
基于RISC-V的近数据计算系统设计方法
2020-10-13 13:27陶常勇高彦钊王元磊张兴明
火控雷达技术 2020年3期
陶常勇 高彦钊 王元磊 张兴明
(1.天津市滨海新区信息技术创新中心 天津 300450;2.解放军信息工程大学 郑州 450000)
0 引言
RISC-V最初是从2010年开始,由UCB的Krste等人开始着手研究的,并于2015年左右最终开发出了一套完整的新指令集,还包括对应的编译器和工具链[1]。在近两年的时间里,RISC-V的发展得到了学术界和工业界的大量关注,UCB已经建立了一个名为Rocket-chipGenerator的开源项目[2],在国内也成立了开放指令生态联盟。RISC-V的优势在于它真正做到了免费开放,并且其指令集丢弃了历史包袱,支持模块化,可高效实现各种微结构和大量定制、加速功能[3]。
在计算密集型和数据密集型的高性能计算中,如果采用冯诺依曼架构的通用处理器完成计算,因涉及到大量的数据需要在ALU和内存之间反复搬移,计算效率会大打折扣[4]。一种可能的思路是将数据与算粒就近放置,实现近数据计算的计算架构。本文根据RISC-V开源架构的特点,结合高性能计算对数据和算粒就近放置的需求,提出了一种基于RISC-V的近数据计算协处理器加速阵列与系统,在文中,首先介绍了乘加计算需求,接着重点描述了协处理器加速阵列的电路和微码表项的结构,紧接着完成了针对该电路的RISC-V自定义指令设计,最后以一个实例对系统进行了定性的评估。
1 近数据计算加速阵列设计
针对有规律的乘累加计算,完全可以将计算过程中的运算部分和控制部分相分离,控制部分在RISC-V的内核中实现,而运算部分在一个协处理器阵列中以流式计算的形式完成。在本部分,我们首先介绍了乘加运算的计算需求,然后完成了协处理器阵列的逻辑结构设计,同时详细介绍了协处理器阵列中微码表项的组织结构。
1.1 乘累加计算分析
在信号处理或深度学习领域中,大量涉及有规律的乘累加计算,比如在矩阵乘法中,其计算公式的基本形态为
其中,i,j的值为0,1,…K;K为矩阵的维数。
再比如在卷积神经网络的卷积运算中,其可能的计算公式[5]
其中,i,j的值为0,1,…N,N为特征图像尺寸;K为卷积核尺寸。
再比如,在基2的某一级FFT运算中,其可能的计算公式为
(3)
其中,i的值为0,1,…,N/2-1;k的取值与FFT运算的基数有关[6]。
