
基于改进精英策略的PCA-NSGAⅡ的高维目标调度优化
2020-10-12 12:39:02熊书平湛梦梦
计算机集成制造系统 2020年9期
刘 琼,熊书平,湛梦梦
(华中科技大学 数字制造装备与技术国家重点实验室,湖北 武汉 430074)
0 引言
现实生活中,存在许多多目标优化问题(Multi-objectives Optimization Problems,MOP),当优化目标个数增加到4个及以上时,即视为高维目标优化问题[1]。由于目标函数之间经常是冲突的,其最优解并非单一解,而是一组非支配解[2]。一个目标的优化将可能导致其他目标的恶化,只能采用折中的方式让各个目标尽可能达到最优。而且,优化过程导致计算复杂度和搜索空间急剧扩增,高维目标优化问题已成为目前国内外智能优化领域最难解决的问题之一[3],有效地解决高维目标优化问题具有广泛的理论和实际意义。
在中国制造2025的背景下,企业间趋于协同合作,制造资源互相开放、共享。企业的产品加工需求可以通过各企业制造资源间的协同合作完成。由于协同合作涉及的加工任务多,设备规模大,加工路径多样,这些因素扩大了可行解的搜索范围,与传统车间调度问题相比规模更大,更复杂;且随着问题规模的增大,计算的复杂度将呈指数增长[4]。同时,资源共享需兼顾各个企业的需求,通常涉及多个优化目标,目标间不是完全线性相关,呈现出高维目标特性。因此,解决协同加工中调度优化问题,需要在满足各企业不同需求的基础上,从整体进行优化,使企业能快速响应市场需求,减少固定资产投入,提高资源利用率。
文献[1]认为,当调度优化问题的目标个数增加到4个及以上时,即可视为高维目标调度优化问题,目标个数2或3个的调度优化问题为多目标调度优化问题。在实际生产调度中,企业可考虑的优化目标有很多,包括完工时间、成本、提前/拖期惩罚、设备利用率、设备负荷、碳排放等,企业可根据自身需要选择合适的优化目标。目前多目标调度优化问题研究较多,一般通过非劣解排序(Pareto排序)来选择个体和确定优化方向,如张超勇等[5]提出一种改进的非支配排序遗传算法,设计新的编码解码机制,解决了以时间和成本为优化目标的多目标柔性作业车间调度问题。Liu等[6]采用基于Pareto排序的混合果蝇算法来解决以减少最大完工时间和制造过程中碳排放为目标的多目标调度优化问题。当优化的目标数增加至4个或以上形成高维目标时,算法的选择压力减弱,非支配解的个数将呈指数增长,基于Pareto排序的多目标调度优化算法优化效果大大降低。针对该问题,现有研究大都通过给目标赋予不同权重来减少目标的维数,以增强算法的种群选择能力。吴秀丽等[7]建立了以完工时间、成本、交货期满意度和设备利用率为目标的高维目标调度模型,采用基于集成权重系数和小生境技术的混合遗传算法,通过随机权重混合集成法将多目标转化为单目标再优化,但权重分配随机,导致算法沿着随机方向搜索,搜索效率不高。白俊杰等[8]建立了以完工时间、拖期惩罚、机床利用率和机床总负荷为目标的高维目标调度模型,并采用基于偏好信息的粒子群算法,定量表达决策者对各目标的偏好,仅对感兴趣的区域进行搜索排序,有效引导搜索方向,提高了求解速度。但上述算法的本质是通过采用权重法将高维目标转化为单目标优化来解决,即使有权系数的变化机制,也不能保证Pareto最优性和解的质量[9]。目前,解决高维目标优化问题方面的理论算法很多,其中包括通过采用降维法的算法来解决高维目标优化问题,如陈小红等[10]提出基于稀疏特征选择的目标降维算法,将高维目标空间投影至低维目标空间实现降维,对比其他降维算法,求解高维目标优化测试问题能得到更好的结果,但随着目标数量增加,错误目标子集数增多,准确性无法保障。刘立佳等[11]提出了分组进化算法,通过对目标函数进行分组来降维,求解各组目标Pareto非支配解集,再对全部解集采用SPEA2求得整体最优解,虽然通过求解标准测试函数与其他降维算法对比证明了其性能上的优势,但目标函数分组具有较大的随意性,分组不同将导致不同的优化结果,无法保证解的质量。目前而言,采用降维法的算法解决高维目标优化的研究效果并不理想。此外,还有通过宽松Pareto支配的算法来解决高维目标优化问题。Drechsler等[12]将一种用来确定个体间支配关系的优胜关系与进化算法相结合来解决电路设计中高维优化问题,若解a在更多目标上优于解b,则a支配b,但该优胜关系不具有传递性,当存在a支配b,b支配c,c又支配a的循环情况时,无法对所有个体完全排序,易出现选择压力退化。郭思涵等[13]提出带有正交E占优策略的算法,采用正交试验初始化种群,采用E占优代替Pareto排序,通过求解标准测试问题来对比说明改进后的算法比原算法具有更好的收敛性能,但算法的参数难以确定,易受主观干扰,同时改动了个体的真实目标值,易导致无法真正收敛到Pareto前沿。杨顺生[14]提出基于主成分分析法(Principal Component Analysis, PCA)占优机制的PCA-NSGAⅡ算法,通过对目标矩阵进行PCA分析得到各目标的权重,再对各目标值与权重的积进行差值求解来选择非支配解,代替传统Pareto占优排序机制,从而增大了选择压力。求解标准测试函数验证了算法的有效性。采用PCA占优机制的算法考虑了所有目标的特性,使原有目标属性被保留和体现,提高了解的分布性。但仍需进一步完善收敛性能和解质量。目前这些算法还未在生产调度领域中得到应用,故将基于PCA占优机制的算法引入到解决生产调度领域的高维目标调度优化问题中,并针对基于PCA的占优机制的算法缺少精英引导策略、求解质量和收敛效果还不够理想的问题,提出一种改进精英策略的PCA-NSGAⅡ算法来求解所建立的高维目标调度优化模型。在原有PCA-NSGAⅡ算法的基础上,提出增加一个外部种群,对算法精英策略进行改进,将算法中优化后的优秀个体放入外部种群中,原种群和外部种群同时进化,并通过优先选择外部种群中个体的方式,引导种群进化方向,改善种群的质量,提升种群整体进化水平,以提高算法的求解质量和收敛效果来有效地解决高维目标调度优化问题。
1 高维目标调度优化建模
各制造企业将自己的具有某种加工功能的加工机器,通过协调优化,在满足各企业不同需求的情况下,实现资源快速共享提高资源利用率。各制造企业拥有一台或多台加工机器,构成一个制造系统,多台机器可共同完成各工件的加工任务。
1.1 问题描述

