
物联网用户的时空特征挖掘算法
2020-10-12 12:40于海宁
计算机集成制造系统 2020年9期
于海宁,方 舟,马 超
(1.哈尔滨工业大学 计算机网络与信息安全研究中心,黑龙江 哈尔滨 150001;2.黑龙江省网络空间研究中心,黑龙江 哈尔滨 150001;3.哈尔滨理工大学 软件与微电子学院,黑龙江 哈尔滨 150040)
0 引言
随着网络技术、信息技术的发展,物联网受到学术界和工业界的广泛关注。物联网成为连接物理世界与虚拟世界的纽带,并逐步描绘出万物互联的愿景[1]。研究机构Gartner公布的最新报告显示,2016年全球的网络设备数量将达到64亿,较2015年增长了30%,预计2020年,网络设备的数量会增长至208亿。网络规模迅猛扩张的同时也制造了海量的多模态数据。市场调研机构IDC预计,未来全球数据总量年增长率将维持在50%左右,预计2020年,全球数据总量将达到40 ZB,我国数据量将达到8.6 ZB,占全球的21%左右。在物联网环境下,用户由传统的数据消费者变为数据生产者。面对海量的用户数据,物联网服务商亟须解决“信息过载,知识匮乏”的问题,为用户提供个性化、智能化的物联网服务。物联网用户特征是物联网个性化应用设计的基础依据之一。物联网应用往往涉及用户的时空特性,用户的时空运动模式是时空特性最直接的表现.运动模式能够体现出用户兴趣爱好、活动规律、经验等特征,如何发现时间敏感、空间敏感的用户特征,以支持物联网个性化应用,这是急需解决的关键问题。针对该问题,本文提出物联网用户的时空特征挖掘算法,从用户的GPS轨迹中发现其隐藏的时空运动模式,该方法的创新点概括如下:①提出用户全球定位系统(Global Positioning System, GPS)轨迹预处理方法,在综合考虑GPS点的时间和空间特性的基础上,挖掘隐藏的热点区域序列;②提出热点区域序列的异步周期序列模式挖掘模型,刻画那些频繁的且呈现出异步周期性的热点区域序列;③提出一种基于模式增长的多最小支持度的异步周期的序列模式挖掘算法,发现异步周期的序列模式,即用户的时空运动特征;④采用真实和仿真的数据集对所提方法进行验证与评估。
1 相关工作
目前已有许多研究关注从用户GPS轨迹中挖掘用户时空运动模式[2],如,轨迹模式挖掘[3-4]、移动对象的位置预测[5-7]、基于位置的行为识别[8-9]。挖掘GPS轨迹中隐藏的行为模式前,需要对GPS轨迹进行处理,发现对用户有意义的热点区域。上述文献采用GPS点的密度聚类算法获取热点区域,这些方法只考虑了用户在空间域内频繁出现的位置,而忽视了用户在时间域内频繁出现的位置。文献[10]在空间域和时间域内检测用户频繁出现的位置,提出基于停留点的热点区域挖掘方法,但该方法忽视了那些用户没有停留的,却具有特殊意义的位置。
通过序列模式挖掘算法和周期模式挖掘算法能够发现热点区域中隐藏的用户时空运动模式,传统的序列模式挖掘模型用于发现序列数据库中所有频繁的序列模式,其目标数据库如表1所示。表中:{a,b,c,d,e,f}是所有项的集合,表示一个序列,例如a(abc)(ac)d(cf),其中()表示一个项集,如(abc)。时空序列挖掘模型用于发现时空序列数据库中所有频繁的时空序列模式,其目标数据库如表2所示,表中下标t表示项集关联的时间戳。周期模式挖掘模型用于发现时间序列数据库中所有周期模式,其目标数据库如表3所示。
按照这3个挖掘模型,可以将序列的时间属性划分为两个层次:①用于标注项集的细粒度时间属性,如表4中序列项集的下标ti;②用于标注序列的粗粒度时间属性,如表4中序列的时间槽tidi。细粒度时间属性是对粗粒度时间属性的进一步划分。序列挖掘模型仅利用细粒度时间属性排序项集,且不关注序列的粗粒度时间属性。时空序列挖掘模型将细粒度时间属性引入挖掘算法,它以标注相似性作为判断序列相同的依据,能够容忍项集时间标注的误差。上述两个序列挖掘模型均忽视了序列的粗粒度时间属性,即它们只关注序列的频繁性,但忽视了序列在数据库中的分布周期性特征。周期模式挖掘模型虽然能够以细粒度时间属性为标准发现周期模式,并依此推算出粗粒度时间属性的周期模式,但它对项集的标注要求过于苛刻(细粒度时间属性必须被划分为等间隔的时间段),且无法容忍频繁的项集标注的时间误差。此外,对于稀疏的时间序列数据库,周期模式挖掘模型可能产生大量稀疏且无意义的周期模式。因此,现有模型只关注了序列发生的频繁性,而忽视了序列分布的周期性。

表1 符号序列数据库

表2 时空序列数据库

表3 时间序列数据库

表4 粗细粒度时间标注的序列数据库
传统的序列挖掘算法是在序列数据库中发现频繁的序列模式,如PrefixSpan[11]、SPADE[12]等。文献[11]对传统的序列挖掘算法进行了详细的叙述。时空序列挖掘算法本质上是一类特殊序列挖掘算法,它需要考虑序列的时间标注和空间位置的误差。文献[13]提出了基于PrefixSpan的时空序列挖掘算法,在该算法中,时空序列中的时间标注不仅用于位置或状态的排序,还直接参与序列模式的挖掘。当序列模式变得较长时,该算法的复杂度急剧升高。
周期模式挖掘算法是在时间序列数据库中发现周期性重复出现的周期模式.周期模式按照不同特征可以分为以下类型:
(1)完全周期模式挖掘和部分周期模式挖掘 完全周期模式[14]描述了时间序列中的全局的周期性,部分周期模式[15]描述了时间序列中某些局部的周期性。部分周期模式相比于完全周期模式更为松散,也更符合真实的情况。完全周期模式的挖掘算法在信号分析领域中得到了广泛的研究,快速傅里叶变换和小波分析经常被用来发现时间序列中的完全周期模式。文献[16]提出一个基于向下封闭属性的部分周期模式挖掘算法,通过建立命中模式树来分离部分周期模式,提高挖掘效率。文献[17]提出了基于卷积的部分周期挖掘算法,采用基于改进的快速傅立叶变换来挖掘部分周期模式。文献[18]将时间序列划分为密区间,挖掘分布于各密区间上的同步部分周期模式。
