
全矢HMM 在轴承剩余寿命预测中的应用
2020-12-25 12:30周玉平
机械设计与制造 2020年12期
高 山,周玉平,陈 宏,张 旺
(郑州大学振动工程研究所,河南 郑州 450001)
1 引言
旋转机械在汽车行业,航空航天,冶金制造,发电等工业领域扮演着重要角色,而旋转机械最为关键的零部件之一便是轴承,轴承工作状况的好坏可以对整个旋转机械的工作产生举足轻重的影响。所以对轴承的寿命预测及其状态的检测是国内外研究的重要课题[1]。
为了克服传统频谱分析方法不能全面反映信号特征的问题,全矢谱[2]采用同源双通道信息融合技术,可以更加全面的反映设备的振动信息。目前以时间序列为基础的剩余使用寿命预测方法已获得很大进展,例如,以AR 模型为基础的寿命预测模型在非线性时间序列预测方面表现出良好的预测特性[3],近几年来也出现了大量的基于机械学习算法的寿命预测方法[4],例如利用神经网络,根据经验风险最小化原则和某一时刻的信息与模板库匹配系数来进行剩余寿命的预测[5],其预测精度较为准确。然而在实际的情况中,会得到大量的,复杂的数据,导致剩余寿命模型的时效性受到很大的局限,且基于时效性的寿命预测方法并不能对旋转机械的运行状态有很好的体现。为了更好的处理实际工况中出现的随机信号,提出基于KPCA 的全矢HMM 剩余寿命预测模型。
以滚动轴承全寿命数据研究对象,把全矢谱技术理论和KPCA 降维方法相结合[6-7],运用隐士马尔科夫理论建立剩余寿命预测模型,对滚动轴承的剩余使用寿命进行研究。分析并验证了该方法预测轴承剩余寿命的可行性。
2 理论基础
2.1 全矢希尔伯特
设{xn},{yn}分别是X,Y 方向上的离散序列,其构成复序列{zn}={xn}+j{yn}(n=1,2,…,N/2-1),其中j 为虚数,为了进一步提高计算效率,全矢谱理论是通过傅立叶变换可以得到{Zn}={ZRn}+j{Zin},其中{ZRn}和{Zin}是{Zn}的实部和虚部。由此可快速计算得出:(具体推导过程参见文献[2]):
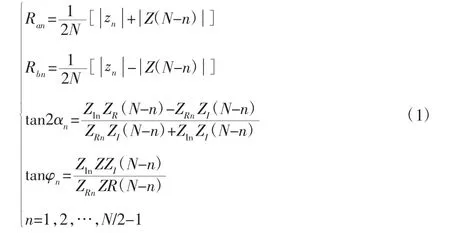
式中:椭圆长轴Ran—主振矢;短轴Rbn—副振矢;an—主振矢与x轴夹角;φn—初始相位角。
实际工况中采集的信号往往为非平稳的信号,记为x(t),其希尔伯特变换为:

定义复信号:

为x(t)的解析信号,将A(t)称为x(t)的包络。
Hilbert-全矢谱[8]以全矢谱为基础结合希尔伯特包络解调,该方法的具体步骤如下:(1)对转子在同一截面用相互垂直的两个传感器采集同源双通道振动信息,分别记作x(t)、y(t)。(2)对x(t)、y(t)分别带入式(2)做希尔伯特变换得到;再将x(t)、y(t)、带入式(3)得到x(t)的包络A(t)、y(t)的包络B(t)。(3)将解调后的信号A(t)、B(t)作为输入信号,在数据层进行信息融合,利用全矢谱理论得到双通道信息融合后的频谱结构。
2.2 隐马尔科夫模型(HMM)
隐马尔科夫模型是马尔科夫模型的进一步发展,它是一个双随机过程,包括可观察的观测随机序列和不可见的状态转移序列。它反映了状态和观测变量之间的对应统计关系,观测序列和转移序列的关系并不是一一对应的,而是用统计学的概率分布来描述,更符合实际情况[9-10]。
HMM 由以下五个基本参数来描述:
(1)N:模型的状态个数。记N 个状态值为q1,q2,…qm,将t时刻的状态用qt表示则qt∈{q1,q2,…qm};
(2)M:各状态对应的最大的观测值数目。记M 个观测值为o1,o2,…om,将t 时刻的观测值用ot表示,则有ot∈{o1,o2,…om};
(3)π:初始状态概率分布,π≡(π1,π2,…πN),其中πi≡p[π1=qi],1≤i≤N,其中πi满足
(4)A:状态转移概率矩阵,A=(aij)N×N,其中从t 时刻si转移到t+1 时刻si的概率为:
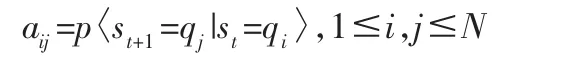
其中aij满足
(5)B:观测转移密度矩阵,根据观测序列的离散连续情况,可将HMM 分为离散HMM(DHMM)和连续HMM(CHMM)
2.3 核主成分分析(KPCA)
核主成分分析(KPCA)定义为在共有K 个样本的随机变量O={O1,O2,O3,…On}的条件下,定义非线φ,φ:xt→φ(xt),i=1,2,…,k,将原始数据从低维空间Rn映射到高维空间F,使得投影后的数据集变为线性可分的数据集,此空间成为希尔伯特空间,则有输入数据集:
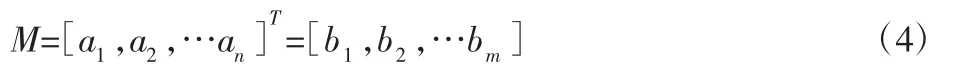
在高维空间F 中可得:
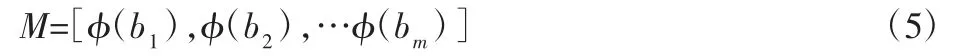
然后对高维空间中的数据φ(x)进行KPCA 主元分析。
其算法可总结为以下步骤:
(1)计算核矩阵:

(2)计算K 的特征值和对应的特征向量:

(3)根据置信区间选取前S 个特征向量并归一化,使得:

(4)利用投影公式计算样本O 的第j 个核主成分。即

3 基于KPCA 降维算法的全矢HMM 轴承退化状态识别与时间序列预测模型
该模型首先利用全矢Hilbert 方法对同源双通道振动数据进行预处理,得到主振矢的频谱结构并对其进行频域参数计算分析,同时对全矢Hilbert 融合后的振动数据进行时域参数分析计算。选出优秀的时、频域指标,分别进行KPCA 降维处理,得到少数核主元进行对比,选出最优主元作为轴承寿命模型的退化指标,建立剩余使用寿命预测模型,设置阈值作为失效评定点,利用HMM 方法进行剩余寿命预测。
3.1 KPCA 降维处理
实验数据源于美国美国宇航局(NASA)网站,辛辛那提大学智能维护系统的滚动轴承退化数据。该数据通过轴承退化实验得来,具有很强的代表性。
实验时的电机转速约为2000r/min,用加速度传感器(单位g)采集振动信号,采样频率为20000Hz,采样点数为20480。
选用ZA-2115 双列滚柱轴承,每列有16 个滚动体,滚动体直径为8.4mm,节圆直径为71.5mm,接触角15.17°。
实验一共进行三次,第一次实验3 号轴承出现内圈故障,4号轴承出现滚动体故障,第二次实验1 号轴承出现外圈故障,第三次实验3 号轴承出现外圈故障。
第一次试验获得2155 组数据,其中的3 号轴承发生内圈故障,4 号轴承发生滚动体故障;第二次试验获得984 组数据,1 号轴承发生外圈故障。选取第一次试验3 号轴承从正常状态退化成内圈故障的数据进行分析。试验台结构示意图,如图1 所示。
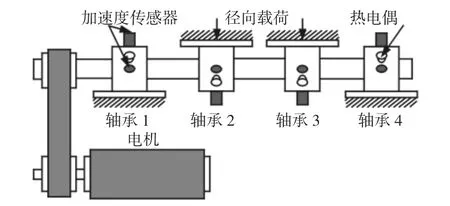
图1 试验台结构示意图Fig.1 Structure Diagram of Experiment Bench
首先取一组内圈故障的振动数据用传统的Hilbert-fft 方法对双通道信号做频谱分析,得到频谱结构,如图2 所示。
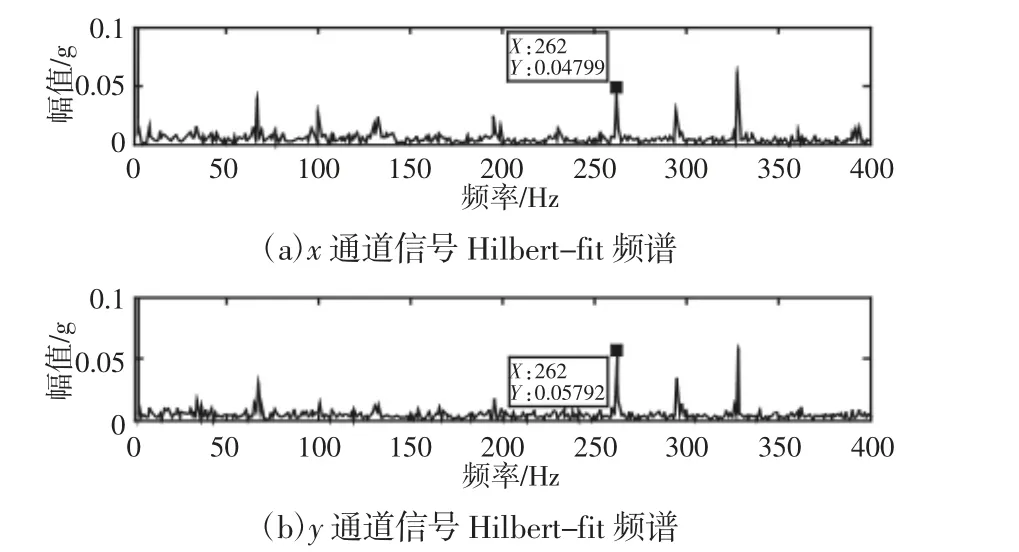
图2 内圈故障x、y 通道的传统频谱图Fig.2 Traditional Spectrum Diagram of x and y Channels of Inner Circle Failure
用Hilbert-全矢谱方法获得主振矢的频谱结构,如图3 所示。
将得到的振动信号首先进行全矢Hilbert 融合,得到主振矢的频谱结构,如图3 所示。可以看出进行全矢Hilbert 融合后得到的信号更能全面发映出信号的特征,从中选取内圈故障频域信号的特征频262Hz,转频33Hz、转频半频16Hz 及转频倍频66Hz、100Hz、133Hz、196Hz、262Hz 八种频域幅值作为评价指标,分别对轴承运行状态进行识别,然后选取平均值、峰-峰值、方差、峭度、峰值因子、峭度因子、脉冲因子和裕度因子八种时域信号作为评价指标来反映轴承运行状态。之后对比时域和频域信号的识别结果。
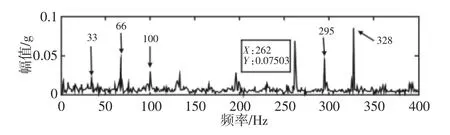
图3 内圈故障的Hilbert-全矢主矢谱Fig.3 Hilbert-Full Vector Principal Vector Spectrum of Inner Circle Fault
首先将KPCA 降维算法的阈值设置为90%时,时域信号降为二维,其累计贡献率维95%,频域信号降为五维,其累计贡献率维90%。将阈值设置为95%时,时域信号降为二维,其累计贡献率维95%,频域信号降为七维,其累计贡献率维97.2%。由此可以看出多种时域信号降维后包含的轴承寿命信息仍然较为全面,而多种频域信息经过KPCA 降维后维数仍然较高不利于数据计算,因为选取降维后的时域信号数据作为HMM 的训练数据。
3.2 KNN 数据聚类及K-means 近邻分析
将经过KPCA 处理后时域信号的两维数据进行趋势项聚类,计算各类内均值和方差作为近邻分析数据输入,初始化轴承内圈全寿命的三个阶段。根据欧氏距离法调整三个阶段内类的个数,直至各阶段内类的个数不变。聚类和近邻分析划分的三阶段轴承寿命,如图4 所示。由图4 看出,第一阶段(1~252)内波形会受到加工和安装环境等因素的影响波形并不稳定,趋势变化较为剧烈。经过一段时间磨合后振动强度变低且趋于平稳,此时进入第二阶段,平稳运行阶段(252~1946)。当进入第三阶段(1946~2150)时,轴承出现故障,振动幅值开始增大,波形变化出现异常,到达临界点时波形急剧增大。说明由趋势项聚类结合近邻分析可以达到预期的分裂效果。
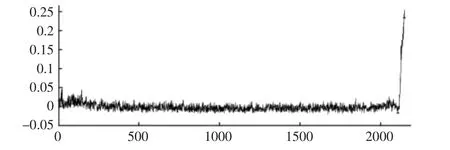
图4 聚类和近邻分析划分的三阶段轴承寿命Fig.4 Life of Three-Stage Bearing Divided by Clustering and Nearest Neighbor Analysis
3.3 轴承状态识别和剩余寿命预测
为缩小识别误差,降低后续的识别难度。利用KPCA 降维处理后的数据,根据三个阶段各个聚类结果选取各类内前25 个数据作为训练数据,后17 个数据作为测试数据,估算三个阶段HMM 模型的参数。由上可知轴承全寿命的三个阶段按聚类结果分为:第一阶段时间点为1~252(聚类点为1~6)、第二阶段时间点为252~1946(聚类点为6~42)、第三阶段为1946~2150(聚类点为42~45)。将测试数据带入验证其识别效果,如表1 所示。

