
基于统计直方图k-means聚类的水稻冠层图像分割
2021-01-29 10:44陈科尹,吴崇友,关卓怀,李海同,王刚
江苏农业学报 2021年6期
关键词:图像分割
陈科尹,吴崇友,关卓怀,李海同,王刚








摘要:針对现有k-means聚类图像分割方法存在对初始聚类中心敏感、易错分割以及运行时效低等问题,提出了一种基于统计直方图k-means聚类的水稻冠层图像分割方法。该方法首先根据图像直方图蕴含的像素数量先验信息,选择像素数量差异较大的像素值作为水稻冠层图像的初始聚类中心;然后再利用图像直方图中像素值与图像像素数量的先验对应关系,对水稻冠层图像聚类目标函数权值化;最后依据k-means聚类框架对水稻冠层图像进行聚类分割。为了验证本方法的有效性,分别同基于k-means、k-means++、k-mc2、afk-mc2等4种主流均值聚类的水稻冠层图像特征像素提取方法进行对比试验。结果表明:对于临稻20号、武运粳32号以及中粳798号成熟中期水稻冠层图像聚类分割,常光下本方法的平均类内平方差分别为36.6、29.5、29.5,平均类间平方差分别为67.5、51.8、51.8,平均运行时间分别为0.2 s、0.3 s、0.3 s;强光下本方法的平均类内平方差分别为15.2、4.9、12.1,平均类间平方差分别为30.9、9.5、21.2,平均运行时间分别为0.3 s、0.2 s、0.3 s,均优于以上4种聚类方法。
关键词:水稻冠层图像;图像分割;统计直方图;k-means聚类
中图分类号:S126文献标识码:A文章编号:1000-4440(2021)06-1425-11
Rice canopy image segmentation based on statistical histogram k-means clustering
CHEN Ke-yin1,2,WU Chong-you 2,GUAN Zhuo-huai 2,LI Hai-tong2,WANG Gang2
(1.School of Physics and Electronic Engineering, Jiaying University, Meizhou 514015, China;2.Nanjing Institute of Agricultural Mechanization,Ministry of Agriculture and Rural Affairs, Nanjing 210014, China)
Abstract:A rice canopy image segmentation method based on statistical histogram k-means clustering was proposed to solve the problems of existing k-means methods, such as sensitivity to the initial cluster center, error prone segmentation and low operation efficiency. Firstly, according to the image histogram, the pixel value with large difference in the number of pixels was selected as the initial cluster center of the rice canopy image. Secondly, the prior correspondence between the pixel value in the image histogram and the number of pixels in the image was used to weight the clustering objective function. Finally, the k-means clustering framework was used to cluster and segment the rice canopy image. In order to verify the effectiveness of the proposed