(2)同步周期模式和异步周期模式的挖掘 同步周期模式[15]是指如果某周期模式在时间槽ti处发生,则该周期模式以后发生的时间槽一定是ti+period×n(n>0),其中:period是该周期模式的周期长度,不在这些固定时间槽发生的周期模式被视为不相关模式。异步周期模式[16]是指如果某周期模式在时间槽ti处发生,则该周期模式以后发生的时间槽不再限定只发生在ti+period×n(n>0),该周期模式可能随机出现在其他时间槽处。同步周期模式是异步周期模式的一个特例,异步周期模式更符合真实的情况。文献[16,19]提出一个最长子串识别(Longest Subsequence Identification, LSI)的异步周期模式挖掘算法,试图发现一个允许“噪声”的最长的周期序列,该算法可能会遗漏非最长异步周期序列。针对该缺陷,文献[20]提出一个基于哈希表和枚举的改进算法SMCA,该算法改进了LSI算法的缺陷。文献[21]提出一个改进的频繁模式树结构,用于挖掘呈现出周期性的频繁项集,文献[22]扩展了该算法,使其支持多个最小支持度的周期性的频繁项集的挖掘。
用户的GPS轨迹往往具有稀疏性,上述周期挖掘算法无法有效地发现隐藏的周期模式。虽然上述序列模式挖掘算法能够应对轨迹稀疏性,但它只关注序列的频繁性,而忽视了序列分布的周期性。目前,针对稀疏的GPS轨迹,还没有同时关注序列模式频繁性与周期性的挖掘模型与算法,从而导致无法全面、准确地发现用户的时空特征。
2 GPS轨迹的预处理方法
用户GPS轨迹的预处理方法综合考虑了GPS点的时间和空间特性从GPS轨迹挖掘出隐藏的热点区域,并将GPS轨迹转化为热点区域序列。该方法由去噪、停留点和切换点检测、停留点和切换点聚类、停留点和切换点替换4部分构成,如图1所示。
由于GPS系统自身精度的限制,以及天气和建筑物对GPS信号的影响,原始GPS轨迹中可能存在离群点。原始的GPS轨迹首先需要进行过滤去噪处理,删除轨迹中的离群点。离群点的检测主要依据GPS轨迹点的速度和加速度。GPS轨迹的交通模式是指用户运动所使用的交通工具,如步行、跑步、自行车、汽车和地铁等,识别常见的交通模式能够有效地丰富GPS轨迹所包含的信息。
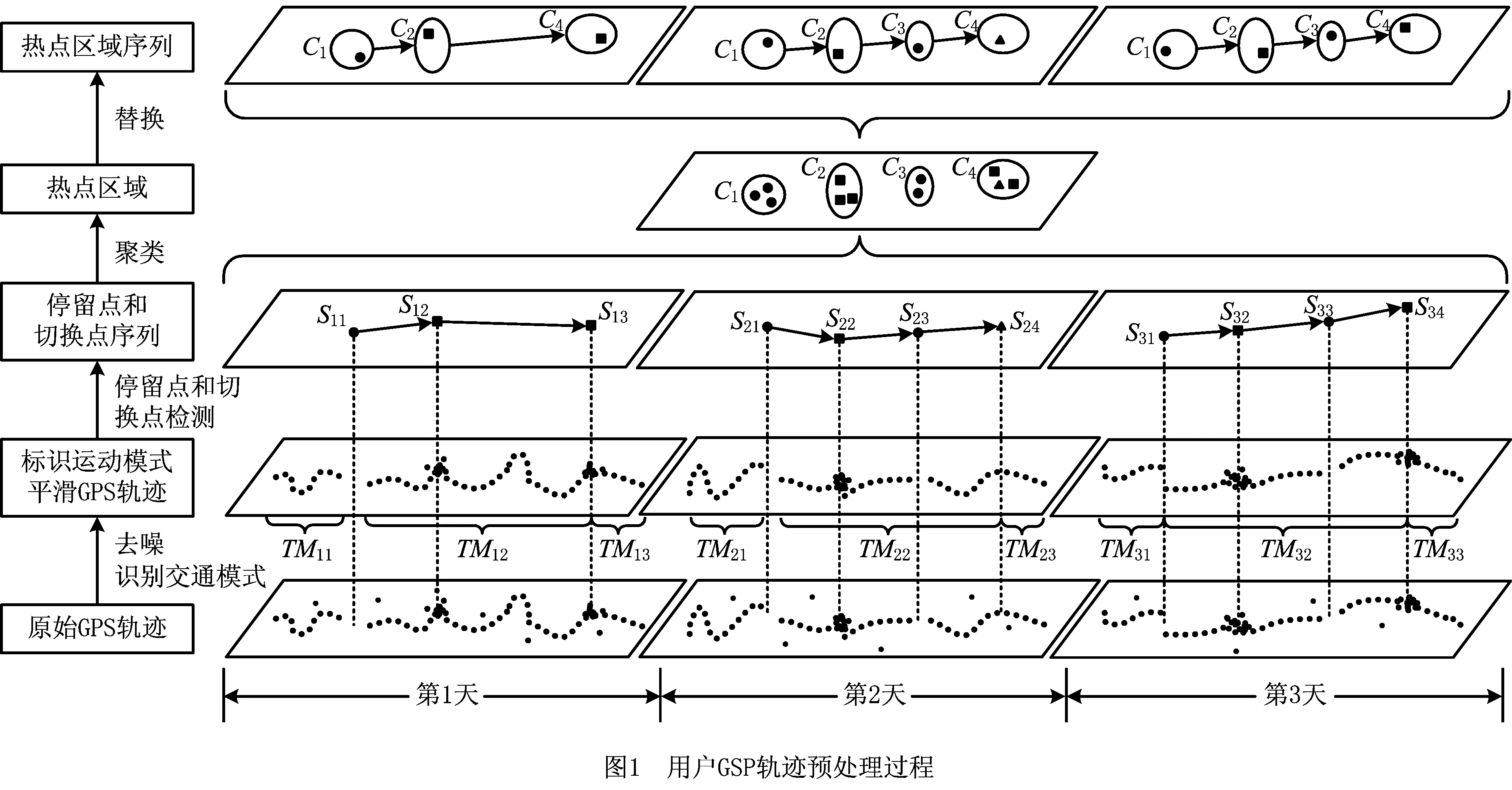
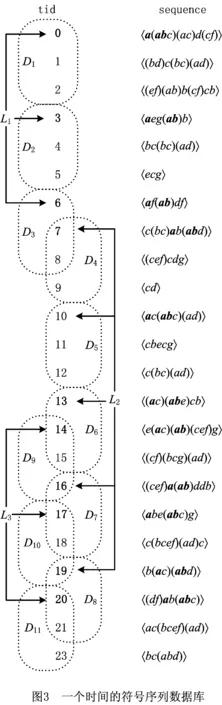
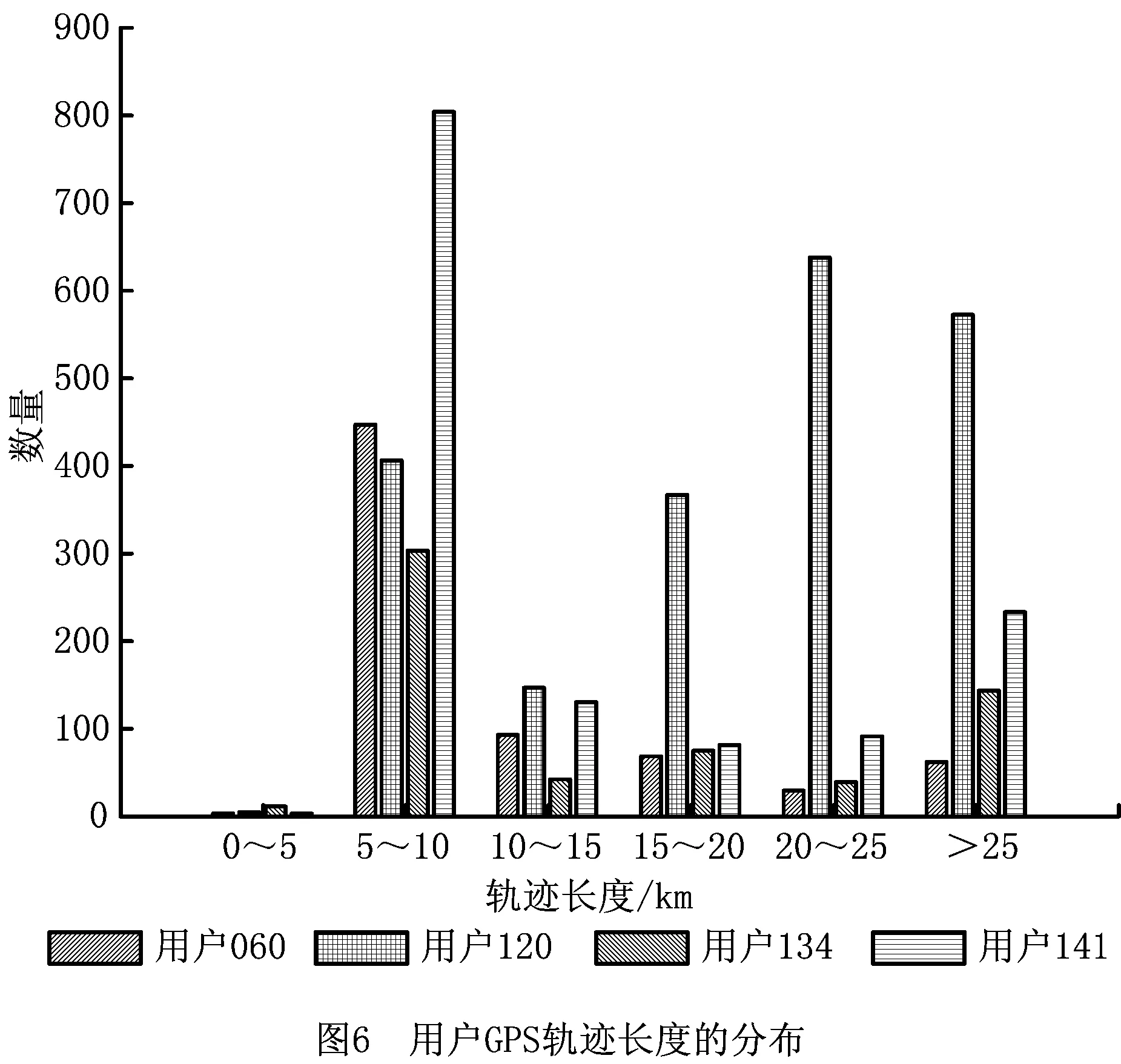
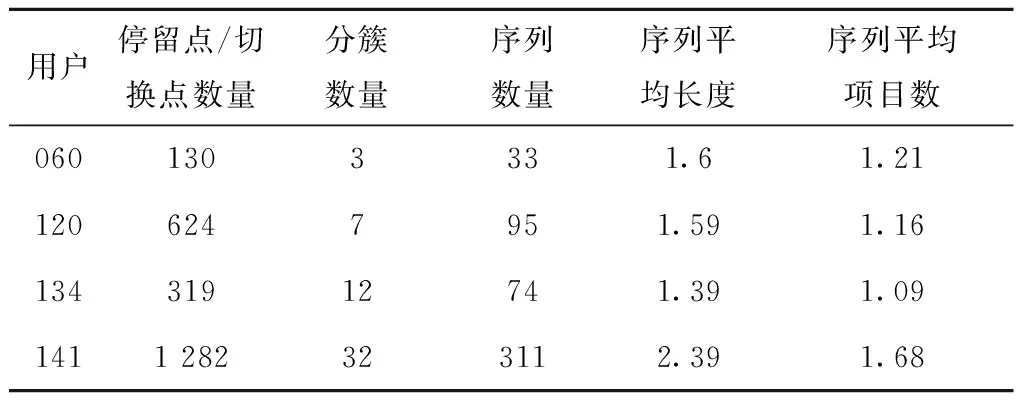
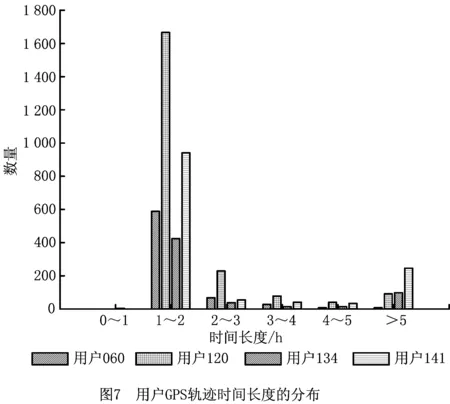
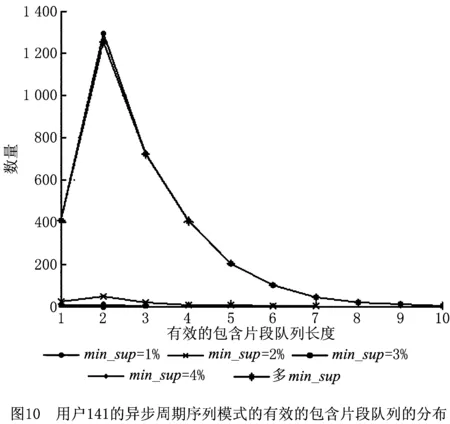
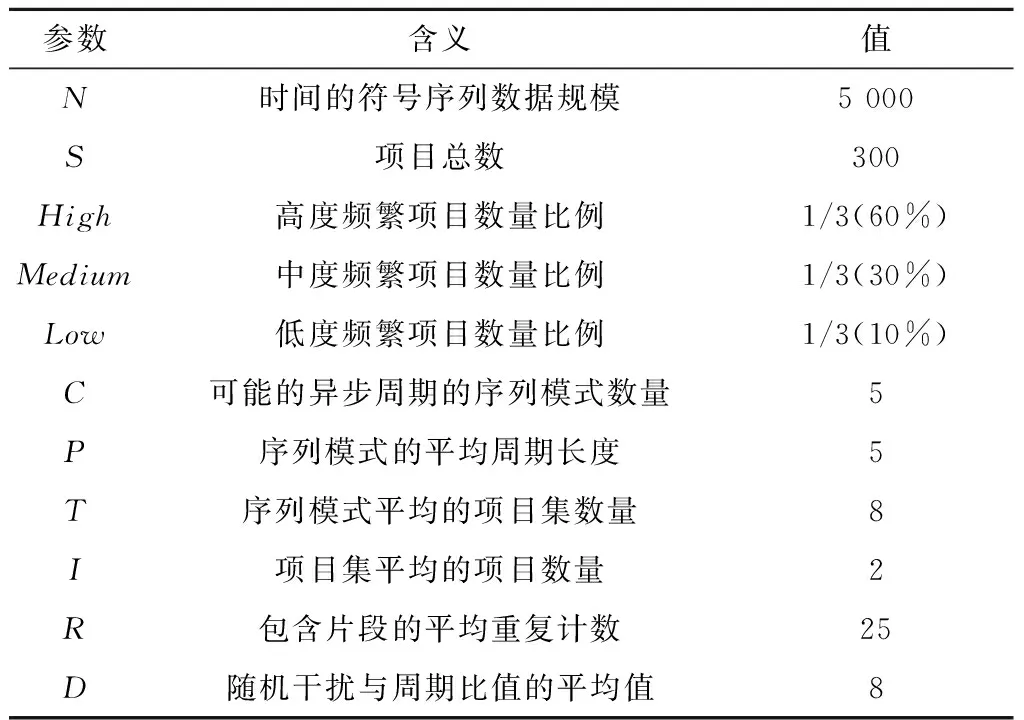
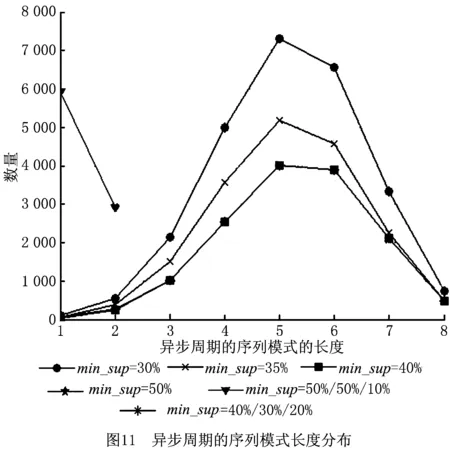
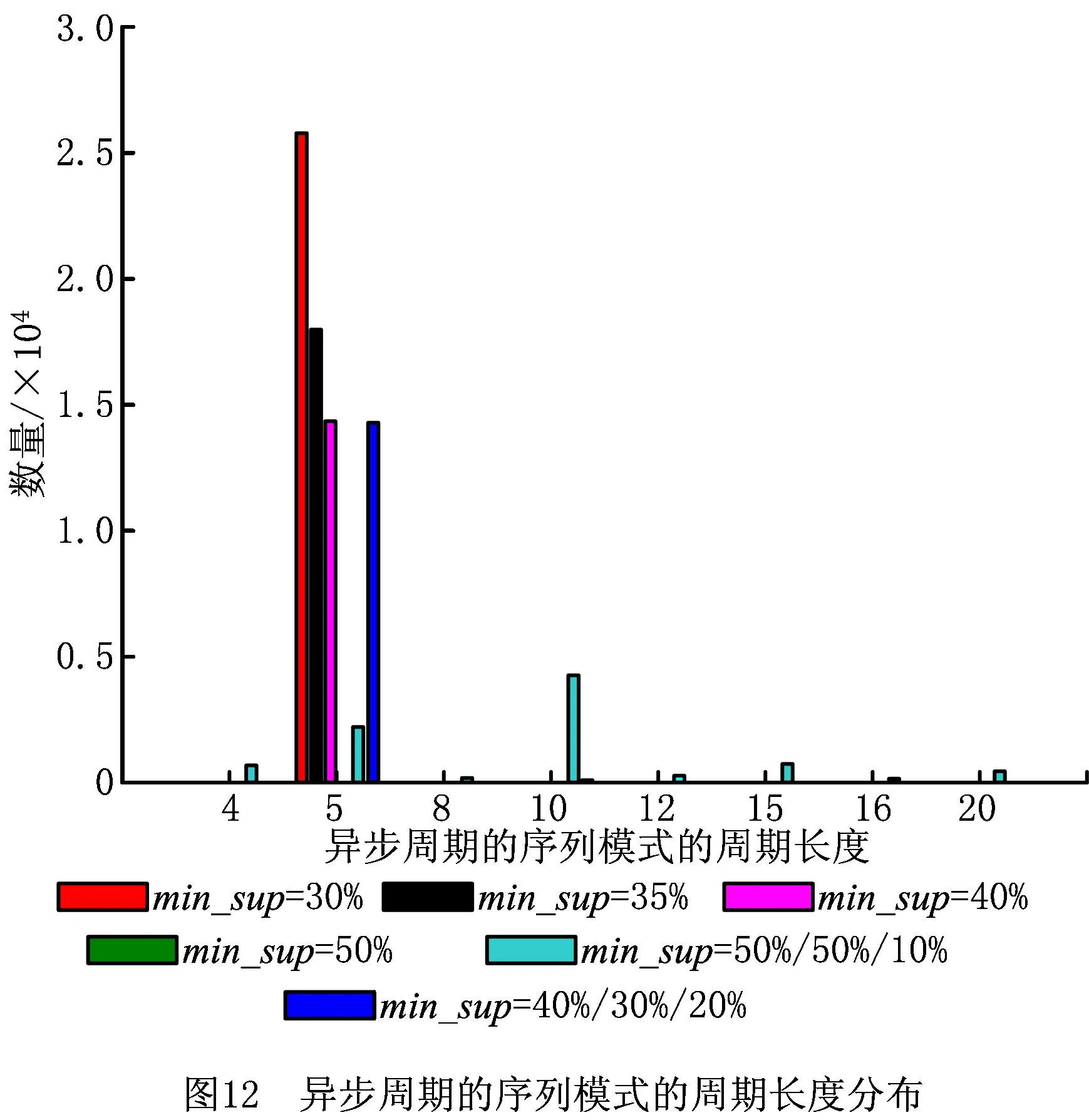
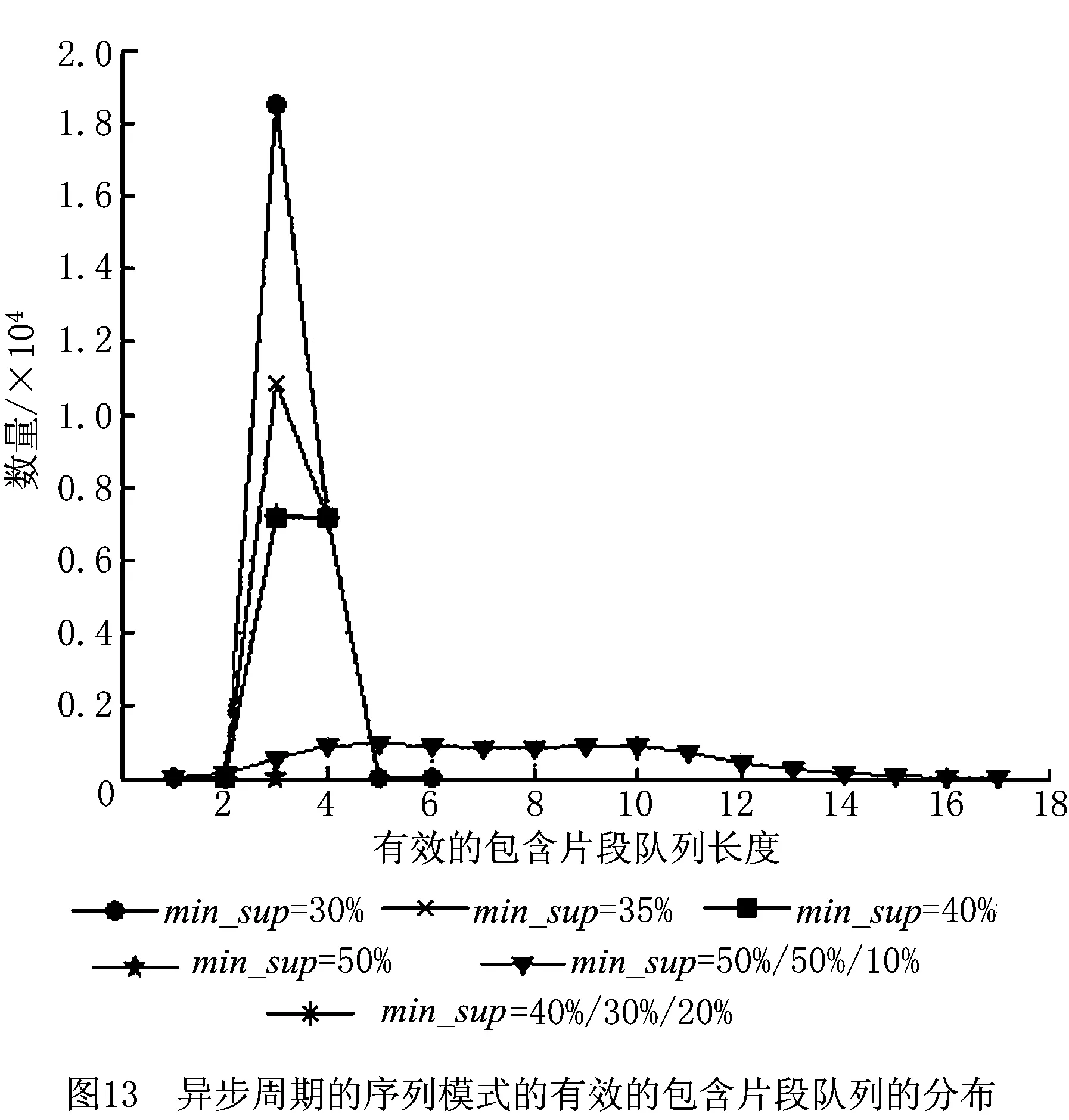
一条GPS轨迹Traj是由一组GPS点构成的队列,每个GPS点pi包含了纬度pi.latitude、经度pi.longitude和时间戳pi.time。轨迹表示为Traj=p1→p2→…→pn,其中:n为中的GPS点的数量,pi.time 停留点代表用户逗留或徘徊一段时间的地理位置,例如,用户进入屏蔽GPS信号的区域,并逗留一段时间后离开该区域(如图2a); 用户在一定的地理区域内徘徊(如图2b); 用户围绕地标移动(如图2c)。一个停留点s被视为由一组连续的GPS点确定的虚拟位置P={pm,pm+1,…,pn},其中,∀m s.startTime=pn.time,s.endTime=pm.time。 其中:latitude表示停留点的纬度,longitude表示停留点的经度,startTime表示停留点的起始时间,endTime表示停留点的结束时间。 切换点是指用户交通模式变化的地理位置,例如,用户基本没有停滞直接变化交通模式(如图2d); 切换用户经过停滞后变化交通模式(如图2e)。一个交通模式切换点s被视为由两个连续的GPS点确定的虚拟位置P={p1,p2},虽然交通模式的变化是瞬时的,但是为了更加准确地表示交通模式变化的过程,可以引入时间盐值ΔTsalt。交通模式切换点s表示为一个四元组s=(latitude,longitude,startTime,endTime),其中: s.latitude=(p1.latitude+p2.latitude)/2, s.longitude=(p1.longitude+p2.longitude)/2, s.startTime=p1.time-ΔTsalt, s.endTime=p2.time+ΔTsalt。 其中:latitude表示切换点的纬度,longitude表示切换点的经度,startTime表示切换点的起始时间,endTime表示切换点的结束时间。对于未标注交通模式的GPS轨迹,采用文献[23]提出的方法识别其交通模式。 算法1StayPointMiner(sequencegps,θd,θt) 输入:GPS轨迹sequencegps,距离阈值θd和时间阈值θt; 输出:停留点与切换点集合S。 1.i=0;gpsNum=|sequencegps|; 2.tm=pi.transMode; //初始的交通模式 3.WHILE(i 4. Stm=Ф; //交通模式切换点集合 5. FOR(j=i;j 6. IF(pj.transMode≠tm)THEN//交通模式变化 7. s.latitude=(pj-1.latitude+pj.latitude)/2; 8. s.longitude=(pj-1.longitude+pj.longitude)/2; 9. s.startTime=pj-1.time-ΔTsalt; //ΔTsalt盐值 10. s.endTime=pj.time+ΔTsalt; 11. Stm.insert(s); 12. tm=pj.transMode; 13. dis=Distance(pi,pj); 14. IF(dis>θd)THEN 15. ΔT=pj.Time-pi.Time; 16. IF(ΔT>θt)THEN 19. s.startTime=pi.time; 20. s.endTime=pj.time; 21. S.insert(s); 22. ELSE S.insert(Stm) 23. i=j;break; 24. ENDFOR 25.ENDWHILE 26.return S; GPS轨迹可以表示为停留点和切换点的序列,这个序列被称为位置轨迹,表示为 其中Δti=Si+1.startTime-Si.endTime。