
删失指标随机缺失下条件分位数的加权核估计
2020-12-15 04:21:02周杨程王江峰袁汶汶张惠利
高校应用数学学报A辑 2020年4期
周杨程, 王江峰, 袁汶汶, 张惠利
(浙江工商大学统计与数学学院,浙江杭州310018)
§1 引 言
在统计学中,对条件分位数的估计长期以来备受关注.在描述数据时,应用条件分位数会得到一些很好的性质,例如在处理重尾或离异的数据时,可以更加稳健,尤其是条件中位数.令T表示因变量,其分布函数为F(·),X=(X1,···,Xd)>∈Rd为协变量,其联合密度函数为v(·).设F(·,·)和f(·,·)分别为(X,T)的联合分布函数和密度函数,则在X=x条件下,T的条件分布函数F(t|x)可以写成:
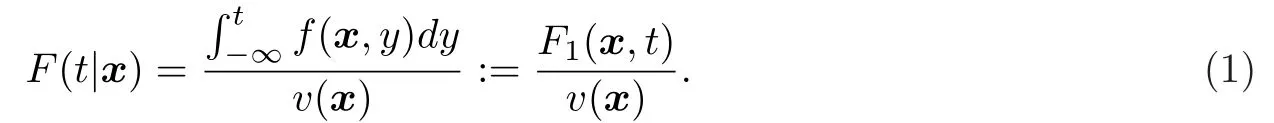
通过(1)式得出条件分位数Qτ(x):
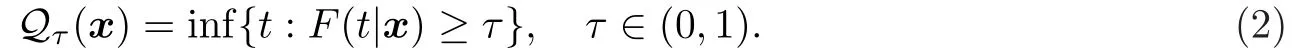
在过去的二三十年中,国内外有大量的文献研究了条件分位数的估计问题.在独立完整数据下,Chaudhuri[1]采用了多种非参数方法来估计条件分位数函数;Xiang[2]先构造了条件分布函数的核估计,由此得到了条件分位数的核估计.但在医学和工程寿命等领域中,因变量T往往会由于许多原因被右删失而不能完全观测到.在右删失数据下,Dabrowska[3]得到了分位数核估计量的Bahadur型表达式;Xiang[4]对随机右删失数据在等覆盖概率准则下,比较了两个核分位数估计与样本分位数估计的性能;Ould-Sa¨ıd[5]建立了条件分位数核估计的强一致收敛速度.
在以往研究右删失数据时,删失指标通常是可以完全观测到的,但在很多实际应用中,由于存在种种复杂因素,部分删失指标会随机缺失.例如,在医学领域中,当死亡原因调查表丢失,死亡原因未被记录或由于病情复杂无法确定等情况出现时[6],研究某个特定死亡原因导致的死亡时间,那么删失指标就会存在部分的缺失.当遇见删失指标缺失的样本时,最直接最简单的方法将删失指标缺失的数据全部去除,并用删失数据下的统计方法对剩下的完全数据进行推断,这种方法称为完全数据(CC)方法.然而,这种CC方法推断出来的结果常常是不可靠的,特别是当缺失严重时,删除后的数据量也会大大减少,无法很好的反映总体.对于此类数据的处理,首先应当将其缺失机制进行划分,Little和Rubin[7]提出可以分为三类:完全随机缺失(MCAR),随机缺失(MAR)以及不可忽略的缺失(non-ignorable missing).过去有大量文献关于相对较强条件的MCAR缺失机制做了深入的研究,见Zhou和Sun[8]以及McKeague[9].
本文讨论的是更一般的MAR情况,这种情况在许多实际问题中常常碰到,具体实例见Little和Rubin[7].最近,有许多作者对MAR情况做了不少工作.比如,Li和Wang[10]在研究线性回归模型中提出了加权最小二乘法估计;Brunel等人[11]研究了条件风险率函数的估计问题,并对该估计提出了基于模型选择方法的非参数自适应策略;Shen和Liang[12]应用分位数回归方法研究了部分线性变系数模型.然而,在MAR情况下,目前还没人研究条件分位数的估计问题,更别说是协变量为多维的情形.在这里,先分别构造条件分布函数的校准加权核估计,插值加权核估计以及逆概率加权核估计;然后根据这些估计分别导出条件分位数的核估计,并建立这些估计的渐近正态性结果;最后在有限样本下,对这些估计进行模拟研究.