通过观察上述公式,对于各种形式的乘累加运算,可总结为如公式(4)的计算格式
yi,j=∑aia,ja·bib,jb
(4)
其中,乘数a的角标和被乘数b的角标ia、ja、ib,jb均是为了描述a和b在矩阵中的相对位置,为了方便硬件处理,假设每个时钟周期完成一次乘加计算,把上述公式中针对乘数a与被乘数b的角标随时钟周期的变化关系转换为四组长度相同的数列来描述,记每组数列的当前值分别为ia_c、ja_c、ib_c、jb_c,每组数列的上一时钟周期的值分别为ia_p、ja_p、ib_p、jb_p。则ia_c、ja_c、ib_c、jb_c的值可由式(5)计算得到
z=x+y+A
(5)
其中,A为一个立即数,x、y描述了参与计算的角标的索引,其取值关系可如下表所示,表中,Null表示当前值索引为数值0,x、y为2’b00时表示选择Null。

表1 乘数与被乘数角标公式选值关系
1.2 近数据计算协处理器阵列
传统的冯诺依曼架构的处理方式需要产生大量的数据搬移,带来了额外的功耗和性能的损失。为此,本文所设计的协处理器阵列采用存算一体的计算结构实现,将待计算数据分散存储在多个RAM块中,并将乘加计算算子尽量靠近RAM放置,如图1所示为协处理器阵列架构框图。
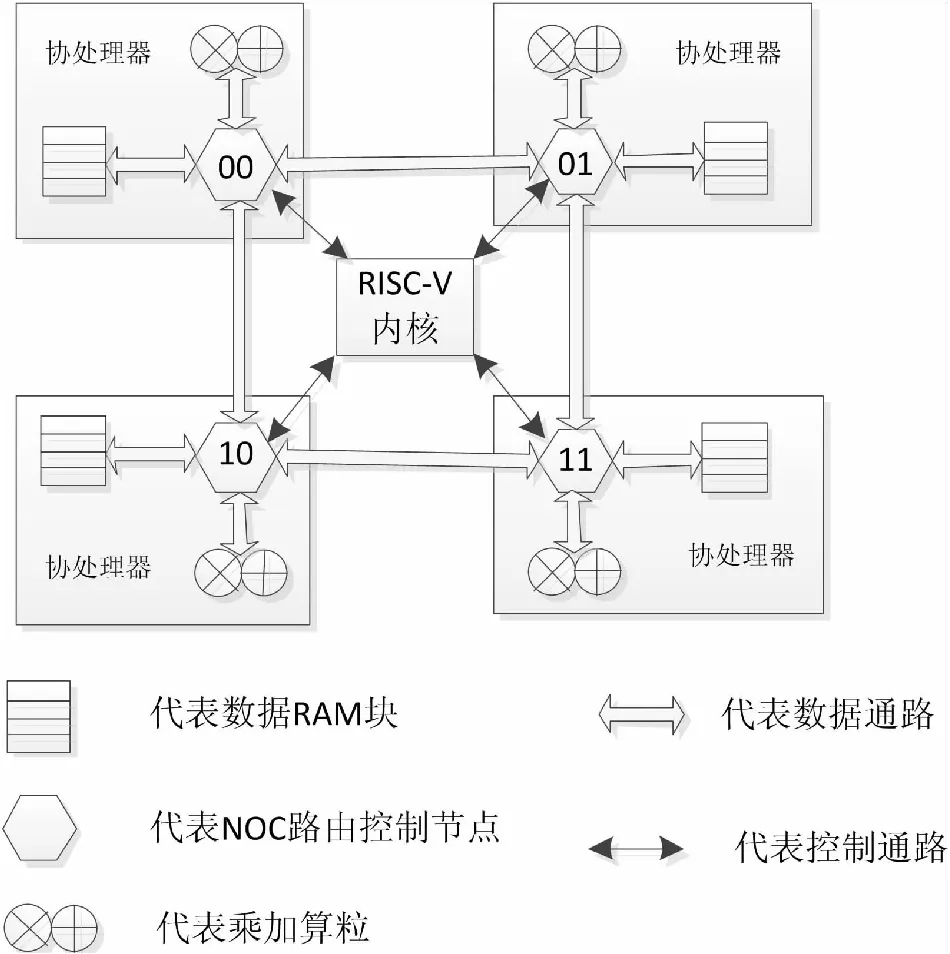
图1 协处理器阵列逻辑框架
图1中,RAM块与乘加算粒一一配对组成一个存算一体化的近数据计算协处理器,相邻协处理器间通过NOC路由控制节点相互连接,组成一个片上网络。在每个NOC路由控制节点中可以有四个数据通路与周边协处理器的路由控制节点相连接,主要实现数据在相邻协处理器间的移动;其内部有两个本地总线分别与数据RAM和乘加算粒相连接,主要实现待计算数据在数据RAM与乘加算粒之间的数据交互。RISC-V的内核通过协处理器接口与各路由控制节点通信,实现用户自定义指令与协处理之间的交互。图中为表述方便,只画出了由四个协处理器组成的一个2DFull-mesh片上网络结构,实际工程实现时,协处理器的数量可以根据硬件资源与计算需求情况进行增删。
1.3 片上网络设计
根据1.1章节中对有规律乘累加计算算法的分析,当待计算数据在RAM块中存储时,假定待计算数据均以矩阵形式进行存储,则对矩阵中某一元素的寻址方式可采用mtx.d_ij的形式进行索引,其中mtx表示数据存储在哪个矩阵中,i与j表示数据在矩阵中的行列角标。
