
Spectrum Prediction Based on GAN and Deep Transfer Learning:A Cross-Band Data Augmentation Framework
2021-01-20 11:06FandiLinJinChenGuoruDingYutaoJiaoJiachenSunHaichaoWang
China Communications 2021年1期
Fandi Lin,Jin Chen,Guoru Ding,Yutao Jiao,Jiachen Sun,Haichao Wang
College of Communications Engineering,Army Engineering University,Nanjing 210007,China
Abstract:This paper investigates the problem of data scarcity in spectrum prediction.A cognitive radio equipment may frequently switch the target frequency as the electromagnetic environment changes.The previously trained model for prediction often cannot maintain a good performance when facing small amount of historical data of the new target frequency.Moreover,the cognitive radio equipment usually implements the dynamic spectrum access in real time which means the time to recollect the data of the new task frequency band and retrain the model is very limited.To address the above issues,we develop a crossband data augmentation framework for spectrum prediction by leveraging the recent advances of generative adversarial network (GAN) and deep transfer learning.Firstly,through the similarity measurement,we pre-train a GAN model using the historical data of the frequency band that is the most similar to the target frequency band.Then,through the data augmentation by feeding the small amount of the target data into the pre-trained GAN,temporal-spectral residual network is further trained using deep transfer learning and the generated data with high similarity from GAN.Finally,experiment results demonstrate the effectiveness of the proposed framework.
Keywords:cognitive radio;cross-band spectrum prediction;deep transfer learning;generative adversarial network;cross-band data augmentation framework
I.INTRODUCTION
1.1 Background and Motivation
With the rapid development of Internet of things(IoT)and intelligent terminal devices,the contradiction between the spectrum under-utilization and the growing demand is more and more intense.The scarcity of spectrum resource has become one of the major challenges of wireless communications.One promising technique to solving this challenge is to obtain information about the evolution of the spectrum.Spectrum prediction is known as an effective technique complementary to spectrum sensing for capturing the relevant information about the spectral evolution and identifying spectrum holes[1].
At present,spectrum prediction based on various machine learning and data mining approaches has been studied (see,e.g.,[2-4]).However,most of the existing studies believe that the historical data of the target frequency band is abundant.In practice,when a cognitive radio (CR) equipment switches the target frequency or the electromagnetic environment transforms,it will be challenging to ensure that the spectrum prediction model still has a good performance since the desirable historical data is relatively scarce.These observations inspire us to develop a data augmentation method to tackle the issue of data scarcity by tailoring the recent advances in generative adversarial network(GAN)and deep transfer learning,both of which show promising potentials to address the issue of data scarcity and improve the performance of spectrum prediction.
1.2 Related Work
1.2.1 Spectrum Prediction Based on Deep Learning
In recent years,spectrum prediction methods have been extensively studied,such as neural network,hidden markov model,bayesian reasoning,moving average,autoregressive model and so on [5].Among them,hidden markov model(HMM)[6],support vector regression(SVR)[7]and artificial neural network(ANN) [8]are the most used in the early methods.With rapid development of neural network,deep learning methods have recently received growing attention for spectrum prediction.In[9],the authors use a convolutional neural network (CNN) to predict the upcoming spectrum usage.In[10],the multi-component time series feature is modeled as the spectral feature,which is input into the Elman recurrent neural network (ERNN) to predict the spectrum occupancy.In[11,12],long short time memory(LSTM)network,an improved version of recurrent neural network(RNN),is firstly applied for spectrum prediction,with an aim to better extract long-term features in spectrum data of time series.In order to improve the efficiency of spectrum prediction,the literature [13]adopts a deep temporal-spectral residual network (DTS-ResNet) to predict multiple time series at the same time by analyzing spectral data at multiple time scales.It is worth noting that all the above deep learning-based spectrum prediction studies have an explicit or implicit assumption that the historical data of the target frequency band is abundant.However,when a CR equipment switches to a new task frequency band or the spectrum environment is changed,the conventional deep learning models will be limited by the timeliness of dynamic spectrum access(DSA)and the scarcity of desirable historical data.The methods to solve the issue of data scarcity in training when switching frequency bands include data augmentation and meta-learning.Compared with meta-learning which has not yet been applied in spectrum sensing,deep transfer learningbased data augmentation and GAN-based data augmentation have received extensive attention in solving the issue of data scarcity.In[14],the authors propose a cross-band data augmentation method base on deep transfer learning that the time series data of single frequency points are augmented to the spectrum prediction.
1.2.2 GAN-based Data Augmentation
Data augmentation is a natural way to tackle the issue of data scarcity.Data augmentation can effectively improve the size and the quality of training data sets in a variety of ways so as to achieve a better deep neural network model[15-18].Recently,GAN-based data augmentation has developed rapidly,which can help generate more data and solve the oversamping problem of unbalanced training data categories [19].It is well known that [20]firstly introduced the concept and framework of GAN,where the core idea is that,through a game modeling approach between a discriminator and a generator,the generator can generate the data that approximates the feature distribution of the real data.In[21],it is reported that deep convolution generative adversarial network (DCGAN) can have better stability and generate higher quality data than the original GAN.A recent survey [22]shows that generative adversarial networks have been successfully used in computer vision,natural language processing,time series synthesis,semantic segmentation and other fields.These observations motivate us to revisit the problem of spectrum prediction from a computer vision perspective,and tailor DCGAN to improve the performance of spectrum prediction under the condition of data scarcity.However,generative adversarial networks are difficult to train and evaluate due to many factors such as the difficulty in achieving Nash equilibrium,and the gradient disappearance.This inspires us to use label smoothing and deep transfer learning in the training of GAN,and the Frechet Inception Distance(FID)metric for evaluation.
