
基于多尺度与改进注意力机制的序列到序列模型
2020-12-14 10:20:34朱丙丽
计算机应用与软件 2020年12期
陈 立 朱丙丽
1(重庆幼儿师范高等专科学校初等教育与应用技术系 重庆 404047)2(重庆三峡学院计算机科学与工程学院 重庆 404199)
0 引 言
深度神经网络是当前机器学习领域流行的方法,由于其灵活和高性能的特点,被广泛应用于多个领域。其中序列到序列模型是对于动态长度的输入序列映射到动态长度的输出序列的特殊模型[1]。经典的序列到序列模型包括编码和解码两个模块,编码模块用来从输入源中捕捉整体信息,解码模块产生目标输出。
序列到序列模型对于编解码过程的训练是比较困难的,因为解码依赖于输入状态的最后一个隐含层,当源输入或目标输出太长时,解码效果会下降[2]。为解决此问题,现在的序列到序列模型一般都引入注意力机制[3]。注意力机制通过在编解码状态中引入快捷联系以避免上述问题。注意力机制让模型聚焦于来自编码器的部分而忽视其他一些次要信息。根据这种策略,很多基于注意力的模型被应用于变长序列的转换任务,例如机器翻译[4]、语音识别[5]和对话生成[6]等。
由于注意力机制的重要性,很多学者致力于研究如何发展、改进这一机制。有学者提出了一种只计算输入序列子集的方法,降低了每个编码步骤的计算成本[7]。还有研究通过对分类的随机变量采样,用硬边界替代传统的软边界[8],以及用一种新的机制来加强单调性并使用在线编码,使模型具有序列到序列的能力[9]。有不少基于通用注意力机制的模型都致力于改进编码器与解码器相关性的评分机制[10],但这一类方法大多都没有考虑合并前一时间步骤的信息以协助评分功能。
本文提出一种全新的注意力打分机制,该机制将多尺度卷积与来自历史步骤的上下文信息结合,将新机制应用于序列到序列的语音识别以及文本到语音系统,实验结果表明新机制具有更好的性能和更高的鲁棒性。
1 序列到序列架构

(1)
式中:Align为注意力机制中的对齐函数;Score表示映射(RM×RN)→R,M表示编码器的隐含单元数量,N表示解码器的隐含单元数量。解码器模块在t时刻根据之前层的输出和上下文信息ct最终通过式(2)生成目标序列。
(2)
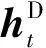
1.1 注意力机制
注意力机制的评分方程产生评分以用来计算源侧与目标侧的相关性,注意力机制可以有点积、双线性乘积和多层感知器(Multi-Layer Perception,MLP)等多种模式。点积评分方程如下:
(3)
(4)
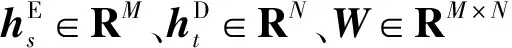
(5)