§2 估计的构造
设{(Xi,Ti),i=1,2,...,n}是一列来自总体(X,T)∈Rd+1的随机向量序列,在右删失情况下,由于删失变量Ci的出现,Ti不能全部观测到,因此实际观测到的数据为Yi=min(Ti,Ci)以及δi=I(Ti≤Ci).设Ci的分布函数为G(·),与Xi独立,并且在条件Xi下也与Ti独立.
在右删失数据下,Ould-Sa¨ıd[5]给出在一维协变量下条件分布函数F(t|x)的核估计

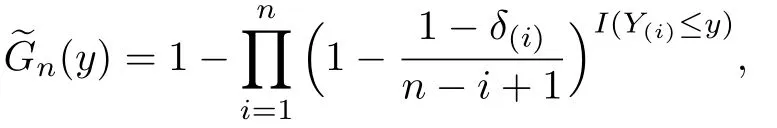
Y(1)≤Y(2)≤···≤Y(n)为Y1,Y2,···,Yn的次序统计量,δ(i)为Y(i)相对应的量.
事实上,易知上式(3)可以看作下式的最小解:
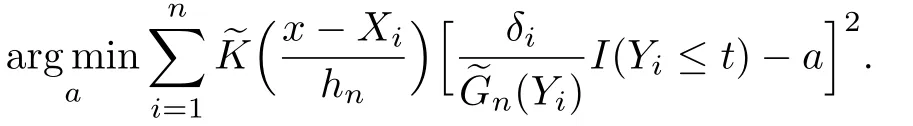
本文考虑的是MAR情形,定义缺失指标ξi:当δi可观测时,ξi=1;反之,ξi=0.假设缺失指标ξi和(Yi,Xi)相关,而与δi独立,即P(ξi=1|Yi,Xi,δi)=P(ξi=1|Yi,Xi).最后实际观察到的样本数据为{Yi,Xi,δiξi,ξi,1≤i≤n}.由于删失指标δi的随机缺失,而(3)式和n(·) 都涉及到δi,因此上面的核估计不能直接用.过去在处理δi的随机缺失时,可以根据Li和Wang[10]的方法,引入条件期望函数,即令φ(Z)=E(δ|Z),这里Z=(X,Y).
设Λ(·)为某个分布函数,λ(·)为它的密度函数,f(·|x)为在X=x条件下T的条件密度函数,Kd(·)定义在Rd上的核函数,.这样有

因此通过(4)式,在MAR情形下,可以构造F(t|x)的估计为下式最优解:
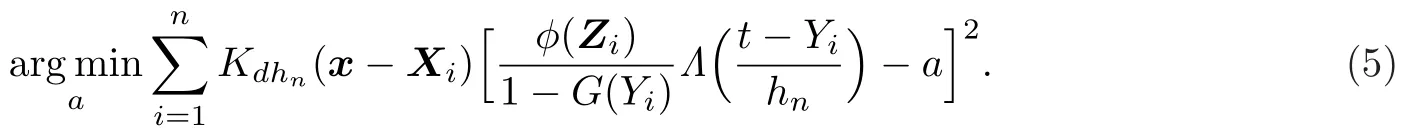
对(5)式不难求解,得到F(t|x)的估计为
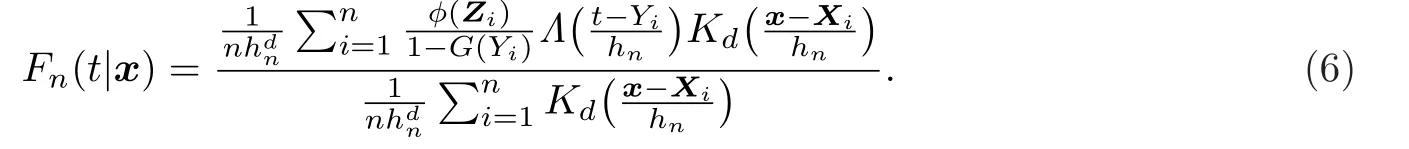
在实际应用时,(6)式中的φ(Z)和G(·)往往是未知的.先处理φ(Z)的估计问题.注意到δ二进制的,对于二进制数据的建模可以用一个指定模型形式来建立,例如Logit模型等.因此假设φ(Z)=φ0(Z;θ0),其中φ0(·;θ0)是已知的函数,θ0∈Rl是未知的参数向量.对于θ0的估计,这里可以沿用Li和Wang[10]的极大似然估计(MLE)方法,即下式的最大解:


故在MAR情形下,在(6)式中分别用φ0(Zi;n)和Gn(Yi)替换φ(Zi)和G(Yi)},得到F(t|x)的校准(CA)加权核估计为:

§3 主要结果
在给出结果之前,先给出一些注记.对于任何分布函数L(·),记

接下来,给出一些条件.