1.2.3 Transfer Learning- and GAN-based Data Augmentation
Transfer learning is another promising method to tackle the issue of data scarcity.Transfer learning aims to improve the training effect of the target domain by transferring knowledge from different but similar source domains [23].In a recent survey [24],deep transfer learning methods are grouped into four categories:Instance-based,mapping-based,networkbased,and adversarial-based.As the authors in [25]point out,domain adversarial learning,as a kind of deep domain adaptation,has received increasing attention and been widely used.Due to the emergence of limitations of datasets[26],the capabilities of deep transfer learning and GAN are increasingly explored[27,28].Those methods can effectively solve the problem that the existing data are not similar enough for transfer learning.Moreover,those methods can reduce the size of target domain data set required by model training [29]and contribute to the rapid convergence of the target training model[30].Therefore,in this paper,we focus on data augmentation for the spectrum prediction through GAN and deep transfer learning in the scarcity of historical data of the target frequency band.Compared with [28],we use a simpler and more stable framework that can be easily trained to make the spectrum prediction model more robust when data is scarce.
1.3 Contributions
In this paper,we propose DA-DTS-ResNet,a crossband spectral data augmentation framework for spectrum prediction based on generative adversarial network and deep transfer learning.Compared with[14],the advantages of this work is two-folds.On the one hand,this work can support wideband spectrum prediction.Instead of single frequency point spectrum prediction base on LSTM,we carry out multiple frequency point spectrum prediction base on DTSResNet.On the other hand,this work can reduce the dependence of source domain data for deep transfer learning to the existing data from other frequency bands.Compared with the existing historical data of other frequency bands,we can use GAN to generate data more similar to the target sample.Specifically,the contributions of this paper are summarized as follows:
·We conduct the correlation analysis on real-world spectrum data and obtain several interesting insights:i)There is a high correlation between adjacent frequency points in the target frequency band;ii) Each frequency point has high temporal correlation on the minute scale and the hour scale;iii) Correlations between the data of other frequency bands and the data of the target frequency band are quite different.
·We develop a cross-band data augmentation framework for spectrum prediction under the condition of historical data scarcity based on generative adversarial network and deep transfer learning.The core idea of the framework is to generate data with high similarity to the target data through pre-trained DCGAN and augment these data through deep transfer learning.By introducing FID evaluation metric,experiments on realworld spectrum data verify that the proposed data augmentation framework can generate data with feature distribution that is highly similar to the original data.
·We test the proposed spectrum prediction framework with different data scales.Through the experiments on real-world spectrum data,we find that the performance of the proposed cross-band data augmentation framework is better than the benchmark method,in terms of prediction root mean square error(RMSE)and computation time.
1.4 Organization
The rest of this paper is organized as follows.In Section II,we analyze and preprocess the data of each frequency band and specify the evaluation metric of generative adversarial network.In Section III,we set up a set of control experiments to verify the effectiveness of data augmentation based on generative adversarial networks and deep transfer learning.In Section IV,we conduct experimental comparison and discussion.Finally,we conclude this paper in Section V.
II.DATASET DESCRIPTION AND DATA PREPROCESSING
2.1 Spectrum Data Visualization
Spectrum data used in this paper are from spectrum occupancy measurement campaigns of Aachen university of technology in Germany [31].The researchers conducted rigorous and comprehensive spectrum measurements at two monitoring sites in Aachen,Germany,and one in Maastricht,Netherlands.The monitored frequency band ranges from 20MHz to 6GHz,including four sub-bands with a bandwidth of 1.5GHz.For any subband,choose a resolution of 200kHz as the tradeoff between the monitored frequency resolution and the maximum frequency span.In measurement,the frequency sweep interval is 1.8 seconds,that is,for each frequency point monitored,the monitoring system can obtain the power spectral density(PSD) values of 1000 frequency points in every halfan hour.The longest time span of continuous monitoring was about 14 days.In this paper,the high frequency(HF)bands from 20MHz to 30MHz are set as the target domain frequency band,which are of interest to predict but facing the issue of data scarcity.We selected several commonly used services frequency bands as alternative source domain data:GSM1800 uplink band,GSM1800 downlink band,GSM900 uplink band,GSM900 downlink band and TV band.As can be seen from Figure1,in this paper,for the purpose of multi-frequency point prediction,we visualize the spectral data of each frequency band.In order to facilitate the extraction of image features,we normalized the PSD measurements to values between 0 and 255 to form a grayscale image of spectrum occupancy.By normalization,we can not only eliminate the influence of different PSD values among different frequency band data but also facilitate the training and convergence of the convolutional neural network.In particular,since the timestamps of the data collected in any minute in the original data are not consistent.That is,there are about 34 measured values in every minute,we locate the minimum time scale of spectrum prediction at the minute level,and take the measured values in every minute as the average measured values in this minute.The HF band data is of 7680 minutes at 50 frequency points from 20MHz to 30MHz.We take each pixel to represent the PSD value at the moment of that minute,and divide it by hour as the scale.We divide the spectrum data of each frequency band based on the size of 50×60.By means of spectrum data visualization,we can observe the changes of spectrum images in different frequency bands.But more importantly,the spectral data is visualized so that we can simultaneously analyze and predict the data at multiple frequency points through the convolutional neural network structure.Similarly,in order to ensure the effectiveness of HF band data prediction,we also visualize the data of other existing frequency bands.After the spectrum data of each frequency band is visualized,the data scale is shown in the Table1.In order to make the timestamps of the HF data consistent,we have taken the mean value of 34 measurement points per minute as the average measurement value for this minute,which make the HF data reduced to about one thirty-fourth of its original size,while the data of other frequency bands remain the original size.Therefore,HF data is much smaller than that of other frequency bands,and it is difficult to ensure that the deep learning model can be well trained.Spectral gray scale images are different from the images such as landscapes and portraits.The width and height of spectral gray scale image have practical physical significance.In spectral gray scale images,different pixels represent the power spectral density values of different frequency points over a certain time slot.Therefore,traditional image data augmentation methods,such as inversion,scale transformation,color space transformation and scaling,cannot be directly applied to the data augmentation for spectral gray scale image.

Figure1.The spectrum data is normalized to the gray scale of the spectrum image between 0 and 255.The size of each image is 50 × 60,which is the data of 60 time slots of 50 frequency points.X-axis represents the time slots,Y-axis represents the frequency points.Each picture is arranged in sequence as the time slot progresses.All images represent the PSD of each frequency point in a frequency band at all time slots.
