
基于Focal Loss和卷积神经网络的入侵检测
2021-01-27 03:42闫芮铵张立臣
计算机与现代化 2021年1期
闫芮铵,张立臣
(广东工业大学计算机学院,广东 广州 510006)
0 引 言
随着互联网时代的到来,网络传输的流量大大增加,同时黑客用来入侵的方式和技术得到了更多的提升,因此越来越多的网络用户和公司受到了网络攻击[1]。例如:2019年11月5日,西班牙的2家大型公司Everis(NTT Data Group旗下的IT咨询公司)和Cadena SER(西班牙最大的无线电网络公司)在同一天受到了网络勒索软件攻击;2019年11月12日SmarterASP.NET公司遭到勒索软件的攻击,该攻击对公司客户数据进行了加密,对该公司造成了巨大的损失。因此网络入侵技术受到了更加广泛的关注。
入侵检测(IDS)概念是Anderson[2]首先正式提出的,IDS主要通过采集网络活动的流量,根据定义好的规则来过滤异常数据,从而实现实时报警。IDS属于主动防护技术,是网络安全系统中的第二道防线。从检测的手段来看,目前的检测技术主要分为基于异常的检测技术[3]和基于签名的检测技术[4]。基于签名的检测技术虽然具有较高的准确率,但是无法检测到未知的入侵攻击类型,而基于异常的检测技术则是可以检测到未知的入侵攻击类型,因此基于异常的检测技术在学术界得到了比较多的关注,越来越多的人投入到了基于异常的检测技术研究中。
随着人工智能技术的发展,越来越多的学者将机器学习方法应用到入侵检测[5-7],机器学习算法是模式识别的核心技术,它具有一定的推理能力,对于未知模式的攻击也有一定的检测效果[8]。随着神经网络技术的发展,Salama等人[9]利用深度信念网络进行入侵检测;Jia等人[10]将神经网络技术应用到入侵检测系统中,并在KDD99数据集以及NSL_KDD数据集检测其性能,取得了较好的结果。由于入侵数据愈发复杂以及不断有新型攻击出现,因此导致传统方法不能有效处理。