method, comparative experiments were carried out with the feature pixel extraction methods of rice canopy images based on k-means, k-means++, k-mc2 and afk-mc2. The results showed that the canopy images of Lindao 20, Wuyunjing 32 and Zhongjing 798 were clustered and seymented at mid-maturing stage, and the average intra-class sequare errors were 36.6, 29.5 and 29.5 under normal light conditions, the average inter-class square errors were 67.5, 51.8 and 51.8, and the average running time was 0.2 s, 0.3 s and 0.3 s. Under strong light conditions, the average intra-class square errors were 15.2, 4.9 and 12.1, the average inter-class square errors were 30.9, 9.5 and 21.2, and the average running time was 0.3 s, 0.2 s and 0.3 s. The results of the method used in this study are better than the above four traditional clustering methods.
Key words:rice canopy image;image segmentation;statistical histogram;k-means clustering
目前,国内外关于水稻联合收割机喂入量调控及基于水稻冠层图像的种植密度预测方面的研究较少,处于探索阶段,行之有效的成果并不多。国内这方面研究比较有代表性的成果有:杨一平等设计了一种联合收割机喂入量信号采集电路,通过获取机械式喂入量传感器获取当前时刻喂入量[1];陈进等提出使用扭矩传感器测量物料脱粒分离情况,从而间接计算喂入量[2];梁学修等提出通过采集滚筒扭矩、转速信息,以及谷物籽粒的流量信息和位置、速度信息,推算出当前收割机喂入量[3];潘静等[4-5]和王轲[6]提出利用图像处理算法检测水稻种植密度,从而间接预测喂入量。国外这方面研究比较有代表性的成果有:kumhala等提出使用扭矩计测量压扁器输入功率,进而间接计算喂入量[7];Montes等提出使用近红外光谱图像分析方法,检测田间作物的种植密度[8];EI-Faki等研究了农田环境影响作物种植密度检测准确度因素[9]。可见,目前水稻联合收割机喂入量调控主要有2种方式:一种是通过机械式传感器直接计算喂入量来调控,这方式虽然较为简便,但不能实时根据田间水稻种植情况调控喂入量;一种是通过图像处理获取水稻种植密度间接计算喂入量来调控,主要采用图像阈值分割方法提取出水稻冠层图像的叶、谷以及田间背景特征像素,然后根据这些特征像素建立定量模型对水稻种植密度进行预测[10]。关于利用图像阈值对水稻冠层图像分割的研究,国内主要有:王远等根据数字图像绿色通道和红色通道差值,通过图像阈值对水稻冠层图像进行分割[11];黄巧义等基于可见光谱,选择Otsu图像阈值和SVM支持向量机对水稻冠层图像进行分割[12-14];徐梅宣等基于G-R颜色通道,选择最大类间方差图像阈值方法对水稻冠层图像进行分割[15]。但作者还未发现基于图像阈值的水稻冠层图像分割相关外文文献。而图像阈值分割需要事先确定一组合理的阈值,才能取得理想的分割效果。但是水稻冠层图像除了叶、谷图像特征像素外,还包含复杂的田间背景图像特征像素,这三者图像特征像素交叉分布,很难找到一组合适的阈值把它们区分开来,进行图像阈值分割。并且,图像阈值方法只能实现单个目标的分割,很难实现多个目标的分割,而水稻冠层往往需要实现叶、谷以及田间背景多目标的分割。
