
基于双向长短时记忆网络的系统异常检测方法
2020-12-14 10:22张林栋刘培玉
计算机应用与软件 2020年12期
张林栋 鲁 燃 刘培玉
(山东师范大学信息科学与工程学院 山东 济南 250014)(山东省分布式计算机软件新技术重点实验室 山东 济南 250014)
0 引 言
系统日志异常检测是计算机系统必不可少的任务。系统日志记录了系统状态和不同临界点上的事件,可以用来帮助技术人员调试机器性能和检测系统故障等问题,也是检测系统是否异常的重要数据。系统日志异常检测最早开始于人工检测,但是人工检测仅限于日志数据较少的环境,很难应用于大数据的环境下。
Xu等[1]提出了一种统计分析的方法,捕获单一类型消息的发生频率来进行异常检测,但是异常行为通常由复杂的若干个软件组成,只进行单一类型的异常检测是远远不够的。Yamanishi等[2]提出了一种基于机器学习的方法来检测日志消息之间的相关性,解决了基于统计分析方法中不能对复杂系统异常检测的问题。但是随着系统的变化,该方法并不能很好地适应新的日志模式。因此越来越多的学者开始利用神经网络进行系统异常检测。
Brown等[3]运用自然语言处理的知识,提出了一种基于递归神经网络(RNN)语言模型,将注意力机制纳入到RNN语言模型中。但是RNN所能存取的上下文信息范围有限,由于其本身的激活函数,在模型训练过程中会产生梯度消失和爆炸的问题,使得隐藏层的输入对于网络输出的影响随着网络环路的不断递归而衰退。为了克服RNN的缺点,Du等[4]提出了一种基于深度学习的系统日志异常检测框架Deeplog,利用长短时记忆网络(LSTM)对系统日志进行异常检测。与基于机器学习的方法[5-7]相比,该方法克服了RNN网络的不足,而且具有很高的准确率,但是由于LSTM网络的结构特性,在进行异常检测时只考虑了日志的前序事件对当前事件的影响而忽略了后序事件对当前事件的影响,使得结果很难具有说服性。
因此,本文提出基于双向长短时记忆网络的日志路径异常检测模型。该模型有效地弥补了LSTM的不足,充分考虑前后事件对当前事件的影响。与之前的方法相比,该模型在HDFS和OpenStack数据集上准确率和F-measure都有显著的提高。
1 相关工作
1.1 递归神经网络(RNN)
RNN[8]是最早应用在时序序列预测的算法之一,是唯一具有内部存储器的神经网络算法,能够广泛地适用于时间序列、语音、文本、财务数据、音频、视频、天气等时序数据的处理。
RNN具有独特的循环机制,因此能够在输入和输出序列之间的映射过程中充分利用上下文相关信息,综合考虑前序事件和后序事件对当前事件的影响。在RNN中,信息只在一个方向上移动。当它作出决定时,会考虑当前的输入以及它从之前收到的输入获得想要的内容。但是RNN也存在着显著的缺点,在训练时会产生梯度爆炸等问题,并且RNN所能存取的上下文信息范围非常有限,使得隐藏层的输入对于网络输出的影响随着网络环路的不断递归而衰退。
1.2 长短时记忆网络(LSTM)


图1 LSTM框架图
1.3 双向长短时记忆网络(Bi-LSTM)
双向长短时记忆网络(Bi-LSTM)[10]模型如图2所示,由前向传播和后向传播的LSTM网络组成。该网络结合了RNN和LSTM的优点,既克服了RNN衰退的问题,又能够利用LSTM网络的优势,通过前向推算和后向推算,有效地结合前后事件对当前事件的影响。

