
基于卷积神经网络的反无人机系统声音识别方法
2020-12-11 01:53李广青吕琼莹毛逸维
工程科学学报 2020年11期
薛 珊,李广青,吕琼莹,毛逸维
1) 长春理工大学机电工程学院,长春 130022 2) 长春理工大学重庆研究院,重庆 400000
近年来,无人机市场需求量不断攀升,但是由于人们缺乏公共安全意识且无人机易被不法分子利用,“黑飞”无人机给国家公共安全造成了严重危害.2015年4月22日,日本首相人身安全受到无人机威胁;2015年5月14日,无人机入侵白宫事件;2017年4月,成都双流机场多次受到来历不明的小型无人机的干扰,客机起飞、降落受到不同程度的影响,甚至航班取消.无人机带来的安全问题多种多样,给社会安全问题造成了极大的隐患.如何识别和治理无人机迫在眉睫,而如何检测无人机更是重中之重,是当前必须要解决的难点问题.
到目前为止检测无人机的方法有多种,陈唯实等[1]使用低空监视雷达检测无人机是否存在;但是雷达检测无人机设备价格昂贵,存在强人体辐射,并且存在检测盲区.Bisio等[2]提出了一种基于WIFI统计指纹的无人机检测方法,该方法能够识别附近的无人机威胁;但是无人机信号为跳频输出[3],WIFI检测技术难度较高,工艺繁琐,并且无人机“静默”时无法进行检测.基于此,本文提出了声音检测[4-5]无人机的方法.声音作为无人机的固有属性,区别于周围的其它声音,而且声音检测不受光线、电子的干扰,具有可以穿透遮挡物,价格低,使用方便等优点.首先对无人机声音进行预处理,然后提取梅尔频率倒谱系数(MFCC)和Gammatone频率倒谱系数(GFCC)特征,最后使用多层卷积神经网络(CNN)对无人机进行声音识别.
卷积神经网络首先应用于图像识别领域,在该领域得到了广泛应用[6-7],在2012年之后,开始应用于声音识别领域中.2013年,Sainath等[8]使用卷积神经网络在Broadca st News和Switchboard task任务上进行实验.本文将卷积神经网络运用在无人机的声音检测中,用来识别“黑飞”无人机.
1 无人机声音样本的采集与预处理
1.1 无人机声音样本的采集
根据奈奎斯特抽样定理,要想抽样后能够不失真地还原出原始信号,则采样频率必须大于等于两倍信号谱的最高频率,如式(1):

式中,fs表示信号抽样频率,fh表示无人机声音的最高频率.无人机主要声音频段小于16 kHz,本文选取抽样频率为32 kHz.
1.2 无人机声音样本的预加重
由于噪声的干扰,无人机的声音信息在空气中传播时会受到不同程度的衰减,并且高频部分受到衰减的程度会大于低频部分.所以为了弥补高频声音信息的损失,防止声音信息部分的丢失,要对其进行预加重.公式如式(2):

本文选取预加重系数a=0.97,d(n)表示第n个采样点的幅值,无人机声音样本预加重后图像如图1所示,绿色曲线表示声音时域原始图像,黄色曲线表示预加重后的声音图像.
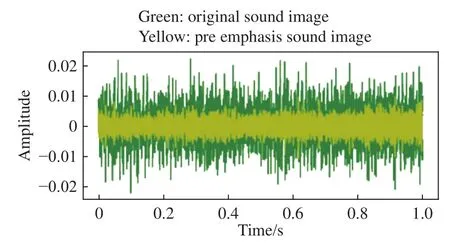
图1 无人机声音样本预加重图Fig.1 Pre-weighting diagram of an UAV sound sample
1.3 无人机声音样本的分帧
由于无人机声音样本很长无法直接提取特征,所以为了方便进行分析和提取特征,并进入到卷积神经网络,所以要对声音样本进行分帧,使其变为一个个的小片段.每个小片段之间会有重叠部分,约占整个片段的1/5~1/2.本次实验选择分帧长度25 ms,帧移10 ms.
1.4 无人机声音样本的加窗
为了防止声音样本进行分帧后两端的不连续性,所以要进行加窗.本文选用的是汉明窗,公式如式(3):
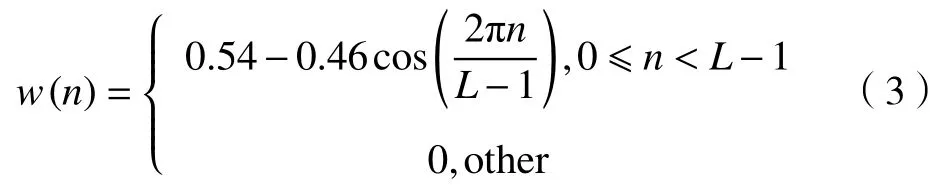
在预加重图像的基础上进行加汉明窗操作,结果如图2所示,绿色曲线表示声音经过预加重后的图像,黄色曲线是在预加重图像基础上经过加窗的图像.

