
基于强化学习的多样性文档排序算法*
2020-10-10 02:52:54丁家满贾连印游进国
计算机工程与科学 2020年9期
官 蕊,丁家满,贾连印,游进国,姜 瑛
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500;2.云南省人工智能重点实验室,云南 昆明 650500)
1 引言
在大数据时代,搜索引擎通常将用户查询检索到的内容以排序的方式反馈给用户,因此排序模型在搜索中起着关键作用。排序学习(Learning to Rank)属于机器学习与信息检索交叉的新兴研究领域,它利用机器学习方法解决排序问题,拥有机器学习的自动调整参数和避免过拟合等优点[1]。排序学习算法被广泛应用于信息检索和推荐系统领域[2,3]。排序性能的优劣直接影响用户使用搜索引擎和推荐系统的体验。近几年,国际顶级会议如SIGIR、WWW、WSDM、CIKM等都将排序学习作为一个主要的研究点[4]。
按照输入数据样例不同,排序学习方法分为3大类:单文档Pointwise、文档对Pairwise、文档列表Listwise。其中,文档列表Listwise方法又可再细分为2类:直接优化基于排序列表的损失的Listwise方法和直接优化信息检索评价指标的Listwise方法[5]。前类Listwise方法通过定义Listwise损失函数并最优化该损失函数而求得排序模型,其损失函数用于衡量预测的文档序列与真实文档序列之间的差异。后类Listwise方法将排序模型的构建与信息检索中的评价指标建立起关联,先定义信息检索中某个具体的评价准则(如归一化折扣累积增益NDCG(Normalized Discounted Cumulative Gain)等)的优化目标,再选择适当的机器学习方法和优化算法去学习排序模型,以构建能满足用户需求的最优排序模型。直接优化信息检索评价指标的Listwise方法在许多排序任务中表现良好。Yue等人[6]提出了SVMMAP(Support Vector Machine learning algorithm based on Mean Average Precision)算法,定义了评价指标为平均精度均值MAP的目标函数,并以此设计了一个基于Hinge的损失函数,利用结构化SVM的框架来设计排序方法。Xu等人[7]提出一种基于Boosting框架的算法AdaRank,能直接最小化定义在信息检索评价准则上的指数损失函数,用以排序预测。Cao等人[8]提出基于神经网络和梯度下降的排序学习算法ListNet,采用K-L散度来定义排序损失函数进行排序。然而,现有的大多数方法仅仅直接优化预定义排名位置处的评价指标,例如采用信息检索评价指标NDCG@k来配置AdaRank 的损失函数,AdaRank算法将集中于优化前k个排序位置的NDCG值,排序在k之后的文档所携带的信息则被忽略,因为它们对计算NDCG@k没有贡献[9],这类方法未完全利用所有排序位置的评价指标作为监督信息。
除了有效利用排序位置的评价指标作为监督信息外,为了提高排序算法效果,突出排序结果多样性也是十分关键的[10]。一方面,由于搜索引擎上的信息是高度冗余的,很容易造成用户查询返回的排序结果中头部包含大量相似甚至重复的信息,导致用户不得不耗费更多的精力跳过这些冗余的信息,方可获得更多所需的信息;另一方面,相同的查询可能代表不同的用户意图或兴趣。因此,如何尽可能多地覆盖多用户的查询意图,成为现代搜索引擎必须考虑的因素。
