
面向深度学习模型的对抗攻击与防御方法综述
2021-01-15 07:17张立国
计算机工程 2021年1期
姜 妍,张立国
(哈尔滨工程大学计算机科学与技术学院,哈尔滨 150001)
0 概述
随着人工智能技术的快速发展,深度学习已广泛应用于图像分类[1-3]、目标检测[4-6]和语音识别[7-9]等领域,但由于其自身存在若干技术性不足,导致深度学习在给人们生活带来极大便利的同时也面临着较多挑战,模型算法的安全隐患更是加剧了深度学习技术被对抗样本欺骗以及隐私泄露等安全风险,因此深度学习的安全问题[10]引起了研究人员的广泛关注。在早期研究中,针对深度学习算法潜在攻击以及相应防御方法的研究,主要关注模型的攻击成功率以及是否能够成功规避某种攻击方法。以传统的分类模型为例,其存在判断准确度越高则模型鲁棒性越低这一问题,因此,学者们开始关注模型鲁棒性和准确度的平衡问题。
现有综述性文献多数倾向于阐述传统的对抗攻击与防御方法。近年来,对抗样本的研究变得多样化,早期研究通常将对抗样本视为神经网络的一种威胁,近期学者们聚焦于如何在不同领域利用对抗样本的特性来更好地完成分类和识别等任务。
2013 年,SZEGEDY等人[11]利用难以察觉的扰动来揭示深度神经网络的脆弱特性。2014 年,GOODFELLOW等人[12]提出对抗样本的概念。此后,越来越多的研究人员专注于该领域的研究。早期的研究工作致力于分析不同深度学习模型(如循环神经网络、卷积神经网络等)中的漏洞以及提高模型对对抗样本的鲁棒性。BARRENO 等人[13]对深度学习的安全性进行了调研,并针对机器学习系统的攻击进行分类。PAPERNOT 等人[14]总结了已有关于机器学习系统攻击和相应防御的研究成果,并系统分析机器学习的安全性和隐私性,提出机器学习的威胁模型。近年来,针对对抗样本的研究更加多样化。2019 年,XIE 等人[15]提出利用对抗样本改进图像识别模型精度的方法。2020 年,DUAN 等人[16]利用风格迁移技术[17]使对抗样本在物理世界变得人眼不可察觉,以达到欺骗算法的目的。由于深度学习模型存在脆弱性,类似的对抗攻击同样会威胁深度学习在医疗安全、自动驾驶等方面的应用。
自从对抗攻击的概念被提出之后,研究人员不断提出新的攻击方法和防御手段。现有的对抗攻击方法研究主要针对对抗样本的生成方法以及如何提高对模型的攻击成功率,对抗防御研究主要关注基于对抗样本的检测与提高模型鲁棒性2 个方面。本文介绍对抗样本的概念、产生的原因及对抗样本的可迁移性,分析现阶段经典的对抗样本生成方法以及检测手段,并归纳针对上述检测手段的防御策略,通过梳理分析较为先进的对抗样本应用方法以展望该领域未来的研究方向。
1 对抗攻击
1.1 深度学习
深度学习[18]是一种深层模型,其利用多层非线性变换进行特征提取,由低层特征抽取出高层更抽象的表示。从广义上而言,深度学习所用到的神经网络主要分为循环神经网络[19]、深度置信网络[20]和卷积神经网络[21]等。与所有连接主义模型固有的脆弱性问题相同,深度学习系统很容易受到对抗样本的攻击。
1.2 对抗攻击的概念
对抗样本指人为构造的样本。通过对正常样本x添加难以察觉的扰动η,使得分类模型f对新生成的样本x'产生错误的分类判断。新生成的对抗样本为x'=x+η,即:

目前,寻找扰动的主流方法包括快速梯度攻击(FGSM)[12]、C&W 攻击[22]、替代黑盒攻击[23]、DeepFool攻击[24]、单像素攻击(One-Pixel Attack,OPA)[25]、AdvGAN 攻击[26]、通用对抗扰动[27]和后向传递可微近似(Backward Pass Differentiable Approximation,BPDA)方法[28]等。一些研究成功攻击了除卷积神经网络和深度神经网络之外的其他深度学习模型,甚至在现实世界中产生对抗的实例,如对抗眼镜[29]、对抗停止标志[30]等,这些都对物理世界中的深度学习系统造成了干扰。
图1 所示为通过FGSM 方法生成的对抗样本,加入了扰动的对抗样本使左图的熊猫被错误分类为长臂猿。FGSM 方法在各个维度上移动相同大小的一步距离,虽然一步很小,但每个维度上的效果相加,也足以对分类器的判别结果产生显著影响,因此,FGSM 攻击方法可应用于任何可以计算∇x L(x,y)的深度学习模型。

