
一种融合主题特征的自适应知识表示方法
2021-01-15 07:17陈文杰
计算机工程 2021年1期
陈文杰
(中国科学院成都文献情报中心,成都 610041)
0 概述
知识图谱是由三元组构成的结构化语义知识库,其以符号的形式描述现实世界中实体和实体间的连接关系。知识表示学习旨在用低维稠密的向量来表示知识图谱中的实体或关系,向量间距离越近,则向量所表示的实体和关系在语义上就越相似。这种基于向量的知识表示形式能够通过简单的数值计算来识别新的实体和关系,从而发现知识图谱中的潜在知识和隐性假设,并且可以作为一种先验知识输入深度神经网络,有效监督和约束网络的训练过程。
按照关系两端实体的连接数量,可以将关系划分为1-1、1-N、N-1 和N-N 4 种类型,其中,除1-1 以外的3 种关系都被称为复杂关系。在现有的表示模型中,TransE 模型最具代表性,但该模型过于简单,仅在1-1 简单关系上效果明显。针对复杂关系,一系列基于TransE 的扩展模型先后被研究者提出。然而,此类模型仅通过知识图谱中的三元组信息进行学习,大量与实体和关系相关的信息未能得到有效利用,如实体和关系的描述信息和类别信息等,而这些多源异构的信息可以缓解数据稀疏问题,提升模型对于复杂关系的建模能力[1]。
为有效利用实体的描述信息,文献[2]提出DKLR模型。该模型利用连续词袋(Continuous Bag of Words,CBOW)模型和卷积神经网络(Convolutional Neural Network,CNN)模型将描述文本转换为实体的表示向量,并将其用于TransE 模型的训练中,有效地增强了实体的区分度[2]。目前关于关系描述信息处理的研究较少。事实上,知识图谱中实体和实体之间存在大量的交互信息,例如:社交工具上用户之间存在着大量的交谈、评论、留言和转发等文本信息;图书情报领域中作者间的合作关系包含论文标题、关键词和摘要等详细信息。因此,如何充分利用关系上丰富的语义信息实现知识表示学习,具有广阔的研究前景。
本文提出一种融合主题特征的自适应知识图谱表示方法,即TransATopic 模型。利用潜在狄利克雷分布(Latent Dirichlet Allocation,LDA)主题模型挖掘关系以描述文本中隐含的主题信息,基于变分自编码器(Variational Autoencoder,VAE)构建关系向量。在此基础上,通过引入对角矩阵将损失函数的度量由欧式距离改进为马氏距离,从而增强距离度量的灵活性。
1 相关工作
为更好地描述相应的算法模型,本文给出相关的定义和符号表示。给定任意一个三元组(h,r,t),其中,h表示头实体,r表示关系,t表示尾实体。Vh、Vr和Vt为三元组每个元素对应的表示向量,S为知识图谱中的三元组集,S′为三元组的负采样集。若(h,r,t)∈S,则表示(h,r,t)是正三元组;若(h,r,t)∈S′,则表示(h,r,t)为负三元组。同时,以E表示实体集,R表示关系集。
受词向量间的平移现象启发,BORDES 等人提出了TransE 模型[3]。该模型将关系r对应的向量Vr作为头实体向量Vh和尾实体向量Vt间的平移向量。由于Vr也可以视为从Vh到Vt的翻译,因此TransE 通常被称为基于翻译的模型。对于每一个三元组(h,r,t),TransE 的目的是使Vh+Vr≈Vt,因此,定义如下损失函数:

该函数值即表示向量Vh+Vr和Vt之间的L1或L2距离。在实际的训练过程中,TransE 采用最大间隔法来增强知识表示的区分能力。
为解决TransE 模型处理复杂关系时的局限性问题,基于翻译的Trans 系列模型在TransE 的基础上进行了改进和补充,其中一类有效的改进是令每个实体在不同的关系下拥有多个向量表示。TransH[4]通过引入关系相关的超平面Wr将实体映射到超平面上:

StransH[5]结合了SE 模型和TransH 模型,一方面将头尾实体映射到关系对应的超平面上,另一方面利用单层神经网络增强实体和关系间的语义关系。PtransW[6]则利用关系路径和关系类型的语义信息对TransH 进行了扩展。
TransR[7]和TransH类似,假设不同关系拥有不同的语义空间,定义了映射矩阵Mr,将实体映射到关系对应的语义空间中:

TransRD[8]利用非对等转换矩阵分别对头实体和尾实体进行映射,并在模型训练中采用AdaDelta算法自适应调整学习率。文献[9]利用卷积神经网络编码实体的描述文本得到实体的表示,并使用不同的低秩矩阵对实体进行映射。文献[10]同样采用卷积神经网络编码实体的描述文本,通过注意力机制筛选文本中的有效信息,并引入位置信息和门机制得到最终的表示向量。
TransR 具有较强的复杂关系建模能力,但由于其为每个关系引入映射矩阵,因此导致参数过多,大幅增加了模型的复杂度。为简化模型,TransD[11]将映射矩阵Mr分解为2 个映射向量的乘积,定义(h,r,t)对应的映射向量为Wh、Wr和Wt,得到:

文献[12]在TransD 模型的基础上,联合了图像和文本等多模态数据。TransParse[13]使用稀疏矩阵来代替稠密的映射矩阵Mr,其中稀疏度θr由关系r连接的实体数量决定:

不同于实体映射方法,另一类改进TransE 的策略是放宽Vh+Vr≈Vt这一约束条件。TransM[14]为每个三元组(h,r,t)赋予一个关系相关的权值θr,定义如下损失函数:
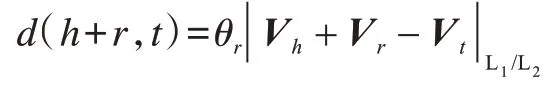
当r属于复杂关系时该函数中的权值较低,使得Vt在空间上离Vh+Vr更远。ManifoldM[15]则是令三元组满足使得Vt靠近以θr为半径的流形区域。TransF[16]要求向量Vt与向量Vh+Vr方向相同,同时Vh与Vt-Vr也具有相同的方向,定义如下损失函数:
d(h+r,t)=(Vh+Vr)TVt+(Vt-Vr)TVh
TransA[17]增加了一个非负的权重矩阵Wr,其为每一维学习不同的权重,在处理复杂关系时更为灵活。TransAH[18]融合了TransA 和TransH 两个模型,其在各项实验指标上取得了很大进步。TransE-SNS[19]基于K-means 算法对实体进行聚类,然后在负采样过程中从目标实体所在的簇中随机选择一个实体来替换目标实体,从而改善了负三元组集的质量。TCSF[20]则在知识表示中融合了关系的先验概率、三元组距离和实体与关系上下文的拟合度等多种特征。
同一关系的语义在不同的实体间可能存在差异,如不同作者间合作的论文通常不同。因此,实体间的关系具有动态性和复杂性,仅通过单个向量无法准确地表示关系。TransG[21]模型假设一个关系可能包含多种语义,对每种语义使用一个高斯分布来刻画,其中某些关系还可以被更细致地划分,如FreeBase 中的“/location/contains”关系可以用来表示国家包含某城市、国家包含某所大学或省包含某城市。CTransR[7]通过对头实体和尾实体的差值Vh-Vt进行聚类,将关系细分为多个子关系,分别用向量表示每个子关系。
2 TransATopic 知识表示方法
本节介绍一种基于主题特征的自适应知识图谱表示方法,分别采用基于主题模型和变分自编器的关系向量构建方法与自适应度量方法解决复杂关系建模问题,并将两个方法融合在所构建的TransATopic模型中,实现模型的快速训练和计算。
2.1 基于主题模型和变分自编器的关系向量构建
TransE 模型采用一种朴素的优化方法,即使Vh+Vr-Vt=0,根据优化规则可以得到以下结果:
1)若(h,ri,t)∈S,i∈{0,1,…,n},可推得
2)若(hi,r,t)∈S,i∈{0,1,…,m},此时r是1-N 关系,可推得同理,如果r是N-1 关系,则存在三元组(h,r,ti)∈S,可推得
TransE 等基于翻译的模型往往把关系看作简单的实值向量,忽略了关系上丰富的文本信息,因而难以处理复杂关系。LDA 主题模型是一种非监督模型,能够用来识别大规模文本集中隐含的主题信息,被广泛应用于文本分类和自动摘要等文本分析任务中[22]。基于此,本文考虑利用LDA 主题模型抽取关系描述文本中潜在的主题特征,并基于主题特征构建关系向量。LDA 训练后会生成两个分布,即文本-主题概率分布θ和主题-词概率分布φ,如表1 和表2所示。表1 反映每个文本在各个主题上的分布概率,表2 则反映每个词在各个主题中的权重。如果直接将关系描述文本d对应的主题概率分布θd作为关系向量,此时θd中主题的个数必须与表示向量的维数相同,且θd中每一维的值(主题出现的概率)都为正,势必影响知识表示的灵活性和可推理性。

