
Coactive design of explainable agent-based task planning and deep reinforcement learning for human-UAVs teamwork
2020-12-09 06:56ChngWANGLizhenWUChoYANZhihoWANGHnLONGChoYU
CHINESE JOURNAL OF AERONAUTICS 2020年11期
Chng WANG, Lizhen WU,*, Cho YAN, Zhiho WANG,Hn LONG, Cho YU
a College of Intelligence Science and Technology, National University of Defense Technology, Changsha 410073, China
b College of Liberal Arts, National University of Defense Technology, Changsha 410073, China
c School of Data and Computer Science, Sun Yat-sen University, Guangzhou 510275, China
KEYWORDS
Abstract Unmanned Aerial Vehicles (UAVs) are useful in dangerous and dynamic tasks such as search-and-rescue, forest surveillance, and anti-terrorist operations. These tasks can be solved better through the collaboration of multiple UAVs under human supervision. However, it is still difficult for human to monitor,understand,predict and control the behaviors of the UAVs due to the task complexity as well as the black-box machine learning and planning algorithms being used. In this paper, the coactive design method is adopted to analyze the cognitive capabilities required for the tasks and design the interdependencies among the heterogeneous teammates of UAVs or human for coherent collaboration.Then,an agent-based task planner is proposed to automatically decompose a complex task into a sequence of explainable subtasks under constrains of resources, execution time,social rules and costs.Besides,a deep reinforcement learning approach is designed for the UAVs to learn optimal policies of a flocking behavior and a path planner that are easy for the human operator to understand and control. Finally, a mixed-initiative action selection mechanism is used to evaluate the learned policies as well as the human’s decisions. Experimental results demonstrate the effectiveness of the proposed methods.
1. Introduction
Unmanned Aerial Vehicles (UAVs) have become important assets in disaster response missions and military activities.Such situations are typically dangerous, dirty, dynamic and difficult for humans. Instead, a swarm of UAVs can be more robust for large-scale tasks due to accidental failures such as hardware damage or communication blackout. Much work have been done on swarm robotics1,2and Multi-Agent Systems(MAS)3from the perspectives of perception,4control,5planning,6decision making,7learning8and communication,9et al.However,it is challenging for a flexible and scalable team of cooperative UAVs to solve complex tasks in uncertain and dynamic environments.
Human still plays an important role of supervising the UAVs because they can hardly achieve full autonomy to solve the tasks independently without human intervention.10Besides, full autonomy is not desirable for autonomous robots with the consideration of ethical issues.11Human-in-the-loop is still necessary in such cases.For example,it has been proved effective to improve the performance of computer vision algorithms for object recognition and target tracking under challenging conditions of deformation,occlusion or motion blur.12–14In the literature, a variety of human-robot interactive systems have been proposed, including teleoperation,15supervisory control,16mixed-initiative interaction,17adaptive autonomy,18adjustable autonomy,19collaborative control,20and coactive design,21et al. However, many of them are autonomy-centered that focuses on improving the Level of Autonomy(LOA)of the team members as high as possible.This causes the problem of opacity that the team members can hardly maintain sufficient awareness of the state and actions of others for effective team performance.22In this paper, we aim to develop autonomous loyal wingman with explainable planning and learning capabilities towards transparent human-UAVs teamwork.
In contrast, coactive design21provides transparency for human-robot teamwork by analyzing the interdependence relationships among the team members based on their capacities required for solving the allocated tasks. The coactive system model is teamwork-centered that uses the Observability,Predictability and Directability (OPD) framework as a guideline for designers to identify the requirements of coherent teamwork.The theory of coactive design has been proved useful in a range of tasks including human-UAV collaborative navigation in cluttered indoor environments,21find-anddeliver in the Blocks World for Teams (BW4T) simulation environments,22robot manipulation in the DARPA Robotics Challenge,23and human-UAV collaborative damage assessment in real-world environments.24Unlike the original work of coactive design that simply uses several colors to represent the levels of capabilities for solving a task or providing support for the task,real values can be used to represent the capacities and calculate the success probability of the task with consideration of situational conditions such as enemy threats in a human-UAVs surveillance task.25
However, there are several drawbacks of the coactive design method. First, it requires a sophisticated human designer to decompose the task into executable subtasks and then allocate the subtasks to capable team members in a pre-planning manner. This design process may require several rounds of iteration and imposes heavy workload on the human designer. Second, it can hardly handle dynamic situations when a teammate’s capability changes or the task context changes. Third, it usually deals with a small human-robot team consisting of a single robot and a single human.21–24In other words, it does not scale well for coordinating a bigger team of robots and humans. In the latter case, the interdependence relationships among the teammates will become very complex. In this paper, we address the first issue by introducing an agent-based task planner for automatic generation of human-UAVs collaboration plans.Besides, we consider the emergence of unexpected events in dynamic task environments as well as a bigger and more complex human-UAVs team consisting of heterogeneous agents with different capabilities.
Mixed-initiative planning is a popular choice of coordinating humans’ decisions with agents’ plans to achieve flexible autonomy. In a search-and-rescue task, a hierarchical planner is combined with the BDI (Belief-Desire-Intention executive system) framework26to handle high-level goals and activities.A single operator can supervise and orchestrate the operations of a set of UAVs by providing sparse and sketchy interventions through a natural multimodal communication.27In a similar study, a scalable mixed-initiative mission planner has been designed to enhance the pilot’s situation awareness.28These mixed-initiative systems are centralized and supervisorcentered. In contrast, a decentralized coordination algorithm max-sum is used and the human operators are allowed to view and influence the plans of UAVs computed by the algorithm.29Also taking the decentralized approach, the disaster response task is modeled by Partially Observable Markov Decision Process(POMDP)and the optimal joint path planning of humans and UAVs can be calculated by solving the POMDP at every time step.30However, these approaches are not teamworkcentered and have not considered the OPD requirements(Observability,Predictability and Directability)21for transparent teamwork.
Different with the planning methods that generate plans associated with task goals,27,28, control law29or path trajectories,30Reinforcement Learning (RL)31provides a sequential decision making framework in which optimal action selection policies can be learned through trail-and-error interactions between the agents and the environments. Specifically, Deep Reinforcement Learning (DRL)32and Multi-Agent Reinforcement Leaning (MARL)33have been shown to achieve human-level performance in several task domains.34,35However, many RL algorithms use neural networks as function approximators so that the learning progress and the learned policies are not transparent or explainable.36As a result, it is difficult for humans to understand how the RL agents learn to make decisions in human-agent-robot joint activities.In a recent paper, this challenge has been addressed from the perspective of the interpretations of human evaluative feedback together with environmental rewards to improve the efficiency of human-centered RL.37Although the learning progress of the RL agent can be guided, the learned policies are still hard to be controlled and used by human. In this paper, we deal with this problem by representing the learned policies in an understandable and useful formalism for the human operator.
The main contributions of this paper are as follows.
(1) A novel mixed-initiative collaboration framework is proposed for human-UAVs transparent teamwork based on the OPD (Observability, Predictability and Directability) requirements of the coactive design method. This teamwork-centered framework improves the situation awareness of each teammate compared with the previous approaches that are human-centered or autonomy-centered.
(2) An explainable agent-based task planner is proposed for automatic generation of human-UAVs collaborative plans based on the results of Interdependence Analysis(IA). A complex task can be decomposed into a sequence of executable subtasks under constrains of resources, execution time, social rules and costs. Compared with previous work, this paper supports a more complex human-UAVs team consisting of heterogeneous agents with different capabilities.
(3) A deep reinforcement learning approach is designed to learn optimal policies of a flocking behavior and a path planner with the consideration of enemy threats in dynamic environments. The learned policies are understandable and controllable for the human operator. A mixed-initiative action selection mechanism is used to evaluate them through the comparison of several human-UAVs collaboration modes.
The rest of the paper is organized as follows. Section 2 introduces the explainable framework for transparent human-UAVs teamwork. Section 3 describes the improved coactive design method, followed by the details of the agentbased task planner in section 4. Section 5 discusses the deep reinforcement learning approach and the mixed-initiative action selection mechanism. Section 6 describes the experiments and results. Finally, section 7 concludes the paper and outlines our plans for future work.
2. Explainable framework for transparent human-UAVs teamwork
The framework for human-UAVs teamwork consists of four modules, i.e., a coactive design module, an agent-based task planning module, a deep reinforcement learning module, and a mixed-initiative action selection module, as shown in Fig.1.
The coactive design module is responsible for analyzing the interdependence relationships among the teammates of human or UAV in the joint activity. First of all, the overall workflow of the activity is described and the required capabilities for the activity are clarified.Then,the capability of each team member is measured and a role is assigned accordingly. The same with the original coactive design method proposed by Johnson,21the principles of Observability,Predictability and Directability(OPD)should be satisfied for each teammate to understand the others’ intentions and behaviors. Different with Johnson’s approach, this paper considers a bigger team consisting of human as well as a squad of heterogeneous UAVs so that the interdependence relationships are much more complex.As a result, manual task planning and decomposition is not feasible in our case as done by Johnson. Therefore, automatic planning is needed for this reason.
All the interdependence relationships are captured by the agent-based task planning module as a part of the social rules.Other social rules include reducing an agent’s wasted time of waiting, balancing the number of actions between agents,reducing the coupling between agent action streams, and removing some sequences of undesired actions, et al. These social rules are useful for Multi-Agent Systems(MAS)to compute and prune the plan trees. The agent-based planning system clearly defines the task goal along with the corresponding cost functions. The results of the plan trees and action streams are displayed in a graphical formalism to show how the task is decomposed as well as the timelines of each agent’s actions. In this way, the results of planning are understandable for human. This paper proposes to use the Hierarchical Agent-based Task Planner (HATP)38to solve the planning problem in a human-aware manner.39

