
基于姿态估计与GRU 网络的人体康复动作识别
2021-01-15 07:17胡北辰
计算机工程 2021年1期
闫 航,陈 刚,佟 瑶,姬 波,胡北辰
(1.郑州大学 信息工程学院,郑州 450001;2.郑州大学 互联网医疗与健康服务协同创新中心,郑州 450001;3.郑州大学 护理与健康学院,郑州 450001)
0 概述
脑卒中发病人数逐年上升,已成为威胁全球居民生命健康的重大疾病,具有极高的致残率,其中重度残疾者约占40%[1]。大量研究表明,由于大脑的可塑性,因此长期规范化的康复训练能够有效帮助脑卒中患者恢复大部分的运动控制和日常生活能力,也是患者出院后进行中长期康复的主要途径[2]。而居家环境下的康复过程缺乏必要的指导,家属由于外出工作等原因也难以做到实时监督,因此患者普遍存在康复训练依从性较差的问题[3],而将基于视频的动作识别技术用于识别人体的康复锻炼动作,实时监督和指导患者的康复过程,可以提高中长期训练的康复效果。
目前,学者们对基于可穿戴设备的康复动作识别方法进行大量研究。文献[4]采用三轴加速度计获取患者的运动信息,通过支持向量机(Support Vector Machine,SVM)识别肩关节屈伸、手臂伸展等多种康复动作。文献[5]采用加速度传感器采集脑瘫儿童的活动数据,分别结合决策树、SVM 和随机森林识别患者动作。文献[6]通过可穿戴设备获得上肢康复训练的常见动作样本,提出改进的SVM 分类器,实现对6 种康复动作的识别。然而,此类方式会对人体活动造成一定干扰,患者需要同时佩戴多个设备才能实现更好的识别效果。
基于机器视觉的康复动作识别不会对人体活动造成过多干扰,因此具有更好的应用前景,但是视频处理的复杂性导致该领域的研究充满挑战[7]。相比吃饭、喝水、刷牙等简单的日常行为,脑卒中康复动作更加复杂,通常可分解为多个元动作,并且动作持续时间较长,因此识别难度较大。传统人工特征用于动作识别时缺乏足够的判别能力,难以对复杂场景的行为进行有效建模[8]。深度学习能够自主提取关键特征,包括3D CNN[9]、LRCN[10]、Two-Stream[11]等典型方法,但深度学习模型通常参数量庞大,计算复杂度高,制约了其在现实场景中的应用[8]。人体姿态特征对背景或无关对象具有较强的鲁棒性,包含的运动信息也更丰富[12]。文献[13]基于国际生物力学学会规范的康复动作,采用深度相机Kinect 提取人体姿态并通过分析关节角度的变化进行动作识别。