
基于相似义原和依存句法的政外领域事件抽取方法*
2020-10-10 02:53:12崔莹
计算机工程与科学 2020年9期
崔 莹
(西南电子技术研究所,四川 成都 610036)
1 引言
随着科技水平日新月异的更新发展,各类新闻数据来源多种多样,导致多源、多品类、异构新闻数据量突飞猛涨。新闻数据作为开源情报的重要数据来源具有实时性高、海量、非结构化等特点。面对海量非结构化新闻数据,如何从中对关注的目标信息进行深层次挖掘、分析与预测,实现数据态势感知、风险预警等目的成为当前亟待解决的问题。目前,对非结构化文本类新闻数据进行结构化转换是新闻数据分析的基础,针对非结构化文本类新闻数据进行结构化信息提取主要有以下解决方法:命名实体提取、实体关系提取和事件提取等,其中命名实体提取、实体关系提取为初级信息提取;真正要做到信息关联和事件关联分析、预测挖掘等,需要进行更高层次的信息提取,如事件抽取、主题提取等。事件抽取是指从文档中识别出某个事件发生的时间、地点和事件的参与者等信息,并以结构化的形式呈现出来,形成模板形式的事件场景描述。针对大量混杂数据中的事件信息,越来越多的学者希望实现这类特殊事件的自动发现,获得大量精度高、机器可阅读的事件数据,并构建出各类结构化事件库[1 - 5]。本文针对政治外交(政外)领域事件提出了一种基于相似义原和依存句法的元事件提取方法,针对政外领域事件构建了8种元事件类别及对应的事件触发词表和事件模板。并以不同来源相同领域数据进行测试,实验结果较传统基于触发词的事件的召回率和F值均有提升,较基于神经网络的端到端事件抽取模型的抽取准确率有显著提升,为政外领域事件库的构建提供了很好的基础支撑。
2 相关定义
定义1(元事件) 表示在特定时刻发生的一个动作或状态变化[6]。
定义2(事件抽取) 事件抽取是信息抽取领域一个重要的研究方向。事件抽取主要把人们感兴趣的、用自然语言表达的事件以结构化的形式呈现出来[6]。
目前事件抽取的研究方法主要有2类,如表1所示:基于模式匹配的方法和基于机器学习的方法。基于模式匹配的方法准确率较高(如果模式提取得非常准确),且接近人的思维方式,知识表示直观、自然,便于推理。但是,这种方法往往依赖于具体语言、具体领域和文本格式,可移植性差,需要富有经验的语言学家才能完成[7]。和基于模式匹配的方法相比,基于机器学习的方法健壮性和灵活性较好,比较客观,不需要太多的人工干预和领域知识,召回率较高,但由于语料库规模的影响数据稀疏问题比较严重,其准确率较基于模式匹配的方法低,有时搜索空间很大还会导致巨大的空间开销,效率不高[8]。另外,它需要大规模的语料库进行训练。