为消除不同位置轨迹的坐标偏差,需要对停留点和切换点进行聚类。将位置轨迹替换为热点区域序列,表示为 其中:Ci是Si所归属的热点区域,Δti与Loc中的相同。热点区域序列将作为后续序列模式挖掘算法的输入序列。 在讨论异步周期的序列模式挖掘算法之前,首先给出一些基本概念的定义。 假设I={i1,i2,…,in}是所有项的集合,项集是项的非空子集。序列是项集的有序列表,表示为s=s1,s2,…,sl>,其中:sj是一个项集,它也被称为s的一个元素,记为sj=(x1,x2,…,xm),其中xk是一个项。为简化表达,如果一个元素由单独的项构成,则省略元素的括号,如元素“(x)”表示为“x”。一个项最多在序列的一个元素中出现一次,但在序列的不同元素中可多次出现。不失一般性,假设元素中的项按照字典顺序排序,序列中项目的数目为序列的长度,长度为l的序列被称为l序列。 异步周期的序列模式挖掘的目标数据库为时间标注的符号序列数据库(temporal symbolic sequence database),它是一个元组的集合,TDB={t0,t1,…,t|TDB|-1},其中:|TDB|是元组的数量,ti是元组(tid,s),s表示一个序列,tid表示s发生的时间槽,如小时、天、周等。TDB的元组按照时间槽升序排序,且时间槽是等间距的。图3给出了一个由23个元组构成的时间的符号序列数据。 下面给出子序列和超序列、包含和发生、前缀、后缀、周期投影数据库、前缀投影数据库的定义。 定义1子序列和超序列。如果存在一组整数1≤j1 定义2包含和发生。给定一个序列α和TDB的一个元组t′=(tid′,s′),t′包含α(或α在t′发生),当且仅当α是s′的一个子序列。例如,如图3所示,(ab)adf在第一个元组(0,a(abc)(ac)d(cf))中发生。 定义5周期投影数据库。指定一个时间的符号序列数据库TDB和一个预设参数最大周期max_per,max_per<<(tidf-tidl),其中tidf和tidl分别是TDB的第一个和最后一个元组的时间标识。元组(tidl+i*p,sl+i*p)(0≤i≤m)构成了从时间槽l起始的、以p为周期的周期投影数据库prjp,l(TDB),其中:l 例如,如图3所示,prj3,1(TDB)包括元组1:(bd)c(bc)(ad),4:bc(bc)(ad),7:c(bc)ab(abd),10:ac(abc)(ad),13:(ac)(abe)cb,16:(cef)a(ab)ddb,19:b(ac)(abd)。 定义6前缀投影数据库。序列α以p为周期的包含片段L,是prjp,l(TDB)中连续包含α的元组所对应的时间槽列表。序列α为时间的符号序列数据库TDB中的一个异步周期的序列模式,则α的前缀投影数据库为TDB中所有以α为前缀的序列关于α的后缀构成的子数据库记为S|α。 下面给出异步周期的序列挖掘模型的相关概念定义。 定义7包含片段。序列α以p为周期的包含片段L,是prjp,l(TDB)中连续包含α的元组所对应的时间槽列表。包含片段L由四元组(α,p,rep,begin)表示,其中:α是目标序列,p是周期,rep是α的重复发生次数(L的重复计数),begin是α重复发生的起始位置(L的起始位置)。若在prjp,l(TDB)中,L两个方向上的相邻序列都不包含α,则L被称为最大的包含片段. 如图3所示,最大包含片段L2记为(a(ab),3,5,7),它表示a(ab)从tid7起始以3为周期重复发生了5次,发生的tid分别是7,10,13,16,19。相似地,L1记为(a(ab),3,3,0),L3记为(a(ab),3,3,14),它们同样是a(ab)周期为3的最大包含片段。 定义8有效的包含片段。一个最大包含片段L=(α,p,rep,begin)是有效的,当且仅当L的重复计数不小于预设的最小重复计数min_rep,即L.rep≥min_rep。 如图3所示,假设min_rep=3,则最大包含片段L1,L2,L3是a(ab)关于周期3的有效的包含片段,因为L1,L2,L3的重复计数分别为3、5和3,它们不小于3。 定义9包含片段的间隔。给出两个包含片段L和L′(L.begin 如图3所示,L1和L2之间的距离为1(7-6),L1和L3之间的距离为8(14-6),L2和L3之间的距离为-5(14-19)。因此,(L1,L2)和(L1,L3)不相交,而(L2,L3)是相交的。 定义10含片段的队列。包含片段的队列是由满足以下条件的一组包含片段组成的序列: (1)包含片段来自相同时间的符号序列数据库,并且是关于同一序列的相同周期的; (2)包含片段是有效的; (3)包含片段按照起始时间槽升序排列; (4)任意两个连续的包含片段是不相交的。 在图3所示的时间的符号数据库中,若预设min_rep=3,max_dis=3,min_sup=6,则(L1→L2)和(L1→L3)是a(ab)的周期为3的有效的包含片段队列。 在许多应用中,序列的周期性往往不是完美和精确的,序列的周期段之间可能存在噪声的干扰。同步周期的序列模式挖掘只能识别“序列缺失”的噪声,而无法识别“序列偏移”的噪声。噪声插入引起的序列偏移会导致许多有价值的序列模式无法被发现。“系统行为”经常在一段时间内重复发生,然后可能改变或消失,这导致序列模式可能在数据库的局部呈现出周期性。 针对上述问题,本文提出了异步周期的序列模式挖掘模型,发现时间的符号序列数据库中某些时间范围内呈现出周期性的序列模式,并能够容忍一定程度的噪声干扰。该模型的核心思想简述如下:判断一个序列是否是潜在的异步周期的序列模式,首先,该序列需要在某些时间范围内连续发生,这反映了序列具有显著的周期性的趋势;然后,检查这些序列周期性连续发生的时间范围之间的时间间隔,确定这些时间间隔是“随机噪声”还是“系统行为的改变”;最后,在允许噪声的前提下,序列周期性连续发生的时间范围被连接为最大的序列周期发生的时间范围。具体地,异步周期的序列模式及其挖掘模型定义如下: 定义12异步周期的序列模式。