图2 无人机声音样本加汉明窗函数图Fig.2 Function diagram of an UAV sound sample plus a Hamming window
2 无人机声音样本特征值的提取
梅尔频率倒谱系数(MFCC)广泛应用于声音识别领域,是在梅尔频率域得到的一种参数,可以准确地还原原始声音信息[9].
先对录取的声音进行预处理,得到关于声音的帧信号;由于在时域内难以判别声音信号的特性,所以接着再进行快速傅立叶变换(FFT)变换,使其变换到频域;在频域内将信号经过26个非线性的Mel滤波器组,而且Mel滤波器组从低频到高频的分布由密变疏;然后对滤波后的信号取对数,便于对信号进行倒谱分析;最后经过离散余弦变换得到关于声音的13维特征参数[10].
梅尔频率倒谱系数是在Mel频率域中得到的,相比于线性频率域可以更好的描述声音特征.Mel频率和Hz频率的关系如式(4)

式中,f为频率,单位为Hz.
Mel频率和Hz频率的转换曲线如图3.
虽然MFCC特征在声音识别领域中得到广泛使用,但是由于其受到环境噪声的干扰很大,在部分情况下无法达到人们的期望值[11].所以本文使用MFCC与GFCC[12-13]融合的特征来对无人机声音进行识别.
GFCC与MFCC相比使用的是Gammatone滤波器,Gammatone滤波器[14]被广泛用于模拟人类听觉系统对信号的处理方式,而且对噪声有较好的抗干扰性,可以增大识别系统的鲁棒性[15],有效弥补MFCC特征的不足.使用MFCC与GFCC融合的特征,既可有效提取声音特征,又可克服随机噪音带来的干扰.

图3 线性频率与梅尔频率转换曲线图Fig.3 Conversion curve of linear frequency and Mel frequency
Gammatone滤波器的时域表达式如式(5):

式中,t为时间,φ为相位,fc为中心频率,k是常数,p为滤波器阶数,b是滤波器的带宽.b的公式如式(6):
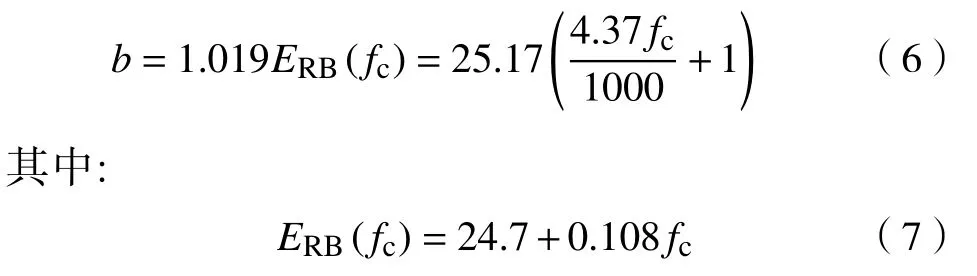
ERB(fc)为Gammatone滤波器的等价矩形带宽.
Gammatone滤波器如图4所示.