正是由于机器学习在政外领域进行事件抽取时需要大规模的标注语料,同时存在识别率低的问题,本文拟采用基于模式匹配的方法对政外领域新闻数据进行事件抽取。
定义3(基于模式匹配方法的事件抽取) 模式是一种规则,模式定义了事件信息抽取的规范。基于模式匹配方法的事件抽取是指通过定义好的模式来识别某一类事件和抽取事件相关的元素信息。模式的获取可以通过手工或者自动的方式来设定。通过定义模式,形成最终的模式库,类似于对知识进行总结然后形成知识库,对整个系统起支撑作用。一般来说,基于模式匹配方法的事件信息抽取系统核心模块是模式获取和事件信息抽取[8]。

Table 1 Comparison of event extraction based on pattern matching and machine learning表1 基于模式匹配方法和基于机器学习方法的事件抽取对比
定义4(触发词) 触发词指的是能够触发事件发生的词,多为动词性词语。
定义5(义原) 义原(Semantics)在语言学中是指最小的不可再分的语义单位,而知网(HowNet)则是最著名的义原知识库[9]。
3 政外领域新闻事件抽取
基于模式匹配方法的事件抽取主要分为2部分:事件检测及类别识别(事件识别);事件论元角色抽取(事件元素识别)。具体处理流程如图1所示。
(1) 定义事件类别,针对每类事件构建触发词表和事件模板,其中事件模板包括触发词、事件论元角色,如表2所示为考察访问类元模板。
(2) 对单篇文档进行分词、词性标注、切分句子等文本预处理操作。
(3) 根据触发词表,判断句中是否包含触发词或与触发词相似的词,对相似词计算相似度,这里考虑到无法枚举出所有事件类型的触发词,因此采用了基于义原相似性的方法来扩展事件触发词。
(4) 筛选触发词相似度满足设定阈值的句子并将其作为事件句(即候选子事件),同时为事件句指定事件类别。
(5) 提取事件句中的实体要素。
(6)根据事件类别模板内的论元角色约束筛选满足事件类别模板的事件元素,即事件元素的识别。