Fig.1 Explainable framework for transparent human-UAVs teamwork.
In the Deep Reinforcement Learning (DRL) module, we have trained a flocking behavior and a path planner to assist the human operator to control the Manned Aerial Vehicle(MAV) and the UAVs. First, the flocking behavior allows a squad of UAVs to autonomously flock with the leader, i.e.,the MAV,in continuous state and action spaces.We note that the MAV may frequently change its flying direction and speed according to task requirements that are typically unknown to the UAVs under the limited communication condition. In this way, the human operator can understand the behaviors of the UAVs in the leader–follower mode.On the other hand,a path planning agent is trained to learn the optimal action selection policies to avoid potential threats while navigating to the given destination.These policies can also be used to provide suggestions to the human or alarm the human when the MAV is approaching dangerous areas.In this way,the learned policies are understandable and controllable towards transparent human-UAVs teamwork.
In the mixed-initiative action selection module, the human operator monitors the execution of the plans through a multiagent control interface that also meets the OPD requirements.The trained flocking behavior and path planner can also be activated by the human operator through the control interface.In other words,the human can observe, predict and direct the behaviors of the UAVs as needed. Different with previous work on coactive design21or agent-based task planning,38this paper considers a more challenging task in dynamic environments with emergent events such as enemy attack,communication fail or UAV damage.
3. Coactive design of human-UAVs teamwork
3.1. Task description

