
基于机器学习的高考信息与大学程序设计课程成绩相关性分析研究
2021-01-25 08:16:36金城崔荣一赵亚慧
延边大学学报(自然科学版) 2020年4期
金城,崔荣一,赵亚慧
(延边大学 工学院, 吉林 延吉 133002 )
近年来,一些研究者针对学生的高考成绩与学生进入大学后的学习成绩(尤其是学生入学第一学期的学习成绩)之间的关系进行了研究.例如:陈小杭[1]对学生高考的数学成绩与学生入学后的大学数学专业课成绩进行了相关性分析,结果表明学生的高考数学成绩与学生入学后的大学数学专业课成绩无显著相关性.石铁玉等[2]研究表明,学生的高考成绩与学生入学后的考试成绩呈弱相关性.杜晓燕等[3]对学生的高考成绩和大一单科成绩的关联性进行研究表明,文科类课程的成绩与高考成绩的关联性较大,而理科类的课程的成绩与高考成绩的关联性较弱.上述文献的研究方法主要是基于统计的相关性分析方法进行的,但该方法对于没有明显统计学规律的多元复杂数据其效果并不理想.文献[4]研究表明,随机森林算法在处理数据复杂、维度较高的分类任务时可获得较高的准确度.因此,本文采用基于随机森林算法研究学生的高考信息与大学一年级的程序设计课程成绩之间的相关性,以为教师在程序设计课程教学中设计出更有针对性和有效的模式提供参考.
1 相关技术
机器学习方法可以从一类数据中自动学习规律,特别是对特征种类多、特征数目庞大的复杂数据进行预测时,其效果显著优于基于统计的方法,因此该方法被广泛地应用于回归、拟合和大数据分析等方面.目前,常使用的机器学习方法包括监督学习、无监督学习和强化学习[5].其中:监督学习方法可以从大量没有显著统计规律的数据中学习到有效的模型,因此常用于解决回归、分类的问题;无监督学习可以在较为规律的统计数据中发现潜在的结构,因此常被用于聚类和降维;强化学习则可在基于环境的动态互动中取得最大化的预期利益,因此常被用于控制系统的设计中.
决策树是一种被广泛应用于金融、保险、医疗等领域的树状分类器,但决策树算法在数据复杂时准确率较低.为此,L.Breiman结合Bagging集成思想[6]与随机子空间方法[7]提出了随机森林算法[8],该算法具有解释性好、结构简单、计算开销小等优点[9].随机森林算法的具体步骤如下:
输入: 样本集D={(x1,y1),(x2,y2),…,(xm,ym)}, 决策树迭代次数T
输出: 随机森林f(x)
1) fort=1 toT:
a)对训练集进行第t次随机采样,共采集m次,由此得到包含m个样本的采样集Dt.
b)用采样集Dt训练第t个决策树模型Gt(x). 训练决策树模型的节点时,首先在所有样本特征中随机选择一部分样本特征,然后在选出的样本特征中选取一个最优的特征来划分决策树的左右子树.
2)在形成的T个决策树中,利用投票表决结果.当结果只有一个类时,将票数最多的类别作为最终类别;当结果包含多个类时,将目标类别作为最终类别.
2 基于分类的成绩影响因素分析
2.1 数据收集
本研究以大学一年级的C语言程序设计课程为例,收集的数据为2014—2016年延边大学计算机科学与技术专业3个年级的学生个人信息.信息包括:高考成绩、学生生源、民族、考生类别和入学第1年的C语言期末考试成绩.3个年级的学生人数分别为115人、157人和145人.
3个年级学生的高考特征属性及其分布如表1所示.由表1可知:在性别方面,男生略高于女生;在民族结构方面,考生以朝鲜族和汉族学生为主,其中朝鲜族学生占总考生的34.2%;在考生类别方面,城市考生占总考生的58.7%;在生源方面,考生主要来自吉林省,占总考生的49.9%.

表1 考生特征属性分布
2.2 特征选择
由于本数据集中的学生主要为汉族与朝鲜族的考生(占总人数的91.7%),且朝鲜族和非朝鲜族考生的录取政策不同(非朝鲜族的其他少数民族和汉族采用同一录取标准),因此本文将民族特征分为朝鲜族和非朝鲜族进行分析.同时去除不使用全国I卷和全国II卷省份的学生信息.将考生进入大学后的C语言成绩按分数段分为5类: 100~90(第1类), 89~80(第2类), 79~70(第3类), 69~60(第4类), 59~0(第5类).各年级C语言成绩的分布情况如图1所示.