(7) 根据事件模板生成事件描述。
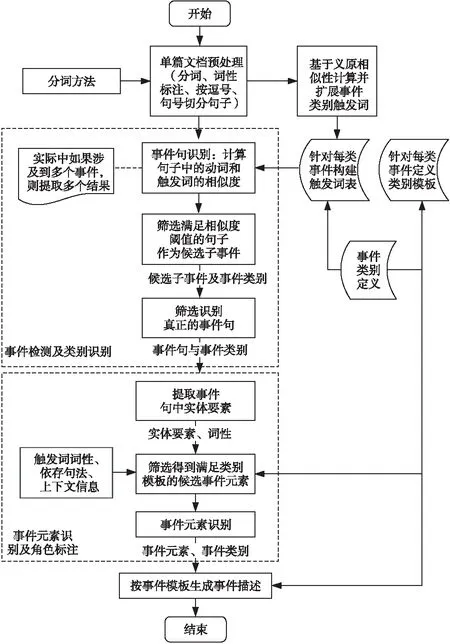
Figure 1 Meta event extraction process图1 元事件抽取处理流程
在基于模式匹配方法事件抽取过程中,有2个核心关键环节。一是事件触发词表的构建,触发词表构建的完整性和准确性,对事件的识别起到决定性的作用,因此如何完整地构建触发词词表至关重要。二是事件论元角色内容的填充,一句话中针对同一事件要素类型可能会提取到多个事件要素,如何选取合适的要素进行事件论元内容的填充同样对事件提取最终结果的准确性会产生深远的影响。
传统触发词表的构建主要通过计算词频、选取相关动词性关键词作为触发词,或通过专家手工构建触发词表。本文在传统触发词构建基础上,采取了基于义原相似性计算的方法,对触发词进行扩展,能够提升触发词表的完整性,提升事件识别准确率和召回率。
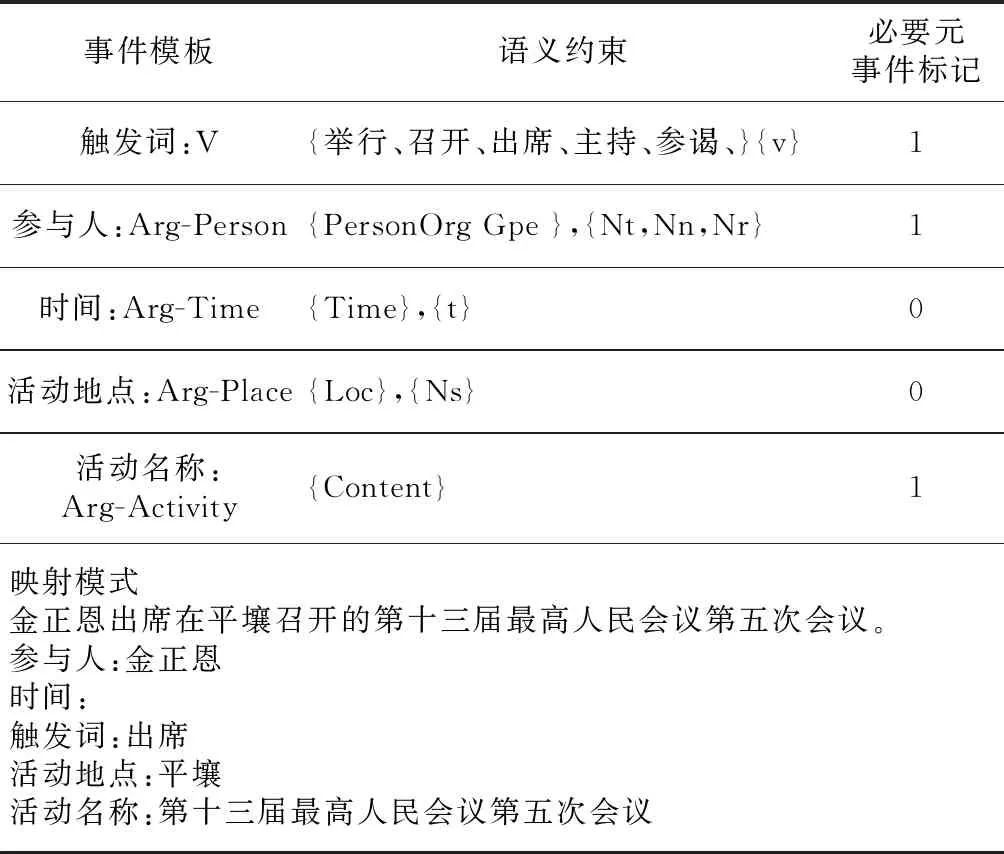
Table 2 Metaevent template of visit class表2 考察访问类元事件模板
本文在事件论元角色内容填充过程中,综合考虑上下文语义信息,结合句法分析、指代消解及触发词词性判断等方法,进行事件论元角色内容的填充。
基于模式匹配方法的元事件抽取主要处理环节包括触发词表的构建、事件句的识别以及事件模板中论元角色内容的填充,下面对这几方面在本文实验中的实现原理及相关算法进行详细介绍。
3.1 触发词表的构建
事件触发词是事件描述中的重要组成要素,直接引发事件的产生,是决定事件类别的重要特征。而事件触发词具有领域特色,事件触发词的提取在进行领域事件抽取过程中是非常重要的。本文对触发词表的构建采用人工构建初始触发词集合的方式,再通过对特定范围内的语料进行人工分析结合义原相似性计算,扩展并构建触发词表。
首先根据新闻标题或正文内容中是否包含触发词作为判断是否是候选事件的标准,判断句子中是否有触发词,有则归类到相关候选类别中。判断过程中考虑到触发词无法全面覆盖所有新闻标题关键词,利用知网词语相似度计算标题文本中的词语与类别触发词的相似度。实词的每一个概念是由一组义原描述式来定义的,这些义原描述式可以分为4部分:第一独立义原描述式和其他独立义原描述式、关系义原描述式和符号义原描述式。本文参考并借鉴了刘群等[10,11]的词语相似度计算方法来计算触发词语义相似度:
第一独立义原之间的相似度是通过计算义原在知网中上下位关系树中的距离得到的,公式为:
(1)
其中,p1和p2表示2个义原;d是p1和p2在义原层次体系中的路径长度,是一个正整数;α是一个可调节的参数。2个触发词概念之间的相似性可以通过式(1)计算触发词独立义原之间的相似度得到,记为Sim1(S1,S2)。
其他独立义原描述式,是指除第一独立义原描述式以外的其他独立义原描述式,因此这一部分相似度计算公式同第一独立义原相似度计算公式,即式(1),这样通过计算其他独立义原描述式相似度得到2个概念之间的其它独立义原相似度,记为Sim2(S1,S2)。
关系义原描述式,是用来描述概念和概念之间的关系,描述形式用“关系义原=基本义原”或者“关系义原=(具体词)”或者“(关系义原=具体词)”来表示,因此这一部分相似度计算仍然采用式(1),计算结果记为Sim3(S1,S2)。
符号义原描述式:其值是一个特征结构,该特征结构中的每一个特征包含属性和关系2部分,其中属性是一个关系义原,值是一个基本义原或具体词的集合。通过将2个概念的符号义原描述式中的基本义原或词集合进行两两组合,利用式(1)计算得到不同相似度值,符号义原相似度取其中基本义原相似度最大的值,我们将2个概念这一部分的相似度记为Sim4(S1,S2)。
最后,计算第一独立义原描述式、其他独立义原描述式、关系义原描述式和符号义原描述式4部分相似度的加权平均值作为词语的相似度,如式(2)所示:
(2)
计算文本中的词语与触发词的相似度过程中,如果文本中的词语和多个类别的触发词的相似度都超过阈值,那么选择触发词相似度最高的类别作为候选事件类别。
利用以上相似义原扩充触发词集方法,不同类型事件触发词扩展结果如表3所示。
3.2 事件句的识别
因为绝大多数事件触发词的词性是动词,因此事件句的识别是通过对句子进行分词处理,将所有词性为动词的词与触发词表进行比对,当该句子中包含有触发词表中的某触发词时,将该句判定为事件句,同时根据触发词指定该事件句的事件类别。当一句话中包含多个触发词时,认为该句属于多事
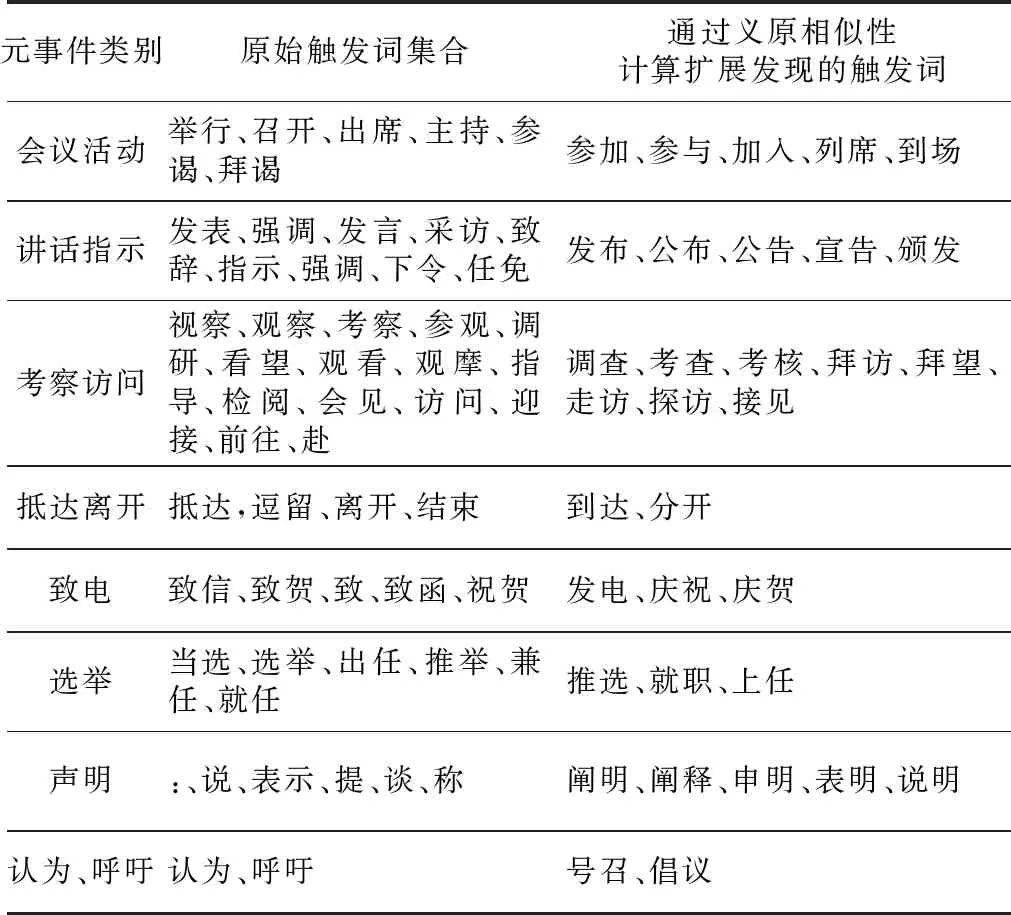
Table 3 Trigger extension results表3 触发词扩展结果