文献[14]基于Kinect 获取骨架关节点,然后结合随机森林识别老年人的室内活动动作。以上通过传统分类器或者关节角度比对的识别方式需要人工建立复杂的对照模型,泛化能力较差。文献[15]采用循环神经网络(Recurrent Neural Network,RNN)从骨架数据中提取时空特征,显著提高了对康复动作的识别能力,而RNN 在挖掘时序关系时仍存在一定的局限性。此外,多数识别算法的输入需要依赖已获取的姿态特征,对RGB 视频的通用性较差。
针对上述问题,本文以郑州大学第二附属医院神经康复科设计的家庭脑卒中康复动作为研究基础,提出一种基于姿态估计与门控循环单元(Gated Recurrent Unit,GRU)网络的人体动作识别算法Pose-AMGRU。引入OpenPose 姿态估计方法[16]对RGB 视频中等间隔采样的图像帧提取骨架关节点,并通过预处理进一步提高姿态数据的可靠性。结合注意力机制构建融合三层时序特征的GRU 网络,从输入动作特征序列中提取丰富的时空信息,并通过Softmax 分类器进行人体康复动作识别。
1 人体康复动作识别算法
本文提出的人体康复动作识别算法主要由人体姿态估计、预处理、特征提取和分类网络组成。Pose-AMGRU 识别框架如图1 所示。
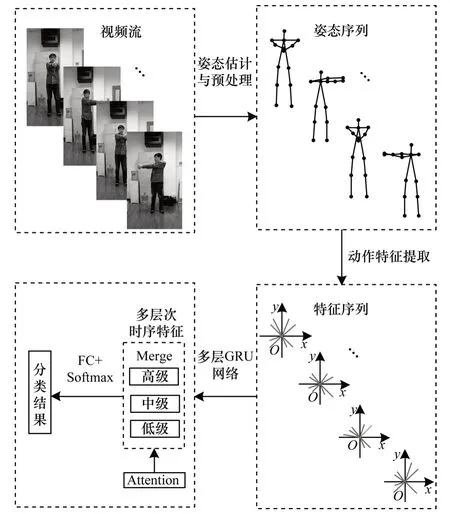
图1 Pose-AMGRU 识别框架Fig.1 Framework of Pose-AMGRU recognition
该框架的输入为RGB 视频流,以一定间隔截取视频帧,通过OpenPose 姿态估计方法从中提取包括手臂、腿部以及颈部等18 个2D 骨架关节点。针对姿态估计过程中缺失的关节点,通过计算相邻帧中相同关节点坐标的均值以填充缺失点,然后通过霍尔特指数平滑法减小原始关节坐标的抖动。在直角坐标系中将骨架关节点转化为26 个动作特征并进行归一化处理,结合注意力机制构建多层GRU 网络挖掘丰富的时空关系并融合初级、中级和高级时序的特征,融合后的特征通过全连接神经网络(FC)与Softmax 分类器进行多种康复动作识别。该算法利用2D 骨架关节点的多层次时序关系进行动作识别,相比于3D CNN 等算法具有更强的速度优势,并且由于每一帧只对提取的26 个关键动作特征进行处理,构建的多层GRU 网络相对于主流方法中的CNN网络大幅减小了参数规模,降低了对海量数据集的依赖,模型更易于优化。