1.2 序列到序列的自动语音识别
将序列到序列模型应用于自动语音识别(Automatic Speech Recognition, ASR)时,设x是一系列音频特征的序列,例如梅尔频谱滤波器组或者梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient, MFCC)。因此x∈RS×F,其中:F是特征的数量,S是发声的总帧长度。输出y是语音转录序列,其可以是音素序列也可以是字符记录的序列。基于注意力机制的序列到序列的ASR原理如图1所示。
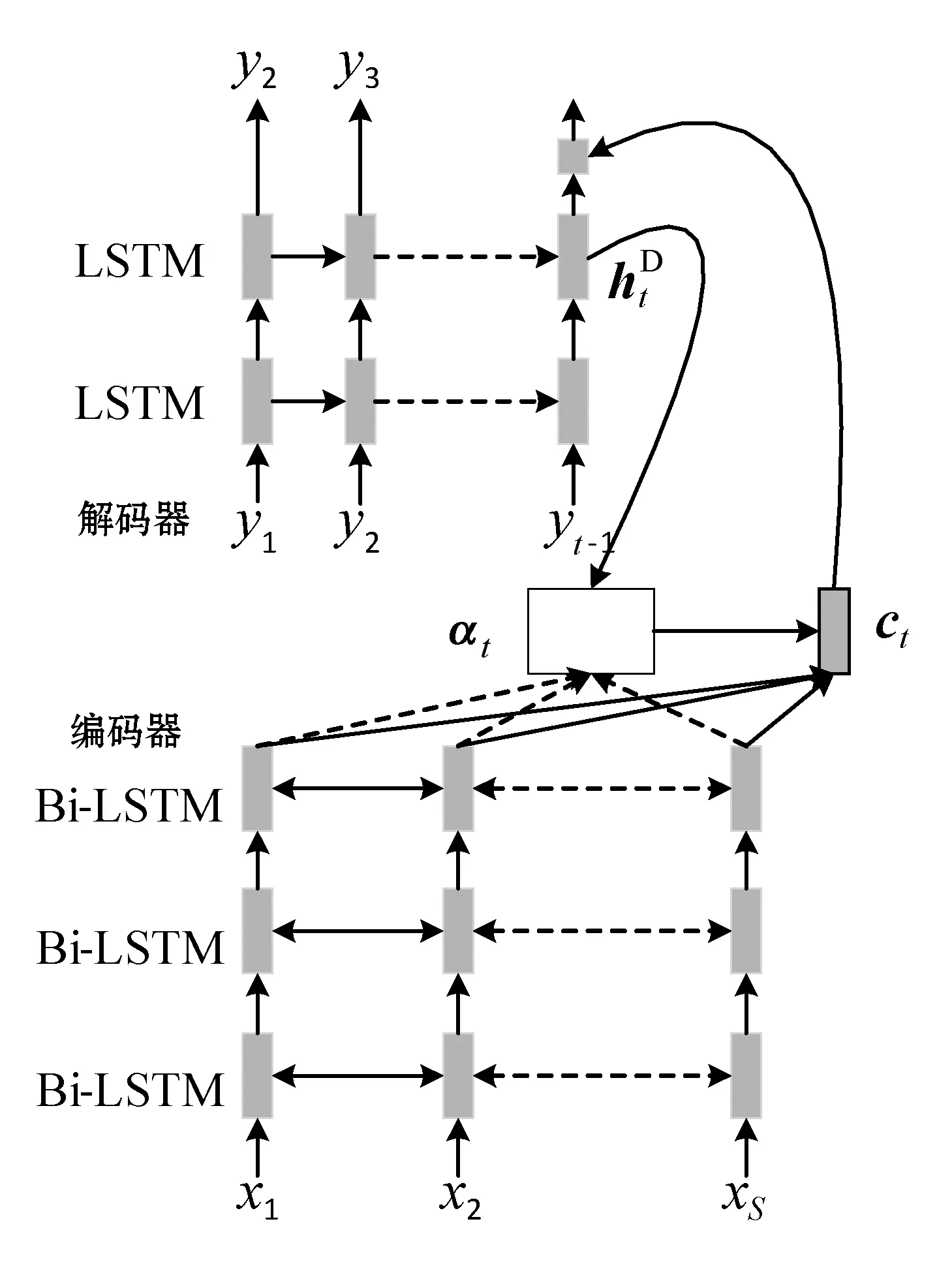
图1 基于注意力机制的序列到序列ASR原理
1.3 序列到序列的语音合成
将序列到序列模型应用于语音合成(Text to Speech, TTS),在训练阶段可以通过最小化如式(6)所示的损失函数来优化模型。
(6)


图2 基于注意力机制的序列到序列TTS原理
2 引入多尺度与历史上下文信息
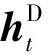
2.1 多尺度对齐信息
为了从语音中抽取出信息,对前序层的注意力向量使用多尺度的1维卷积。与单个的1维卷积相比,这样可以通过不同的核尺寸获得不同的信息。此处输入为从前o步at-o=[at-o[1],at-o[2],…,at-o[S]]得到的归一化的对齐概率。可以有K个不同的1维过滤器集合,分别为F={F1,F2,…,FK}。对于任意FK∈Ri×tk×dk,有一个核尺寸为tk的卷积过滤器、1个输入通道以及dk个输出通道。
通过所有的过滤器F将卷积应用于at-o,并根据最后一个轴也就是输出通道来连接结果,计算过程如下:
(7)
式中:*是用来保证输出序列与输入序列at-o长度相同的卷积运算子;f(·)是非线性激活函数。对于at-o的1维多尺度卷积如图3所示。

图3 对于at-o的1维多尺度卷积
通过对多个时间步骤共享过滤器F将式(7)应用于所有的at-o,at-o+1,…,at-1。然后通过式(8)来融合信息。
(8)


(9)


图4 上下文信息集成
2.2 带有历史对齐和上下文信息的多层感知器
为了将多层对齐的所有信息和上下文的所有信息集成到一个多层感知器中,将式(7)重写为:
(10)

集成了带有历史对齐信息和上下文信息的多层感知器注意力模型的工作过程如算法1所示。
算法1本文提出改进算法
1. Parameters OT: time-step history
2. Procedure Decode(hE∈RS×M)
3.qA=Queue()
//历史对齐队列
4.qC=Queue()
//历史上下文信息队列
5.y=[
6. foriin[0…OT]do
//初始化队列
7.qA.push([1,0,0,…,0]∈RS)
8.qC.push([1,0,0,…,0]∈RM)
9. end for
10. whiley[t]
//eos: end-of-sentence

