
基于贝叶斯网的跨领域情感分析方法
2020-12-14 10:22刘慧清郭延哺李维华
计算机应用与软件 2020年12期
刘慧清 郭延哺 李维华
(云南大学信息学院 云南 昆明 650500)
0 引 言
随着社会化媒体和社交网络的迅速发展,越来越多的人在各种网页及应用上发表和分享自己的观点和看法,产生了大量的文本信息。这些观点和看法往往潜在地表达了他们的情感或者情绪,如何从这些海量的评论数据中挖掘出用户的情感信息,分析出用户的情感倾向成为近年来自然语言处理和数据挖掘领域的一个研究热点[1-2]。
情感分析,又称情感分类或意见挖掘,就是基于人们发表的文本分析人们的意见、情绪、态度、情感[3-4]。基于机器学习的情感分析方法依赖于大量的高质量标签样本,而人工标注样本的方式显然不能完全满足情感分析的需求。文本情感表达与描述的对象或者语义概念(领域)密切相关,不同领域的情感描述有着明显的差别,且数据特征分布也不同,直接使用其他领域训练的情感分类器进行情感分析就存在适应性不佳的问题。因此,利用带标签的源领域提高情感分类器在目标领域适应性的跨领域情感分析成为新的研究关注点[5-7]。
跨领域情感分析是迁移学习的一个重要研究方向,迁移学习是从源任务中提取知识,并将其运用在目标任务中的一种新机器学习方法[8]。跨领域情感分析领域常用到的迁移方法有:基于特征空间的迁移方法,基于实例的迁移方法。前者包括基于特征选择和特征映射两类。基于特征选择的跨领域情感迁移方法是通过一些策略寻找源领域和目标领域间的共享特征,然后利用这些特征进行知识迁移。贾熹滨等[9]借助已有的情感词典和改进的互信息技术对领域间无歧义的共享特征进行选择,然后通过句法分析和关联规则算法提取领域间专有特征词进行词典扩展和领域间信息分布对齐。李鼎宇等[10]通过谱聚类选择领域间相似的特征词进行特征扩展来提升情感分类效果。基于特征映射的跨领域情感迁移方法是把各个领域的特征映射到一个统一的特征表示空间中,建立各个域特征之间的关联,从而减少领域信息分布的差异。SCL(Structural Correspondence Learning)方法[7]、SFA(Spectral Feature Alignment)方法[11]是基于该方法的典型代表。它们利用领域间枢纽特征,通过特征变换将源领域和目标领域特征映射到同一个空间,达到缩小领域间语义距离的目的。特征映射与特征选择的区别在于,这些映射得到的特征不在原始的特征当中,是全新的特征。基于实例的跨领域情感迁移方法主要从源领域已标记数据中选取那些对目标领域分类有价值的实例,用于辅助目标领域情感分类。例如:廖祥文等[12]通过选取高质量的样例对训练集进行扩充,以减少领域间的特征分布差异;赵传君等[13]将源领域带标签数据等量分割,并分别与目标领域带标签数据组合,训练多个分类器来提升跨领域分类精度。