1.2 条件假设
为便于研究,作如下假设:
(1)各工件的工艺路线已知,且所有加工任务仅涉及机加工车间,不涉及热处理和毛坯工艺;
(2)各加工机器在首个工件抵达后启动;
(3)加工机器在整个加工过程中只开关一次,所有加工机器的启动、预热和停止能耗引起的碳排放在优化目标中为一个常量,对优化结果不产生影响,故在计算中忽略;
(4)忽略机器使用润滑油和冷却液产生的碳排放;
(5)制造工厂间使用小型货车运输工件,搬运工件产生的能耗只与运输距离有关;忽略工厂内部机器间运输时间和运输产生的碳排放;
(6)加工任务开始后不允许中断,且工件的每个加工任务只能在一台机器上加工;
(7)不同工件的加工任务间没有优先级;
(8)在零时刻,所有的工件都可以开始加工;
(9)所有工件只能在前一道任务完成后才能进入下一道任务的加工。
1.3 调度优化模型
目前生产调度中考虑的优化目标有很多,如完工时间、成本、提前/拖期惩罚、设备利用率、设备负荷、碳排放等,依据企业的实际需求,以总成本、最大完工时间和总提前/拖期惩罚为主要考虑目标。同时,近年来环境问题日益突出,制造过程产生的碳排放已越来越引起企业和公众的关注,未来制造模式将向低排放、低污染、低能耗方向发展,故将制造过程碳排放作为一个优化目标。因此以总成本最小、最大完工时间最小、总拖期/提前惩罚最小以及制造过程中碳排放最小为目标,建立高维目标调度优化模型。具体优化模型如下,模型参数如表1所示。
(1)
minCtime=max{Cijk|i∈N;j∈J;k∈Mij};
(2)
min(0,Cipik-di)×Ei);
(3)
(4)
s.t.
Sijk≥Chlk+thikh,i∈N,j,l∈J;
k∈Mij∩Mhl;
(5)
Sijk≥Ci(j-1)k′+tt,ij,i∈N,j>2,j∈M,
k∈Mij,k′∈Mij-1;
(6)
Cijk≥Sijk+tijk,i∈N,j∈J,k∈Mij;
(7)
Ctime≥Cijk,i∈N,j∈J,k∈Mij;
(8)
(9)

