
基于深度学习和语法规约的需求文档命名实体识别
2021-01-27 03:42许梦笛王金华
计算机与现代化 2021年1期
许梦笛,王金华
(中国电子科技集团公司第三十二研究所,上海 201808)
0 引 言
命名实体识别(Named Entity Recognition,NER)[1]是知识图谱乃至自然语言处理领域的关键任务,在机器翻译、智能问答、信息检索等领域的研究和应用中都扮演着不可忽视的角色。在知识图谱构建的流程中,NER是第一个步骤,它所识别的实体会用于后续的属性识别、关系识别以构成三元组,如(马化腾,董事长,腾讯),这样的三元组又用于实体消歧和实体链接等后续工作,因此NER造成的误差将对形成的整个知识图谱产生非常大的影响。
需求文档是面向产品开发的重要指标。其中包含了针对产品的需求描述、定位、目标、结构、业务流程、具体用例描述、功能内容描述等详细的指标,在软件工程的进步与迭代中,逐渐形成了一种规范化的形式,因此需求文档拥有相对固定的内容架构和规范的描述方式,以方便制定者和使用者快速定位所需的内容。即使如此,由于需求文档的独一性,不同的文档之间对同一组件的定义与功能需求仍有不同,对于专业的开发团队,想要从众多的需求文档中获取相应的知识体系是非常困难的。
从需求文档中进行NER,有以下几个难点:1)需求文档中的实体与常用的实体不同,存在很多由多个实体、动词构成的虚功能(Virtual Function),如果使用常见的NER方法进行识别,这些实体容易被分开成多个实体或非实体,从而导致识别出错;2)需求文档中有结构化、半结构化和非结构化的文本,不同类型的文本,识别的方式也有所不同,如果使用纯粹的深度学习方法[2-3]或语法规约的方法都会产生一定的误差;3)每个产品只能有一个需求文档,样本数量相对较少,因此对模型的精确率(Precision)、召回率(Recall)具有较高的要求。
Lample等人[1]将传统的LSTM模型替换为字符级的LSTM模型,这种思想对中文NER的任务产生了启发,因此字符序列标注成为中文NER的主要研究方向[4]。经过He等人[5]对比后发现,字符级的模型在表达能力上要普遍优于词语级模型。Zhang等人[6]的实验表明,在经过适当的转义表示之后,一种基于字符的LatticeLSTM模型取得了更好的效果。在这之后,Zhu等人[7]借鉴BERT中self-attention的思想,将其与CNN相结合,获得了更进一步的突破。在互联网巨头阿里巴巴的推动下,多向图神经网络也几乎在同一时间被引入到字符级模型中,取得了较好的效果[8]。为了更好地寻找中文实体的边界,Liu等人[9]在字编码时取得了进展,从而推进了词语级的模型研究。本文的工作是在已经实现并发表的NER工作之上实现的。Hammerton[10]尝试使用单向LSTM实现NER,被认为是最初的NER模型;Collobert等人[11]使用CNN-CRF框架使得NER的准确性有了较大的提升;目前使用最多的是LSTM-CRF[4,12-13]模型,在工程中有比较稳定且良好的表现;本文研究的基本模型仍然沿用类似的模型。
1 深度学习模型
1.1 深度残差网络
深度残差网络(ResNet)[14]是传统卷积神经网络在深度学习领域的一项创举,有效地解决了在网络层数达到一定规模后出现的性能下降问题。对于一个残差网络单元,数据在输入时分为2个路径,其中一条通过单元内部的多个卷积层进行运算,得到输出结果,另一条则直接连接到输出端与运算得到的结果进行组合后成为当前残差网络单元的输出,此举有效避免了层数过深时误差的产生,因为在传递过程中当前单元计算的结果没有优化时,计算会被忽略,即只传递优化后的结果。一个简单的残差网络单元如图1所示。