Fig.2 Illustration of human-UAVs teamwork (HUT)environment.
Similar with HADES (Hoplological Autonomous Defend and Engage Simulation),40the Human-UAVs Teamwork (HUT)environment is shown in Fig.2. Our human-UAVs teamwork environments are also similar with the popular real-time strategy games such as StarCraft I and II which have been used as the benchmark environments to test the state-of-the-art multi-agent collaboration algorithms.41,42A typical HUT environment consists of two adversarial teams of agents. One team is controlled by a human operator that supervises three types of agents:Manned Aerial Vehicle(MAV)equipped with detection sensors and weapon systems (i.e., multi-task MAV),UAV_Z equipped with only detection sensors (i.e., single-task UAV), and UAV_ZD also equipped with detection sensors and weapon systems (i.e., multi-task UAV). We note that the numbers and types of detection sensors or missiles can be different for MAV,UAV_Z and UAV_ZD.In other words,they have different task capabilities. On the other hand, the enemy team has several types of units such as critical targets,Surfaceto-Air Missiles(SAM)sites,and radar stations,et al.The task goal for the human’s team is to destroy the critical targets with minimal loss of UAVs.If the MAV is destroyed by the enemy,then the task is considered a failure.We also note that a HUT environment can be initialized with different settings of compositions and locations for both teams.
The MAV is manually controlled by the human operator.Reasonable or unreasonable decisions of action selection can be given to the MAV. Then, the operator can observe from the control interface how the UAVs respond to the decisions of the MAV, e.g., warn the operator about the potential danger, or suggest a better path to solve the task. Meanwhile, the operator can accept or veto the decisions from the UAVs. In this way, the action selection of HUT is mixed-initiative and the collaboration becomes explainable.
3.2. Interdependence analysis
An Interdependence Analysis(IA)table is given in Fig.3 based on the coactive design method. In an HUT environment, a task can be typically divided into several stages: planning,reconnaissance, attack and assessment. Each of these stages can be further divided into executable subtasks.For each subtask, a team member’ role is assigned as performer or supporter according to the required capabilities and its actual capabilities.Green means the team member can solve the subtask alone. Yellow means the team member needs support.Orange means the supporter can provide help. Red means no capability for the subtask. In addition, the OPD requirements of the subtasks are analyzed.
We note that different team members have different capabilities. For example, MAV can carry large EW (Electronic Warfare) pods and anti-radiation missiles, which is not available for UAVs. In addition, MAV is better at understanding task situations and environmental context to achieve goals under human supervision.On the other hand,UAVs are better at reconnaissance tasks because they can stay longer in the target zones which can be dangerous for the MAV. However,UAVs are not good at dealing with emergent events or threats.MAV can help make decisions in such cases.
4. Explainable agent-based task planning
Hierarchical Agent-based Task Planner (HATP) can solve the task planning problem in a human-aware manner. The IA table(see Fig.3)provides useful interdependence relationships for HATP to generate plan trees and action streams, and the optimality of the planned solution is guaranteed by global constraints of social rules and user-defined cost functions. In the sequel,the HATP modeling of the HUT tasks will be described in detail.

Fig.3 Interdependence Analysis (IA) table for a typical task in the HUT environments.
4.1. Problem domain representation
HATP uses the object-oriented programming language. Each element involved in the problem domain is defined as an object, or called an entity. An agent is a first class entity capable of executing an action stream.Agents are predefined entities, but their attributes can have different values. The definition of an entity is composed of a unique name and a set of attributes. Attributes are used to define the relationship between entities. Attributes include dynamic attributes and static attributes.Dynamic attributes can be iteratively updated with the task assignment being solved. Static attributes can only be initialized beforehand and cannot be modified thereafter.An attribute can be an atomic attribute or a set attribute.An atomic attribute means that the attribute is a single value,and a set attribute means that the attribute can have multiple values. An example of entity definition is given in Table 1.
After an entity is defined,it needs to be instantiated and its attributes need to be assigned values.The initial problem state is determined by the initial attributes of each entity. The description of the initial states should be as complete and detailed as possible to avoid ambiguity. An example of entity declaration and attribute assignment is given in Table 2.In thisexample,the symbol ≪==indicates inserting an element into the attribute set.

Table 1 An example of entity definition.
4.2. Task decomposition
The goal of HATP planning is to decompose a high-level task into executable atomic tasks. In HATP, a high-level task iscalled a method.An atomic task is called an action.Each agent maintains an action stream consisting of executable actions.We note that the concepts of method and action are similar to the concepts of task and subtask in the IA table.But HATP usually has a much more complex hierarchy of tasks than the IA table. On the other hand, the IA table captures the most important interdependence relationships for collaboration and therefore is useful for improving the planning efficiency by pruning the task trees.

Table 2 An example of state initialization.
When defining a method, a termination condition, i.e., a goal, needs to be defined first. It determines when the decomposition is terminated. Other important features of a method are preconditions and subtasks. Preconditions defines under what circumstances the method decomposition will be executed,while subtasks can be partially ordered or fully ordered.Users can define the order of subtasks with symbol >together with a subtask ID. In this way, ordered subtasks can narrow down the search space of the planner. An example of method definition is given in Table 3. In this example, the symbol ≫indicates the judgement of whether an element is belonged to the attribute set.
An action is the lowest level of task decomposition. The structure of an action includes a set of preconditions, a set of effects,a cost function and a duration function.The preconditions describe the context in which this action can be executed. The effects represent the expected results of this action.The cost function represents the cost of completing this action, including economy cost or time cost. The durationfunction indicates the time period taken to complete the action, which is also used to coordinate the timeline between the action streams of multiple agents. An example of action definition is given in Table 4.

Table 3 An example of method definition.
4.3. Plan generation
The HATP planner first executes the decomposition iterations based on the defined methods, and then refines the problem into a plan tree. The main purpose of HATP optimization is to control costs. After the plan tree calculation is done,resulted subtasks are assigned to each agent to form an action stream. An important advantage of HATP is that social rules can be defined for coherent teamwork. For example, the wasted time of waiting can be shortened to make the action streams of different agents as compact as possible. Effort balancing is also useful to balance the number of actions between agents.Undesirable sequences of actions can be avoided if the human do not want them to happen. Besides, intricacy can be controlled to reduce the coupling between agent action streams, i.e., reducing the interdependencies between agents.In other words, the above characteristics make the HATP a good choice of explainable planner for human-UAVs teamwork. The experiment results of the HUT tasks will be given in Section 6.2.
5. Deep reinforcement learning and mixed-initiative action selection
5.1. Deep reinforcement learning of a flocking behavior
Deep neural networks are powerful function approximators that can generalize over the high-dimensional or continuous state and action spaces. In this way, the agents can deal with new situations that they have never encountered before.Different with the method of consensus control,29we solve the leader–follower flocking problem of fixed-wing UAVs through deep reinforcement learning. In our scenario, we assume that there is one leader and several followers that they all fly at a constant average speed and fixed different altitudes to simplify the collision problem.43As the followers are collision-free,they can use a shared control policy. The leader’s behavior is decided by its operator. It shares its state information with the followers by broadcasting via a wireless communicationchannel,including its location and roll angle.The follower has to control its roll angel and speed in order to maintain a certain distance from the leader (see Fig.4(a)).