件句,对该事件句赋予多个事件类别。
3.3 论元角色内容的填充
论元角色内容的填充主要是对事件句中的事件元素进行识别,再按照事件模板将事件元素填充到对应的论元角色中。论元角色内容的填充结果准确性主要依赖于分词结果和依存句法分析结果的准确性。由于政外领域语料触发词具有专业性,因此在触发词表构建完成时,为提高事件句识别准确率,同步对分词算法中用户自定义词典进行了手动更新。
本文实验中的分词方法采用了HanLP分词算法,通过对句子做依存句法分析,得到句子的依存句法关系,如图2所示,利用句子的依存句法关系作为指导,对抽取的实体元素进行论元角色的填充,论元角色内容填充流程如图3所示。
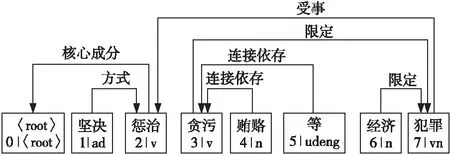
Figure 2 Dependency parsing graph图2 依存句法分析图
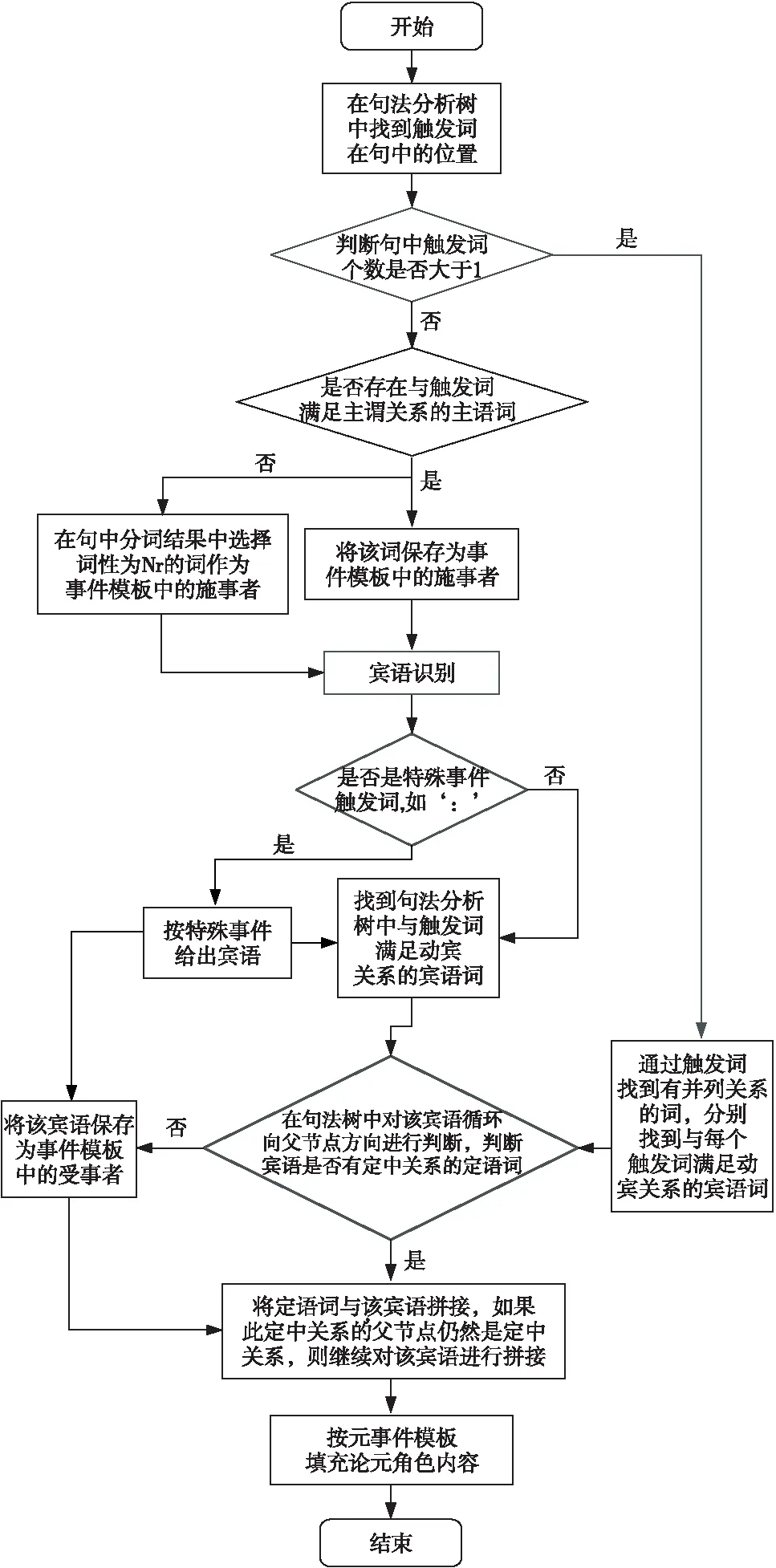
Figure 3 Content filling process for argument roles图3 论元角色内容填充流程
该事件要素识别环节中,因为数据涉及政外领域,HanLP分词算法在政外领域中得到的分词结果不够准确,经常会将一个具有特殊含义的实体拆分为多个词语,对事件要素抽取准确性造成了干扰。同时,事件要素抽取后,需要对其在整个事件描述中的角色给予定义。因此,本文利用依存句法分析结果,加入一定的规则来提升事件要素识别和论元角色内容填充的准确率。部分规则如下:
规则1在句法树中,通常将主谓宾词语中的主语词定义为事件主体,将谓语词定义为事件触发词,宾语词定义为事件客体。但是,实际情况是一句话中可能存在多个事件描述,因此需要进一步结合规则来生成事件描述。如果存在多个动宾关系,则判断多个动宾关系是否共享同一个主语,针对同一主语生成多个事件描述;否则在事件句中,按动宾关系对句子进行分割,在子句中为各动宾关系找到主语即事件主体,进而生成多个事件描述。
规则2对事件要素填充事件客体这一论元角色时,在句法树中,如果与触发词构成动宾关系的词语前面有定语词,则将该定语与宾语词进行拼接,如果该定中关系的父节点词语前仍有定语,则继续对该宾语进行拼接,直至定中关系判定结束,则该拼接词为事件客体。
