
基于GMM-HMM 的语音识别垃圾分类系统
2020-11-02 07:49邓江云李晟
现代计算机 2020年26期
邓江云,李晟
(江西理工大学理学院,赣州341000)
0 引言
近年来,随着经济社会发展和物质消费水平大幅提高,我国垃圾产生量迅速增长,不仅造成资源浪费,也使环境隐患日益突出,现有的垃圾分类装置主要为四色分类垃圾桶,现有的垃圾分类装置存在只是简单地通过文字标识提示了每种垃圾桶需要投放的垃圾大类。并不能直观、细致地指示出具体垃圾种类的投放位置,导致垃圾分类推广存在困难的问题。为解决该问题,本文设计并实现了一种基于语音识别的垃圾分类分装置,通过投放者与装置之间的语音交互,即投放者只需说出待投放的垃圾名称,装置便可以自动识别需要投放的垃圾类别,同时引导投放者将垃圾投放如正确的垃圾桶中。而隐马尔科夫模型(Hidden Markov Model,HMM)提供了一种统计学模型,该模型对过程的状态预测效果良好,适宜系统的短期状态预测,因此可使用HMM 原理对字数较少的中文垃圾词汇的识别模型进行建模。本设计先利用MFCC 对采集到的原始语音信号进行特征提取,再利用HMM 模型建立语音识别模型,其中利用混合高斯模型(Gaussian Mixture Model,GMM)拟合语音特征向量的概率密度分布函数。将提取的特征样本分为训练样本集和测试样本集,利用训练样本集训练HMM 模型,利用测试样本集测试训练模型的识别准确率。最后通过一个实例验证了设计的有效性。
1 语音识别基本理论
语音识别的目的是将声音信号转换为文本文字,也就是输入一段语音信号,输出对应的文本。一般的语音识别系统并不能直接识别原始的数字语音信号,需要先将语音信号的特征向量提取出来再进行识别。识别流程图如图1 所示。

图1 语音识别系统流程
将语音数据库中的原始语音数据进行预处理、特征提取后得到的特征向量作为训练样本进行无监督学习,得到HMM 模型参数,最后将模型参数带入测试样本,求解最大输出概率,从而得到识别结果。
1.1 语音信号预处理
一般的原始数字语音信号往往包含各种噪声,包括说话人唇齿碰撞的低频噪声,还有语音采样装置的电流毛刺,加上说话声音的大小都会影响到语音信号识别结果,所以在进行特征提取之前按,我们需要先对语音信号进行一些预处理,预处理流程图如图2 所示。
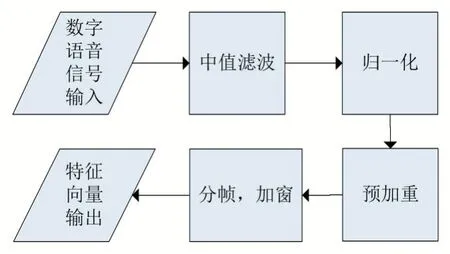
图2 预处理流程
预处理总共分为4 个步骤:中值滤波,归一化,预加重,分帧与加窗。中值滤波的目的在于消除由于语音采样电路本身性质引起的冲激信号、毛刺等噪声。

其中x 表示语音数据向量,median 表示求括号中数据的中位数。
归一化的目的是为了消除由于声音振幅的大小对特征提取产生的影响,是音频信号映射到同一区间[-1,1]。
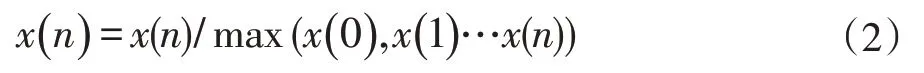
为了消除声音由唇与声带产生的低频噪声,将数字语音信号通过一个高通滤波器,这一步称为预加重。高通滤波器的系统函数与时域表达式分别为:

研究表明[1],a 的取值范围在0.93 到0.98 之间。
一般情况下,语音信号是在不断变化的,为了简化建模,假设语音信号是短时稳定不变的。分帧处理的目的就是将数字语音信号分割为帧长为15~25 毫秒的帧,为了让帧与帧之间平滑过渡,相邻两帧会有一个重叠部分,重叠部分称为帧移。一般情况下,帧移为帧长的(0,0.5)倍长度之间[1]分帧信号如图3 所示。
在经过分帧处理后,每一帧的截断处是不平滑的,不利于后续处理。解决办法是使用窗函数对截断处的不连续变化进行平滑,减少泄露,降低傅里叶变化后旁瓣强度,将能量集中在主瓣内。常用的窗函数以及对应基本指标如表1 所示。

图3 语音信号分帧
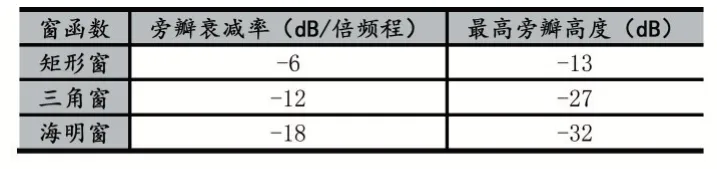
表1 窗函数指标
处理语音信号一般采用边界平滑下降的海明窗[2],海明窗函数W(n)表达式为:
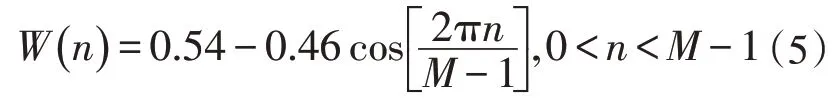
加窗处理方式为:

1.2 语音信号特征提取
(1)MFCC 原理
根据人耳听力对频率的敏感度是非线性的,定义一种符合人耳听觉敏感度的频率:梅尔频率Fmel:

人耳的耳蜗结构相当于一组MEL 滤波器组,其传递函数Hm(k)为:

f(m)表示第m 个三角滤波器的中心频率。利用MATLAB 绘制梅尔滤波器组,如图4 所示。
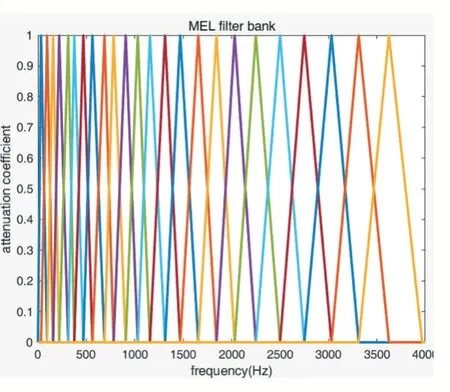
图4 梅尔滤波器组
该图体现了不同频率信号通过梅尔滤波器组后的衰减程度(横坐标代表频率,纵坐标代表衰减系数),该滤波器组由24 个梅尔滤波器线性相加构成。
(2)特征提取流程
基于MFCC 的语音特征向量提取流程如图5所示:
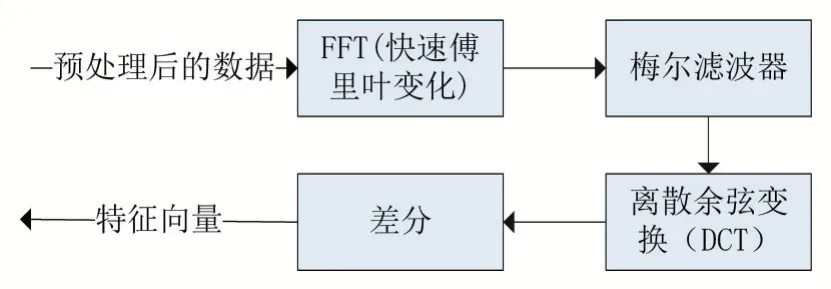
图5 特征向量提取流程
由于梅尔滤波器是在频域上处理语音信号,所以需要先通过(FFT)快速傅里叶变换将每一帧语音数据由时域信号转换为频域信号:

将转换后的数据通过梅尔滤波器组Hm(k),即可得到语音特征向量Y。此时的特征向量已经可以用于训练与识别,但由于每一帧语音包含的采样点数较多(一般为200 到1000 个左右),用于训练或识别会大大提高运算量,降低系统的实时性。本文的解决方法是利用离散余弦变换(DCT)压缩特征向量信息:

其中,m 为13 维向量[3]。考虑到实际语音信号是动态变化的,而每一帧语音是假设短时不变的,所以我们需要一个指标来表示语音的动态变化性质,一般通过计算每一帧特征向量m 的一阶差分与二阶差分来实现[4]:

2 基于GMM-HMM的语音识别模型
2.1 GMM-HMM模型原理
HMM 是比较经典的机器学习模型,在自然语言处理,模式识别等领域都有着广泛的用途,一般用于解决含有两类数据(观测序列,状态序列)的问题,该模型由俄国科学家马尔科夫提出[5],目的是解决统计过程中状态和行为之间的“联动性”,即某个行为的发生与不同状态之间存在特定的概率关联。

图6 隐马尔科夫模型
如图6 所示,{1,2,3}为模型状态序列,而{O1,O2,O3}为模型观测序列。状态之间可以相互进行转换,其转换结果由状态转移概率矩阵决定。而每一种状态可以同时对应多种观测值,其中离散的对应关系使用观测概率矩阵表示,连续的对应关系则使用概率密度函数表示。HMM 的参数及其含义如表2 所示。
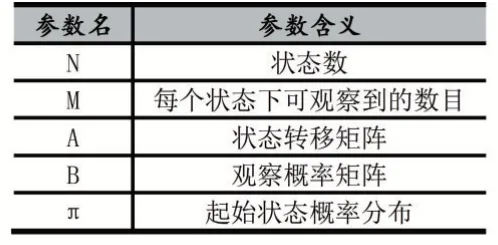
表2 隐马尔可夫模型参数及其含义
混合高斯模型(Gaussian Mixture Model,GMM)是一种统计学模型[7],可以用来表示在总体分布中含有K个子分布的概率模型,表示了观测数据在总体中的概率分布,由K 个子分布组成的混合分布,而每一个子分布都遵循高斯分布,理论上混合高斯分布可以用于拟合任意分布的样本,因此本文使用GMM 拟合语音特征向量的分布情况,其概率密度函数为:

其中,μ为数据均值(期望)向量,Σ 为协方差矩阵,D 为数据维度。
前后向算法用于解决HMM 模型三大问题中的参数学习问题。求解前后向概率的公式为:
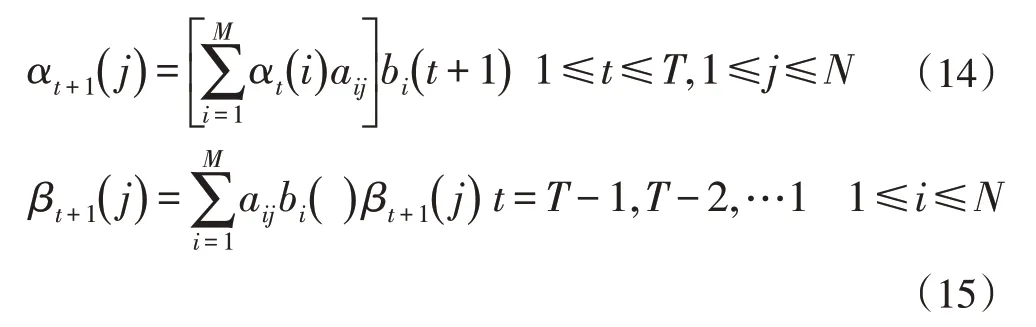
前向概率αt(j)表示在t 时刻,状态为j 且观测序列为{o1,o2…,ot-1,ot} 的概率。后向概率βt(i)表示在t时刻,状态为j 的且从t+1 时刻到T 时刻的观测序列为{ot+1,ot+2…,oT}的概率。其中aij表示状态转移概率矩阵,bj(t)表示观测概率矩阵。
2.2 孤立词识别算法
在基于HMM 建立的孤立词模型当中,经过MFCC提取出的特征向量序列为状态序列,而文本信息为观测值。由于在孤立词的HMM 当中,一段语音信号仅仅对应了一个观测值,所以求解最大概率并识别的方式为遍历每个孤立词模型,求解出概率最大的模型对应的词汇,流程如图7 所示。

