战性。由于微博内容的短文本形式、表达形式灵活多变,影响了情感分析的准确率。比如当对一个产品进行评论时,若只有很少来自用户的评论,这将对情感分析带来阻碍。为了解决数据稀疏问题,近年来有许多研究者利用社会学理论对数据进行扩充。社交网络平台除了包含发表的内容信息,还包括用户的个人信息和交互行为,主动的交互行为包括关注其他用户,发布微博内容,点赞、评论、转发其他微博内容;被动的交互行为包括被其它用户关注,微博内容被点赞、评论和转发。通过个人信息和交互活动建立起用户间的关系信息、用户和微博的关系信息和微博文本间的关系信息,这些信息在社交网络情感分析领域起到了不可忽视的作用。
Hu等人[20]提出了利用社会学中的情感一致性和情绪感染理论分析推文情感的SANT (Sociological Approach to handling Noisy and short Texts)模型,利用社会关系处理多噪声和简短的文本,该模型证明了利用社会关系分析情感的可行性和有效性。文献[20]在利用社会关系时,考虑了由同一用户发表的内容比任意2条博文内容的情感更具有一致性,以及2条由具有朋友关系的用户发表的内容比任意2条博文内容的情感更具有一致性。由于社会关系不仅局限于用户间的关注关系,所以一些研究在文献[20]的基础上对社会关系进行了进一步具体的量化。比如,文献[21]提出了MSA-USSR (Microblog Sentiment Analysis-User Similarity information and Social Relation information)模型,用于对新浪微博文本进行情感分析。该模型利用用户间关注网络结构相似性、个人基本信息相似性、兴趣相似性和用户间交互频率构建了表示微博内容间相关性的矩阵,实验结果表明,该模型的分类准确率优于SVM和SANT的。此外,Zou等人[22]在SANT模型的基础上又提出了SASS (Sentiment Analysis using Structure Similarity)模型,该模型不仅考虑了用户之间的直接关注关系,还考虑了用户间隐含的联系和话题间的相关性,即有共同朋友的用户成为朋友的概率比随意2个用户成为朋友的概率大,属于同一话题类型的微博文本相似度更高,情感相似度也更高。Lu[23]通过微博内容间的社会联系构建了基于图的半监督分类器SSA-ST (Semi-supervised Sentiment Analysis using Social relations and Text similarities),利用社会关系和文本相似性刻画了微博文本间的关系,然后利用微博文本间的关系将标记数据和未标记数据连接起来,在一定程度上解决了人工标注大量微博数据成本昂贵的问题。文献[24]也提出了一种基于社会关系的半监督情感分类SASR (Sentiment Analysis using Social Relationships)模型,同样通过微博文本的话题相似度和用户间的转发点赞关系构建社会关系。此方法有效减少了对训练数据集的依赖性,同时也取得了较高的分类准确率。以上研究均采用传统的监督学习分类方法,通过最小二乘优化对文本情感分析进行建模,将分类问题转化为优化问题。表2列出了上述利用社会关系进行情感分析的模型所采用的数据集和社会关系以及实验结果。表2中的实验结果表明,以上研究利用社会关系实现了较高的情感分类准确率。
根据以上介绍,有许多研究针对于社交网络中的文本情感分析,通过用户之间交互形成的社会关系构建内容文本之间的联系,为语义模糊内容提高情感判别准确率提供了具有可实施性的方法。但是,对社会关系的研究并不局限于对文本进行情感分析。比如文献[16]对群体行为的选择和情感的变化过程进行了模拟,将SIR (Susceptible Infected Recovered)模型和个人特性因素结合起来构建了情感传染模型,个人特性因素包括情感传送能力 (Extroversion)和情感接受能力 (Empath),通过OCEAN (Openness Conscientiousness Extroversion Agreeableness Neuroticism)模型对个人情感接受能力进行了刻画,通过个人受到的情感感染强度预测个人当前时刻的情感,情感的变化进而会对个人行为的选择产生影响。文献[19]利用社会学理论对流言传播过程中网民的情感变化状态进行了模拟仿真,刻画用户的情感变化状态有利于政府部门快速做出决策。Yang等人[25]根据用户受到不同社会角色好友的情感感染和用户历史情感趋向对用户发表在社交网络上的图像进行情感分析,同样取得了较好的性能。
根据以上分析可知,利用社会关系进行社交网络情感分析取得了较好的分类结果。文献[20-24]利用用户间的社会关系对微博文本内容进行了情感分析,其中,一些研究充分利用了社交网络中存在的用户信息度量社会关系,比如文献[21]综合考虑了在同一话题下用户间关注网络结构的相似性、个人基本信息的相似性、兴趣相似性和用户间的交互频率,较为全面地考虑了影响社会关系的因素。还有一些研究较为简单地考虑了影响用户间社会关系的因素,文献[20]只根据用户间的关注关系构建用户间的社会关系,无法较为精确地度量出用户间的关系强度,从而可能造成情感分类的结果产生一些偏差。以上对度量社会关系的研究取得了较大的进展,然而对情感分析方法的选择较为单一,多数采用了传统的监督学习分类方法,一些通过最小二乘优化对文本情感分析进行建模,不太适用于对高维度、无标签数据的处理,所以选择情感分析方法的方式有待改进。