为了实现数据在片上网络中的传输,如图1所示需要对每个NOC路由控制节点按照它所在的行列位置进行编号,同时还需要按照图2所示的帧格式将待传输数据进行封装。

图2 路由节点间数据传输帧结构
图2中,
1)s_rij表示该帧是从哪个NOC路由控制节点发出的;
2)d_rij表示该帧需要发往哪个NOC路由控制节点;
3)Type指示帧类型是请求帧还是响应帧;
4)rd_wr指示帧操作是读操作还是写操作;
5)mtx.dij指示元素在矩阵中的具体位置;
6)dir表示矩阵中的数据在RAM块中是按行存储还是按列存储;
7)d_len指示帧中有效数据的长度;
8)data为帧中需要传输的数据。
当一个数据帧进入到某个NOC路由控制模块时,首先NOC路由控制模块判断该帧中的d_rij是否与自己所在的行列号相同,若不相同,则根据d_rij与自己所在的行列号进行大小判断,从4个数据通路中的某一个转发走。若相同,则表明该数据帧是与自己相关的,此时需要根据mtx_dij和dir的指示转换为RAM的物理地址空间。为了实现这一点,还需要在每个路由控制模块中维护一个矩阵与RAM地址的映射关系表,表中包含矩阵第一个元素在矩阵中的偏移地址,以及矩阵的行列维数、存储方式等信息。
1.4 路由控制节点结构与微码表项
根据1.1章节对规律性乘累加计算的描述,NOC路由控制节点除了实现待计算数据的流动外,更重要的是要针对乘累加规律性运算进行加速,这就涉及到乘累加计算过程中待计算数据角标的产生与控制,下面着重介绍NOC路由控制节点模块中对角标规律的控制方法。
NOC路由控制节点的内部结构如图3所示。

图3 路由控制节点内部结构框图
图3中,
1)交换转发模块用于实现相邻路由控制节点之间的数据交换,因通常NOC网络采用2Dfull-mesh结构,因此一个路由控制节点可与周边4个路由控制节点产生互联。
2)帧解析和帧生成模块负责完成路由控制节点之间传输的数据帧的解析与生成。
3)RAM读写控制模块根据得到的数据角标,按序从RAM中读取数据,并送入到乘加算粒中。同时接收乘加算粒返回的结果,并将结果或保存到本节点的RAM中,或通过帧生成和交换转发模块传输到其他协处理器中。