现有的多样性排序方法将排序过程形式化为顺序文档选择的过程,从而实现排序结果多样性的目标。一般可分为2类方法:第1类是启发式方法,启发式方法使用最大边界相关性标准MMR(Maximal Marginal Relevance)[11]来指导不同排序模型的设计。Santos等人[12]提出一种xQuAD(the explicit Query Aspect Diversification)排序方法,明确地为查询检索出的文档与可能的子查询之间的关系进行建模,以实现多样性排序。第2类是机器学习方法[13],结合机器学习方法实现搜索结果多样性。近年来,强化学习被广泛应用于信息检索、机器人控制等领域,应用强化学习解决排序问题成为新的研究点。强化学习问题通常用马尔可夫决策过程MDP(Markov Decision Process)来描述。Zeng等人[9]提出一种基于马尔可夫决策过程的排序学习算法MDPRank,将奖励函数定义为信息检索评价指标NDCG,充分利用排序位置的信息排序,效果显著。Luo等人[14]提出利用部分观测马尔可夫决策过程将会话搜索建模为一个双智能体随机博弈,以构建双赢搜索框架。Zhang等人[15]提出利用基于日志的文档重排序,将其建模为POMDP(Partially Observable Markov Decision Process),以提高排序性能。Xia等人[10]提出一种基于连续状态的马尔可夫决策过程的多样性排序MDP-DIV(DIVerse ranking model based on Markov Decision Process)算法,利用排序位置的效用信息,实现多样性排序。Wang等人[16]提出了一种极大极小博弈模型,统一迭代优化生成检索模型和判别检索模型,其中生成检索模型采用策略梯度算法中的REINFORCE算法[17]进行优化,解决了网页搜索、项目推荐等问题。Hu等人[18]提出一种搜索会话马尔可夫决策过程来建模多步排序问题,设计策略梯度算法学习最优的排序策略,在电子商务搜索场景中取得了很好的排序效果。Oosterhuis等人[19]提出一种Double-Rank方法,利用深度强化学习技术同时为排序和网页布局建模,解决复杂排序场景问题。Feng等人[20]提出利用蒙特卡洛树搜索结合MDP的排序方法,解决了贪心选择框架造成的局部最优解问题。然而,现有的多样性排序方法对每个排序位置的顺序文档选择,需要评估所有查询与候选文档的相关性,如此导致形成了巨大的搜索空间。
受MDPRank算法的启发,本文考虑将多样性排序问题建模为马尔可夫决策过程,该过程通过研究排序列表的状态来决定文档的排序,从中获得奖励回报,并将文档列表的状态从当前转移到下一个,通过不断选择局部最优解来得到最优的排序策略。
综上,针对现有的Listwise排序方法的损失函数在最大化利用所有排序位置的信息以及融合多样性排序因素方面的不足,本文提出基于强化学习的多样性文档排序算法RLDDR(Diversity Document Ranking algorithm based on Reinforcement Learning),将文档排序问题建模为马尔可夫决策过程。一方面,RLDDR算法通过计算所有排序位置的奖励回报,充分利用所有排序位置信息,在每一次迭代过程中进行学习,不断为每个排序位置选择最优的文档;另一方面,采用多样性策略,在排序过程中依据相似度阈值,将高度相似的文档删除,缩小搜索空间,增强排序结果的多样性。
2 问题定义
在RLDDR算法中,假设有n个带标签的训练查询集合{qn,Xn,Yn},设Xn={x1,x2,…,xM}为文档的特征集合,Yn={y1,y2,…,yM}为查询检索出的文档的相关性标签。M为由查询qn检索出的候选文档{d1,…,dM}的数目。
