
基于MFCC,MODGDF和支持向量机的环境音识别研究
2020-12-01 03:04任立勇何永彬贺茜于永斌刘思怡
河南理工大学学报(自然科学版) 2020年6期
任立勇,何永彬,贺茜,于永斌,刘思怡
(1.电子科技大学 信息与软件工程学院,四川 成都 610054; 2.四川长江职业学院,四川 成都 610106)
0 引 言
为了应对低级特征和高级语义内容之间的语义鸿沟,环境音识别在多媒体搜索的许多应用中发挥着重要作用[1]。音频数据携带着大量日常环境及发生在其中的物理事件信息,人们可以根据音频数据中的环境音大致分辨出其所处的环境,如热闹的街道、安静的办公室等。然而,对智能系统而言,仍然需要研究人员进行大量的环境音识别研究,才能使智能系统可靠地识别环境音,进一步有效地分辨出所处的环境。
环境音是非结构化的,并且具有类似噪声的特性和平滑的频谱,这就使通常应用于音乐和语音数据的识别方法不适用于识别环境音。与音乐和语音信号相比,环境音的识别更难,其原因是在现实生活环境中,音频数据中语音和音乐具有相对较高的能量,而环境音通常包含在这些声音的背景中,具有较低的能量。因此,与音乐和语音信号相比,环境音的特征提取和分类更受研究人员的关注。
特征参数选取是环境音识别的关键,特征参数提取的好坏直接影响到环境音识别的精度。常用的特征参数有MFCC,LPCC,GDF,等等,其中MFCC充分考虑人耳的听觉特性,具有良好的识别性能,但是只包含幅度谱信息。GDF考虑了相位变化随着频率变化的快慢程度,但是只包含相位谱信息。由于特征提取参数的单一化,不能全面覆盖音频所包含的信息,所以考虑将提取的参数进行互补作为环境音的特征参数。
本文在现有环境音识别技术基础上提出一种采用MFCC和MODGDF[2]联合作为特征参数,并使用主成分分析(principal component analysis,PCA)对联合特征进行降维,再利用多分类SVM进行环境音识别的方法。将本文方法的识别效果与DCASE 2017及DCASE 2018数据集的基线系统识别效果进行比较,整体识别准确率有明显提升。
1 相关工作
为了使智能系统能够充分利用音频文件,智能系统不仅需要识别作为指定任务的语音和音乐,而且还需要可以识别日常环境中的一般声音。为了激发该领域的研究,2013年IEEE音频和声学信号处理技术委员会提出对声学场景和事件的检测及分类(DCASE)进行研究,并提供了IEEE AASP Challenge(DCASE 2013)数据集[3]。之后的2016—2018年也相继提供DCASE 2016—2018数据集[4-6]。到2018年底,该领域吸引了全球超过80多个国际团队进行研究。
