
加标法则操作下的汉语浮游量化现象
2021-01-08 07:15:04孙悦
哈尔滨学院学报 2020年12期
孙 悦
(安徽师范大学 外国语学院,安徽 芜湖 241003)
一、引言
浮游量化结构是指量化词脱离其毗邻的量化名词组,浮游到其他位置,从而生成新的句法结构,且两句的量化关系不会发生任何变化。
例1
a.All the students have finished the assignment.
b.The students have all finished the assignment.[1]
例2
a.Tous les enfants ont vu cefilm.
All the children have seen this movie.[2]
b.Les enfants ont tous vu ce film.
The children have all seen this movie.[2]
上述例句中,例1a中“all”本来修饰“the students”,尽管在量化词“all”移位至其他位置,但是仍然修饰名词组“the students”。同样的,例2b中“tous”脱离其量化名词组“les enfants”,但是两句的量化关系没有变化。对于上述例句这一句法现象,学者们提出了不同的分析方法:移位分析法(Stranding Analysis)和状语分析法(Adverbial Analysis)。前者认为量化词向右移位,并且名词组“the students”受到格位的驱使提升至主语位置。后者则认为量化词是基础生成的,而不是通过移位转换生成的。
汉语中浮游量化词的数量要远比英语等其他语言的丰富,且可以划分成强量化词和弱量化词,且强量化词具有强特征。[3]另外,与英语中量化词受格驱动移位不同,汉语量词移位的动因多受到话题特征的驱动。[4]
因此,本文将以最简方案下加标法则(Labeling Algorithm)为理论框架,对汉语浮游量化现象的句法机制加以研究,避开滞留分析法和状语分析法的争议和难题,不考虑汉语浮游量化结构在移位过程中可能会遇到的孤岛效应,仅仅研究汉语一般和限定性浮游量化结构的加标运算,更直观地分析浮游量化结构的生成过程和步骤,进而考察量化词的句法地位。
二、加标法则操作下浮游量化结构推导
(一)理论基础
“句法标签(label)”是指句法学里用来标示各种不同语法成分的标识系统,例如N,VP,PP等。[5]Chomsky将合并操作分为外合并(Internal Merge)和内合并(External Merge),提出标签是句法成分组成的一部分,同时也能够对句法对象内部操作的先决条件,只能通过推导一步一步生成。[6]
例3我看了两部电影。
“看”和“两部电影”合并之后投射vP:{vP,{v-看,DP-两部电影}}。内合并一般由通过移位或者提升到目的地所在的成分加标,即,外论元(external argument)“我”从[Spec, vP]移位到[Spec,TP]位置上,这种情况下由目的地的T来加标,因此经过内合并之后结构仍为TP,即TP:{TP,{EA我,TP}}。
为了更好的构建最简方案的探索平台,Chomsky重新定义了投射“标签”这一句法特性,为了解决两个短语成分{XP, YP}合并组成新的结构的加标运算,提出了加标法则:[7](1)从合并集合中选取中心语获得标签;(2)通过最小搜索法则(minimal search algorithm)来探索集合语类中的最显著的语法特征。