4)算式间循环控制和算式内循环控制实现了规律性乘加运算角标的产生,可以看出这两个模块是路由控制节点的关键模块。下面详细说明这两个模块的工作原理。
1.4.1 算式间循环控制模块
算式间循环控制模块主要实现对计算过程中计算结果的角标控制,其内部逻辑结构如图4所示。
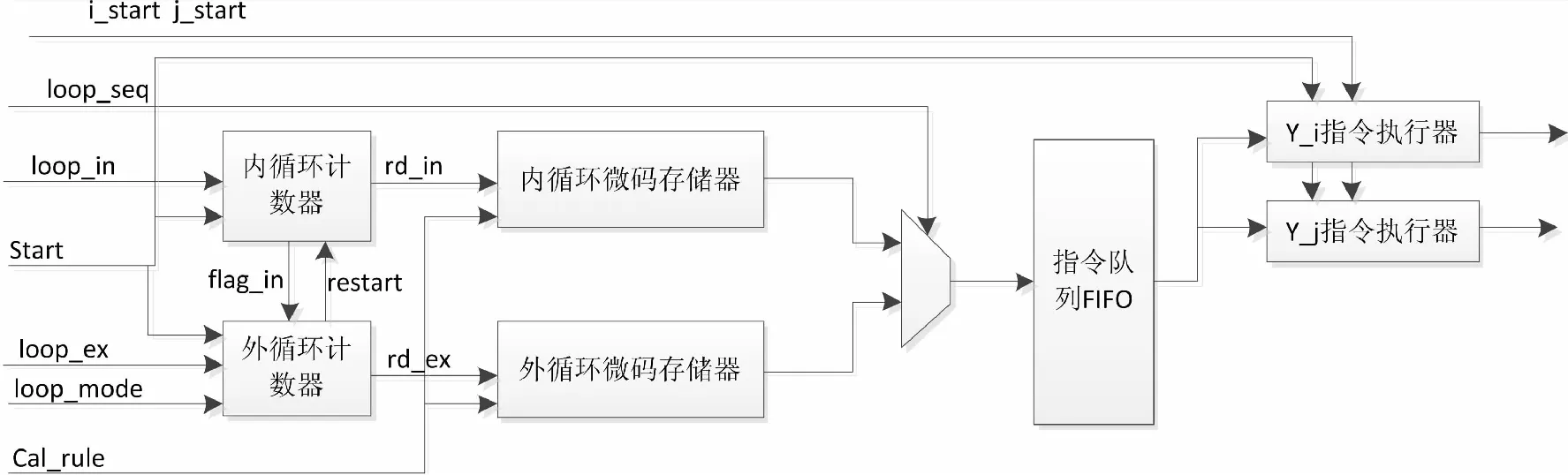
图4 算式间循环控制模块逻辑结构
内循环计数器模块主要实现内层循环次数控制功能,当检测到start信号的上升沿后,Loop_in循环计数器模块内的计数器开始自动增加,每增加一次,向内循环指令存储器中发出一次rd_in读请求信号;当计数值与loop_in的值相等时,向外循环计数器给出flag_in指示。
Loop_mode控制内外循环之间是否为嵌套关系,当为嵌套关系时,外循环计数器模块每收到一次flag_in信号加1,同时给出restart信号重新启动内循环计数器工作。当为非嵌套关系时,外循环计数器收到flag_in之后会连续增加。外循环计数器每增加1输出一个rd_ex脉冲信号,当外循环计数器的计数值与loop_ex的值相等时,表明循环控制结束。
内循环指令存储器和外循环指令存储器均是由RAM实现,RAM中存储了针对1.1章节中描述的角标计算的微码指令,其格式如图5所示。

图5 算式间循环微码表结构
其中,微码指令分为两部分,i微码指令用于控制i角标的变化。j微码指令用于控制j角标的变化。两条微码指令合并为一条表项存储在内外循环微码存储器中。
1)x_sel和y_sel的取值原则与表 2中指示的x和y的取值规律相符;
2)X_inv和y_inv指示x_sel和y_sel索引的数据在计算时,是否需要将符号位取反;
3)A为微码中的立即数。
在系统工作时,可预先在内循环或外循环微码指令存储器中预置多条微码表项,这些微码表项可与多种计算场景对应。当某一场景需要工作时,由cal_rule作为内外循环微码存储器的地址,将对应的微码表项读出。
读出的两条微码表项需要经过指令队列FIFO送到i指令执行器和j指令执行器,如果在同一个时钟周期同时从内循环微码存储器和外循环微码存储器中读出两个表项,则此时需要由loop_seq指示这两条表项需要执行的先后顺序,这两条表项按照先后顺序存入指令队列FIFO中。
最后,i指令执行器和j指令执行器完成角标的计算后,输出具体的计算结果的i角标和j角标值。到此算式间循环控制模块的工作过程就介绍完了。
