
融合TLD框架的DSST实时目标跟踪改进算法*
2020-10-10 02:51:48黄浩淼保峻嵘
计算机工程与科学 2020年9期
黄浩淼,张 江,张 晶,保峻嵘
(1.昆明理工大学信息工程与自动化学院,云南 昆明 650500; 2.中国船舶集团有限公司第七〇五研究所昆明分部,云南 昆明 650102;3.云南枭润科技服务有限公司,云南 昆明 650500; 4.昆明理工大学云南省人工智能重点实验室,云南 昆明 650500;5.云南省信息技术发展中心,云南 昆明 650228)
1 引言
目标跟踪在计算机视觉领域和信息物理融合系统(Cyber Physical Systems)的感知层中一直是研究的热点。然而在快速移动、目标受到长时间遮挡、背景杂乱等复杂场景下跟踪结果仍然面临很大的挑战性。因此,众多优秀的判别式与生成式目标跟踪算法[1]相继被推出,其中,相关滤波算法凭借速度快和循环采样方式增加样本丰富性,有效提高了跟踪鲁棒性和实时性,在近几年受到研究者更多的关注。比如:引入循环矩阵和核概念的CSK(Circulant Structure of tracking-by-detection with Kernel)[2]算法,CSK通过循环对密集样本目标周围的背景进行采样,然后分类器经过核函数对循环移位的样本进行快速检测,提高跟踪的速度。但是,由于目标特征提取只选择灰度特征,导致CSK算法在复杂情景下不能很好地表现目标外观模型,出现跟踪失败。CN算法(adaptive color attributes for real-time visual tracking)[3]根据目标的表观模型,经过快速傅里叶变换与核映射得到多通道下的颜色特征信息,然后预测下一帧的目标最大响应位置,并使用PCA降维技术减少特征维度,提高算法的实时性,但也屏蔽了部分目标信息,对于光照强度鲁棒性较差。KCF(high-speed tracking with Kernelized Correlation Filters)[4]在CSK的基础上,采用HOG多通道特征替换灰度特征,并通过高斯核函数简化循环矩阵傅里叶对角化计算,提高了算法的鲁棒性,但对于目标尺度发生变化的情况,容易跟踪漂移。DSST(Discriminative Scale Space Tracking)[5]通过引入尺度滤波器,构建33层金字塔特征向量,对目标尺度变化进行响应,解决目标尺度变化问题的同时跟踪精度也很高,但是在跟踪快速运动目标时,跟踪效果不佳。Nam等人[6]提出TCNN (Tree Convolutional Neural Network)方法,通过树形结构结合多个CNN来表示目标的多种外观模型,然后对每个模型的候选框加权平均得到目标位置,从而适应目标的快速形变,但模型复杂,降低了跟踪的实时性。Oron等人[7]提出一种对目标区域分块的跟踪方法,首先对图像目标区域进行分块处理,根据像素匹配的相似性预测目标的下一帧所在位置,提高跟踪的精确度,但跟踪速度很慢。火云莲等人[8]提出一种融合多特征的相关滤波跟踪算法,通过提取多种特征构建目标表观模型,进行降维后重新构造特征矩阵并融合入相关滤波器,得到更精确的目标跟踪效果,但模型变得复杂,降低了跟踪的实时性。陈晨等人[9]提出一种多模糊核融合的单目标跟踪算法,根据模糊理论改进核函数的损失函数,提高了算法在跟踪过程中的实时性。张晶等人[10]提出一种TLD(Tracking-Learning-Detection)跟踪框与STC(fast tracking via Spatio-Temporal Context learning)响应位置进行相似度联合优化的目标跟踪算法TLD-STCS,通过对上下帧图像目标区域相似性的判定,快速找到STC算法置信图中置信度最大的输出响应值,从而得到合适的目标框。