同时深度学习在图像识别[11-15]与目标检测[16-18]等很多领域取得了很大成功。深度学习可以有效地提取数据特征,并且能够很好地处理大量无标签数据,因此,基于深度学习的入侵检测技术也受到业界人士的广泛关注。王明等人[19]提出了一种基于卷积神经网络的入侵检测系统,该系统可以有效地提取原始样本信息,从而提高分类准确率;Kwon等人[20]利用不同深度的卷积神经网络验证了网络深度对检测性能的影响;Kim等人[21]利用深度神经网络并结合Relu激活函数和Adam优化算法来检测持续性威胁,并且取得了较好的成果。
深度学习可以很好地处理大量无标签的数据,但是如今网络中大量的入侵数据是不平衡数据集,因此为了进一步改进CNN入侵检测模型,本文提出一种基于Focal Loss和卷积神经网络的入侵检测方法,并且为了避免模型过拟合,加入了DropBlock。该模型相较于传统的CNN模型有更好的检测性能和泛化能力。
1 相关知识
1.1 卷积神经网络
卷积神经网络(CNN)在图像处理领域一直有很好的表现,CNN相对于传统的BP神经网络减少了网络参数的数量,并且CNN实现了权值共享,因此CNN网络便于优化,一般CNN网络模型主要包括输入层、卷积层、池化层(下采样层)、全连接层和输出层,如图1所示。

图1 卷积网络模型
CNN的卷积层可以对特征进行提取,通过卷积核检测输入信号的不同特定特征,卷积核是在输入的数据上通过滑窗的方式实现,因此CNN实现了权值参数共享。其中卷积操作如式(1)所示[22]。
s=f(x×w+b)
(1)
其中,s表示输出数据,x表示输入的样本数据,w表示卷积核的权重,b表示偏差,f表示激活函数。
非线性激活函数可以去除数据中的冗余信息,并且可以加强网络模型的非线性表达能力,可以使CNN模型训练处理多维复杂数据,常见的激活函数有sigmoid、tanh和Relu。
池化层主要进行下采样操作,实现了数据降维,并且可以更多地保持数据的总体信息,常用的池化操作主要有最大池化操作和平均池化操作。本文采用的是最大池化操作。