随着深度学习逐渐成为自然语言处理领域研究热点,利用深度学习的方法解决情感分析问题的技术飞速发展[14],基于深度学习的方法主要利用深度神经网络的学习能力和词向量在语法和语义上同时表达的优点。例如:Bollegala等[15]通过嵌入学习方法构造三个目标函数来对领域特征进行建模;Zhao等[16]提出一个两阶段双向长短时记忆(Bi-LSTM)和参数传输框架,通过使用少量的目标领域训练样本共享Bi-LSTM网络的底层参数并重新训练高层参数,将其用于短文本跨领域情感分类任务中;Li等[17]提出一种端到端对抗记忆网络(AMN),构建两个参数共享记忆网络分别用于情感分类和领域分类。然而,基于深度学习的方法往往依赖于大量的标签样本,而且已有的方法并没有充分考虑到领域间的差异。
贝叶斯网(Bayesian Network,BN)[18]是每个节点都有一张概率表(也称参数)的有向无环图(Directed Acyclic Graph,DAG),可以直观地表示节点间的定量依赖关系,并为这些依赖关系提供有效的推理方法。贝叶斯网是不确定知识表示和推理最有效的模型之一,已经成功应用于预测[19]、决策[20]、可视化分析[21]等问题中。此外,贝叶斯网还提供多种灵活的学习方法[22],既可以从大数据样本中学习BN,也可以根据专家知识构建BN,这不仅可以为多源、甚至异构的数据源提供统一的表示形式,也为跨领域情感分析中领域间情感知识的建模和迁移提供基础。
本文从跨领域情感分析所面临的困难出发,利用贝叶斯网在知识表示和推理方面的优势,结合知识迁移,提出一种基于贝叶斯网的跨领域情感分析方法。基于特征词之间的相似度来确定特征词的依赖关系,对源领域和目标领域建立基于贝叶斯网的特征模型,并设计特征模型的融合规则,对局部模型进行融合,得到全局特征模型,让源和目标域特征表示在一个统一的特征空间中,建立各个域特征之间的关联。在此基础上,利用BN推理建立情感特征的迁移方法,在新的特征空间中实现源和目标领域的情感知识迁移,以减小领域间的特征分布差异,提升分类效果。
1 问题和基本框架
文本情感表达和描述的对象或者语义概念(领域)密切相关,不同领域的情感描述有着明显的差别。
表1是一个关于电子领域和书籍领域的评论样本集,其中每个域都有积极(+)和消极(-)两种情感。在电子领域中,excellent、high pixel、high-resolution、run fast表达积极情绪,blurred sound、high noise、horrible表达消极情绪。在书籍领域,excellent、printed well表达积极情绪,horrible、waste表达消极情绪。