为此,本研究选择k-means聚类,对成熟中期水稻冠层图像进行图像分割,利用其统计直方图蕴含的聚类空间位置信息,对聚类中心进行先验初始化和聚类目标函数权值化,解决聚类效果不理想、影响冠层叶、谷图像特征像素提取的问题。
1水稻冠层图像采集及其颜色空间分析
1.1水稻冠层图像采集
水稻冠层图像采集地点为江苏省泰州市红旗种子试验基地,水稻品种分别为临稻20号、武运粳32号、中粳798号,随机在每块田地不同区域,采集水稻冠层图像。设计了如图1所示的数码相机支架,该支架可根据田间情况,自由调整数码相机的高度和方向。通过该支架调整数码相机的高度和方向,使该相机距离水稻植株正上方100 cm处,选择上午9∶00-11∶00时间段,田间阳光均匀即常光下采集3个品种水稻成熟中期冠层图像各30张;选择下午13∶30-15∶30时间段,田间阳光强烈即强光下,采集3个品种水稻冠层图像各30张;选择下午17∶30-18∶30时间段,田间阳光昏暗即弱光下,采集3个品种水稻冠层图像各30张。以上每张冠层图像分辨率大小为640×480个像素,如图2所示。
1.2水稻冠层图像颜色空间分析
在进行水稻冠层图像聚类分割之前,一般要选择一个合适的聚类空间,由于水稻冠层叶、谷以及田间背景图像特征在颜色方面存在差异,所以本文选择颜色空间作为水稻冠层图像的聚类空间。常见的图像颜色空间有:RGB、HSV、YCbCr和Lab。 通过对水稻冠层图像的颜色空间统计分析,发现基于RGB空间和Lab空间,水稻冠层叶、谷以及田间背景图像特征分布过于集中,很难区分;基于HSV空间,水稻冠层叶、谷以及田间背景图像特征分布又过于分散,也很难区分;只有基于YCbCr空间,水稻冠层叶、谷以及田间背景图像特征才容易区分。所以,聚类分割前,选择将水稻冠层图像从RGB空间转换为YCbCr空间。
2k-means聚类框架与水稻冠层图像分割
2.1k-means聚类框架改进
虽然k-means[16-26]、k-means++[27-29]、k-mc2[30-31]和afk-mc2[32-33] 4种聚类在具体细节上有所差异,但后3种聚类都在k-means聚类基础进行改进的,它们都属于k-means聚类框架[34]。k-means聚类的一般框架思路是:假设存在一个包含N个样本数据的数据集,以及给定聚类数目k,首先随机选择k个样本分别作为初始聚类中心,然后依据聚类目标函数采用迭代的方法,计算还未划分剩余的样本数据到每个聚类中心的距离,并将该样本数据划分到与之最近的那个聚类中心所在的簇类,对划分完的每一个簇类,重新计算该簇类内所有数据平均值不断修改聚类中心,再进行新一轮划分聚类,直到簇类内误差平方和最小化。
但是该聚类框架存在以下不足[35-37]:(1) 随机选择初始聚类中心。聚类中心的初始值直接影响聚类结果的好坏。虽然k-means聚类框架可以通过迭代不断调整聚类中心,但也只能达到局部最优,不能达到全局最优。随机选择初始聚类中心,尽管操作简单,但一般很难得到理想的聚类结果。所以,在进行聚类划分之前,事先对待聚類样本数据进行统计分析,基于先验的统计结果,尽量选择相似性小的样本数据作为初始聚类中心。(2) 聚类目标函数基于欧式距离。聚类目标函数计算方式的不同会导致不同的聚类结果,但基于欧式距离的聚类目标函数对待聚类样本数据同等处理,但是实践中面对待聚类样本数据的侧重点不同。对聚类目标函数进行权值化,更加符合实际情况。(3) 待聚类样本数据之间存在相关性。在k-means聚类框架中使用欧氏距离只是计算距离,没有排除待聚类样本数据之间的相关性,聚类结果对数据相关性非常敏感。所以,事先对待聚类样本数据属性特征进行主成分多元统计分析,找出代表待聚类样本数据的主要属性特征,从而降低聚类空间维数。
由于图像颜色空间直方图与图像像素之间存在一一对应关系,通过此直方图可挖掘出蕴含在图像颜色空间中的聚类先验信息。所以,在考虑水稻冠层图像颜色空间基础上,首先计算出颜色空间直方图,然后按照该直方图所对应的水稻冠层图像像素个数的大小,选择图像像素个数差异较大的像素作为初始聚类中心,并依据该直方图对聚类目标函数进行权值化,从而压缩图像聚类空间维数。最后按照k-means聚类框架进行聚类分割,从而提取出水稻冠层图像中叶、谷以及田间背景图像特征像素。基于以上分析,对k-means聚类框架中的距离公式、聚类中心更新公式和聚类目标函数公式以及初始聚类中心的选择方法进行修改,具体如下:
聚类距离公式:
di=X-Ci(1)
修改为:
di=X-Ci·H[X](2)
聚类中心更新公式:
Ci=Xij∑Nij=1Xij(3)
修改为:
Ci=Xij·H[Xij]∑Nij=1H[Xij](4)
聚类目标函数公式:
J=∑ki=1∑Nij=1Xij-Ci2(5)
修改为:
J=∑ki=1∑Nij=1Xij-Ci2·H[Xij](6)
其中,X=(Y,Cb,Cr)为图像颜色空间数据;Ci为第i个聚类中心,k为聚类数目,i=1,2,...,k;Xij为属于第i类的图像颜色空间数据,Ni为属于聚类中心Ci的Xij个数,j=1,2,...,Ni。
初始聚类中心的选择方法:
HS[*]=Sort(H[*])(7)
其中,H[*]为图像颜色空间直方图,HS[*]为降幂排序后的直方图,Sort()表示降幂排序。
Xij=Select{kHS[*]}(8)
其中,Select{kHS[*]}表示根据HS[*]大小选择其所对应的k类图像颜色空间数据,Xij为属于第i类的图像颜色空间数据,k为聚类数目,i=1,2,...,k,j=1,2,...,Ni,Ni为属于第i类Xij的个数。
C(0)i=1Ni∑ijXij(9)
其中,C(0)i为第i个聚类中心的初始值,Xij为属于第i类的图像颜色空间数据,k为聚类数目,i=1,2,...,k,j=1,2,...,Ni,Ni为属于第i类Xij的个数。
2.2水稻冠层图像分割
基于本研究方法,提取水稻冠层图像的叶、谷以及田间背景特征像素的算法步骤为:
Step1:采集水稻冠层图像数据。
Step2:将其从RGB颜色空间转换为YCbCr颜色空间,形成对应图像颜色空间数据X。
Step3:基于YCbCr颜色空间,计算图像颜色空间直方图H[*]。
Step4:设置聚类数目k。
Step5:依据公式(7)、公式(8) 、公式(9),选择k个初始聚类中心Ci=C(0)i,i=1,...,k。
Step6:按照公式(2),计算每个图像颜色空间数据(X)到k个聚类中心(Ci)的距离(di)。
Step7:分配每个图像颜色空间数据X到与它距离最近的聚类中心所在的类族,并记下其所属的类别Label[X]。
Step8:按照公式(4),更新聚类中心(Ci),i=1,...,k。
Step9:按照公式(6),计算聚类目标函数(J)。
Step10:若J值收敛,输出k个最优聚类中心 ,Cibest=Ci,转到Step11,否则,转到Step6。
Step11:按照公式(2),计算X到k个最优聚类中心Cibest的距离dibest。
Step12:分配每一个图像颜色空间数据X到与它距离最近的最优聚类中心所在的类族,并记下其所属的类别Label[X]。
Step13:按照Label[X]与图像颜色空间数据(X)的对应关系,输出图像聚类结果即得到水稻冠层图像叶、谷以及田间背景特征像素的归类。
3结果与分析
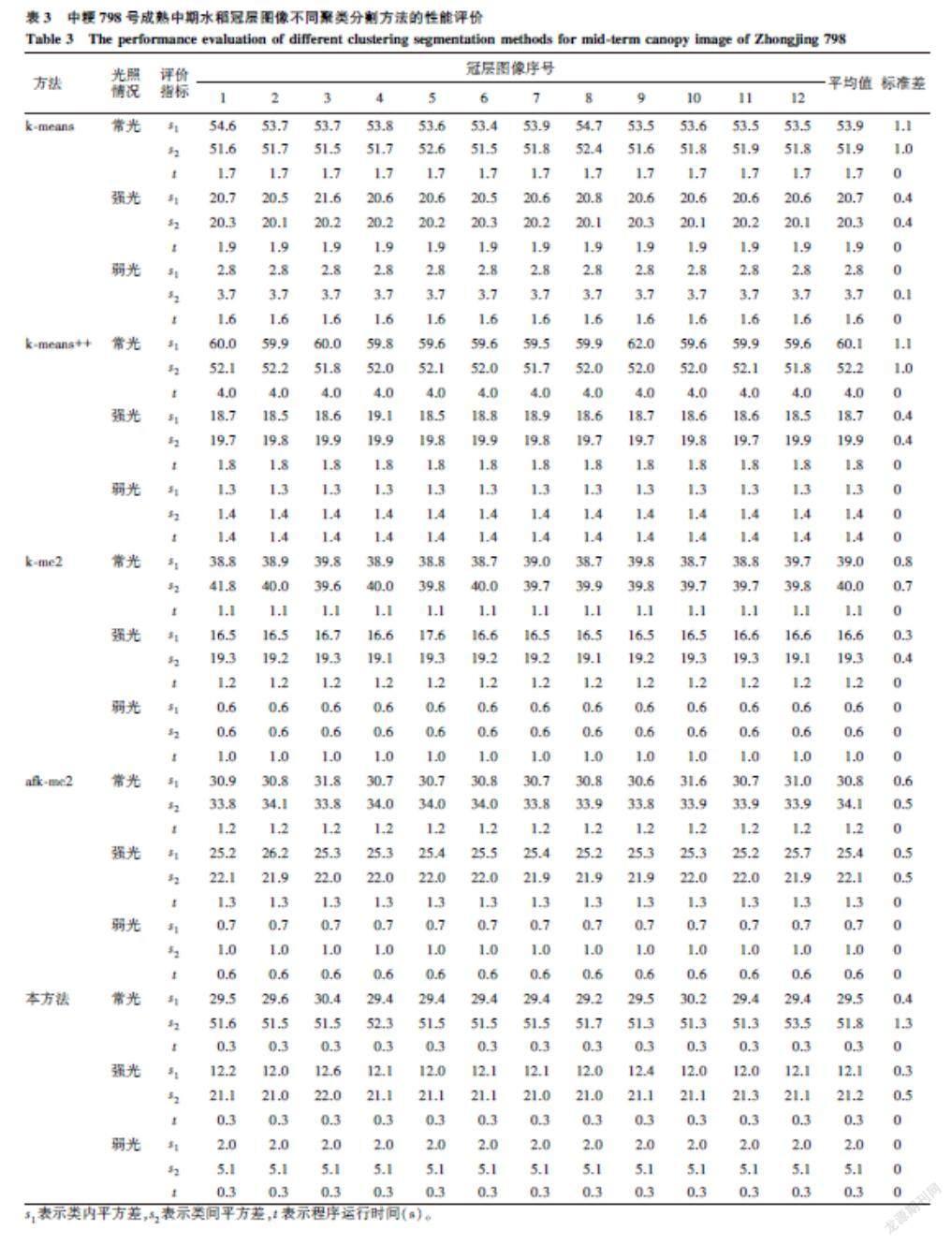
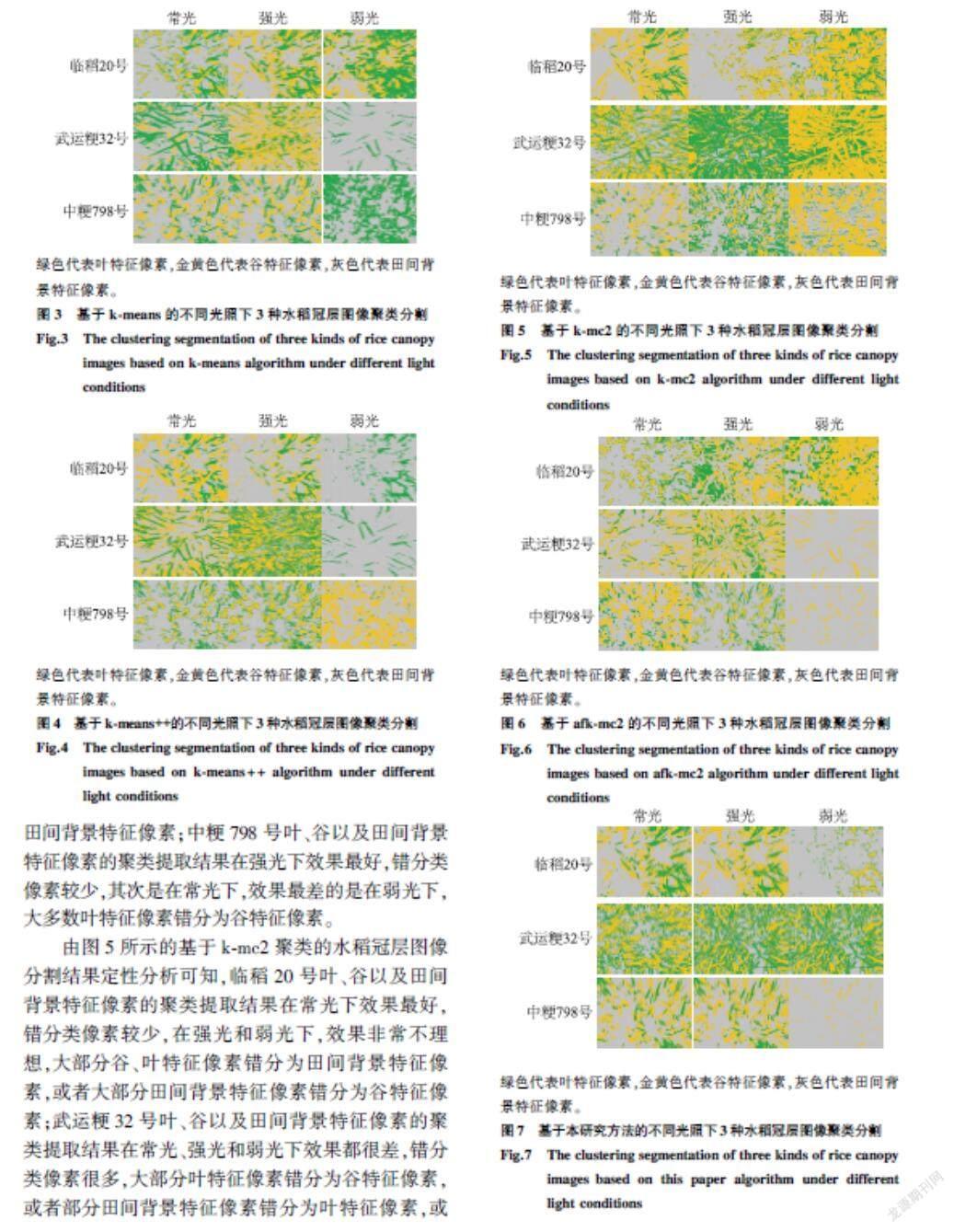
为了验证本方法的有效性,运用VC++2015和OpenCV编写聚类程序,选择YCbCr颜色空间,基于k-means、k-means++、k-mc2、afk-mc2等聚类方法和本方法,分别在常光、强光和弱光情况下,对成熟中期的临稻20号、武运粳32号和中粳798号各30张冠层图像,进行聚类分割试验。具体分割效果如图3至图7所示。
由图3所示的基于k-means聚类的水稻冠层图像分割结果定性分析可知,临稻20号叶、谷以及田间背景特征像素的聚类提取结果在强光下效果最好,错分类像素较少,其次是在常光下,效果最差是在弱光下,部分田间背景特征像素错分为叶特征像素;武运粳32号叶、谷以及田间背景特征像素的聚类提取结果在常光下效果最好,错分类像素较少,其次是在强光下,部分谷特征像素错分为叶或者田间背景特征像素,效果最差是在弱光下,谷特征像素几乎全部错分为田间背景特征像素;中粳798号叶、谷以及田间背景特征像素的聚类提取结果在常光和強光下差不多,效果较好,错分类像素较少,效果最差的是在弱光下,谷特征像素几乎全部错分为叶或者田间背景特征像素。