2.2 Autocorrelation Analysis
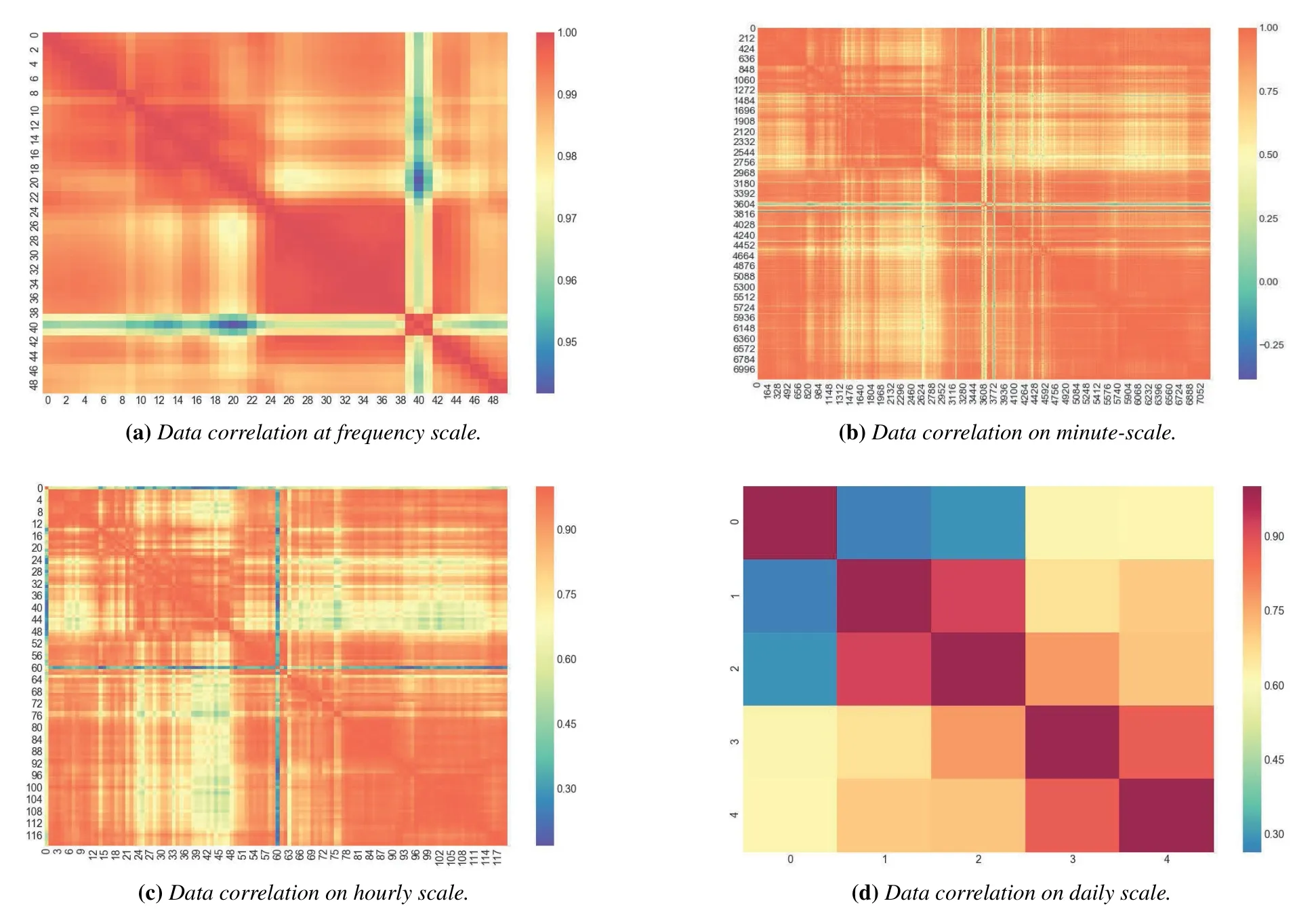
Figure2.The autocorrelation analysis of HF band from different scales.
In order to verify whether the future value can be predicted through historical observations,we calculate the autocorrelation of the data based on PSD values.As shown in Figure2,we analyse the correlation of HF spectrum data from frequency domain and time domain,the time domain include various time scales:minute-scale,hourly scale and daily scale.By analyzing the correlation from the time domain,we can observe the overall correlation of HF band data.By analyzing the correlation in frequency domain,we can find out the different correlation of each frequency point in HF band.
From the perspective of frequency domain,as shown in Figure2a,the point near the 39th frequency point,namely 27.8MHz,has poor correlation with the adjacent frequency point.It is difficult to predict such abnormal frequency points.Therefore,the framework proposed by us should not only improve the prediction performance of normal frequency points,but also improve the prediction performance of abnormal frequency points.From the perspective of time domain,minute-scale as shown in Figure2b,the horizontal and vertical coordinates are the frequency spectrum data of HF band at the scale of every minute.It can be found that there is a strong correlation between the frequency band data of every minute and the frequency spectrum data of the day.Hourly scale as shown in Figure2c,the horizontal and vertical coordinates are the frequency spectrum data of HF band at the hourly scale,and the same conclusion can be found with Figure2b.Daily scale as shown in Figure2d,it can be found that except the spectral data of the first day,the spectral data of other days have certain correlation with the spectral data of the adjacent day.Based on the correlation between frequency domain and time domain of spectrum data,it is possible and interesting to effectively extract the relationship between each pixel and adjacent pixel points as the image features after imaging the spectrum data.Furthermore,these observations motivate us to leverage the residual network[32]has the potential to effectively extract inter-data information with time-domain correlation for prediction.