图2 Bi-LSTM网络模型
2 模型构建
2.1 异常检测框架
日志路径异常检测的框架如图3所示。首先把正常执行的日志文件通过日志解析器提取出对应的日志键,并将一系列日志键建模成为一个时间序列。其次通过Bi-LSTM模型进行训练,使模型充分学习日志键序列执行模式。在进行检测时,将新的日志文件使用日志解析器构造日志键序列,通过Bi-LSTM模型进行检测。若未发现异常则模型将序列标记为正常;若检测出异常,则将根据用户的反馈来判断是否发生误判。如果发生误判则通过在线更新优化模型参数的机制,再次通过模型进行异常检测;如果没有发生误判,模型将输出日志序列标记为异常。
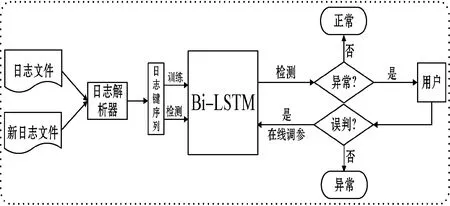
图3 日志路径异常检测框架图
2.2 日志解析器
日志解析器[11-13]的目的是将结构不统一的日志数据进行归一化处理。通过解析日志文件提取日志键构造时序序列的方法,将不同结构的日志数据转化为具有相同格式时序化日志键序列。首先逐行读取日志数据,每个日志行都使用一个简单的正则表达式进行预处理。其次提取该日志的关键特征构造成一个日志键,并将每行解析的日志键构建成一个时序序列。例如,一个日志条目为“Adding an already existing block(10)”,则可以用一个日志键k1来代替它,即k1=Adding an already existing block(.*)。其中日志键中参数被抽象为*号。如表1所示,通过日志解析器的日志文件将被解析为一个时序序列,例如{k1,k2,…}。

表1 日志解析实例
2.3 日志路径异常检测
将通过日志解析器获得的日志键序列进行系统日志异常检测。假设K={k1,k2,…,kn}是一个日志块所转换的日志键序列,每一个日志键代表某一时刻日志执行的路径命令,整个日志键序列反映了日志的顺序执行路径。对整个序列进行检测,需要依次检测每个日志键是否为异常。令ki为K序列n个中的某一个,代表着即将检测的日志键。
如图3所示,采用Bi-LSTM网络来进行系统日志异常检测,该网络由前向LSTM和反向LSTM网络组成,充分考虑了后序事件对前序事件的影响。输入是几个连续的日志键,输出是下一个日志键ki的概率。ki的概率由前向传播和反向传播得到的概率共同决定的。前向或反向传播都由一层LSTM网络组成。每一块LSTM都有隐藏状态ht-i和细胞状态Ct-i,两者都被传递到下一个块以初始化其状态。目的是通过模型得出当前日志键ki的概率,然后设定一个概率界限(参数g)来判断当前日志键是否发生了异常。通过各个门控的计算最终得出ki的条件概率,与通过训练得出的g进行比较,把低于g的日志键标记为异常。
其前向传播推算的公式为:
输入门:
(1)
(2)
遗忘门:
(3)
(4)
输出门:
(5)
(6)

反向传播推算的公式为:
输入门:

(7)
遗忘门:

(8)
输出门:

(9)
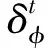
训练阶段:在训练阶段中使用正常执行的日志条目作为数据集来训练模型,目的是让模型充分学习到系统日志正常的执行模式,尽可能避免出现误判的情形。通过日志解析器得到一个日志键序列,然后给定一个窗口大小h,将日志键按窗口的大小、执行顺序组合成一个时序序列,该序列记为w,例如w={ki-h,ki-h+1,…,ki-1},将w输入到模型Bi-LSTM网络中。例如,假设一个日志键序列为{k11,k23,k5,k9,k12,k25,k3}。给定窗口大小h=4,则用于训练模型的输入序列和输出标签为:{k11,k23,k5,k9→k12},{k23,k5,k9,k12→k25},{k5,k9,k12,k25→k3}。通过Bi-LSTM模型得出下一日志键ki的条件概率,根据ki概率分布的范围,设置g的参数大小。
检测阶段:基本方法跟训练阶段相同,对于新加入的日志条目首先通过日志解析器构造成日志键序列w。将w输入到Bi-LSTM模型中得出当前日志键的条件概率,通过与设置的参数g进行对比,把高于设置的g值的ki标记为正常;若得到的ki概率值低于g值,那么模型将把该结果反馈给用户,用户判断是否发生了误判,如果发生了误判,则通过在线更新机制调整模型参数,将得出的日志键与实际的日志键设为相同的概率,如果没有发生误判则直接将该序列标记为异常。
异常检测模型如图4所示。为了检测一个新的日志键ki是正常还是异常的,把窗口大小为h的日志键序列w作为输入,输出是给定输入日志键序列的下一个日志键ki的条件概率。通过将得出的条件概率Pr与参数g进行比较,判断日志执行路径是否发生了异常。