表1 模型参数
其中:式(1)表示生产总成本Ccost,由加工成本和运输成本组成;式(2)表示最大完工时间Ctime,即从第一个工件的第一道工序在机器上开始加工到最后一个工件的最后一道工序在机器上加工完成之间的时间;式(3)表示总拖期/提前惩罚ET,即衡量工件实际加工完成时间与规定交货期之间的偏差;式(4)表示制造碳排放CP,式中第一项表示机器加工时消耗电能所产生的碳排放,第二项表示机器空转时消耗电能所产生的碳排放,第三项表示机器加工不同工件时调整所产生的碳排放,第四项表示工件在机器间运输时油耗所引起的碳排放。
约束(5)表示加工机器k上任务Oi-j的开始加工时间Sijk不能小于加工机器k上的紧前任务Oh-l的完工时间Chlk与这两个任务在加工机器k上的调整时间thik的和;约束(6)表示工件i任务j在加工机器k上的开工时间Sijk与该工件的紧前任务j-1在加工机器k′上的完工时间Ci(j-1)k′的间隔不能小于该工件从上一加工机器k′搬运到加工机器k所需的时间tt,ij;约束(7)表示工件i的第j道任务的完工时间cijk不能小于该任务的开始加工时间Sijk与加工时间tijk的和;约束(8)是为了确保最大完工时间Ctime不小于任何一个任务的完工时间Cijk;约束(9)表示一道任务只能在一台加工机器上加工。
2 改进精英策略的PCA-NSGAⅡ
高维目标调度优化模型中,各优化目标和约束条件呈非线性关系,若采用线性化处理求解该模型,会严重影响模型的准确性。同时,采用一般算法求解时具有明显的高计算复杂度,且精度大幅下降。基于Pareto的算法在求解高维目标调度优化非线性模型时,其选择压力减弱,非支配解的个数将呈指数增长,算法优化效果大大降低,无法获得满意的解,甚至无法求解。针对其计算复杂度高、求解难度大和易导致算法选择压力不足的难点,本文设计了一种基于改进精英策略的主成分分析—快速非支配排序遗传算法(Principal Component Analysis-Non-dominated Sorting Genetic Algorithm Ⅱ, PCA-NSGAⅡ)。为降低算法的计算复杂度,增加算法选择压力以提高收敛性,设计了快速非支配排序算子以及拥挤度比较算子;为了改善解的质量,提高寻优效率,改进了算法的精英保留策略,在原有将父代和子代合并同时优化产生下一代的精英保留机制的基础上,提出增加一个外部种群,丰富种群个体的多样性,用于保留每代的精英个体,外部种群同时进行优化,并在选择操作时优先选择外部种群中的个体。算法具体流程如图1所示。

2.1 编码和解码
设计一种基于任务和机器的二段式编码,第一段为任务加工顺序编码,由工件号组成,工件号i在基因串中从左至右出现的次数j表示该加工方案中工件i的第j道任务,图2中3个工件的加工任务的加工顺序为:O1-1→O1-2→O3-1→O2-1→O1-3→O2-2→O3-2→O3-3;第二段为机器分配编码,确定各任务对应的加工机器。基因串中从左至右依次为工件1的第一道任务到最后一道任务的所选加工机器,其中基因k表示机器Mk。图2中加工机器分配方案为:工件1的第一、二、三道任务分别在M4、M2、M5上加工;工件2的第一、二道任务分别在M3、M4上加工;工件3的第一、二、三道任务分别在M1、M4、M3上加工。