绿色代表叶特征像素,金黄色代表谷特征像素,灰色代表田间背景特征像素。
绿色代表叶特征像素,金黄色代表谷特征像素,灰色代表田间背景特征像素。
绿色代表叶特征像素,金黄色代表谷特征像素,灰色代表田间背景特征像素。
绿色代表叶特征像素,金黄色代表谷特征像素,灰色代表田间背景特征像素。
绿色代表叶特征像素,金黄色代表谷特征像素,灰色代表田间背景特征像素。
由图4所示的基于k-means++聚类的水稻冠层图像分割结果定性分析可知,临稻20号叶、谷以及田间背景特征像素的聚类提取效果在常光下最好,错分类像素较少,其次是在强光下,部分谷特征像素错分为田间背景特征像素,效果最差的是在弱光下,稻谷特征像素几乎都错分为田间背景特征像素;武运粳32号叶、谷以及田间背景特征像素的聚类提取结果在常光下效果较好,错分类像素较少,在强光和弱光下,效果都不很好,错分类像素很多,或者大部分叶特征像素错分为谷特征像素或者部分田间背景特征像素错分为叶特征像素或者谷特征像素几乎都错分为田间背景特征像素;中粳798号叶、谷以及田间背景特征像素的聚类提取结果在强光下效果最好,错分类像素较少,其次是在常光下,效果最差的是在弱光下,大多数叶特征像素错分为谷特征像素。
由图5所示的基于k-mc2聚类的水稻冠层图像分割结果定性分析可知,临稻20号叶、谷以及田间背景特征像素的聚类提取结果在常光下效果最好,错分类像素较少,在强光和弱光下,效果非常不理想,大部分谷、叶特征像素错分为田间背景特征像素,或者大部分田间背景特征像素错分为谷特征像素;武运粳32号叶、谷以及田间背景特征像素的聚类提取结果在常光、强光和弱光下效果都很差,错分类像素很多,大部分叶特征像素错分为谷特征像素,或者部分田间背景特征像素错分为叶特征像素,或者田间背景特征像素几乎都错分为谷特征像素;中粳798号叶、谷以及田间背景特征像素的聚类提取结果在常光下效果较好,错分类像素较少,在强光和弱光下效果都不很好,错分类像素很多,部分谷、田间背景特征像素错分为叶特征像素,或者大部分叶、田间背景特征像素错分为谷特征像素。
由图6所示的基于afk-mc2聚类的水稻冠层图像分割结果定性分析可知,临稻20号叶、谷以及田间背景特征像素的聚类提取结果在强光下效果最好,错分类像素较少,其次是在常光下,效果最差的是在弱光下,绝大部分田间背景特征像素错分为谷特征像素;武运粳32号叶、谷以及田间背景特征像素的聚类提取结果在常光、强光和弱光下,效果都不理想,部分谷、叶特征像素错分为田间背景特征像素,或者部分田间背景特征像素错分为谷特征像素,或者叶特征像素几乎都错分为田间背景特征像素;中粳798号叶、谷以及田间背景特征像素的聚类提取结果在常光下效果最好,错分类像素最少,其次是在强光下,效果最差的是在弱光下,大多数叶特征像素和部分谷特征像素错分为田间背景特征像素。
由图7所示的基于本研究聚类方法的水稻冠层图像分割结果定性分析可知,临稻20号、武运粳32、中粳798号的叶、谷以及田间背景特征像素聚类提取结果在常光和强光下一样,效果最为理想,谷、叶以及田间背景特征像素错分类像素较少,效果最差的是在弱光下,叶、谷特征像素几乎都错分为田间背景特征像素,或者很大部分田间背景特征像素错分为叶特征像素。对比图3至图7,可知基于本方法的聚类分割效果较基于前面4种不同聚类方法,错分割现象较少,在常光和强光下,基本上能够提取出水稻冠层图像的谷粒、叶片以及田间背景图像的特征像素;其次是基于k-means和k-means++算法的聚类分割;聚类分割效果较差的是基于k-mc2和afk-mc2。所以,由以上定性分析可以验证基于本研究方法的水稻冠层图像分割在常光和强光下是有效的。
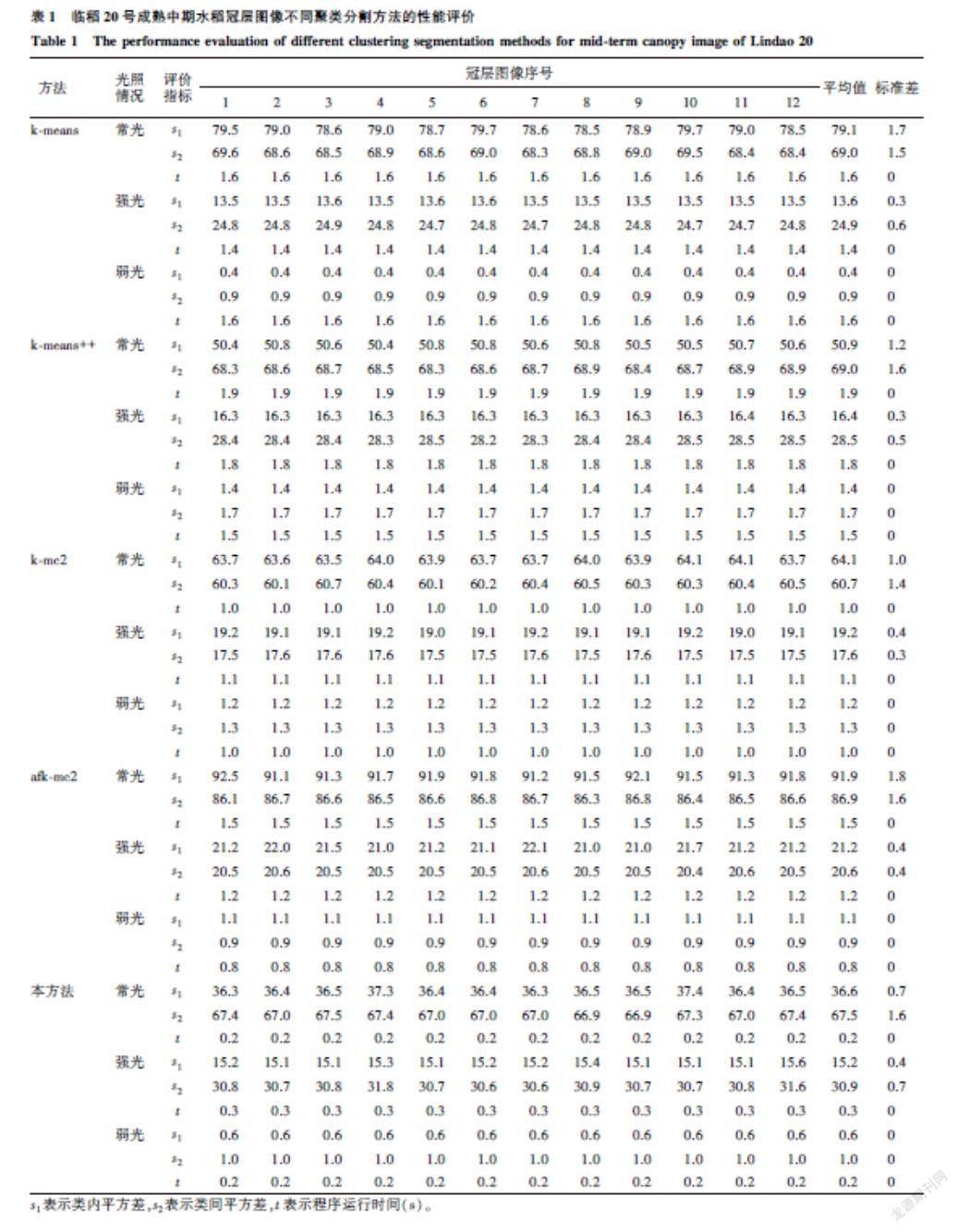
但定性分析带有主观因素,为了更好地比较各类水稻冠层图像聚类分割方法的性能,对3个品种水稻在常光、强光和弱光下分别采集到的30张冠层图像中,分别随机抽取12张,采用类内平方差s1=1n∑ni=1(xi-c)2(其中,xi表示属于聚类中心图像像素c的第i个图像像素,c表示某一类的聚类中心图像像素,n表示与聚类中心图像像素c同类的所有图像像素的个数)、类间平方差s2=1m∑mj=1(ci-cj)2(其中,ci表示第i个聚类中心图像像素,cj表示不同于ci的第j个聚类中心图像像素,m表示除ci聚类中心图像像素外所有聚类中心图像像素的个数)以及程序运行时间(t)作为评价指标,进行定量统计分析。一般在类内平方差(s1)平均值较小的情况下,类间平方差(s2)平均值越大,聚类分割效果越好,具体分析结果见表1至表3。