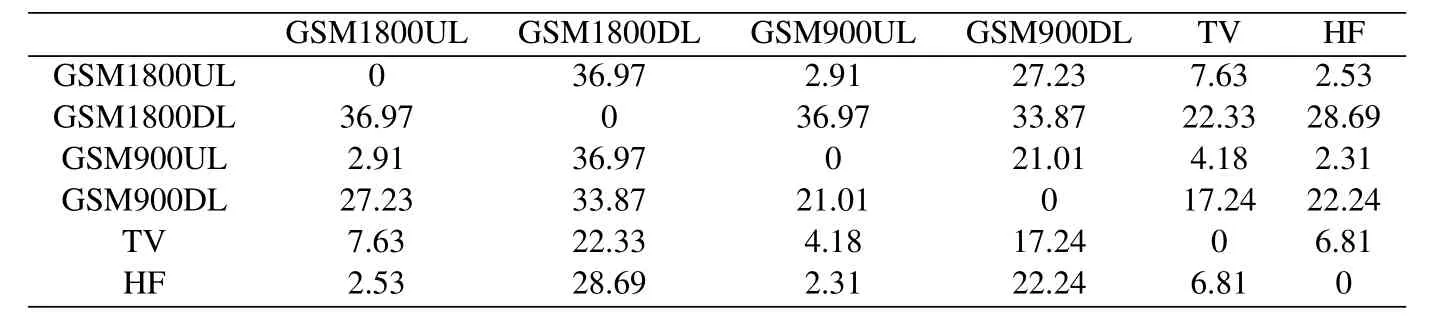
Table2.Frechet Inception Distance between pairings of each frequency band
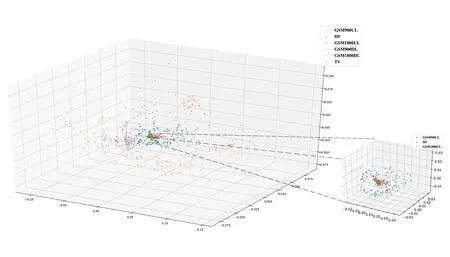
Figure3.The features distribution of data in each frequency band are reduced to the 3D space through PCA.
2.3 Cross-Band Cross-Correlation Analysis
We measure the cross-correlation of data between different datasets using Frechet Inception Distance(FID)evaluation index.As described in the literatures[33,34],Frechet Inception Distance performs well in discriminant power,robustness and efficiency.It is an excellent evaluation indicator to describe the correlation between different datasets,although it can only model the first and second moments of the distribution in the feature space.Inception V3 [35]models pre-trained through large-scale ImageNet datasets are stripped of the final full connection layer.The model removes the last softmax layer and keeps the last 2048 dimensional vector as output.This model will be used as the image feature extractor to extract the 2048 dimensional vector as the image feature.According to the characteristic mean value and covariance matrix of the two datasets,it is calculated by the following formula[36]:
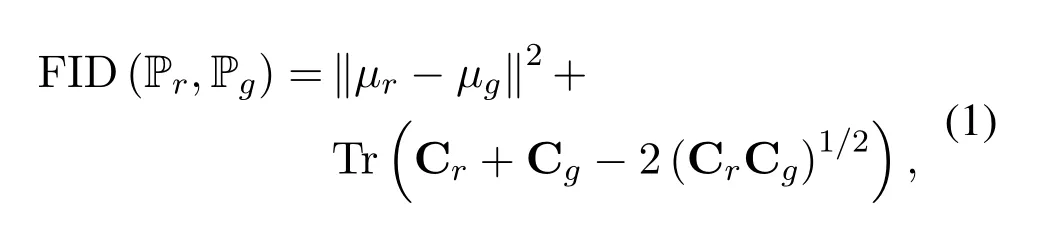
whereµrandµgare the mean values of the features of the two datasets,and Crand Cgare the covariance matrices of the features of the two datasets.The FID evaluation index can calculate the distance between two distributions by means of the mean and covariance matrix.Further,FID for different data sets can be used to illustrate the similarity between the two datasets.FID can also be used to illustrate the similarity and diversity between the generated data and the measured dataset.In general,the FID evaluation index has better robustness and sensitivity to mode collapse and noise.
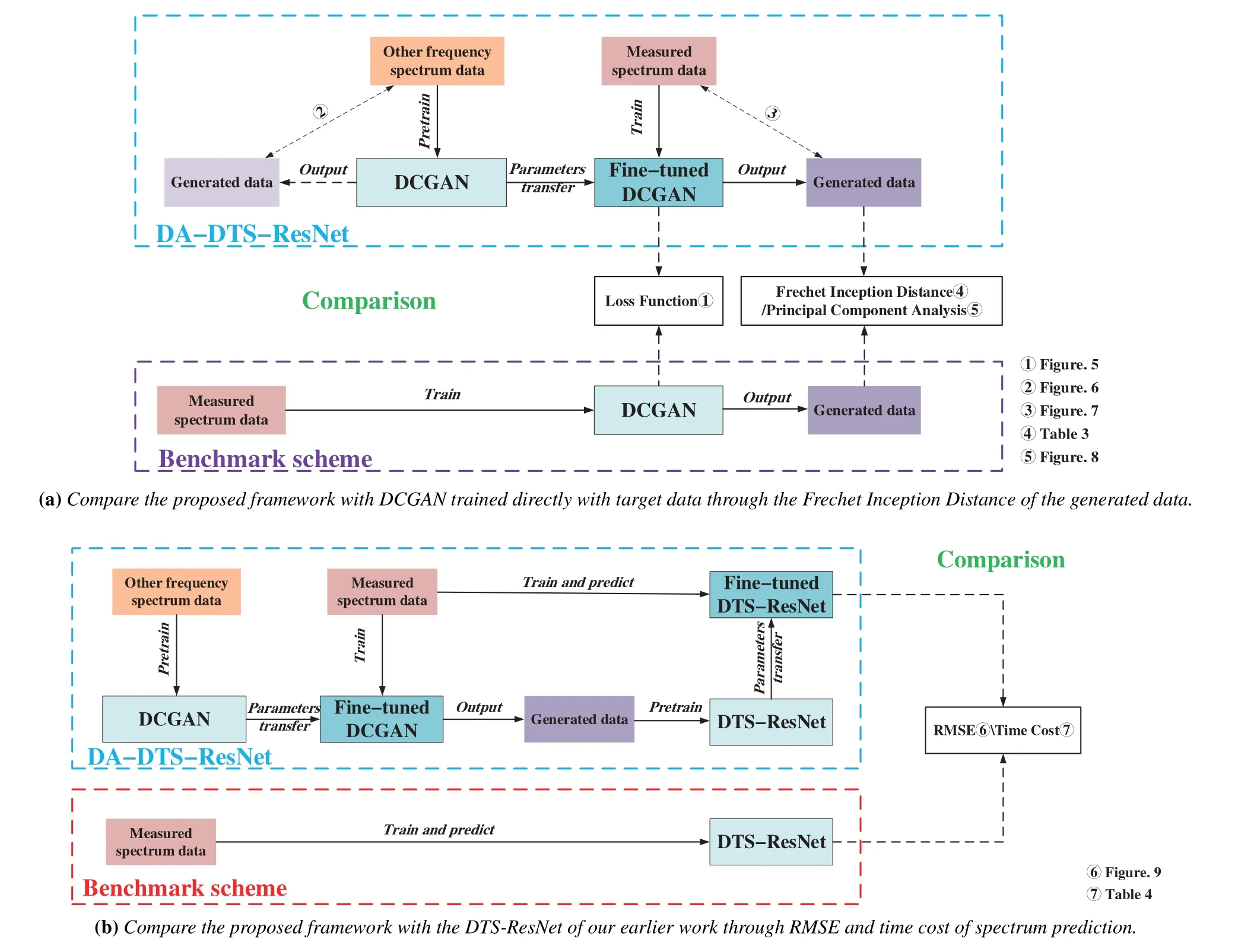
Figure4.Experimental framework of spectrum data augmentation based on generative adversarial network and deep transfer learning.