2.2 种群初始化以及选择、交叉、变异操作
(1)种群初始化 采用随机生成的方式产生任务加工顺序编码和机器分配编码。
(2)选择操作 采用二元锦标赛方法对解集的非支配等级以及拥挤距离进行选择。优先选择非支配等级低的解,若解的非支配等级相同,则比较拥挤距离,选择拥挤距离大的解。
(3)交叉操作 对加工顺序编码段进行交叉操作(Precedence Operation crossover, POX)[15];对机器分配编码段采用多点交叉操作(Multi-point Preservative crossover, MPX)[5]。上述两种交叉依次以设定的概率进行。
(4)变异操作 采用文献[5]中的两种变异操作,第一种扩展的插入变异操作用于任务加工顺序编码段;第二种机器分配编码段的变异操作,随机选取机器编码段上的两个基因,在其对应的任务的可选加工机器集中随机选取加工机器对该基因进行替换。
2.3 PCA占优机制
PCA占优是一种基于主成分(PCA)分析的差值求解选取非支配的方法。先用NSGAⅡ算法对高维目标问题进行迭代优化,得到一个非支配种群,再对非支配种群对应的目标进行PCA分析,得到目标的权重向量。假设M个目标的权重向量为w,w={w1,w2,…,wM},则种群个体间的占优关系判断标准如下:
个体a与个体b对于任意目标fi,若存在:
fi′(a)-fi′(b)+Temp<0,
则个体a占优个体b。其中:fi(a)为个体a在目标fi上取得的目标值,wi为目标fi的权重系数。
2.4 外部种群
为提高PCA-NAGAⅡ算法的寻优效果和收敛性能,对算法的精英保留策略进行改进,通过每次迭代保留子代与父代合并后生成的组合种群中部分好的个体生成一个外部种群P1。对外部种群P1和原有种群P进行选择、交叉、变异。外部种群P1的子代、父代与原有种群P的子代、父代一同合并成组合种群,从而增加种群中较优个体的数量。丰富种群个体的多样性,引导算法的寻优方向,加快算法向较优解逼近,提升收敛性能,使最终解质量更好。
3 算例验证
从合作企业中选取由3个制造工厂和8个加工机器组成的制造系统作为研究对象,3个工件作为加工对象,工件1、2和3分别包含6、5和8个加工任务。制造工厂U1包含加工机器M1,M2,M3,制造工厂U2包含加工机器M4,M5,制造工厂U3包含加工机器M6,M7,M8。各任务可选加工机器以及其对应的加工时间和加工成本如表2所示。制造工厂间的搬运工具为小型货车,其平均速度为28.7 km/h,耗油均值为0.121 4 L/km[16]。小型货车所使用的柴油价格为6.5元/L。表3为各制造工厂间的距离;表4为各加工机器加工各工件任务时的平均加工功率,空载功率以及调整功率;表5为各加工机器加工工件时的调整时间。电能的碳排放因子参照香港中小企业碳审计工具箱[17],取值为0.674 7 kg CO2/kW·h,由文献[16]对各类货车CO2碳排放因子的计算中查得小型货车CO2碳排放因子的均值为326.88 g CO2/km。

表2 工件任务可选机器以及加工时间和加工成本

表3 制造工厂间的距离 km

表4 机器功率 kW

表5 机器加工不同工件间的调整时间 s
采用Python编程,参数设置为:种群规模N=60,最大迭代次数m=500,交叉率C=0.85,变异率A=0.2,得到一组Pareto解集如表6所示。