Table 4 An example of action definition.
Based on the previous work,43we also formulate the leader–follower problem as a Markov Decision Process(MDP).Based on the MDP model, we propose a Continuous Actor-Critic algorithm with Experience Replay (CACER) to solve the leader–follower problem in continuous state and action spaces.The network structure for CACER is illustrated in Fig.4(b).In contrast to the previous work43, the state representation has been extended from 6 dimensions to 9 dimensions. Both the actor and the critic use the similar structure of MLP that consists of 3 fully-connected neural network layers(Dense layers)with 512,512 and 256 nodes,respectively.Each Dense layer is followed by a Rectified Linear Unit(ReLU)activation function layer.After the 3 Dense layers,the actor transfers the input state to the roll and the velocity commands of the UAV. To guarantee the output of the actor is within the range of [-1,+1], the output layer of the critic is activated by a hyperbolic tangent (tanh) activation function. As the roll action space is[-10, +10], the output of the roll stream should be linearly magnified by multiplying with a constant 10. For the critic, it also uses 3 Dense layers to estimate the state value. Accordingly,its output layer uses a linear activation function.
Specifically,we use a MultiLayer Perceptron(MLP)to represent the actor that maps the state space to the action space,i.e.,Act*: S →A,where Act*(s)denotes the optimal action in the state s. We also use an MLP to represent the critic that approximates the state value function: V:S →R. Denote by(sk,ak,rk,sk+1)the tuple of state,action,and reward at the time step k and k+1, respectively. The update rule of the critic is defined as follows:

in which the TD-error δkis:

where 0 ≤γ ≤1 is the discount factor, and 0 ≤β ≤1 is the learning rate of the critic.
Differ from the critic, the actor is updated only when the TD-error is positive, which means the current state is better than expected. Therefore, the actor is updated as follows:where 0 ≤α ≤1 is the learning rate of the actor.
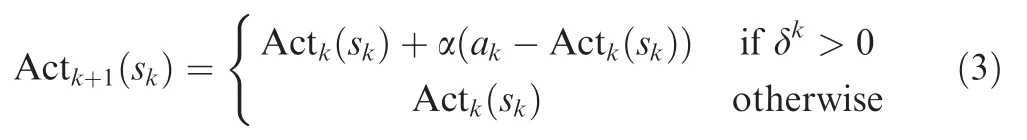
Gaussian exploration is used for selecting explorative actions. In other words, the action is randomly selected from the Gaussian distribution G(x,μ,σ) centered at the current output of the actor Actksk( ):
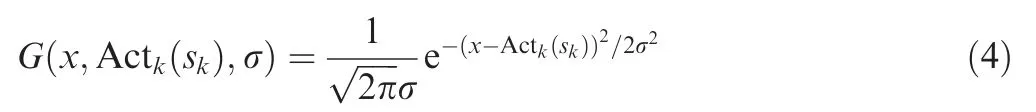
where σ is the Gaussian exploration parameter.
The leader is controlled by the operator,so we treat the leader as part of the environment for the followers.In each training episode, both a follower and a leader are randomly initialized. Then, the follower agent obtains the system state skby combining its own state and the leader’s state.The agent selects an action akaccording to the Gaussian exploration Eq. (4) based on the output of the actor network. Consequently, the UAV kinematic model generates the next system state sk+1, and the immediate reward rkis given. Every tuple of (sk,ak,rk,sk+1) is saved to the experience replay memory.If the replay memory is full, the oldest data will be replaced by the latest one. Through randomly sampling a mini-batch from the replay memory,the network parameters are updated.
5.2. Deep reinforcement learning of a UAV path planner
Situation Assessment (SA) is important in our case of path planning due to the potential threats from the enemy units.In this paper, the SA module is the front-end function of the UAV path planner(see Fig.5).The situation assessment module of the agent uses the received data to build a situation map.Then, the proposed D3QN module uses the saved situation maps to predict the Q-values corresponding to all valid actions. According to the predicted Q-values, the action selection module selects an action and the selected action number is sent to the environment. Finally, the preplanned path of the UAV will be updated, and then the UAV will fly to the new position using the selected action.
We construct the situation assessment model using the distance between the UAV and the center of an enemy unit, e.g.,early warning radar or Surface-to-Air Missile (SAM). Specifically,once the UAV is detected by a radar,it will be destroyed by a SAM with a certain probability which is calculated with regard to their distance. This calculation considers the maximum detection range of the radar,the maximum radius of missile killing zone, and the maximum range of no-escape zone.As a result,the threat level of each defense unit to the UAV is calculated as follows:

Fig.4 Deep reinforcement learning of a flocking behavior.
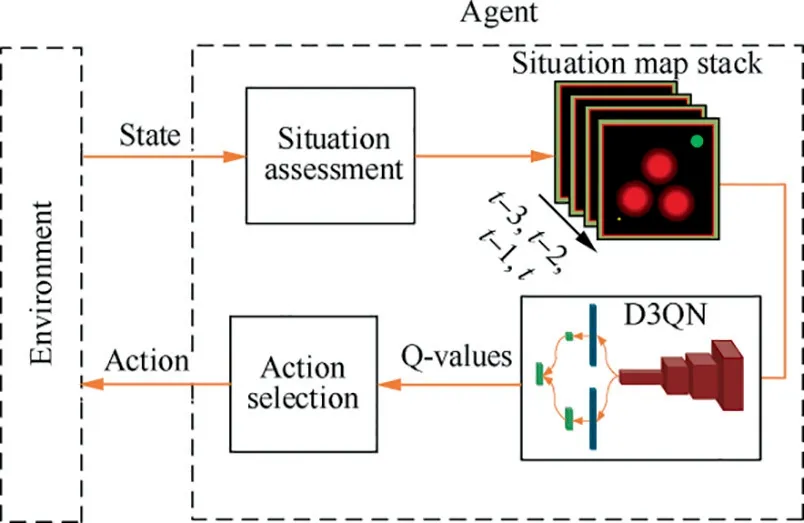
Fig.5 Deep reinforcement learning of a UAV path planner.