1.1 视频姿态估计
本文采用兼具速度与精度的OpenPose 姿态估计方法从视频中检测骨架关节点。OpenPose 是一种自顶向下、基于深度学习的实时姿态估计方法,能够实现人体面部、躯干、四肢以及手部关节点的提取,在多人场景中也能保持速度优势。
OpenPose 网络采取多阶段预测的方式,结构如图2 所示,引入VGG-19 模型的前10 层作为基础网络,将输入的图像转化为特征F,通过多层卷积神经网络(C)分阶段回归L(p)与S(p),其中:L(p)为亲和度向量场(Part Affinity Fields,PAFs),描述关节点在骨架中的指向;S(p)表示关节点的置信度,描述关节点的位置信息。
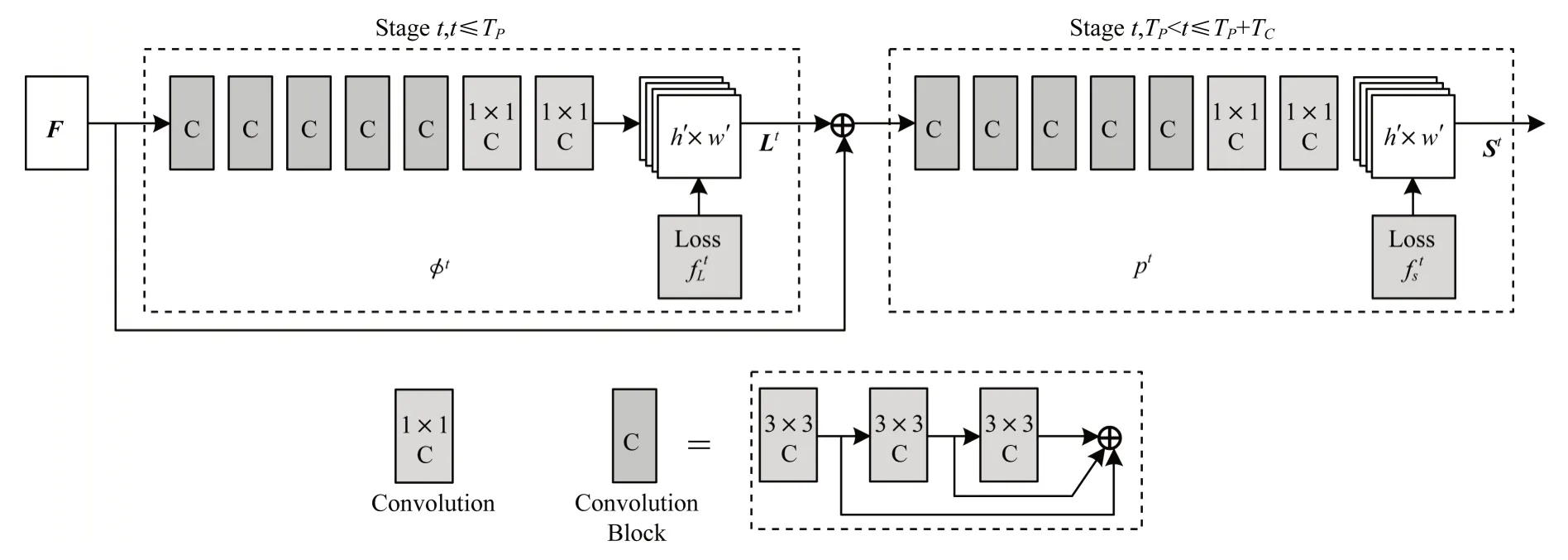
图2 OpenPose 网络结构Fig.2 Structure of OpenPose network
预测过程通过前TP个阶段预测亲和度向量场Lt,后TC个阶段预测置信度St。在每个阶段都将前一阶段的结果与原始特征相融合,用以保留图像较低与较高层次的特征。当1≤t≤TP时,Lt的计算公式为:
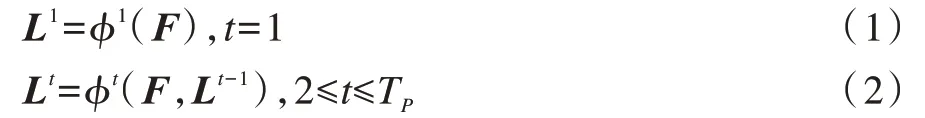
当TP≤t≤TP+Tc时,St的计算公式为:
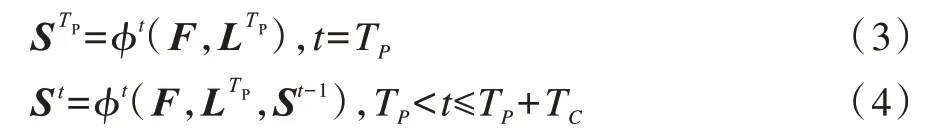
预测出关节点的位置与亲和度向量后,采用匈牙利算法对相邻关节点进行二分最优匹配,最终得到属于同一个人体的姿态信息。姿态估计模型需要大量标注关节点的图像样本进行训练,本文预先加载在超大规模图像数据集COCO 中训练的网络参数,在保证检测精度的同时能够简化训练过程。为加快姿态估计速度并减少相邻视频帧中的冗余信息,每间隔两个视频帧进行一次姿态运算。
1.2 数据预处理
OpenPose 兼顾了速度与精度,但应用于视频中时会出现一定强度的节点抖动,且在短暂遮挡、光照剧烈变化、目标移动过快等复杂场景下存在关节点丢失问题。为了尽可能地补全漏检的节点坐标,假定短时间内关节点的移动位近似匀速,在时域上通过结合相邻视频帧的节点信息计算缺失点坐标。
时域均值填充方法如图3 所示,假设第i帧存在丢失的关节点,j表示人体关节编号,通过求取间隔K帧内的关节点均值来填充缺失点,缺失点的计算方法为:


图3 时域均值填充示意图Fig.3 Schematic diagram of time domain mean filling
通过在未缺失关节点上的实验结果表明,当K=2 时能取得较好的填充效果。然后采用霍尔特指数平滑法对关节点坐标进行平滑操作,去除原始姿态数据中的极值点以减小抖动,同时进一步修正所填充的关节点坐标,计算公式为:

其中:α、β为平滑参数且通常均设为0.5;xi、Si、bi分别为第i帧的关节点坐标检测值、平滑值和趋势增量;Si、bi在初始时分别设置为第1 帧的关节点坐标平滑值、第2 帧与第1 帧的关节点坐标之差。图4 为坐站活动中左手关节点的平滑过程。
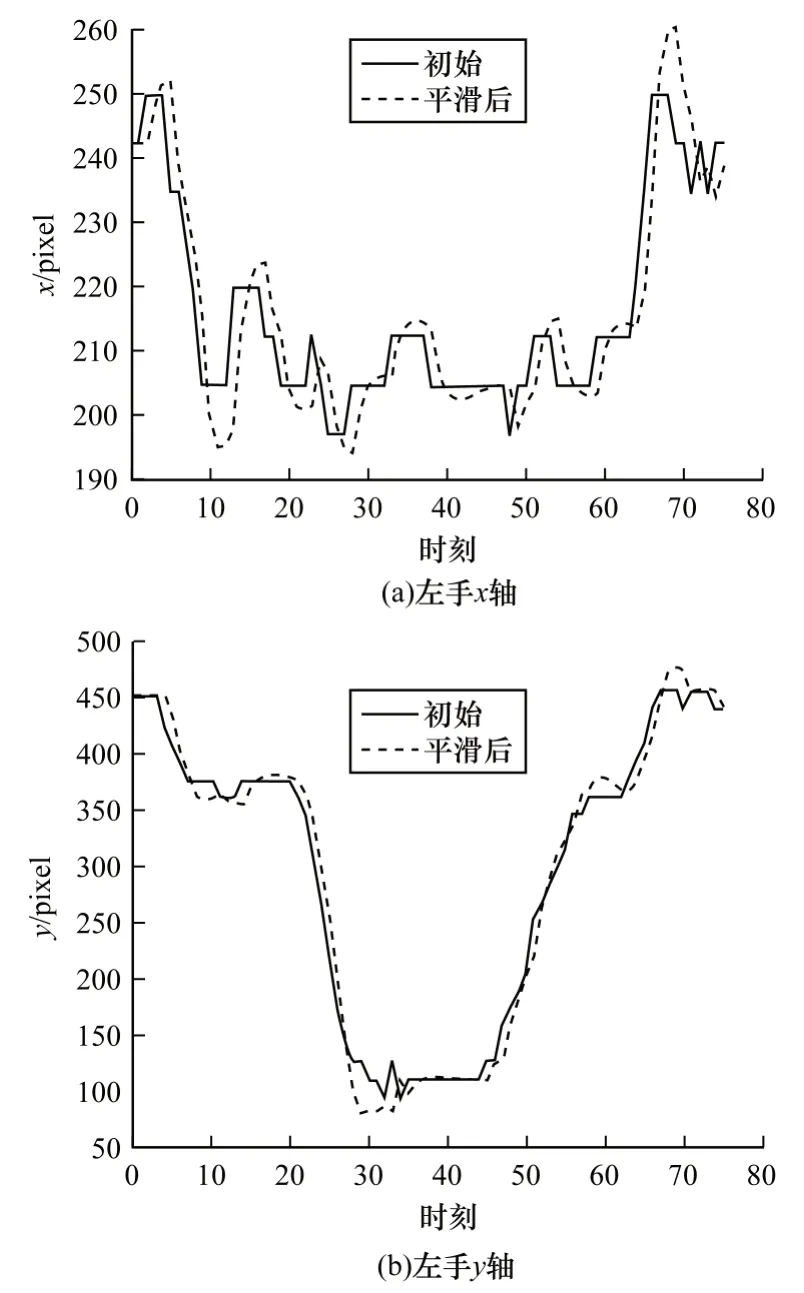
图4 坐站活动中左手关节点的平滑过程Fig.4 Smoothing process of the left hand joint point in sit-down activities
1.3 动作特征提取
单个视频帧能够获取到运动目标的18 个2D 骨架关节点即36 个特征,为进一步减小冗余特征,从中提取能够表达人体运动的显著性特征。首先去除左右眼、左右耳共4 个对于所研究动作无关的关节点,保留的关节点为鼻(x1,y1)、颈(x2,y2)、左肩(x3,y3)、右肩(x4,y4)、左肘(x5,y5)、右肘(x6,y6)、左手(x7,y7)、右手(x8,y8)、左腰(x9,y9)、右腰(x10,y10)、左膝(x11,y11)、右膝(x12,y12)、左足(x13,y13)和右足(x14,y14)。人体骨架关节点为直角坐标系下的绝对坐标对于目标远近、位置和视角变化比较敏感,本文从14 个关节点中基于肢体划分进行矢量运算,提取出反映肢体活动的13 个动作矢量。
动作矢量提取方式如图5 所示,计算方法为同一视频帧中相邻的两个关节点坐标之差,计算公式为:

其中,Va,Vb,…,Vm为提取的13 个动作矢量,每一个动作矢量为直角坐标系下(x,y)两个坐标值,表征了每个肢体活动的角度与幅度信息。

图5 动作矢量提取示意图Fig.5 Schematic diagram of action vector extraction
骨架关节点的取值范围与视频分辨率成正比,为统一不同样本的尺度大小并且减少样本间的差异,将动作矢量V(x,y)进行如下处理:

其中,(vw,vh)为视频源的分辨率为归一化为[0,1]的动作矢量。由于不同视频样本的时长不一致,因此通过补0 的方式统一时间步长的大小并将其设置为T,每个时间步长的特征维度为26。
1.4 分类网络
人体动作能够通过具备时序关系的一系列姿态关节点进行描述,本文结合注意力机制并融合多层时序信息挖掘具有明显辨别性的动作特征。循环神经网络利用可递归的循环单元,通过分析上下文状态挖掘时序信息,但传统的RNN 无法解决长期依赖问题,限制了其预测能力。长短时记忆(Long Short Term Memory,LSTM)网络的出现解决了长时间序列训练过程中的梯度消失问题,并广泛应用于语音识别、机器翻译等领域。文献[17]在LSTM 的基础上提出GRU 网络,其在保证性能的同时相比LSTM 结构更加简单,并减小了神经网络的参数量,其网络结构如图6 所示。

图6 GRU 网络结构Fig.6 Structure of GRU network
在图6 中,σ表示Sigmoid 激活函数,GRU单元网络将原LSTM 中的输入门、遗忘门和输出门整合为更新门zt和重置门rt,并去除了LSTM 的单元状态c,仅保留一个输出状态h。若当前时刻序列的输入为xt,则GRU 单元网络的一次前向计算为:
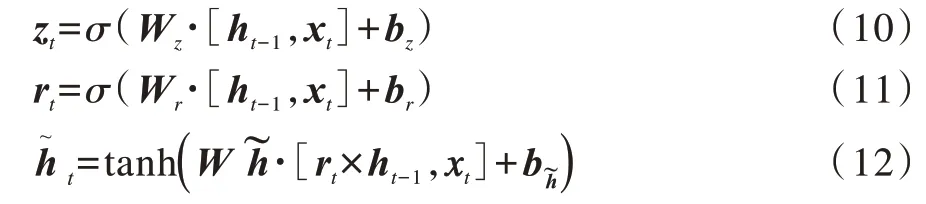

融合多级空间特征的SSD[18]等卷积神经网络在目标检测领域取得了较好的结果。受该思想启发,本文融合不同层次的时序特征进行动作识别,同时结合注意力机制增强特征的显著性,所设计的分类网络如图7 所示。