图4 Gammatone滤波器幅频特性图Fig.4 Amplitude frequency characteristics of a gammatone filter
本文使用MFCC+GFCC的特征参数来识别无人机声音,MFCC特征参数为13维,GFCC特征参数为13维,经过线性叠加后特征参数为26维.既有Mel滤波器的特征参数,又包含经过Gammatone滤波器的特征参数,对周围环境噪声具有较强的鲁棒性.
截取一段1 s的无人机声音片段,对其分别提取MFCC、GFCC和MFCC+GFCC特征参数,特征频谱图如图5所示.其中,X轴表示特征参数的维度,Y坐标表示1 s分帧的数量,Z坐标表示幅值,两种特征为纵向结合.右侧图例体现图形的表面颜色,数值表示幅值
3 支持向量机和卷积神经网络的设计
3.1 支持向量机的设计
针对本文样本数量集少的问题,使用了支持向量机(SVM)和CNN进行对比试验.支持向量机在小样本数据集和非线性分析上的实验结果十分优秀,具有很强的适应性、很好的分类能力和泛化能力[16],是目前使用最广泛、效果最好的分类器之一.
支持向量机[17-19]是一种典型的分类模型,其主要目的就是寻找一个超平面,超平面可以正确地把训练数据集分割开来,并且保证几何间隔最大.
本文使用支持向量机时,选取的样本是无人机声音数据和环境声音数据.首先提取声音数据特征,然后将两类声音数据合并到同一维度空间.如图6所示,红色标志代表无人机的声音数据,蓝色标志代表环境声音数据.目的是寻找紫色平面,将两种数据集正确划分.对某些数据集,这样的超平面有无穷多个,超平面需要满足两侧的点到超平面的最小距离是最大的.
由于有时样本在原空间不是线性可分的,所以需要将它映射到高维空间中,在高维空间中样本是线性可分的.推导可得到式(8)[20]:

其中:i,j=1,2,···,m,m为样本个数;样本为(x1,y1),(x2,y2),···,(xm,ym);αi和αj为拉格朗日乘子,且αi,αj≥0;G(xi)TG(xj)是在空间中的内积,但是在高维空间中计算它会很难.所以提出一种核函数K(xi,xj)使其在低维空间计算,但其效果等价于高维空间中的内积.显然,核函数的选择至关重要,本文选择的是线性核函数[21],公式如式(9):

图5 特征频谱图.(a)MFCC+GFCC 特征频谱图;(b)MFCC 特征频谱图;(c)GFCC 特征频谱图Fig.5 Characteristic spectra: (a) characteristic spectrum of mel frequency cepstral coefficient (MFCC) + gammatone frequency cepstral coefficient(GFCC); (b) characteristic spectrum of MFCC; (c) characteristic spectrum of GFCC
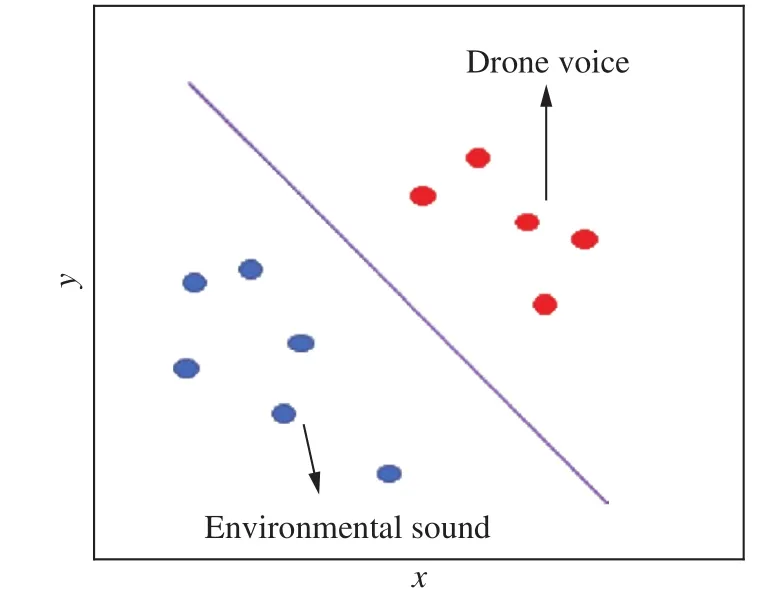
图6 SVM分类示意图Fig.6 Schematic of support vector machine classification

3.2 卷积神经网络的设计
设计的卷积神经网络结构如图7所示.
卷积神经网络各层参数设置如表1所示.
3.2.1 输入层
将代表无人机样本的MFCC+GFCC特征的特征矩阵作为输入,输入矩阵的特征维度是26.
3.2.2 卷积层
卷积层初步提取无人机MFCC+GFCC矩阵的特征.本文使用两个卷积层,卷积核大小都为5×5,步长均为1,padding 设置为SAME,必要时进行数据扩长.卷积核的个数分别为32个和64个.
3.2.3 激励层
卷积和池化的过程都是一种线性运算,而激励层的作用是在其中加入非线性成分,来增加训练模型的表达能力.本文使用的是经典Relu[22]函数.
3.2.4 池化层
池化层[23]的目的就是为了简化卷积层的输出,降低特征矩阵的维数.池化方式分为最大池化和均值池化,本文运用最大池化,设计两个池化层,池化窗口大小均为2×2,水平垂直步长均为2.

