
一种Protobuf到JSON动态转换方法
2020-12-02 06:07田丹张金杰李翀曲艳华焦昊
数据与计算发展前沿 2020年4期
田丹,张金杰,李翀,曲艳华,焦昊
1. 中国中钢集团有限公司,北京 100180
2. 中国科学院计算机网络信息中心,北京 100190
3. 中国科学院大学,北京 100049
4. 战略支援部队航天系统部,北京 100094
引 言
随着互联网的不断发展,兴起了多种数据交换格式,其中比较常用的便是JSON、Google Protocol Buffer 和XML,他们都有各自的使用场景。JSON 是一种轻量级的数据交换格式,它基于JavaScript 的一个子集,采用完全独立于语言的文本格式,易于编写和解析[1]。Google Protocol Buffer(简称Protobuf或PB)是一种灵活高效的、用于序列化结构化数据的机制,类似于XML,但比XML 更小且更简单[2]。Protobuf 序列化为二进制数据,不依赖平台和语言,同时具备很好的兼容性。XML 是一种重量级数据交换格式,是可扩展标记语言。相比于前两种数据交换格式,XML 占用带宽比较大,现在主要用于描述数据和用作配置文件,在服务器与Web/客户端中使用较少[3]。本文重点研究JSON 和Protobuf 的互相转换方法。
JSON 和Protobuf 都是应用非常广泛的数据交换格式,两者在使用场景上有所不同:JSON 主要用于Web 场景、数据对人可读、服务端应用程序向Web浏览器发送数据和跨组织的API 的交互场合更适合;Protobuf 自带加密功能,主要用于客户端到服务器端高效安全数据传输。Protobuf 编解码速度和数据大小上有更多优势,可以得到最快的序列化速度和最小的结果[4]。当Protobuf 数据需要发送给Web 浏览器以供人们浏览时,或者Web 浏览器产生的JSON 数据需要大批量进行高效传输时,需要两种异构数据进行相互转换。
目前开源的JSON 与Protobuf 的转换工具有Flask-Pbj、pbf2JSON、Node-proto2JSON、pb2doc等。Flask-Pbj 是基于python 实现的,它提供了对Protobuf 和JSON 格式的请求和响应数据的支持,且API 修饰器可以实现JSON 或Protobuf 格式的消息与Python 字典之间的序列化和反序列化。pbf2JSON 是基于Go 实现的,它是一个输出JSON的OpenStreetMap pbf 解析器,允许用户挑选标签并处理反规范化的方式和关系,可作为独立的二进制文件提供,并带有方便的npm 包装器。Nodeproto2JSON 是基于JavaScript 的 .proto 文件到JSON 转换器,没有额外的依赖关系。pb2doc 是用于将Protobuf 消息转换为JSON 或html 的解析器,具有递归解析消息、支持grpc 服务、可配置的文档类型、基于注释的服务描述等功能。可见,上述转换工具开发语言各异且较小众,多数工具使用步骤繁琐复杂,只能实现单向转换,或者无法实现批量转换。
本文基于C 语言实现了Protobuf 与JSON 数据转换,可以方便快捷地将Protobuf 格式的二进制数据批量转换为JSON 格式的文本数据,该方法可靠稳定且兼容性好,同理也很容易将若干JSON 数据批量转换为Protobuf 格式二进制数据。
1 相关技术
1.1 Protocol Buffer
Protobuf 是Google 公司内部的混合语言数据标准,最新版本为3.X,最初用于实现客户端与服务器之间的通信协议,是一种灵活高效的结构化数据存储格式[5]。Google 提供了一套软件库,可以把Protobuf 的记录序列化和反序列化,序列化后的数据小以及数据解析速度快,方便网络传输和存储。由于Protobuf 是二进制数据格式,编码和解码双方必须有共同的.proto 文件才能获取到相应的信息,数据本身不具有可读性,因此只能反序列化之后得到真正可读的数据,一定程度上保证了其安全性;另一方面,二进制数据比使用XML 等其他类型进行数据交换要快得多,因此可以把它用于分布式应用之间的数据通信或者异构环境下的数据交换[6-7]。作为一种效率和兼容性都很优秀的二进制数据传输格式,Protobuf 可以用于诸如网络传输、配置文件、数据存储等诸多领域,目前提供了 C++、Java、Python、JS、Ruby 等多种语言的API。