全连接层主要将经过池化层所得到的特征图中的每个神经元与全连接层中的神经元进行连接。
1.2 Focal Loss损失函数
Focal Loss[23]是由交叉熵损失函数演变而来,主要减少了对于不平衡数据中的不同分类所存在的难度差异等问题。其形式如式(2)和式(3)所示。
(2)
(3)
引入α在0~1之间可以平衡正负样本的重要性,但是无法解决简单样本与复杂样本的分类问题;γ减少易分类样本的损失,使得分类器更关注于困难的、错分的样本。
1.3 DropBlock
传统的Dropout[24]的主要作用就是随机drop特征,从而提高模型的泛化能力,但是Dropout层只在全连接层是有效的,而在卷积层是无效的,因为卷积层的特征是空间相关的。当特征相关时,即使有Dropout,信息仍能传送到下一层,导致过拟合。
DropBlock[25]是Dropout的一种结构化形式。在DropBlock中,特征在一个block中,例如一个特征图中的连续区域会一起被drop掉。DropBlock模块主要有2个参数:block_size和γ,其表达式如式(4)所示。
(4)
其中,γ表示drop过程中的概率,这个概率只表示了随机drop的中间点的概率,block-size表示drop的方块的大小(长,宽);feat-size表示卷积层的输出(也就是特征图)。keep-prob的作用和Dropout里的参数一样。实践应用中主要调整keep-prob的值,本文中将block-size设置为2。
1.4 CNN入侵检测模型
利用CNN进行入侵检测主要包括数据预处理模块、CNN模型搭建以及分类模块,如图2所示。
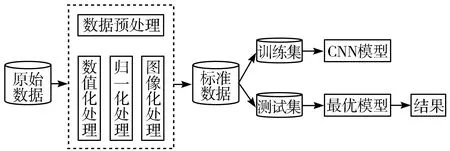
图2 CNN入侵检测模型
该入侵检测模型的具体步骤如下:
1)获取网络流量数据包;
2)对原始数据进行预处理操作;
3)将预处理后的数据划分为训练集和测试集,并将训练集输入到CNN模型不断优化模型参数,直到满足结束条件或得到最优模型;