图7 设计的卷积神经网络结构图Fig.7 Structure of a CNN
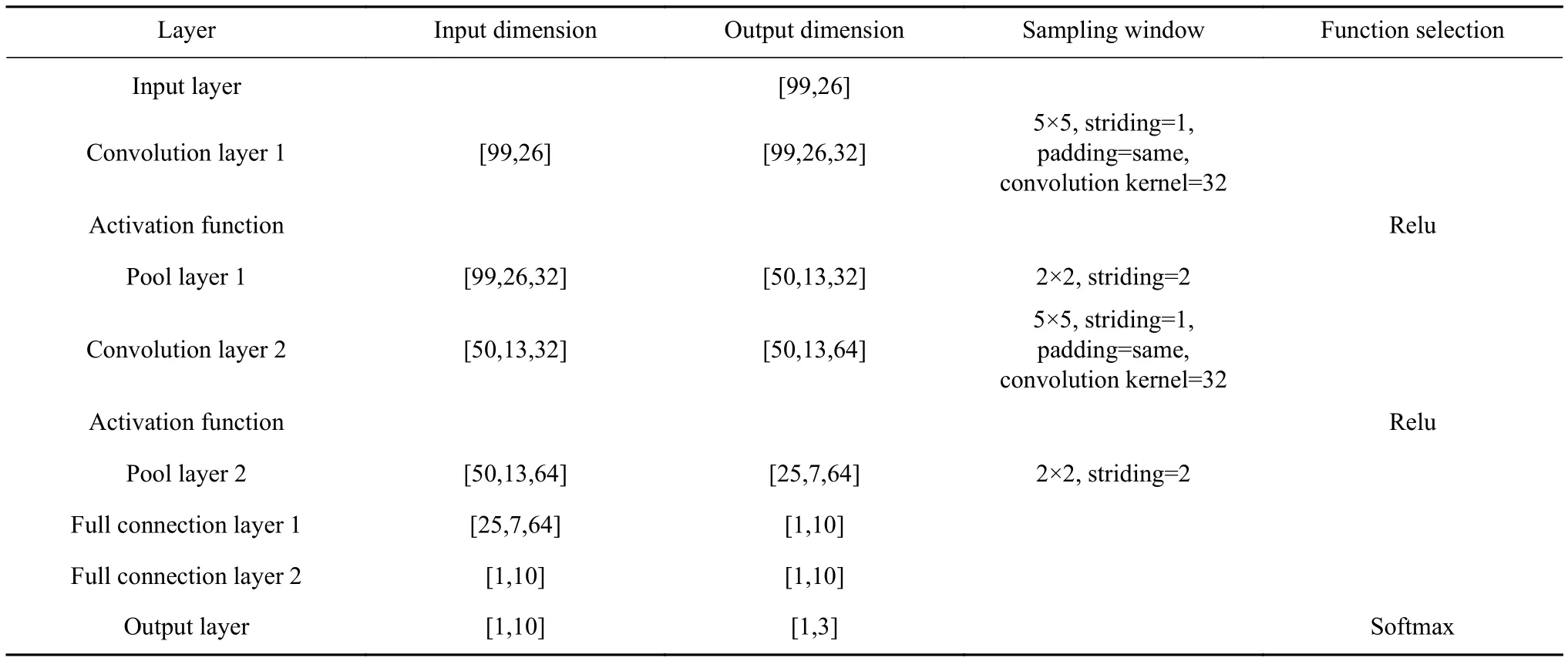
表1 CNN参数设置Table 1 CNN parameter setting
3.2.5 全连接层
全连接层是将卷积和池化操作后的特征进行重新拟合,由于用到了全部的局部特征,故叫做全连接.本文设置2层全连接层,增强特征表达能力.
3.2.6 输出层
使用的是softmax分类器,它把一些输入映射为0~1之间的实数,并且归一化保证和为1,因此多分类的概率之和也刚好为1[24-25].
4 实验与分析
4.1 实验数据采集
本实验在长春理工大学东校区停车场和操场进行,使用远距离声音采集器对100 m范围内的无人机、鸟叫声和人说话的声音进行声音采集,采集频率为32000 Hz,实验照片如图8所示.经过分割后每个声音样本时间长1 s,数量如表2所示,训练和测试的数据集数量(段数)分别为4500和900,比例为5∶1.