对于以上的相关滤波器算法在跟踪快速运动目标时,滤波器都容易因为边界效应导致跟踪失败,Kalal等人[11]提出了跟踪与检测结合的 TLD算法,该算法通过TLD检测器筛除错误样本,避免了快速运动产生的边界效应影响,由一种正负样本在线学习机制不断优化算法的鲁棒性,但由于检测器采用了整帧循环采样矩形框,降低了算法的实时性。Danelljan等人[12]提出空间约束相关滤波器SRDCF(learning Spatially Regularized Correlation Filters for visual tracking),将正则化的权重系数加入滤波器,得到更大的检测区域,从而改善边界效应中边缘物体的检测,提高了目标快速运动时的跟踪鲁棒性,但目标完全遮挡时容易丢失目标。Zhang等人[13]提出的快速压缩跟踪算法通过引入朴素贝叶斯函数改进分类器,使得分类器能避免目标区域中相似度高的背景干扰,提高对正负样本的分类,但没有考虑到目标局部特征变化。Liu等人[14]提出一种前景划分下的双向寻优跟踪方法BOTFP,通过将颜色属性引入目标表观模型,然后对图像进行背景消除的方式解决目标快速运动时特征容易丢失的问题,但目标外观变化时鲁棒性较差。Wang等人[15]提出从图像中提取目标模型和背景的跟踪方法,从图像的置信图中分离出目标和背景,然后对模型中的目标与背景同时训练并响应,有效地缓解了边缘效应,但未达到实时跟踪的效果。
在相关滤波算法中,DSST算法可以达到快速且更鲁棒的跟踪效果,但目标快速运动时产生的边界效应,使其不能准确响应目标位置,从而导致跟踪失败。本文在文献[5]的基础上,首先使用较大尺寸的滤波器来检测目标区域,保留更多目标信息,提高目标外观模型的可信度,在损失函数的系数上加入权重系数矩阵,对目标检测区域中心位置进行集中响应,达到目标的粗定位;目标快速运动使滤波器对运动模型更新失败,检测器的在线学习机制可以重新找到目标,因此本文使用文献[11]的检测器来约束DSST算法滤波器的位置响应;目标快速运动导致图像模糊,产生边界效应,为了减少检测器采样滑动矩形框的误差,在TLD检测器中加入自适应朴素贝叶斯分类器,通过分块计算图像特征得分,对检测器产生的滑动矩形框中背景信息与目标进行有效区分,得到更多包含目标的滑动矩形框;最后通过DSST的目标响应位置与TLD检测器输出的滑动矩形框进行最优相似性匹配,平滑输出响应,对目标位置进行精确定位。实验表明,本文算法在目标快速运动情景中,通过对目标区域中心进行集中响应,并通过检测器来约束滤波器的初始位置响应,提高了对目标进行定位的鲁棒性。但是,TLD检测器对图像采用一种网格循环采样矩形框的方法导致算法实时性不高。本文提出了使用DSST尺度滤波器获得的目标尺度对滑动矩形框循环采样,从而减少相关计算量,提高了算法的实时性。
2 DSST目标跟踪算法
DSST算法以上一帧目标位置为中心提取S种不同尺度下的矩形样本,然后把所有固定尺寸为M×N的样本构建成M×N×S的矩形图像块,并在这个尺寸下提取fhog特征,使用三维高斯函数构建对应的期望输出g,经过相关滤波器进行迭代运算,取矩形图像块响应中的最大值,得到新位置和新尺度。相关滤波器使用2个相互独立的滤波器,选择不同维度的特征和特征种类来训练样本,分别评估目标的尺度和位置变化。
2.1 位置滤波器
首先利用二维高斯函数初始化目标位置得到期望输出g,以该目标位置为中心构建S个尺寸不同的矩形样本,依据矩形样本对图像循环采集矩形图像块f,对图像块中每个像素点计算其一维灰度特征和27维fhog特征;将这些特征融合后乘以二维汉宁窗作为目标位置预测输入Z,根据滤波器响应函数求得Z对应的最大响应值,即获得目标的新位置。为了构造最佳的位置滤波器h,需要满足代价函数最小:
(1)
其中,d=28为特征融合后的维度;at表示滤波器训练第t个矩形图像块的权重;上标l表示特征的第l维;fl为矩形图像块第l维的特征;hl为矩形图像块第l维对应的滤波器;g为样本中目标位置二维高斯函数输出值;λ为正则项系数,用于防止滤波器过拟合,样本离目标区域中心越远,正则项的值越大,则训练滤波器影响越小。
然后利用Parseval定理将式(1)变换到频域上求解。由于需要对矩形图像块中的每个像素点求解d×d维的线性方程,计算非常耗时,为了加快算法运行速度,得到鲁棒的近似结果,使用式(2)对滤波器进行更新:
(2)

(3)
(4)
其中,η为学习速率。在下一帧图像中,目标位置的定位可以通过求解位置滤波器的离散傅里叶逆变换最大响应yt来确定,响应函数表示如下:
(5)

2.2 尺度滤波器
位置滤波器得到目标响应位置后,通过一维高斯函数初始化目标尺度得到期望输出g。按照样本尺度选择原则得到包含目标的矩形样本,计算每个样本中像素点的31维fhog特征,将样本中提取的特征重构为一个33层金字塔的特征向量,再乘以一维汉宁窗后作为目标尺度预测输入Z,根据滤波器响应函数求得Z对应的最大响应值,即获得目标当前的尺度。由于二维位置滤波器已经确定P×R目标区域的大小,再利用一维尺度滤波器评估目标尺度。目标样本尺度的选择原则为:
(6)
其中,P和R分别为目标区域的宽和高,a=1.02为尺度因子,S=33是尺度滤波器的样本尺度选择层数。尺度滤波器评估目标尺度为非线性增长的指数函数,可以达到接近目标响应位置的细检测目的,得到更准确的尺度评估结果。再根据式(5)求得尺度滤波器中最大响应值,即可获得目标的尺度,然后根据式(3)和式(4)更新尺度信息。
3 改进的目标跟踪算法
3.1 改进的DSST位置滤波器
DSST算法的相关滤波器在训练响应之前,依据构建的矩形样本对图像循环采集矩形图像块f,但在目标快速运动情景下,包含目标边缘的矩形图像块存在着位移边界,导致滤波器不能准确响应目标位置。文献[16]通过构建的矩形样本加上余弦框,当目标处于搜索区域的边界时,弱化区域边界背景对响应的干扰,但这样屏蔽背景信息,同时也弱化了目标模型对物体信息的描述,导致跟踪算法跟踪失败。本文使用较大尺寸的滤波器来检测目标区域,保留目标更多的物体真实信息,不会忽略目标边缘处背景信息的检测。由于循环采样的矩形图像块中心位置不存在边界位移问题,本文将相关滤波器的正则项系数λ乘以权重系数矩阵,使靠近目标边缘处的正则项系数更大,对滤波器响应的影响更小,最后滤波器响应集中在矩形图像块的中心区域,克服了边界效应。具体为通过一个M×N空间权重系数矩阵w来惩罚距离目标中心比较远的矩形图像块。
(7)
当目标处的矩阵权重系数较小时,背景处的矩阵权重系数较大,为了使滤波器关注目标信息,背景处的滤波响应结果应当尽量小,这是引入权重系数矩阵的目的。然后使用帕斯瓦尔定理将目标函数变换到频域:
(8)

(9)
其中,D(·)为对角化操作,C(·)为循环化操作。根据位置滤波器中傅里叶变换的共轭对称特性,可以对求解过程进行加速,因此将傅里叶变换后的实部与虚部合并为一个实数,在保持2个矩阵相差结果不变的前提下,求解速度快了至少一倍。
对零频Ω0、正频Ω+、负频Ω-的点分别将其实部和虚部的矩阵转换为纯实部数矩阵的方法,如式(10)所示:
(10)
然后对式(9)通过左乘同一变化稀疏酉矩阵B得到:
(11)

经过向量化和块对角化操作,将求和符号去掉简化得到改进的滤波器,公式为:
(12)
3.2 自适应目标与背景区分TLD检测器