4)将测试集输入到最优模型中并得到预测结果。
2 实验与分析
2.1 数据预处理
实验中使用的是KDD CUP 99数据集,该数据集中每一条记录有42个属性,其中41个属性表示数据的特征属性,1个属性表示类标识符,并且在数据的41个特征属性中,有9个特征属性为离散型,其他均为连续型,标签包含正常数据和4种异常类型。首先需要对数据进行处理,对数据的预处理操作主要包括数值化处理、归一化处理以及图像化处理。
1)数值化处理。
对于字符型特征,需要将特征从字符型转换成数字型。主要采用独热(One-hot)编码方式,将字符型特征映射为数字特征。
2)归一化处理。
对数据进行归一化处理,可以将数据特征的取值映射到[0,1]区间内,这样可以加快学习速率,其中归一化公式如式(5)所示:
(5)
其中,Xmax表示属性的最大值,Xmin表示属性的最小值,X表示属性的原始值,Xnorm表示归一化后的结果。
3)图像化处理。
经过以上2步使原始数据变为119维的数据,为了使数据转化为图像化数据,因此需要对数据进行补“0”操作,将数据特征变为11×11。预处理完成后的数据如图3所示。
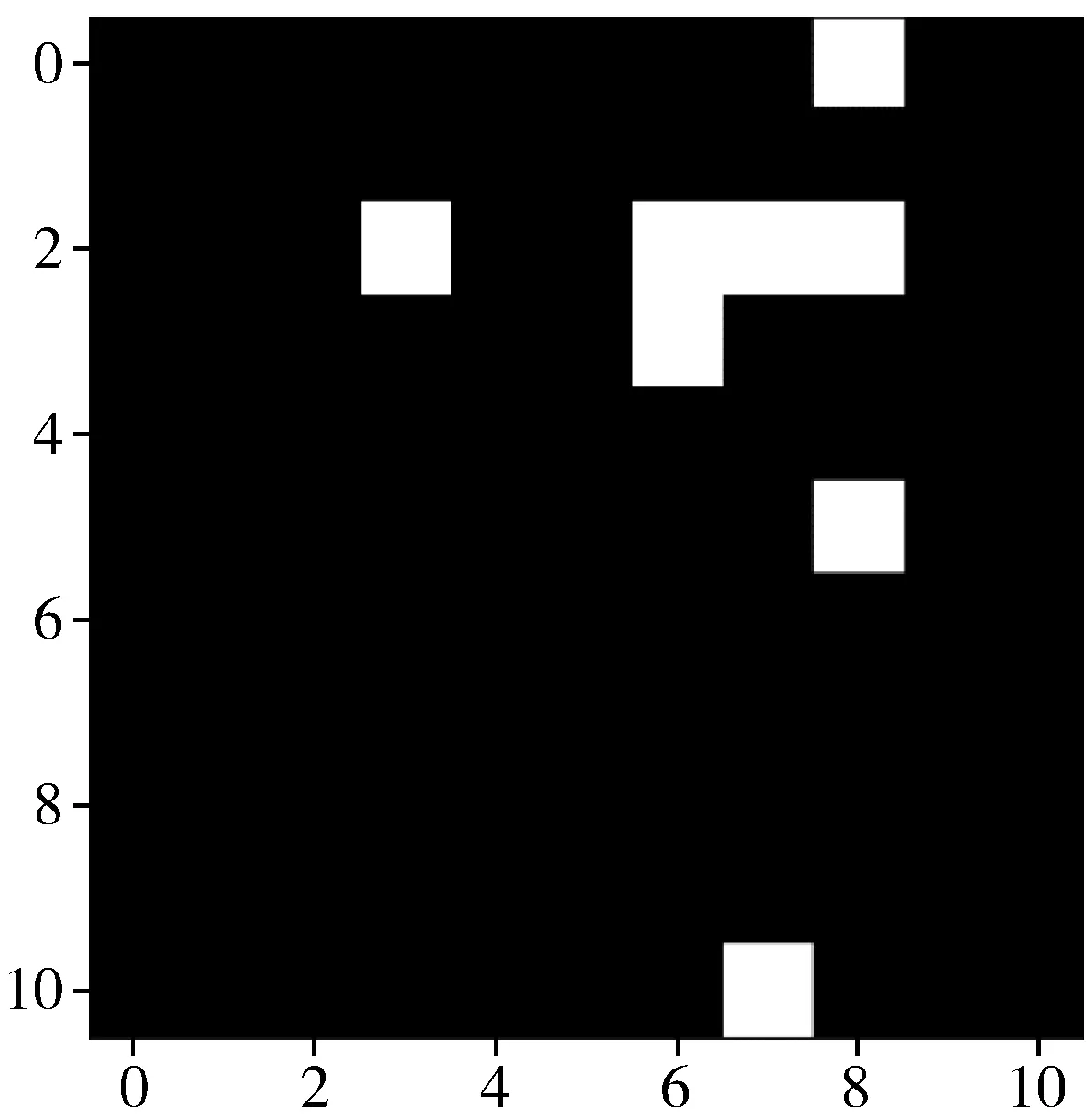
图3 预处理后的数据
为了增加模型的说服力以及训练速度,本文选取KDD99训练集随机抽取10000条数据作为实验的训练集,以及从测试集中随机抽取5000条数据作为实验的测试集,并将4种攻击类型都归类于负类,标记为“0”,将正常数据归类为正类并标记为“1”,本实验训练集与测试集的分布情况如表1所示。

表1 样本类别分布
2.2 模型参数
通过设置不同的CNN模型参数来搭建不同的CNN模型,并利用多次实验进行对比,结果如表2所示,其中原始数据通过预处理转化为11×11的图像数据,因此输入层设置为11×11的矩阵,本实验中将数据分为攻击数据与正常数据,并将标签属性分为0和1,因此输出层的神经元个数设置为1。

表2 CNN模型参数
2.3 实验环境