表1 文本-主题概率分布Table 1 Document-topic probability distribution

表2 主题-词概率分布Table 2 Topic-word probability distribution
本文采用变分自编码器(VAE)[23]建模主题分布特征,以无监督的方式构造关系向量,VAE 的结构如图1 所示。其中,编码器的输入为x,输出为变分分布q(z|x;φ),z是潜在向量,φ是推断网络的参数。解码器的输入为z,输出为概率分布p(x|z;ω),ω是生成网络的参数。令x=θd,潜在向量z即为构造的关系向量。
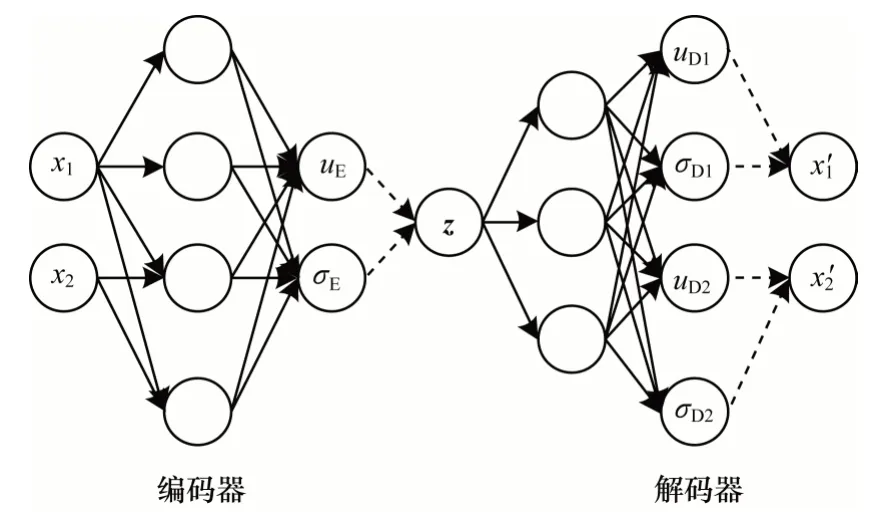
图1 变分自编码器示意图Fig.1 Schematic diagram of VAE
VAE 假设q(z|x;φ)服从对角化协方差的正态分布,即因此,编码器由以下两层神经网络构成:

其中,W(1)、W(2)、W(3)和b(1)、b(2)、b(3)构成推断网络的参数φ,sigmoid 和softplus 是激活函数。在解码器中,VAE 假设p(x|z;ω)同样服从对角化协方差的正态分布,即由解码器预测得到。
VAE 的误差包括重构误差和KL-散度误差,总体目标函数如下:
maxE[lnp(x|z;ω)-DKL(q(z|x;φ)||p(z;ω))
其中,先验分布p(z;ω)=N(z|0,I)。VAE 通过“再参数化”采样得到潜在向量,令z=μE+σE⊙ε,将从正态分布采样转换为标准正态分布N(0,I)采样,从而保证模型的训练效率。
传统基于翻译的表示模型实体区分效果如图2(a)所示,由于模型没有对关系r进行主题识别,导致r的所有语义混在一起,因此无法对多个实体进行有效区分。假设:三元组(h,r,ti)中关系描述文档为d1,其中i∈{1,2,3};三元组(h,r,ti)中关系描述文档为d2,其中i∈{4,5,6,7}。本文将输入VAE 中,得到关系向量根据不同的描述文本,将同一关系表示为不同向量,从而有效地区分出白色实体和灰色实体,提高了知识表示的准确度,如图2(b)所示。

图2 传统模型与TransATopic 模型的实体区分效果Fig.2 Comparison of entity discrimiation effects by traditional model and TransATopic model
2.2 自适应度量方法
为有效处理复杂关系,一系列模型在TransE 的基础上进行了改进和补充,如TransH、TransR 和TransD。这类翻译模型通常根据不同的规则对实体向量进行转换,但采用同样的损失函数:
d(h+r,t)=(Vh+Vr-Vt)T(Vh+Vr-Vt)
由上式可知,损失函数采用欧式距离度量向量间的差异。由于在欧式距离度量中所有特征维度权重相同,灵活性不够,导致知识表示能力较差,因此通常考虑引入权重矩阵将欧式距离替换为自适应的马氏距离,为每一维学习不同的权重[17]。对损失函数改进如下:
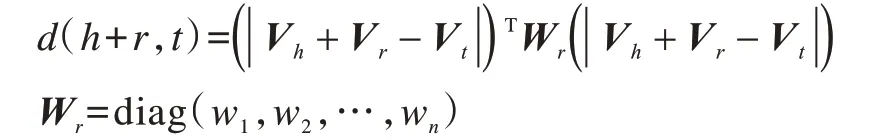