图4 异常检测模型图
语言模型:把日志执行路径作为时序序列处理,其原理是应用自然语言处理的语言模型。在训练模型时,把每个日志键都可以看作是从词汇表K中提取的一个单词,应用自然语言处理的语言模型来计算该词出现的概率,从而判断系统是否发生异常。近年来,使用神经网络的神经概率语言模型(NPLM)[14]已被证明在自然语言处理任务中非常有效。因此在Bi-LSTM中使用了NPLM语言模型来对日志键序列进行异常检测。NPLM语言模型沿用了传统的N-gram模型[15]中的思路,认为目标词wt的条件概率与其之前的n-1个词有关。但与N-gram模型区别是在计算P(wt|w1,w2,…,wt-1)时,其使用了机器学习的方法,很好地解决了给定一个日志键序列如何最大化地计算日志键ki概率的问题。NPLM语言模型的计算公式为:
p(w|context(w))=k(iw,Vcontext)
(10)
式中:k表示神经网络;iw为w在词汇表中的序号;context(w)为w的上下文;Vcontext为上下文构成的特征向量。
2.4 在线更新机制
如何保证检测模型的时效性、如何解决日志新的执行模式等,是系统异常检测必须要解决的问题,因此在模型中加入了用户反馈在线更新的机制。随着工作量以及工作方式的变化,用户可以在线优化模型的参数。例如:检测时可能会出现误报的情况,假设一个窗口大小h=4日志键序列为{k22,k16,k5,k6},已知训练后,模型已经将概率为1的下一个日志键预测是k7,而实际序列中的日志键是k3,那么模型将把k3标记为异常。如果用户反馈这是误报(实际情况下k7和k3都是正常的日志键),模型就可以根据用户的反馈优化新的权重来学习这个新序列。当再次输入该序列时,检测到的k7和k3都将会得到相同的概率且被标记为正常。
3 实 验
3.1 传统异常检测方法
主成分分析法(PCA)[16]是一种基于降维的统计方法。在进行异常检测的时候,PCA根据每个日志事件的标识符进行分组,然后记录每组中每个日志事件出现的次数。PCA的基本思想是将高维数据投影到由k个维度组成的新坐标系中,通过测量坐标系的子空间上的投影长度来检测异常。因此,PCA可以保留原始高维数据的主要特征。
Xu等[17]首先将PCA应用在的异常检测中。在Xu等的方法中,每个日志序列被转化为日志事件的计数向量,使用PCA构造成两个子空间,正常空间Sn和Sm异常空间。然后,计算事件计数向量y到Sm的投影,如果超过阈值,则对应的日志事件将被标记为异常。
Lou等[18]最先将不变量挖掘(IM)的方法应用到系统日志异常检测中。IM根据日志参数之间的关系将日志消息进行分组,从日志消息组中自动地获取程序不变量。程序不变量在系统运行期间始终保持线性关系,其输入是从日志序列生成的事件计数矩阵,其中每一行是事件计数向量。首先,使用奇异值分解来估计不变空间的不变量r;其次,通过强力搜索算法找出不变量;最后,通过与设定的阈值进行比较来验证挖掘的不变量。重复执行以上步骤,直至获得r个独立不变量。在检测时,对新的日志序列进行判断是否符合不变量,如果至少有一个不符合,则日志序列将被报告为异常。
3.2 数据集
实验采用系统日志异常检测中通用的权威数据集,一是Xu等[17]所公开的HDFS日志数据集,另一个是Du等[4]在Deeplog中公开的OpenStack数据集。
HDFS数据集是基于PCA的主要数据集,并在在线PCA和基于IM的异常检测方法中广泛应用。该数据集包含了11 197 954个日志条目,其中约3%是异常的。通过标识符字段将日志条目分组到不同会话中,HDFS的标识符为block_id,每组会话对应着一个日志块。
OpenStack数据集包含1 333 318个日志条目,约7%是异常的。主要的进程包括VM的创建/删除、停止/启动、暂停/恢复等。OpenStack数据集的标识符为instance_id。分别将每个日志条目通过解析器转化为日志键,然后通过Bi-LSTM网络来训练其权重,进行异常检测。
3.3 实验评估标准
为了评估模型的有效性,本文采用Precision(召回率)、Recall(准确率)和F-measure作为评价标准。Precision为所有检测到的异常与真正异常的百分比[19]。Recall反映了被正确判定的正常样本占总的正常样本的百分比。设置参数g决定了得到下一日志键概率判断为异常的最低概率值。F-measure的值同时受到Precision、Recall的影响。设置默认输入窗口h的大小为10,一个LSTM网络块的存储单元α的个数为64。为了检测模型的性能,做了三组对比实验:首先比较该模型与之前的基于机器学习的方法的性能;其次通过调整参数g、h、α、Pr的大小来对模型参数进行实验分析;最后进行模型有在线更新机制与无在线更新机制的对比实验。
(11)
(12)
(13)
式中:TP为将正常样本预测为正常类数;FN为将正常样本预测为异常类数;FP为将异常样本预测为正常类数;TN为将异常样本预测为异常类数。
表2为HDFS数据上每种方法的假阳性和假阴性的数目。PCA实现了最少的假阳性,但是具有很高的假阴性。IM假阳性和假阴性都很高;Bi-LSTM的假阴性和假阳性都具有较低的水平。