1.4.2 算式内循环控制
算式内循环控制主要实现一个计算公式内,乘数a和被乘数b的角标ia、ja、ib、jb产生的方法,算式内循环控制模块的工作原理与算式间循环控制类似,其内部结构如图6所示。
图6中,因为要对一个计算公式的乘数a和被乘数b进行循环展开所花费的时钟周期较长,因此需要一个队列FIFO来缓存算式间循环控制输出的启动指示。
乘数a和被乘数b的角标变化的微码指令存储在算式内微码存储器中,其表项内容如图7所示。
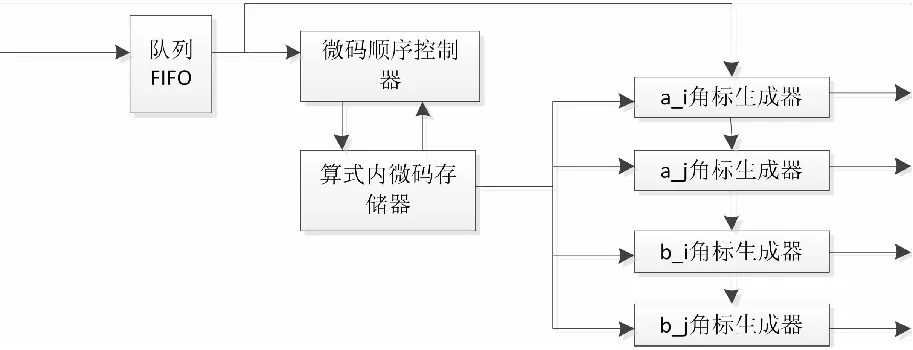
图6 算式内循环控制内部逻辑结构框图

图7 算式内循环微码表结构
图7中,一条微码表项被分为5个区域,其中ia微码指令、ja微码指令、ib微码指令和jb微码指令的格式和含义与算式间循环控制模块的内容类似,在此不做赘述。
微码循环控制区域中由两个位域组成,其中times字段指示从当前微码条目开始,需要循环执行多少次。scop指示从当前微码指令开始,需要循环执行的微码条数有多少条。微码顺序控制器根据times和scop的指示,决定了读取算式内微码存储器的地址指针是否需要跳回,以及跳回多少。当times为1时,地址指针自动加1即可,当times大于1,scop为1时,地址指针需要停滞times所指示的周期数,当times大于1,scop大于1时,地址指针就需要有跳回操作了。如果将一个scop所指示的微码指针空间称为一个微码循环段,则多个微码循环段之间有可能发生重叠,此时就需要在微码顺序控制器中设置一个栈空间,处理微码循环的嵌套问题,比如在卷积运算中,通常需要至少支持两层嵌套。
从算式内微码存储器中读出的微码指令,有四个角标生成器并行执行,从而得到了每个计算公式中乘数与被乘数角标的具体数据。
2 RISC-V用户指令设计
在上一部分的内容中,我们介绍了协处理器加速阵列的逻辑结构,以及其中的微码表项的结构与工作原理,在本部分的内容中,我们将结合RISC-V指令集架构的特点,从微码表配置、数据搬移和运算控制三个方面着重介绍RISV-V用户自定义指令的设计。
2.1 RISC-V介绍
自从RISC-V架构诞生以来,在全世界范围内已经出现了数十个版本的RISC-V架构处理器,其中,最具代表性的Rocketcore是伯克利开发的一款64位的开源RISC-V处理器核,其性能可与ARMCortex-A5对标。更重要的是,在相关的以RISC-V为基础的内核中配置了可扩展指令接口,可供用户扩展协处理器指令[7]。