实验的运行环境配置如表3所示。

表3 实验环境
2.4 评估标准
实验主要通过准确率(Accuracy,Acc)、召回率(Recall,Re)和误报率(False Alarm Rate,FA)来评估模型的性能。
其中,TP表示将正类预测为正类的个数;FP表示将负类预测为正类的个数;FN表示将正类预测为负类的个数;TN表示将正类预测为负类的个数。
准确率表示被正确分类的样本所占总样本的比例;召回率表示预测值为真的样本个数所占实际样本中正类个数的比例;误报率表示预测出的假正例占实际所有负例的比例。
2.5 激活函数
激活函数可以使CNN模型训练处理多维复杂数据,常见的激活函数有tanh和Relu。图4展示的是不同激活函数下分类的准确率和召回率。

图4 准确率和召回率对比
由实验对比可以得出,使用tanh激活函数的网络模型相较于使用Relu激活函数的网络模型有较高的准确率与召回率,因此选择tanh激活函数作为本实验的激活函数。
2.6 DropBlock
DropBlock可以提高模型的泛化能力,图5显示的是在CNN模型中加入DropBlock与不加入DropBlock的准确率。
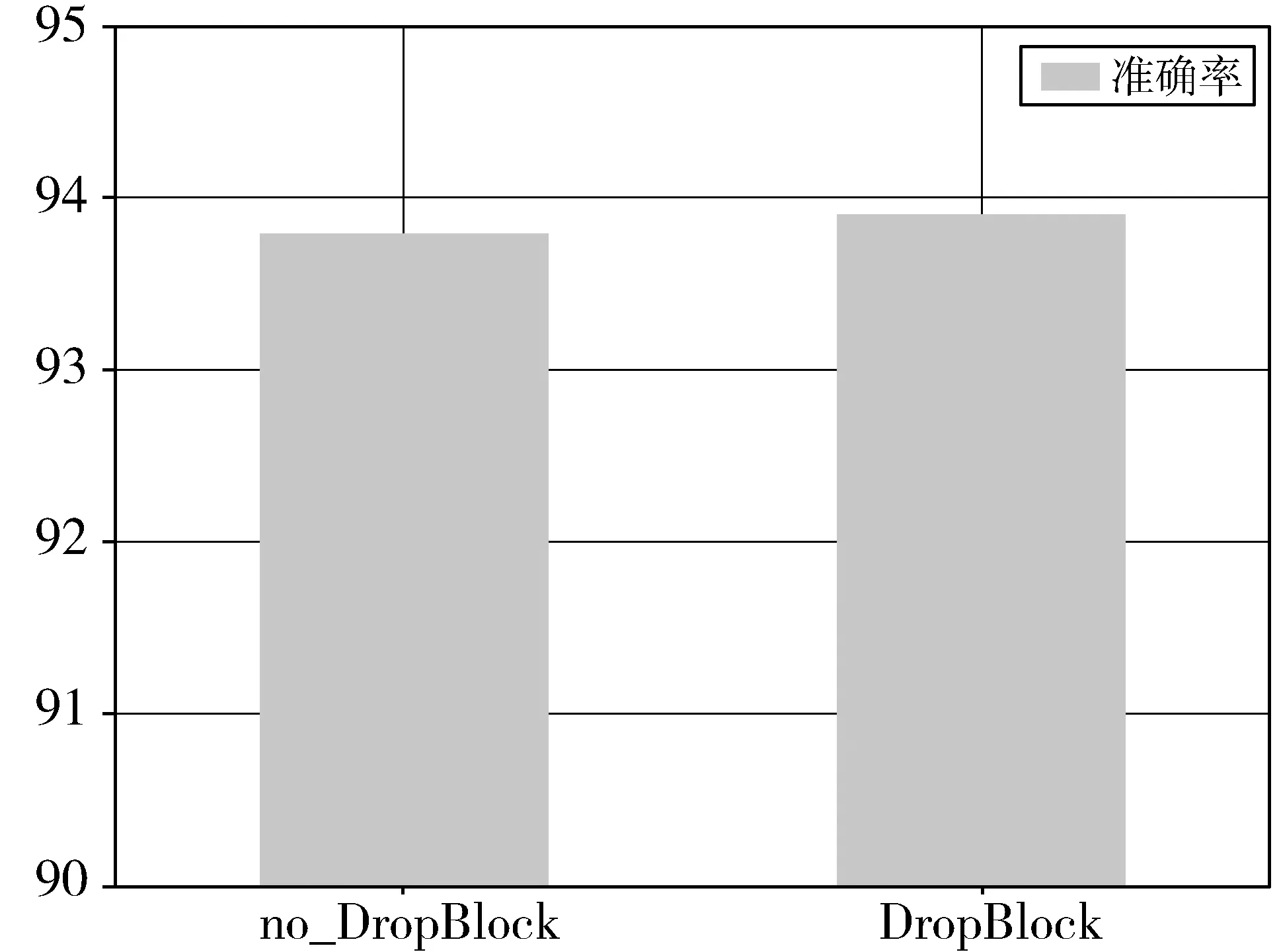
图5 准确率对比
通过实验对比加入DropBlock可以提高模型的准确率,因此本实验在卷积层加入DropBlock,用来提高模型的泛化能力。
在DropBlock主要调整drop的概率,以及block的大小,在本文实验中主要将block_size固定为2并对不同的keep-prob取值下的准确率进行比较,如图6所示。
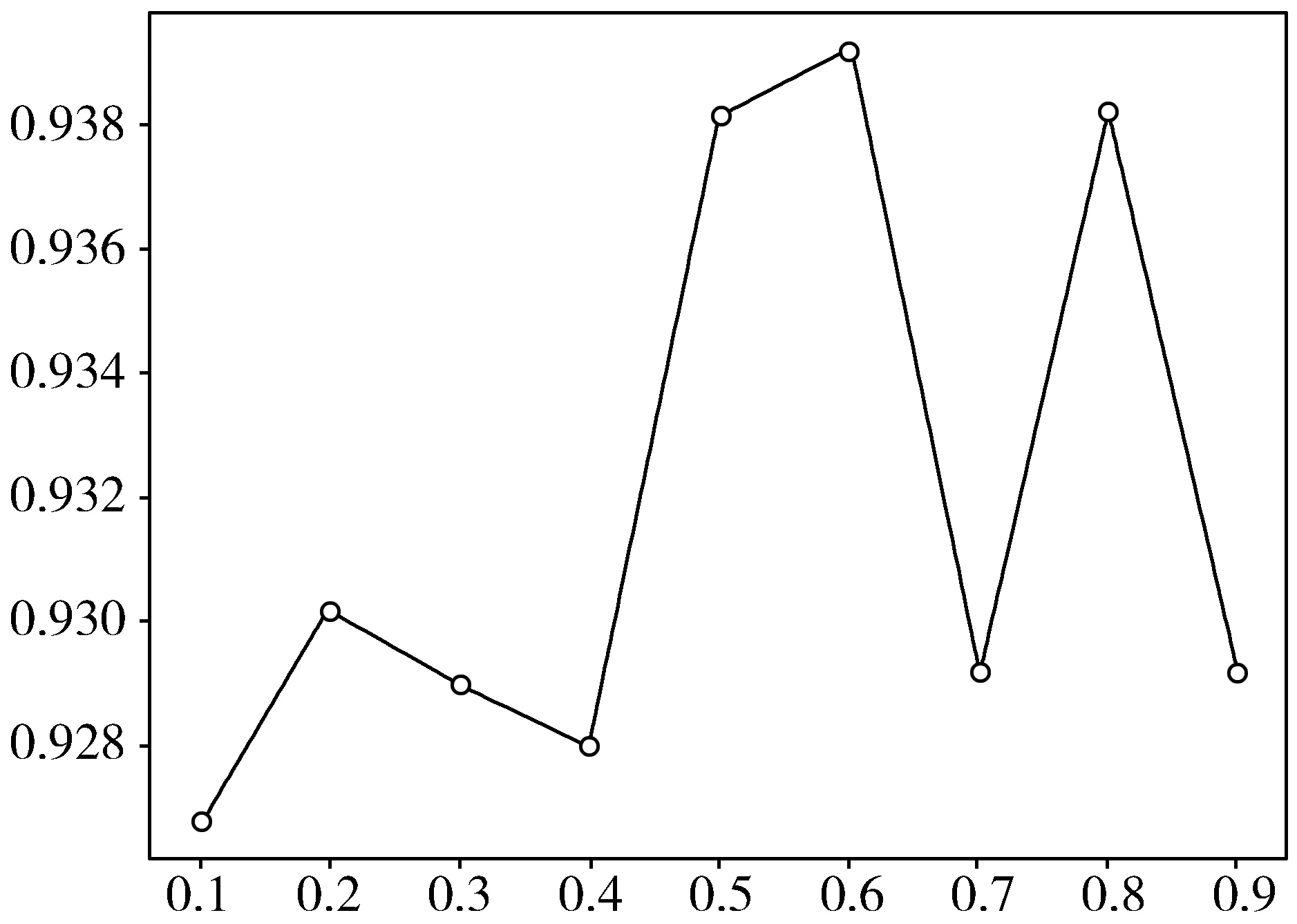
图6 不同keep_drop的取值
2.7 Focal Loss
Focal Loss损失函数可以用来处理数据不平衡问题,KDD99数据集中攻击数据与正常数据相差较大,因此将传统binary_crossentropy损失函数与Focal Loss损失函数对比,其结果如图7所示。