表2 HDFS数据集FP和FN的数量
3.4 结果分析
3.4.1方法对比分析
图5和图6分别为HDFS和OpenStack数据集上不同方法对比实验结果。虽然传统的PCA在HDFS数据集上的准确率为0.98,但是F-measure值仅有0.79,OpenStack数据集上也并未表现出突出的性能。而IM尽管在HDFS数据集上表现出良好的性能,而在OpenStack数据集上准确率和F-measure分别为0.02和0.04。由此可以得出:传统的基于机器学习的检测方法并不具有很好的适用性,不能有效地应用到不同系统之间的异常检测。使用LSTM的检测方法的Deeplog模型准确率和F-measure都高达0.95以上。基于Bi-LSTM的方法在两个数据集上都表现出良好的性能,准确率和F-measure分别为0.98和0.98。这是由于Bi-LSTM综合考虑前后事件对当前事件的影响,因此实验结果高于Deeplog模型。通过对比实验可以得出:Bi-LSTM模型不仅能够适用于随机生成的数据集而且在大规模的数据上也表现出优越的性能,能够适用于不同系统日志路径的异常检测。

图5 HDFS数据集性能对比结果图

图6 OpenStack数据集性能对比结果图
3.4.2Bi-LSTM模型参数分析
通过调整Bi-LSTM网络中各种参数来测试模型的性能,其中调整的参数包括:g,h,α,Pr。在每个实验中只改变一个参数的值,其余参数保持默认值。图7为改变参数α,其他参数不变的情况下的模型性能随着LSTM单元个数的变化趋势,实验表明当内存单元数为192时,模型的准确率和F-measure都明显优于其他内存单元数。图8反映了改变参数g后模型的性能变化,当设置的g阈值偏低时,虽然模型具有很高的准确率但是其F-measure却很低。