图7 孤立词训练与识别流程
本文采用了无监督学习的方法进行模型的训练。利用K 均值算法将每一个孤立词分为4~6 种状态[6],通过最大期望(Expectation-Maximum,EM)算法求状态之间的转移概率矩阵。状态转移概率矩阵与前后向概率向量之间的递归公式[7]为:
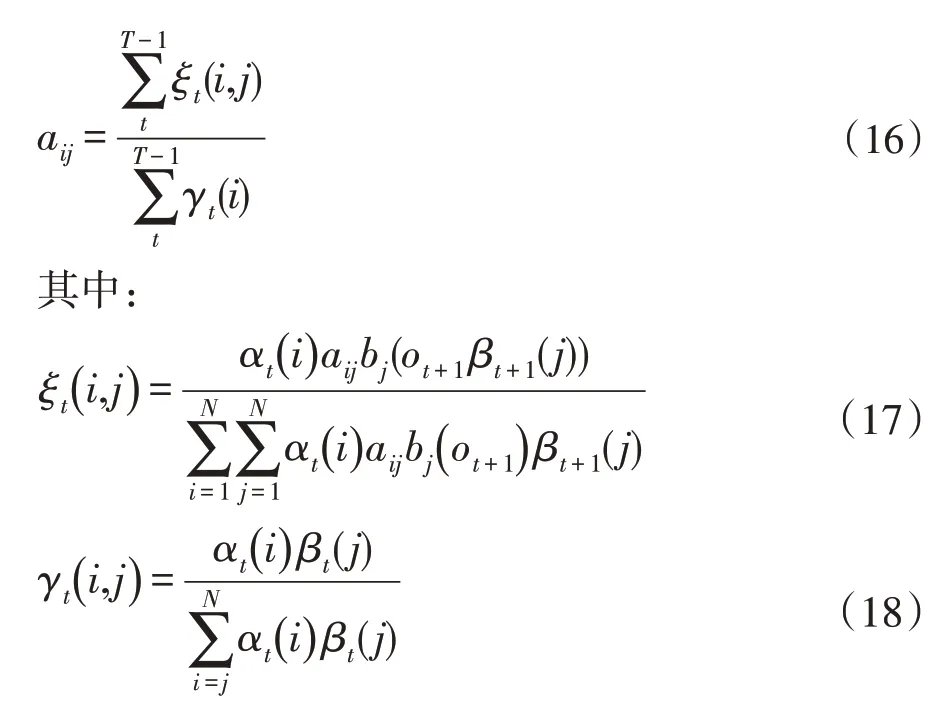
由于语音信号受情绪、环境影响较大,不同的人音调、音色也存在许多差异,导致同一个词汇存在无数种与之相对应的语音波形。使用观测概率矩阵B 来作为语音特征状态与观测值之间的对应关系是不切实际的,所以本文采用GMM 来拟合语音特征观测向量的分布情况,使用多维混合高斯分布密度函数P(X|θ)来代替(4-5)中的bj(ot+1),其中X表示第(t+1)帧的语音特征向量,θ表示第状态j 对应的GMM 参数。
利用递归与重估的方式训练参数往往都需要一个指标来判断是否完成训练,本文采用最大输出概率作为该指标。当连续两次重估之后最大输出概率之差小于10-6时,训练完成。重估参数流程如图8。
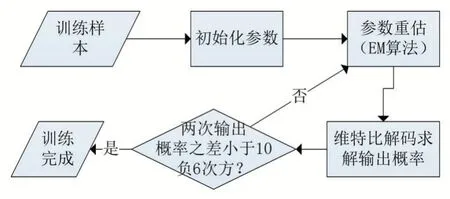
图8 参数重估流程
维特比解码是在给定一段观测序列时,需要找到一条最佳路径使得该路径上的状态序列转移为改观测序列时概率P*最大,P*即为最大输出概率。在完成对HMM 模型训练之后,使用维特比算法求解测试样本相对于每一个孤立词模型的最大输出概率,比较得到概率最大的模型即可完成识别任务。
3 实例分析
现有的国家标准将垃圾分为四个大类,分别是可回收垃圾、厨余垃圾、有害垃圾、其他垃圾,本文对每一种类各选择了3 个词汇进行识别实验。采用MATLAB完成对孤立词语音模型的训练和识别。