加标法则包括两种基本加标运算:{H,XP}和{XP,YP}。在{H,XP}直接选择中心语H作为ɑ的标签。在集合{XP,YP}中,因为XP和YP都不是中心语,无法直接获取标签。解决集合{XP,YP}的加标问题,主要有两种途径:(1)对词组XP/YP提升或者移位来加标,修改句法对象内部结构,打破{XP,YP}的对称结构,使得剩下的成分可以对其加标。[8](2)直接获取XP和YP最显著的共同特征,将这一特征作为其标符。如,
例4[ɑ[DP which book][CP C[TP you read which book]]]
which book首先移位到[Spec,CP]上,移位后形成的新结构ɑ,而新结构ɑ的标签界定要取决于合并组成这个机构的句法成分。因为which book不是一个词汇项(中心语),不能直接为ɑ加标。DP从vP内论元位置移位至[Spec,CP],与C合并形成一个新的结构ɑ,根据加标法则b,提取二者共享特征[+Q],迫使该特征为ɑ加标。
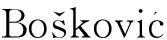
(二)浮游量化结构推导
汉语是一种话题显著型的语言,[10]句子时态的标识没有那么明显,因此T的时态特征很弱,不能单独加标。量化词提升运算过程中,包含嫁接操作,将整个QP嫁接到句子层次。量化词在量化运算过程中会核查[+Q]特征。
例5
a.张三喜欢所有的侦探小说。
b.张三所有的侦探小说都喜欢。
c.侦探小说,张三所有的都喜欢。
d.所有的侦探小说,张三都喜欢。
e.侦探小说,所有的张三都喜欢。
以例5a加标操作过程为例:
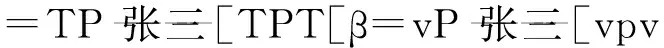
以上是普通话题结构的加标操作,在此基础上将对浮游量化结构进行加标运算演绎。对于例5中(b、c、d)这类既有话题又有主语的句子,本文将处理成主次话题。强量化词Q“所有的”同名词词组NP“侦探小说”底部生成于动词之后,由于Q是中心语,因此可以将合并的成分标为QP。QP受到句首[Top]特征驱动向左提升,途径vP语段边缘位置时,核查vP边缘特征(edge-feature),但是其自身的强特征不能核查,因此处在vP边缘的隐性量化算子“都”被激活,[11]投射成DistP,QP整体移位至[Spec,DistP],核查量化词组强特征[Q]。这样量化特征[Q]可以给ε加标:ε=
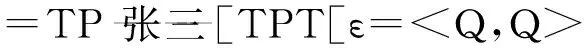
搁浅在DouP指示语位置的DP受到话题特征的驱动继续向前移位,从QP的边缘出口逃逸(escape-hatch),与Top2合并,投射成TopP2,然后内论元“侦探小说”移位至[Spec,TopP2]位置,因为“侦探小说”携带显著的[Top]特征,因此新的结构δ可以标记为,δ=

如果将内论元提升至句首,让外论元滞留在原来的结构中,则成为了单纯的话题句如例5d,但是该句含有量化词组,要和一般话题结构区分开来。首先,内论元移出vP宾语位置,可能是宾语前置结构,也可能是受到话题特征的驱动。QP受到量化特征驱动提升至[Spec,TopP2]位置时,δ=[δXP(=Q所有的DP侦探小说),YP(=Top2)],其实不能获得标签,这是因为QP中的[Q]特征不能核查。根据连续循环原则,新结构δ可以提取二者共同的特征[Top],加标为