图1 FGSM 方法生成的对抗样本Fig.1 Adversarial samples generated by FGSM method
对抗样本可以轻易欺骗某种深度神经网络模型,且其具有可迁移性[31],可用于欺骗其他模型。对抗样本的可迁移性分为以下3 种类别:
1)在同一数据集训练的不同模型之间的可迁移性,如深层神经网络下的VGG16[32]和ResNet[2]之间。
2)在不同机器学习技术之间的可迁移性,如支持向量机[33]和深度神经网络之间。
3)在执行不同任务的模型之间的可迁移性,如语义分割[34]、图像分割和目标检测模型之间。
影响样本可迁移性的4 个因素具体如下:
1)模型类型。PAPERNOT 等人[35]研究发现,深度神经网络和k 近邻算法对跨技术可迁移性更为稳健,但对技术内可迁移性较为脆弱,线性回归[36]、支持向量机、决策树[37]和集成方法对技术内可迁移性更为稳健,但对跨技术可迁移性较为脆弱。
2)对抗样本的攻击力。KURAKIN 等人[38]研究发现,能够穿透坚固防御模型的更强的对抗样本不太可能迁移到其他模型,而生成攻击但并未成功攻击防御模型的对抗样本更容易迁移,为渗透特定防御方法而产生的对抗样本可能“过拟合”欺骗特定模式。
3)非目标攻击比目标攻击更容易迁移。LIU 等人[39]通过研究ImageNet 数据集的可迁移性,发现可迁移的非目标对抗样本比目标样本更多,且不同模型的决策边界一致。
4)数据的统计规律。JO 和BENGIO[32]认为卷积神经网络倾向于学习数据中的统计规律而非抽象概念。由于对抗样本具有可迁移性,使其在同一数据集上训练的模型之间可迁移,这些模型可能学习相同的统计信息从而落入同样的“陷阱”。
1.3 对抗样本的产生原因
自从对抗样本被发现以来,其产生原因一直是学者们争议的热点。
2014 年,SZEGEDY 等人[11]认为对抗样本位于数据流形的低概率区域,由于分类器在训练阶段只学习局部子区域,而对抗样本超出了学习的子集,导致深度神经网络分类错误。如图2 所示,A 类和B 类分别表示不同的样本空间,模型训练所得的分类边界(曲线)与真实决策边界(直线)并不重合,在曲线与直线相交的区域出现样本会导致模型判断失误,曲线和直线包围的区域即为对抗区域。
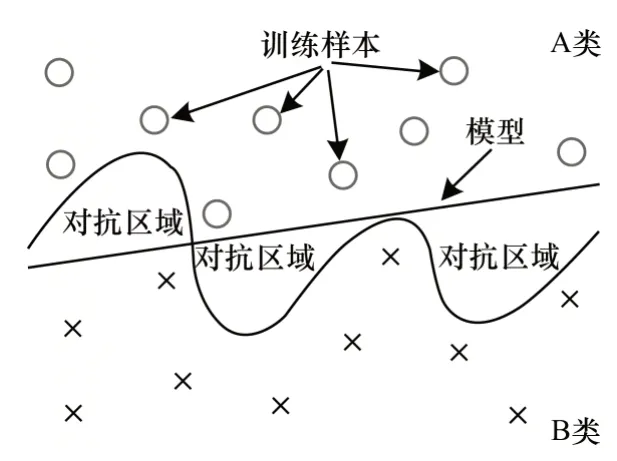
图2 对抗样本区域Fig.2 The area of adversarial samples
2015年,GOODFELLOW 等人[12]反驳了SZEGEDY等人的观点,认为深度神经网络的脆弱性是由于模型的局部线型特性所导致,特别是模型使用如ReLU[35]或Maxout[40]等线性激活函数时,更容易受到对抗样本的攻击。虽然神经网络也使用非线性激活函数,但是为避免出现梯度消失等现象[40-42],研究人员通常在激活函数的线性区域内训练网络。此外,GOODFELLOW 等人认为快速梯度攻击是基于线性假设而设计的,能够有效欺骗深层神经网络,从而验证了神经网络行为类似于线性分类器的论点。
2017 年,ARPIT 等人[31]通过分析神经网络对训练数据的记忆能力,发现记忆能力强的模型更容易受到对抗样本的影响。
2018 年,GILMER等人[43-44]认为数据流形的高维几何结构产生了对抗样本,他们在合成数据集的基础上对对抗样本与数据流形高维几何结构之间的关系进行了分析论证。
截至目前,深度学习模型易受对抗样本攻击的原因仍然是一个开放的研究课题,缺乏完备的理论体系,这也制约着深度学习系统的进一步发展。
2 对抗样本的攻击方式及目标
根据攻击者掌握的模型信息可将攻击分为白盒攻击与黑盒攻击2 种,通过攻击者选择的攻击目标可将攻击分为目标攻击、无目标攻击和通用攻击3 种。
2.1 攻击方式
白盒攻击与黑盒攻击具体如下:
1)白盒攻击:攻击者了解攻击模型的详细信息,如数据预处理方法、模型结构和模型参数等,某些情况下攻击者还能掌握部分或全部的训练数据信息。在白盒攻击环境中,攻击者对可攻击的模型拥有控制能力,能够观测并设计相应的攻击策略并更改程序运行时的内部数据。