TLD 跟踪算法[11]由一种判别正负样本的在线学习机制对目标持续跟踪,使用一对约束估计出检测错误,在因边界效应产生错误样本被有效筛除的过程中持续修正检测器,跟踪过程的鲁棒性不断增强。但是,检测器根据设定的尺度步长,依次对每个视频帧进行全局扫描,生成大量的矩形框,这些矩形框占用了大量的计算资源,降低了检测模块的运算速度。改进的检测器首先使用2.2节中规定的33种尺度进行全局扫描得到矩形框,增加算法的实时性。并且为了加强检测器对目标与背景的区分能力,先对矩形框内的图像分块提取特征,通过朴素贝叶斯分类器计算得分,得分高的即为输出矩形框。针对目标快速运动后导致图像模糊,TLD检测器对矩形框内图像块中目标信息进行循环拼接,拼接过程中这些信息在拼接处并不是连续的,会产生边界效应。本文改进的检测器自适应区分目标与背景,能有效解决目标信息在拼接处不连续的边界效应问题,提高检测器的鲁棒性。

Figure 1 Schematic of the improved detector图1 改进的检测器示意图
首先检测器根据式(6)的尺度扫描产生n个滑动矩形框,然后提取矩形框中目标特征并将其代入到朴素贝叶斯分类器中,实现对背景信息和目标的分类。假设正负样本先验概率相同,则朴素贝叶斯分类器模型如下所示:
(13)
其中,fi为第i个矩形框;y∈{0,1}是二元变量,其值分别代表正负样本标签。视频跟踪中目标一般为不规则形状,导致检测器产生的矩形框中包含的背景信息较少,而边缘处含有的背景信息较多,检测器对矩形框样本进行分类将产生干扰。因此,本文提出依据网格均分采样得到N×N共W块图像的目标特征,从而弱化边缘背景信息对矩形框内特征的干扰;再将第k块图像的特征压缩输入到朴素贝叶斯分类器,计算每个图像特征的得分,筛选出其中得分较大者,并根据距离目标中心位置分配的权重值组成强检测器。矩形框内第k块图像距离矩形框中心位置越近,其图像块特征得分权重值越高,反之亦然,进而弱化矩形框内边缘处图像中包含的背景信息对检测器分类的影响。第k块图像权重值公式如下所示:
k=1,…,W
(14)
其中,(lx,ly)为矩形框的中心位置坐标,(kx,ky)为网格均分中第k块图像的中心位置坐标。将图像权重值作为朴素贝叶斯分类器模型计算图像特征得分的系数,矩形框边缘位置得到较小的图像权重值,使图像特征得分更低,从而弱化检测器对矩形框分类时边缘处背景信息的干扰。改进后的自适应加权朴素贝叶斯分类器模型如下所示:
(15)
其中,fki为矩形框第k块图像提取的第i个目标特征。对矩形框内网格均分得到的W块图像得分进行加权求和,得分较大的矩形框即为跟踪的目标相似度高的滑动矩形框,然后依次通过级联分类器,将最终通过的矩形框聚类后作为检测器输出框。改进的检测器示意图如图1所示。
3.3 最优相似性匹配
跟踪过程中,检测器通过级联分类器产生大量聚类后的矩形框。本文通过图像最优相似性匹配关系得到与滤波器响应的目标位置最相似的矩形框,进而平滑目标位置的输出响应。利用该方法可约束初始响应值,抑制跟踪过程中的漂移现象。
首先对DSST响应的目标区域和TLD检测器滑动矩形框进行初始化:Q={qj},j∈1,…,n;P={pi},i∈1,…,m,pi表示TLD检测器矩形框内第i个特征点,qj表示DSST目标响应的区域内第j个特征点。下一步,获得跟踪框中P与Q集合之间的特征点最优匹配对。在匹配过程中,分别计算出集合Q中DSST响应的目标区域内特征点qj与集合P中特征点的最近邻匹配距离,若在P中得到的最优匹配特征点为pi,则OMP(pi,qj,P,Q)为1,否则为0。
OMP(pi,qj,P,Q)=
(16)
其中,NN(pi,Q)=argmind(pi,qj)=argmin|pi-qj|2为最近邻匹配距离。然后计算P与Q之间的最优相似性匹配的期望:
(17)
其中,p(·)为概率分布函数。若期望大于设定阈值,则保留该匹配的矩形框,再通过权重比例系数ρ弹性调整输出框中心位置:
XTLD-DSST=ρXTLD+(1-ρ)XDSST
(18)
其中,XTLD表示TLD检测器矩形框的中心点,XDSST表示DSST目标响应的位置中心点。TLD-DSST算法输出目标框调整过程如图2所示。
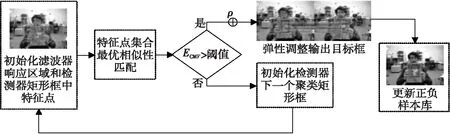
Figure 2 TLD-DSST algorithm output target frame adjustment process diagram图2 TLD-DSST算法输出目标框调整过程图
3.4 算法流程
TLD-DSST算法的流程如图3所示。
Step1初始化目标框。DSST算法滤波器根据3.1节增加空间权重系数矩阵w来调整距离目标中心比较远的矩形图像块,对这些矩形图像块进行滤波响应,最大响应即为目标位置和尺度。
Step2初始化TLD算法检测器。检测器按照DSST尺度滤波器的尺度循环采样矩形框,并根据3.2节对矩形框进行分块提取目标特征,经由自适应朴素贝叶斯分类器计算得分,筛除包含更多背景的矩形框;然后经过三大级联分类器的滑动矩形框进行相似度scbb和重叠度dbb计算;最后进行聚类得到检测器预测的矩形框集合。
Step3综合模块中DSST响应的目标位置中心点和TLD检测器滑动矩形框中心点集合进行最优相似性匹配,利用该关系约束初始响应值,根据3.3节更新目标的中心位置,并将其作为正样本放入学习模块。
Step4学习模块通过P-N在线学习机制对检测器中的目标模型进行学习,并更新正负样本库,提高TLD检测器的鲁棒性。
Step5视频结束则退出,反之返回Step 1跟踪下一帧。

Figure 3 Flow chart of TLD-DSST algorithm 图3 TLD-DSST算法流程图
4 实验结果
本节将TLD-DSST算法与 CN算法、TLD算法、DSST算法、TCNN算法进行对比实验分析,从目标跟踪测试集网站上(http:∥www.visual-tracking.net)选择6个实验测试视频,如表1所示,共有2 823帧,实验测试视频序列包括快速运动、背景杂乱、光照变化、旋转、遮挡等背景环境。

Figure 4 Accuracy of test videos图4 测试视频的精度图
本文实验环境的处理器为Intel i5-4210 2.60 GHz,内存为4 GB,对本文中学习速率取η= 0.085,尺度因子取a=1.02,权重比例系数取ρ= 0.75。本文算法从成功率图、精度图和帧率FPS3个评测标准来比较上述5种算法,使用文献[17]的测试视频中的Ground truth作为实际目标框计算成功率图和精度图。其中,跟踪算法输出目标框的中心位置与实际目标框的中心位置的欧氏距离用于计算精度图,通过计算跟踪算法每帧的包围框重叠度,然后将大于给定阈值的帧数除以总帧数得到成功率图。图4和图5为算法精度图与成功率图的对比。通过对6个视频序列的跟踪,综合以上3种评测标准,可以看出本文算法在中心位置误差的精度和包含框重叠度的成功率方面都优于原先的DSST算法。接下来通过本文实验结果以及视频测试序列部分截图对5种不同的跟踪算法进行分析。
4.1 跟踪结果定性分析
在实验测试视频中,本文选择soccer测试视频中具有遮挡、背景杂乱、快速运动的情景。图6第1部分是soccer测试视频跟踪结果的截图,从#62可以看出,目标的衣服与背景的颜色相似,在快速运动中,由于目标姿态的变化产生边界效应,导致CN算法的目标颜色模型和DSST算法的相关滤波器模型更新受到背景信息的干扰,对目标颜色特征和HOG特征的描述变差,影响跟踪框准确表征目标区域,从而跟踪框发生偏移;从#104、#138可以看出,目标被彩带遮挡时,TLD算法、DSST算法和TCNN算法跟踪框偏移,TLD算法由于将包含大量干扰物的区域作为正样本在检测器中进行训练,导致跟踪失败;从#202可以看出,偏移的误差积累后导致DSST算法跟踪失败,而TLD算法由于检测器具备错误更新机制,能对目标进行有效跟踪。从以上视频帧中可看出,本文算法明显提高了DSST算法目标跟踪的鲁棒性,首先分块提取检测器采集矩形框中目标特征,由自适应权重值改进的朴素贝叶斯分类器模型计算得分,对目标与背景信息进行区分,通过此检测器来平滑滤波器响应,矫正目标中心位置。