where D is the distance between the UAV and the enemy unit;RRmaxdenotes the maximum detection range of the radar:RMmaxrepresents the maximum radius of the missile killing zone;RMkmaxindicates the maximum range of the no-escape missile killing zone.
The threat level Tpindicates the probability of being hit by a SAM. The hit probabilities of different missiles are assumed independent.Therefore,the overall threat of all enemy units to the UAV can be calculated by the following equation:

where k denotes the number of enemy units in the task area of the UAV; Tpirepresents the damaged probability of the UAV passing the ith enemy unit.
An RGB color model is used to represent the results of the proposed SA model, and then situation maps are constructed accordingly. The synthetic threat value Tsis calculated for each position using the situation assessment model, which is then converted to the pixel value of a color channel to build a situation map according to:
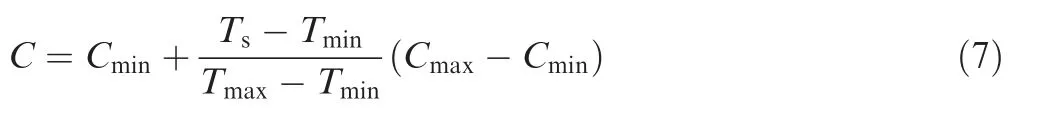
where Cmaxand Cmindenote the maximum and minimum pixel values of a color channel,respectively;Tmaxand Tminrepresent the maximum and minimum synthetic threat values based on the situation data. In our case, Cmax=255 and Cmin=0.Then, the threat value is converted to the pixel value of the red channel. A resulting situation map is shown in Fig.5.
Different with the MDP model in Section 5.1, the MDP model is constructed in discrete spaces in Section 5.2.The state representation is based on the situation map.Three roll angles of{-15,0,15}are drawn from the continuous action space of Eq. (3). Besides, the reward function is defined as follows: if the agent enters the ground radar identifiable zone, a reward of-2 is given; if the agent enters the SAM attacking zone, a reward of-4 is given;if the agent arrives the given destination,a reward of 10 is given.
In order to estimate the state-action value function (Qfunction) of UAV, we establish a Dueling Double Deep Qnetwork (D3QN) as shown in Fig.6.
The input of the network is an 84×84×12 situation map stack constructed by the situation assessment model. It is followed by four convolutional layers and two full connected layers for two streams of dueling architecture. We note that the parameters of the network is the same with the previous work.44The pseudocode of the proposed D3QN algorithm is shown in Algorithm 1.
The UAV agents can use air-to-ground missiles to destroy the enemy surface-to-air missile sites, which will reduce the level of threats when they approach the critical target. But using missiles may also increase the danger of being destroyed by the enemy’s defense units. Therefore, the UAV agents should reasonably allocate their missiles according to the distribution of the enemy units. In other words, the UAV agents can choose to attack the enemy missile units to increase the survival probability, or they can choose to attack the critical targets to solve the task.In the first case, the remaining weapons may be insufficient to solve the task.In the latter case,the survival probability may drop. This decision making problem is challenging because the task scenario is dynamic and not fully known beforehand.

Fig.6 Architecture of the proposed Double Deep Q-network (D3QN).
We solve the problem through deep reinforcement learning that can shape the behaviors of agents through rewards or punishments. The minimum number of missiles required to destroy a critical target is predefined. If the UAV agents use the missiles to attack the enemy units, the number of onboard weapons will reduce. When the UAV agents finds the critical target, the agents will receive a reward if the left weapons are enough, otherwise a penalty is given. In addition, punishments are given with a probability if the agents are within the enemy’s defense range. After episodes of training, the UAV agents are expected to learn how to allocate the weapons among the enemy units.remind and assist the human with decision making. As the human operator can test the behaviors of the DRL agents through the interface, the learned policies obtained by the DRL agents are considered understandable and useful to improve the teamwork performance. In other words, we have designed a mixed-initiative action selection paradigm for collaborative human-UAVs teamwork by using the results of agent-based planning as well as deep reinforcement learning.
To sum up,three modes of human-UAVs collaboration can be chosen as follows:
(1) Autonomous mode.Every agent follows the HATP plan as well as the learned policies of flocking and path planning.The weapons are autonomously fired according to the environmental situations.
(2) Following mode. The human supervises the task execu-