例如,朝鲜劳动党中央委员会、朝鲜中央政治局、中华人民共和国第十三届全国人民代表大会等,在句法树中,上述示例中的短语常被识别为委员会、政治局、大会等,在事件要素填充过程中,此类识别结果是不完整且不准确的,因此通过结合句法树中定中关系等判断,可以提升事件要素识别准确率和完整性,同时能够对领域词典进行很好的补充。
规则3同规则2,在判断事件主体时,在句法树中,如果主语前有多个词语与其是定中关系,则不断向该定中关系的父节点循环拼接,直至定中关系判定结束,则拼接词为事件主体。
4 实验分析
4.1 实验场景
首先以朝鲜劳动新闻网金正恩相关报道为主要分析数据来源,对金正恩行为事件进行分析。实验场景如表4所示,建立8种元事件类别及对应事件触发词和事件模板(如表5所示),利用该模板分别对不同来源数据和不同施事者数据的事件句识别和论元角色内容填充进行实验设计,并对元事件抽取结果进行验证,验证新闻数据中同一领域内不同对象的相同类型事件的描述是否相似,进一步验证本文方法中事件触发词和事件模板对同一领域内其他对象的相关数据抽取是否具有通用性。
同时,为对比传统方法与基于相似义原和依存句法的事件抽取方法在特定领域的抽取效果,在实验中采用传统的基于模板匹配方法和基于LSTM的事件抽取方法,分别进行实验比对。具体来说,基于模板匹配方法中,主要采用元事件基础模板(如表5所示),其中事件触发词未进行扩展;LSTM方法中,模型主要由表示层(词向量、位置向量、实体向量)、双向的LSTM层、卷积层、max-pooling层和softmax分类层组成,利用双向LSTM完成词表示,每个词表示的基本信息包含有词向量、实体类别向量和依存关系向量。通过对比不同方法抽取结果,验证本文方法在特定领域中的优势。
实验使用的触发词表及元事件模板是通过基于相似义原对朝鲜劳动网有关金正恩行为报道的数据进行触发词相似性计算得到的。

Table 4 Experimental scenario settings表4 实验场景设置

Table 5 Meta event triggers and meta event templates表5 元事件触发词及元事件模板
针对不同的任务、不同的语料来源,事件抽取的评价方法也有所不同,本文借鉴ACE会议的评价标准,采用经典的准确率P(Precision)、R召回率(Recall)和F值(F-Measure)评价最终的抽取结果。具体计算公式如下所示。