环境音识别的目的是为音频流选择语义标签以表征音频流的声学环境。关于环境音识别的相关工作以前主要是关注从单声道信号中提取特征,一般采用MFCC作为参数。在环境音识别领域,A.Kumar等[7]分别提出基于神经网络和支持向量机的2个框架来解决环境音识别问题;M.A.Ling 等[8]提出MFCC-HMM方法,对日常环境中的10种不同音频事件进行分类。他们使用MFCC参数和HMM分类器,整体识别准确率较高。但由于当时还没有标准的数据集,所以他们自定义数据集中的样本数量不够多,也不够全面;S.E.Kucukbay等[9]提出MFCC-SVM方法,该方法通过分析改变Mel系数的数量以及优化SVM参数以对环境音进行识别,但是准确率不够高;M.Valenti等[10]、M.Valenti等[11]提出CNN实现基于卷积神经网络(CNN)的模型来识别环境音,由于最近两年深度学习快速发展,使得识别效果好于传统方法,但是系统过于复杂;I.Trowitzsch等[12]提出基于弱监督学习(WSL)提取双通道音频的特征,使用CNN深度模型,能够与使用全监督数据训练的方法一样准确识别环境音,但对纯净的环境音识别性能大幅下降。
2 识别原理及流程
本文的目标是在DCASE数据集上进行环境音识别,主要过程首先是将DCASE 2017数据集和DCASE 2018数据集录制的音频文件输入环境音识别系统,系统将对音频文件经过特征提取,得到MFCC和MODGDF特征参数,其次使用SVM进行特征分类,最后把训练或测试的识别结果输出,总体设计图如图1所示。
3 特征提取及分类
特征提取是将音频文件采样数据转换为具有明显物理意义或者统计意义的特征。音频特征提取有多种方法,如MFCC,LPCC,GDF,等等,考虑到人耳的听觉特性以及短时相位谱在环境音处理应用中的意义,本文选取MFCC和MODGDF作为特征参数。
3.1 MFCC特征提取
MFCC是梅尔频率倒谱系数,是一种能具有良好识别性能和抗噪能力的参数,正因为如此,MFCC是许多识别系统最佳的参数。MFCC是由滤波器组频谱的离散余弦变换(DCT)产生的,在提取MFCC参数中完成2个过程,即倒谱计算和梅尔缩放。MFCC方法依赖于短时分析和每帧的矢量特征。12~14个参数就足够表示这些特征,本研究MFCC提取参数个数为14,其中 12 个静态特征,1 个能量特征和1个一阶差分系数。MFCC参数的提取及计算过程如图2所示,具体如下。

图1 总体设计图
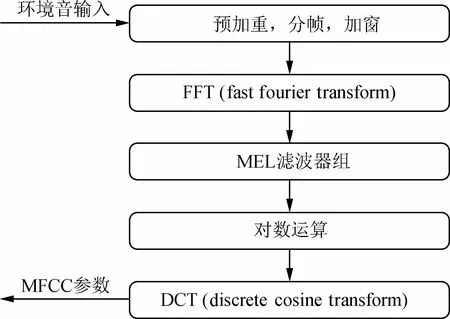
图2 MFCC参数提取过程
(1)预加重。通过一个高通滤波器,使信号频谱变得平坦,不易受到发音系统所抑制的高频部分带来影响。
H(z)=1-μz-1,
(1)
其中,μ的值介于0.9~1.0间,本研究取0.97。
(2)分帧。将N个采样点集合成一个观测单元,称为帧。通常情况下N的值为256或512,涵盖的时间为20~30 ms,本研究取N=256。
(3)加窗。为了使音频帧的两端不引起急剧变化而平滑度过,将每一帧乘以汉明窗,以增加帧左端和右端的连续性。
(4)离散傅里叶变换。由于信号在时域上的变换通常很难看出信号的特性,所以通常将它转换为频域上的能量分布以便观察,不同的能量分布,代表不同环境音的特性。对每帧信号s(n)经过离散FFT变换得到离散功率谱。
(5)Mel滤波器组。将离散功率谱通过M个梅尔尺度的三角形滤波器组,三角形滤波器的主要作用是对频谱进行平滑化,消除谐波和突显原先音频信号的共振峰。
(6)对数运算。计算每个滤波器组输出的对数能量L(m),