5.3. Mixed-initiative action selection
The tasks can be done either in a manual mode by following the planofHATPorinafullautonomousmodebyfollowingthepolicies learned through deep reinforcement learning.However,following the HATP plan has limitation for dynamic task reallocation required by the human operator or caused by emergency.On the other hand,following the learned policies has limitation for handling unexpected events such as enemy attack,communication fail or UAV damage. Therefore, we propose a mixed-initiative action selection mode that combines the strength of symbolic task planning and deep reinforcement learning (see Fig.1).
In this paper,the MAV is manually controlled through the human-UAVs control interface, and the UAVs can flock with the MAV or follow the learned policies. We assume that the human operator can make reasonable decisions if she is aware of the situation through the control interface. When the human’s decision is unreasonable, the UAV agents should tion process. The UAVs simply follow the instructions from the human. In the case that the UAVs do not receive the commands from the human,they only follow the HATP task plan and preplanned path.The UAVs do not evaluate the potential threats or fire at the critical targets. The human decides whether to fire or not.
(3) Mixed-initiative mode.The UAVs evaluate the potential threats and alert the human about the potential threats.The UAVs send messages to the human about their actions, leaving a certain time for the human to intervene. If the human does not veto, the actions are executed accordingly.
6. Experiments and results
6.1. Task environment
The human-UAVs teamwork (HUT) control interface has been implemented using the Unity Real-time Development Platform, as shown in Fig.7.
As introduced in section 3,a typical task requires a human operator controlling an MAV along with several UAVs to find and destroy critical enemy units. The human-UAVs team has to solve the task while maximizing the survival probability by avoiding enemy radar detection and Surface-to-Air Missiles(SAM).In our experiment,we used two single-task UAVs and two multi-task UAVs along with a multi-task MAV.
In the first-person perspective, the human operator can observe the task environment in the 3D space as well as through a 2D global map (left-bottom). This map can be zoomed in for task allocation by switching to the map perspective via the Perspective button.By default,the task is initiated in an autonomous mode without human intervention.The following mode or mixed-initiative mode can be activated by clicking the corresponding buttons.Messages among the teammates are shown in the upper zone of the interface when an agent is going to execute a new task or a potential threat is discovered. The time spent and the goals achieved are shown in the bottom zone of the interface. The statistics of the MAV and the four UAVs are shown at the right column, including the number of entering SAM zone, the number of entering radar zone, the flying height, the scores and the security state evaluation results.
6.2. Agent-based task planning
As introduced in Section 4,an entity is defined to describe the problem domain knowledge and states.The entities used in the experiment and their meanings are shown in Table 5. In our example experiment, the human-UAVs team consists of five aerial vehicles: one multi-task MAV, two single-task UAVs for reconnaissance,and two multi-task UAVs.We assume that two critical targets have to be destroyed at two different task locations.The definition of methods are based on the IA table(see Fig.3).The methods defined in the experiment are shown as Table 6.
The actions defined in the experiment are shown as Table 7.
A resulted plan tree is shown in Fig.8.In this plan tree,the task is decomposed into 3 levels.Each decomposition is represented with a bounding box. The first level is the WholeMission method. The second layer shows several lower level methods (see Table 6). The methods cannot be executed directly, so they are represented in gray. Among them, a double-layered ellipse indicates that there are multiple agents participating in the method, while a single-layered ellipse indicates that only one agent is involved. The third level is the atomic tasks performed by the agents.An action is represented by a colorful single- layered ellipse. Different colors represent different agents. Arrows indicate the causal relationship between actions or methods.The parentheses include the entity parameters of the action or method.
With the generated plan tree, HATP evaluation thread can calculate the action cost of each agent. In the process of cost optimization, the plan tree is transformed into action streams for each agent, as shown in Fig.9. Each color represents an agent. Yellow indicates the Manned Aerial Vehicle (MAV).Blue indicates the single-task UAV (UAVz1) in Formation1,and orange indicates the multi-task UAV (UAVzd1) in Formation1. Green and purple represent two UAVs (UAVz2 and UAVzd2) in Formation2. The arrows indicate the causal links between the agent actions. The parentheses indicate the entity parameters of action. Square parentheses indicate the time duration of this action, e.g., [2,7] means from time Step 2 to time Step 7. As shown in the action streams, each agent is either independent or collaborative according to task requirement. The generated teamwork plan is in accordance with the interdependency analysis in Section 4. The plan tree and the action streams are explainable for the human operator.The MAV has the central role of monitoring the task execution process.

Fig.7 A typical human-UAVs teamwork (HUT) task environment in the first-person perspective.
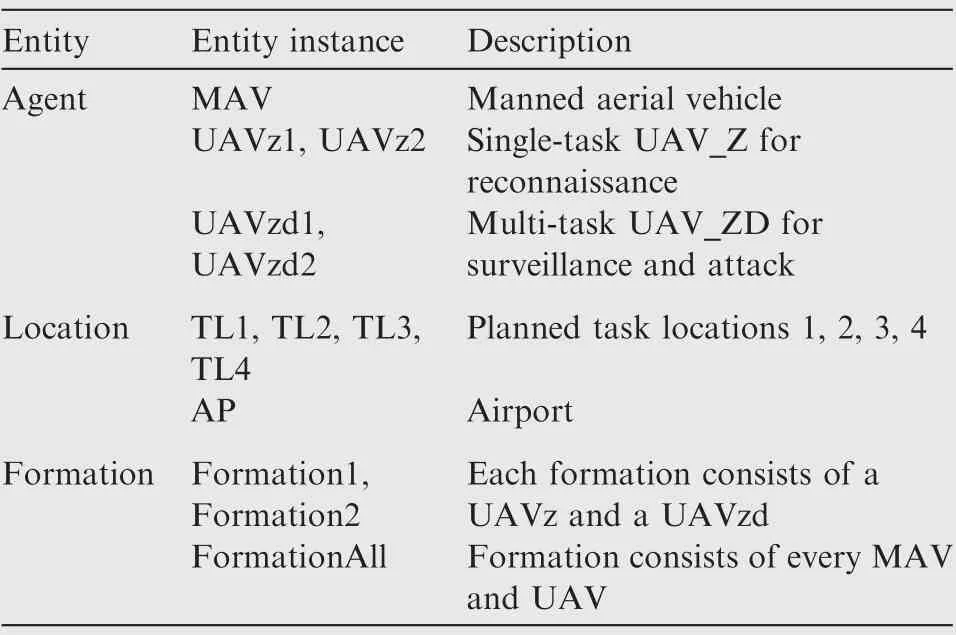
Table 5 Entities defined in the experiment.