图9为改变参数h模型的性能变化,由于LSTM网络需要长依赖性,所以当选择的窗口越大时,其表现的性能越明显。图10反映了改变参数Pr后模型的性能变化,Pr的大小决定着前向推算和后向推算各自对预测的概率所占的比重。综合所有的实验结果,发现Bi-LSTM网络的性能在调整各个参数时表现得非常稳定,单一改变参数或者是组合调整对模型的性能影响不大。
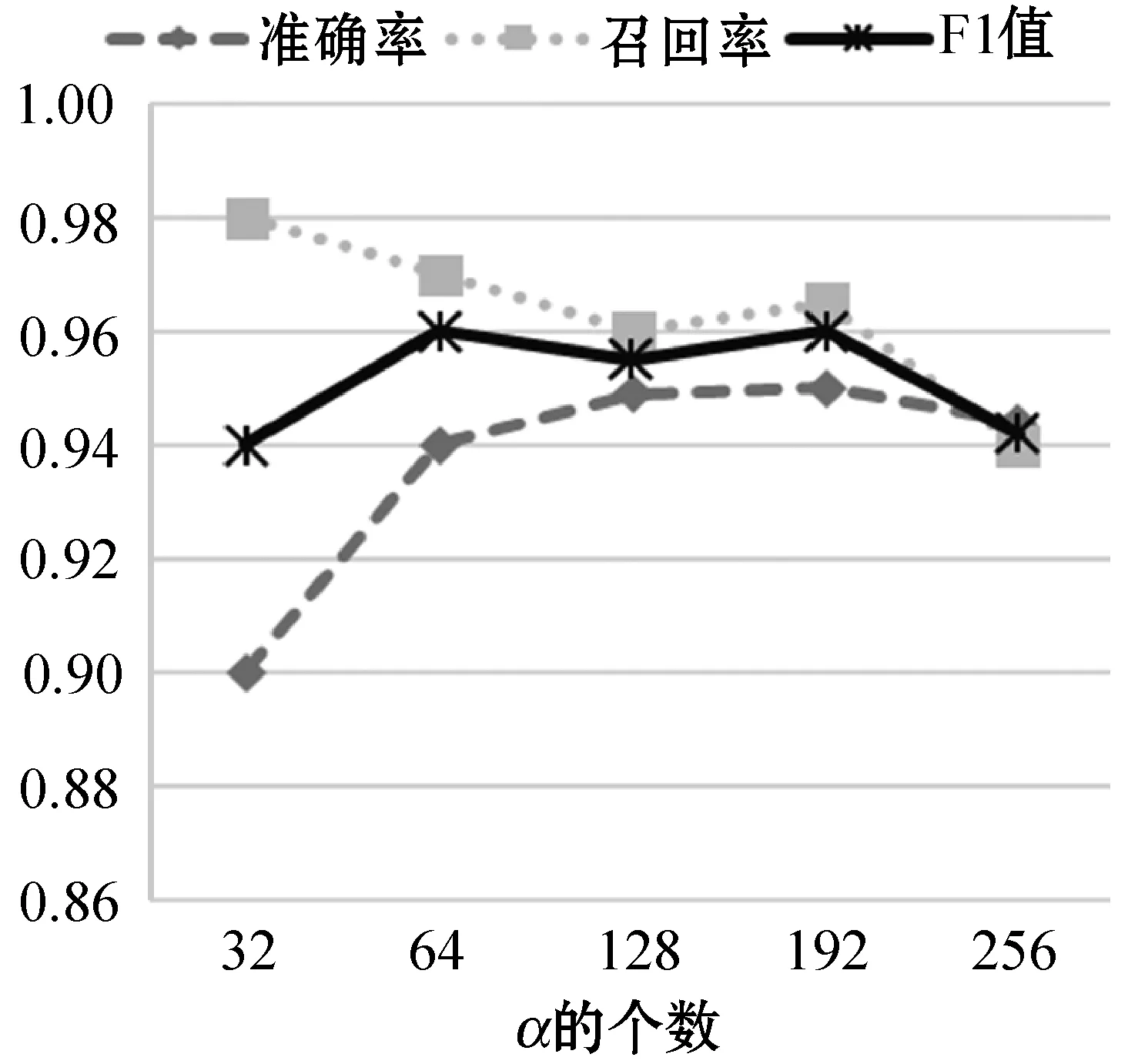
图7 改变参数α性能对比结果图
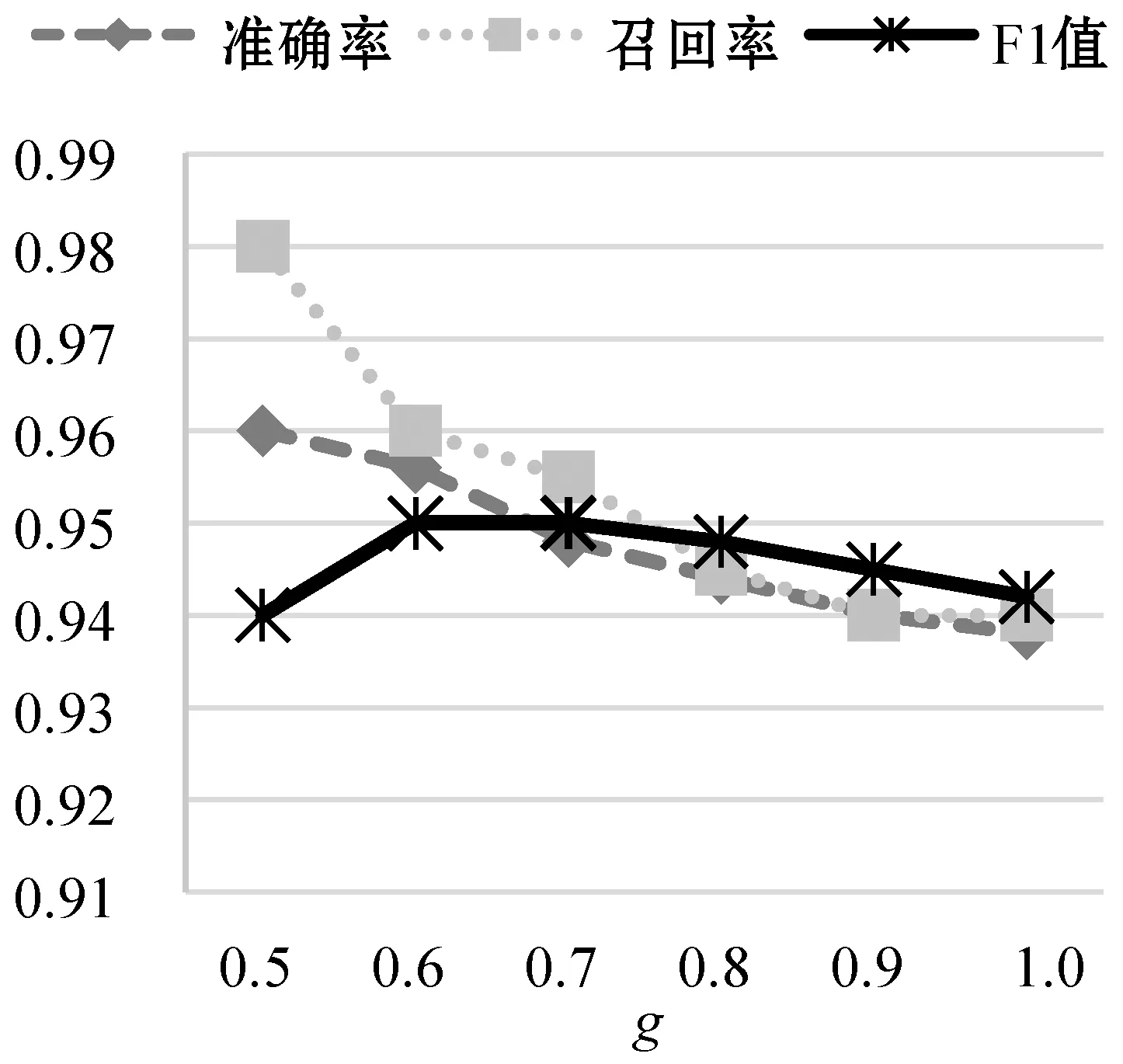
图8 改变参数g性能对比结果图
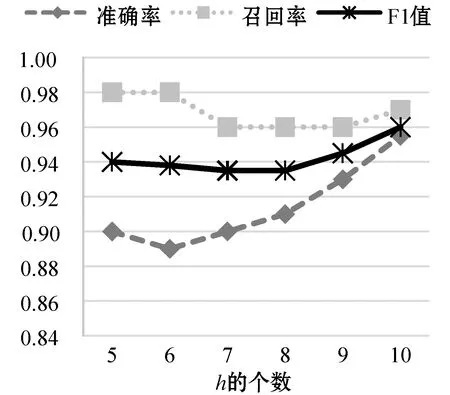
图9 改变参数h性能对比结果图

