
微信电商平台搜索及推荐系统的接口实现
2020-11-02 07:49李沂洋赵浩东王祖浩尹宝鑫刘劲男
现代计算机 2020年26期
李沂洋,赵浩东,王祖浩,尹宝鑫,刘劲男
(长春理工大学计算机科学与技术专业,长春130022)
0 引言
实体识别[1]在自然语言处理方面有很广泛的应用,它指的是识别一段文本中具有特定意义的实体,例如地名、人名、组织机构名称等一些具有实际含义的实体。自然语言处理技术多用于和用户行为相关的交互功能方面,例如对于用户输入文本框内容的分析就可能会用到实体识别技术,对于用户的评论就可能会用到情感分析方面的技术。
目前,有很多种方法可以实现实体识别,但针对于不同的应用场景,不同的算法之间存在一些原理与实现效果上的差异。其实很早之前的命名实体识别方法是基于规则原理的,后来由于基于数据规模庞大的语料库的统计方法广泛应用于自然语言处理,与之相对应的一些机器学习的算法也应用于实体识别领域。
这些方法包括有监督的学习方法,例如基于马尔科夫模型、条件随机场等的方法,一些无监督的学习算法也有涉及。当然最重要的是伴随着深度学习逐渐应用于自然语言处理领域,主角BiLSTM(Bi-directional Long Short-Term Memory,双向长短时记忆循环神经网络)+CRF(Conditional Random Field,条件随机场)逐渐成为实现实体识别的主流算法。
在推荐系统方面,协同过滤推荐算法是诞生最早的,比较著名的推荐算法。它通过挖掘用户历史行为数据来识别出用户的偏好。该算法主要分为两个分支,分别是基于用户的协同过滤算法(user-based col⁃laborative filtering)和基于商品的协同过滤算法(itembased collaborative filtering)。
1 命名实体识别
1.1 BiLSTM的使用
既然要模拟实体识别,我们先需要设置实体识别的标签(label),事实上标签的设置种类有很多,这里我们以BIO 标注法为例,即此处设置7 个标签:“O”表示寻常字,“B-PER”表示人名的开头,“I-PER”表示人名的剩余部分(除去开头字的部分),“B-LOC”表示地名的开头,“I-LOC”表示地名的剩余部分,“B-ORG”表示组织的开头,“I-ORG”表示组织的剩余部分。
这些标签标记在我们的语料库中,带有标签的语料库就是我们用于训练的样本,我们通过语料库训练得到词向量。词向量本质是把一组字用低维稠密矩阵来表示,每个字映射对应一个1*维度的向量,表示把这个字投射到多维空间中,而含义相近的字之间的距离更近,由此可以表示字与字之间的关系,这就是词向量的存在意义。传统的one-hot 编码维度太高而且非常稀疏,不合适用来训练模型。
生成词向量的方法有很多,从早期的Word2Vec、ELMo 到最近的BERT,可以说获取词向量的方法越来越合理,对于精确率的提升帮助越来越大。
1.2 CRF与BiLSTM结合
其实CRF 的应用替代了BiLSTM 中Softmax 的地位,我们本可以用BiLSTM 加上激活函数Softmax 来得到一句话中每个字对应七个分类标签的概率值矩阵,标签序列的概率就是序列中每个字对应标签概率的乘积。
但是实体识别的应用环境是一个语义连贯性很强的句子,考虑字与字之间的关系是必不可少的环节,显然Softmax 没法做到这一点。换句话说,其实Softmax无法体现字与字之间的约束关系。举个例子,之前我们定义标签的时候说过,B-PER 是表示人名的开头,IPER 则是人名的剩余部分,显然,几乎不可能出现两个B-PER 标记的字紧挨着出现的情况,但是Softmax 并没有从我们的训练样本中得到这个约束信息,从而导致确定最终分类标签时的干扰信息太多。Softmax 的示意图如图1 所示。

图1[4] Softmax示意图
相比而言CRF 则可以做到这一点,它着重的考虑了上下文关系对于结果的影响,我们在下面会介绍这个约束条件具体在CRF 的哪个环节得以体现,CRF 示意图如图2 所示。