图7 不同损失函数对比
2.8 与传统方法对比
为了提高本模型的说服力,通过与传统的分类算法进行对比,比如K近邻算法(KNN)、支持向量机模型(SVM)、随机森林(RF)、PCA-SVM,并比较各个模型的准确率、召回率和误报率,结果如表4所示。

表4 不同模型对比
由表4可以看出,本文模型的准确率为94.66%,相较于其他6种模型都有所提高,并且误报率相较于其他方法都有所降低。本文模型召回率与RF相比较低,但两者相差较小,并且本文模型的综合性能更好。本文模型利用CNN有效提取数据特征的优点并引入Focal Loss损失函数来处理不平衡数据集,本文模型更加适用于处理高维不平衡数据集,并具有较好的泛化能力,因此本文模型相较于传统模型有更好的鲁棒性。
3 结束语
卷积神经网络可以有效地提取高维数据的特征,并且可以高效准确地完成分类任务,因此利用卷积神经网络进行入侵检测能够取得良好的性能。但是随着入侵数据量的不断增加,使得入侵数据变得极不平衡,因此为了使模型能够更好地在非平衡数据集上有良好的表现,本文引入Focal Loss损失函数来增加CNN模型对不平衡数据的处理能力,同时加入DropBlock层来增加模型的泛化能力,并利用KDD99数据集验证了该模型的可行性。本文主要利用FBCNN模型来进行二分类操作,未来工作主要尝试将模型应用到多分类问题上,利用本文模型处理多分类不平衡问题,使模型能够更好地应用到实际中,增加模型的实用性。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
电子制作(2019年19期)2019-11-23
电子制作(2019年11期)2019-07-04
中国交通信息化(2018年5期)2018-08-21
北京航空航天大学学报(2018年1期)2018-04-20
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