2.3 基于随机森林算法的C语言课程成绩预测模型
构建C语言成绩预测模型的方法如下:
1)将处理后的数据按9∶1分为训练集和测试集;
2)利用各年级的训练集数据训练随机森林模型,并通过调整随机森林的参数得到最优的预测模型;
3)利用Bootstrap方法从训练集中随机抽取多个训练样本子集,并对每个子集分别进行随机森林建模;
4)利用测试集对各随机森林进行测试,并综合多棵随机森林的测试结果以通过投票的方式得出最终的C语言课程成绩预测模型;
5)使用可解释性模型LIME(local interpretable model-agnostic explanations)计算对随机森林模型贡献度最大的特征.
上述步骤中利用LIME计算调整贡献度的方法为:①在原始样本中随机替换掉若干特征,以此得到含有噪声的数据z′.②计算随机森林模型对z′预测的值.③求出原样本与生成样本之间的距离,并将其作为权重.④利用生成样本、预测值和权重训练一个简单的线性模型g.⑤按式(1)计算模型g拟合样本的结果与随机森林模型预测样本的结果之间的差值,然后根据差值对随机森林模型进行解释(差值越小贡献度越大).
(1)
其中,f为原模型,w为权重,z为原样本,z′为加入噪声后的样本.基于随机森林算法构建C语言成绩预测模型的流程如图2所示.
3 实验结果与分析
利用随机森林算法对数据进行训练,结果如表2所示.

表2 训练集和测试集的准确度
为获得最佳的分类效果,本文利用实验对模型的参数进行了选定,结果如表3所示.
利用LIME模型计算每个特征对随机森林模型的贡献度,结果如表4所示.
根据表4中的贡献度结果,本文将各年级中排序为前2名的特征作为最大的相关性特征.这些特征包括生源、民族、总成绩、数学和语文5个特征.在所有特征中任取5种特征,并按不重复原则组合方案进行排列组合,共得到126种组合方式.为验证本文选择的特征方案为最佳方案,对126种不同的特征组合使用随机森林进行了训练和测试,其中部分特征组合方案测试集的平均准确率的结果如图3所示.

表3 最优模型参数
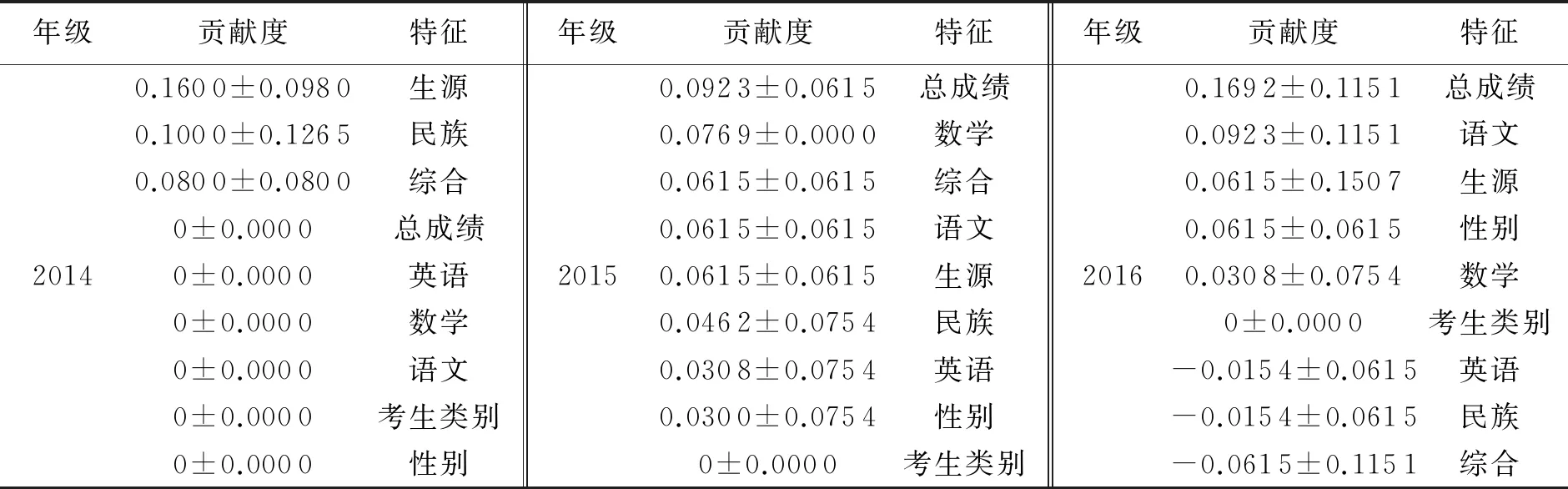
表4 各特征对模型的贡献度
由图3可知,在所有的特征组合方案中,本文提出的特征选择方案的准确率最高(68%),故本文提出的特征组合方案为最优组合方案.在本文提出的特征组合方案中, 5种特征与C语言成绩相关度最大的原因是:
1)学生的学习能力与地区的经济和教育发展水平存在一定相关性,因此来自不同地区的学生其学习能力存在一定的差异.