0≤m≤M。
(2)
(7)离散余弦变换DCT,得到MFCC系数,
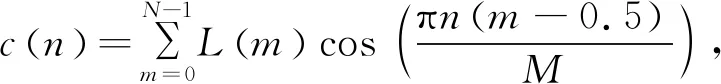
(3)
其中,n=1,2,…,L,求出L阶的MFCC参数。L阶指MFCC参数阶数,本文取12。
(8)计算当前一帧的能量和其一阶差分系数,添加到MFCC参数尾部,即得到14位的MFCC特征参数。
最终得到的MFCC特征值是一个n维14列的矩阵,该矩阵的行数由音频信号的长度决定,列数由算法中使用的滤波器组的个数决定。特征矩阵中的行向量对应音频信号在某一时间段的频率特征。因此,特征矩阵的列数是固定的,行数是可变的。即可能存在音频长度太长导致参数矩阵行数过大的问题,所以引入PCA进行降维处理。
3.2 MODGDF特征提取
MODGDF的设计是通过将负导数应用于相位以提取最佳参数。方程(4)定义了修改群延迟函数,是描述相位变化随着频率变化快慢程度的量。

(4)
其中,

(5)
式中:下标R和I分别为实部和虚部;S(ω)为 |X(ω)|的平滑版本。
由于基音周期性效应,传统的群延迟函数无法捕捉到音频频谱的共振结构和动态范围,为了减少共振峰性质,对GDF进行修改,并将其称为修正群延迟函数MODGDF,恢复了音频频谱的动态范围。在改进的GDF中定义了2个新的参数α和γ。引入的新参数范围都为0到1。为了从MODGDF中提取特征,采用离散余弦变换(DCT)将MODGDF变换为倒谱系数,即

(6)
式中:Nf为DFT序列;τx(k)为群延迟函数,DCT作为一个线性去相关器,它允许使用对角线协方差来建模说话人矢量分布;c(n)为n维16列MODGDF特征值,与MFCC同样原因,需引入PCA进行降维,降至与MFCC一样的维数。
3.3 PCA降维
PCA的基本思想是从一组特征中计算出一组按重要性从大到小依次排列的新特征,它们是原有特征的线性组合,并且新特征之间不相关,计算出原有特征在新特征上的映射值即为新的降维后的样本。本研究使用PCA降维将MFCC和MODGDF特征值降至10维的矩阵,实现流程如下:
(1)输入数据,X为p维的n个列向量。
(2)数据中心化,

(7)
(4)对协方差矩阵Σ进行特征值分解,得到特征值λ1≥λ2≥…≥λp,选择前k个特征值所对应的特征向量,构成投影矩阵:W={w1,w2,…,wk},wi为p维列向量。
(5)将原样本投影到新的特征空间,得到新的降维样本,X′=WTX,X′即为k×n维矩阵。
结合MODGDF和MFCC为一组特征值,可用于作为环境音识别的特征集[13]。MFCC特征反映的是幅度谱的信息,而MODGDF特征则是反映相位谱的信息,二者存在互补关系,所以将MFCC特征参数和MODGDF特征参数进行合并,得到特征数据。特征数据结合了MFCC和MODGDF的特点,在一定程度上提高了环境音识别的效果。
3.4 SVM特征分类