Table 1 Test video sequences表1 测试视频序列

Figure 5 Success rates of test videos图5 测试视频的成功率图

Figure 6 Partial screenshots of video tracking sequences图6 视频跟踪序列部分截图
选择BlurCar1测试视频中具有快速运动的情景。图6第2部分是BlurCar1测试视频跟踪结果的截图,从#22、#133、#376、#378可以看出,目标快速运动后图像模糊,目标与背景具有一定的颜色相似度,影响CN算法和DSST算法的目标响应,导致跟踪漂移;本文算法对滤波器加入权重系数矩阵,考虑到目标区域边缘检测,对有效信息分配高权重,得到目标的准确位置。
选择coke测试视频中具有光照变化、旋转、遮挡的情景。图6第3部分是coke测试视频跟踪结果的截图,从#25可以看出,光线变强时,影响TLD跟踪框内特征点通过光流法计算前后向误差,导致特征点预测的跟踪框缩小;从#273、#281可以看出,目标发生完全遮挡后,CN算法和DSST算法对伪目标叶子进行滤波器训练并更新目标模型,导致跟踪失败,TCNN树状模型根据上一帧伪目标叶子的位置得到检测后的候选框,导致跟踪结果不鲁棒。TLD算法通过检测器的跟踪失败恢复机制重新找到目标区域,同样本文算法中检测器通过对前几帧图像进行训练,更新学习模块中正负样本库,目标完全遮挡再出现后,检测器根据正负样本库筛选出包含目标的矩形框,再通过最优相似性匹配提高跟踪性能。
选择BlurOwl测试视频中具有尺度变化、快速运动的情景。图6第4部分是BlurOwl测试视频跟踪结果的截图,从#47、#77、#97可以看出,目标上下快速移动时,CN算法和DSST算法跟踪框发生偏移,最后跟踪失败;从#121可以看出,目标左右快速移动时,CN算法和DSST算法的跟踪框跟踪失败,快速移动产生的边界效应影响了CN算法和DSST算法对目标模型的更新,引入了过多背景信息,导致目标跟踪失败。TCNN算法通过多个CNN模型进行权重计算候选框,可以适应目标的快速变换。TLD算法和本文算法可以持续跟踪到目标,TLD算法具有检测器可筛除边界效应得到的错误样本,而本文算法的检测器能更好地区分目标和背景,平滑滤波器的响应,得到目标跟踪的准确位置。
选择bird1测试视频中具有快速运动、形变、遮挡的情景。图6第5部分是bird1测试视频跟踪结果的截图,从#12、#16可以看出,目标发生形变后,翅膀的摆动使CN算法和TLD算法跟踪框漂移;从#119、#187可以看出,目标被彩云完全遮挡后,CN算法和DSST算法滤波器对背景信息进行位置响应,最后跟踪失败,TCNN算法通过多个模型检测候选框,但无法确定目标位置,最后跟踪失败。本文算法和TLD算法通过在线学习机制重新找到目标区域,实现了对目标的实时跟踪。
选择DragonBaby测试视频中具有快速运动、旋转的情景。图6第6部分是DragonBaby测试视频跟踪结果的截图,从#28、#36可以看出,目标发生旋转后,CN算法和DSST算法提取目标单一的特征导致跟踪框漂移;从#44、#84可以看出,目标快速运动后,TCNN算法提取目标深度特征后,通过树状模型避免了最近帧的过拟合,本文算法通过对目标中心位置集中响应,并通过检测机制平滑初始响应位置,得到了精确的定位结果。