(1) 事件类型类别的识别:
(3)
其中,PS为事件类型识别准确率,RS为事件类型识别召回率,其计算方式如式(4)和式(5)所示。
(4)
(5)
(2) 事件元素的识别:
(6)
其中,PA为事件元素识别准确率,RA为事件元素识别召回率,其计算方式如式(7)和式(8)所示:
(7)
(8)
4.2 实验数据
实验数据采用互联网政治新闻领域事件数据,如表6所示,共计784条新闻标题数据,标注其所有事件要素和事件类型,标注数据类别及个数如表7所示,其中550条作为训练数据,234条作为测试数据。

Table 6 Experimental data表6 实验数据
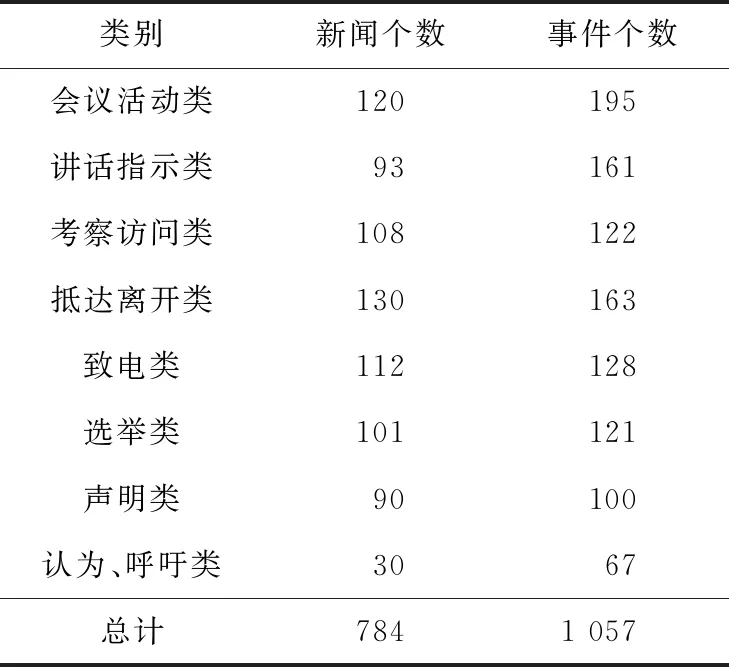
Table 7 Tagging data表7 标注数据
4.3 实验结果及分析
事件类型识别结果对比和事件元素识别结果对比分别如图4和图5所示。
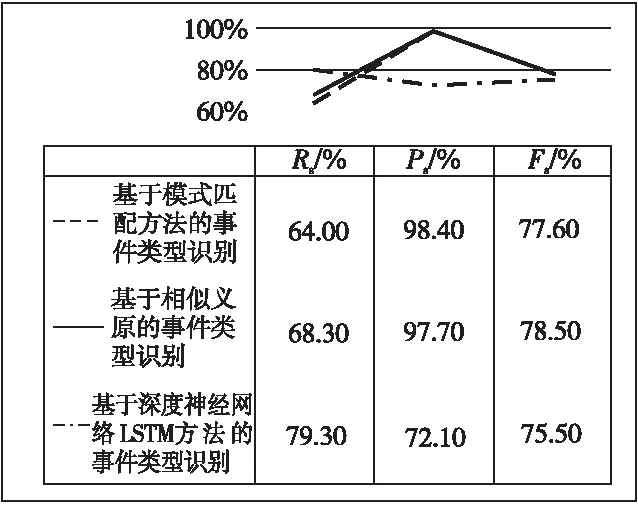
Figure 4 Comparison of event type recognition results图4 事件类型识别结果对比
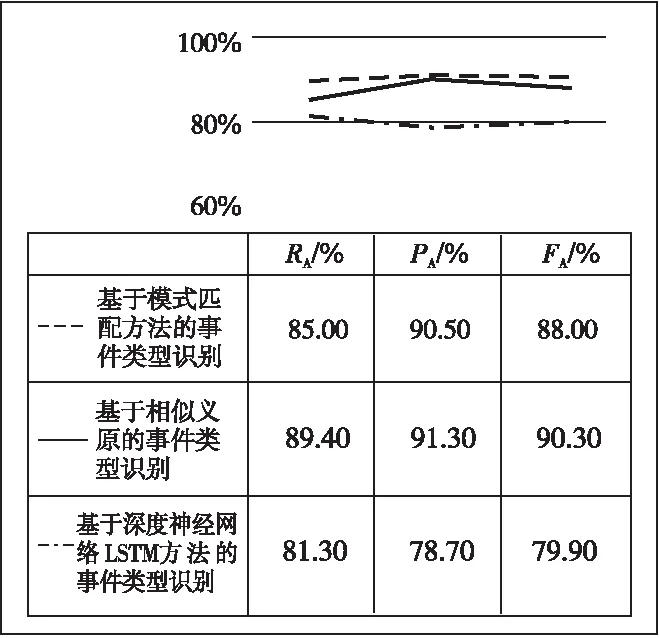
Figure 5 Comparison of event element recognition results图5 事件元素识别结果对比
本实验所采用的触发词表及事件模板类型来自于领域专家对朝鲜劳动网有关金正恩行为报道的总结归纳,事件类型参考目前最权威的事件数据分类编码方案冲突与调解事件框架CAMEO(Conflict And Mediation Event Observations),所测试的数据均为同一领域相关报道。
(1)通过实验可以看出本文方法中触发词及元事件模板对同一领域内其他主体对象的相关事件要素抽取具有通用性,说明新闻数据中同一领域内不同对象的相同类型事件的描述是相似的。
(2) 通过基于模式匹配、相似义原、深度神经网络LSTM不同方法的对比实验分析发现,在元事件类型识别中,采用相似义原的触发词扩展方法使得事件类型召回率和事件类型识别F值均得到了一定的提升,如图4所示。数据召回率低主要是因为触发词表不完备,元事件模板不完备,其他类型元事件在元事件模板定义中缺失,通过补充触发词表可提高元事件类型召回率。