图3 欧式距离度量与马氏距离度量效果比较Fig.3 Comparison of distance measurement effects by Euclidean distance and Mahalanobis distance
2.3 TransATopic 模型架构与训练
将基于主题模型和变分自编器的关系向量构建方法与自适应度量方法进行融合,用一个统一的模型TransATopic 来表示,如图4 所示。

图4 TransATopic 模型整体架构Fig.4 Overall architecture of TransATopic model
该模型整体的损失函数如下:

其中,d是关系r上的描述文本,Zd是VAE 构建的关系向量。在实际的模型训练过程中,TransATopic 与TransE 一样采用最大间隔法来增强知识表示的区分能力,其目标函数如下:

其中,[x]+表示正值函数,m表示间隔距离,S'(h,r,t)是三元组(h,r,t)的负采样集。通过将h和t替换为实体集中随机选择的某个实体,得到:

该目标函数的主要目的是最大化正三元组与负三元组间的距离。
在模型的具体训练过程中,采用随机梯度下降法来优化目标函数,通过计算梯度实现向量和参数的自动更新,如算法1 所示。

该训练算法将三元组集和关系的描述文本集作为输入,首先利用LDA 主题模型生成文本-主题概率分布θ,然后将主题分布特征输入变分自编码器中得到编码矩阵Z,最后进行迭代训练:从三元组集S中随机选取小批量三元组得到Sbatch,其中每个三元组(h,r,t)从Z中获取对应的关系向量Vr并生成一个负采样集计算一对正负三元组的距离L,并计算梯度更新实体向量和权重矩阵(算法第11 行~第13行)。假设迭代训练了p次,批量的大小为b,每次负采样K个三元组,则迭代训练部分的时间复杂度为O(pbk)。迭代训练中的参数是表示向量和权重对角矩阵,假设向量的长度为n,则参数复杂度为O(|S|n)。
3 实验验证
本文采用Arnet-S、Arnet-M、FB13 和FB15K 数据集验证TransATopic的有效性。ArnetMiner[24]是一个提供基于社交网络的搜索和挖掘服务的学术网站,其中发布了一个包含1 712 433 名作者、2 092 356 篇论文和4 258 615 种合作关系的数据集。本文将作者作为实体,合作论文的标题和摘要作为关系的描述文本,从ArnetMiner 中抽取出两个不同规模的数据集Arnet-S 和Arnet-M[25]。FB13 和FB15K 均是Freebase 的子集,其中,FB13 包含13 种关系,FB15K 包含1 345 种关系,本文将维基百科作为语料集抽取出每个关系对应的描述文本[26]。实验数据集的详细信息如表3 所示。

表3 实验数据集描述Table 3 Description of datasets for experiment
本文基于ArnetMiner 和Freebase 的子数据集,针对链接预测和三元组分类任务进行实验,从不同的角度评估模型预测能力和精确度。由于TransATopic模型的效果受数据规模和参数设定等因素影响,因此分别在不同因素设定下进行测试。为分析TransATopic 的实验效果,选择以下两类不同的模型进行比较:1)基于TransE 的距离模型,以TransH、TransA 和TransG 为代表;2)基于随机游走策略的表示模型,通常用于学习网络的结构特征。第1 类模型已在上文相关工作中详细介绍,不再赘述。第2 类模型介绍如下:
1)DeepWalk 通过随机游走构造节点和边的序列,将序列视为一种特殊的“上下文”,利用skip-gram模型将节点和边转换为表示向量。
2)Node2vec 是DeepWalk 的扩展,其通过超参数控制随机游走的广度和深度,使得节点和边的表示既包括局部网络结构特征,又包括更深层的全局结构信息。
3.1 链路预测
对于一个三元组(h,r,t),链路预测的主要任务是给定(h,r)预测t或给定(r,t)预测h,从而评估模型预测实体的能力。本组实验将Arnet-S 和FB15K 作为数据集,采用与TransE 相同的评价指标,即MeanRank 和HITS@k,以便与TransE 等现有模型进行比较。其中,MeanRank 表示测试集中三元组的平均排序得分,HITS@k表示排序不超过k的三元组在测试集中所占的百分比。MeanRank 的值越小或HITS@k的比例越高,表明实验结果越好。排序的计算过程如下:
1)对于测试集中的一个正确三元组(h,r,t),随机丢弃头实体h或尾实体t,得到不完整三元组(r,t)或(h,r)。
2)从实体集中随机选择一个实体,补全不完整三元组,得到错误三元组(h',r,t)或(h,r,t')。重复此过程多次,得到负采样集。
3)利用损失函数d(h+r,t)计算正确三元组和负采样集中三元组的值,并对结果进行排序。
需要注意的是,由于不完整三元组补全后可能恰好与知识图谱中某个正确三元组相同,负采样集和训练集、测试集存在交集,这个交集会干扰三元组的排序值,因此,在生成负采样集时需要过滤掉该部分的三元组,将此过程称为Filter,将未经Filter 的过程称为Raw。Filter 后的实验结果往往更好,具有更低的MeanRank 和更高的HITS@10 指标值。
在训练TransATopic 模型时,将主题的个数k设置为50,表示向量的维数设置为20,学习率η设置为0.01,间距m设置为2。TransATopic 与TransE 等现有模型的实验对比结果如表4 和表5 所示,其中,加粗数据表示MeanRank、HITS@5 和HITS@10 指标的最优值。

