
融合外部语义知识的中文文本蕴含识别
2021-01-15 07:17李世宝赵庆帅殷乐乐刘建航黄庭培
计算机工程 2021年1期
李世宝,李 贺,赵庆帅,殷乐乐,刘建航,黄庭培
(中国石油大学(华东)海洋与空间信息学院,山东青岛 266580)
0 概述
文本蕴含识别也称为自然语言推理,是一项基础而又重要的自然语言处理任务。该任务给定前提文本(P)与假设文本(H),然后从语义层面识别出P 和H 之间的单向推理关系,包括蕴含、矛盾、中立3 种关系[1],并且在文本蕴含识别任务上所取得的进展可进一步提高文本摘要、语义搜索、阅读理解和问答等任务的性能[2]。
早期研究多数采用统计及机器学习方法进行文本蕴含识别[3]。近年来,端到端训练的神经网络模型在阅读理解、情感分析和机器翻译等自然语言处理任务中表现出色,由此研究人员提出了一些组合多种神经网络和注意力机制的文本蕴含识别模型,并且经过大量数据训练,取得了相当高的训练精度。这些文本蕴含识别模型大致可以分为两类。一类侧重编码器设计,能够较好地对句子特征进行编码,并且整体网络结构简单,是早期的主流方向。文献[4]使用长短期记忆(Long Short-Term Memory,LSTM)网络分别学习前提和假设的句子表示并对其进行串联及分类。文献[5]进一步使用双向LSTM(Bi-directional LSTM,BiLSTM)网络对句子进行编码,并运用句子内自注意力机制更好地增强句子编码能力。文献[6]设计HBMP 模型进行句子编码,相比使用单一的BiLSTM 层效果更佳。另一类注重句间交互,引入句间注意力机制提取句子之间的语义信息,能够更好地识别句子之间的语义关系。文献[7]提出一个逐词注意力模型,对文本中隐含的前提和假设之间的关系进行编码。文献[8]对文献[7]做了进一步扩展,解决了学习注意力权重前提下单个向量表示的局限性问题。文献[9]提出双向多视角匹配机制,分析并对比了多种注意力机制的匹配策略。文献[10]提出一种增强序列推理模型(Enhanced Sequential Inference Model,ESIM),利用两层不同的BiLSTM 网络和注意力机制对文本进行编码。
但是由于上述模型仅从训练数据中学习推理知识,受限于训练数据集规模,导致模型泛化能力较弱[11],因此文献[12]利用WordNet 作为外部知识,增强了模型在不同测试集上的泛化能力,为结合外部知识的相关研究提供了参考。文献[13]在模型中使用多个英文知识库,并引入知识图概念,提高了模型识别性能。然而,基于神经网络的文本蕴含识别在中文领域的研究较少[14],且知网(HowNet)等中文外部语义知识库与WordNet知识库有较大区别,使得无法直接迁移并应用基于英文数据集的文本蕴含识别模型。因此,本文提出中文知识增强推理模型(Chinese Knowledge Enhanced Inference Model,CKEIM),通过分析中文语义知识库的特点,精确提取词级的语义知识特征以构建注意力权重矩阵,同时将其融入神经网络训练过程。
1 知识库处理
1.1 知识库结构分析
HowNet 知识库[15]的层次结构为词语-义项-义原,其包含2 000 多个基础义原,将词语从语义上进行拆分,同一个词语的不同含义分为多个义项,每个义项又由多个义原组合而来。如图1 所示,词语“苹果”有多种含义,分别代表“电脑”“手机”“水果”以及“树木”。每一种含义表示一个义项,用多个义原加以注解。在HowNet 中,使用“样式值”“携带”“特定品牌”和“电脑”等义原描述“苹果”表示电脑品牌时的义项,并以树状结构进行组织。本文忽略了义原之间的结构关系,并且对于每个词语,将其所有的义原归类为无序集。