Based on FID evaluation index,the data of each frequency band selected in this paper are measured for similarity,and the results are shown in the Table2.Analyzing the results in the table,we can find that in general,GSM1800UL and GSM900UL have similar services activity situations.For HF band data,we find that GSM900UL is more similar to the target frequency band.With GSM900UL data,we can improve the prediction performance of HF band data through deep transfer learning.Because of this,we choose GSM900UL data as the source domain data for deep transfer learning in this paper.In order to intuitively analyze the similarity between different frequency bands,the Inception V3 model is used to extract features from the selected data of each frequency band.The features of different frequency bands are analyzed by principal component analysis(PCA).The 2048-dimensional features of data in each frequency band are reduced to a 3-dimensional space,which will facilitate us to observe the feature distribution of data in each frequency band.As shown in Figure3,the observed situation is consistent with the conclusion of FID similarity measurement.The data of GSM1800UL,GSM900UL and HF are similar,while the data of GSM1800DL,GSM900DL and TV are quite different.In the previous work [14],we find that the services activities of GSM1800UL and GSM900UL are not very frequent.GSM1800DL,GSM900DL and TV have strong services activities at some frequency points.The reason for the large similarity difference may be the great difference in the degree of services activities between different frequency points.
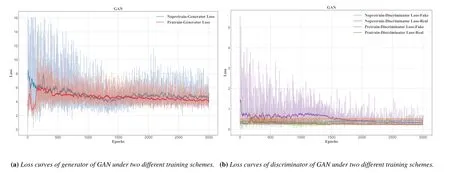
Figure5.The loss function performance of DCGAN under two different training schemes.
III.CROSS-BAND DATA AUGMENTATION FRAMEWORK
3.1 Design Rationale
Aiming at the issue of spectrum prediction under the condition of data scarcity,we propose a data augmentation framework for spectrum prediction based on generative adversarial network and deep transfer learning.The core idea of the framework is to generate data with high similarity to the target frequency band data through pre-trained generative adversative network,and then augment the data of the spectrum prediction model through deep transfer learning.More specifically,deep transfer learning aims to improve the performance of models by measuring differences between data sets to find transferable knowledge.Generative adversarial networks aim to generate similar data by approaching the distribution of the features of target samples.However,the traditional generative adversarial network has a certain demand for the number of target samples.When the number of target samples is scarce,the generative adversarial network tends to fall into the mode collapse.Deep transfer learning can solve the problem of mode collapse of generative adversarial network,while the generative adversarial network can reduce the strict requirement of deep transfer learning that source domain data must have similarity with target domain data.In this paper,three control groups are designed to verify the effectiveness of the proposed framework.As shown in Figure4,we design two comparative experiments for the three control groups of models.As shown in Figure4a,we directly train a DCGAN with target band data and used it as a benchmark model to verify that our proposed framework could generate higher quality data.As shown in Figure4b,we use the temporal-spectral residual network model of our early work [13]as the benchmark model to compare the effectiveness for spectrum prediction of the proposed framework.Deep transfer learning,which plays a key role in the whole framework,adopts the method of fine-tuning.The deep learning model is first pre-trained with the source domain data,then the parameters are transferred to the target domain deep learning model.Finally,a small amount of target domain data is used to train the model and fine-tune the parameters.
3.2 The Principle of Generating Transferable Data by GAN
The generative adversarial network [20]inspires the theory of domain adversarial learning and enriches the theory of transfer learning and domain adaptation learning.In the generative adversarial network method,we need to train a generator model and a discriminator model simultaneously in order to ensure that the data can be generated close to the feature distribution of the sample data.The discriminator model discriminate whether the data is a fake sample that generated by the generation model or a sample from the real data.According to [20],the sample distribution of real data ispdata.For the generator model,we define the input noise variable z∼pz,and the distribution of sampleG(z) generated by the generator ispg.For the discriminator model,D(x)represents the probability thatxis derived from real data rather than generated data.We train the generator as well as the discriminator model.Therefore,the goal of the training is to play a minmax game on the value functionV(D,G)of the discriminator and generator[20]:
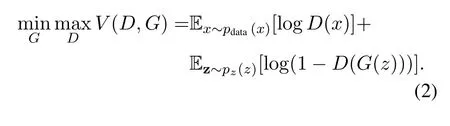
For the above formula,if and only ifPG=Pdata,the global minimum point of training goalC(G)=maxV(D,G) can be reached.Furthermore,whenPG=Pdata,the Jenson-Shannon divergence of the two distributions was 0,that is,JSD(Pdata|PG)=0.