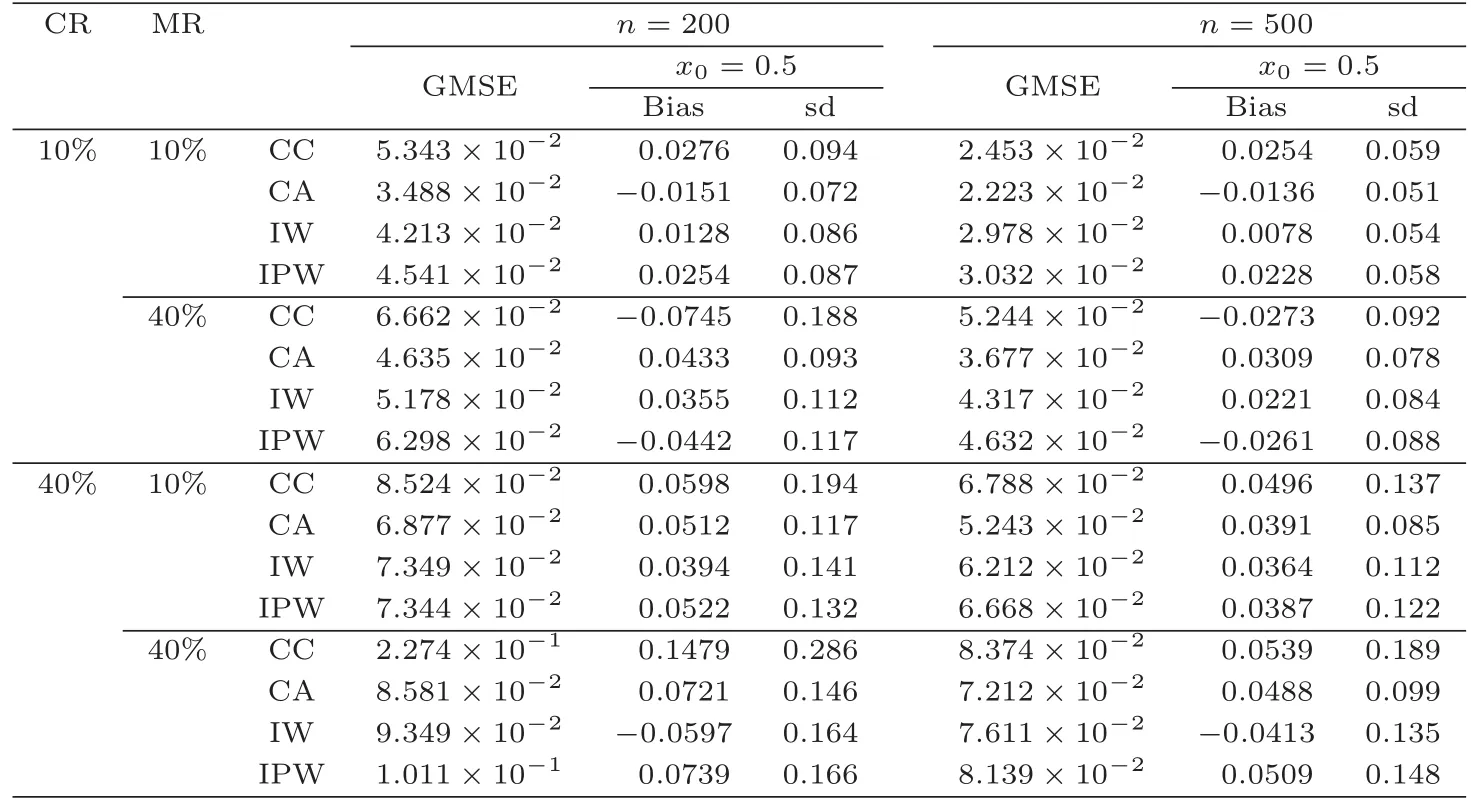
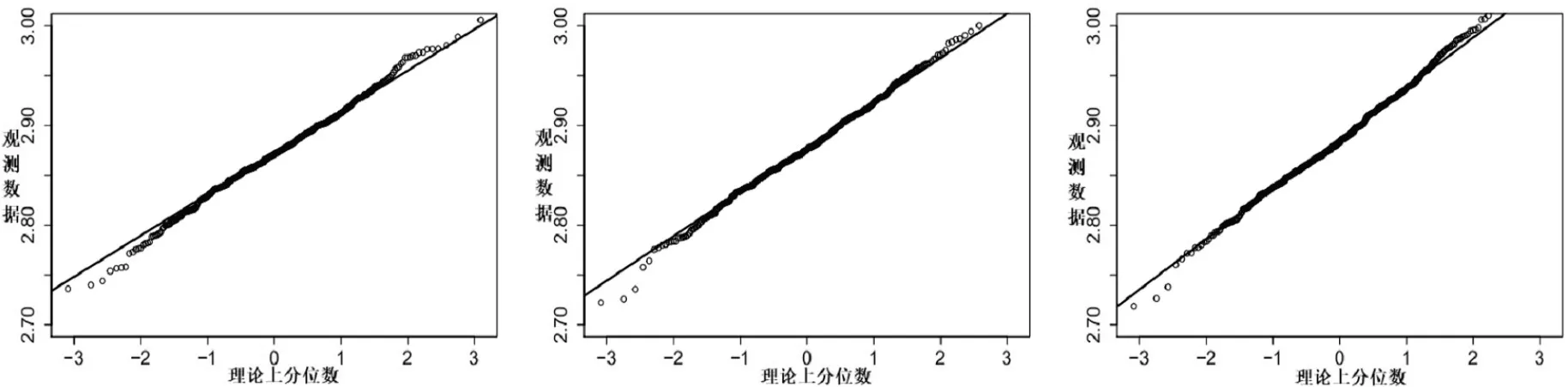
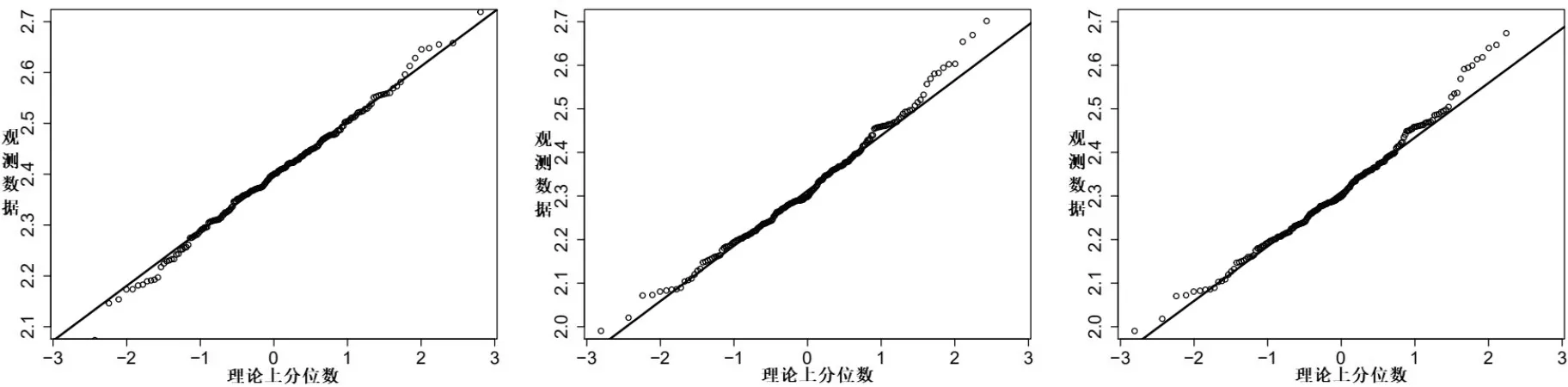
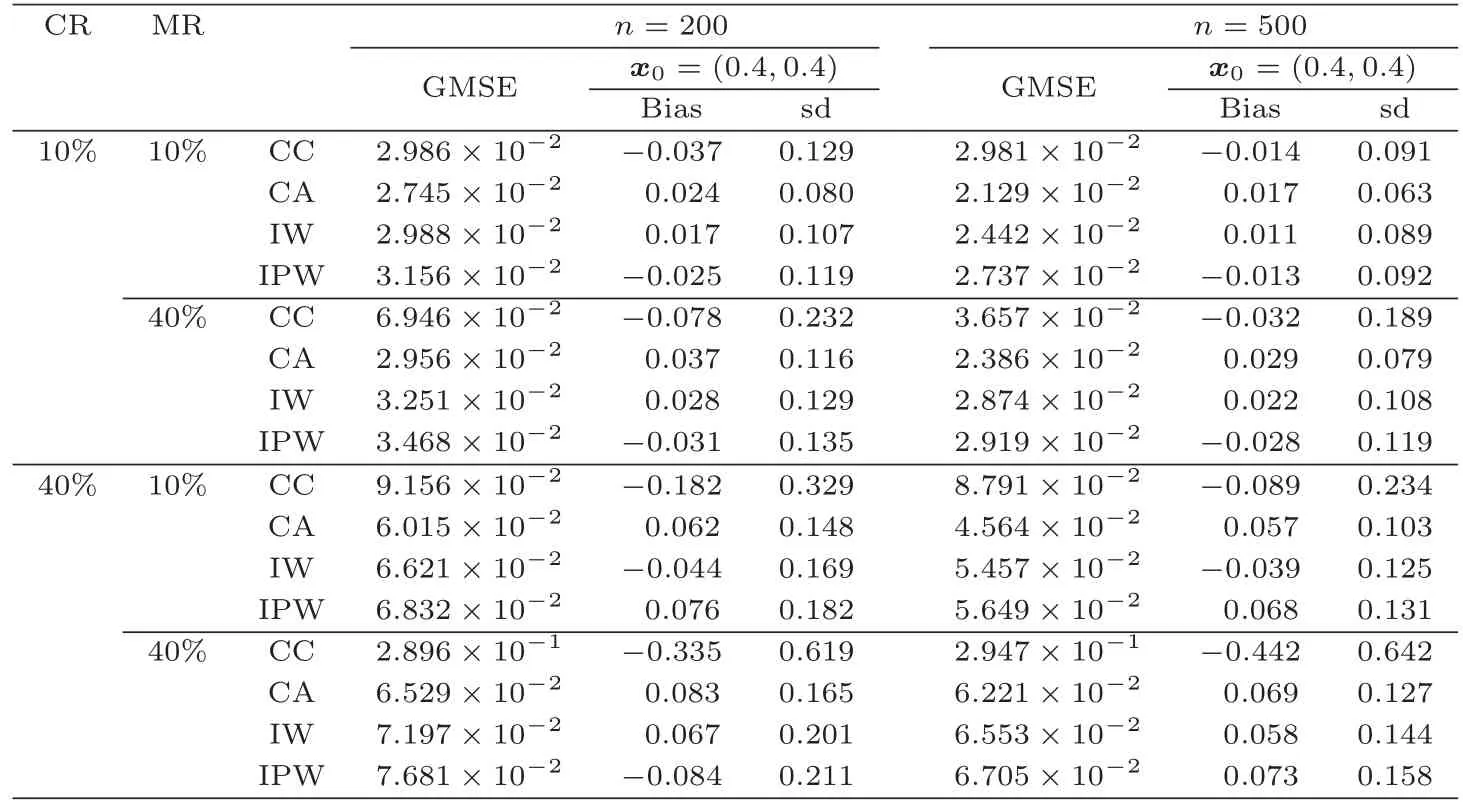
(A1)(i)H(t)在t (ii)F1(r,s)和条件分布函数F(s|r)在任意的(r,s)∈U(x)×U(t)上具有连续的二阶偏导数. (A2)Kd(·)为定义在Rd上紧支撑的有界核函数,满足 (A3)Λ(·)为一个连续且严格增的分布函数,其密度函数λ(·)满足Rtλ(t)dt=0. (A4)X的密度函数v(·)在点x上连续,且v(x)>0. (A5)窗宽hn满足 (A6)条件密度函数f(s|r)在任意的(r,s)∈U(x)×U(t)上具有连续的二阶偏导,且f(t|x)>0. (A7)Σi,1(x,t)>0,i=1,2,3,且关于点x上连续. (A8)I(θ0)为正定矩阵,∇φ0(Z;θ)在θ0上连续;L(·)和Ω(·)是R上紧支撑的核函数,窗宽满足 注3.1条件(A1)中的aH 在这一节,通过两个例子(d=1,d=2),模拟研究Qτ(x)的各个估计的性质,内容主要包括:(i)比较Qτ(x)的CC(第一节提到过),CA,IW以及IPW核估计之间的整体均方误差(GMSE)以及固定点上的偏移(Bias)和标准差(Sd);(ii)应用正态Q-Q图研究各个估计的渐近正态性效果. 例4.1考虑协变量为一维的模型 这里的Xi∼N(0,1),且与εi相互独立.研究τ=0.5下Q0.5(x)的各估计的模拟情况.显 然Q0.5(x)=2+sin(2x)+2exp{−16x}.