表6 改进精英策略的PCA-NSGAⅡ算法所得解集
由表6可知,序号解1是制造过程中碳排放最小的解(Cp=45.723 7 kg CO2);序号解7是最大完工时间最小的解(Ctime=5 861.298 s);序号解23是货拖期/提前惩罚最小的解(ET=58.140 6元);序号解26是生产总成本最小的解(Ccost=440.443 8元)。其中对碳排放最小的解进行解码所得到甘特图如图3所示。图中:“-”前的数字表示工件编号;“-”后的数字表示该工件的任务编码。
为了说明本文算法对高维目标调度优化的效果,将所提算法的优化结果分别与传统的基于Pareto排序的NSGAⅡ算法得的结果、基于ε支配的NSGA-Ⅱ算法以及原PCA-NSGAⅡ算法所得结果进行比较。同样设置种群规模N=60,最大迭代次数m=500,交叉率C=0.85,变异率A=0.2,3种算法得到的非支配解集分别如下表7、表8和表9;3个算法在4个目标上的结果对比如表10所示。
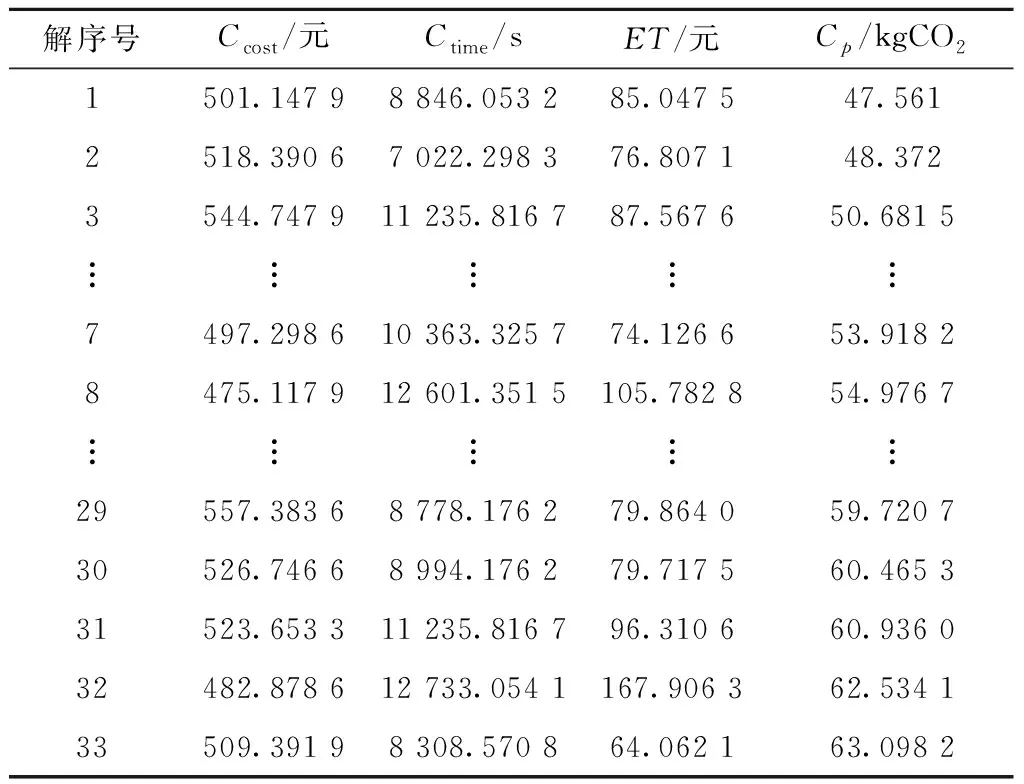
表7 原PCA-NSGAⅡ算法所得解集