表4 Arnet-S 实验对比结果Table 4 Comparison of experimental results in Arnet-S

表5 FB15K 实验对比结果Table 5 Comparison of experimental results in FB15K
可以看出,相较于TransA 模型,TransATopic 的MeanRank 指标更低,HITS@k指标更高,验证了基于主题分布特征的表示方法和自适应度量方法融合的有效性,表明TransATopic 在向量表示和链路预测上具有明显的优势。在FB15K 中边和节点的数量比为39.6,而在Arnet-S 中为8.6,因此,FB15K 中边的密度更大且关系更为复杂。相较于TransE 模型,TransATopic 在Arnet-S 数据集上HITS@k平均提升21%,在FB15K 上平均提升39%,这进一步说明TransATopic 在处理多语义复杂关系上具有更大优势。
3.2 三元组分类
三元组分类任务主要用于验证模型识别正确三元组和错误三元组的能力。对于给定的三元组(h,r,t),首先计算模型损失函数d(h+r,t)的值,如果大于某个阈值,则将该三元组划分为正确三元组,反之划分为错误三元组;然后判断三元组分类结果的正确性,若正确则生成正标签;否则生成负标签;最后统计正负标签数量,计算三元组分类的准确率。TransATopic 与TransE 等模型在数据集Arnet-M 和FB13 上的实验对比结果如表6 所示,其中,加粗数据表示准确率指标的最优值。

表6 三元组分类准确率对比Table 6 Accuracy comparison of triple classification %
可以看出,在Arnet-M和FB13数据集中,DeepWalk和Node2vec 的准确率最低,这说明基于翻译的表示模型更适用于大规模的数据集。相较于TransE 模型,TransATopic在Arnet-M上准确率平均提升10%,在FB13上平均提升7%。由于Arnet-M 上边和节点的数量远大于FB13,说明Arnet-M 是一个规模更大且关系更为复杂的网络,因此表明TransATopic 在Arnet-M 上能够更好地提高三元组的分类效果。此外,相较于TransA 模型,TransATopic 在准确率上同样取得了一定的进步,说明关系的主题分布特征能够有效提高知识表示的区分度。
4 结束语
传统基于翻译的知识表示方法在复杂关系建模和距离度量上存在不足,影响了知识表示的区分度。为此,本文提出TransATopic 模型。在复杂关系建模过程中,基于主题模型和变分自编码器建模关系的主题分布特征,提高关系向量的区分度;在距离度量过程中,使用一种自适应度量方法,通过引入非负对角矩阵,将损失函数的度量由欧式距离转换为马氏距离,为向量的每一维赋予不同的权重,从而增强度量的灵活性。现有的知识表示方法通常粗略地将关系划分为1-1、1-N、N-1 和N-N 4 种类型,然而实体在空间中往往呈现出层次结构。文献[27]利用双曲线代替欧几里得嵌入空间来表示分层数据,在嵌入图形时取得了较好的结果。受此启发,下一步拟基于双曲空间改进TransATopic 模型,并且将其应用于关系抽取、语义解析和实体聚类等任务。
猜你喜欢
上海文化(文化研究)(2022年3期)2022-06-28
数学年刊A辑(中文版)(2022年4期)2022-02-16
山西大学学报(自然科学版)(2021年1期)2021-04-21
中国外汇(2019年18期)2019-11-25
数学年刊A辑(中文版)(2019年3期)2019-10-08
五邑大学学报(自然科学版)(2019年3期)2019-09-06
计算机技术与发展(2018年12期)2018-12-20
哲学评论(2017年1期)2017-07-31
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