图7 分类网络结构Fig.7 Structure of classification network
分类网络模型的输入是从每帧图像中提取26 个动作特征,时间步长大小为T。MK 为Masking 层,用于支持变长序列,在GRU 递归计算中忽略特征值全为0 的时间步长。BN 为Batch Normalization 层,引入可学习参数β、γ,对输入样本进行批标准化处理,将其转化为均值为0 且方差为1 的分布,能够改善网络梯度并加快训练时的收敛过程。设计三层堆叠的GRU 单元网络,每层网络神经元的个数为64,底层单元网络所有时刻的输出状态h传递给下一层。视频中每帧图像对于特定动作的分类并非同等重要,为增强关键视频帧的表达能力,引入注意力机制计算每个时间步长输出特征ht的注意力权重αt,通过每一时刻输出特征与注意力权重的加权求和得到每一层的时空特征v。本文通过神经网络得到注意力打分函数,计算公式为:
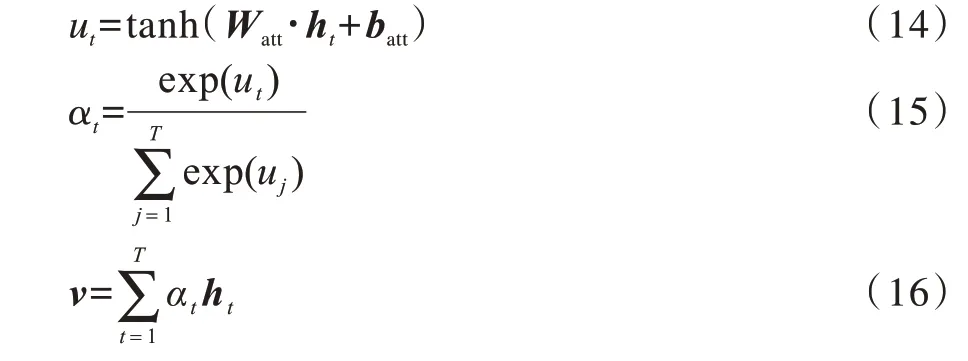
其中,Watt、batt分别为注意力网络的权重和偏置。第一层~第三层GRU 单元网络通过注意力机制提取的向量v1、v2、v3分别表达了低层、中层和高层时序特征,并将三层时序特征拼接为融合的特征F:

然后将融合的时序特征F通过全连接神经网络进一步整合关键特征,输出层采用Softmax 分类器进行多种康复动作的分类。通过Softmax 激活函数将多个神经元的输出转换为0 到1 范围的置信概率,假设为Softmax激活函数输入向量的第i个特征,计算公式为:

其中,K表示输入特征个数,即待分类的类别数,通过将输入转为概率分布。考虑到人体活动过程中除康复动作外,还会出现其他的动作类型。为提高算法鲁棒性,将日常活动所发生的动作与行为归为一类并与K-1 种康复动作同时进行分类。对于多分类问题采用交叉熵损失函数,并引入L2 正则化降低模型过拟合风险:

其中,n表示输入的样本批量大小,标签yi为one-hot编码函数运算时只保留正确预测的置信概率,其他值则为0。之后采用Adam 优化算法来最小化损失函数,Adam 结合了多种优化算法的优势,通过计算梯度的一阶矩阵和二阶矩阵估计动态调整每个参数的学习率,具有计算高效、迭代过程稳定的特点。经过多次迭代来训练神经网络直到参数收敛,Pose-AMGRU 算法的分类网络通过加载训练好的模型对输入的视频进行动作识别。
分类网络应结合实际动作的特点、持续时长和视频帧率选择输入的序列长度即时间步长T,因为过短的时间步长不能覆盖一个完整的动作,过长的时间步长存在的冗余信息不但会降低识别精度,而且会增加模型预测时间,所以合理的时间步长对于识别精度与计算速度至关重要。
2 实验结果与分析
2.1 实验平台
本文实验处理器采用Intel i7-8750,内存为8 GB,显卡为GTX1060,显存为6 GB,通过1080P 摄像头采集视频,基于Tensorflow 深度学习框架进行姿态估计模型及分类网络的搭建,并使用GPU 加速姿态估计模型的识别过程。
2.2 数据集
本文根据参考文献[19]设计的脑卒中患者家庭康复动作并在专业护理医师的指导下自建一组康复动作数据集,同时为客观评价Pose-AMGRU 算法性能,选取了KTH 公开数据集[20]作为对比,数据集示例如图8 所示。

图8 数据集示例Fig.8 Datasets examples
KTH 是动作识别领域的经典数据集,包含由25个志愿者录制的拳击、拍手、挥手、慢跑、跑步和步行6 种动作。该数据集共有599 个视频,可细分为2 391 个动作片段。KTH 中的视频包含整个目标人体,能够检测到完整的姿态关节点。
康复动作数据集由10 位志愿者在6 种不同环境下采集的动作组成,共有2 075 个视频。动作类型分为5 种康复动作及1 种日常活动动作,其中康复动作的具体说明如表1 所示。日常活动动作包括慢走、伸展、静止坐、静止站等多个行为状态。视频帧率为15 frame/s,持续时长为7 s~15 s。