表1 电子和书籍领域的情感评论
可以看出,excellent、horrible都出现在两个领域中,但high resolution、run fast很少出现在书籍领域,printed well很少出现在电子产品领域。所以,直接使用电子领域训练的情感分类器,对书籍领域评论进行情感预测就存在适应性不佳的问题。此外,专有词high resolution和共有词excellent可能存在共现关系,这表明领域间共有的词汇往往是连接两个领域的桥梁。
针对情感分类器存在的领域适应性,以及目标领域缺少标签样本的问题,本文提出一种基于贝叶斯网的跨领域情感分析方法。该方法充分利用贝叶斯网在知识表示和推理方面优势,为源领域和目标领域建立一个统一的框架,将目标领域的情感知识迁移到源领域中,达到提高分类器在目标领域中适应性的目的。
基于贝叶斯网的跨领域情感分析的基本框架如图1所示,该方法主要包括四个模块:局部模块,融合模块,迁移模块和预测模块。局部模块就是在特征提取的基础上,定量度量特征词之间的依赖关系,构建源和目标的局部特征模型。融合模块基于局部特征模型,从结构和参数两方面构建全局特征模型。迁移模块基于全局特征模型,通过特征扩展进行领域间情感知识的迁移。预测模块基于扩展后的特征空间训练分类器,完成目标领域的情感预测。

图1 基本框架
2 局部特征模型
局部特征模型就是基于贝叶斯网定量度量源和目标领域特征之间的依赖,为进一步的模型融合和特征扩展提供支持。
2.1 特征模型定义
贝叶斯网是一个二元组(G,P),G是一个有向无环图,每个节点表示一个变量,有向边表示变量之间的直接依赖关系;P是贝叶斯网的参数,每个节点u包含一个该节点在其父节点pa(u)条件下的条件概率表。下面给出特征模型的定义。
定义1文本集D的特征词为W={u1,u2,…,um},D上构建的特征模型是满足下面条件的(G,P):
(1)G=(U,E)是一个有向无环图,U为图中的节点,每个节点表示W中的一个特征词,且取值空间为{0,1},分别表示特征词不出现和出现,E表示节点之间的有向边集合,若存在有向边(u,v),则称u是v的父节点。
(2)P={p(u|pa(u))|u∈U}表示特征模型的参数,p(u|pa(u))表示每个节点u在其父节点pa(u)条件下的条件概率表。
在特征模型中,节点和特征是一一对应的,因此本文后续的描述中不再区分节点和特征。
2.2 局部特征模型构建
根据特征模型的定义,分别对源领域和目标领域构建局部特征模型的DAG和参数。
源领域特征模型的节点为US={us1,us2,…,usp},目标领域特征模型的节点为UT={ut1,ut2,…,utq};分两步确定特征模型的DAG,首先确定特征词之间是否有边,再确定边的方向。