Based on the above theoretical analysis,we can generate data that is highly similar to the distribution of real data for deep transfer learning by generative adversarial network.By generating highly similar data,the data can be augment under the condition that the real data is relatively scarce,so as to better train the deep learning model.
In this paper,DCGAN [21]is used.On the basis of DCGAN,the data with feature distribution similar to HF band are generated.Based on the high similarity between the generated data and the measured data,the temporal-spectral residual network is trained based on deep transfer learning.Finally,the multi-frequency point prediction based on deep transfer learning is completed.
3.3 Temporal-Spectral Residual Network
Based on the literature [13],the DTS-ResNet is the basic model for spectrum prediction.Residual unit and convolution unit are basic units of these modules.When the input of the convolution unit is denoted as X(0),its calculation is shown as follows[13]:
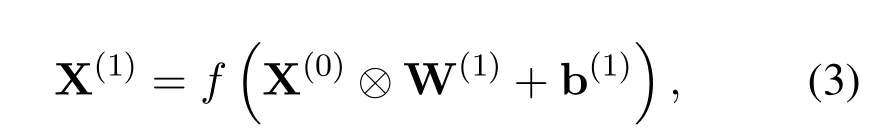
where W(1)represent convolution kernel,whose are adjustable parameters as well as b(1).whilef(.)represents activation function,⊗means convolution of the input data.when the input of the residual unit is denoted as X(l),its calculation is shown as follows[13]:
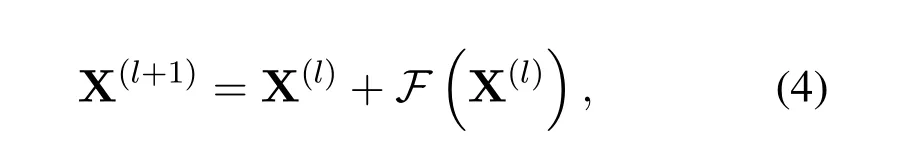
whereF(.)is the residual function.Through residual unit and convolution unit,the model can comprehensively quantify the correlation factors of spectrum data in different time scales.The final output is the prediction resultswhile real values in thet-th time are denoted as Xt.The prediction error is minimized by back propagation when DTS-ResNet is trained,which is shown as follows[13]:
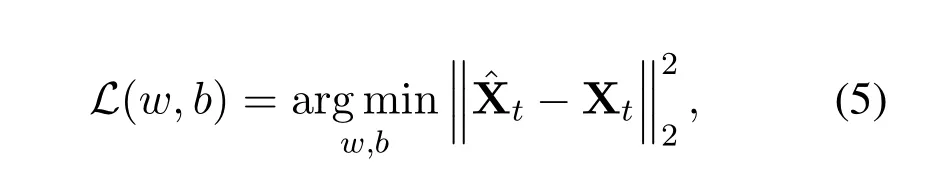
wherew,bmean trainable paremeters in DTS-ResNet.
In this paper,DTS-ResNet is used to verify the effectiveness of the data augmentation method.In order to ensure the effectiveness of experimental control,we keep the model parameters and settings unchanged.As shown in Figure4b,we directly used the spectral data of the target domain for training and output RMSE,and finally compared it with the proposed framework.
3.4 Data Augmentation of GAN With Pre-Training
In this paper,we compare the proposed framework with benchmark scheme to verify the necessity and the effectiveness of generative adversarial network crossband pre-training based on deep transfer learning.As shown in Figure4a,the benchmark scheme is designed to directly use the target frequency spectrum data to train GAN and generate data.According to the previous work,when the measured data is only 128 spectrum diagrams,it may be difficult for us to ensure that GAN can get better training and generate similar and diversified data.Because,when training data is scarce,GAN training tends to cause mode collapse.For our work,it may be detrimental to the training of spectrum prediction models.Furthermore,in GAN training,mode collapse is not easy to find,so it is necessary to verify the generated data with the help of good evaluation indicators.

Figure6.Pre-trained GAN in HF band data training.
As shown in Figure5,GAN without pre-training can also have better convergence under the training of spectral data in the target domain.However,the convergence of the model cannot be used as a judgment that GAN has been able to generate data that meets our actual needs.In order to test the effect of direct use of target domain data for GAN training,we used FID evaluation indicators to analyze the generated data.
For the experiment of the proposed framework,FID evaluation metric is used to measure the similarity between different datasets when we select data of other frequency bands for pre-training the generative adversarial network.After analysis,we found that GSM900UL frequency band dataset is the most similar to HF band dataset,but there are still some differences.Therefore,GAN can be pre-trained based on deep transfer learning by using GSM900UL data to help GAN achieve better training performance on HF data.
In order to observe whether the pre-training process can generate images similar to the spectral grayscale image,we show the images generated after the pretraining of the generative adversarial network the Figure7.Furthermore,we observe the training of pretrained generative adversarial network model in HF band data training.As shown in Figure5,we can see that after the pre-training of GAN based on deep transfer learning,the model gets better convergence in HF band data training and the convergence speed is faster.The image generated by pre-trained GAN in HF band data training is shown in Figure6.In order to ensure the reliability of generated data,we used FID evaluation metric to measure generated data and target domain spectrum data to verify that the pre-training of GAN based on deep transfer learning is helpful to improve the generation effect of GAN.
IV.EXPERIMENTAL RESULTS AND ANALYSIS
All experiments in this paper are based on tensorflow and keras.On the basis of DCGAN,we adjust the model according to the spectrum data images.In the model,we selected the optimization function as RMSProp [37]when training the discriminator,and we selected the optimization function as Adam [38]when training both the generator and the discriminator,and set the epoch=3000 and batchsize=64.In order to further verify the validity of the proposed framework,some spectrum prediction methods,such as CNN,LSTM,SVR and the method proposed in literature [14],which is called DA-LSTM in this paper,are introduced in the comparison experiment in addition to the benchmark method.The hyperparameters setting of all models is based on the basis of previous work [13,14]and common hyperparameters setting.In the whole training experiment,we observe the performance of GAN under different spectrum data conditions.We verify that under the condition of scarce target data,the pre-training of GAN based on deep transfer learning can make the generated data more similar to the target spectrum data.Finally,we verify the effectiveness of the data augmentation method based on generative adversarial network and deep transfer learning through temporal-spectral residual network.