要使用Protobuf,首先我们需要编写一个.proto文件来定义结构化数据Message。如图1 所示,Protobuf 还允许对消息的嵌套,使得其能够表达更为复杂的数据结构,功能更加强大。
通过Protobuf 编译器将.proto 文件转换成对应平台(Python、C++、Java)的代码文件。在C/C++中通过包含该代码的头文件就能使用定义好的数据类型,诸如对消息的成员进行赋值,将消息序列化等都有相应的方法。
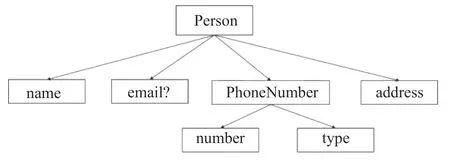
图1 消息的嵌套Fig.1 Demo for nested message types
1.2 序列化和反序列化
Protobuf 的核心技术之一是序列化与反序列化。序列化是指将数据结构或对象转换成二进制串的过程,而反序列化则是上述过程的逆操作,即将序列化过程中所生成的二进制串转换成数据结构或者对象。
Protobuf 将消息里的每个字段进行编码后,再利用T-L-V 存储方式进行数据的存储,最终得到的是一个二进制字节流[8]。其中T 即Tag,字段的标识号,也叫Key;L 是Value 的字节长度;V 是该字段对应的值Value,即消息字段经过编码后的值。序列化后的Value 是按原样保存到字符串或者文件中,Key 按照一定的转换条件保存起来,序列化后的结果就是如图2 所示的形式。

图2 序列化结果T-L-V 示意Fig.2 Serialization result T-L-V diagram
Key 的序列化格式是按照Message 中字段后面的域号与字段类型来转换。序列化过程不需要分隔符就能分隔字段,各个字段存储得非常紧凑,存储空间利用率非常高;如果一个字段没有被设置字段值,那么该字段在序列化时对应的数据中是完全不存在的,即不需要编码。同时序列化涉及到的运算也仅是一些简单的数学操作,只用到Protocol Buffer 自身的框架代码和编译器,无需其他的工具,这些特点共同保证了运算的高效。
Protobuf 反序列化过程如下:(1)调用消息类的parseFrom(input) 解析从输入流读入的二进制字节数据流;(2)将解析出来的数据按照指定的格式读取到Java、C++、Python 对应的结构类型中。由于反序列化是序列化的逆过程,因此同样无需复杂的词法语法分析,解析过程只需要通过简单的解码方式即可完成[9]。
1.3 Jansson 开源库
Jansson[10]是一个用于解码、编码和操作JSON的C 语言库,其提供了简单直观的API 和数据模型,无需其他依赖项,并完整地支持Unicode 编码。JSON 规范定义了以下数据类型:对象、数组、字符串、数字、布尔值和Null。Jansson 库中分别对应JSON_OBJECT、JSON_ARRAY、JSON_STRING、JSON_INTEGER、JSON_REAL、JSON_TRUE、JSON_FALSE、JSON_NULL 类型。由于JSON 数据结构是动态变化的,使用数据结构JSON_t 来表示所有JSON值。JSON_typeof函数可以获得JSON值的类型。
Jansson 库中所有以JSON 值作为参数的函数都将管理引用,即根据需要增加和减少引用计数。创建新JSON 值的函数将引用计数设置为1。如果函数调用增加了引用计数,一旦不再需要该值,应调用JSON_decref 释放引用,即该值将被销毁并且无法再使用。
2 设计与实现
在本部分,本文以Protobuf 转JSON 为例,详细地介绍设计思路与具体的实现方法。而JSON 转Protobuf 为其的逆过程,两者使用的思路与方法基本一致,且从JSON 结构化到二进制转换相对更简单,本文不再赘述。
2.1 设计思路
将Protobuf 转换为JSON,需要以下四个步骤:
(1)读入二进制文件和.proto 描述文件;
(2)根据.proto 文件解析出消息类型结构;
(3)动态解析出二进制文件中每条数据所属的消息类型及其各个字段的含义,并组成一个或多个消息对象;
(4)根据消息对象中的每个field 的类型和属性,找到其对应的JSON 格式,构造为JSON 数据。