图1 HowNet 结构示意图Fig.1 Schematic diagram of HowNet structure
同义词词林[16]将中文同义词以及同类词进行划分和归类,分为5 层层次结构,其中1 层~4 层仅包含分类编码信息,没有具体词汇。本文使用改进版同义词词林[17]将原子词群中较抽象的概念提取到1 层~4 层的分类节点中,使1 层~4 层的分类节点包含代表整个类别的具体概念,如提取“生物”“人”“植物”“动物”等抽象概念并将其放置于大、中、小3 类高层节点中。
为方便表述,本文使用的符号定义如下:HowNet中所有的义原、义项和词语集合分别表示为ε、S和W;语料库包含K=|ε|个义原、M=|S|个义项以及N=|W|个词语;Sw表示词语w∈W所包含的义项集合表示词语w所包含义原的无序集合;εs表示义项s∈Sw所包含义原的无序集合。
1.2 知识库特征提取
通过HowNet 知识库结构可知,在使用HowNet知识库计算两个词语的相似度时,如“苹果”和“梨”的相似度,由于“梨”只有“水果”1 种义项,而“苹果”有“电脑”“水果”“手机”“树木”4 种义项,这样就会出现4 个差距相当大的相似度,如果取相似度的最大值或者平均值,则会造成误差,而在相互为多义词的词语之间计算相似度会产生更大的误差。本文设计一个义项选择器结构,如图2 所示,在模型训练时根据词语p5的上下文信息p1、p6等,计算出其与各个义原匹配的概率,进而选出当前词语p5所代表的真正义项,然后进行词语间的相似度计算。
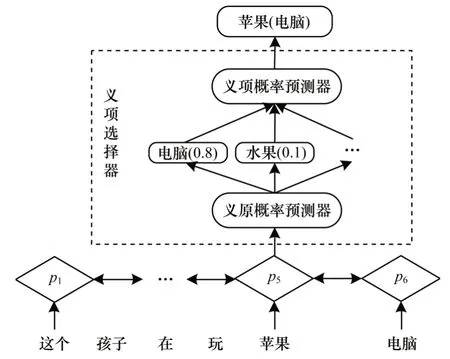
图2 义项选择器结构Fig.2 Structure of sense selector
对于义原概率预测器,假设给定上下文w1,w2,…,wt,…,wn,经过BiLSTM 网络编码后,得到词语wt的上下文向量,H0为向量gt的维度。将gt输入到预测器中,可生成词语wt包含的每个义原ek与gt的关联度。由于义原是最小的语义单位,任何两个不同的义原之间不存在语义重叠,因此词语wt包含的义原ek事件为独立,当前词语wt在上下文语境中编码后得到的上下文向量gt与义原ek的关联度可表示为,如式(1)所示:
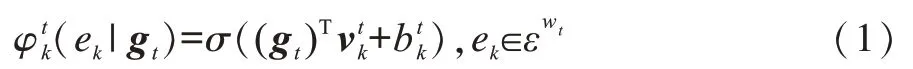
对于义项概率预测器,由于一个义项会包含一个或多个义原,因此根据在义原概率预测器中得到的ek与gt的关联概率可进一步得到词语wt中各义项s与gt匹配的概率P(s|gt),如式(2)所示:

由以上设计的义项选择器可计算出词语wt在当前语境下概率最大的义项smax。在确定义项后,根据混合层次结构的HowNet 词语相似度计算方法[19],精确计算出词语wi和wj在具体语境中的相似度Zij。
由于提取的同义词词林特征包含词语相似度特征以及词语上下位特征,因此将基于信息内容的词林词语相似度计算方法[17]作为相似度特征的提取方法,使提取到的词语wi和wj之间的相似度表示为Cij。同义词词林共5 层结构,设层次结构中两个词语之间的距离为n,可提取的词语间上下位信息具体包括:
1)上位词特征Sij:如果一个词语wj是另一个词语wi的上位词,该特征取值为1-n/4,如[苹果,水果]=0.75,[苹果,植物]=0.5。
2)下位词特征Xij:与上位词特征正好相反,如[水果,苹果]=0.75。
最终将外部语义知识库中提取到的4 个特征组合成特征向量Rij=[Zij,Cij,Sij,Xij],并将其作为外部语义知识融入神经网络中。
2 CKEIM 模型
在CKEIM 模型中,设前提语句p=[p1,p2,…,],假设语句h=[h1,h2,…,hlh],首先对语句进行编码,使用预训练的词向量对词语进行初始化,然后输入BiLSTM 网络进行编码,获得上下文相关的隐层向量,如式(3)、式(4)所示:
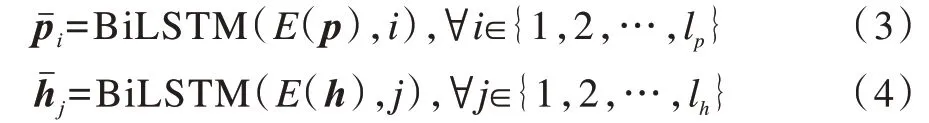
其中,(E(p),i)表示前提语句p的第i个词语初始化后的词向量,(E(h),j)表示假设语句h的第j个词语始化后的词向量。
根据HowNet 知识库中提取的词语相似度特征Zij,结合BiLSTM 网络输出的隐层向量的内积可计算出知识增强的协同注意力权重Mij,如式(5)所示:

其中,λ为超参数。将得到的注意力权重归一化后可得到注意力权重矩阵μij和ηij,进而得到前提语句中的每个词语在假设语句中相关语义信息的向量表示,以及假设语句中每个词语在前提语句中相关语义信息的向量表示,如式(6)、式(7)所示:

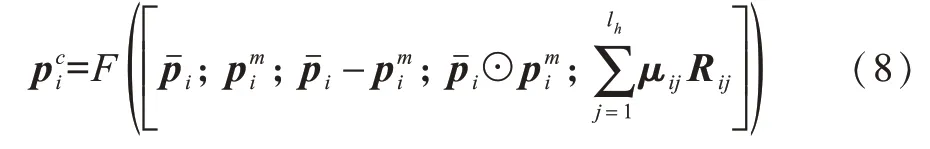
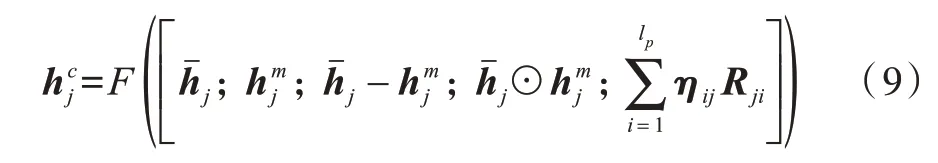
其中,F是前馈神经网络,其以ReLU 为激活函数。
经过拼接并降维后得到的关系向量包含了大量词语间的推理信息,需要进行组合并提取出语句级的推理信息,因此再用一层BiLSTM 网络进一步收集并组合这些信息,提取前提和假设文本之间语句级的推理关系,得到包含语句级推理关系的向量和,如式(10)、式(11)所示:


图3 CKEIM 模型结构Fig.3 Structure of CKEIM model
3 实验结果与分析
3.1 实验数据集
本文在RITE 和CNLI 两个中文文本蕴含数据集上进行相关实验。
1)RITE:该数据集收集了2012 年和2014 年日本国立情报学研究所组织的NTCIR 项目发布的2 600 个文本对,其中,训练集中有2 000 个文本对,测试集中有600 个文本对。数据集涵盖多音字、同音字等多种语言现象,包括人文、历史、政治等多种题材,并且以识别准确率作为评价标准。
2)CNLI:该数据集由SNLI 数据集通过机器翻译和人工筛选得到,包括145 000 个文本对,其中,训练集有125 000 个文本对,验证集和测试集各有10 000 个文本对,分类结果包括蕴含、矛盾和中立3 种关系,每个文本对具有唯一的标签,并且以识别准确率作为评价标准。
3.2 实验参数设置
CKEIM 模型的实验参数设置如下:单词嵌入与BiLSTM 网络隐藏层的维度均为200 维,使用腾讯AI实验室[20]发布的200 维中文词向量初始化词嵌入,词表中不存在的词语会随机初始化;将Adam[21]作为随机梯度优化策略,初始化学习率为0.000 4,批处理(Mirri-batch)大小为32;利用哈尔滨工业大学的LTP语言云[22]作为中文分词工具。
为便于对比,ESIM 等基线模型的实验参数、实验环境、实验设置与CKEIM 模型相同。首先从集合{0.2,0.5,1,1.5,2,5,10,15,20}中依次选取计算注意力权重的超参数λ并在训练集上进行训练。然后根据测试集的实验结果选择效果最优的λ值,再以此λ值为基础,通过调整±(0.1~0.5)的步长改变λ值,直到找到实验效果最优的λ值。最后得到CNLI 数据集的最佳λ值为1,RITE 数据集的最佳λ值为20。
3.3 结果分析
表1 为本文CKEIM 模型与BiLSTM+广义池化层模型、BiLSTM+句内注意力模型[5]、BiLSTM+最大池化层模型[6]、HBMP 模型[6]和ESIM 模型[10]在大规模CNLI 数据集上的识别准确率对比。由于在神经网络中结合外部知识的文本蕴含识别模型都是基于英文知识库,无法在中文数据集上进行比较,因此本文选择其基础模型ESIM 作为主要基线模型,同时与其他经典模型进行对比。表2 为CKEIM 模型与BiLSTM+广义池化层模型、BiLSTM+句内注意力模型、HBMP 模型和ESIM 模型在小规模RITE 数据集上的识别准确率对比。