序列α是时间的符号数据库TDB的一个异步周期的序列模式,如果在TDB中至少存在一个关于α的有效的包含片段队列,该队列关联的周期是异步周期的序列模式α的一个周期。不难发现,一个异步周期的序列模式可能具有多个周期,而每个周期也可能对应了多个有效的包含片段队列。 定义13异步周期的序列模式挖掘模型。在指定最小支持度、最大间隔系数、最小重复计数和最大周期的前提下,异步周期的序列模式挖掘就是发现时间的符号数据库中所有异步周期的序列模式及其对应的有效包含片段队列。 如果使用单一最小支持度进行挖掘,则隐含假设所有项目具有相同的性质和相似的出现频率。该隐含假设与实际情景相违背,导致含有稀少但重要项目的序列模式被遗漏。一个完善的异步周期的序列模式挖掘算法应该支持多个最小支持度,即用户可以为每个项目指定一个最小支持度,不同的序列根据其所包含项目的不同需要满足不同的最小支持度。多最小支持度不仅能够避免由于单一最小支持度设置过低所产生的大量无意义的模式,还能够对含有稀少项目的模式进行挖掘. 为了按照多个最小支持度进行异步周期的序列模式的挖掘,本文提出一个基于模式增长的多最小支持度挖掘算法AP-PrefixspanM(Asynchronous Periodic Prex-projected sequential patterns with Multiple minimum item supports)挖掘算法。 令MinIS(i)表示第i个项目的最小支持度值,序列模式P的最小支持度是P所有项目中最低的最小支持度值,设P中项目的集合为i1,i2,…,ik,则P的最小支持度为 min_sup(P)=min(MinIS(i1), MinIS(i2),…,MinIS(ik))。 令MinREP(i)表示第i个项目的最小重复计数值,P的最小重复计数是P所有项目中最低的最小重复计数,即 min_rep(P)=min(MinREP(i1), MinREP(i2),…,MinREP(ik))。 令MaxDis(i)表示第i个项目的最大干扰间隔系数,P的最大干扰间隔系数是P中所有项目中最高的最大干扰间隔系数,即 max_dis(P)=max(MaxDIS(i1), MaxDIS(i2),…,MaxDIS(ik))。 为减少用户设置的工作量,又不失一般性,假设项目的最小重复计数、最大干扰间隔系数与最小支持度之间存在函数关系。具体地,第i个项目的最小重复计数MinREP(i)与最小支持度MinIS(i)之间呈线性递增关系: MinREP(i)=λ×MinIS(i),0<λ≤1。 第i个项目的最大周期间隔系数MaxDis(i)与最小支持度MinIS(i)之间呈指数递减关系: 其中:η是预设的干扰间隔常数,max(MinIS)是MinIS中最大的最小支持度。 若MinIS(i1)≤MinIS(i2)≤…≤MinIS(ik),则MinREP(i1)≤MinREP(i2)≤…≤MinREP(ik),MaxDIS(i1)≥MaxDIS(i2)≥…≥MaxDIS(ik)。 为了大幅压缩异步周期的序列模式挖掘的搜索空间,单一最小支持度的异步周期的序列模式挖掘模型利用向下封闭属性。 性质1向下封闭属性(Downward Closure Property)。如果序列α是一个异步周期的序列模式,且其有效的包含片段队列集合为QSet,则任何α的非空子序列也是异步周期的序列模式,且该子序列的有效的包含片段队列的集合是QSet的超集。 当使用多个最小支持度进行异步周期的序列模式挖掘时,一个异步周期的序列模式的最小支持度可能小于其子序列的最小支持度,因此,无法直接应用向下封闭属性剪枝搜索空间。 AP-PrefixspanM算法的主要思想是采用分治策略,将异步周期的序列模式挖掘问题逐级地分解为互不相交的更小的异步周期的序列模式挖掘的子问题,先深递归地挖掘相应的子数据库即可以解决子问题。算法的数据库划分框架如图4所示,包括两种划分方式:①利用向下封闭属性剪枝搜索空间,在第1层根据最小支持度向量将数据库拆分为一系列子数据库;②从模式增长的方式产生异步周期的序列模式,在第2层以下的层次按照前缀递归产生前缀投影数据库。 AP-PrefixspanM算法首先根据最小支持度向量拆分数据库,产生一系列以单一最小支持度进行挖掘的子数据库。其中每次拆分都以一个频繁项目为基准,该频繁项目称为关键项目,挖掘该子数据所采用的单一最小支持度为该关键项目的最小支持度,挖掘这些子数据能够利用向下封闭属性剪枝搜索空间。具体的数据拆分步骤描述如下(具体算法如算法2所示): 步骤1扫描一遍目标数据库TDB,获取每个真实支持度至少为MinIS(xi)的项目xi,这样的xi被称为频繁项目,将频繁项目按照其MinIS(xi)升序排列,获得列表list=x1,x2,…,xn,(xi≤xi+1)。 步骤2异步周期的序列模式的完全集可以划分为以下n个互不相交的子集(允许子集为空): (1)包含x1的序列模式; (2)包含x2,但不包含x1的序列模式; …… (i)包含xi,但不包含{x1,x2,…,xi-1}的序列模式; …… (n)只包含xn的序列模式。 按上述n个子集将TDB拆分为以下n个子数据库,分别挖掘这些子数据库即可以获得上述n个异步周期的序列模式子集。 (1)TDB1(关键项目x1),删除元组中非频繁的项目,删除不包含x1的元组; (2)TDB2(关键项目x2),删除元组中非频繁的项目和x1,删除不包含x2的元组; …… (i)TDBi(关键项目xi),删除元组中非频繁的项目和{x1,x2,…,xi-1},删除不包含xi的元组; …… (n)TDBn(关键项目xn),删除元组中除xn以外的所有项目,删除不包含xn的元组。 针对拆分后的子数据库TDBi,算法以MinIS(xi)作为最小支持度进行异步周期的序列模式挖掘。挖掘TDBi中异步周期的序列模式的问题可以分解为一系列互不相交的子问题: (2)设α是一个长度为l的异步周期的序列模式,{β1,β2,…,βo}是所有以α为前缀、长度为l+1的异步周期的序列模式集。除α本身以外,以α为前缀的异步周期的序列模式的完全集可以划分为k个互不相交的子集,第k个子集(1≤k≤o)是以βk为前缀的异步周期的序列模式子集,如图5所示。 基于上述分析,异步周期的序列模式的挖掘问题可以进行递归划分,即每个异步周期的序列模式子集合可以进一步划分,进而构成一个分治框架。