2)黑盒攻击:攻击者不了解攻击模型的关键细节,攻击者仅能够接触输入和输出环节,不能实质性地接触任何内部操作和数据。在黑盒攻击环境中,攻击者可以通过对模型输入样本并根据模型的输出信息来对模型的某些特性进行推理。
2.2 攻击目标
目标攻击、无目标攻击和通用攻击具体如下:
1)目标攻击:攻击者指定攻击范围和攻击效果,使被攻击模型不但样本分类错误并且将样本错误分类成指定的类别。
2)无目标(无差别)攻击:攻击者的攻击目标更为宽泛,攻击目的只是让被攻击模型对样本进行错误分类但并不指定分类成特定类别。
3)通用攻击:攻击者设计一个单一的转换,例如图像扰动,该转换是对所有或者多数输入值造成模型输出错误的攻击。
3 对抗样本的生成方法
现阶段较为经典的攻击方法是FGSM 方法及其变体、C&W 攻击、替代黑盒攻击、DeepFool 攻击、单像素攻击、AdvGAN 攻击、通用对抗扰动、后向传递可微近似方法,具体如下:
1)FGSM 方法。FGSM 方法最早由GOODFELLOW等人[12]提出,其工作原理是计算输入的损失函数的梯度,并通过将一个选定的小常数乘以梯度的符号向量来产生一个小的扰动,如下:
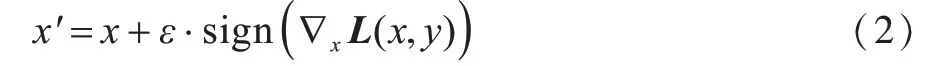
其中,ε表示调节系数,∇x L(x,y)是相对于输入x损失函数的一阶导数。FGSM 是早期经典的攻击方法,此后衍生出许多以FGSM 为基础的对抗攻击方法,如基本迭代方法(Basic Iterative Method,BIM)、动量迭代的FGSM 方法和多样性的FGSM 方法等。
(1)基本迭代方法。BIM 是FGSM 的一种拓展,由KURAKIN 等人[38]提出。BIM 通过迭代的方式沿着梯度增加的方向进行多步小的扰动,并且在每一小步后重新计算梯度方向,迭代过程如下:
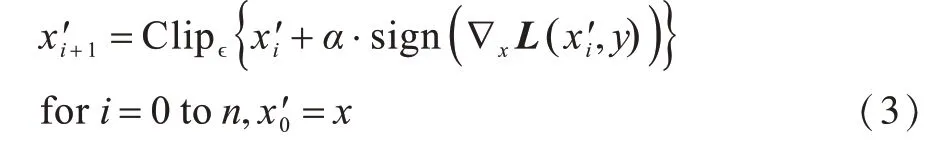
其中,Clip{·}约束坐标的每个输入特征,如像素,将其限制在输入x的扰动邻域以及可行的输入空间中,n为迭代总数量,α为步长。BIM相比FGSM 能构造出更加精准的扰动,攻击效果更好,并在诸多对抗样本攻防比赛中得到了广泛应用,但是其不足之处是提高了计算量。
(2)动量迭代的FGSM 方法。2018 年,DONG 等人[45]提出一种优化的基于动量迭代[46]的FGSM(Momentum Iterative FGSM,MI-FGSM)方法。使用动量能够稳定扰动的更新方向,也有助于逃离局部极大值,从而提高样本的可迁移性并提升攻击的成功率。将动量融入到基本迭代的方法中从而产生扰动,首先输入到分类器f以得到梯度,通过式(4)累积梯度方向上的速度矢量从而更新gt+1,然后应用式(5)中的符号梯度来更新,最后产生扰动。

上述过程能够证明BIM 生成的对抗样本比FGSM 生成的对抗样本更不可迁移,更强的样本通常更不可迁移,与FGSM 和BIM 攻击相比,MIFGSM 提高了对抗样本的可迁移性。

其中,T(·)表示图像变换。DI-FGSM 方法可以和其他攻击方法相结合,例如PGD 和C&W。实验结果表明,加入多样性的D-C&W 的攻击成功率明显高于原始的C&W 攻击。使用DI-FGSM 方法能够同时实现白盒攻击和黑盒攻击的高成功率,并在此基础上提高对抗样本的可迁移性。DI-FGSM 方法的更新过程与基本迭代方法相似。
图3 所示为FGSM 方法及其变体的转换关系,其中,N表示可迁移性概率,μ表示衰减因子,p表示总的迭代数量。

图3 FGSM 方法及其变体之间的转换关系Fig.3 Transformation relationship between FGSM method and its variants
2)C&W攻击。CARLINI 和WAGNER[22]提出3 种对抗攻击方法(L0攻击、L2攻击、L∞攻击),用于寻找能够最小化各种相似性度量的扰动。通过限制L0、L2、L∞范数,使得扰动近似于无法被察觉。实验结果表明,这3 种攻击以100%的成功率绕过了防御蒸馏,同时在L0、L2和L∞范数下保持对抗样本与原始输入相似,具有很强的可迁移性。在MNIST、CIFAR10和ImageNet 上进行评估时,C&W 方法优于同一时期较先进的攻击方法,如BIM 攻击,即使在现阶段,C&W 攻击依旧被广泛应用。