Figure7.GAN is pre-trained using GSM900UL band data.

Table3.FID metrics between data generated by GAN with pre-training and HF band data
4.1 Effectiveness of Generating Data by GAN
Based on FID evaluation metric,we compare the experimental results of DCGAN and the proposed framework.As shown in the Table3,the FID evaluation metric of generated data in DCGAN is not even as good as the FID index of GSM900UL dataset.This reflects that the feature distribution of the generated images does not approximate the feature distribution of the sample data well when the HF band data is directly used to train the GAN.This is because the scarcity of HF sample data makes the generative adversarial network unable to get better training.The FID evaluation metric of generated data in the proposed framework is smaller than that of other frequency spectrum datasets.As shown in Figure6,although,due to the limitations of DCGAN,the data we generated is still a little fuzzy.However,combined with the comparison in Figure6 and the FID evaluation metric,the feature distribution of the generated data in the proposed framework is closer to the HF data.Therefore,the data we generated is still valid.Furthermore,in order to visualize the feature distribution of data in HF band,DCGAN and the proposed framework,we performed PCA dimension reduction on the three groups of data.After PCA,the spectral image features are reduced to 3 - dimensional features.This allows us to visualize the feature distribution of the spectral data.As shown in Figure8,the red points are the measured data of HF band,the blue points are the data generated by DCGAN,and the green points are the data generated by the pre-trained DCGAN.The distribution of green points is closer to that of most red points,while the distribution of blue points is relatively dispersed around the red points.Therefore,it can be concluded that the data generated in the proposed framework better fit the feature distribution of HF band data than the data generated in DCGAN.Obviously,the 3D distribution after dimensionality reduction of PCA basically conforms to the result of FID evaluation metric.We transfer the generative adversarial network pre-trained by other frequency band data to HF band for training,and used FID evaluation metric to verify the distribution of generated data and real data.
From the perspective of training generative adversarial network,the generated data in the proposed framework better fit the distribution of real data than other frequency band data,and at the same time avoid mode collapse.The control experiment of DCGAN and the pre-trained DCGAN is well verified.When the sample data is scarce,it will be difficult to train GAN.Therefore,deep transfer learning provides a solution based on deep transfer learning to augment the data of cross-band pre-training to the problem of scarce train-ing data of GAN.

Table4.Time cost for multiple methods
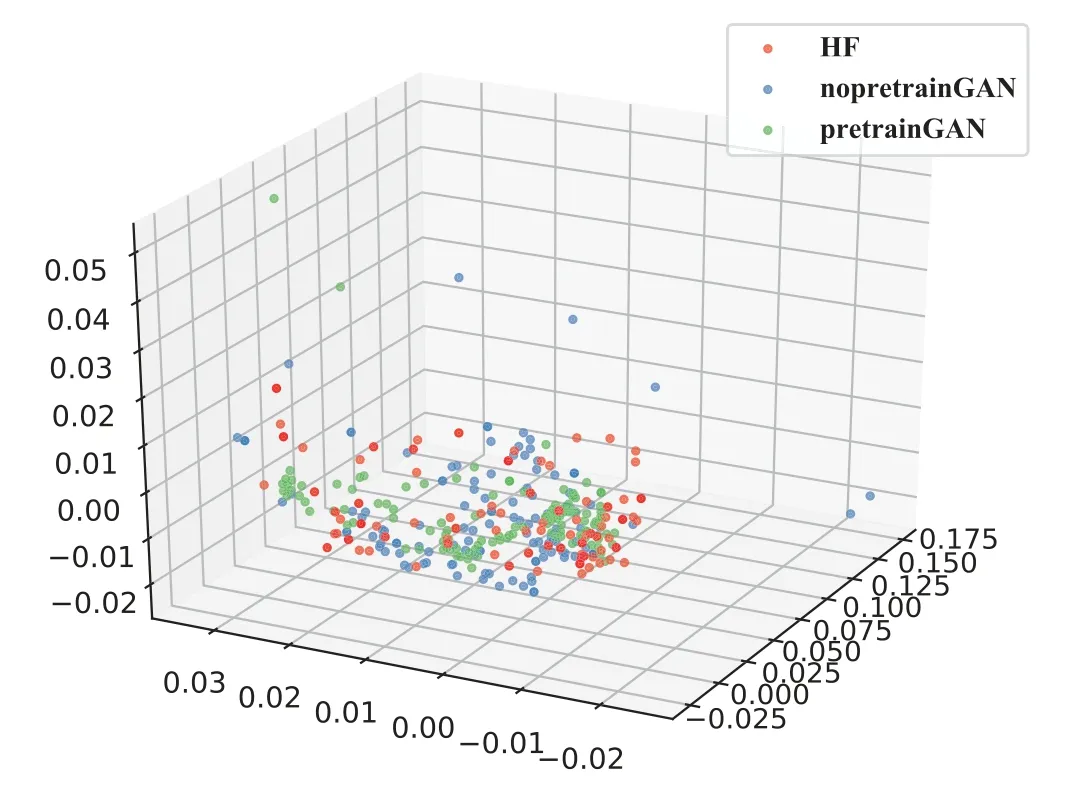
Figure8.Feature distribution of three kinds of data after PCA.

Table5.List of Abbreviations
From the perspective of transferable,the generated data of the proposed framework is a valid set of source domain data.The generated data can overcome the difference between the data across the frequency band through the GAN.The positive transfer can be realized by deep transfer learning of the model based on effectively generated data.In the actual experiment,due to the feature distribution of spectral data is a highdimensional complex distribution and the limitation of GAN structure designed in this paper,the feature distribution of generated data cannot completely approximate the feature distribution of real measured data.