表1 HMM 识别结果Tab.1 HMM Recognition Results
第三阶段识别错误类点为第43 个类,其识别结果为第二阶段,由于在第42 个类点时其实内圈已经发生故障,但是第二阶段包含的时间长、数据信息量大,对比第43 类点和第二阶段的波形可以看出其有很多相似波形,并且具体识别类点为第39 个类点,误差在合理的范围之内。所以整体的识别效果较为理想,可以作为进一步识别的结果。
选取内圈特征主振矢全寿命时域信号对当前状态进行精确定位,识别当前运行状态,估算剩余寿命。根据聚类方法,主振矢时域信号被分为45 个类,选取各类的前25 个数据作为训练数据,后10 个作为测试数据估算45 个类相应的HMM 模型参数。根据上一步我们可以得到测试数据的时间点以及当前所属的运行阶段(即类的识别范围),选取相应主振矢的聚类点在相应的范围类进行识别。该识别步骤由于识别类较多,其中波形相似度较大,易造成误判,选取以下判别公式作为识别的阈值,减少误判率。
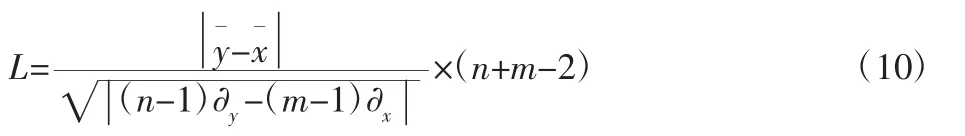