图2[4] CRF示意图
其实我们知道,BiLSTM 最终输出的是每个字对应的标签得分情况,由BiLSTM 得到的标签得分称为发射得分,假设用户输入的句子包含10 个字,以1,2,3,4,5,6,7,8,9,10 为索引。然后为分类标签添加索引如表1 所示。
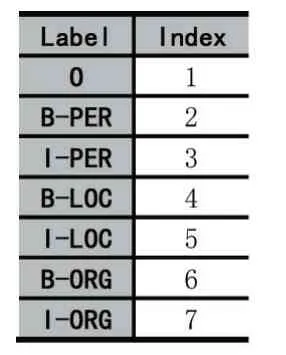
表1 分类标签索引表
因为有10 个字,对应7 个标签,所以该语句的发射矩阵X为10×7 的矩阵,xij表示第i个字对应第j个标签的概率。
CRF 中的转移得分是关键所在,我们用T来表示转移矩阵,tij则表示由第i个标签转移到第j个标签的概率,i向j转移的意思是当前字的标签是i标签,那么其后一个字的标签是j标签这种情况。那么很明显,我们一共有7 个标签,所以转移矩阵是7×7 的矩阵。转移矩阵的关键之处在于,它体现出了我们之前提到的约束关系,例如,t25表示B-PER 标签对应的某个字的后面一个字的标签是I-LOC 的概率,显然我们知道,训练数据中几乎不可能出现这种情况,试想一下,一个人名的开头字后面紧邻的字的标签是一个地名的中间字。这几乎是不可能出现的情况。所以说,可想而知,转移矩阵中t25的数值应该接近于0,这个就很好的体现出了约束关系,Softmax 无法做到这一点。
上面都是对于CRF 所涉及到的一些概念的描述,其实它真正巧妙的地方在于它的算法理念,即寻找一条概率最大的路径。例如我们上面举例一句话有10个字,每个字有7 个标签,每个字有7 种可能,那么这句话总共有7 的10 次方种标签分类组合,每一种成为一条路径。在这里也可以看出Softmax 和CRF 的区别,前者并没有考虑前后,所以在前者眼里,不过是10组7 分类问题,而CRF 是考虑前后关系的,在后者眼里,上面这个问题是1 组710分类问题。
在BiLSTM-CRF 训练过程中,模型会不断更新,从而使得最优路径得分占比变大,即损失函数计算的是得分最高的路径的得分占所有路径得分之和的百分比,是用交叉熵来计算的,其形式为:

Si表示第i条路径的得分,那么所有路径的得分就是:

上式中S的计算主要与之前讲的发射得分和转移得分有关:

即第i条路径得分等于发射得分与转移得分之和。这条路径对应的发射得分和转移得分可以这么计算,假如我们这条路径是这样的:

上述数字为对应的标签index,那么对应该路径的发射得分和转移得分就是:

知道了如何计算最优路径,下一步就是想办法找到最优路径,通常采用维特比算法。它是一种动态规划形式的寻找最优解的算法,可以这么理解,它每次只走一步,每一步都是最优的方案,图3 是维特比算法的图解。

图3 维特比算法图解
如图3 所示,W表示当前要确定标签的字,t1~t3为标签分类,假设有3 类。首先从起点到W1 的标签有3 条路,因为起点到每个点都只有1 条路,所以这三条路我们本次不做删除操作,只有到达同一个结点有很多条路时我们才删除,尽管这三条路有长有短。
然后再看W2,到达W2 对应的t1 标签有三条路,分别来自W1 的3 个标签,我们图中取了最短的一条,如图所示是来自于W1 对应的t2 标签,于是我们删除另外两条路。对W2 对应的t2 和t3 标签做相同处理。这样我们就得到了从W1到W2 的3 条路,以此类推,最终,我们从W3 对应终点的3 条路中选择最短的一条路,即图中所示红色路径,即为最优路径。
纵观整个CRF 的大致流程,我们可以体会出CRF在实体识别方面是优于Softmax 的,并不是说Softmax算法不好,而是在处理各自适合的问题的时候,都有比较鲜明且优越的特点。显然在实体识别方面,CRF 善于结合前后文的特点使得其成为实体标签的分类利器。
2 意图识别
2.1 搜索引擎优化
大多搜索引擎使用的是TF-IDF 的优化模型——BM25 模型,主要针对TF-IDF 逆文档频率对于某些特定状况进行了优化,如下所示:
doc1=“北京东城三环外洋人咖啡馆”
doc2=“北京东城咖啡馆”
例1
当我们进行意图识别时,例如搜索“我想找一家咖啡馆”,两个document 的匹配度对于TF-IDF 是一致的,显然我们不希望内容过于具体,不希望到达doc1那样的精确度,而是能够理解用户想要找到“北京咖啡馆”这样的目的即可,因为这样的不必要的限定会使得搜索精度下降。所以相对于doc1,选择doc2 是更加明智的选择。那么BM25 加入的域长度惩罚机制对于意图识别就有着很大的帮助。