表1 脑卒中康复动作描述Table 1 Description of stroke rehabilitation actions
2.3 训练策略
KTH 数据集参考文献[19]的划分规则选取训练集与测试集,其中训练集的视频样本通过对称变换、随机裁剪等方式进行数据增强,将训练集扩增1 倍。康复动作数据集中按照7∶3 的比例划分训练集和测试集,并保证测试集中每类动作的样本比例保持平衡。分类网络的训练参数通过高斯分布获取的随机值进行初始化,样本分批量(batch-size)输入到分类网络中。初始学习率设置为0.001,batch-size 为32,时间步长为500。
2.4 结果分析
2.4.1 识别结果可视化及序列长度对准确率的影响
图9 为Pose-AMGRU 算法对康复动作识别的可视化结果,所测试的动作类型分别为站位扣手上举、坐位扣手上举、站位扣手左右平举、坐位扣手左右平举、坐站和日常活动。本文算法对每种康复动作都预测出较高的置信概率值,表现出较强的区分能力,在显卡GTX1060 上的运行速度达到14.23 frame/s。
为分析输入的序列长度对识别准确率的影响,设置不同的时间步长输入到分类网络。实验结果如图10 所示,KTH 和康复动作数据集分别在80、70 的时间步长下达到最优识别准确率,且随着时间步长的增加,识别性能出现下降的趋势。

图9 康复动作识别的可视化结果Fig.9 Visualized results of rehabilitation action recognition

图10 不同时间步长下的识别准确率比较Fig.10 Comparison of recognition accuracy under different time steps
2.4.2 网络模型结构与数据预处理对准确率的影响
本文验证融合多级时序特征与引入注意力机制的网络模型有效性,实验结果如表2 所示。可以看出,引入注意力机制的GRU 网络显著提高了识别效果,未融合三层时序特征的GRU 网络识别效果也优于单层GRU 网络,而融合三层时序特征的GRU 网络进一步提高了识别准确率,其在KTH 和康复动作数据集中的识别准确率相比单层GRU 网络分别提高了6.48 和0.97 个百分点。

表2 不同网络模型结构的识别准确率对比Table 2 Comparison of recognition accuracy of different network model structures %
本文对原始骨架关节点进行缺失点填充、数据平滑和归一化等数据预处理操作,数据预处理对识别准确率的影响如表3 所示。相比原始关节点数据,预处理后的关节点数据进一步提高了姿态特征的鲁棒性和识别准确率,而康复动作数据集中的视频分辨率较高,因此原始关节点也取得了较高的识别准确率。

表3 数据预处理对识别准确率的影响Table 3 Influence of data preprocessing on recognition accuracy %
2.4.3 不同动作识别算法的准确率对比
图11 为本文Pose-AMGRU 算法在KTH 数据集上的混淆矩阵。可以看出,Pose-AMGRU 算法对拳击、拍手、慢跑和步行这4 种动作的识别准确率高达100%。
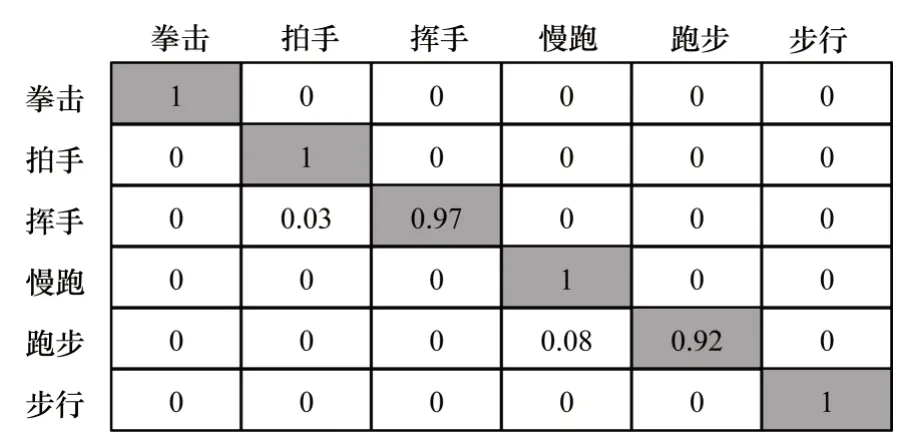
图11 Pose-AMGRU 算法在KTH 数据集上的混淆矩阵Fig.11 Confusion matrix of Pose-AMGRU algorithm on KTH dataset
表4 为本文Pose-AMGRU 算法在KTH 数据集上与其他人体康复动作识别算法的识别准确率对比结果。对比算法具体为:1)基于3D CNN 的人体康复动作识别算法[9],从空间与时间维度同时进行卷积来提取时空特征进行动作识别;2)基于Optical flow-SURF+SVM的人体康复动作识别算法[21],融合光流和加速稳健特征后,通过SVM分类器进行动作识别;3)基于DT+SVM的人体康复动作识别算法[22],采用降维后的稠密轨迹特征与SVM 分类器进行动作识别;4)基于LC-YOLO的人体康复动作识别算法[23],先从视频帧中检测目标人体,再结合CNN 与LSTM 对目标人体进行动作识别;5)基于CNN+SVM-KNN 的人体康复动作识别算法[24],采用混合的SVM 与KNN 分类器对CNN 提取的特征进行动作识别。