对比分析表1所列的5种聚类分割方法性能评价指标可知,对于临稻20号水稻冠层图像,常光情况下类内平方差(s1)平均值较小的聚类分割方法有k-means++方法和本方法,分别为50.9和36.6,而且两者的类间平方差(s2)平均值較大,分别为69.0和67.5,所以这2种方法的分割效果较其他方法理想,但本方法的类内平方差(s1)平均值比k-means++方法更小,所以分割效果更好,且平均程序运行时间(t)比其他方法短。强光情况下,类内平方差(s1)平均值较小的聚类分割方法有k-means方法和本方法,分别为16.4和15.2,而且两者的类间平方差(s2)平均值较大,分别为24.9和30.9,所以这2种方法的分割效果较其他方法理想,但本方法的类内平方差(s1)平均值比k-means方法更小,类间平方差(s2)平均值比k-means方法更大,所以分割效果更好,且平均程序运行时间(t)比其他方法短。
对比分析表2所列的5种聚类分割方法性能评价指标可知,对于武运粳32号水稻冠层图像,常光情况下,类内平方差(s1)平均值较小的聚类分割方法有k-means方法和本方法,分别为28.7和29.5,而且两者的类间平方差(s2)平均值较大,分别为48.5和51.8,所以这2种方法的分割效果较其他方法理想,但在两者的类内平方差(s1)平均值差不多情况下,本方法的类间平方差(s2)平均值比k-means方法更大,所以分割效果更好,且平均运行时间(t)比其他方法短。强光情况下,类内平方差(s1)平均值较小的聚类分割方法有k-mc2方法和本方法,分别为4.7和4.9,而且两者的类间平方差(s2)平均值较大,分别为4.5和9.5,所以这2种方法的分割效果较其他方法理想,但在两者的类内平方差(s1)平均值差不多情况下,本方法的类间平方差(s2)平均值比k-mc2方法更大,所以分割效果更好,且平均运行时间(t)比其他方法短。
对比分析表3所列的5种聚类分割方法性能评价指标可知,对于中粳798号水稻冠层图像,常光情况下,类内平方差s1平均值较小的聚类分割方法有afk-mc2方法和本方法,分别为30.8和29.5,而且两者的类间平方差(s2)平均值较大,分别为34.1和51.8,所以这2种方法的分割效果较其他方法理想,但本方法的类内平方差(s1)平均值比afk-mc2方法更小,类间平方差(s2)平均值比afk-mc2方法更大,所以分割效果更好,且平均运行时间(t)比其他方法短。强光情况下,类内平方差(s1)平均值较小的聚类分割方法有k-mc2方法和本方法,分别为16.6和12.1,而且两者的类间平方差(s2)平均值较大,分别为19.3和21.2,所以这2种方法的分割效果较其他方法理想,但本方法的类内平方差(s1)平均值比k-mc2方法更小,类间平方差(s2)平均值比k-mc2方法更大,所以分割效果更好,且平均运行时间(t)比其他方法短。但对比分析图3至图7可知,弱光情况下各种聚类分割方法对3种水稻冠层图像的分割效果均很不理想,所以弱光情况下类内平方差(s1)和类间平方差(s2)性能评价指标不具有实际意义。综合以上分析,除了弱光情况外,在常光和强光情况下,本研究方法的分割效果较其他4种聚类方法更为理想,且类内平方差(s1)和类间平方差(s2)比其他4种聚类方法更优,并且程序运行时间(t)也远远短于他余聚类方法,达到了实时性的要求。
4结论
本研究探讨了通过图像分割提取水稻冠层图像的叶、谷以及田间背景特征像素的方法,并统计直方图对k-means聚类框架进行修改,使之适合水稻冠层图像聚类分割处理。具体研究结论如下:(1) 通过对水稻冠层图像的RGB、HSV、YCbCr、Lab 4种颜色空间进行统计分析,发现基于YCrCb颜色空间,更有利于水稻冠层图像聚类分割;(2) 通过分析水稻冠层图像的图像直方图与其叶、谷以及田间背景图像特征之间的关系,发现利用图像直方图能够合理确定水稻冠层图像的初始聚类中心;(3) 通过分析水稻冠层图像直方图像素值与像素个数的对应关系,发现利用图像直方图能够对其聚类目标函数权值化,从而压缩图像聚类空间,减少错误聚类;(4) 在以上基础上,对水稻冠层图像特征值进行定量统计分析,提出基于本聚类算法的水稻冠层图像分割方法,从而为水稻联合收获的喂入量调控研究提供一定的理论基础和试验数据。