2)高考总成绩是反映一个学生学习能力的重要指标,因此C语言成绩与高考总成绩呈一定的相关性.
3)因朝鲜族考生的录取分数普遍低于汉族考生,且入学初期存在一定的汉语表达障碍[10](因朝鲜族考生在高考前主要接受的是朝鲜语教学),因此朝鲜族学生在大一初期的学习成绩普遍偏低.
4)学好计算机程序设计课程需要学生具有较好的逻辑思维能力,而数学成绩在一定程度上能体现一个学生的逻辑思维能力,因此其与C语言成绩具有较大的相关性.
5)语文成绩能够体现学生的表达能力和理解能力,其对学习和理解知识至关重要,因此语文成绩和C语言成绩也具有较大的相关性.
为进一步说明基于随机森林分析方法的有效性,本文基于相同的数据集,计算了2014—2016年级的不同特征与C语言成绩间的Pearson相关系数、Spearman相关系数、Kendall相关系数,结果(平均值)如表5所示.由表5可知,不同的特征和C语言成绩之间的相关系数均较低(低于0.36),表明其相关性较弱.
利用随机森林模型对各相关系数排名前5的特征进行训练,得到的模型准确率如图4所示.由图4可以看出,采用本文提出的随机森林分析法得出的模型准确率均高于采用3个相关系数分析法所得的准确率,因此表明采用本文提出的基于随机森林的方法分析高考信息和C语言成绩之间的相关性更为准确.
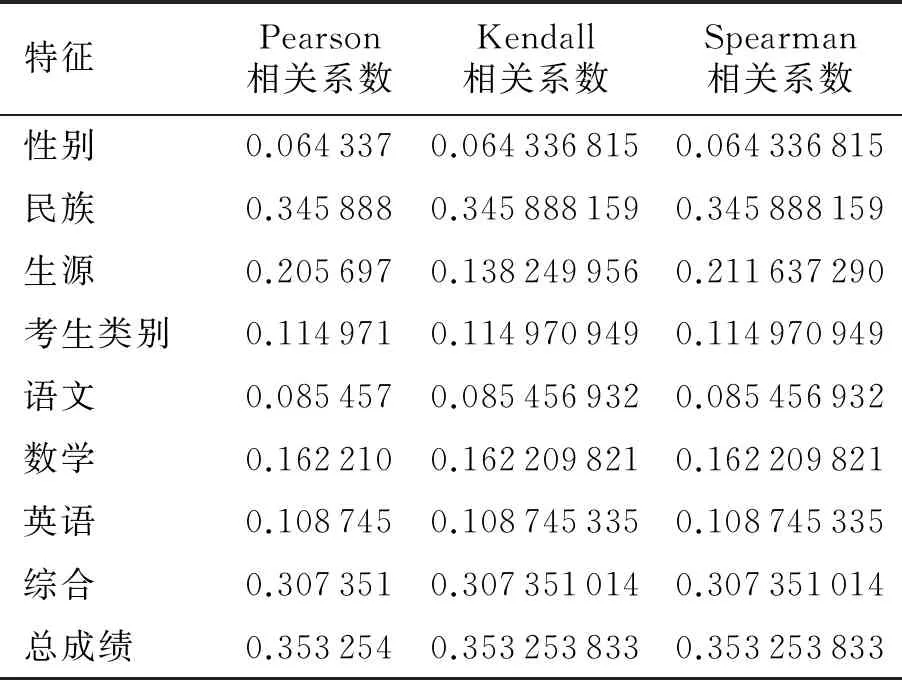
表5 不同特征与C语言成绩间的相关系数
4 结论
本文利用基于随机森林算法的预测和分析方法对C语言成绩的影响因素进行了分析,结果表明生源、总成绩、民族、数学、语文5种特征与C语言成绩的相关性最高.本文的研究结果有助于教师根据新生的实际情况设计出具有针对性的教学模式,以提高程序设计课程的教学质量.本文在研究中所使用的数据量相对较少,因此在今后的研究中我们将进一步增加实验数据量以提高模型的拟合能力,使实验结果更具有普适性.
猜你喜欢
延边大学学报(社会科学版)(2020年2期)2020-03-25 13:28:32
延边大学学报(社会科学版)(2020年2期)2020-03-25 13:28:26
成都信息工程大学学报(2019年3期)2019-09-25 08:31:20
汉语世界(The World of Chinese)(2018年5期)2018-11-24 06:30:48
电子制作(2018年16期)2018-09-26 03:27:06
作文大王·笑话大王(2017年1期)2017-02-21 16:08:53
作文大王·笑话大王(2016年10期)2016-10-18 14:58:58
作文大王·笑话大王(2016年7期)2016-08-08 11:28:43
中央民族大学学报(自然科学版)(2016年4期)2016-06-27 08:06:04
作文大王·笑话大王(2016年2期)2016-02-24 11:27:15