应用强化学习解决文档排序问题,可以用一个连续状态的马尔可夫决策过程来描述。马尔可夫决策过程由状态集、动作集、状态转移函数、奖励值函数和策略函数组成,可以用五元组〈S,A,T,R,π〉表示。下面将分别说明各元组的含义:
(1)状态集S是描述系统环境的一组状态集合。状态集定义为一个二元组,包含排序位置信息和候选文档集合。因此,在时间步t,状态st定义为二元组[t,Xt]。其中,Xt是时间步t待排序的所有候选文档集合。
(2)动作集A是智能体Agent可选的所有离散动作集合。所有可选的动作集合取决于当前的状态st,表示为A(st)。在时间步t,选择一个文档xm(at)∈Xt放在排序位置t+1上。其中m(at)是在动作at下可选文档的索引。
(3)状态转移函数T(S,A)是一个描述环境状态转移的函数,作为对时间t选择执行动作at的结果,该函数将环境状态st转移到st+1。一旦选择了一个动作意味着选择了一个文档放置在排序位置,这时要将该动作选择的文档在候选文档集中删除。避免选择重复的文档进行排序。新状态st+1如式(1)所示:
st+1=T([t,Xt],at)=[t+1,Xt
(1)
(4)奖励函数R(S,A)也称为强化函数,是一种即时奖励。在排序问题中,奖励视为对动作选择文档的评价。因此,本文将奖励函数定义为信息检索的评价指标。本文将执行动作at后,环境给予的奖励定义为信息检索的评价指标归一化折扣累积增益NDCG,使得RLDDR算法能够利用所有排序位置的评价指标,即所有排序位置的NDCG值。奖励函数R(S,A)如式(2)所示:
(2)
其中,ym(at)是动作at选择的文档xm(at)的相关性标签。每一个排序位置的奖励对应于每个排序位置的NDCG值。
(5)策略函数π(a|s)描述了Agent的行为。它是从环境状态到动作文档的一种映射。RLDDR算法的策略函数定义为所有可选的候选动作文档的概率分布。策略函数π(a|s)如式(3)所示。
(3)
其中,θ是策略参数,θ的维度和文档向量的特征维度相等。
3 RLDDR算法
3.1 融合多样性
排序的最终目的是确定用户查询返回的文档序列列表,除了传统的相关性因素外,保证排序结果的多样性能够给用户提供有关查询的更丰富的查询结果,避免了返回结果的冗余。在提高排序相关性的基础上,综合多样性因素,不仅能够帮助用户了解查询的相关信息,还能提高用户的搜索兴趣。
对于排序结果的多样性,本文目标是将最相关的文档返回到查询中,同时确保文档的多样性。由于RLDDR算法的空间复杂度与查询返回的候选文档集的个数即动作集A的大小密切相关,因此若要降低算法的空间复杂度,一种方法是通过缩小动作集A来缩小算法的多样性搜索空间,同时必须保持排序准确性不降低,这时就要求缩小动作集的方法必须保证2点。第1,它能够智能地删除部分冗余即高度相似的动作。第2,删除后的候选动作集几乎可以替代原候选动作集。例如,候选动作集中动作ai和动作aj高度相似,且都和查询q相关,则在动作集中删除动作ai或动作aj。因为动作ai和动作aj高度相似,当获取了动作ai所携带的信息,对动作aj所携带的信息也就有了了解。此外,为了保证候选文档的多样性,将它们都删除是不合理的。
RLDDR结合多样性策略,降低算法搜索的空间复杂度。假设某一时间步t,选择动作at∈A(st),此时,计算候选动作集中动作at的K个最近邻动作。由于文档向量通常很长,并且是稀疏的,于是本文采用余弦相似度(如式(4)所示)计算动作at的K个最近邻动作。设置相似度阈值来评判候选动作集中动作at的近邻动作。