图9
首先通过函数audioread 读取出wav 文件当中的数据,其调用方式为:

其中x 为数字音频信号向量,fs 为采样频率,fname为文件名称。由于人类发声的频率范围一般在80Hz~3400Hz,由采样定理可知采样频率应当为信号最高频率的两倍以上,所以这里fs 一般取8000Hz。提取出数据之后,采用自定义函数MFCC 对语音信号进行特征提取
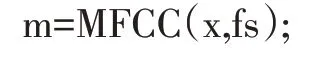
输出参数m 表示语音信号特征向量,原始语音信号波形以及对应特征向量波形如图10。

图10 语音波形
特征提取完成后,通过自定义函数tran 进行训练,其调用方式为:

Samples 为元胞型数据,包含了一个孤立词所有训练样本的特征向量,而Hmm_mode 是一个存储模型参数的结构体变量。训练完成之后,使用自定义函数vit⁃erbi 求解测试样本的特征向量对于每一个孤立词模型当中的最大输出概率:

输出概率最大的模型对应的词汇文本即为识别结果,如图11 所示。

图11 训练过程
完成训练之后,设计GUI 界面用于进行实验验证,如图12 所示。通过“音频选择”按钮选择PC 上的音频文件,点击“开始识别”按钮即可完成识别。

图12 GUI界面
本次实验共测试了10 个人的语音样本,其中男生女生各5 人,测试结果(识别正确率)如表3 所示。

表3 语音识别结果统计表
实验结果表明,总体识别正确率可以达到93.5%,说明本文设计的有效性和可行性。
4 结语
本文设计并实现了一种基于HMM 的语音识别垃圾分类系统,该系统通过语音交互自动识别垃圾种类信息,并指导垃圾的分类投放。该系统采用统计学习方法中的HMM 模型对语音信号进行建模,相比于一般的机理建模,该方法可以通过不断增加训练样本来提高识别率,识别不同的词汇时也无需重新建模,只需更新训练样本即可,这在社会发展迅速,有关垃圾的新兴词汇不断增加的背景下显得尤为重要。经过实验验证,本设计识别率高,可以为我国垃圾分类的智能化提供有效的技术支持。
猜你喜欢
客联(2022年4期)2022-07-06
成都信息工程大学学报(2022年2期)2022-06-14
保定学院学报(2022年2期)2022-04-07
国际太空(2021年11期)2022-01-19
中学生理科应试(2021年11期)2021-12-09
地理教育(2019年1期)2019-03-06
数学学习与研究(2018年15期)2018-11-12
中国化妆品(2017年12期)2017-06-27
智能计算机与应用(2016年1期)2016-03-02
中学数学研究(2008年11期)2008-01-05