参考文献:
[1]杨一平,胡德民. 联合收割机喂入量信号采集电路的设计与研究[J]. 安徽农业科学,2008,36(35):15746-15748,15750.
[2]陈进,李耀明,季彬彬. 联合收获机喂入量测量方法[J]. 农业机械学报,2006,37(12):76-78.
[3]梁学修,陈志,张小超,等. 联合收获机喂入量在线监测系统设计与试验[J].农业机械学报,2013,44(增刊):1-6.
[4]潘静,邵陆寿,王轲. 水稻联合收割机喂入密度检测方法[J]. 农业工程学报,2010,26(8):113-116.
[5]潘静. 基于遗传算法的水稻联合收割机喂入密度检测方法研究[D]. 合肥:安徽农业大学,2011.
[6]王轲. 基于视频挖掘的成熟期水稻图像处理算法研究[D]. 合肥:安徽农业大学,2011.
[7]KUMHALA F, KROULIK M, MASEK J, et al. Development and testing of two methods for the measurement of the mowing machine feed rate[J]. Plant Soil & Environment,2003,49(11):519-524.
[8]MONTES J M, PAUL C, MELCHINGER A E. Quality assessment of rapeseed accessions by means of near-infrared spectroscopy on combine harvesters[J]. Plant Breeding,2010,126(3):329-330.
[9]EI-FAKI M S, ZHANG N, PETERSON D E. Factors affecting color based weed detection[J]. Transaction of the ASAE,2000,43 (4):1001-1009.
[10]劉汉青. 基于机器视觉的油菜收获疏密度与损失检测[D]. 南京:南京大学,2019.
[11]王远,王德建,张刚,等. 基于数码相机的水稻冠层图像分割及氮素营养诊断[J]. 农业工程学报,2012,28(17):131-136.
[12]黄巧义,张木,李苹,等. 支持向量机和最大类间方差法结合的水稻冠层图像分割方法[J]. 中国农业科技导报,2019,21(4):52-60.
[13]黄巧义,张木,黄旭,等. 基于可见光谱色彩指标Otsu法的水稻冠层图像分割[J]. 广东农业科学,2018,45(1):120-125,3.
[14]黄巧义,樊小林,张木,等. 水稻冠层图像分割方法对比研究[J]. 中国生态农业学报,2018,26(5):710-718.
[15]徐梅宣,张智刚,潘慕,等. 田间水稻冠层图像分割算法的研究[J]. 广东农业科学,2015,42(13):161-164.
[16]SELIM S Z, ISMAIL M A. k-means-type algorith-ms: a generalized convergence theorem and character-ization of local optimality[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,1984,6(1):81-87.
[17]ESTEVES R M, HACKER T, RONG C. Competitive K-means, a new accurate and distributed k-means algorithm for large datasets[C]//IEEE. IEEE 5th internati-onal conference on cloud computing technology and science. Bristol:IEEE, 2013:17-24.