在RISC-V的指令集支持各种不同的指令长度,以最常用的32位指令集为例,如表2所示为32位指令集的opcode表,其中,定义了4组custom指令类型,分别为custom-0/1/2/3,每种custom均有自己的opcode。

表2 RISC-V指令opcode空间划分
本文所采用的32位custom指令的编码格式如图8所示,图中,xs1、xs2和xd比特位分别用于控制是否需要读取源寄存器rs1、rs2和写目标寄存器rd,rs1、rs2和rd为寄存器组的索引地址,funct7作为额外的编码,用于编码更多的指令。

图8 custom指令格式
2.2 数据搬移指令设计
数据搬移指令实现待计算数据矩阵或计算结果矩阵在协处理器节点间的移动,如图9所示,为微码表配置指令的具体格式。

图9 数据搬移指令结构
图9中,
1)opcode的值为7’b0001011表示采用custom-0的指令空间。
2)i_type的值为2’b00,表示该指令为数据搬移指令。
3)i_len表示数据搬移的数据长度,最多一条指令可搬移32个数据。
4)xs1和xs2的值均为1,表示数据搬移时,协处理阵列需要用到rs1和rs2所指示的通用寄存器中的数值。xd的值为0,表示数据搬移时,协处理器阵列无需返回执行结果。
5)rs1和rs2所指示的通用寄存器的格式定义相同,rs1指示待搬移数据的来源,rs2指示待搬移数据的目的。其中的mtx.dij指示待数据元素在哪个矩阵中的哪个起始位置上,rij表示数据元素在哪个协处理器节点上,dir指示从mtx.dij开始,i分量和j分量是否递增。step指示i分量和j分量递增的步进值,core_f指示数据搬移的源或目的是否通过RISC-V内核的存储器访问接口进行。
2.3 微码表配置指令设计
微码表配置指令用来完成对每个协处理器节点中的微码表项的配置,因每条微码表配置指令只能配置32bit的表项,而一条微码表项的宽度可达88bit,因此,一条微码表项有可能需要多条微码指令才能完成配置。其指令格式如图10所示。

图10 微码表配置指令结构
图10中,
1)opcode的值为7’b0001011表示采用custom-0的指令空间。
2)i_type的值为2’b01,表示该指令为微码配置指令。