图1 残差卷积网络单元结构
卷积神经网络在序列数据中的应用主要是其短距离特征提取和降维的能力,经过特定大小的卷积核运算后,可以得到当前位置的字符与其前后短距离字符直接的关系,因而具有2个方面的用途,在字符级的NER中可以用于拼接相邻的字符形成可能的实体,在词语级的NER中可以用于相邻词直接的特征提取,用于decoder中的标签分类。
1.2 BiLSTM
RNN网络是常用的序列数据处理方法,而LSTM网络由于其门机制对于梯度弥散的优化,实现了对长距离特征的提取,成为了当前序列数据处理的主要工具。
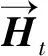

图2 BiLSTM模型结构
1.3 attention机制
在自然语言中,文本通常具有一定的规律,如英文中的主谓宾关系句式,这样的规律在自然语言处理中同样非常重要。传统的机器学习方法可以通过生成句法分析树来进行这一规律的提取,但这样的方法在中文文本中的表现不佳。注意力机制在神经网络发展初期就已经受到关注,随后Bahdanau等人[17]首次将其引入到NLP领域中,注意力模型能够从序列中学习到每一个元素的重要程度,然后按重要程度将元素合并。其简化原理如图3所示,输入一个语料Q,通过计算其与key的相似度S并进行权值归一化处理,再用归一化的权值与对应的value进行加权求和,即可获得当前语料的attention,实验表明这种机制可以灵活地捕捉全局和局部的联系,在长距离的特征提取上有很大的优势。