[18]CHEN X, MIAO P, BU Q. Image segmentation algorithm based on particle swarm optimization with k-means optimization[C]//IEEE. IEEE International Conference on Power, Intelligent Computing and Systems. Shenyang,China:IEEE,2019:156-159.
[19]SINAGA K P, YANG M. Unsupervised k-means clustering algorithm[J]. IEEE Access, 2020,8: 80716-80727.
[20]KUMAR K M,REDDY A R M. A fast k-means clustering using prototypes for initial cluster center selection[C]//IEEE. IEEE 9th international conference on intelligent systems and control. Coimbatore:IEEE,2015:1-4.
[21]LEI G. A novel locality sensitive k-means clustering algorithm based on subtractive clustering[C]//IEEE. 7th IEEE international conference on software engineering and service science. Beijing:IEEE,2016: 836-839.
[22]GU L. A novel sample weighting k-means clustering algorithm based on angles information[C]//IEEE. International joint conference on neural networks. Vancouver, BC:IEEE, 2016:3697-3702.
[23]HUNG W,YANG M,HWANG C. Exponential-Distance weighted k-means algorithm with spatial constraints for color image segmentation[C]//IEEE. 2011 international conference on multimedia and signal processing. Guilin, Guangxi:IEEE, 2011:131-135.
[24]郭永坤,章新友,劉莉萍,等. 优化初始聚类中心的k-means聚类算法[J]. 计算机工程与应用,2020,56(15):172-178.
[25]田诗宵,丁立新,郑金秋. 基于密度峰值优化的k-means文本聚类算法[J]. 计算机工程与设计, 2017,38(4):1019-1023.
[26]贾洪杰,丁世飞,史忠植. 求解大规模谱聚类的近似加权核k-means算法[J]. 软件学报,2015,26(11):2836-2846.
[27]ESTEVES R M,HACKER T,RONG C. Cluster analysis for the cloud: Parallel competitive fitness and parallel k-means++ for large dataset analysis[C]//IEEE. 4th IEEE international conference on cloud computing technology and science proceedings. Taipei:IEEE,2012:177-184.
[28]NIU K,GAO Z,JIAO H,et al. k-means+:A developed clustering algorithm for big data[C]//CCIS. 4th international conference on cloud computing and intelligence systems(CCIS). Beijing:CCIS,2016:141-144.
[29]GADDAM S R, PHOHA V V,BALAGANI K S. k-means+ID3:A novel method for supervised anomaly detection by cascading K-means clustering and ID3 decision tree learning methods[J]. IEEE Transactions on Knowledge and Data Engineering,2007,19(3):345-354.
[30]NA S,XUMIN L,YONG G. Research on k-means clustering algorithm: An improved k-means clustering algorithm[C]//IEEE. 2010 third international symposium on intelligent information technology and security informatics. Jinggangshan: IEEE, 2010:63-67.
[31]YANG Q,LIU Y,ZHANG D,et al. Improved k-means algorithm to quickly locate optimum initial clustering number K[C]//IEEE. Proceedings of the 30th chinese control conference. Yantai:IEEE, 2011: 3319-3322.
[32]GUANG-PING C,WEN-PENG W. An improved k-means algorithm with meliorated initial center[C]//ICCSE. 7th international conference on computer science & education. Melbourne,VIC:ICCSE, 2012:150-153.
[33]LIU G L,WANG T T,YU L M,et al. The improved research on k-means clustering algorithm in initial values[C]//IEEE. Proceedings 2013 international conference on mechatronic sciences, electric engineering and computer. Shengyang:IEEE,2013:2124-2127.
[34]朱淑鑫,楊宸,顾兴健,等. K均值算法结合连续投影算法应用于土壤速效钾含量的高光谱分析[J]. 江苏农业学报,2020,36(2):358-365.
[35]BACHEM O, LUCIC M, HASSANI S H, et al. Approximate k-means++ in sublinear time[C]//AAAI. Proceedings of the thirtieth AAAI conference on artificial intelligence. Phoenix,Arizona,USA:AAAI,2016: 1459-1467.
[36]BACHEM O,LUCIC M,HASSANI H,et al. Fast and provably good seedings for k-means[C]//NIPS. 30th conference on neural information processing systems. Barcelona,Spain:NIPS,2016:55-63.
[37]CELEBI M E, KINGRAVI H A, VELA P A. A comparative study of efficient initialization methods for the k-means clustering algorithm[J]. Expert Systems with Applications,2013,40(1):200-210.
(责任编辑:张震林)
收稿日期:2021-05-07
基金项目:国家重点研发计划项目 ( 2016YFD0702100 );国家自然科学地区基金项目( 61863011);广东省普通高校特色创新项目(2020KTSCX142);中国农业科学院基本科研业务费专项(SR201919)
作者简介:陈科尹( 1982-) ,男,广东雷州人,博士,讲师,从事农业图像处理、机器视觉方面研究。(E-mail) chenkeyin10@126.com
通讯作者:吴崇友,(E-mail)542681935@ qq com
猜你喜欢
现代电子技术(2016年24期)2017-01-19
电子技术与软件工程(2016年22期)2016-12-26
现代商贸工业(2016年25期)2016-12-26
科技视界(2016年26期)2016-12-17
电脑知识与技术(2016年24期)2016-11-14
电脑知识与技术(2016年24期)2016-11-14
科技视界(2016年13期)2016-06-13
科技视界(2016年12期)2016-05-25
科技视界(2016年3期)2016-02-26