3)替代黑盒攻击。PAPERNOT等人[23]提出一种早期的黑盒攻击方法,即替代黑盒攻击(Substitute Blackbox Attack,SBA)。SBA 攻击训练一个模仿黑盒模型的替代模型,在该替代模型上使用白盒攻击。具体而言,攻击者首先从目标模型收集一个合成数据集,训练一个替代模型来模拟目标模型的预测。在训练替代模型后,可以使用任何白盒攻击生成对抗样本,原因是替代模型的细节已知。SBA 可用于攻击其他机器学习模型,如逻辑回归和支持向量机等模型。通过在MNIST 数据集上定位来自亚马逊、谷歌和MetaMind 的真实世界图像识别系统来评估SBA,结果表明,SBA 能够以高精度(>80%)欺骗所有目标,且其可以规避依赖梯度掩蔽的防御方法。
4)DeepFool 攻击。MOOSAVI 等人[24]提出一种不对原始样本扰动范围进行限制的新方法DeepFool,其为一种早期的对抗样本生成方法,可以生成比快速梯度攻击更小的扰动。DeepFool 首先初始化原始图像并假定分类器的决策边界限制图像分类的结果,然后通过每一次迭代,沿着决策边界方向进行扰动,逐步地将分类结果向决策边界另一侧移动,使得分类器分类错误。和FGSM 相比,DeepFool计算速度更快,可以生成更精确的扰动。
5)单像素攻击。OPA[25]是一种“半黑盒”攻击方法,其使用差分进化算法策略来寻找对抗性扰动。OPA 的目的是通过只修改给定图像x的一个特征来欺骗目标模型。通过对原有数据修改3 个或5 个像素来产生对抗样本,在多种模型下都可达到误分类的效果,好的情况下修改1 个像素即可产生误分类结果。
6)AdvGAN 攻击。XIAO 等人[26]提出一种基于生成对抗网络(GAN)框架的对抗生成方法AdvGAN,AdvGAN 主要由3 个部分组成,分别为生成器G、判别器D和目标神经网络C。该方法将原始样本x通过GAN 生成器G映射成对抗扰动G(x),然后将扰动输入原始样本x中,一旦经过训练,网络可以迅速产生新的对抗样本x+G(x),判别器D判别输入的样本是否为对抗样本,同时用生成的对抗样本欺骗目标神经网络C。AdvGAN 在对抗性训练中的表现优于快速梯度攻击和C&W,其产生的对抗样本在视觉上与真实样本难以区分。但是,AdvGAN 方法存在一个潜在问题,尽管其被证明能够绕过阻碍快速梯度攻击和C&W 方法的防御方法,但与其他基准对抗性攻击和防御方法相比,AdvGAN 在对抗性训练设置中较为单一,可能不会被广泛应用。
7)通用对抗扰动。通用对抗扰动(Universal Adversarial Perturbation,UAP)[27]是一种适用于不同网络模型的通用扰动计算方法,其工作原理是累积单个输入的扰动,以这种方式产生的扰动v可以添加到每个数据样本中,以便将它们推向目标的决策边界附近,重复此过程,直至样本被错误分类。实验结果表明,各种模型均存在通用扰动,通用扰动在这些模型之间表现出较高的可转换性。UAP 攻击的一个潜在缺陷是其不能保证每一个更新的通用扰动v对更新前出现的数据点仍然具有对抗性。
采取SPSS16.0软件对整理后的数据做进一步的描述统计分析、独立样本T检验、相关分析以及一元回归分析。
8)后向传递可微近似方法。ATHALYE 等人[28]针对现有多数防御方法依赖于模糊模型梯度的问题,提出利用防御模型的可微近似来获得有意义的对抗梯度估计从而修改对抗攻击的方法,该方法称为BPDA 方法。BPDA 方法结合期望大于转化攻击(Expectation over Transformation,EoT)方法[40],可以攻破混淆梯度防御。BPDA 方法给定输入样本数据x,假设神经网络可写为函数f1,2,…,j(x),在计算对抗样本梯度时,攻击者可以用另一个函数g(x)来进行计算,在前向传播验证对抗样本是否成功时仍然使用f1,2,…,j(x)进行判断。BPDA 方法成功攻破了7种基于混淆梯度的防御方法。