综合以上四个步骤,本文将实现的主要内容分为两个模块:二进制文件的动态解析模块和Protobuf转JSON 模块。
2.2 动态解析方法
2.2.1 问题分析
通常输入仅有Protobuf 的Schema 定义以及相应的二进制Protobuf 数据,即Message 的定义事先是未知的,因此我们需要根据.proto 文件解析出每条Message 的结构,根据Protobuf 二进制数据解析出不同的数据记录,并确定每条数据记录所对应的消息类型。
由于Protobuf 打包的数据没有自带长度信息或终结符,当有多条序列化二进制数据时,我们无法判断哪一部分对应的是一条完整的数据,无法直接进行反序列化。因此需要解决如下问题:第一:长度。由应用程序自己在发送和接收的时候做正确的切分;要求生成的分隔符不能与消息内容重复,否则可能出现无法区分的情况,从而无法获取正确的Protobuf格式的数据。第二:类型。Protobuf 打包的数据没有自带类型信息,需要由发送方把类型信息发送给接收方,接收方创建具体的 Protobuf Message 对象,再做对应的反序列化。
因此我们规定分隔符形式为:^@UCAS@Message_type^,其中Message_type 表示每条完整的二进制数据对应的类型。将其添加分隔符后如图3所示。

图3 加入分隔符后的序列化二进制数据Fig.3 Serialized binary data with delimiters
根据对应的分隔符,可以明确得出图中含有三条序列化二进制数据,第一条、第三条对应的消息类型为Person,第二条对应的消息类型为Test。
在确定了每条数据的内容以及其所对应的Message 类型后,接下来需要研究如何自动创建具体的 Protobuf Message 对象,再对其做相应的反序列化。Google Protobuf 本身实现了根据 type name 创建具体类型的 Message 对象这一功能。Protobuf Message class 采用了 prototype pattern,Message class 定义了 New() 虚函数,用以返回本对象的一份新实例,类型与本对象的真实类型相同。也就是说,只需要Message* 指针,而不用知道它的具体类型,就能创建和它类型一样的具体 Message Type 的对象。具体的实现步骤如下:
(1)调用 DescriptorPool::generated_pool() 找到一个 DescriptorPool 对象,它包含了程序编译的时候所链接的全部 Protobuf Message types。
(2)调用DescriptorPool::FindMessageTypeByNa me() 根据 type name 查找相应 Descriptor。
(3)调用 MessageFactory::generated_factory()找到 MessageFactory 对象,创建程序编译的时候所链接的全部 Protobuf Message types。
(4)调用 MessageFactory::GetPrototype() 找到具体 Message Type 的default instance。
(5)调用 prototype->New() 创建对象。
2.2.2 主要代码实现
(1)string analyPackage(string protoPath)
函数参数:.proto 文件的路径。
函数功能:根据.proto 文件解析出对应的包名,若没有则返回空。如果.proto 文件中使用了package语句,则需要使用对应的package_name 才能访问其内部的Message 类型。
(2)string analyMessage(string protoPath);
函数参数:.proto 文件的路径。
函数功能:保证程序的健壮性。我们要求序列化的文件一定要有分隔符,若没有检测到分隔符,则默认该条数据对应.proto 文件的第一个Message类型,此时需要从.proto 文件解析其第一条Message类型。
(3)string regexClassName(string p_str)
函数参数:给定的字符串(含有自定义的分隔符)。
函数功能:从分隔符中获取二进制数据所对应的类型。采取正则表达式的方式来实现:
regex reg(“\^@UCAS@(.*)\^”)
smatch m;