由于模式识别应用的成功[14],该实验选用SVM进行特征分类。LIBSVM是由Chih-Chung等[15]实现的一种机器学习方法,是一种非常有用的数据分类技术。它的主要思想是:建立一个最优决策超平面,使所有数据到这个超平面的距离最小。对于一个多维的样本集,系统将随机产生一个超平面并不断移动,直到样本集中属于不同类的样本点正好位于该超平面的两侧,这样的超平面可能有很多个,而SVM将在保证分类准确的同时,寻找到一个最优超平面,使超平面两侧的空白区域最大化,从而实现对线性可分样本的最优分类。
目前有很多种不同的分类技术,例如模式识别、统计、人工神经网络、Nave Bayes和WPD等。大多数研究者认为SVM比神经网络等更容易使用,和神经网络等[16]其他分类方法相比,支持向量机算法的优点是不需要很多样本,可以解决小样本情况下的机器学习问题,并且结构风险小,算法最终将转化为一个二次型寻优问题,同时可以解决非线性问题等。
考虑到数据集里需要分类的样本并不是很多,而SVM具有小样本分类性好的优点。本研究采用SVM分类方法将特征矢量进行训练分类,之后用于环境音识别。分类需进行2个阶段,即训练阶段和测试阶段,使用了径向基内核RBF核函数以及基于二叉树的SVM分类器。训练阶段将环境音训练集的联合特征参数(MFCC+MODGDF)输入到SVM中,得到分类模型;测试阶段则将环境音测试集的联合参数输入到SVM中,SVM则根据分类模型给出测试集样本分类的结果。SVM 的最终决策函数只由少数的支持向量所确定,这不仅可以帮助抓住关键样本、去除冗余样本,而且具有较好的鲁棒性[17]。
4 结果与分析
4.1 数据集的选择
为了评估所提出的方法,本文采用DCASE 2017和DCASE 2018数据集进行实验,其中DCASE 2017数据集包含15种环境音,即bus,cafe/restaurant,car,city,forest,grocery store,home,lakeside beach,library,metro station,office,residential area,train,tram和urban park,每个音频文件时间长3~5 min,然后将原始录音分割成30 s和10 s的片段;DCASE 2018数据集包含10种环境音,即airport,indoor shopping mall,metro station,pedestrian street,public square,street with medium level of traffic,travelling by a tram,travelling by a bus,travelling by an underground metro,urban park,每个音频文件时间长5~6 min,将原始录音分割成10 s的片段。分别将每个数据集按比例划分为训练集和测试集,随机选取2/3作为训练数据,剩余1/3作为测试数据。
4.2 实验方法
实验中首先对各个数据集的所有音频文件分别进行MFCC和MODGDF特征参数提取,并且使用PCA对特征参数进行降维,以便进行参数合并;其次利用SVM分类器对提取的特征进行分类。