[δ=
但是在上述结构中,量词“所有的”还不能被视作为浮游量词,因为其没有浮游至其他位置。事实上,在话题句中,浮游量化词本身携带显著的与焦点有关的信息,[12]因此可以与上层的焦点句合并,并且核查其焦点信息。
宁春岩提出标符有延续合并的作用,[13]即合并{ɑ,β},如果该词项集合中所有的句法特征都被剔除,ɑ的特征集合归零时,β可以与其他词汇合并时,则选用β作为此次合并的标签。例5e中,DP受到量化特征移位至TocP指示语的位置,标签Q与名词组“侦探小说”合并成一个集合时,因为名词组的词汇特征数量没有减少到零,受到上层的话题特征[Top]牵引提升至高处。DP与上级的TopP2合并,组成一个新的集合,θ={DP-侦探小说,TopP2}。当合并至此时,参与合并的词汇项的所有特征集合数量全部被探查,因此句法推导成立。
(三)限定性量化结构的加标运算
汉语浮游量化结构中,名词词组可能会受到限定词和量化词的双重约束。
例6
a.这些官员,大多数/全部/所有的/三个都出席了会议。
b.这堆书,我买了三本。
c.这堆书,三本被我买了。
上述例句中都存在“整体—部分”的关系,“这些”限定了“官员”和“书”的整体范围,而且对其进行限定量化。全称量化词或部分量化词也可以对名词组进行量化。[14]限定词和量化词对名词组共同进行量化,致使合并之后的结构不能简单的投射为QP。Citko将这一结构看作多重支配结构,实质上是一种对称性结构。[15]
Y和XP合并形成YP,Z和XP合并形成ZP,ZP和YP构成{YP,ZP}对称结构,其中XP和ZP都不是中心语。根据加标法则,合并操作的句法实体必须带有标签,且句法标签只能来自于构成其结构的两个成分本身,即要么是XP,要么是ZP,否则无法在接口层面被语义解读。其结构表示如下:
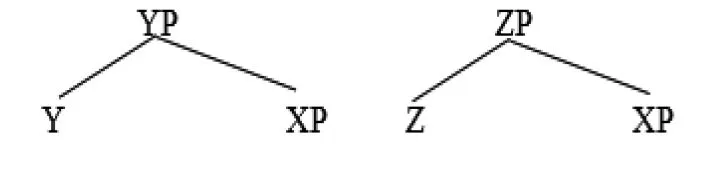
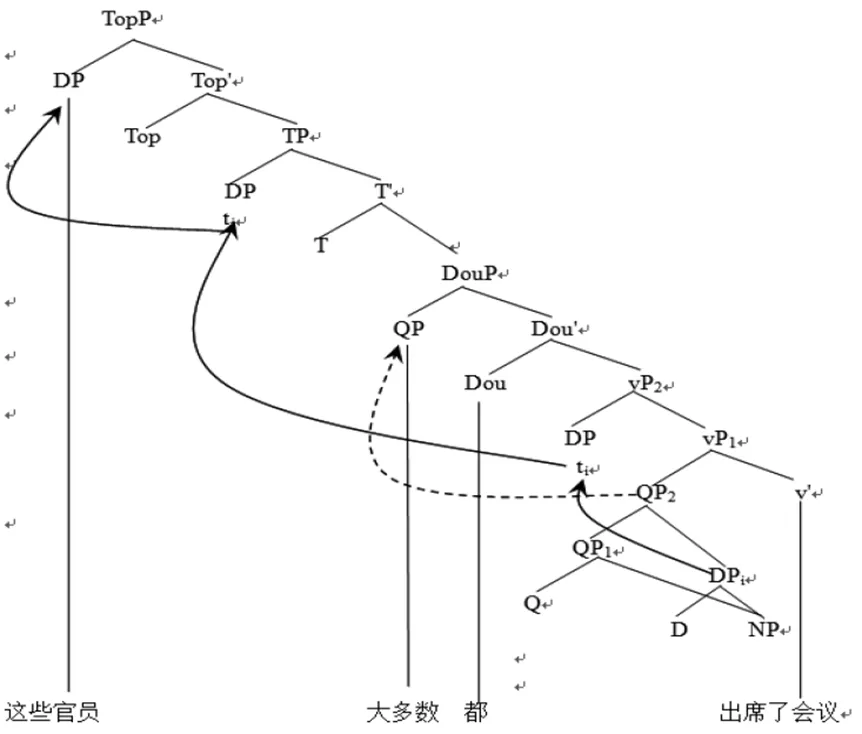
例7这些官员,大多数都出席了会议。
QP和DP合并形成最大投射ɑ:{QP, DP},因为QP和DP对名词组的功能各不相同,无法提取二者相同的特征,只能通过对QP/DP移位进行加标,从而打破对称结构,这样滞留在原位的成分可以作为合并实体的标签。
上述对称结构{QP,DP}基础生成[Spec,vP]的位置,同动词v合并之后,在界面处无法获得标签:首先移动QP“大多数官员”,留下DP后加标为DP,但是QP在上层无法获得标签,因此这一推导被驳回。那么只能移动DP“这些官员”,使得该结构ɑ加标为QP,从而将量化词滞留生成浮游量化结构。即,
第一步:对称结构{QP,DP}因为无法获得标签,移动DP至vP语段边缘位置,核查边缘特征,并从vP语段的边缘出口逃逸,打破对称结构,从而生成新的结构加标为QP。
第二步:DP“这些官员”继续前移至[Spec,TP]位置,与TP合并,形成不能获得标签的结构γ={XP,YP}。
第三步:DP受到[Top]特征的驱动继续向前移位至[Spec,TopP]位置上,核查句首的话题特征。