本文总结以上8 种比较经典的对抗攻击方法,包括攻击类型、目标、学习方式、攻击强度及算法优势和劣势。学习方式可分为单次迭代和多次迭代,单次迭代方法可以快速生成对抗样本,并用于对抗训练从而提高模型的鲁棒性;多次迭代方法则需要更多的计算时间来生成对抗样本,但其攻击效果强且难以防范。以上经典对抗攻击方法的对比分析结果如表1所示,其中,单步表示单次迭代,迭代表示多次迭代,W 表示白盒攻击,B 表示黑盒攻击,T 表示有目标攻击,NT 表示无目标攻击,*的数量代表攻击强度。

表1 攻击方法性能对比结果Table 1 Performance comparison results of attack methods
4 对抗防御
对抗样本的存在促使学者开始思考如何成功防御对抗攻击,从而避免模型识别错误。对抗防御主要分为对抗攻击检测和提高模型鲁棒性2 种方式,检测方法独立于防御方法,可以单独用来检测样本的对抗性,也可以与防御方法结合使用。
4.1 对抗攻击的检测
对抗样本产生原因的复杂性使得对于对抗样本的通用化检测变得十分困难。对抗攻击检测通过检测样本的对抗性来判断其是否为对抗样本。对抗攻击检测主要包括如下方法:
1)H&G 检测方法。HENDRYCKS 等人[49]提出3 种对抗性检测方法,统称为H&G 检测方法。从广义上而言,H&G 检测方法利用了正常样本和扰动问题之间的经验差异来区分正常样本和对抗样本。3 种对抗性检测方法具体如下:
(1)通过对对抗样本的主成分分析白化输入系数的方差从而检测样本的对抗性。当攻击者不知道防御措施是否到位时,该方法可用于检测FGSM 和BIM 攻击。
(2)正常输入和对抗输入之间的Softmax分布不同,H&G 检测方法利用该分布差异执行对抗检测,测量均匀分布和Softmax 分布之间的Kullback-Leibler 散度,然后对其进行基于阈值的检测。研究发现,正常样本的Softmax 分布通常比对抗样本的均匀分布离散,原因是模型倾向于以高置信度预测输入。
(3)在以逻辑为输入的分类器模型中加入一个辅助译码器重构图像从而检测对抗样本,解码器和分类器只在正常样本上联合训练,检测通过创建一个检测器网络来完成,该网络以重建逻辑和置信度得分为输入,输出一个输入具有对抗性的概率,其中,探测器网络在正常样本和对抗样本上都受过训练。该方法能够检测FGSM 和BIM 产生的对抗样本。
2)对抗性检测网络。METZEN 等人[50]提出对抗性检测网络(Adversary Detector Network,ADN),其为一种用二元检测器网络扩充预训练神经网络的检测方法,检测器网络被训练以区分正常样本和对抗样本。ADN 方法能有效检测FGSM、DeepFool 和BIM 攻击,但CARLINI 等人[51]发现该方法对C&W等强攻击具有较高的假阳性,并可以通过SBA 攻击来规避。GONG 等人[52]对ADN 方法进行改进,改进方法中的二进制分类器是一个与主分类器完全分离的网络,其不是针对检测器生成对抗样本,而是为预训练分类器生成对抗样本,并将这些对抗样本添加到原始训练数据中以训练二进制分类器。但CARLINI 等人[51]指出,该改进方法在CIFAR10 模型上测试时具有较高的假阳性,并且容易受到C&W攻击。
3)核密度法和贝叶斯不确定性估计法。FEINMAN等人[53]假设对抗样本不在非对抗性数据流形中,在此情况下提出核密度法和贝叶斯不确定性估计(Bayesian Uncertainty Estimates,BUE)2 种对抗性检测方法。使用核密度估计(Kernel Density Estimates,KDE)的目的是确定一个数据点是否远离类流形,而BUE 可以用来检测靠近KDE 无效的低置信区域的数据点。BUE 是较难欺骗的检测方法,作为现有网络的附加组件,其实现也相对简单。