用相似度来度量特征词之间是否有边。考虑到两个特征的点互信息越大则它们越相关,所以两个特征词u和v之间的相似程度计算式表示为:
(1)
式中:p(·)=c(·)/N是特征词的联合概率函数,c(·)为文档频度,N为文本数;p(u=1,v=1)表示u、v都出现的联合概率。
如果I(u,v)>ω,则u和v之间存在一条边,否则节点u和v之间不存在边,其中ω是相似阈值。
节点顺序可以简化方向的确定[22],并减少模型融合的冲突。本文在UT∩US的节点之间定义一个优先顺序,在UT∩US优先于其他节点的条件下,对任意u∈US∩UT,f(u)=g(fS(u)+fT(u)),且fS(u)和fT(u)分别是源领域和目标领域的IDF值。在有序的条件下,如果两个节点u和v之间有边,且u优于v,则该边的方向是u指向v,反之为v指向u。
得到特征模型的结构之后,通过样本集中特征词的频度c(u,pa(u))和c(pa(u))估计每个节点的条件概率表p(u|pa(u))=c(u,pa(u))/c(pa(u))。
3 全局特征模型
利用贝叶斯网可以有效地进行知识表示和推理的优点,通过领域特征模型融合、构建全局特征模型,将所有特征词之间依赖关系表示在一个知识网络中,并利用贝叶斯网的推理将这些知识结合进行特征扩展,为缩小领域间的差异提供有效的支持。
3.1 模型构建
针对特征模型的特点,本文分别对模型的结构和参数进行融合,构建U=US∪UT上的全局特征模型。节点序简化了BN的融合方法[23],算法1描述全局特征模型结构的构建方法。
算法1全局结构的构建
输入:局部特征模型的结构GS=(US,ES)和GT=(UT,ET)。
输出:全局模型的结构G。
1.U=US∪UT;
2. for each pairu,v∈U-UT∩USdo
if(u,v)∈ES∨ETthen(u,v)∈E
else if(v,u)∈ES∨ETthen(v,u)∈E;
3. for each pairu,v∈UT∩USdo
if(u,v)∈ES∧ETthen(u,v)∈E
else if(v,u)∈ES∧ETthen(v,u)∈E;
4. return(U,E)
例1设源领域和目标领域的特征模型结构分别如图2所示,其节点集分别为US={u1,u2,u3,u4}和UT={u1,u2,u3,u5,u6}。按照算法1中步骤2,E={(u2,u4),(u3,u4),(u1,u5),(u1,u6),(u2,u5)};按照算法1中步骤3,E=E∪{(u1,u3),(u2,u3)}。最后得到图3所示的全局特征模型结构。
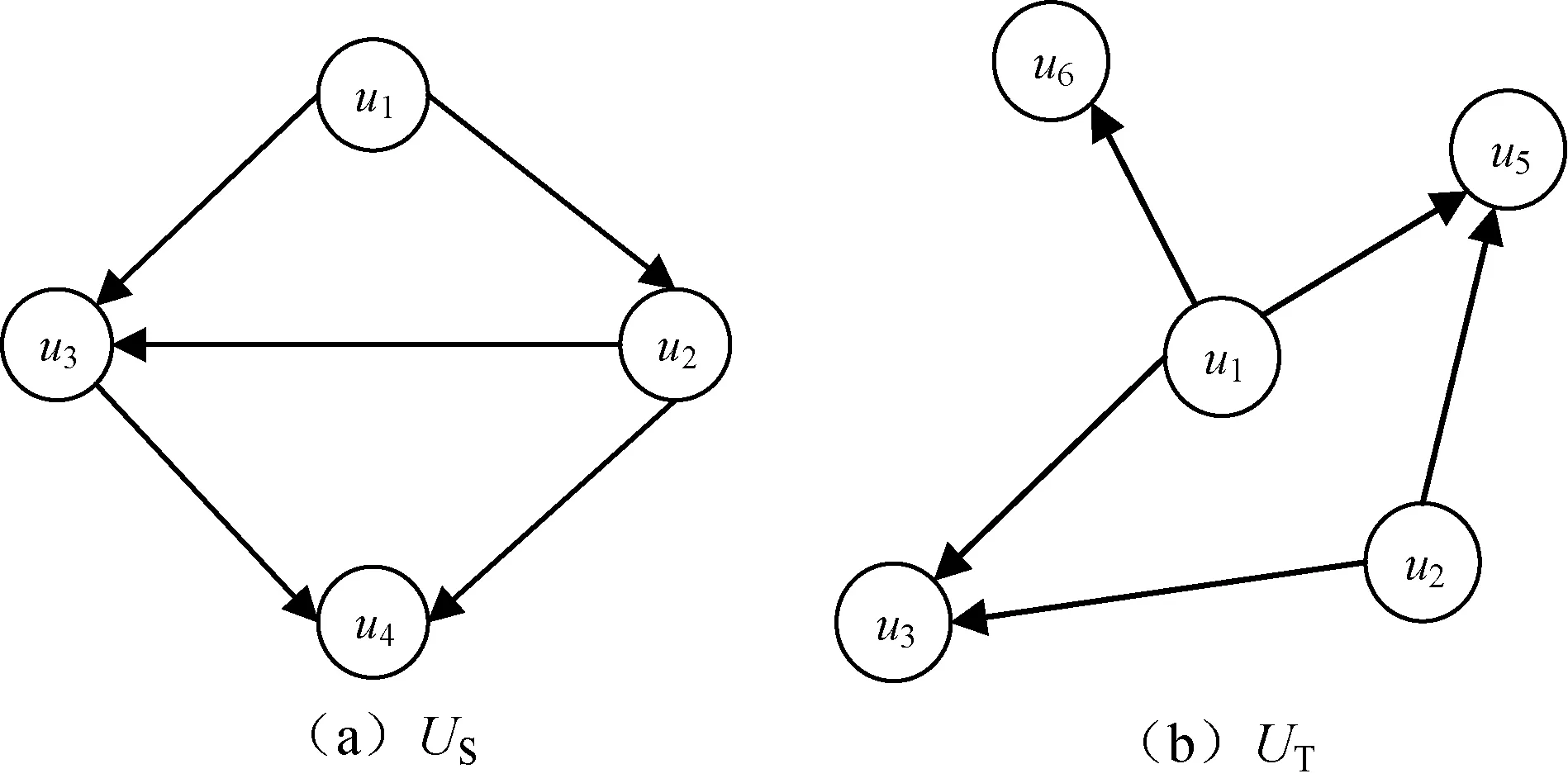