3)offset的为5bit的值,表示该条指令需要配置一条微码表项的哪一部分,因微码表的宽度超过32bit位宽,该字段指示本条微码指令是微码表项中的第几个32bit。最大可支持的微码宽度为1024bit。
4)xs1和xs2的值均为1,表示微码表配置时,协处理阵列需要用到rs1和rs2所指示的通用寄存器中的数值。xd的值为0,表示微码表配置时,协处理器阵列无需返回执行结果。
5)rs1所指示的通用寄存器中,rij指示需要配置哪个协处理器节点中的表项。table_sel用来控制将表项配置到算式内微码存储器、内循环微码存储器还是外循环微码存储器中。addr指示表项的具体地址。
6)rs2所指示的通用存储器中,table_content指表项的具体内容。
2.4 运算控制指令设计
运算控制指令用来实现对计算启动的控制,其指令格式如图11所示。
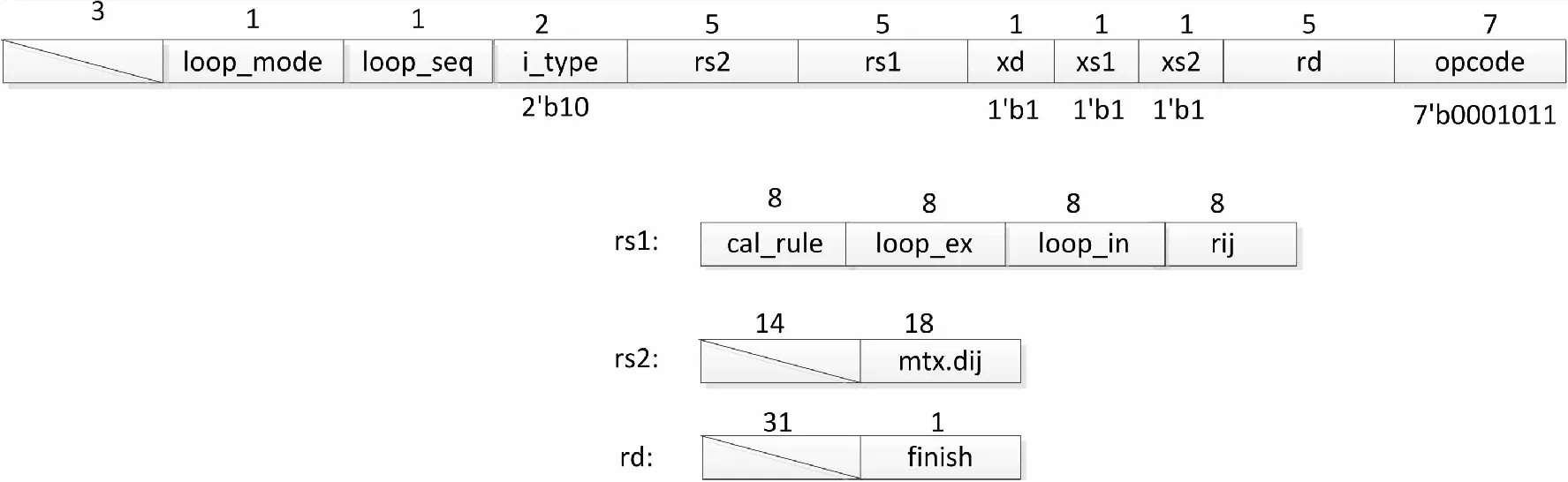
图11 运算控制指令结构
图11中,
1)opcode的值为7’b0001011表示采用custom-0的指令空间。
2)i_type的值为2’b10,表示该指令为运算控制指令。
3)loop_sel用来控制算式间循环控制器内外循环微码指令执行的顺序。
4)loop_mode用来控制算式间循环控制器内外层循环是否嵌套。
5)xs1和xs2的值均为1,表示运算控制指令执行时,协处理阵列需要用到rs1和rs2所指示的通用寄存器中的数值。xd的值为0,表示运算控制指令执行时,协处理器阵列需要返回执行结果。
6)rs1中,rij指示需要启动哪个协处理器节点中的计算。loop_in用来控制算式间循环控制内循环的次数。loop_ex用来控制算式间循环控制器中外循环的次数。cal_rule用来控制内循环微码存储器和外循环微码存储器的地址。
7)rs2中,mtx.dij给出了算式间循环控制器中y_i指令执行器和y_j指令执行器的初始值。
8)rd中,finish指示算式间循环控制器的循环是否执行完毕。
3 示例
在本部分,我们以典型矩阵乘法为例,说明协处理器工作的具体过程。首先介绍了矩阵乘法所需的计算公式,然后分析了针对矩阵乘法所需要的微码表项和相关指令,最后定性评估了执行过程中对risv-v内核与协处理器之间对微码和指令执行速率的要求。