为了挖掘异步周期的序列模式的子集,可以构造相应的前缀投影数据库,并先深递归地挖掘每个前缀投影数据库。针对每个子数据库TDBi具体的挖掘步骤描述如下(具体如算法2中函数1所示): 步骤1生成参数。以MinIS(xi)作为最小支持度,并生成相应的最小重复计数MinREP(xi)和最大干扰间隔系数MaxDIS(xi)。 步骤2发现长度为1的序列模式。扫描数据库一次,生成所有长度为1的异步周期的序列模式,并将长度为1的异步周期序列模式扩展到当前前缀之后,获得长度加1的序列模式。 步骤3划分搜索空间。将异步周期的序列模式完全集划分上述长度加1的序列模式为前缀的序列模式子集。 步骤4发现异步周期的序列模式的子集。分别构建相应的前缀投影数据库,递归地挖掘出每个异步周期的序列模式的子集。具体地,在相应的前缀投影数据库中重复上述步骤,直到不能产生长度为1的异步周期的序列模式为止。在上述挖掘过程中,只有那些包含关键项目的异步周期的序列模式添加到挖掘结果中,其他模式在完成挖掘后被删除。 AP-PrefixspanM算法的伪码如算法2所示。首先,根据最小支持度向量MinIS生成最小重复计数向量MinREP和最大干扰间隔系数向量MaxDIS(如算法2中步骤1和步骤2所示)。然后,扫描目标数据TDB一次,找出所有真实支持度至少为MinIS(xi)的频繁项目xi,它是潜在长度为1的异步周期的序列模式(如算法2中步骤4所示),按照最小支持度向量MinIS升序排序频繁项目,获得队列SPF1(如算法2中步骤5所示)。最后,根据SPF1,获取|SPF1|个拆分后的子数据库。针对每个子数据库,调用MAPPrefixSpan函数进行异步周期的序列模式的挖掘(如算法2中步骤6~步骤10所示)。 算法2AP-PrefixspanM(TDB,MinIS,max_per)。 输入:目标数据库TDB,最小支持度向量MinIS和最大周期max_per; 输出:所有异步周期的序列模式及有效的包含片段队列。 1.MinREP←generateREP(MinIS); 2.MaxDIS←generateDIS(MinIS); 3.L←init_pass(M,TDB); 4.PF1←{〈l〉|l∈L,l.count≥MinIS(l)}; 5.SPF1←sort(PF1,ASCEND); 9. MAPPrefixSpan(null,SUB_TDB〈xi〉,〈xi〉,MinIS(xi),MaxREP(xi),MaxDIS(xi)); ENDFOR 函数1MAPPrefixSpan(prefix,DB,c_item,min_sup,min_rep,max_per,max_dis)。 输入:前缀prefix,时间标识的符号序列数据库TDB,关键项目c_item,最小支持度min_sup,最小重复计数min_rep,最大周期max_per,最大干扰间隔系数max_dis 2.FOR each tuple t in DB DO 3. IF〈x〉∈t.s,x∈L THEN 4. hash_item[x].count++;hash_item[x].tid←t∪t.tid.tid; 5. IF〈{perfix.litemset,x}〉or〈_x〉∈t.s,x∈L THEN 6. //prefix.litemset是前缀的最后一个项集 7. hash_item[_x].count++;hash_item[_x].tid←t.tid;; 8.ENDFOR 9.FOR each key c in hash_item DO 10. IF hash_item[c].count 11.ENDFOR 12.FOR each key c in hash_item DO 13. ASPDetector(c,hash_item[c],c_item,prefix,min_sup,min_rep,max_per,max_dis); 14. IF c can be extended to prefix THEN 15. newprefix←extend(c,prefix); 16. DB|c←Projectdatabase(c,DB); 17. IF prefix not contain c_item THEN 18. delete tuples in DB|cwhich not contain c_item; 19. IF min_sup≤|DB|c|THEN 20. AP-PrefixspanM(newprefix,DB|c,c_item, min_sup,min_rep,max_per,max_dis); 21.ENDFOR MAPPrefixSpan函数通过深度优先搜索方式查找所有异步周期的序列模式,其伪码如函数1所示。首先,定义一个哈希表hash_itemitem_id,(count,tids)记录每个频繁项目的发生次数及相应的时间槽(如函数1中步骤1所示)。其中:item_id是哈希表的键,二元组(count,tids)是键值,count代表item_id的发生次数,tids代表item_id发生的时间槽队列。每个项目x都有两种可能的方式扩展到前缀,获得新的序列模式:①将x加入前缀的最后一个项集,此时,x对应的item_id表示为“_x”;②将x独立地加入前缀,此时,x对应的item_id表示为“x”。扫描投影数据库TDB,通过哈希表hash_item记录每个项目在两种扩展方式下的发生次数及相应的时间戳队列(如函数1中步骤2~步骤8所示)。删除hash_item中发生次数小于min_sup的项目(如函数1中步骤9~步骤11所示)。此时,hash_item中的频繁项目可能扩展到当前前缀产生新的异步周期的序列模式。针对每个项目,通过ASPDetector函数进一步判断频繁项目扩展到前缀的可能性和产生新模式的可能性,如果可以产生新模式,则生成新模式所有有效的包含片段队列集合(如函数1中步骤13所示)。若频繁项目能扩展到前缀,则生成扩展后的前缀(如函数1中步骤15所示)。同时,调用Projectdatabase函数产生当前项目的前缀投影数据库DB|c,若前缀不包含c_item,则删除DB|c中不包含关键项目c_item的元组(如函数1中步骤16~18所示)。