图2 源域与目标领域特征模型结构

图3 全局特征模型结构
算法1在进行结构融合的过程中,只会在公共节点的父节点发生改变,且变化后的父节点是该公共节点在局部模型上父节点的交集,定理1说明了该事实。
定理1设G、GS和GT是结点集U、US和UT上的三个有向无环图,并且U=US∪UT。G是按照算法1得到的DAG,如果在U上存在节点序,该序满足US∩UT优先于其他节点,则在G中,任意u∈UT∩US,pa(u)=paT(u)∩paS(u)⊆UT∩US。
证明(1)按照确定方向的原则,paT(u)中的节点优先于u。因为u∈UT∩US且UT∩US优于其他节点,所以paT(u)⊆UT∩US。同理,paS(u)⊆UT∩US,所以,paT(u)∩paS(u)⊆UT∩US。(2)因为IF(u,v)∈ES∧ETthen(u,v)∈E或者IF(v,u)∈ES∧ETthen(v,u)∈E,所以pa(u)=paT(u)∩paS(u)。
局部特征模型的参数融合可以按照算法2进行。
算法2全局参数的计算
输入:局部特征的参数PS、PT。
输出:全局模型的参数P。
1. for each nodeu∈U
2. ifu∈US-UTthenp(u|pa(u))=pS(u|paS(u));
3. ifu∈UT-USthenp(u|pa(u))=pT(u|paT(u));
4. ifu∈UT∩USthen
(1)V=paT(u)∩paS(u);
(2)p(u|pa(u))=βpT(u|V)+(1-β)pS(u|V)
5. returnP
算法2中β是控制融合的权重。通过参数融合,最后可以得到全局特征模型。
3.2 情感知识迁移
知识迁移不仅能够减小领域之间的差异性,同时能够提高机器学习方法在小数据集上的适应性。全局特征模型为源领域和目标领域提供了一个统一的知识表示模型。BN为特征之间的关联推理提供了高效的方法。本文基于BN推理,在全局特征模型的基础上选择与源领域相关的特征并与源领域带标签的特征一起构建新的特征空间,在目标领域完全无监督的条件下,学习情感分类器。
后验概率可以体现一个特征对其他特征的依赖程度,关联度在后验概率的基础上形式化地描述了特征选择的方法。
定义2设u为全局模型中的一个节点,d∈DS是源领域中一个文本,且其特征词集为V={u1,u2,…,uα},u与d的关联度score(u,d)定义为:
(2)
算法3概括地描述了基于全局模型进行特征选择和特征空间构建的过程。
算法3特征空间的构建

1.for eachdi∈DSdo
2.di的特征词V={u1,u2,…,uα};
3.di的标签为ysi
4.for eachu∈U-Vdoscore(u,di);