表1 6 种模型在CNLI 数据集上的识别准确率对比Table 1 Comparison of recognition accuracy of six models on CNLI dataset %

表2 5 种模型在RITE 数据集上的识别准确率对比Table 2 Comparison of recognition accuracy of five models on RITE dataset %
由表1 可以看出,CKEIM 模型在大规模CNLI 数据集上达到81.4%的识别准确率,比ESIM 模型提高了0.9 个百分点,也明显优于其他经典模型。由表2可以看出,CKEIM 模型在小规模RITE 数据集上优势更加明显,超出ESIM 模型3.3 个百分点。可见,CKEIM 模型在两种数据集上都要优于ESIM 基线模型及其他经典模型,且在小规模RITE 数据集上优势更加明显,因此其泛化能力更强,从而说明本文CKEIM 模型通过将中文外部语义知识融入神经网络,提高了模型识别准确率和泛化能力。
为比较不同规模训练集下外部语义知识对识别效果的影响,更进一步验证模型识别准确率和泛化能力,将CNLI 数据集进行拆分并在整个训练集上随机采样得到原训练集4%、15%、50%和100%数据规模的训练集,然后分别在这些训练集上对本文CKEIM 模型与BiLSTM+广义池化层模型、BiLSTM+句内注意力模型、HBMP 模型和ESIM 模型进行训练,得到如表3 所示的实验结果,并据此得到如图4 所示的柱状图,其中:对于4%和15%数据规模的训练集,设置最佳λ值为5;对于50%和100%数据规模的训练集,设置最佳λ值为1。

表3 5 种模型在不同训练集规模下的识别准确率对比Table 3 Comparison of recognition accuracy of five models at different training set scales %
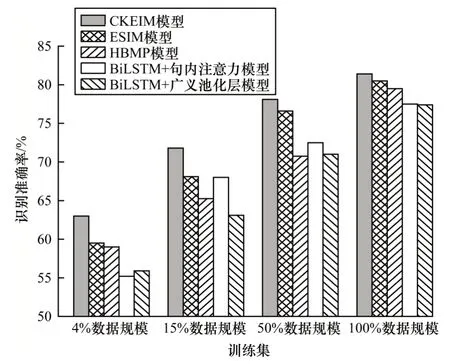
图4 不同训练集规模下的模型识别准确率对比Fig.4 Comparison of model recognition accuracy at different training set scales
由表3 和图4 的数据可以看出,当训练数据非常有限时,即只有4%数据规模的训练集时,ESIM 模型的识别准确率为59.5%,而CKEIM 模型为63.0%,超出其3.5 个百分点。在15%、50%和100%数据规模的训练集下识别准确率始终都高于ESIM 模型,提升比例分别为3.7%、1.5%和0.9%,整体呈递减趋势。该结果进一步说明融合外部语义知识的CKEIM 模型具有更好的识别性能和泛化能力,且训练数据量越小,增强效果越明显。
4 结束语
本文提出一种基于外部语义知识的CKEIM 模型,从HowNet和同义词词林知识库中提取外部知识,建立注意力权重矩阵并组成特征向量融入神经网络训练过程中,增强模型识别性能和泛化能力。实验结果表明,CKEIM 模型在不同规模的训练集下的识别准确率均优于对比模型,并且训练数据量越小,其识别准确率和泛化能力的增强效果越明显。后续工作可将中文知识图谱融入神经网络训练过程中,进一步提高CKEIM 模型的识别准确率及鲁棒性。
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
制造技术与机床(2019年6期)2019-06-25
数学物理学报(2017年5期)2017-11-23
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
知识窗(2015年1期)2015-05-14
新课程学习·中(2013年3期)2013-06-14
Beijing Review(2012年37期)2012-10-16
读写算·高年级(2009年3期)2009-11-16