第四步:被滞留在原位的QP为了核查“都”的强量化特征,需要移位至[Spec, DouP]位置并且滞留于此,从而生成新的结构,最终浮游量化结构生成。其具体推导过程如下,
三、理论反思
本研究采用了加标运算推导理论,而不是最简方案下应用广泛的语段理论。语段是实现计算最小化和循环最大化的途径。[16]语言机能局部处理有限的信息量,减少记忆负担,提高运算效率。加标法则运算是最简方案时期最新的理论成果,很多句法结构都不能用加标进行解释。但是加标运算确定了句法结构生成的过程和推导步骤,无需探针—目标这一句法内部成分,避免了循环复杂的操作运算过程。另外,加标运算只是简单的对搜寻到中心语成分进行加标,无需核查成分本身的特征,也没有太过于关注EPP特征的存在,因此也避免了必须满足EPP特征的问题。而且在汉语中,由于T的时态特征过于薄弱,因此不要求显性主语必须出现在TP指示语的位置,核查EPP特征。即使主语出现在此位置,也可以被移走。
例8
a.人来了。
b.来人了。
除此之外,加标法则也可以解释许多其他复杂的句法现象。如,领有名词移位的真正的原因是为了满足合并成分的句法加标要求,不是为了满足格位和EPP特征,这两个特征只是作为“搭车者”一并获得核查。[17]而且,如果运用语段理论分析某类浮游量化结构,如例8b,似乎没有办法很好的区分浮游量化句与一般话题结构,但是加标运算可以。与语段理论相比,加标法不用生成许多不合语法的句法结构表征移交至接口进行语义解读,减轻了语言处理负担。[18]
在最简方案下,汉语中与加标运算相关的问题还有很多,仍然未能得到一个统一、全面的解释。一种可能的原因是对于复杂结构{XP,YP}的加标运算还不能获得一个合法的解读。另一种原因则可能是加标运算还不能描写汉语无形态语言现象的句法生成机制。汉语语言结构复杂,与英语等其他语言大不相同,很难运用统一理论来解释句法现象。
四、结语
本研究采用最简方案框架下加标法则运算,对不同的浮游量化结构的句法机制进行了描写。话题特征驱动量化词组前移,在这一过程中,LA提取不同的中心信息,为合并后生成的新结构加标。限定量化结构因为其名词组受到双重量化限定的原因,与一般浮游量化结构形成了对称结构{QP,DP}。这一结构需要通过移位打破对称结构获得标签,因此比一般浮游量化结构多一层处理,才能为新结构获得标签。通过加标运算,可以发现量化词在句中的位置不固定,可以浮游到多个位置,但其落脚点多是中心语的位置。但是本研究尚未对汉语非浮游量化结构中的生成机制作出研究,其量化词的生成动因和地位还有待进一步探讨和分析。
猜你喜欢
中华诗词(2021年3期)2021-12-31 08:07:22
中学生天地·高中学习版(2021年10期)2021-10-28 11:09:18
大连民族大学学报(2021年2期)2021-07-16 05:41:42
潍坊学院学报(2020年2期)2021-01-18 07:02:00
流行色(2019年10期)2019-12-06 08:13:26
名作欣赏·学术版(2019年5期)2019-06-25 08:29:29
中华诗词(2018年3期)2018-08-01 06:40:40
中华诗词(2018年11期)2018-03-26 06:41:32
海外华文教育(2017年6期)2017-08-07 03:11:06
环境科技(2016年2期)2016-11-08 12:18:22