表8 NSGAⅡ算法所得Pareto解集
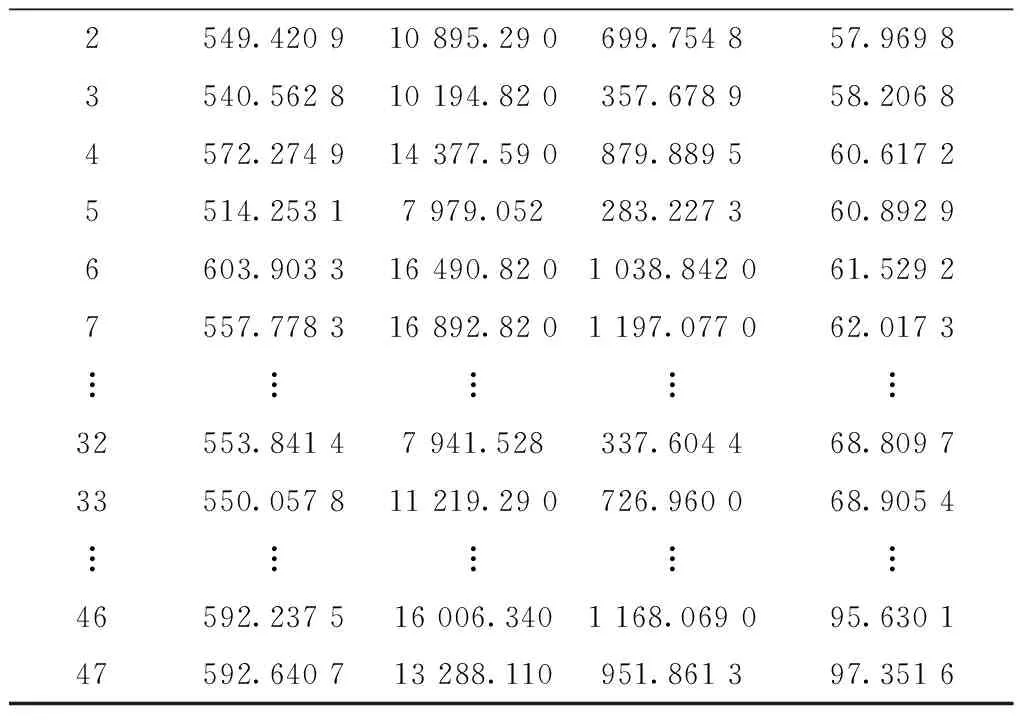
续表8
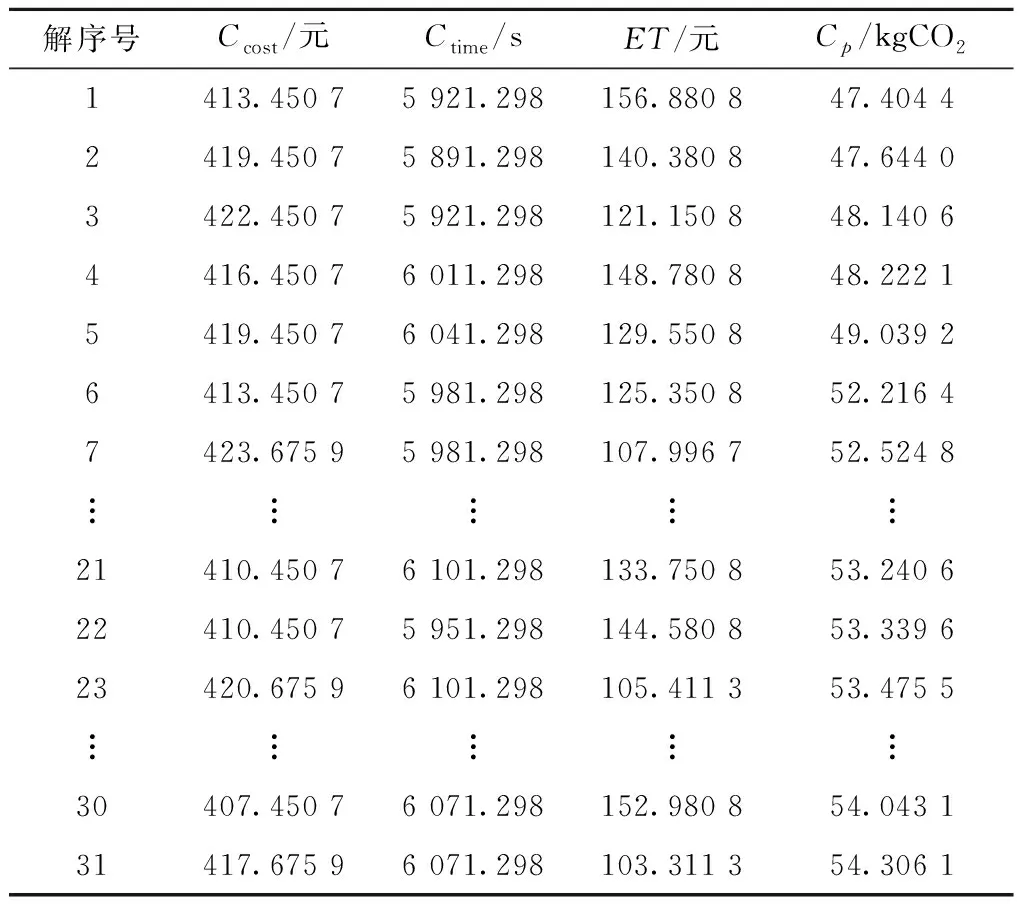