(4)
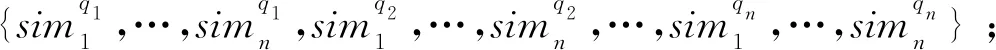
在训练阶段,文档多样性排序的过程如下所示:给定查询q、查询q返回的M个文档的特征集合X以及每个文档相应的相关性标签。系统环境的状态初始化为s0=[0,X]。在每个时间步t=0,1,…,M-1,Agent根据环境状态st=[t,Xt],选择一个动作,即从候选文档集中选择文档xm(at)并将其放置于排序列表中。基于所选择文档的相关性标签ym(at),Agent接收环境给出的即时奖励rt+1=R(st,at)。然后,根据相似度阈值,判断是否在候选集中删除与所选文档相似的K个最近邻文档。若所选文档的相似度大于相似度阈值,表明该文档与所选文档高度相似,则在候选文档集中删除该文档;若小于相似度阈值,则不删除该文档。算法随之转移到下一时间步t+1,系统环境状态变化为st+1=[t+1,Xt+1]。同时,重复此过程直至M个文档全部被选择,完成排序。
在测试或在线文档多样性排序阶段,因为并没有相关性标签,也就无法得到每个排序位置相应的奖励。此时RLDDR算法按照学习到的策略,选择在每个时间步具有最大概率的文档,因此在线文档多样性排序相当于为所有检索到的文档分配排序分数f(x;θ)=θTx,其中,x为文档向量,依据相似度阈值裁剪高度相似文档,按降序对文档进行排序。
3.2 策略参数学习
在本文中,通过强化学习中的策略梯度方法REINFORCE来学习策略参数θ。策略梯度方法是强化学习中的另一大分支。与基于值的方法(如Q-learning,Sarsa)类似,REINFORCE也需要同环境进行交互,不同的是它输出的不是动作的价值,而是所有可选动作的概率分布。RLDDR算法的目标是最大化每一时间步的累积期望奖励J(θ),如式(5)所示:
J(θ)=ΕL~πw[G(L)]
(5)
其中,L={xm(a0),xm(a1),…,xm(aM-1)}是根据RLDDR算法排序的文档列表,G(L)定义为文档列表的累积奖励,如式(6)所示:
(6)
其中,γ为折扣因子,rn为奖励回报。
若γ=1,则G(L)的定义与信息检索的评价指标NDCG一致。因此,RLDDR算法可以直接优化信息检索的评价指标。
(7)
其中,πθ为策略参数θ下的策略表示。
利用该梯度调整策略参数,得到策略参数更新式为:
(8)
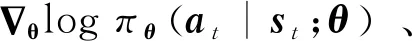
(9)
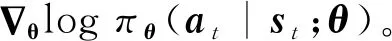
(10)
Gt的设置让参数θ沿着有利于产生最高奖励回报的动作的方向移动,可以使好的动作得到更高的奖励。本文提出的RLDDR算法的具体描述如算法1所示。算法2为多样性序列算法,描述了算法1中获取多样性序列的详细过程。
算法1RLDDR算法
输入:带标签的训练样例集合D={q,X,Y},学习率η,折扣因子γ,奖励函数R。
输出:策略参数θ。
步骤1随机初始化策略参数θ;
步骤2初始化策略中间参数Δθ=0;
步骤3根据算法2获取多样性序列(θ,q,X,Y,R);
步骤4根据式(9)计算多样性序列(θ,q,X,Y,R)的累积期望奖励Gt;
步骤5根据式(10)更新策略中间参数Δθ;
步骤6根据式(8)更新策略参数θ。
算法2多样性序列算法
输入:带标签的训练样例集合D={q,X,Y},策略参数θ,奖励函数R,序列长度L,相似度阈值ε。
输出:多样性序列E。
步骤1初始化s0= [0,X],M=|X|,多样性序列E。
步骤2根据式(3)取样动作at∈A(st)~πθ(at|st;θ)。