//式(7)、式(8)

//式(9)
14. forsin[0,S]do
16. end for
//式(1)
18.qA.pop();qC.pop();
19.qA.push(at);qC.push(ct);
20.PY=Softmax(Wct+b)
21.t=t+1
22.y[t]=argmaxcPY[c]
23. end while
24. returny
25. end procedure
3 实 验
3.1 端到端语音识别实验
在端到端语音识别的实验部分,将本文提出的方法应用于WSJ数据集[11]。将WSJ数据集分为两部分,用WSJ-SI284作为训练集,用WSJ-SI84作为验证集,用dev_93和eval_92作为测试集。所有来自言语记录的文本被映射为32个字符的集合,其中包括26个字母、逗号、句号、破折号、空格、噪声和音频终点(End of Speech, EOS)。在每个实验中,从话音中抽取120维的梅尔频谱特征,并将每一维归一化为零均值单位方差。
在编码端,根据LeakyReLU[12]激活方程通过512个隐含单元将输入特征变换为线性层。为了提高运行速度并降低内存开销,在Bi-LSTM[13]的顶部3层采用分层次采样[14]。在解码端,采用128维的嵌入矩阵将输入的字素映射为连续向量。在训练过程,通过最大似然估计来优化模型,并根据式(4)求和。
以多层感知器和当前在端到端语音识别领域效果最好的算法之一light GRU[16]等算法作为参照方法,对比了本文提出模型分别在应用了多尺度聚合、历史上下文信息,以及二者都应用情况下的端到端语音识别的字符错误率(Character Error Rate, CER),各种算法使用了相同的数据集和数据设置,实验结果如表1所示。

表1 端到端语音识别CER对比
与对照方法相比,本文提出模型可以显著提高端到端话音识别的准确率,特别是多尺度与上下文两种改进策略同时使用时,字符错误率将低至6%以内,这是其他方法难以实现的。
3.2 文本转语音实验
在文本转语音实验部分,采用LJSpeech数据集[15],其中94%的数据作为训练数据,3%的数据作为测试数据。为了提取特征,用50 ms的时间窗口做对数线性频谱采样,并做2014点位的短时傅里叶变换,然后抽取80维的对数梅尔频谱特征。
为了验证本文提出方法的有效性,测试了本文方法和对照方法生成的语音的单词错误率(Words Error Rate, WER),实验结果如表2所示。

表2 文本转语音WER对比
在文本转语音实验中,依然采用了基本多层感知器模型、多层感知器模型+Location Aware以及lightGKU作为对照方法。表2结果说明在文本转语音方面,本文方法具有理想的性能,特别是同时应用多尺度聚合与上下文信息两方面改进时,转换的单词错误率可达到4%以内,明显优于对比方法。
为了验证本文方法的有效性,进一步对比了在文本转语音领域,各种方法在相同数据规模条件下的时间开销。实验结果如表3所示。

表3 文本转语音时间开销 s
可以看出,当测试数据分别为总数据集大小的25%、50%和75%时,本文方法在三种模式下的时间开销仅次于基本MLP方法,优于其他两种对比方法,并且随着数据规模的增长,本文方法的时间开销增长比较平缓,具有较好的时间性能。
4 结 语
语音数据处理是近年来人工智能与机器学习领域的热点研究问题,其研究成果在互联网经济产业的各个方向有旺盛的应用需求。本文在经典序列到序列模型的基础上,引入了增加多尺度与历史上下文信息的注意力模型,通过多尺度实现深度神经网络多层次信息的卷积,通过历史上下文信息提高特征选择的针对性,从而提高了传统模型的性能。实验结果表明,无论是应用于端到端话音识别还是文本转语音,本文提出方法都有理想的性能,具有相关领域的应用价值。
在语音处理领域,梅尔频率倒谱系数提取的时间开销成为大规模实时在线应用的瓶颈,为了解决这一问题,相关学者提出了一些改进措施,如何将本文模型与这些改进措施相结合,使本文方法具有更优的实时性,将是这一领域有意义的研究。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09 18:39:41
传感器与微系统(2021年7期)2021-07-15 12:08:44
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06 09:08:52
中国矿业(2019年7期)2019-07-26 05:37:30
环球时报(2019-04-26)2019-04-26 06:17:15
发明与创新·中学生(2019年2期)2019-02-26 12:39:22
传媒评论(2017年3期)2017-06-13 09:18:10
第二课堂(课外活动版)(2016年2期)2016-10-21 16:58:54
太空探索(2016年5期)2016-07-12 15:17:55
时代英语·高三(2014年5期)2014-08-26 17:01:17