auto ret = regex_search(p_str, m, reg);
(4)int dynamicParseFromProtoFile(const string &filePath, const string &MessageName, function<void(::google::protobuf::Message *msg)> callBack)
函数参数:.proto 文件的路径;.proto 文件中第一个Message 类型;回调函数。
函数功能及说明:对给定的一条二进制数据msg 进行动态解析,若某条二进制数据不含有分隔符,则默认其对应.proto 文件的第一个Message 类型。回调函数就是一个通过函数指针调用的函数。本函数的第三个参数为一个回调函数,该函数的参数为一个::google::protobuf::Message 类型的指针,用于承接解析出来的Protobuf 数据。
动态解析部分的核心代码如下:

2.3 转换方法
2.3.1 问题分析
得到Protobuf 格式的消息对象后,需要对消息对象中的数据进行解析,并按照JSON 格式构建数据,转换为字符串类型,写入JSON 文件。
需要用到Protobuf 提供的Descriptor、Field- Descriptor 和Reflection 类的API。
Descriptor 类:描述一种Message 类型(不是一个单独的Message 对象)的meta 信息。可以通过Descriptor 获取任意Message 或service 的属性和方法,包括Message 的名字、所有字段的描述、原始的proto 文件内容。
FieldDescriptor 类:Message 中的每项field 类型的描述类,利用该类就能获得每个field 的名称、类型、属性等信息。
Reflection 类:提供方法来动态访问/ 修改Message 中的field 的接口类,遍历解析其中的每个field 获取对应的值。
解析每个filed 的过程是:首先需要判断field 的属性是否为重复的(repeated),如果是重复的,则需要获取其重复数量和数据类型,依次读取每一项进行转换。重复的field 对应于JSON 中的数组类型,其每一项都转换为数组的一个元素。如果不是重复的,则需要判断是否为可选的(optional)。如果是可选的,则判断这个field 是否设值,有值则进行以下判断:
(1) 如果是布尔、字符串和数值类型,则转换为一个JSON 对象的键值对,key 为field 的名字,由field->name()得到,value 为该field 的值。其中Double、Float 类型对应JSON 中实数类型,Int32、Int64、UInt32、UInt64 类型对应JSON 中的整数类型。
(2) 如果是枚举类型,同样转换为一个JSON 对象的键值对。可以通过getEnum->name()获得字符串,或者getEnum->number()获取其索引值,可以选取任意一项作为value。
(3) 如果是Message 类型,同样对应为一个JSON 对象,其内部的子消息,对应嵌套的JSON 对象。key 是field 的名字,value 则是子JSON 对象,通过递归调用解析函数进行嵌套填充。
需要注意的是,由于Jansson 库不支持二进制字节的字符,当字符串是二进制字节表示时,即类型为FieldDescriptor::TYPE_BYTES,需要转换为十六进制序列。需要遍历所有字节,进行与运算,转为十六进制字符,然后拼接成字符串。使用JSON_dumps 函数将构造好的JSON 对象转换为字符串,并通过ofstream 流将字符串输出到文件中。
2.3.2 主要代码实现
(1)char *pb2JSON(Message *msg, char *buffer)
函数参数:空消息对象msg,二进制数据缓冲区buffer
函数功能:适用于实参是二进制数据buffer,在函数里先进行反序列化成Protobuf 数据,保存在提供的空Message 对象中,然后再进行转换。返回值是JSON 的字符串形式。
(2)char *pb2JSON(Message *msg)
函数参数:消息对象msg
函数功能:适用于实参是解析好的Protobuf 数据,直接对msg 的内容进行转换;其内部功能由以下函数实现:
①JSON_t *parseFromMsg(const Message *msg)
函数参数:消息对象msg
函数功能:对msg 的每个field 进行判断和处理,生成对应的JSON 对象作为返回值。
②JSON_t *parseFromRepeatField(const Message *msg, const FieldDescriptor *field)
函数参数:消息对象msg,field 的描述类对象
函数功能:对判断为重复属性的field 进行解析,利用for 循环对所有项进行处理,返回一个JSON 对象。
③string hexEncode(string binInput)
函数参数:二进制的字符串binInput
函数功能:将每个二进制字符转为十六进制字符,然后拼接成字符串,返回十六进制字符串。
3 实验验证
3.1 环境配置
实验环境为Ubuntu 20.04 LTS,Protobuf 3.11.4,Jansson 2.12,GCC 9.3.0。
首先需要编译安装Protobuf 与Jansson 库,因为本文是基于C 平台的转换工具,因此需要GCC 环境,安装配置过程本文不再赘述。
然后通过Protobuf 编译器编译.proto 文件,生成.h 文件和.cc 文件。通过在C/C++代码中包含.h头文件,可以使用其中的一系列获取、设置字段值等方法为Message 中的字段赋值,编写测试用例。
3.2 正确性测试
为了验证转换的正确性,本文针对三种比较极端的场景进行测试:
(1)定义一条Message,Message 含有很多成员;
(2)定义多条Message,每条Message 不含或仅含较少成员;
(3)多重嵌套测试。
进行正确性测试的目的是测试程序能否正常执行,以及当传递以上3 种情况的信息时,程序能否对每个Message 以及Message 内部的成员进行正确的解析并返回正确结果。
多重嵌套用例如图4 所示,实验表明设置大量Message Type 对象并不影响程序的正确性,解析程序可以正确转换多重嵌套的Message 情况。且由于每个Message 中的成员较少,Message 在处理能力范围内对性能的影响不大,可以保证较好的运行效率。测试结果如图5 所示。
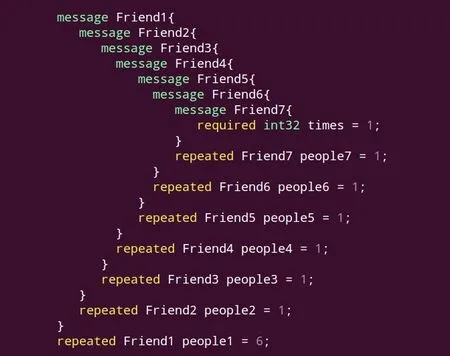
图4 多层嵌套用例Fig.4 Multilevel nested message use case
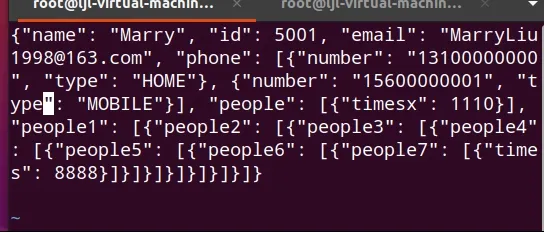
图5 多层嵌套测试结果Fig.5 Conversion result of multilevel nested message
综合分析正确性测试,可以得出结论,我们的解析程序可以对每个Message 以及Message 内部的成员进行正确的解析,且具有较好的稳定性,能够适用于绝大多数的信息转换情形。而且通过测试可以得知,当不同Message 定义有几乎相同的数据结构时,解析时可以相互套用不影响正确性。但是针对多重嵌套,要注意其正确的嵌套格式。
3.3 性能测试
测试解析程序在一次性解析大量数据时的承受能力以及Protobuf 转JSON 的性能。
经过查阅官方文档得知,Protobuf 对于定义的信息文件有默认大小的限制,要解析的数据不能超过默认的64MB,否则会解析失败。
首先测试单次Protobuf 可以转换多大量的JSON数据。该部分测试,我们采用fixed32 类型作为多次重复传递的消息,因为fixed32 类型在Protobuf 的定义中为固定的4bytes大小,方便我们计算一次传输的数据量。
3.3.1 对单条Message 解析测试
利用循环添加1000、10 000、100 000 个fixed32类型数据,每个为4bytes 大小,都由repeated 来修饰,定义的字段可出现0 到多次。数据均成功解析。100 000 条数据均成功解析成JSON 格式如图6 所示。
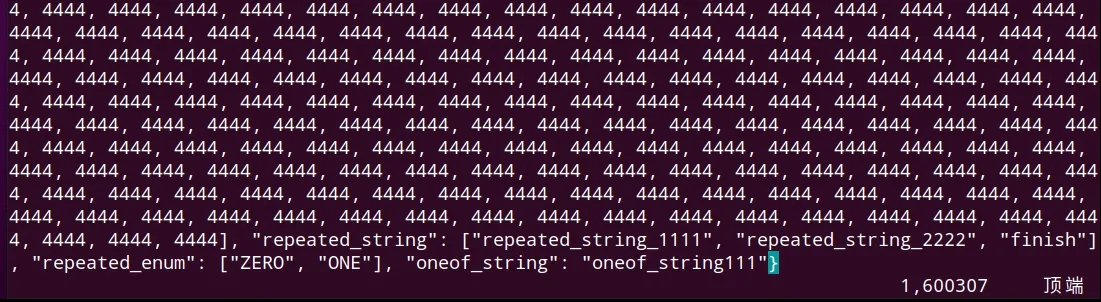
图6 100 000 个fixed32 类型数据执行结果Fig.6 Conversion results for single message with 100 000 fixed32 data