步骤3根据式(2)计算奖励值rt+1=R(st,at);
步骤4根据式(4)计算at的K个最近邻动作的相似度s=sim(at,a)。
步骤5若相似性s>ε,从X中删除at的K个最近邻动作;若s≤ε,则不删除。
步骤6根据式(1)转换状态st至st+1。
步骤7添加(st,,at,rt+1)至E的末端。
步骤8重复步骤2~步骤7,直至多样性序列E长度等于L。
4 实验结果与分析
实验数据集来自微软亚洲研究院开发的LETOR数据集,本文从中选取了OHSUMED[21]和MQ2007[22]作为基准数据集。每个数据集由查询、相应的检索文档和人工标注的相关性标签组成。在多样性排序领域,本文组合了4个TREC数据集(WT2009,WT2010,WT2011,WT2012)[23]进行实验,共有200个查询。每个查询包括由TREC确定的若干个子主题。相关性标签根据子主题级别设定,0表示不相关,1表示相关。在所有实验中,根据训练经验,K取动作集A大小 的10%,序列长度L取返回结果个数k,学习率设为0.001,相似度阈值设为0.65。使用LETOR标准特征并设置γ=1进行实验,使RLDDR算法能够直接优化信息检索的评价指标NDCG。
对于实验结果,本文采用了信息检索中广泛使用的评价指标进行评价,包括NDCG@k,α-NDCG,S-recall。NDCG@k指标通过评价查询返回的文档列表中,相关文档与不相关文档的相对位置来衡量排序文档列表的优劣。所有的查询相关文档均排在不相关文档的前面时,评价指标NDCG的值达到最大。本文采用在排序位置k为1,3,5和10的NDCG值进行评估。TREC数据集的评价指标α-NDCG被广泛应用于评估排序模型的多样性,通过明确奖励多样性文档和惩罚冗余文档来衡量排序列表的多样性。根据经验设置参数α为0.5。传统的多样性评价指标S-recall衡量检索文档子主题的覆盖率。所有的评估都是在top-k返回结果(k=5和k=10)上计算的。
将3个数据集的数据均分为训练集、验证集和测试集,大小比例为3∶1∶1。实验结果均采用五折交叉验证数据集上各评价指标的平均值。将提出的RLDDR算法与经典的排序学习算法进行比较,包括基于Listwise的ListNet算法、直接优化信息检索评价指标的MDPRank算法。在多样性排序领域,选取代表性的多样性排序算法MMR、xQuAD、MDP-DIV(S-recall)进行对比。
表1和表2分别列出了RLDDR算法和对比算法在NDCG@k评价指标上的对比结果。
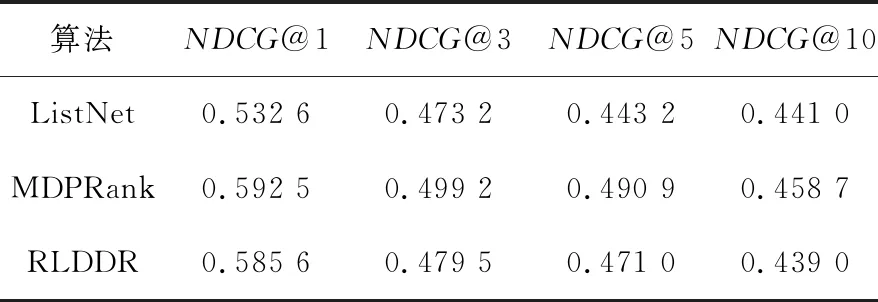
Table 1 Comparison of NDCG@k value on OHSUMED表1 在OHSUMED 上NDCG@k值的比较
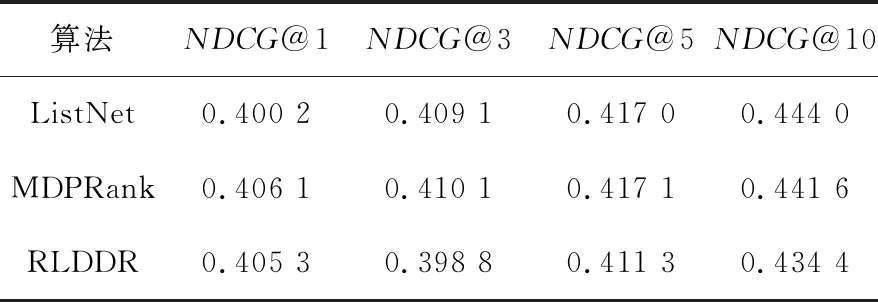
Table 2 Comparison of NDCG@k value on MQ2007表2 在MQ2007上NDCG@k值的比较
由表1可知,本文算法在k=1时具有较高NDCG@k值,说明其能够将最相关文档排序在排序列表的前方位置。但是,随着k的增大,由于RLDDR算法的融合多样性因素原则,裁剪了高度相似文档致使NDCG@k有所下降。MDPRank算法排序准确性整体优于RLDDR算法。但是,在k取1,3,5时,相较基于Listwise的ListNet算法,本文算法仍具有一定的准确性。由表2可知,在MQ2007数据集上,RLDDR算法在k=1时也取得了较高的NDCG值。在k=3,5,10时,本文算法也获得了不错的准确性。在k=10时,基于神经网络和梯度下降的ListNet算法的排序准确性最好。