(3) 通过基于模式匹配、相似义原、深度神经网络LSTM 3种方法的实验分析,如图5所示,在元事件元素识别中,有未召回的事件元素主要是因为分词结果中部分分词结果不准确,或是特殊的专有名词,在实验过程中,通过将未识别出的词加入到分词词典中,可提高事件元素识别召回率;同时,可以看出由于基于相似义原的方法对触发词进行了扩展,因此该方法在事件要素识别准确率和召回率上均有提升。
(4) 基于深度神经网络LSTM在政治外交领域的元事件元素识别召回率和准确率不高的主要原因是论元角色涉及大量领域专有名词,如“朝鲜劳动党第5次支部委员长大会”,只能抽取到“朝鲜”“劳动党”;而本文方法结合相似义原和依存句法的方法可以做到事件要素的准确识别和抽取。
(5)针对政外领域数据的元事件抽取,需要专有的触发词表及元事件类型定义。
5 结束语
元事件识别过程中触发词的扩展、论元角色的识别(包括时间表达式识别、专有名词的识别)、事件类型的定义等都是影响元事件类型识别和元事件元素识别效果的因素,在未来的研究中,可针对各方面尝试不同的方法,在整体上提高对元事件抽取的质量。
本文方法在实际工程中主要用于针对非结构化文本类新闻数据进行结构化抽取,通过元事件抽取得到数据内部人物、时间、地点、组织等关联关系,对事件库的构建进行支撑和补充,进一步为事件关系挖掘、事件预测等提供基础支撑。
猜你喜欢
英语世界(2021年13期)2021-01-12 05:47:51
电子制作(2019年13期)2020-01-14 03:15:32
移动信息(2018年1期)2018-12-28 18:22:52
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
韶关学院学报(2017年4期)2017-04-13 20:25:22
海外华文教育(2016年3期)2017-01-20 08:22:14
国家图书馆学刊(2016年2期)2016-10-09 06:19:31
山东工业技术(2015年21期)2015-07-27 08:18:10
江西师范大学学报(哲学社会科学版)(2014年1期)2014-09-05 07:44:12
图书馆建设(2012年3期)2012-10-23 05:16:30