4)特征压缩。XU 等人[54]认为输入特征的维度通常过大,导致出现一个大的攻击面。根据该原理,他们提出基于特征压缩的检测方法(FS),用以比较压缩和非压缩输入之间的预测结果。特征压缩的目的是从输入中去除不必要的特征,以区分正常样本与对抗样本。如果模型对压缩和非压缩输入的预测结果之间的L1范数差大于某个阈值T,则该输入被标记为对抗性输入。FS 方法独立于防御模型,因此,其可以与其他防御技术结合使用。特征压缩被证明能够在攻击者不了解所使用的防御策略的情况下检测由FGSM、BIM、DeepFool、JSMA[55]和C&W攻击生成的对抗样本。
5)逆交叉熵检测。2017 年,PANG 等人[56]提出利用新的目标函数进行反向检测的逆交叉熵(Reverse Cross-Entropy,RCE)方法,该方法训练一个神经网络以区分对抗样本和正常样本。在FGSM、BIM/ILLCM、C&W、MNIST 和CIFAR10 数据集上进行评估,结果表明RCE 具有有效性。与使用标准交叉熵作为目标函数的方法相比,RCE 不仅允许用户进行对抗性检测,而且在总体上提高了模型的鲁棒性。
本节总结现阶段主要的对抗攻击检测方法的性能,结果如表2 所示。

表2 对抗攻击检测方法性能对比结果Table 2 Performance comparison results of adversarial attacks detection methods
4.2 对抗攻击的防御
为了使模型对对抗性攻击更加具有鲁棒性,研究人员提出不同的防御方法,这些方法建立在对抗性和正常输入下同样具有良好表现的模型上,使模型对输入的不相关变化不太敏感,从而有效地正则化模型以减少攻击面,并限制对非流形扰动的响应。目前,针对对抗攻击的防御方式主要分为以下4 类:
1)数据扩充,该方法通过在训练集中加入对抗样本进行再训练,从而提高模型的鲁棒性。
2)预处理方法,该方法通过对原有数据进行处理从而降低对抗样本的有效性。
3)正则化方法,该方法使用防御蒸馏方法降低网络梯度的大小,提高发现小幅度扰动对抗样本的能力。
4)数据随机化处理,该方法通过对输入进行随机调整来消除扰动。
4.2.1 数据扩充
具有代表性的数据扩充方法如下:
1)对抗训练。为提高神经网络模型在对抗攻击环境下的鲁棒性,很多学者对对抗样本进行代入训练[12]。在每次迭代训练中,通过在训练集中注入对抗样本来对模型进行再训练。由于单步对抗训练的鲁棒性主要由梯度掩蔽引起,因此该模型可以被其他类型的攻击所规避。此外,单步对抗训练可能会出现标签泄漏问题,容易导致模型过度拟合。
2)映射梯度下降对抗训练。2018 年,MADRY 等人[57]改进了对抗训练,提出一种映射梯度下降对抗训练(Projected Gradient Descent,PGD)。标准对抗训练方法是在正常样本和对抗样本上训练模型,而在PDG框架中,模型只在对抗样本上训练。PGD 方法在白盒和黑盒2 种设置下对各种类型的攻击都保持一致的鲁棒性,但其模型可能无法达到最优的性能。由于PGD的计算代价随迭代次数的增加而提高,因此该方法的计算代价通常高于标准对抗训练。
3)综合性对抗训练。2018 年,针对传统对抗训练容易出现过拟合的问题,TRAMER 等人[58]提出综合性对抗训练,其为对抗性训练的另一种变体。在综合性对抗训练中,模型根据生成的对抗样本进行再训练,以攻击其他各种预先训练的模型。这种目标模型和对抗训练实例的分离能够有效克服传统对抗训练的过拟合问题。
4)逻辑配对防御机制。KANNAN 等人[59]提出逻辑配对防御(ALP)机制,其鼓励输入对(即对抗性和非对抗性输入对)的逻辑相似,并设计对抗性逻辑配对和正常逻辑配对(CLP)2 种不同的逻辑配对策略。ALP 在原始输入及其对抗输入之间强制执行逻辑不变性,而CLP 在任何一对输入之间强制执行逻辑不变性。KANNAN 等人发现PGD 攻击的对抗性训练与ALP 相结合,在ImageNet 模型上对白盒攻击与黑盒攻击都具有较优的鲁棒性。
4.2.2 预处理方法
通过对数据进行预处理能够降低对抗样本的有效性,现有的预处理方法主要包括:
1)通过学习非对抗性数据集的分布,将对抗性输入投射到学习的非对抗性流形中。
2)通过对对抗样本的过滤或去噪将其转化为纯净样本。
3)对输入进行变换处理,使攻击者难以计算模型的梯度,从而达到防御对抗攻击的目的。
4)对输入数据进行量化和离散化处理,有效消除对抗性扰动的影响。