Table 2 Comparison of sentiment analysis models using social relationships表2 利用社会关系的情感分析模型对比
5 研究趋势与展望
通过以上介绍可知,社会关系在社交网络情感分析中发挥了重要作用,无论是对发表内容进行情感分析还是对用户的情感趋势和行为决策进行预测,都有极大的帮助,但是仍存在很多亟须解决和优化的问题,下面对利用社会关系进行情感分析的研究方向进行总结:
(1)收集包含社会关系的数据集。虽然已有许多针对社交网络的数据集,但多数只包含文本内容及其情感标注,或是加入了文本内容所属话题类别和ID信息,未包含社交网络上用户的个人信息和用户间的交互信息,无法直接从数据集中获取用户间的关系信息,进而无法准确度量出用户在社交网络中受到的情感影响的强度值。所以,如何获取包含社会关系信息的数据集成为了利用社会关系进行情感分析的关键问题。
(2)准确度量用户间的社会关系。现有的大部分研究只简单考虑了影响社会关系强度的因素,比如只考虑用户间的关注关系或发表内容的相似度,通过较浅层面的相关关系建立用户间的社会关系,没有考虑到真正会对用户情感产生影响的交互活动。现有的大多数研究在度量用户间的社会关系时只用0和1分别表示用户间是否有关联,没有准确描述出用户间社会关系的具体强度值。所以,为了准确刻画出用户间的社会关系,需要从用户间的交互活动和情感影响强度值2个方面进行度量。
(3)使用有效的情感分析方法。综上所述,已有许多研究利用社会关系对社交网络中的文本、图像进行情感分析,但大多数研究采用机器学习或情感词典的方法进行情感分析,这些方法依赖于带标签数据的数目、特定的领域和标注情感分数的单词序列,当处理社交网络中的大数据时,性能表现较差。而基于神经网络自动提取特征的深度学习方法被广泛应用于情感分析领域,也可对社交网络中庞大的数据进行有序的处理,以提高分析的准确率。
(4)将融合社会关系的多模态情感分析应用于社交网络。随着社交网络的发展,由于社交网络内容的多样性,单一模态的情感分析远不能令人满意,现有许多研究将社交网络中的文本和图像结合起来进行情感分析,但对融合了社会关系的多模态情感分析的研究不是很多。社交网络中包含着丰富的社交关系信息,如何将这些信息合理地应用到社交网络情感分析中也是一个值得研究的问题。
针对以上问题,可从社会关系和情感分析2方面展开研究工作。首先,采用API接口或网络爬虫获取社交网络上丰富的社会关系信息,比如用户的个人信息和交互活动信息,在获取所需信息后对数据进行清洗,去除多余内容,将用户间的点赞、转发、关注和评论等交互活动信息保存下来,用于构建用户间的社会关系。其次,为了准确描述用户间的社会关系强度,可采用霍克斯模型进行测量。该模型通过历史事件与当前事件的某种关系预测当前事件发生的概率,即可通过用户间的历史交互活动预测当前用户间的关系强度值;或是利用其他会对情感产生影响的因素,比如通过研究用户对情感的传播能力和用户对他人或社会产生情感影响的接受能力,从而刻画出用户在社会关系影响下的情感改变状态。为了更精准地计算用户间的社会关系强度,可针对不同用户在特定话题下的交互活动展开研究,以确保数据的准确性。由于深度学习在情感分析领域取得的卓越性能,可将社会关系与深度学习结合起来,将用户间的社会关系转化成内容之间的相关关系,对情感特征数据进行扩充,然后利用神经网络模型将融合了社会关系的大量的社交网络数据进行情感分析,从而达到预测用户或群体情感极性的目的。
6 结束语
随着社交网络的兴起,对社交网络的情感分析逐渐成为了热点研究方向,也成为了文本情感分析的重要研究课题。社交网络中有着丰富的包含情感的文本内容,但是文本内容灵活多变、语句内容的随意性以及社交网络对文本长度的限制,对社交网络文本内容的情感分析造成了一定的阻碍。然而,社交网络具有其独特的特点,除了包含内容信息,还包含了丰富的社会关系,利用社会关系分析情感也成为了研究者的研究方向。本文就社会关系和对社交网络情感分析的方法进行了介绍,并总结了一些仍需解决的问题和未来的研究方向,以更好地利用社会关系提高对社交网络情感分析的准确率。
猜你喜欢
意林彩版(2022年2期)2022-05-03
好日子(2021年8期)2021-11-04
建材发展导向(2021年7期)2021-07-16
第一财经(2020年4期)2020-04-14
制造技术与机床(2019年10期)2019-10-26
电子制作(2018年18期)2018-11-14
文苑(2018年17期)2018-11-09
西安建筑科技大学学报(自然科学版)(2016年5期)2016-11-10
小学教学参考(2015年20期)2016-01-15