为了计算Q0.5(x)的各个估计,分下面几个步骤: Step 1从模型(11)中,产生一组样本数据{(Xi,Ti),1≤i≤n}. Step 2获取不同的删失比例(CR):假设Ci∼exp(µ)+2,Yi=min(Ti,Ci)以及δi=I(Ti≤Ci),这里µ用来调整获取不同的CR. Step 3获取不同的缺失比例(MR):由于考虑的是MAR情况,假设Logit(E(ξi|Xi,Yi))=α1+α2Xi+α3Yi,这里通过调整(α1,α2,α3)的值获得不同的MR. Step 4φ0(Zi;n)和n(Yi)的计算:通过(11)以及步骤1-3,可以模拟一组观察数据{(Yi,Xi,δiξi,ξi),1≤i≤n}.假设φ0(Zi;θ)服从Logit模型, 即Logit(φ0(Zi;θ))=θ1+θ2Xi+θ3Yi.参数θ=(θ1,θ2,θ3) 的估计根据§2提到的MLE方法得到; 对于n(Yi),选取L(x)=,然后由§2的乘积极限估计获得. Step 5计算Q0.5(x)的CA,IW以及IPW估计:选取,Λ(x)为标准正态分布函数,把φ0(Zi;n)和n(Yi)带入(7)-(9)式,算出,i=1,2,3;然后根据,计算出Q0.5(x)的CA,IW以及IPW估计. 在比较Q0.5(x)的各估计好坏时,要用到GMSE,其定义为 在表格1和表格2中,分别对εi∼N(0,0.52)和εi∼t(3)两种情况进行模拟.考虑CR=10%和40%,MR=10%和40%,n=200和500,基于M=200重复得到关于Q0.5(x)的CA,IW以及IPW估计的GMSE.窗宽hn的取值范围从0.01到1.0,增量为0.02,分别选择使GMSE达到最小的窗宽.另外,在x0=0.5上,基于200次重复计算各估计下的偏差和标准差. 表1 在例4.1和εi∼N(0,0.52)中,CC,CA,IW以及IPW估计下的GMSE,Bias以及Sd的模拟结果 通过表1和表2,可以得到一些结论:(1)当样本量n增大时,无论从GMSE,Bias还是sd的结果,CC,CA,IW以及IPW估计模拟效果都更好;而当CR和MR增大时,这四种估计模拟结果会变差;(2)在其他条件相同下,从GMSE以及Sd的结果来看,CA估计都最优,与定理3.1的结论