具有代表性的预处理方法具体如下:
1)去噪特征映射方法。XIE 等人[60]研究发现,与原始输入相比,对抗性扰动导致模型生成的特征图所发生的变化较大,基于此,他们提出一种去噪特征映射(FDB)方法。实验结果表明,去噪块不会大幅降低非对抗性输入的性能,当与PGD 对抗训练相结合时,无论是在黑盒还是白盒模式下,FDB 防御都能达到当时较优的对抗鲁棒性。
2)综合分析方法。一些基于生成对抗网络的防御机制相继被提出,如基于生成模型的GAN 防御方法,该方法学习非对抗性数据集的分布,以将对抗性输入投射到学习的非对抗性流形中。SCHOTT 等人[61]提出了综合分析(ABS)防御方法,该方法并非学习整个数据集的输入分布,而是学习每个类的输入分布。在MNIST 数据集上,ABS 在对抗L0和L2对抗样本时表现出比PGD 对抗性训练更优、更健壮的效果,但针对L∞对抗样本时ABS 的鲁棒性较低。
3)ME-Net 方法。YANG等人[62]提出基于预处理的防御方法ME-Net,其对输入进行预处理,以破坏对抗性噪声的结构。ME-Net 方法的工作原理是根据一定的概率r随机丢弃输入图像中的像素点,假设该概率r可以破坏对抗干扰,使用矩阵估计算法重建图像。ME-Net 方法是从噪声观测中恢复矩阵数据的方法,在CIFAR-10、MNIST、SVHN 和小型ImageNet 数据集上的黑盒和白盒模式中,ME-Net 测试各种L∞攻击时都表现出了很强的健壮性。
4)总方差最小化和图像拼接方法。在分类之前,可以对输入图像应用各种图像变换方法,在这些图像变换方法中,GUO 等人[63]研究发现总方差最小化和图像拼接最有效,特别是当模型在转换后的图像上训练时,总方差最小化和图像拼接都引入了随机性,并且都是不可微的操作,使得攻击者很难计算模型的梯度。该防御是模型不可知的,意味着模型无需再训练或微调,且这种防御方法可以与其他防御方法结合使用。
5)温度计编码防御方法。BUCKMAN 等人[64]提出神经网络的线性使其易受攻击的假设,并根据该假设提出温度计编码防御(TE)方法。TE 防御对输入数据进行量化和离散化处理,有效消除了通常由对抗性攻击引起的对抗扰动影响。TE 防御和对抗训练相结合后具有很高的对抗稳健性,可以超过PGD 对抗训练,但是,TE 防御依赖梯度掩蔽,可以使用BPDA 攻击绕过。
4.2.3 正则化方法
正则化方法包括深度压缩网络[65]和防御蒸馏[66]等。防御蒸馏是早期较为经典的一种方法,“蒸馏”一词由HINTON 等人[67]引入,是一种将深层神经网络集合中的知识压缩为单一神经网络的方法。防御蒸馏由原始网络和蒸馏网络2 个网络组成,原始网络也叫教师网络,一般为参数多且结构复杂的网络,蒸馏网络也叫学生网络,一般为参数少且结构简单的网络。蒸馏方法可以将教师网络的知识有效地迁移到学生网络,从而起到压缩网络的作用。防御蒸馏对由早期攻击方法生成的对抗样本具有健壮性,但是,这种防御易受到C&W 与SBA 变体的攻击。
4.2.4 数据随机化处理
数据随机化处理包括随机调整大小、填充、随机激活剪枝[68]等。XIE 等人[69]提出基于随机调整大小和填充(RRP)的防御机制,其通过输入变换消除扰动,并在推理过程中引入随机性,使得相对于输入的损失梯度更难计算。该机制不需要对防御模型进行微调就能保证精确性,并且可以与如对抗性训练等其他防御方法相结合,对FGSM、BIM、DeepFool 和C&W 等白盒攻击都表现出良好的性能。
现阶段主要的4类防御方法总结对比如表3所示。在保证计算成本的情况下,目前较常用的防御方法是数据扩充方法。随着攻击手段的提高,未来可能会以多种方法相结合的方式来提高模型的鲁棒性,并且使得模型的鲁棒性与准确率达到平衡。

表3 各种防御方法总结对比结果Table 3 Summary and comparison results of various defense methods
5 对抗样本应用实例
随着对抗样本研究的多样化发展,学者们开始从不同角度探索对抗样本的特性,发现除对抗样本对神经网络模型构成威胁之外,还可以利用对抗样本的特性提高模型性能,具体如下:
1)利用对抗样本提高图像识别准确率。XIE 等人[15]研究发现已有方法可以共同训练原始图像和对抗样本,但此类方法往往会导致最终图像识别准确率下降,即使从不同的分布中提取图像,也会导致同样的结果。由此他们假设原始图像与对抗样本之间分布不匹配是导致此类方法性能下降的关键因素,基于该假设,XIE 等人提出一种新的训练方法——AdvProp 方法,其通过一种简单且高效的两批次标准方法来解决分布不匹配的问题。使用2 个批处理规范统计信息,一个用于原始样本,另一个用于对抗样本,2 个批处理规范在归一化层正确分散了2 个分布,以进行准确的统计估计。实验结果表明,AdvProp大幅提高了卷积网络的模型识别准确率。
2)利用对抗性特征解决超分辨率问题。感知损失函数在解决图像超分辨率问题时虽然取得了较好效果,但也会在超分辨输出中产生不期望的图案伪像。TEJ 等人[70]针对图像超分辨率不确定的问题,提出利用内容损失函数增强现有感知损失函数的方法,该函数使用鉴别器网络的潜在特征来过滤多个对抗相似性级别上的不需要的伪像。实验结果表明,上述损失函数具有互补的优势,相结合后可以有效提高超分辨率重建的保真度。
3)利用对抗扰动检测木马。ZHANG 等人[71]针对深度神经网络木马中毒的问题,提出一种验证预训练模型是否被特洛伊木马攻击的方法。该方法利用从网络梯度中学到的对抗性扰动的形式捕获神经网络指纹,在系统后门插入神经网络会更改其决策边界,这些系统后门可以在其对抗性干扰中有效地进行编码,从其全局(L∞和L2有界)扰动以及每个扰动内的高能量局部区域训练2 个流网络来检测木马。前者对网络的决策边界进行编码,后者对未知的触发形状进行编码,并设计一种不会改变触发类型、触发大小、训练数据和网络架构的异常检测方法来识别木马网络中的目标类。实验结果表明,该方法能够取得92%以上的检测精度。
6 未来研究展望
深度学习技术的迅速发展,使得其在图像分类、目标检测等领域取得重大进展的同时也暴露了数据、模型等安全隐患。针对在深度学习系统中出现的安全问题,研究人员开展了一系列攻击防御方法研究,但是,对于深度学习系统的安全性能而言,未来还有很多问题等待解决。本文总结以下3 个未来的研究方向:
1)应用对抗样本技术作为数据增强的手段。对抗样本可用于提升模型的泛化性,起到数据增强的作用,目前通常在图像分类中提高分类准确率,也可以在恶意软件检测中提升对恶意软件的检测率。相较于普通的数据增强,对抗样本的优势是可以根据模型自身去调整正则化的强度,从而更好地优化模型。
2)改进对抗训练。对抗训练是目前较优的提高模型鲁棒性的方法,但其存在速度慢、在小数据集上训练会过拟合等问题。后续将在兼顾计算效率与效果的情况下,结合不同的损失函数或者改进应用的网络结构。
3)研究除范数约束和对抗训练之外的攻击防御方法。现有的攻击防御大多是基于范数约束和对抗训练,而这些方法不是唯一有效的攻击防御手段,例如,通过风格迁移技术可以生成对抗样本、利用3D打印技术能够实现攻击等。因此,在物理场景中应用并开展对抗样本防御的研究,从不同角度探索其他的攻击防御方式也具有实际意义。
7 结束语
针对深度学习技术的安全问题,本文介绍对抗样本和对抗攻击的概念,对比分析目前比较经典的对抗攻击方法,在此基础上,总结现阶段相应的防御方法和对抗攻击检测方法的性能。深度学习模型的安全领域未来仍有许多问题需要解决,对抗样本防御技术将与统计学习等方法相结合,为同时提升模型的泛化性和鲁棒性提供新思路,加快推进深度学习模型的安全建设,保护人们的信息隐私安全。
猜你喜欢
数学物理学报(2022年4期)2022-08-22
数学物理学报(2021年6期)2021-12-21
四川工商学院学术新视野(2021年1期)2021-07-22
应用数学(2020年2期)2020-06-24
数学物理学报(2019年4期)2019-10-10
数学年刊A辑(中文版)(2018年2期)2019-01-08
东方教育(2018年19期)2018-08-23
中国体育教练员(2017年2期)2017-07-31
贵州师范学院学报(2016年3期)2016-12-01
电源技术(2015年11期)2015-08-22