表4 KTH 数据集上人体康复动作识别算法的识别准确率对比Table 4 Comparison of recognition accuracy of human rehabilitation motion recognition algorithms on KTH dataset %
在康复动作数据集中,首先从视频中提取骨架关节点进行预处理,在姿态特征的基础上将本文Pose-AMGRU 算法与其他人体康复动作识别算法进行对比,实验结果如表5 所示。运行时间为所有测试样本的预测总时长,不包括姿态估计与预处理的计算耗时。可以看出,基于RNN 系列的人体康复动作识别算法的识别准确率优于基于传统隐马尔科夫模型(Hidden Markov Model,HMM)的人体康复动作识别算法,而Pose-AMGRU 算法取得了最好的识别结果,但其需要耗费更多的运算时间,在一定程度上影响了实时性。

表5 康复动作数据集上人体康复动作识别算法的识别准确率对比Table 5 Comparison of recognition accuracy of human rehabilitation motion recognition algorithms on rehabilitation action datasets
2.4.4 不同动作识别算法的训练参数量对比
将本文Pose-AMGRU 算法与基于主流深度学习模型的人体康复动作识别算法的训练参数量进行对比,实验结果如表6 所示。基于Two-Stream 的人体康复动作识别算法[11]虽然在动作识别领域取得了较好的成果,但是其光流图的计算非常耗时,模型也存在参数量过大的问题。基于C3D 的人体康复动作识别算法[27]由多层3D CNN 构成,参数量庞大。基于LRCN 的人体康复动作识别算法[11]中的卷积网络部分可以采取迁移学习方法,一定程度上解决了小样本下的学习问题。本文Pose-AMGRU 算法只需对每帧所提取的低维度特征进行处理,并通过浅层GRU 网络进行时空特征提取,大幅降低了所需训练的参数量。

表6 4 种人体康复动作识别算法的训练参数量对比Table 6 Comparison of training parameter amount of four human rehabilitation motion recognition algorithms
3 结束语
本文提出一种轻量且高效的人体康复动作识别算法。通过姿态估计方法获取骨架数据并进行预处理,然后从中提取表征肢体活动的动作特征序列,结合注意力机制构建融合多级特征的GRU 网络进行动作识别。实验结果表明,该算法在康复动作数据集中能够有效识别5 种典型的脑卒中康复动作,并且具备良好的实时性。后续将增加更多类型的脑卒中康复动作,同时引入多视角视觉信息以提取更加丰富的特征,进一步增强人体康复动作识别算法对复杂动作的识别能力。
猜你喜欢
科学技术创新(2021年19期)2021-07-16
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
沈阳航空航天大学学报(2020年6期)2021-01-27
学生天地(2020年3期)2020-08-25
汽车观察(2018年9期)2018-10-23
中国自行车(2018年8期)2018-09-26
中国交通信息化(2018年5期)2018-08-21
军营文化天地(2017年6期)2017-06-28