若过滤后的DB|c中元组数量不小于min_sup,则递归调用MAPPrefixSpan函数,在更小的前缀投影数据库上继续查找可以扩展到前缀的项目,发现逐渐增长的异步周期的序列模式(如函数1中步骤19~步骤20所示)。在上述递归过程中,所有异步周期的序列模式及其有效的包含片段队列将被发现。 ASPDetector函数判断能否将当前项目扩展到前缀,进而获得新的增长的异步周期的序列模式(简称新模式),并发现新模式的有效的包含片段队列。模式增长的判断由3个阶段构成:①潜在周期探测阶段(Potential Period Detection, PPD);②有效的包含片段探测阶段(Valid Segment Detection,VSD);③有效的包含片段合并阶段(Valid Se gment Mergence,VSM)。 (1)PPD阶段(如函数2中步骤3~步骤9所示)负责探测新模式所有可能的周期 哈希表hash_periodp,count用于记录周期的出现次数,其中键值count初始化为1。扫描参数occur的时间槽队列,以队列的首个时间槽起始,建立一个长度为最大周期max_per的滑动窗口,分别计算窗口内第一个时间槽与它之后的时间槽之间的时间间隔。在时间槽队列的任一时间槽tidi处,计算tidi和tidj之间的间隔pij=|tidi-tidj|,其中i+1≤j≤min(max_per-i,|occur|),若pij≤max_per,则hash_period对应周期pij的计数加1(如函数2中步骤4和步骤5所示);否则,停止计算,将窗口滑动到tidi之前的时间槽tidi+1处,重复上述计算过程,产生以pi(1≤pi≤max_per)为周期的新模式的必要条件是周期pi出现的次数不小于min_rep,即hash_period[pi]≥min_rep。 (2)VSD阶段负责发现新模式的所有有效的包含片段 首先,对于每个潜在的周期pi定义一个哈希表hash_segmentpos,(rep,last)来记录模式的包含片段(如函数2中步骤10所示)。其中:键pos表示模式的偏移量,键值(rep,last)记录包含片段的重复计数和最新时间槽。在时间槽队列的任一时间槽tidi处,tidj-hash_segment[posi].last(posi=tidi%pi)表示偏移量为posi时两次同步发生的时间间隔。若tidi-hash_segment[posi].last=pi,则这两次发生在同一包含片段中是同步连续的。hash_segment[posi].rep记录了包含片段的重复计数,当hash_segment[posi].rep≥min_rep时,当前偏移量为posi的包含片段被认为是有效的。具体地,对于每一个周期pi,算法需要扫描一遍时间槽队列,针对队列中的每个时间槽tidi,计算偏移量posi=tidj%pi(如函数2中步骤13所示),若tidj-hash_segment[posi].last=pi,意味着当前包含片段增长,hash_segment[posi].rep加1,并更新hash_segment[posi].last为tidi(如函数2中步骤15和步骤16所示),而后继续处理下一个时间槽;否则,意味着当前包含片段中断,此时,若hash_segment[posi].rep≥min_rep,意味着当前中断的包含片段是有效的,它以四元组的形式记录在vs_set中(如函数2中步骤18~步骤20所示)。该包含片段中断后,hash_segment[posi].rep重置为1,hash_segment[posi].last更新为tidi(如函数2中步骤21和步骤22所示)。当时间槽队列检验完毕后,再检查一遍hash_segment,判断是否存在有效的包含片段(如函数2中步骤24~步骤27所示)。将所有以pi为周期的有效包含片段按照起始时间槽升序排序(如函数2中步骤28所示)。针对每个包含片段调用MergeSeg函数合并包含片段,生成所有以pi为周期、当前包含片段起始的有效的包含片段的队列(如函数2中步骤29~步骤31所示),并输出模式中包含关键项目的有效包含片段队列。 (3)VSM阶段负责生成有效的包含片段队列MergeSeg函数采用深度优先的枚举方式将所有可能合并的包含片段组合成队列。分别产生不同包含片段起始的片段队列,对于每个包含片段,算法采用分治策略,每次查找能够与起始片段直接合并的片段,分别以这些片段为起始片段递归地查找能直接合并的片段,重复该过程直至没有可以继续合并的片段。具体地,如果起始片段的重复计数不小于min_sup,则输出该片段(如函数2中步骤29和步骤30所示)。针对任一起始片段,扫描一遍svs_set,发现可以直接合并的片段集合(如函数3中步骤2~步骤7所示)。对于集合中的片段,递归地调用MergeSeg函数(如函数3中步骤14所示),每次递归产生更小的片段集合(如函数3中步骤11所示),并可能合并出更长的片段队列(如函数3中步骤9所示)。在合并过程中一旦发现队列中片段重复计数的和不小于min_sup,且模式含有关键项目,则输出该片段队列(如函数3中步骤12和步骤13所示)。 函数2ASPDetector(fitem,occur,c_item,prefix,min_sup,min_rep,max_per,max_dis)。 输入:频繁项目fitem,时间槽列表occur,关键项目c_item,前缀prefix,最小支持度min_sup,最小重复计数min_rep,最大周期max_per,最大干扰间隔系数max_dis。 