相一致;但是从Bias的模拟结果,发现IW估计最优;(3)从CR=10%,MR=40%和CR=40%,MR=10%这两组模拟的结果发现,CR的影响比MR的影响似乎更大;(4)当缺失比例很大时,即MR=40%,CC方法比CA,IW以及IPW估计方法模拟出来的结果都要差. 表2 在例4.1和εi∼t(3)中,CC,CA,IW以及IPW 估计下的GMSE,Bias以及Sd的模拟结果 接下来,在εi∼N(0,0.52)下,通过Q-Q正态图来研究CA,IW以及IPW估计的渐近正态性效果.在图1-图3中,对n=500和M=500,分别在(CR=10%,MR=40%),(CR=40%,MR=10%)以及(CR=40%,MR=40%)下对Q0.5(x0)(x0=0.5)的CA,IW以及IPW估计作了QQ正态图.从图1-图3看,发现CA估计的渐近正态性效果似乎更好,这和定理3.1中的结论(CA估计的渐近方差最小)一致;另外,可以发现随着CR和MR的增大,各估计的渐近正态效果越差;而通过图1和图2的比较,可以看出CR的变化对各估计的渐近正态性的影响要比MR的变化所受的影响要大,这个结论和表1的结论一致. 图1 在例4.1中,在CR=10%和MR=40%,n=500下,从左到右分别表示CA,IW以及IPW估计的正态Q-Q图 例4.2考虑一个协变量为二维的模型 这里的X1i∼U(−1,1),X2i∼U(−1,1),和εi∼N(0,0.52)是相互独立的.此处的估计目标为条件分位数.选择二元核函数 图2 在例4.1中,在CR=40%和MR=10%,n=500下,从左到右分别表示CA,IW以及IPW估计的正态Q-Q图 图3 在例4.1中,在CR=40%和MR=40%,n=500下,从左到右分别表示CA,IW以及IPW估计的正态Q-Q图 仍然沿用例4.1的步骤,可以计算Q0.5(x)的各估计.表3选择CR=10%和40%,MR=10%和40%,n=200和500,基于M=200重复得到关于Q0.5(x)的CA,IW以及IPW估计的GMSE.