表9 基于ε支配的NSGAⅡ算法所得Pareto解集
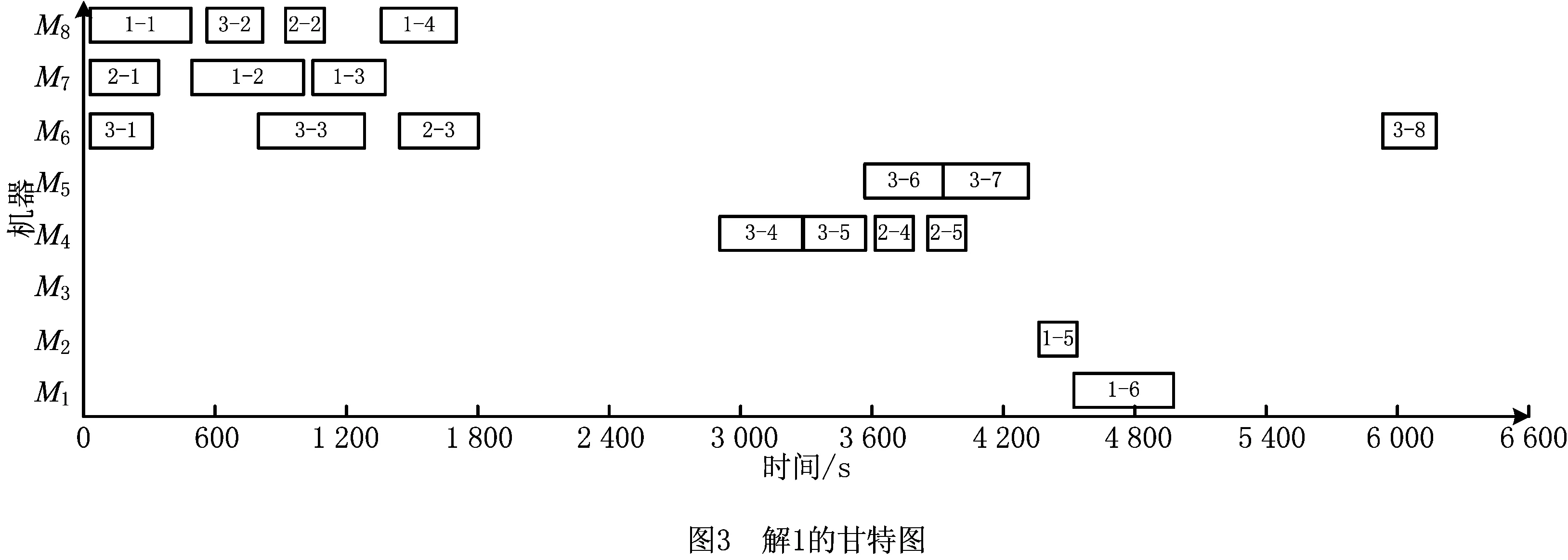
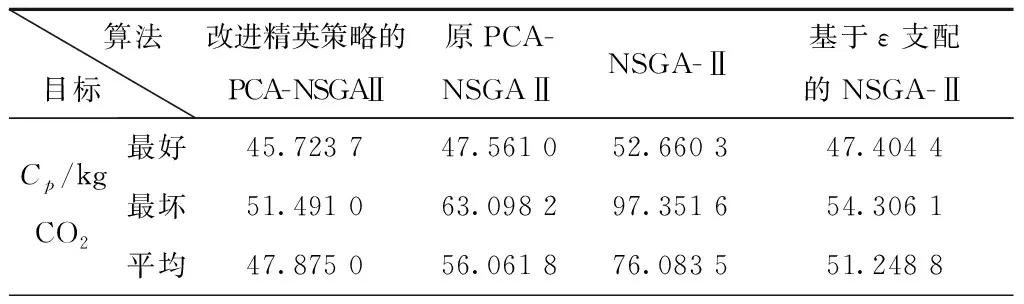
表10 算法结果对比