Table 6 Methods defined in the experiment.
6.3. Deep reinforcement learning and mixed-initiative action selection
First, we tested the learned flocking behavior using the proposed deep reinforcement learning algorithm CACER (see Section 5.1). In this experiment, the actions of the leader were generated according to task requirements, and the followers used the learned policy to follow the leader. We note that the parameter settings were the same with the previous work,43but we dealt with a more difficult problem in this paper. The result of one leader and four followers flocking is shown in Fig.10(a).
The trajectory results illustrated that the followers were able to keep up with the leader even if the leader changed its heading sharply at the end of the experiment.The best performance of the flocking behavior was achieved when the heading of the leader did not change much.
We also compared the results of the proposed CACER flocking algorithm with a start-of-the-art DRL-based algorithm DDPG.45Specifically, we calculated the averaged reward as follows:

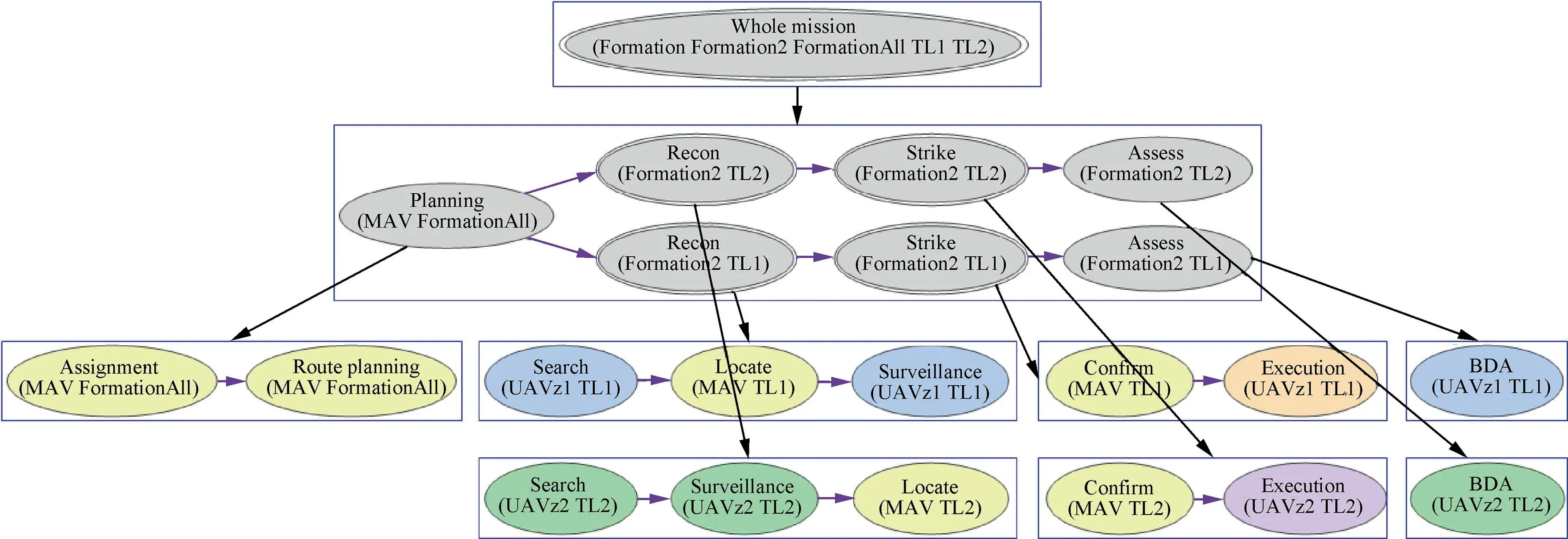
Fig.8 Results of a plan tree for an HUT task with one MAV and four UAVs.

Fig.9 Results of action streams for an HUT task with one MAV and four UAVs.

Fig.10 Results of the DRL-based flocking behavior.
In the training process, we calculated GAveobtained by the follower agent using CACER every 100 episodes.Additionally,the two algorithms used the same network structure as well as the same parameters for fair comparison(see Fig.4(b)).Additional parameters used by DDPG were the same with.45As shown in Fig.10(b),the averaged reward of the two algorithms both increased rapidly in the early stage before around 2000 episodes.Compared with DDPG,the reward curve of CACER grew faster from 2000 episodes and gradually became stable.After about 12000 episodes, their reward curves were both stable, but CACER obtained a higher reward than DDPG.The above results illustrated that CACER learned faster than DDPG and its reward curve became stable earlier than DDPG. In other words, CACER slightly outperformed DDPG in both the learning speed and the stability.
For further quantitative evaluation, we also compared CACER with DDPG and two other policies,i.e.a greedy policy and an imitation policy(see Fig.10(c)).For the greedy policy, the follower used the UAV kinematics model to choose sequential actions that resulted in maximum immediate reward by iterating all possible actions at each time step. For the imitation policy, the follower simply selected the same roll angle and velocity setpoints with the leader, which was likely to result in satisfying flocking result when the follower’s initial state was the same or similar with the leader. We compared the averaged rewards of the four policies under three different conditions [-90, +90], [-60, +60], [-30, +30], which represented the difference in heading between the leader and the follower at the initial time step. As can be seen, the two DRL-based methods, i.e., CACER and DDPG, achieved similar and higher averaged reward than the imitation and greedy approaches. Meanwhile, their results were also more stable with a much lower variance. This demonstrated the effectiveness of DRL-based methods for the flocking problem.Furthermore, the initial heading difference did not have much influence on the performance of CACER or DDPG compared with other two approaches.
Then, we trained the UAV path planner using the D3QN algorithm (see Section 5.2). The training scenario(see Fig.11) was simpler than the testing task environment of Section 6.1.As a result,the generalization capability of deep neural network could be verified in the testing task.
Finally, we compared the three modes of autonomous, following and mixed-initiative in the testing task introduced in section 6.1.Based on the generated HATP plans in Section 6.2,the five agents started off and searched for the critical targets.They had to avoid the enemy radar and surface-to-air missiles.The four task locations (TL1, TL2, TL3, TL4) were visited in the planned order,corresponding to four enemy areas(A1,A2,A3, A4). Four experiments were carried out by the same human operator to illustrate the decision making differences of the three task modes. The trajectory results are shown in Fig.12.
As shown in Fig.12(a), the agents successfully carried out the HATP plan without any modification. Either the MAV or the UAVs followed the safe paths by avoiding the radar areas. However, one disadvantage of this mode was that the planned path was not allowed to change even if there existed a better path. In contrast, the MAV could choose a shorter path by keeping an appropriate distance from the dangerous area according to the observed environmental states, e.g., the MAV flied over A1 in Figs. 12(b) and (d) other than flying around it.