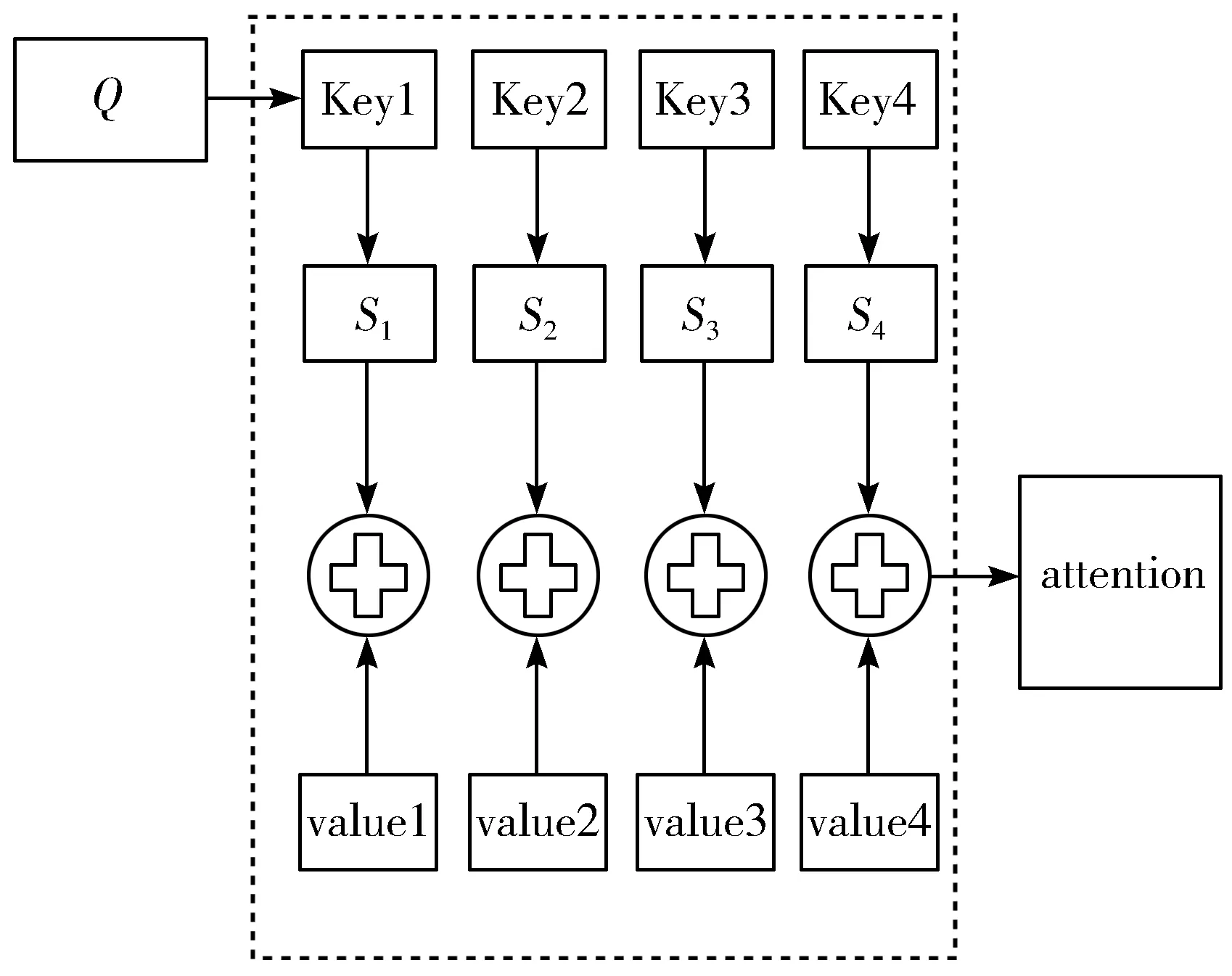
图3 attention机制的实质
1.4 分词与命名实体识别模型
对于字符级的文本,输入到模型中的是一个个的汉字或符号,为了整合得到可用的分词结果,需要用到多个不同卷积核的残差神经网络进行实现,通过不同的卷积核大小来识别不同长度的实体。分词模型结构如图4所示,为方便下文说明将该分词模型命名为WS(Word Segmentation)。
如图4所示的模型输入为字符序列,记为X,输入中的xt表示在t时刻输入的字符,W为当前残差单元的卷积核大小。进入到模型中的字符序列首先经过embedding层转换成长度相同的字符向量,然后进入残差网络,分别使用大小为2到W的卷积核进行识别,这里的拼接操作为concatenate,不使用常规的累加操作是因为模型的最后需要分类得到最佳的词长度。残差网络的输出是形如(W,max_review_len,embedding_len)的矩阵,再经过一个全连接层以及Softmax激活函数即可得到最终的拼接结果。拼接的结果是一个分类结果,代表从当前字开始的总长度为W的序列将被识别为一个词,最终经过简单的文本处理即可得到分词结果。由于该模型仅用于实现分词操作,因此仍需要额外地用于实现NER的功能,本文使用的NER模型结构如图5所示,其中Ht代表来自不同的数据源(字符或词语的向量)中的数据。
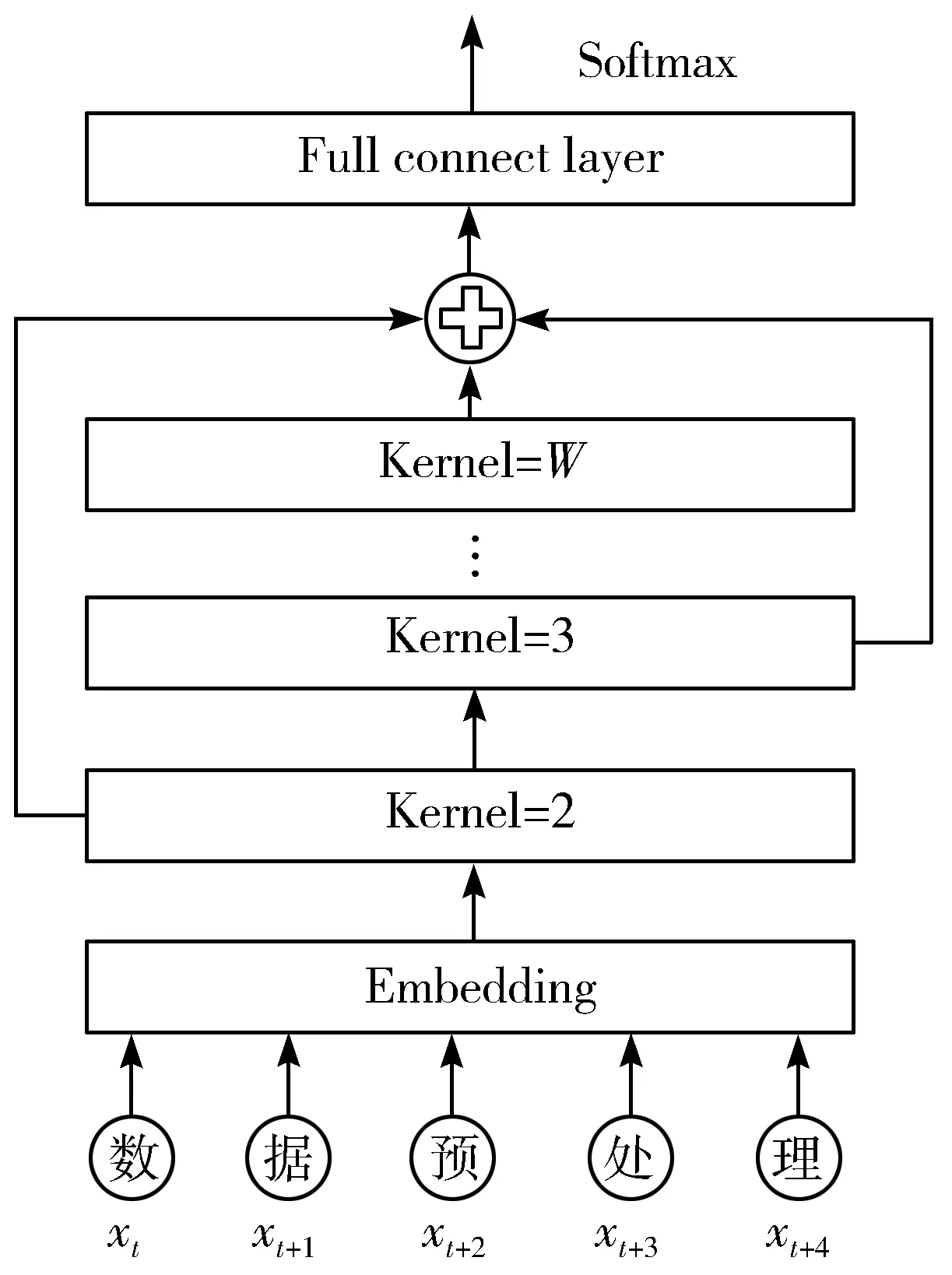
图4 WS网络结构