续表10

续表10
由表8可以看出,采用NSGA-Ⅱ算法迭代优化后所得的Pareto解集中个体的数量为47,与设置的种群规模N=60很接近,这也验证了传统基于Pareto排序的进化算法在解决目标维度大于或等于4的高维目标问题时,非支配解的数量会随着目标个数的增加而增长,从而导致算法选择能力减弱这一现象。
从表10可以看出,改进精英策略的PCA-NSGAⅡ算法在最好值上除了生产总成本外的其他3个目标均优于其他3种算法,在生产总成本上的最好值同样优于原PCA-NSGAⅡ算法和NSGA-Ⅱ算法,略差于基于ε支配的NSGA-Ⅱ算法;且在所有目标上无论是最好值、最坏值还是平均值均明显优于NSGA-Ⅱ算法;除了总拖期/提前惩罚目标上的最坏值和平均值外的其他目标无论最好值、最坏值还是平均值均明显优于原PCA-NSGAⅡ算法。其中,改进精英策略的PCA-NSGAⅡ算法所有最好值都优于原PCA-NSGAⅡ算法,在4个目标上分别多减少了3.86%、7.30%、16.53%和9.24%;改进精英策略的PCA-NSGAⅡ算法最好值除在生产总成本这一目标外在其他3个目标比基于ε支配的NSGA-Ⅱ分别多减少3.55%、0.5%和43.7%,特别在拖期惩罚上减少效果明显。在生产总成本上的最好值,基于ε支配的NSGA-Ⅱ比改进精英策略的PCA-NSGAⅡ多减少7.49%;故从4个目标整体来看,改进精英策略的PCA-NSGAⅡ算法在解决高维优化问题上,其总体优化效果比其他3种算法的优化效果好。
为了验证所提增加一个外部种群,与原始种群共同进化的改进精英策略是否有效,对改进精英策略的PCA-NSGAⅡ算法和原PCA-NSGAⅡ算法在收敛性上进行比较。为了考虑模型中所有目标在整个优化过程中的收敛情况,选取了国内外通用的收敛性评价标准[18]即世代距离(GD)来衡量算法的收敛性能,为了避免随机性导致的误差,取5次计算结果的平均值作为对比值。其结果如表11所示。

表11 世代距离(GD)对比
可以看出,改进精英策略的PCA-NSGAⅡ算法获得的平均GD值明显小于原PCA-NSGAⅡ算法,说明改进精英策略的PCA-NSGAⅡ算法在收敛性上具有一定的优势。由此可见,所提改进的精英策略能有效地提升算法的收敛性能,使算法向好的方向优化,改善算法的优化结果,从而说明了改进精英策略的有效性。
为进一步验证所提算法对求解不同规模的高维调度优化问题的有效性,将其他规模算例的结果也进行了对比分析。选取其他2种不同规模的算例2×7×3×15、4×11×5×25(制造工厂数×加工机器数×工件数×加工任务数)进行测试,具体各目标最优值的结果对比和GD均值分别如表12和表13所示。

表12 其他规模算例结果对比

表13 其他规模算例的世代距离均值对比
可以看出,改进精英策略的PCA-NSGAⅡ算法在解决不同规模的高维问题上,其优化结果均优于其他3种算法的优化结果,且所提改进的精英策略能有效地提升算法的收敛性能,验证了所提算法的有效性。
4 结束语
为了探索如何有效地解决制造系统中的高维目标调度优化问题,以生产总成本最小、最大完工时间最小、交货拖期/提前惩罚最小和制造过程中碳排放最小为目标构建高维目标调度模型,设计了改进精英策略的PCA-NSGAⅡ算法,用PCA占优机制代替传统算法中Pareto排序来解决高维目标调度优化问题。为了保证种群多样性,提高算法寻优质量,对算法精英策略进行改进,提出增加一个外部种群引导种群进化方向,改善种群的质量,提高算法的收敛性,并通过算例对比与分析,说明所提出的改进精英策略的PCA-NSGAⅡ算法在处理高维目标调度优化问题时的有效性。
高维目标问题在实际应用中计算的复杂度很高,当数据量更加庞大时,对算法的运算速度有更高的要求,后续研究拟关注算法对大规模问题的计算速度。另外,关于如何有效地解决高维目标优化问题,后续研究还可考虑一些非Pareto排序的排序方法,设计新的适应度计算准则和多样性维护机制,增加个体的选择压力,提升算法的搜索能力,保证算法的优化效果。
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
数学小灵通·3-4年级(2020年9期)2020-10-27 03:26:14
测控技术(2018年4期)2018-11-25 09:46:48
红土地(2018年7期)2018-09-26 03:07:38
NBA特刊(2018年11期)2018-08-13 09:29:14
电信科学(2017年6期)2017-07-01 15:44:37
海外星云(2016年7期)2016-12-01 04:18:01
世界汽车(2016年8期)2016-09-28 12:11:11
数学年刊A辑(中文版)(2015年3期)2015-10-30 01:56:52
应用数学与计算数学学报(2014年3期)2014-09-26 12:03:56