2.FOR each tidiin occur.tids DO 3. FOR each tidjin occur.tids,i 4. IF(|tidj-tidi|)≤max_per THEN 5. hash_period[tidj-tidi].count++; 6. ELSE break; 7. ENDFOR 8.ENDFOR 9.FOR each key pithat hash_period[pi]≥min_rep DO 11. vs_set(patten,period,rep,start)←; 12. FOR each tidiin occur.tids DO 13. posi←tidimod pi; 14. IF(tidi-hash_segment[posi].last)==piTHEN 15. hash_segment[posi].rep++; 16. hash_segment[posi].last←tidi; 17. continue; 18. IF hash_segment[posi].rep≥min_rep THEN 19. pattern←extend(prefix,fitem); 20. vs_set←vs_set∪(pattern,pi,hash_segment[posi].rep,hash_segment[posi].last -pi*(hash_segment[posi].rep-1)); 21. hash_list[posi].rep←1; 22. hash_list[posi].last←tidi; 23.ENDFOR 24.FOR each key posithat hash_list[posi]≥min_rep DO 25. pattern←extend(prefix,fitem); 26. vs_set←vs_set∪(pattern,pi,hash_list[posi].rep, 27. ENDFOR 28. svs_set←sort(vs_set); 29. FOR each vsiin svs_set DO 30. IF(vsi.rep≥min_sup)&&(c_item∈pattern)THEN 31. Output(vsi); 32. MergeSeg(vsi,svs_set,vsi.rep,min_sup,max_dis); 33. ENDFOR 函数3MergeSeg(prefix_segs,svs_set,prefix_sum,min_sup,max_dis)。 输入:前缀片段prefix_segs,包含片段集合svs_set,前缀片段重复次数prefix_sum,最小支持度min_sup,最大干扰间隔系数max_dis。 2.FOR each vsiin svs_set i>1 DO 3. tail←vs1.start+vs1.period*(vs1.rep-1); 4. IF((vsi.start-tail)>max_dis*p)THEN break; 5. ELSE IF(tail>vsi.start)THEN continue; 6. ELSE VSQ←VSQ∪vsi; 7.ENDFOR 8.FOR each vsiin VSQ DO 9. newprefix_segs←prefix_segs∪vsi; 10. newprefix_sum←prefix_sum+vsi.rep; 11. newsvs_set←svs_set delete segments before vsi; 12. IF(newprefix_sum≥min_sup)&&(c_item∈pattern)THEN 13. Output(newprefix_segs); 14. MergeSeg(newprefix_segs,newsvs_set,prefix_sum,min_sup,max_dis); 15.ENDFOR 本文实验所用数据集是微软亚洲研究院的Geolife数据集中4位用户3年(2007年4月~2010年12月)的GPS轨迹数据。数据集中的一条GPS轨迹是由一组按照时间升序排列的GPS点所组成的序列,每个GPS点记录了经度、维度、海拔高度、日期和时间。在数据集中,用户120记录了2135条GPS轨迹,用户141记录了1 343条GPS轨迹,用户060记录了723条GPS轨迹,用户060记录了621条GPS轨迹。本文对这4位用户的GPS轨迹的距离长度和时间长度进行了统计,如图6所示,时间长度的统计结果如图7所示。统计结果显示,用户每天往往只记录几个小时的GPS轨迹,且多数GPS轨迹的时间长度分布在1~2小时之间,较为稀疏,GPS轨迹的距离长度由时间长度和运动模式共同决定。 GPS轨迹的转化步骤包括去噪、停留点和切换点检测、停留点和切换聚类、停留点和切换点替换4个步骤。在去噪过程中,设置速度和加速度的上限阈值分别设置为35 m/s和10 m/s2。在停留点的检测算法中,时间阈值被设置为15 min,距离阈值被设置为150 m,即若用户在150 m的距离内徘徊15 min以上,则会产生一个停留点。本文利用OPTICS算法对用户的停留点和切换点进行聚类,其中,ε邻域最小点数MinPts参数设置为4,可达距离的阈值设置为150 m。按照本文提出的GPS轨迹预处理方法对4位用户的GPS轨迹进行处理,转化后的统计结果如表5所示。 表5 用户GPS轨迹预处理统计结果 利用AP-PrefixspanM算法分别对用户141的热点区域序列进行异步周期的序列模式挖掘。图8给出了在不同最小支持度条件下,异步周期的序列模式的长度分布。当最小支持度为1%时,产生了大量的无意义的序列模式,此后,随着最小支持度的增大,序列模式的数量急剧减少。当最小支持度为4%时,只存在3个长度为1的模式。长度为1的序列模式数量最多,这是因为用户GPS轨迹的时间长度较短,不足以生成较长的序列模式。图9给出了不同最小支持度条件下,序列模式的周期长度分布。当最小支持度不小于2%时,多数序列模式的周期长度分布在1~14天之间。图10给出了在不同最小支持度条件下,有效的包含片段队列的长度分布,有效的包含片段队列的长度是指它所含有的有效包含片段数量。当最小支持度不小于2%时,多数有效的包含片段队列的长度分布在1~3之间。 考虑到用户真实GPS轨迹的稀疏性,为进一步验证异步周期的序列模式挖掘算法的有效性和稳定性,本文依据文献[16]设计实现了一个仿真数据的生成算法,如算法3所示。首先,算法产生C个可能的异步周期的序列模式,其周期由期望为P的正态分布生成,模式的项目集数由期望为T的正态分布生成,项目集的平均项目数由期望为I的正态分布生成,项目出现的概率按照高频(High)、中频(Medium)和低频(Low)3个等级分布,模式的起始位置由期望为N/5的均匀分布决定。然后,针对每一个异步周期的序列模式,产生一组包含片段直至到达末尾时间槽,并将该模式按照这组包含片段插入到相应的时间槽,其中,包含片段的重复计数由期望为R的正态分布产生。最后,扫描一遍所有的时间槽,如果时间槽中序列为空或较短,则向序列中补充一些项目,项目总数由期望为T×I的泊松分布产生。 