假设将两个72×72维的矩阵相乘,则有公式(6)
(6)
通过分析公式(6),在算式间循环控制器中,采用内循环和外循环嵌套的方式进行,在协处理器中配置的微码表如表3所示。
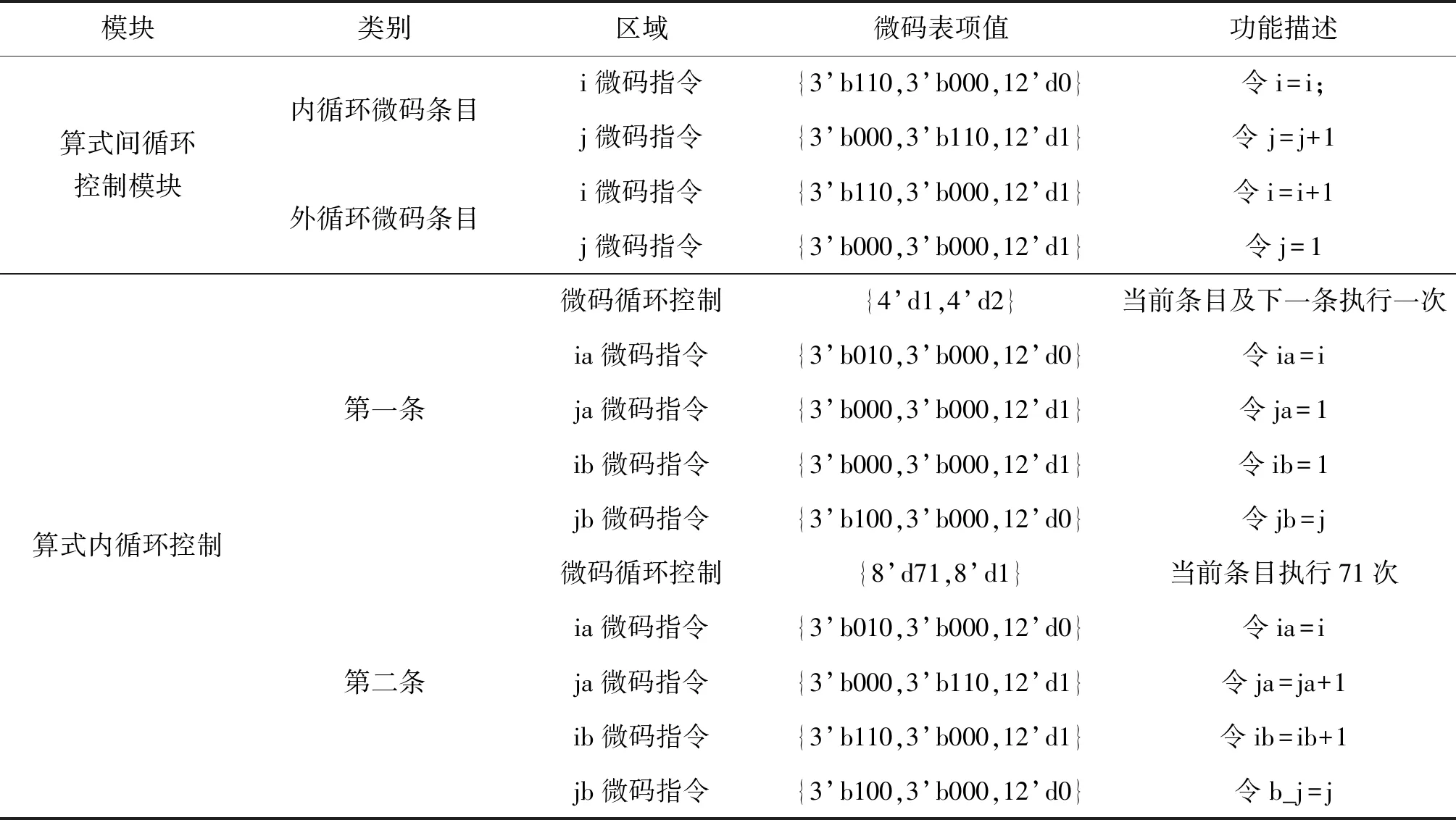
表3 矩阵乘法微码配置表
在完成了上述微码表现配置以后,在RISC-V内核中只需执行2条指令,即可完成72×72维的矩阵乘法,首先执行一条数据搬移指令,将待计算数据搬移到指定协处理器中,然后再执行一条运算控制指令,启动协处理器乘法计算过程。可以看出,与没有协处理器参与的72×72维矩阵乘法相比,由于乘加计算均通过协处理器完成,在RISC-V内核中指令执行数量得到大幅缩减。
4 结束语
计算的硬件加速方法多种多样,常见硬件加速方法有以谷歌TPU为代表的脉动阵列结构[8]、以清华Thinker为代表的可重构计算[5]等。前者通过将计算中间结果进行直接复用的方式减轻访存带来的内存墙问题;后者强调了算力的可重构特性,但本质上仍然需要仔细设计控制流与数据流的紧密配合问题。而本文采用的是数据分散存储在算粒附近方法,强调的是一种近数据计算阵列的实现方法。
在本文中,我们基于RISC-V内核提出了一种近数据计算的协处理器阵列结构,待计算数据分散存储在各协处理器阵列的节点中,在每个协处理器中算式间循环控制器和算式内循环控制器的控制下,通过将RISC-V的自定义指令与协处理器中的微码表项有机结合,实现了有规律乘加运算的可重构近数据计算,从而减少了访存次数。通过定性分析论证,将有规律的乘加运算均放置到协处理器中运行,在RISC-V的仅保留规律运算的过程控制部分,可以极大减少RISC-V内核的负担。
猜你喜欢
航天器工程(2021年5期)2021-10-15
计算机与网络(2020年9期)2020-07-29
学校教育研究(2020年11期)2020-06-08
小学生学习指导(低年级)(2019年11期)2019-11-25
电脑知识与技术(2019年22期)2019-10-31
传播力研究(2019年24期)2019-10-21
航空科学技术(2019年2期)2019-09-10
小学生学习指导(低年级)(2018年9期)2018-09-26
作文周刊·小学一年级版(2017年5期)2017-07-29
作文周刊·小学一年级版(2017年5期)2017-07-29