本文算法在考虑多样性因素之外,仍能保证排序准确性的主要原因是在训练阶段,能够利用奖励回报作为监督信息,更新策略参数,学习最优的排序策略。RLDDR算法在OHSUMED和MQ2007数据集上均有一定改进,是直接优化信息检索评价指标的有效算法。
图1更加直观地显示了本文算法和对比算法在NDCG@k上的效果及趋势。
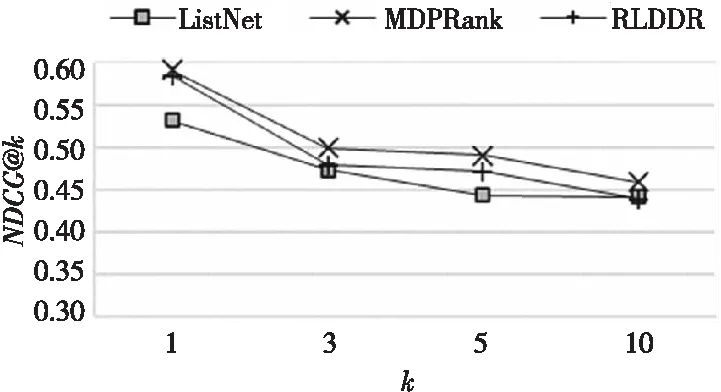
Figure 1 Comparison of NDCG@k value on OHSUMED图1 在OHSUMED 上NDCG@k值的比较
表3和表4列出了在多样性排序领域中本文算法和对比算法的多样性排序评价指标α-NDCG和S-recall的实验对比结果。
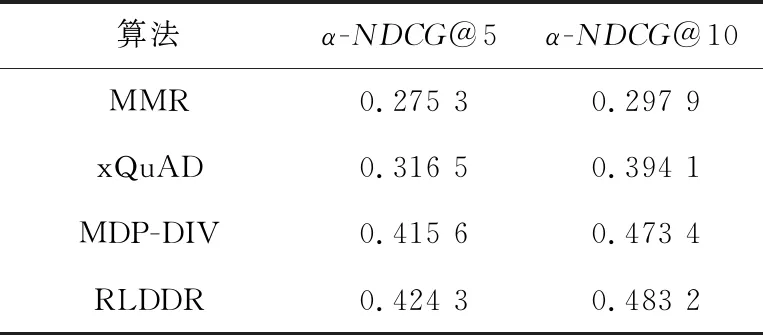
Table 3 Comparison of α-NDCG value on TREC表3 在TREC上α-NDCG值的比较
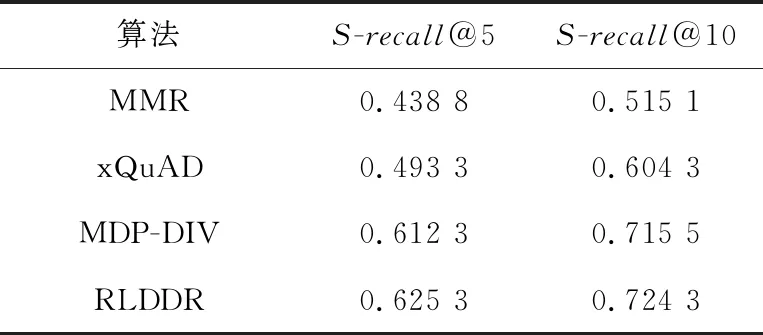
Table 4 Comparison of S-recall value on TREC表4 在TREC上S-recall值的比较
由表3可知,在提高文档多样性方面,本文算法有不错的表现。本文算法在k=5和k=10时评价指标α-NDCG均高于对比算法。通过裁剪高度相似的文档,缩小了文档搜索空间,增强了排序文档的多样性。由表4可知,在传统的多样性指标S-recall方面,本文算法较对比算法能够使排序文档涵盖更多的子主题,说明文档的多样性高于对比算法的,体现了RLDDR算法融合多样性排序的有效性。
综上,在排序学习方法中加入多样性排序因素,排序准确性会有所下降。但是,保证一定程度的搜索结果多样性也是未来搜索引擎算法调整的趋势。多样性排序的优点将弥补准确性稍有下降的缺点,帮助用户过滤高度相似的文档,不仅能够避免返回结果的冗余,还能提高用户的搜索兴趣。
5 结束语
针对现有排序学习算法中损失函数未能充分利用所有排序位置信息,以及确保排序结果多样性方面能力不足的问题,本文引入强化学习思想,通过计算所有排序位置的奖励回报,并将其作为评价监督,在每一次迭代过程中进行学习,保证了每个排序位置选择最优的文档,提高排序准确性;结合多样性策略,通过将高度相似的文档删除的方式确保排序结果的多样性。实验结果表明,RLDDR算法较相关对比算法能获得更显著的排序结果。在以后的工作中,将继续挖掘影响排序性能的因素,得到性能更优的排序模型。
猜你喜欢
中学生数理化·七年级数学人教版(2022年11期)2022-02-14 07:14:12
中国新闻周刊(2021年26期)2021-07-27 04:02:12
科普童话·学霸日记(2020年1期)2020-05-08 16:45:11
小天使·一年级语数英综合(2019年2期)2019-01-10 11:57:30
儿童绘本(2018年5期)2018-04-12 16:45:32
信息安全研究(2016年4期)2016-12-01 06:06:54
新闻传播(2016年18期)2016-07-19 10:12:06
现代计算机(2016年11期)2016-02-28 18:35:15
Asian Pacific Journal of Reproduction(2015年1期)2015-12-22 12:09:35
河南科技(2014年11期)2014-02-27 14:10:19