4.2 Effectiveness of Spectrum Prediction With Cross-Band Data Augmentation Framework
Through the comparison experiment between DCGAN and the proposed framework,we get that when target data is scarce,the pre-training of GAN based on deep transfer learning is helpful to generate data that are similar to target spectrum data.However,further experiment is needed to verify that deep transfer learning based on data generated by the pre-trained DCGAN model can realize positive transfer of multifrequency point spectrum prediction model based on temporal-spectral residual network.As shown in Figure4b,we generate 4000 images using the DA-DTSResNet that has been trained.The 4,000 generated images is used to pre-train the temporal-spectral residual network.In benchmark scheme,we directly select 128 images of measured spectrum data in the target domain to train the temporal-spectral residual network.To further verify the performance of the proposed framework,we also compare some existing spectrum prediction methods,such as CNN,LSTM,SVR and DA-LSTM.We use root mean square error to compare the prediction accuracy of those models.As shown in Figure9,we used several methods predict simultaneously the frequency occupancy of HF points from 20MHz to 29.16MHz.We analyze the errors of each frequency point and found that all the models have huge errors at the frequency point near 27.32MHz.From the time dimension analysis of the actual spectrum data,time series of frequency points near 27.32MHz are less predictable.This phenomenon can be further transformed into a problem with weak temporal correlation.The problem may be due to the abnormal usage frequency at the frequency point near 27.32MHz.Moreover,as shown in the Table4,we analyze the time cost of those methods.CNN and SVR require less training time,but the RMSE of two methods are not as good as other methods.LSTM is better than CNN and SVR in root mean square error,but the training time is much more than other methods.DA-DTS-ResNet has lower time cost and RMSE than DTS-ResNet at the same target frequency band data scale.For the multi-frequency point prediction,although RMSE of DA-LSTM at a few frequency points is better than that of DA-DTS-ResNet,the time cost of DA-LSTM is much higher than that of DA-DTSResNet.
In general,the prediction performance of the DADTS-ResNet is better than the DTS-ResNet and other spectrum prediction methods.Therefore,we can draw the conclusion that the data augmentation method based on generative adversarial network and deep transfer learning can effectively solve the problem of multi-frequency point prediction under the condition of scarce spectrum data.
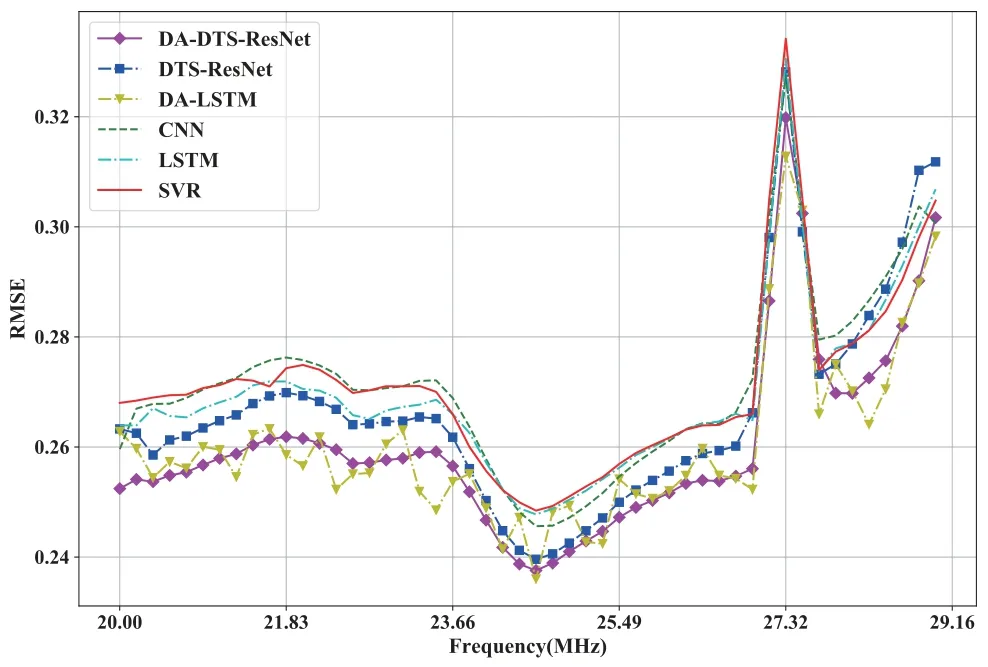
Figure9.RMSE comparisons for multiple methods.
V.CONCLUSION
In this paper,data augmentation of scarce real spectrum data is carried out by generating highly similar data based on deep transfer learning and GAN.First,we have conducted the correlation analysis on realworld spectrum data.We mine the autocorrelations of spectrum data in different time scales and between different frequency points,and the cross-correlations of spectrum data between frequency bands.Then,we have developed a cross-band data augmentation framework.When the target data is scarce and existing datasets are limited,the framework can generate data of higher quality for spectrum prediction.Finally,we have shown the spectrum prediction performance of cross-band data augmentation framework with different data scales.The proposed framework can help improve spectrum prediction in both the accuracy and time cost.Data augmentation method for environment-resilient spectrum prediction is an interesting direction for future work.
ACKNOWLEDGEMENT
This work was supported by the Science and Technology Innovation 2030-Key Project of “New Generation Artificial Intelligence” of China under Grant 2018AAA0102303,the Natural Science Foundation for Distinguished Young Scholars of Jiangsu Province(No.BK20190030)and the National Natural Science Foundation of China(No.61631020,No.61871398,No.61931011 and No.U20B2038).

- China Communications的其它文章
- Edge Caching in Blockchain Empowered 6G
- Layered D2D NOMA
- Fully Connected Feedforward Neural Networks Based CSI Feedback Algorithm
- Erasure-Correction-Enhanced Iterative Decoding for LDPC-RS Product Codes
- Power Allocation for NOMA in D2D Relay Communications
- A Game-Theoretic Perspective on Resource Management for Large-Scale UAV Communication Networks