4.2 跟踪结果定量分析
从表2和表3的soccer实验精确度和成功率得到,DSST算法精确度为0.463,成功率为0.323,本文算法分别提高了45.6%和55.1%。从图5的soccer实验成功率图得到,在重叠阈值大于0.8时,本文算法比其他算法的成功率高。主要是在快速运动时,CN算法、DSST算法和TCNN算法跟踪框漂移,TLD算法根据检测器调整跟踪框输出,本文算法通过检测器提取目标特征,自适应区分矩形框内的目标与背景,避免了快速运动和背景杂乱导致的背景信息干扰。
从表2和表3的BlurCar1实验精确度和成功率得到,DSST算法精确度为0.483,成功率为0.385,本文算法分别提高了36.2%和40.8%。从图4的soccer实验精度图得到,在中心误差阈值小于15时,TLD算法比DSST算法的精确度高。主要是因为出现快速运动时,DSST算法因为边界效应对边缘进行训练,导致跟踪框漂移,TLD算法的检测器筛除错误样本,通过重叠度的计算获得矩形框,避免了边界效应的影响;中心误差阈值大于15时,DSST算法比TLD算法的精确度高,主要是TLD算法虽然具有检测器的错误样本筛选机制,但是由于对视频帧中目标的训练不足,学习模块中正负样本库不完善,导致算法的鲁棒性不强。本文算法结合了上述2种算法的优点,对前期的视频帧经过提取HOG特征并迭代运算得到目标响应,将其作为正样本更新学习模块,学习模块的样本与检测器中采样的矩形框进行相似度和重叠度计算,得到更准确的矩形框,不断提高算法的鲁棒性。

Table 2 Average center error rate (accuracy) for five different algorithms表2 5种不同算法的平均中心误差率(精确度)
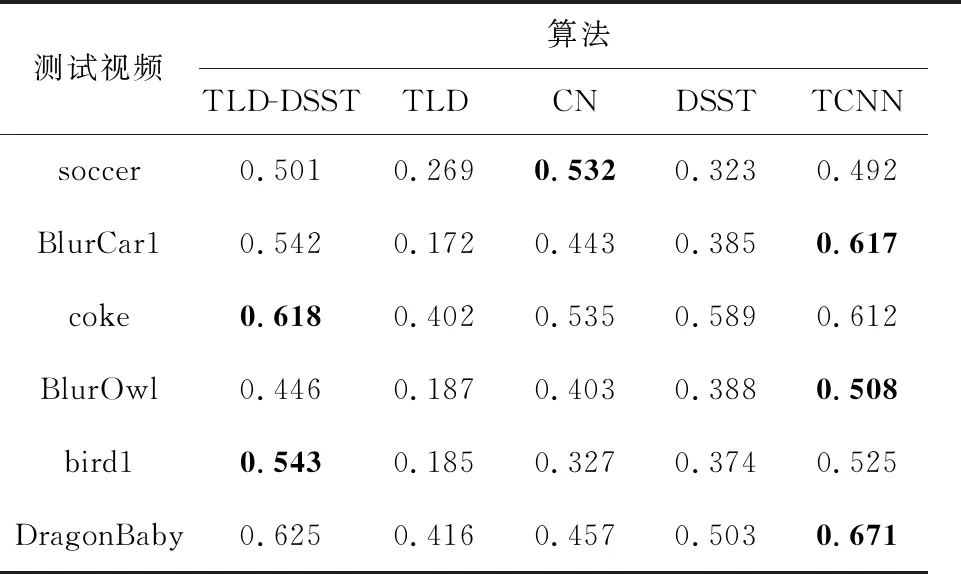
Table 3 Average overlap ratio (success rate) of five different algorithms表3 5种不同算法的平均重叠率(成功率)
从表2和表3的coke实验精确度和成功率得到,DSST算法精确度为0.747,成功率为0.589,本文算法分别提高了3.9%和4.9%。从图5的coke实验成功率图得到,在重叠阈值大于0.8时,本文算法、CN算法、DSST算法和TCNN算法都比TLD算法的成功率高。主要原因是视频中存在光照变化导致TLD跟踪框缩小,本文算法和其他3种算法通过提取目标特征,有效地改善了光照变化对目标跟踪的影响。在重叠阈值小于0.8时,本文算法比CN算法、DSST算法和TCNN算法的成功率高。主要原因是相关滤波算法的滤波器对叶子进行训练响应,导致目标跟踪失败,深度学习算法模型得出错误的候选框,而本文算法具有检测器的跟踪失败恢复机制,能重新找到目标区域。
从表2和表3的BlurOwl实验精确度和成功率得到,DSST算法精确度为0.463,成功率为0.388,本文算法分别提高了18.4%和14.9%。从图4的BlurOwl实验精度图得到,在中心误差阈值小于10时,本文算法和TCNN算法比CN算法、DSST算法和TLD算法的精度高。主要原因是在出现快速移动时,边界效应影响了CN算法和DSST算法对目标特征模型的更新,导致目标跟踪失败,而本文算法扩大滤波器的目标检测尺寸,增加物体有效信息的检测,避免边界效应中边缘检测的影响,并将结果作为正样本更新学习模块,提高了算法的鲁棒性。