为了直观表现本文提出的MFCC+MODGDF-SVM方法的性能,本实验对每个数据集分别进行了4项对比实验。第一项实验:提取音频文件的MFCC特征参数,再用带有径向基内核(RBF)的支持向量机(SVM)通过LIBSVM实验库实现分类,也就是Mustafa Sert 等提出的MFCC-SVM方法;第二项实验:重现DCASE 2018测试集的基线系统的识别方法,即CNN识别方法;第三项实验:提取音频文件的MODGDF特征参数,然后利用SVM进行分类;第四项实验:合并第一项实验、第三项实验的特征参数,再使用SVM实现分类。
4.3 实验结果
图3 和图4 分别展示了MFCC-SVM方法、CNN识别方法、MODGDF-SVM方法和MFCC+MODGDF-SVM在DCASE 2017和DCASE 20182个数据集上的识别率。根据图3和图4中的数据可以得出,在DCASE 2017和DCASE 2018数据集上MFCC+MODGDF-SVM方法的平均识别率分别为85.6%和85.5%;MFCC-SVM方法的平均识别率分别为72.8%和70.3%;MFCC-SVM方法的平均识别率分别为72.8%和70.3%;MODGDF-SVM方法的平均识别率分别为67.3%和64.7%;CNN方法的平均识别率分别为74.8%和59.7%。根据图3和图4中的折线可以看出,在不同的数据集上,MFCC+MODGDF-SVM方法均优于其他3种方法。最终可以计算出MFCC+MODGDF-SVM方法对环境音的识别率比CNN方法,即基线系统的识别率分别高10.8%和25.8%。
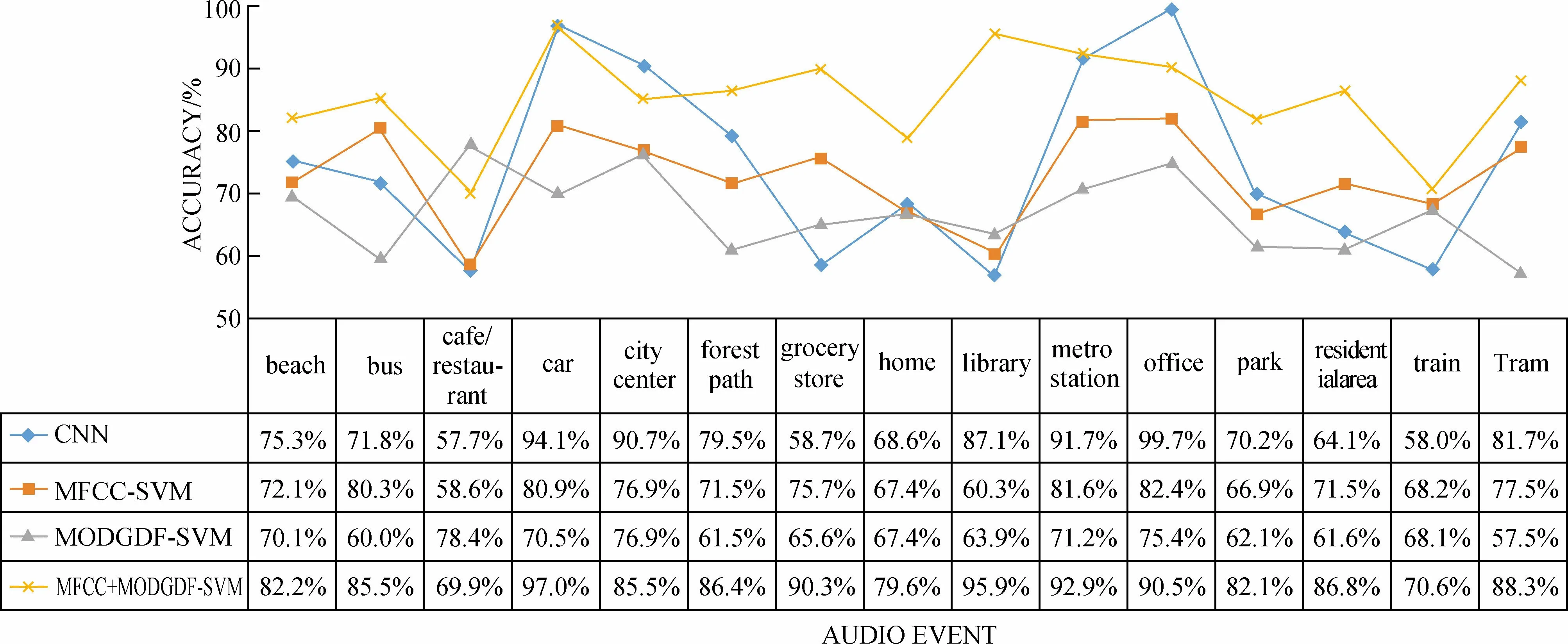
图3 MFCC-SVM,BASELINE SYSTEM和MFCC+MODGDF-SVM在DCASE 2017数据集上的识别率对比

图4 MFCC-SVM,BASELINE SYSTEM和MFCC+MODGDF-SVM在DCASE 2018数据集上的识别率对比
5 结 论
本文提出一种新的环境音识别方法,采用联合MFCC和MODGDF作为特征参数,并使用PCA对联合特征参数进行降维,最后使用SVM分类器对特征参数进行分类,达到识别环境音的目的。实验结果表明,与CNN识别方法、MFCC-SVM和MODGDF-SVM 3种方法相比,本文提出的方法能够达到较好识别环境音的目的,并且相比于CNN方法,环境音的识别率平均提升约18.3%。但在现实环境中,各种环境音彼此相互混叠干扰,容易混淆。因此,未来可继续拓展本文提出的方法,争取在复杂现实环境中,能够对环境音实现准确识别。
猜你喜欢
舰船科学技术(2022年10期)2022-06-17
空间科学学报(2020年1期)2021-01-14
杭州电子科技大学学报(自然科学版)(2020年6期)2020-12-03
中国交通信息化(2019年12期)2019-08-13
中国听力语言康复科学杂志(2019年3期)2019-06-24
家庭影院技术(2018年11期)2019-01-21
电子制作(2018年19期)2018-11-14
中国高新技术企业(2017年5期)2017-05-05
电子制作(2017年9期)2017-04-17
物联网技术(2016年11期)2017-01-12