图4[3] BM25主要组成

表2 参数
下面为R=0 后二元独立模型的简化公式:

简化后IDF 公式如式(5)。
当然在搜索引擎中为了保证评分为正,会在对数内部加1:

而第二部分表征的是查询词文档权值,是查询词针对于该文档的权重。fi表示该词在文档中的词频,dl为查询的域的字符串长度,avdl 为所有预字符串的平均长度,主要调参为k1以及b。b 表征的是命中域长度对于整个评分的影响程度,当dl 超过平均域长度时,K值会大于1,则会减小总体评分。这样的惩罚机制正好解决了例1 提出的问题。
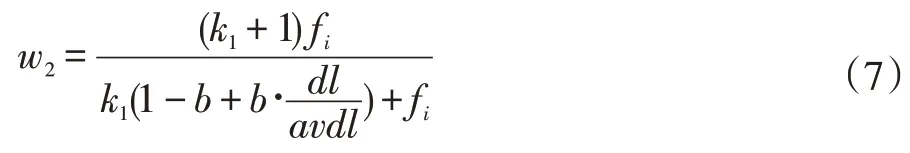
2.2 最低评分阈值评判
最低评分阈值判定对于本模型是必要的,这是衡量搜索引擎能否准确完成意图识别的核心环节。由于同时命中AB 后正确率相比单独命中A 或B 要高得多,在这种情况下无需进行后期模型预测,可以直接从搜索引擎中获取预测结果;而当AB 无法命中时,此时意图识别的准确率将无法保证,甚至多数出现牵强匹配的现象,因此我们需要对上面的评分机制进行优化,以达到明显分离匹配AB 与未匹配AB 的评分,从而有效在准确率与召回率之间进行折中。
对于一个数据量为1000~10W 左右的意图识别库,由于AB 形式的专有名词受限,对于意图识别库来说,大部分情况有且仅有一个名词严格匹配,所以通过简化BM25 计算公式可得:(搜索引擎默认b=0.75,k1=1.2)


但是对于前项w(A)+w(B)的稳定性显然不足,对于大多数情况,ni 的hit 数不会超过N/10,但是随着ni 的大小变化,W 在ni<100 范围内会发生突变(如下图),并且随着数据规模N 的增大峰值会更加明显,这对于衡量最低评分阈值显然不尽人意。

图5 W权重变化图
因此,对于此种情况,我们并不是要将整个IDF 曲线变化完全填平,而是我们在衡量评分阈值的时候进行“削峰”操作,并且不会影响整体的变化趋势,让权重变化不会因为ni 的变化发生突变。因此我们在公式中加入一个IDF 平滑项R(ni),其函数变化与ni(当前分割词命中数)相关:

在大量数据试验下,α=2.2,β=0.1 较为匹配,下面是平滑后的曲线与原始BM25 计算权重比对:

图6 加入平滑引子(N=10w)
明显发现通过加入平滑因子后,整个函数曲线的峰值被削减以及平滑,并且R 对后面的曲线影响并不大,因此我们可以对优化后的曲线进行评分阈值衡量。
现在,对于特定关键词N,我们对于评分的计算公式变为:

此时,设置阈值将会变得简单,此时我们给出阈值计算公式:

W'(N)是数据规模为N 时的无完全匹配项的权重,则avg(W'(N))只是其命中项在100 以下的平均值(此值基本保持在[3.0,3.5]区间内,默认取3.0),再将数据规模带入公式,即可计算动态阈值。
通过以上的相关优化以及创新,我们最终得到了一个考虑到多方面情况,并且灵活、快速的意图识别模型。
3 智能推荐
3.1 模型构建
数据收集选取ELK 作为核心系统,输入数据是用户对于项目的评分,系统依据用户操作类型给予用户评分,具体操作类型包括收藏、购买、评价、浏览、点赞、分享、评论。设定参数λ,日志用户操作数n,用户操作评分S,用户评分Score,使得当前评分计算公式为:

评分采取1-5 分制评分体系,值越大表明用户的喜好程度越高,未评分项目评分均用0 来代替。
本系统选用余弦相似度来作为计算用户相似度的一个判断标准。其公式如下:

上式中,N(i)与N(j)分别表示喜欢物品i 和喜欢物品j 的用户数。使用该方法的好处是可以避免热门物品和很多物品相似的可能性,有利于挖掘长尾信息。为了进一步增加推荐的准确度,提高推荐的覆盖率和推荐的多样性,我们可以进一步将相似度矩阵W进行归一化。

ItemCF 通过如下公式计算用户u 对一个物品j 的兴趣:

N(u)为用户喜欢的物品集合,S(j,K)为与物品j最相似的K 个物品的集合,Wij物品j 和i 的相似度,rui用户u 对物品i 的兴趣。
ItemCF 模型与UserCF 模型实现过程相近,不过考虑到对于电商平台来说,用户数量要远多于商品数量,但很多用户相互之间并没有对同样的物品产生过行为,所以采用倒查表以及引入稀疏矩阵统计不同用户同时拥有的物品数量。
(1)计算用户之间的相似度。
本系统选用余弦相似度来作为计算用户相似度的一个判断标准。其公式如下:

上式中,N(u)与N(v)分别表示有用户u 操作的商品数以及用户v 操作的商品数。使用该方法的好处是可以活跃和很多其他用户相似的可能性。为了进一步增加推荐的准确度,降低热门物品对相似度的影响,对wuv作进一步改进:

其中N(i)表示商品i 的操作人数。
(2)根据物品的相似度和用户的历史行为给用户生成推荐列表。
ItemCF 通过如下公式计算用户u 对一个物品j 的兴趣:

N(i)是对物品i 有过行为的用户集合,S(u,K)为和用户u 兴趣最接近的K 个用户,wuv用户u 和用户v的兴趣相似度,rvi用户v 对物品i 的兴趣。
3.2 基于邻域算法协同过滤模型评估
在基于邻域算法的推荐系统[2]中,有一个重要的参数K,K 越大则基于邻域算法推荐结果就越热门,K 增加会降低系统的覆盖率,对长尾或餐品的推荐越来越少。由于准确率和召回率与K 值不是单纯的正相关和负相关,因此我们可以将准确率和召回率作为模型评估标准,选取合适的K 值。当然,推荐结果的精度对K也不是特别敏感,只要选在一定的区域内,就可以获得不错的精度。
推荐结果的准确率定义为:

其中R(u)是根据用户在训练集上的行为给用户作出的推荐列表,而T(u)是用户在测试集上的行为列表。最终针对不同的K 值,我们可以画出准确率/召回率曲线寻找最佳K 值。
4 结语
本文介绍了有关微信小程序在搜索和推荐系统优化方面可采用的技术模型,其实技术是不断发展的,微信小程序日益发展,必然将带动一系列技术层面的革新与探索,本文借鉴了推荐系统领域比较成熟的协同过滤算法以及实体识别领域的BiLSTM+CRF 模型来为电商所需要的接口模型提供了假设与方案。
猜你喜欢
小学生学习指导(低年级)(2022年5期)2022-05-31
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
智能计算机与应用(2020年4期)2020-08-31
读与写·教育教学版(2017年10期)2017-11-10
小天使·二年级语数英综合(2017年3期)2017-04-01
南都周刊(2015年4期)2015-09-10
南都周刊(2015年3期)2015-09-10
南都周刊(2015年1期)2015-09-10