算法3.DataGenerator(N,S,High,Medium,Low,C,P,T,I,R,D) 输入:参数及其含义如表5所示。 输出:仿真数据集。 1. FOR i=1 to C do 2. p.period=GaussianDist(P,MAXPER); 3. p.pattern=GenPattern(p.period,T,I,High,Medium,Low); 4. position=UniformDist(N/5); 5. WHILE(1)DO 6. p.local=GeometricDist(R,MAX=N/P); 7. IF(N-position 8. FOR j=1 to p.local DO 9. position+=p.period; 10. insert p.pattern into TIDS[position]; 11. ENDFOR 12. p.disturbance=p.period*GeometricDist(D,MAXDIS); 13. postion+=p.disturbance; 14. ENDWHILE 15.ENDFOR 16.FOR i=1 to N DO 17. t=PoissonDist(I,MAX=N); 18. k=t-|TIDS[i]|; 19. random generatek symbols with TIDS[i]; 20.ENDFOR 利用仿真数据集生成算法得到一个仿真数据集,算法参数值如表6所示。利用AP-PrefixspanM算法对仿真数据集进行异步周期的序列模式挖掘,算法的最大周期max_per为20,系数λ和η分别为0.2和10. 表6 仿真数据集生成算法参数设置 图11给出了不同最小支持度条件下,异步周期序列模式的长度分布。实验结果显示,随着最小支持度的减小,序列模式的数量逐渐增大。当将高频、中频项目的最小支持度设置很高(5%),低频项目的最小支持度设置很低(1%)时,出现了大量长度为1或2的序列模式,表明即使只关注低频项目,如果最小支持度过低,也会出现大量无意义的序列模式。在其他最小支持度条件下,随着序列模式长度的增加,序列模式数量激增,当序列模式长度为5时,序列模式数量达到最大值,之后随序列模式长度增加递减。项目总数较少导致了长度短的序列模式数量较少。随着模式增长,越来越多的项目能够扩展到短模式,导致了模式数量的激增。随着模式长度的增加,可扩展的项目减少,导致了模式数量的减少。当高中低频项目的最小支持度分别为4%、3%和2%时,序列模式数量略高于最小支持度为4%时的序列模式数量,这说明AP-PrefixspanM算法能够有效地挖掘出含有稀少项目的异步周期的序列模式,同时避免了产生大量无意义的模式。 图12给出了不同最小支持度条件下,异步周期序列模式周期长度的分布。实验结果显示,当高中低频项目最小支持度分别为5%、5%和1%时,周期长度呈现出混乱的状态,这表明挖掘结果中存在着大量无意义的序列模式。在其他最小支持度条件下,挖掘出的异步周期的序列模式的周期长度几乎都是5,这与数据集生成算法的预设参数P=5相符合。 图13给出了在不同的最小支持度条件下,有效的包含片段队列的长度分布。实验结果显示,除高中低频项目最小支持度分别为5%、5%和1%外,在其他最小支持度条件下,有效的包含片段队列的长度多数为3或4。虽然数据集生成算法的预设参数R=25,即包含片段的平均重复计数25,但序列模式的独立插入和序列的随机补充导致许多较短序列模式的包含片段的重复计数大于25,从而使得有效的包含片段队列的长度多数为3或4。 上述实验结果证明了AP-PrefixspanM算法能够稳定、有效地用于异步周期的序列模式的挖掘。 物联网应用往往涉及用户的时空特性,用户的运动模式是时空特性最直接的表现。用户运动模式往往呈现出不完美的规律性,即有序的规律中掺杂着无序的干扰噪声。这些不完美的模式揭示了用户的兴趣偏好、行为模式和生活规律等诸多特征。用户时空特征为制定个性化物联网应用提供了决策依据。基于此,本文提出了物联网用户的时空特征挖掘算法,从GPS轨迹中发现隐藏的用户运动模式,。具体而言,提出了:①GPS轨迹的转化方法,将 GPS 轨迹转化为热点区域序列;②异步周期的序列模式挖掘模型,用于发现时间标注的符号序列数据库中频繁出现的且呈现出异步周期性的序列模式,并识别出它们发生的时间范围;③基于模式增长的多最小支持度的异步周期的序列模式挖掘算法,采用分治的策略,将异步周期的序列模式挖掘问题逐级地分解为互不相交的更小的异步周期的序列模式挖掘的子问题,在相应的子数据库上进行异步周期的序列模式挖掘。实验结果证明了该算法的有效性和准确性。未来将在时空特征挖掘算法中引入地图的语义信息,进而更加全面、准确地获取物联网用户的时空特征。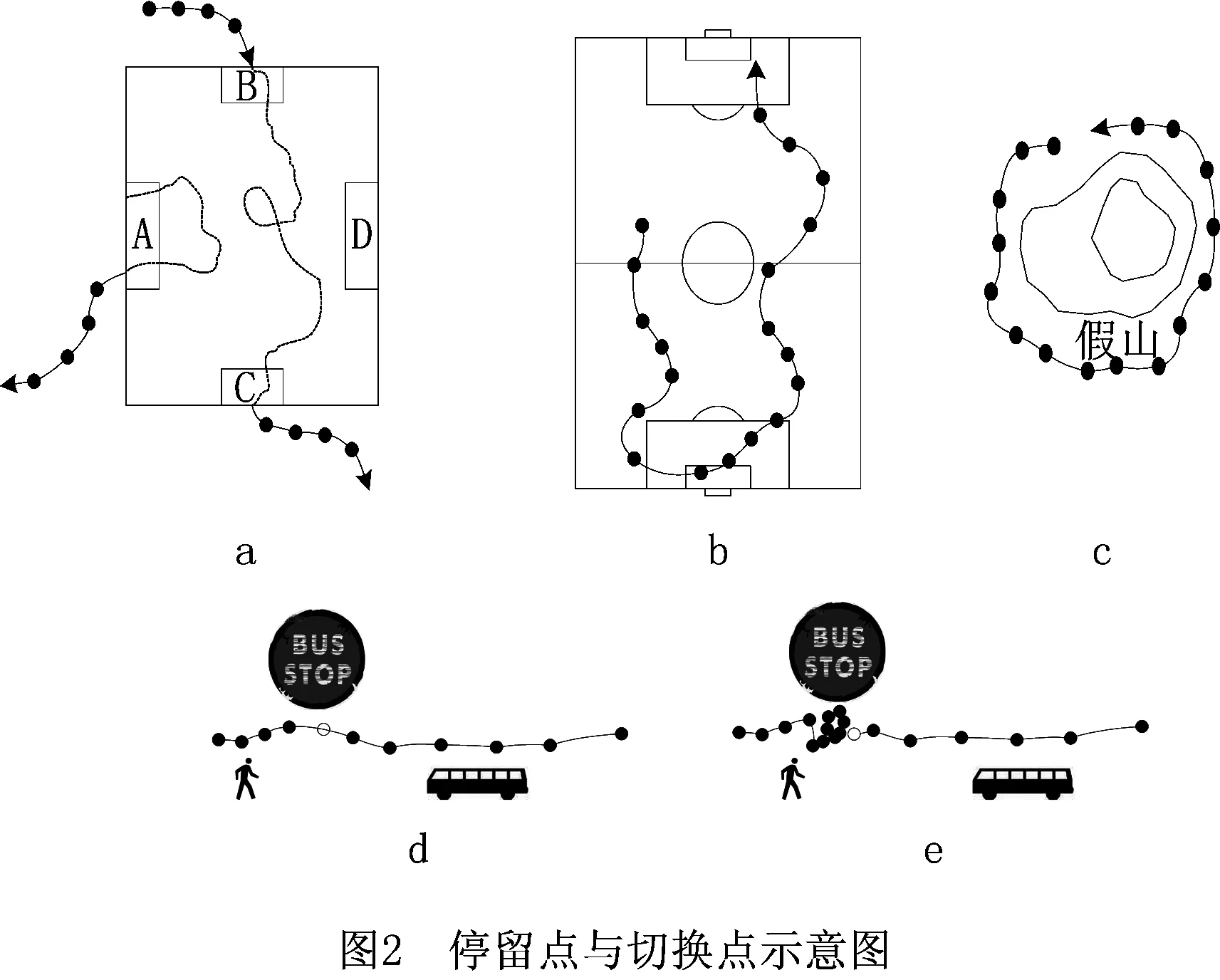
3 异步周期的序列模式挖掘模型
3.1 相关概念定义


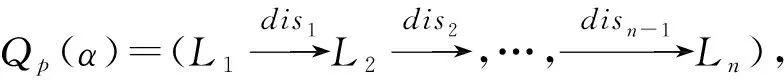
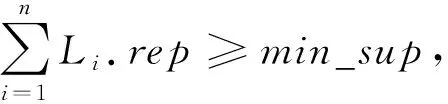
3.2 同步周期的序列模式挖掘模型
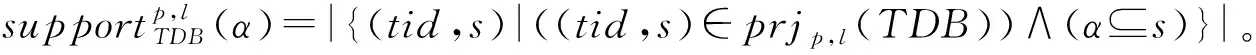
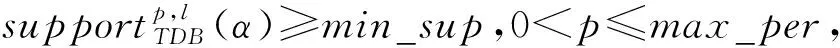
3.3 异步周期的序列模式挖掘模型
4 AP-PrefixspanM挖掘算法
4.1 算法的参数关系

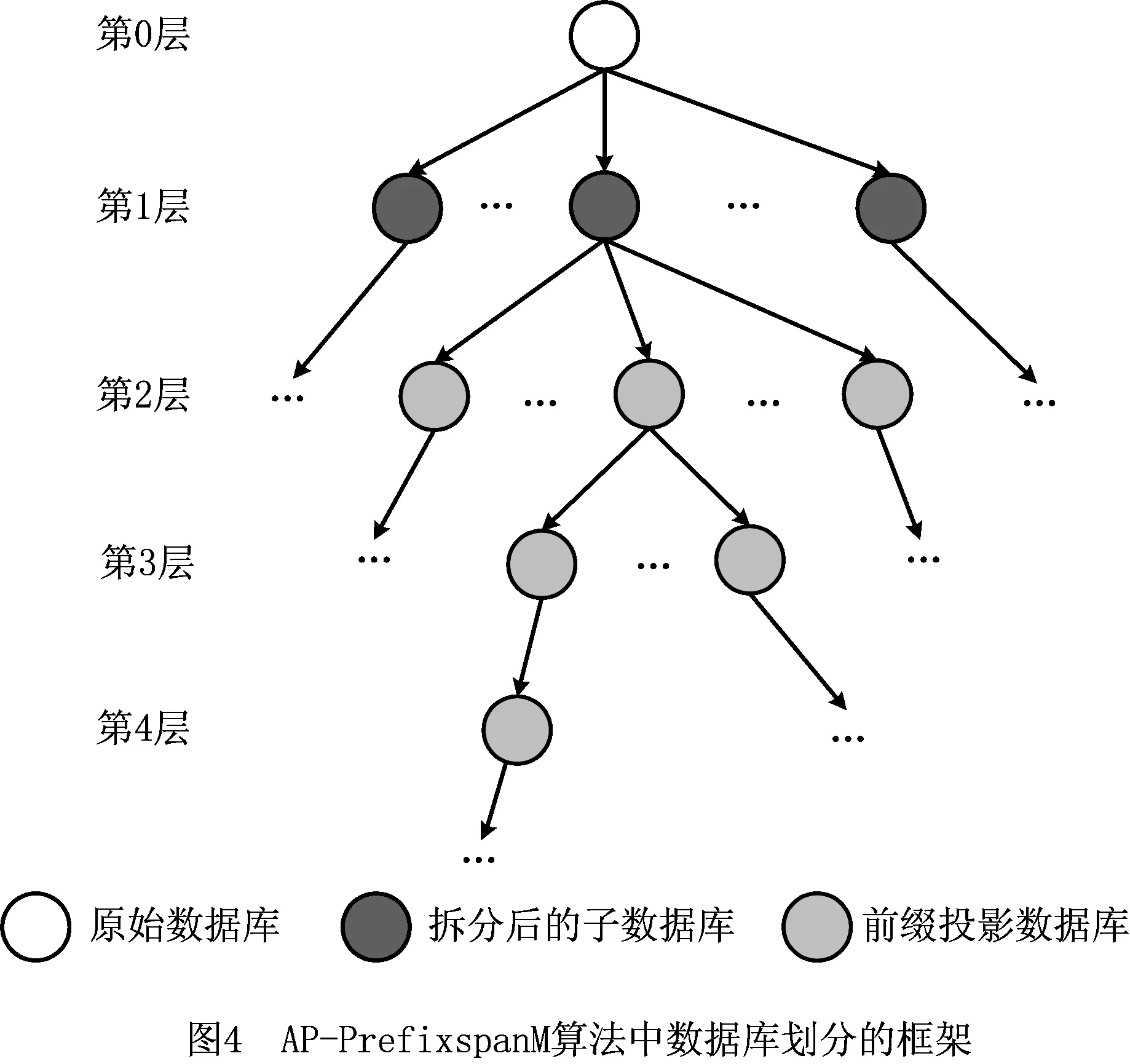
4.2 算法的主要思想和步骤

4.3 算法的实现
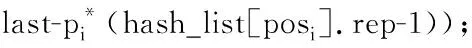
5 实验分析


5 结束语
猜你喜欢
读友·少年文学(清雅版)(2020年4期)2020-08-24读友·少年文学(清雅版)(2020年3期)2020-07-24小学生学习指导(低年级)(2020年4期)2020-06-02软件(2020年3期)2020-04-20军营文化天地(2018年2期)2018-12-15现代装饰(2018年5期)2018-05-26产品可靠性报告(2017年7期)2017-09-05中国三峡(2017年2期)2017-06-09财经(2017年2期)2017-03-10财经(2016年15期)2016-06-03