图10 改变参数Pr性能对比结果图
3.4.3在线更新对模型性能的分析
在HDFS和OpenStack两个数据集中,许多日志键仅在特定时间段内出现,因此训练数据集可能不包含所有正常日志键,具有很好的未知性。首先,用数据集的前10%作为训练数据,其余的作为测试数据。然后,设置各个参数α=64、g=0.8、h=10、Pr=0.5,并保证参数不改变。对于有在线更新的模型,假设有用户报告检测到的异常为误报,Bi-LSTM使用该标记来更新其模型以学习这种新模式。图11是模型在HDFS数据集下的性能,无在线更新的模型准确率仅为0.30,F-measure为0.46,而有在线更新的模型准确率和F-measure分别为0.90和0.95。图12是模型在OpenStack数据集下的性能,无在线更新的模型准确率仅为0.35,F-measure为0.52,而有在线更新的模型准确率和F-measure分别为0.93和0.96。结果表明,有在线更新的异常检测模型在准确率和F-measure都明显高于无在线更新模型,在线更新的机制可以提高模型在检测新执行模式时的性能。

图11 HDFS数据集有无在线更新性能比较图

图12 OpenStack数据集有无在线更新性能比较图
4 结 语
本文提出一种基于双向长短时记忆网络的系统异常检测模型。首先在每个日志条目的级别上,通过日志解析器实现从日志文件中分离出不同类别的任务,从而构成时序化的日志键序列,有效地解决传统异常检测方法中日志结构不统一的问题。其次使用双向长短时记忆网络对时序化的日志序列进行建模和预测,并且增加在线更新优化模型参数的机制,提高模型检测新执行模式的性能。实验结果表明,与传统的基于机器学习异常检测的方法相比,本文模型在HDFS和OpenStack数据集上准确率分别提升了0.11和0.2,召回率提升了0.29,F-measure分别提升了0.19和0.11。基于双向长短时记忆网络的系统异常检测模型在系统日志异常检测上具有显著的性能,对系统异常检测和优化模型参数等方面具有重要的意义。
在未来工作中,将改进模型使其不仅能适用于系统日志执行模式的异常检测,还能够对日志中的各个参数进行异常检测。同时改进模型的输出最大化概率的最优路径来提升模型的效率。
猜你喜欢
今日农业(2022年14期)2022-09-15
华人时刊(2021年13期)2021-11-27
纺织科技进展(2021年5期)2021-07-22
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
心声歌刊(2020年4期)2020-09-07
家庭影院技术(2019年8期)2019-08-27
思维与智慧·上半月(2018年10期)2018-11-30