图8 采集样本实验图.(a)白天停车场采集样本图;(b)晚间操场采集样本图Fig.8 Sample collection experiment map: (a) sample collection map of parking lot during day; (b) sample collection map of playground at night

表2 各类音频样本数量表Table 2 Number of audio samples
将无人机声音作为目标声音事件,其余声音为干扰声音.
4.2 实验环境
实验所用计算机是Windows10系统,Intel(R)Core(TM) i7-9750U CPU@2.60 GHz,8 G 内存,基于开源深度学习框架tensorflow[26]和开源科学计算库scipy,采用Python3.7编写预处理和识别程序,文本编辑器为Sublime.其中,tensorflow为1.13.1版本,scipy为1.4.1版本.实验设备为深圳市科视达电子有限公司的远距离声音采集器,采样频率为32 kHz.
4.3 实验过程和结果
4.3.1 不同神经网络的实验结果及对比
使用设计的卷积神经网络和支持向量机在Python中对相同样本进行实验,训练次数均为1500次,实验结果如图9和图10.对比结果如表3.
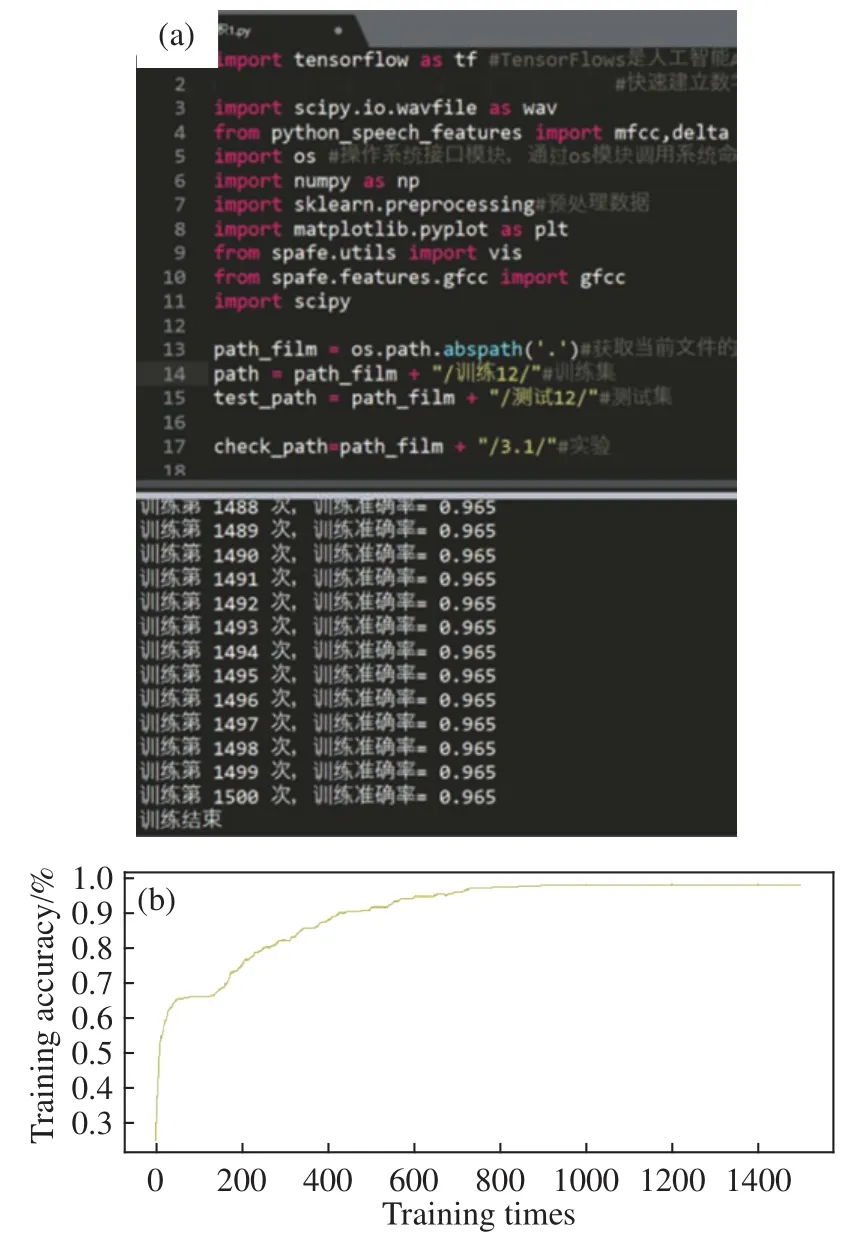
图9 卷积神经网络结果显示图.(a)python 显示图;(b)测试集识别准确率变化曲线图Fig.9 CNN results display: (a) python display; (b) change curve of test set recognition accuracy