式中:ti—预测结果;ti—测试数据的真实剩余寿命;T—总的寿命时间。
无KPCA 降维和分阶段预测的剩余寿命预测结果,如图5所示。
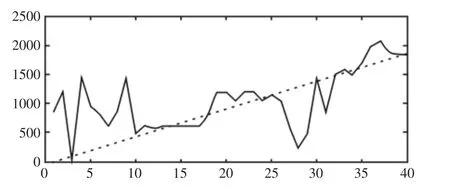
图5 基于全矢Hilbert-HMM 预测结果Fig.5 Based on the Prediction Results of Whole-Vector Hilbert-HMM
由图5 可以看出在未引入KPCA 及分阶段预测的情况下,HMM 整体的预测趋势随着滚动轴承的运行时间而变化,在振动变换相对剧烈的时间类内,HMM 模型的识别效果较好。在开始阶段由于中间类包含的振动情况较为丰富,识别结果易造成混叠,给剩余寿命的评价带来误判。这也反映了实际运行情况,初始阶段由于加工精度和安装误差的影响,轴承的振动剧烈,其振动信号与故障信号以及平稳运行阶段的信号相似度很大,不利于模型的识别和预测,同时在整个寿命周期中共有45 个类,此时类的识别只考虑类内的最大似然估计值,而忽略了类与类之间的相互关系,这对剩余寿命的评价是不全面的。引入KPCA 降维方法,从时域信号和频域信号中选取优秀的主元作为轴承剩余寿命的评价指标,并将轴承全寿命过程划分为三个阶段,通过比较前后类的最大似然估计值作为识别结果,因此可以在模型识别过程中,避免单一的类内比较,加入类之间的相互关系,同时将轴承划分三个阶段,有利于将初始阶段和平稳运行阶段区分开来,避免模型的混叠,为后续HMM 的进一步预测减少计算量。其预测结果,如图6 所示。
由图6 看出在经过KPCA 降维以及HMM 分阶段预测的情况下,整体预测趋势更加平稳,说明分阶段预测可以达到良好的预测结果。整体模型误差集中在轴承运行的初始阶段,这是由于其振动信号与故障信号相似度较大造成的。中间平稳阶段除去个别点外,预测精度可以达到预期效果,在轴承故障阶段模型出现提前预测偏高的情况,尽管出现一定的误差,但整体的预测精度达到预期效果。

图6 基于KPCA 的全矢Hilbert-HMM 预测结果Fig.6 Full Vector Hilbert-HMM Prediction Results Based on KPCA
4 总结与展望
为了提取更为优秀的滚动轴承剩余寿命模型中的退化指标,对轴承的剩余寿命进行准确预测,提出KPCA 降维处理方法结合数学统计模型HMM 进行轴承内圈剩余寿命的预测。用KPCA 将多维数据指标进行降维,且隐马尔科夫链的随机游走特性,其包含概率的统计成分符合实际设备使用状况。创新点如下:(1)提出KPCA 降维处理方法结合数学统计模型HMM 进行轴承内圈剩余寿命的预测和状态识别。减小数据计算量,去除数据冗余,提高预测速度和精度。(2)提出一种结合KNN 近邻分类和K-means 聚类的方法,将聚类标准由欧式距离变为最大似然估计值作为聚类的标准。
但该方法还需要改进和后续研究,结合本次研究,给出以下两点设想:①连续HMM 模型作为一种无监督的故障诊断检方法,以数据概率分布形式将最大似然估计作为评价指标,能否建立一种监督机制,赋予各维数据权重,权衡数据对模型最终结果的影响,减少无用数据造成的干扰。②数据评价指标的制定。对于奇异点的分析,振动强弱可以很好的反应设备的振动情况,但是由于奇异点的存在,对于数据影响较大,在分析数据时是否可以建立更为合理的评价指标,结合奇异点和数据的振动强度,对设备运行状态做出更为合理的评价和预警。
猜你喜欢
车主之友(2022年4期)2022-08-27
中老年保健(2021年8期)2021-12-02
哈尔滨轴承(2021年4期)2021-03-08
作文评点报·低幼版(2020年3期)2020-02-12
海峡姐妹(2019年12期)2020-01-14
制造技术与机床(2019年6期)2019-06-25
华人时刊(2018年17期)2018-12-07
奥秘(2017年12期)2017-07-04
制造技术与机床(2017年4期)2017-06-22