5.ifscore(u,di)>ε,thenV=V∪{u}
6.xi=V,yi=ysi

4 实 验
4.1 数据集与评价指标
本文实验采用在跨领域情感分类中经常采用的英文多领域数据集Amazon评论数据集[24],包括DVD评论(D)、书籍评论(B)、电子评论(E)、厨房和家庭用具评论(K)。每种产品代表一个领域,为了方便与现有方法进行对比,各选择2 000条评论,其中积极评论和消极评论各1 000条。
本文使用支持向量机(SVM)作为分类器,采用分类准确度(Accuracy)作为主要评价指标。
4.2 实验设计
本文设计四组实验来分析本文方法的可行性和有效性。
实验一:为了验证特征迁移对提高情感分类器适应性的必要性,本实验在其他条件相同的情况下,分别对扩展前的源领域数据和扩展后的新特征空间学习分类器,并对目标领域进行分类,对比分类准确率。结果如表2所示。

表2 扩展前后跨领域分类准确率
实验二:控制融合的权重β决定了全局模型中共有特征词的参数,间接影响了特征扩展部分中关联度的大小。本实验通过对β的不同取值测试其对分类结果的影响。β的取值范围是0到1,不同取值对分类准确率的影响如图4所示。为了避免扩展阈值对结果的影响,本实验中扩展阈值ε取0。

图4 不同融合权重下的分类准确率
实验三:为了分析扩展阈值ε对本文方法的影响,本文在0.4~2.0范围内选取了5个ε值,相邻单位取值相差0.4。在保证其他参数相同的条件下,采用不同阈值进行扩展,不同ε下的分类准确率如图5所示。

图5 不同扩展阈值下的分类准确率
实验四:为了验证本文方法的有效性,本文使用几个基准模型:SCL[7],SCL-MI[24], LP-based[25],WAAR[26],WEEF[27]。对基准模型和本文模型在12种跨领域情况(B→D, B→E, B→K, D→B, D→E, D→K, E→B, E→D, E→K, K→B, K→D, K→E)进行了对比分析,结果如图6所示。
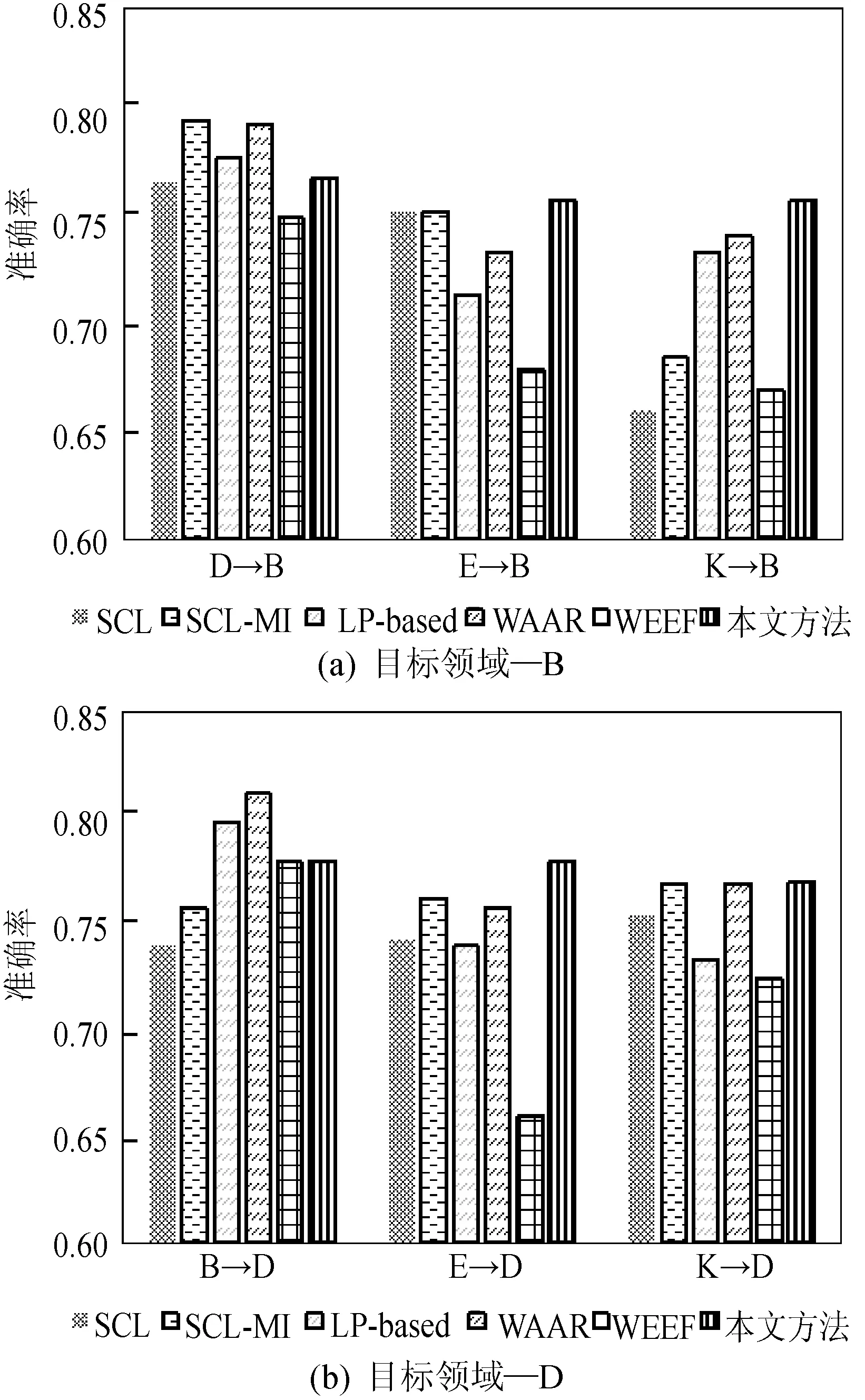
图6 不同方法的分类准确率
4.3 结果分析
实验一:从表2可以看出,在扩展后的特征空间上训练分类器可以提高对目标领域的情感分类。其中E→D、D→E两种情况的准确率提升较多,提高的原因可能是源领域和目标领域语义比较相近。
实验二:从图4数据走向可以看出,参数β对分类结果有一定的影响。目标领域不同,对分类结果的影响也不同。当目标领域为B时,β在0~0.5范围内变化比较平缓,0.5之后开始下降。目标领域为D时,β=0.5时分类效果最好,之后呈下降趋势,其中E→D任务下降较多。目标领域为E时,总体呈现一个抛物线趋势,在0.4~0.6范围内的分类效果较好。目标领域为K时,E→K任务变化较为平缓,B→K、D→K这两个任务在0.4之后出现下降,0.6之后又趋于平缓。总体来看,β在0.4~0.6这个范围内大部分分类任务都能取得较好的分类效果。因此,本实验令β=0.5。