窗宽hn的取值范围仍然从0.01到1.0,增量为0.02,分别选择使GMSE达到最小的窗宽.另外,在x0=(0.4,0.4)上,基于M=200次重复计算各估计下的偏差和标准差. 根据表3中的数据发现:(1)在其他条件相同下,随着CA和MR增大,每个估计在GMSE,Bias以及Sd方面的模拟效果会越差;而当样本容量增大时,各估计的模拟效果越好;(2)在GMSE和Sd方面,CA估计的模拟效果最好;在Bias方面,IW估计模拟的效果比CA和IPW估计的效果要好;(3)CR的变化对各估计模拟效果的影响比MR的变化所带来的影响要大.这些结论和表1和表2的结论是一致的. 例4.3为了能解决实际问题,选取了肺癌患者临床数据.在这组数据中,一共有228个肺癌患者,其中删失的数据为63个.由于这组数据删失指标是完整的,为了得到本文的观察数据,对这组数据做一些处理,即对删失指标进行部分随机缺失.这样228个患者中有151个患者的存活时间未被删失(δ=1,ξ=1),有56个患者的存活时间被删失了(δ=0,ξ=1),最后还有21个患者的删失指标被随机缺失了(ξ=0).另外,作者关心的2项指标是存活时间(time)和患者年龄(age).设T=log(time),X=age/100,X与T的散点图见图4中的左图. 用CC,CA和IW方法对实际数据中的Y=log(time)关于X=age/100作条件中位数曲线(τ=0.5)的模拟(见图4中的右图).从图4种的右图发现,用CC和IW两种方法模拟的效果差不多,在40-50岁之间,患者年龄越大,存活时间反而越长,50-70岁之间,患者存活时间和年龄之间变化不大,到了70岁以后,患者年龄越大,存活时间越短.对于CA方法模拟的曲线似乎更合理,尤其是在40-50岁之间,患者存活时间和年龄之间的变化没有CC和IW两种方法那么明显. 表3 在例4.2中,CC,CA,IW以及IPW估计下的GMSE,Bias以及Sd的模拟结果 图 4 左图为例3中X=age/100与T=log(time)之间散点图;右图为用CC,CA和IW方法估计下条件中位数曲线的模拟图 在证明定理前先给出一个引理.