图5 用于NER任务的BiLSTM-attention-CRF网络结构
单个字符如果直接用于NER任务,则需要附加更多的分类标签,如实体“数据库”,需要定义标签“B-E,I-E,E-E”来表征,这样的形式对于之后的识别任务会产生冗余[18]。因此将WS方法拼接的结果重新整合成完整的词语,形成如图6所示的分词效果,分别将结果送入word2vec模型[19]训练得到词向量,这样就将原本需要3个标签来表征的实体简化到只需要1个标签表征。为了对比结果,转化前的模型命名为CNER-split,转化后的模型命名为CNER-concat。

图6 分词效果图实例
2 实验结果及分析
本文的实验数据为军方产品需求文档,由于数据涉密无法进行公开,样本总量为7677,其中包含name、location、organization、virtual-function、virtual-technique、number共6种类型的实体,采用交叉验证方法,随机抽取80%作为训练集,剩余20%用于测试集。模型使用Adam优化器进行优化,隐藏单元数量为128,学习率为初始0.01,F1值每提升25%学习率缩小10倍,实验使用TensorFlow2.3框架实现。
2.1 字符合并实验
WS模型主要实现了分词操作,为了更好地表现算法的效果,本文从以下3个层面进行实验。评价指标为准确率(Precision)、召回率(Recall)以及F1值(f1_score)。该任务中各评价指标的计算规则如下:
准确率=分词准确的个数/总分词数×100%;
召回率=分词准确的个数/正确分词总数×100%;
F1值=2×准确率×召回率/(准确率+召回率)。
经数据统计发现,实验所用的需求文档数据集中最长实体长度为9,因此设置W参数为2~9的实验,模型训练周期为200,实验结果与超参W的对比关系如表1所示。