图10 支持向量机结果显示图Fig.10 SVM results display
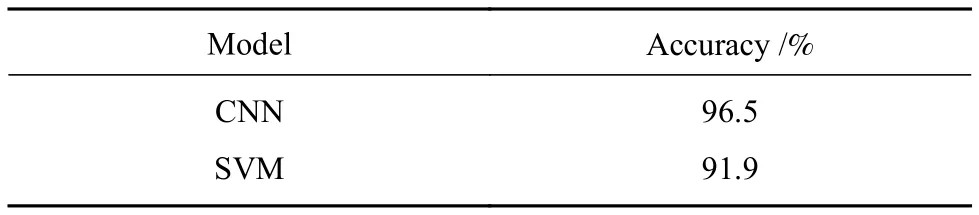
表3 不同模型实验结果Table 3 Experimental results of different models
对比分析表明,设计的CNN网络模型识别无人机的性能优于SVM.
4.3.2 改变卷积层个数进行试验
卷积层可以初步提取音频特征,其层数对实验结果具有重要的影响,本文对四种不同情况下的卷积神经网络进行试验,测试集准确率结果如表4.

表4 不同卷积层测试集准确率实验结果Table 4 Experimental results on accuracy of test sets of different convolution layers
如表4所示,网络迭代次数随卷积层层数的增加而增加,在网络达到收敛的前提下,测试集准确率随卷积层层数的增加有小幅度上升,但准确率增加幅度有限,而网络训练时间却急剧上升.在此条件下,神经网络结构设计了两层卷积层,测试集准确率达到了要求,并且训练时间较短.
4.3.3 部分Urbansound8K数据集验证
为验证所设计的卷积神经网络对声音识别的可行性,除在自行建立的数据集上进行测试外,还在典型的数据集Urbansound8K上进行测试.本文选取Urbansound8K数据集中的冷气机、发动机空转和警笛三种声音进行验证,每个种类数据集600个,总计1800个,训练与测试数量之比为5∶1.实验结果如图11所示,训练1500次时达到收敛状态,测试集准确率为90%.

图11 部分 Urbansound8K 数据集实验结果显示图.(a)python显示图;(b)识别准确率变化曲线图Fig.11 Experimental results display of some Urbansound8K datasets:(a) python display; (b) recognition accuracy change curve
5 结论
(1)针对“黑飞”无人机的检测问题,提出一种反无人机系统中运用卷积神经网络识别无人机声音进而检测无人机的方法.
(2)采集无人机声音样本,滤波和预处理后输入到设计的支持向量机和卷积神经网络进行识别,实验结果表明卷积神经网络能够识别,准确率达到要求,并且准确率高于支持向量机.
(3)将经典声音数据集输入所设计的卷积神经网络,测试所设计的卷积神经网络的性能.实验结果表明,设计的卷积神经网络识别性能良好,达到要求.
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
空间科学学报(2020年1期)2021-01-14
电子制作(2019年13期)2020-01-14
中国交通信息化(2019年12期)2019-08-13
电子制作(2019年11期)2019-07-04
电子制作(2018年16期)2018-09-26
北京航空航天大学学报(2018年1期)2018-04-20
制造技术与机床(2017年11期)2017-12-18
中国交通信息化(2017年8期)2017-06-06
系统工程与电子技术(2016年7期)2016-08-21