3.3.2 对多条Message 解析测试
同理,利用循环对单次转换多条Message 进行了测试,Message 中包含由optional 修饰的字段数据“123”。 用同样方式测试1000、10 000、100 000 条该定义下的Message,编译执行后,均能成功解析。100 000 条Message 的执行结果如图7 所示,可以看到所有Message 均成功转换为对应的JSON格式。
图7 100000 条Message 执行结果Fig.7 Conversion Results for 100 000 Messages
3.3.3 转换性能测试
我们在生成测试数据的C++文件中定义了一条拥有N 个成员信息的Message 和N 个空的Message,通过控制N 的大小来不断增大数据量。通过在多次测试,得出在Mac 电脑(测试机型配置:i5-8279U,16GB LPDDR3,M.2 固态硬盘)上的平均运行性能,如表1 所示。
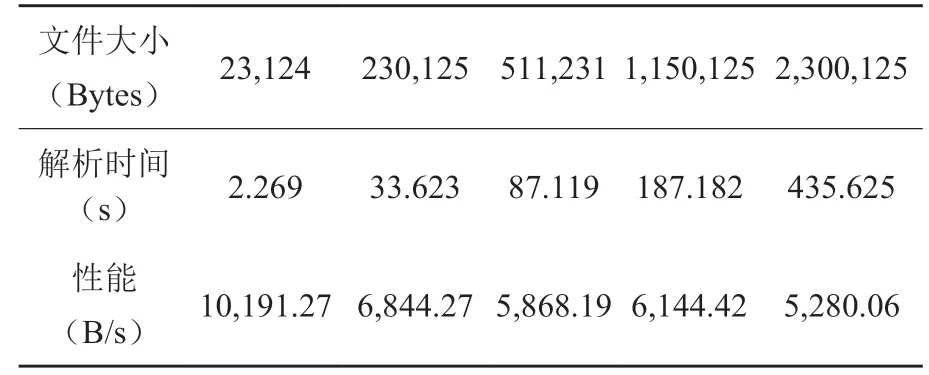
表1 有空Message 时测试结果Table 1 Testing results with null message
我们认为解析N 个空的Message 可能会影响解析速度,因为大量的Message 就意味着需要解析大量的分隔符,而分隔符的定义对于解析批量的Protobuf 数据是不可避免的,所以我们剔除对N 个空的Message 的解析,单纯测试解析一条拥有N 个成员信息的Message 的性能,如表2 所示。
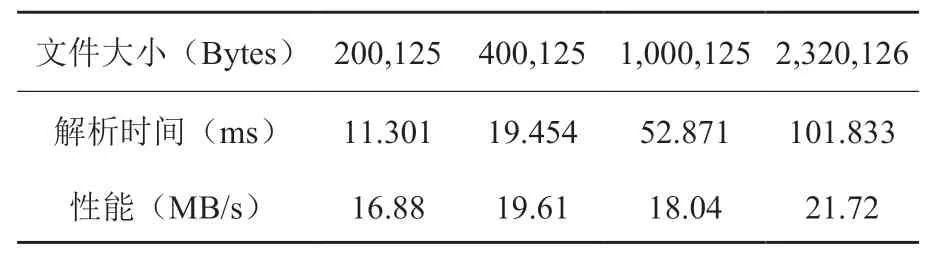
表2 排除空Message 后的测试结果Table 2 Testing results without null message
可以看出,解析一条拥有N 个成员信息的Message 的性能已基本保持线性,可以达到20 MB/s左右,这证明我们解析程序有着很好的纯转换性能。综上可以认为该Protobuf 转换JSON 程序有良好的解析性能,但是信息传输应该尽量使用少次大数据量的Message 来代替使用多次小数据量的Message,从而提升转化效率。
3.4 兼容性测试
上述所有测试都是在Protobuf 2 版本下进行的,本部分测试内容将Protobuf 替换为3.X 版本进行测试。Protobuf 3 移除了“required”类型的字段,因为 required 字段通常被认为是有害的且违反了 Protobuf 的兼容性语义,并用“singular”来替代原本的“optional”。字段的默认值只能根据字段类型由系统决定,而不能使用 default 选项为某一字段指定默认值,对于枚举类型,默认值必须为0。
针对proto3 的特性重新进行测试,程序能够正确地完成Protobuf 到JSON 的转换。所以,本文提出的转换方法同样适用于Protobuf 3 版本,支持转换Protobuf 3 所提供的所有数据类型,具有很好的兼容性。
4 结论展望
本文基于动态解析技术与类型反射技术,实现了一种便捷的Protobuf 与JSON 转换的方法。经过测试,该方法稳定性好、兼容性佳、性能稳定,可以胜任实际生产需要。需要指出得是,本文的各项测试仅在单线程下,若开启多个线程同时进行转换,转换效率将会进一步提高。
本文的实现存在一定的局限性, 如Protobuf 间隔符有极小概率会与消息内容产生冲突且对转换效率有一定影响,在接下来的工作中可以设计使用具有固定字长的分隔符,能在一定程度上解决上述问题。
利益冲突声明
所有作者声明不存在利益冲突关系。
猜你喜欢
四川职业技术学院学报(2022年5期)2022-11-16
中等数学(2021年8期)2021-11-22
甘肃教育(2020年14期)2020-09-11
中学生数理化·七年级数学人教版(2020年4期)2020-08-10
电子技术与软件工程(2020年4期)2020-06-10
数学大王·低年级(2019年10期)2019-11-25
语文世界(小学版)(2018年3期)2018-03-22
商周刊(2017年12期)2017-06-22
福建中学数学(2016年7期)2016-12-03
中学教学参考·语英版(2016年6期)2016-07-07