表1 W与模型训练的实验结果
从实验结果来看,准确率随着W的增加而增加,这是因为能够覆盖到的真实实体更多;召回率在W=8时达到峰值,但始终无法突破85%,且当W再增大时开始下降,这可能是模型在复杂度上升之后将过多的单字组合成其他长度的词造成的;F1值是模型综合能力的评判标准,在W=8时达到最大值,因此可以取W=8为模型的最优超参。
2.2 3种模型对照实验
为了对比不同数据源对NER模型的影响,实验采用了3种不同的数据源,即CNER-split、CNER-concat以及在其基础上通过语法规约修正得到的分词数据(下文简称CNER-rule)。语法规约是由专家描述的用于需求文档分词的规则,理论上准确率接近100%,但召回率仅满足75%,即F1值可达0.86。语法规则主要以正则表达式的形式呈现,用于对CNER得到的分词结果与原始文本进行对比,从而修正分词的结果。经过语法规则的修正,可以将最终的分词结果准确率提升到92%,召回率提升至96%,由于军方数据涉密,完整语法规则无法全部公开,部分语法规则如图7所示。

图7 部分语法规则
对于CNER-split模型,由于除num标签外的每个标签都存在3种额外的定位标签(B-xx、I-xx、E-xx),所以共有16种标签,而CNER-concat和CNER-rule共有6种标签,模型训练周期为100,学习率为0.01,且随F1值递减,训练结果如图8所示(顺序为CNER-split、CNER-concat、CNER-rule)。

(a)CNER-split

表2 3种不同数据源训练的最优结果表
从实验结果来看,正如算法分析的预测,CNER-split虽然与CNER-concat在精确率上相近,但在召回率上有明显不足,因而在F1值上表现不足;而CNER-rule在实验中各指标表现均好于其他2种方法,同时从图像中可以看出其损失仍有下降趋势,因此可以认为本文提出的基于深度学习和语法规约的实体识别算法性能更好。
2.3 通用模型对比实验
从上文中的实验可以发现,使用语法规约的方法进行分词得到的综合性能最好,因此在与通用模型对比实验中仍使用基于深度学习和语法规约的实体识别算法CNER-rule进行对比实验。
目前通用的NER方法分为传统机器学习方法、深度学习方法以及混合方法。传统机器学习方法中行之有效的方法很多,其中以条件随机场(Conditional Random Fields,CRF)[4]表现最为优秀;深度学习方法中,目前大型企业使用最多的是庞大的BERT方法[21];混合方法中目前主要使用的是轻量级的BiLSTM+CRF方法[1]实现,本文将这几种方法与CNER-rule进行对比,得到的结果如表3所示。

表3 与通用模型对照实验的最优结果
取精确率、召回率和F1值为评价标准,4种模型训练的结果如图9所示。观察图9可知,CRF和BiLSTM+CRF方法在需求文档领域内的表现明显不及本文提出的CNER-rule方法。值得一提的是,虽然BERT在精确率和F1值指标上取得了更好的结果,但训练BERT所耗的时间几乎是训练CNER-rule网络的20倍,且在需求文档数据量小的前提下BERT训练得到的模型呈现出一定的过拟合现象,而CNER-rule方法能够在较短的时间内达到接近于BERT的实体识别效果,能够满足项目需求,因此相比之下CNER-rule方法优势明显。

图9 4种模型训练的F1值
3 结束语
本文提出了一种利用深度学习方法和语法规约的模型解决需求文档领域命名实体识别问题的有效方法,该方法在原有的命名实体识别方法的基础上针对需求文档的特征融入了语法规约,有效提升了精确率、召回率等指标。本文提出的命名实体识别方法中融入了词语的上下文信息、中文语法位置信息和语法规则,将语义特征转化为词的分布式特征;考虑了词语和标签之间的约束关系,进一步提高了识别的效果。但本文在分词方面依赖语法规约的准确程度对命名实体进行修正,不同规则下命名实体的表现有所不同,并没有完全解决自动化的分词校准问题,如何将本文提出的CNER方法进行针对性的优化,使其能够以高准确率、召回率的表现自动化进行文本分词处理,是进一步需要解决的问题。
猜你喜欢
网络安全与数据管理(2022年3期)2022-05-23
校园英语·月末(2021年13期)2021-03-15
北京航空航天大学学报(2020年10期)2020-11-14
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
自动化学报(2019年6期)2019-07-23
数字通信世界(2019年3期)2019-04-19
少儿美术(快乐历史地理)(2018年7期)2018-11-16