§4 模拟研究






§5 定理的证明



 猜你喜欢
数学小灵通(1-2年级)(2021年10期)2021-11-05 07:20:44数学年刊A辑(中文版)(2021年4期)2021-02-12 01:20:44数学小灵通(1-2年级)(2020年12期)2021-01-14 00:57:50统计与决策(2017年2期)2017-03-20 15:25:23小学阅读指南·低年级版(2016年10期)2016-09-10 07:22:44电测与仪表(2016年15期)2016-04-12 00:30:58湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:14航天返回与遥感(2014年4期)2014-07-31 17:47:33技术经济(2014年8期)2014-02-28 01:29:42河南科技(2014年11期)2014-02-27 14:09:41
猜你喜欢
数学小灵通(1-2年级)(2021年10期)2021-11-05 07:20:44数学年刊A辑(中文版)(2021年4期)2021-02-12 01:20:44数学小灵通(1-2年级)(2020年12期)2021-01-14 00:57:50统计与决策(2017年2期)2017-03-20 15:25:23小学阅读指南·低年级版(2016年10期)2016-09-10 07:22:44电测与仪表(2016年15期)2016-04-12 00:30:58湖北师范大学学报(自然科学版)(2015年1期)2016-01-10 08:41:14航天返回与遥感(2014年4期)2014-07-31 17:47:33技术经济(2014年8期)2014-02-28 01:29:42河南科技(2014年11期)2014-02-27 14:09:41