Fig.11 Training scenario of the DRL-based path planner.
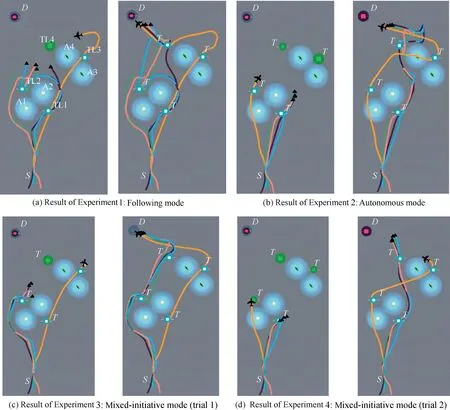
Fig.12 Trajectory results of the testing task in three different modes: Following, autonomous, and mixed-initiative.
In the autonomous mode, the UAVs initially planned the shortest paths and they broadcasted their plans of task locations to the MAV that they would first visit TL1 and then TL3, leaving TL 2 and TL4 for the MAV to visit. However,this plan was changed by the UAVs during task execution because they found TL3 was too difficult for them to visit.As a result, they decided to exchange task with the MAV,i.e., they visited TL4 instead of TL3, and the MAV had to change the original path by heading to TL3. As shown in Fig.12(b), this was not efficient that the MAV had almost arrived TL4.
The above issues were solved in the mixed-initiative mode as shown in Figs. 12(c) and (d). In the experiment of Fig.12(c), the MAV initially headed to TL1 and left TL2 to the UAVs. In the experiment of Fig.12(d), the MAV initially headed to TL2 and left TL1 to the UAVs. In both cases, the MAV decided to visit TL3 after it had finished the first task because the MAV found it difficult for the UAVs to accomplish the task at TL3 due to capability limitations. The tasks were solved more efficiently compared with the following mode and the autonomous mode.
We further compare the three task modes with 15 participants and averaged the results as shown in Fig.13. Figs. 13(a)–(d)compare the results of the three task modes with statistics of spent time and number of failures.Fig.13(a)shows the result of the spent time of executing the tasks and whether the tasks were successfully executed in the first task execution mode,i.e.,fully controlled by the MAV.As can be seen,a total of 15 missions were performed with 7 successes and 8 failures.The successful task execution time was averaged around 206 s.Fig.13(b) shows that the averaged execution time is 182 s,which is shorter than the first task mode.Fig.13(c)shows that the spent time can be further decreased in the mixed-initiative task mode, around an average of 155 s. Besides, the mixedinitiative mode has the highest success rate compared with the other two task modes. Fig.13(d) shows the statistics of the number of errors committed by the three task modes.Each episode corresponds to a comparison of the three task modes,and each episode was performed 15 times to sum up the total number of failures. We note that the numbers of failures decrease for all three modes as the episodes were performed.The mixed-initiative mode has the best performance among the three modes.
Figs.13(e)–(g)show the statistics of the number of weapons used in the three modes.In each mission,every aircraft carried two ground-attack missiles,i.e.,and team carried a total of 10 missiles in total.We note that the first mode required the most averaged number of weapons to solve the task. The mixedinitiative mode required the least averaged number of weapons while guaranteed the task success. The second mode had the lowest number of task success which illustrated that human intervention is useful in the task to improve the teamwork efficiency.

Fig.13 Comparison of statistics of three modes: following (player), autonomous (Al), and mixed-initiative (Mixed).

Table 7 Actions defined in the experiment.
Fig.13(h) shows the statistics of the behavioral evaluation values of each aircraft.The MAV started to choose a high-risk behavior from the 75th second and the evaluated score began to decrease. After the UAVs warned and intervened, the behaviors of the MAV were corrected and score started to increase from around the 105th second (Table 7).
7. Conclusions
(1) An explainable framework has been proposed for human-UAVs transparent teamwork following the OPD principles (observability, predictability and directability). This framework integrates coactive design, agent-based planning, deep reinforcement learning, and mix-initiative action selection to support adaptive autonomy and explainable collaboration. Human-UAVs Teamwork (HUT) environments have been designed to test the proposed framework in adversarial game scenarios.
(2) An agent-based task planner has been proposed for automatic generation of human-UAVs collaborative plans based on interdependence constrains, task goals and costs. A complex task can be decomposed into a sequence of executable subtasks, and the planning results are displayed in a graphical formalism to show how the task is decomposed as well as the timelines of each agent’s actions. In other words, the planning module is understandable for the human operator.
(3) A deep reinforcement learning approach has been designed to learn optimal policies of a flocking behavior and a path planner with the consideration of enemy threats in dynamic environments. The learned policies are understandable and controllable for the human operator. The mixed-initiative action selection mechanism has been shown to outperform the other two human-UAVs collaboration modes, i.e., the following mode and the autonomous mode.
Acknowledgements
This work was co-supported by the National Natural Science Foundation of China (Nos. 61906203, 61876187) and the National Key Laboratory of Science and Technology on UAV, Northwestern Polytechnical University, China (No.614230110080817).
 CHINESE JOURNAL OF AERONAUTICS2020年11期
CHINESE JOURNAL OF AERONAUTICS2020年11期
- CHINESE JOURNAL OF AERONAUTICS的其它文章
- Event-triggered control for containment maneuvering of second-order MIMO multi-agent systems with unmatched uncertainties and disturbances
- Battery package design optimization for small electric aircraft
- Two-phase guidance law for impact time control under physical constraints
- Adaptive leader–follower formation control for swarms of unmanned aerial vehicles with motion constraints and unknown disturbances
- Optimal video communication strategy for intelligent video analysis in unmanned aerial vehicle applications
- An aggregate flow based scheduler in multi-task cooperated UAVs network