从表2和表3的bird1实验精确度和成功率得到,DSST算法精确度为0.485,成功率为0.374,本文算法分别提高了28.9%和31.1%。从图4的bird1实验精度图得到,在中心误差阈值大于20时,本文算法比其他算法的精度高。主要原因是在目标完全被遮挡时,其他算法对背景信息进行错误响应,导致目标跟踪失败,而本文算法通过检测器的在线学习机制对正负样本的每一帧进行学习训练,然后将跟踪的样本作为正样本,放入目标学习模块中不断优化,从而持续跟踪目标。
从表2和表3的DragonBaby实验精确度和成功率得到,DSST算法精确度为0.628,成功率为0.503,本文算法分别提高了16.6%和19.5%。从图4的DragonBaby实验精度图得到,在中心误差阈值小于15时,本文算法、TLD算法和TCNN算法比DSST算法和CN算法的精度高,主要原因是目标快速运动产生的边界效应影响了算法滤波器的位置响应,导致运动模型更新失败,而本文算法扩大滤波器的目标检测尺寸,增加物体有效信息的检测,并对目标中心位置进行集中响应,避免了边界效应中边缘检测的影响。
4.3 算法跟踪速率分析
从表4得到,CN算法对提取的目标颜色特征采用主成分降维技术,跟踪的实时性最佳,DSST算法通过将高斯核函数转为频域计算,并提出滤波器更新机制,从而提高了跟踪的实时性;TCNN算法对目标进行多层卷积提取深度特征,并需要对每一帧进行树形判断,导致实时性最差;TLD算法通过网格循环采样矩形框,计算每个矩形框的重叠度和相似度,实时性较差;本文算法通过DSST算法中相关滤波器得到的目标尺度采样矩形框,从而减少检测器多尺度循环采样矩形框的采样时间,因此本文算法能够在TLD算法基础上,实时性提高了2.37倍,平均帧率达到49.47 f/s,并且本文算法使用傅里叶变换的共轭对称性使得高斯滤波过程缩短了一半时间。

Table 4 Average frame rate comparison among five different algorithms表4 5种不同算法的平均帧率对比 f/s
5 结束语
本文在TLD算法的基础上提出了一种融合TLD框架的DSST实时目标跟踪改进算法TLD-DSST。本文算法在相关滤波器中增加权重系数矩阵来平衡目标中心区域,得到目标响应位置;然后对检测器进行分块提取目标特征,放大目标与背景的差异度,再通过朴素贝叶斯分类器提高检测器的分类能力;最后将检测器聚类得到的众多矩形框与响应的目标位置进行最优相似性匹配,根据权重弹性调整目标输出框的中心位置,提高了本文算法的鲁棒性。同时,本文通过DSST算法中尺度滤波器得到的目标尺度采样矩形框,对比于TLD算法使用循环采样矩形框的方法降低了计算周期。最后通过实验结果表明,与对比算法相比,本文的TLD-DSST算法有最好的实时跟踪性能,在目标快速运动情景下能取得很好的效果,明显优于改进的DSST算法。然而,本文算法并没有考虑相似目标重叠时导致跟踪失败问题,下一步的研究方向是在相似目标发生遮挡情景中,通过卷积网络提取目标特征,提高跟踪算法的鲁棒性。
猜你喜欢
沈阳理工大学学报(2019年4期)2019-09-13 01:02:40
电子制作(2019年11期)2019-07-04 00:34:38
科学与技术(2019年3期)2019-03-05 21:24:32
电子制作(2018年16期)2018-09-26 03:26:50
中国交通信息化(2017年9期)2017-06-06 07:14:57
系统工程与电子技术(2016年7期)2016-08-21 13:59:02
工业设计(2016年11期)2016-04-16 02:49:43
火控雷达技术(2016年2期)2016-02-06 02:29:00
电脑知识与技术(2014年9期)2014-05-30 10:48:04
河南科技(2014年22期)2014-02-27 14:18:12