实验三:通过观察图5中数据点的分布和走向,可以得出无论哪个领域作为目标领域,扩展阈值都会对分类精度有所影响。不同的扩展阈值,分类准确率上下浮动5%左右;此外,目标领域不同,阈值对分类效果的影响也不同。目标领域为B时,ε的大小对D→B的影响较大,且当ε=1.6时效果最好,其余两个任务相对比较平稳;目标领域为D时,ε在1.2~1.8之间有最好的准确率,阈值大于1.6时,分类准确率有下降趋势;目标领域为E时,最好的分类效果在ε=0.4处,当K作为源领域时,有最高的准确率;目标领域为K时,其余三个领域作为源领域,ε对其分类效果的影响大致相同,扩展后的分类效果,E→K任务较好。由此可以说明,通过有效设置扩展阈值,可在一定程度上提高分类器在目标领域的适应性。
实验四:从图6可以观察到,较其他几种方法,本文方法的分类准确率整体优于其他5种算法。与算法SCL和SCL-MI相比,K→B、B→D这两个跨领域分类任务准确率提高较明显,最大提高了近10%。与算法WEEF相比,E→B、K→B、E→D、D→E 4个分类任务都有较高的提升,最大提高了12%,因此,本文方法在相关性不是很大的领域之间也能有较好的分类效果。与LP-based、WAAR方法相比,本文方法在B→E和D→K这两个任务中准确率提升最多,最大提高了7.7%。可见,利用BN建立全局特征模型并利用其进行特征扩展能有效缩小领域之间的距离,并提高跨领域的分类准确率。
5 结 语
本文基于贝叶斯网对跨领域情感分析问题进行建模,充分利用贝叶斯网在知识表示和推理上的优势,通过融合得到全局特征模型,为源和目标领域建立统一的知识框架。实验结果表明,本文方法可以取得良好的预测效果,在目标领域完全无监督的基础上提高分类器的适应性。基于贝叶斯网多种学习方式,建立在多源、异构数据上的跨领域情感分析将是下一步改进研究的方向。
猜你喜欢
计算机技术与发展(2022年8期)2022-08-23
电子产品世界(2022年4期)2022-04-21
计算机系统应用(2021年9期)2021-10-11
法律方法(2021年4期)2021-03-16
法律方法(2021年4期)2021-03-16
计算机系统应用(2021年2期)2021-02-23
现代信息科技(2020年18期)2020-02-22
计算机应用与软件(2020年1期)2020-01-14
计算机测量与控制(2019年4期)2019-05-08
智富时代(2018年11期)2018-01-15
