
生鲜冷链配送区域划分两阶段模型构建
2020-10-10 11:26房庆军
物流技术 2020年9期
房庆军,王 旭
(青岛理工大学 管理工程学院,山东 青岛 266520)
1 引言
随着互联网迅速普及,生鲜品线上需求日益增长,生鲜领域已经成为电商相互争夺的“最后一片蓝海”。但由于生鲜品高时效性、高腐损率等特性,给生鲜电商的物流配送环节带来巨大挑战,生鲜品物流配送质量直接影响着生鲜电商运营的成败。
目前对生鲜冷链配送区域划分的相关研究比较成熟,大多学者主要应用聚类算法解决大规模配送点问题,于晓寒等[1]针对城市内快递配送问题,提出了基于障碍的约束聚类算法,以“障碍距离”作为差异度度量标准,建立BSP树简化距离进行计算;何梦军等[2]采用改进的吸引子传播聚类算法对同城物流网点配送区域进行优化。
通过上述文献综述发现,目前对配送区域划分方面的研究缺少对生鲜品特性以及工人任务量的考虑,只有在配送过程中考虑生鲜品特性的影响才能更好地保证其品质不受影响,只有保证工人配送任务量均衡,才能高效完成配送任务,提高用户体验。因此,本文在前人研究的基础上,将配送区域划分问题分为两个阶段,首先以配送时间最短为前提进行初始区域划分,在此基础上加入对配送量均衡的考虑,进行配送区域调整,保证配送效率。
2 问题描述
本文的研究场景是基于生鲜O2O“冷链物流+终端自提”配送模式,在这一模式下,生鲜电商与便利店合作,在配送区域内建立自营店、便利店、餐馆、小超市、小区自提柜等多种形式的线下体验店。通过线上下单购买商品的消费者,选择一个合适的配送地点,接到到货通知后进行自提;在便利店、自营店进行消费的顾客可以直接选择自己所需的生鲜商品,同时所在的便利店、自营店会自动被定义为配送点,库存水平降低到安全库存,会有冷链运输车辆进行配送补货。O2O信息平台会整合所有客户的订单信息,由冷链运输车辆对自营店、便利店、餐馆、小超市、小区自提柜等终端进行配送,送达自营店、便利店、小区自提柜的生鲜品,会根据顾客要求,等待顾客自提或者由配送员利用电瓶车在规定时间内配送上门。
本文的模型假设如下:(1)配送中心及各个客户点位置已知,且短时间内不会发生变化;(2)一个客户订单配送任务有且只能由一辆车完成;(3)将配送员及冷链配送车辆看做一个整体,即一次配送任务由一个配送员配备一辆运输工具完成;(4)配送的起点是各个配送中心,配送的终点是各个自营店、便利店、餐馆、小超市、小区自提柜;(5)每个配送中心的辐射范围相互不重合,一个客户点只能被一个配送中心服务;(6)每辆车在任何时刻装载的生鲜品不能超过最大载重量。
3 “区域划分+区域调整”两阶段模型构建
3.1 目标函数及约束条件
目标函数:
所有配送车辆遍历完所有配送点完成所有配送任务的最少时间:
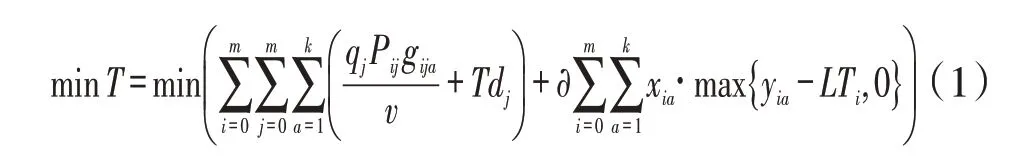
约束条件:
(1)保证每个配送点都有一个配送车辆进行服务:
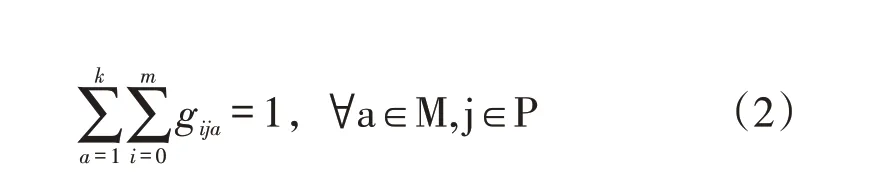
(2)保证每辆配送车辆到达和离开的配送点数量相等:
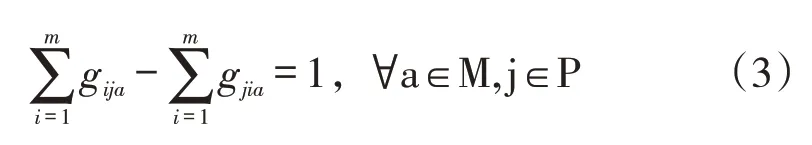
(3)保证每辆车辆的载货量不得超过最大承载量:
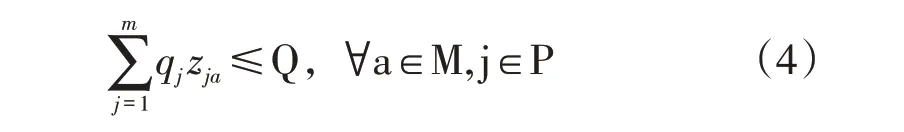
(4)车辆从配送中心出发的时刻为0:

(5)保证每个订单一定有配送车辆服务:
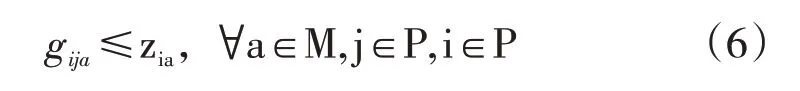
(6)配送车辆的路径是由配送点i到达配送点j:
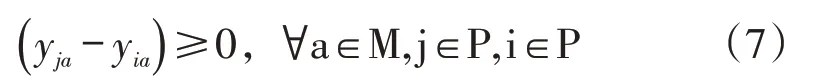
(7)配送车辆从配送点i 到达配送点j 的时间迭代关系:

(8)配送车辆是否经过路径,是否经过配送节点,订单对配送时间是否有要求限制:
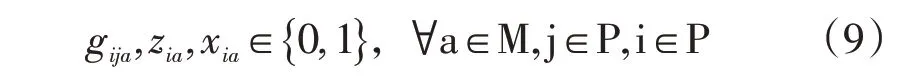
3.2 第一阶段初始区域划分模型
3.2.1 确定初始k值

其中,R 表示在一个配送周期中的生鲜配送总量;Q表示每辆生鲜冷链运输车的最大载货量。
3.2.2 确定初始聚类中心。选择合适的初始点可以使算法收敛更快,因此本文选用均分选择法来确定初始点,其主要思想是:若需要初始点的个数k=p·q,则将整个配送区域地图划分成p 行q 列,每个区域的正中心附近的节点可选择为初始节点,这样选择的节点更趋于均匀,有利于聚类收敛,且不会出现明显的分布不均匀的起始状态。
3.2.3 收敛性检验。K-means 聚类算法要求计算每个新聚类得到的聚类中心,不断重复这一过程直到符合收敛条件。对上述运算得到的k 个聚类中心进行检验,若已经达到收敛条件,则下转进行第二阶段的聚类调整;否则根据重心法重新计算聚类中心,再次聚类,反复迭代,直到算法达到收敛条件为止。
3.3 第二阶段划分区域调整模型
3.3.1 均衡指标计算。均衡载货量指标Wi的现实意义是实现各个划分区域内的配送量达到均衡。Wj表示第j个聚类的Warea值。从计算得到的k个W中,找出最大值Wmax和最小值Wmin,调整的目的是为了让各个区域内的载货量均衡,因此需要将载货最大值Wmax和载货最小值Wmin的差控制在合理范围内,ε 表示可接受的残差,该数值通常由人工设定输入,且取值大小取决于可接受的载货量差异。
.3.2 点集的调整。若上一步的检验没有通过,则需要对此时的聚类结果进行调整。不成立意味着此时聚类划分的各个区域之间的工作量极差较大,说明在这种情况下,有些地区配送任务很快就可以完成,但是有些地区的配送则需要耗时很长,这样会拉低整个区域的配送效率。因此,就需要对区域划分进行如下调整:
在包含最大值Wmax的点集中,筛选出与聚类中心距离最远的数据点,将其弹出该聚类,这样该聚类的W值就会降低,同时,将弹出的数据点加入到该点的k个T中数值次小的另一个聚类中。
为了防止某个数据点被反复弹出,需要对被弹出的数据点进行标记,当下次检验时又识别到标有特殊标记的该数据点时,则不予处理,转而遍历别的数据点,弹出聚类中距离次远的点。这种机制可以有效避免出现某个数据点无法加入到任何一个聚类中的情况,也就是不会出现为某个客户点单独送货的情况。
3.3.3 重新迭代。在对点集进行调整后,有两个聚类的W 值发生变化,需要对这两个聚类重新计算W值,再次检验;不断迭代,直到划分的各个区域之间的载货量基本均衡,即各个区域的工作量极差在可接受的范围之内;最后,停止迭代,最终聚类结果以点集的形式输出。
3.4 两阶段区域划分模型实施步骤
改进的两阶段K-means 聚类算法流程如图1 所示,两阶段区域划分模型具体实施步骤总结如下:
Step1:选取k个初始点聚类中心。
Step2:建立坐标系,标记每一个点的位置坐标,坐标值用经纬度表示;利用公式计算每一个点到k个聚类中心的时间T,录入初始数据库表中。
Step3:在计算的k个配送时间T中选取最小数值对应的点加入到对应类中。
Step4:采用K-means聚类法进行初始阶段聚类,计算得到k 个聚类中心。计算每个聚类的W 值,Wj(j=1,2,...,k)为配送区域内车辆的总载货量。

Step7:将第n 类中到聚类中心配送时间最长的点弹出,加以标记,在之后的循环迭代中遇到有标记的数据点则不予处理,而处理配送时间次短的数据点;将该数据点加入到除n之外配送时间最短的聚类中,重新计算W 值,跳转step5,继续检验、迭代,直至算法满足收敛条件。
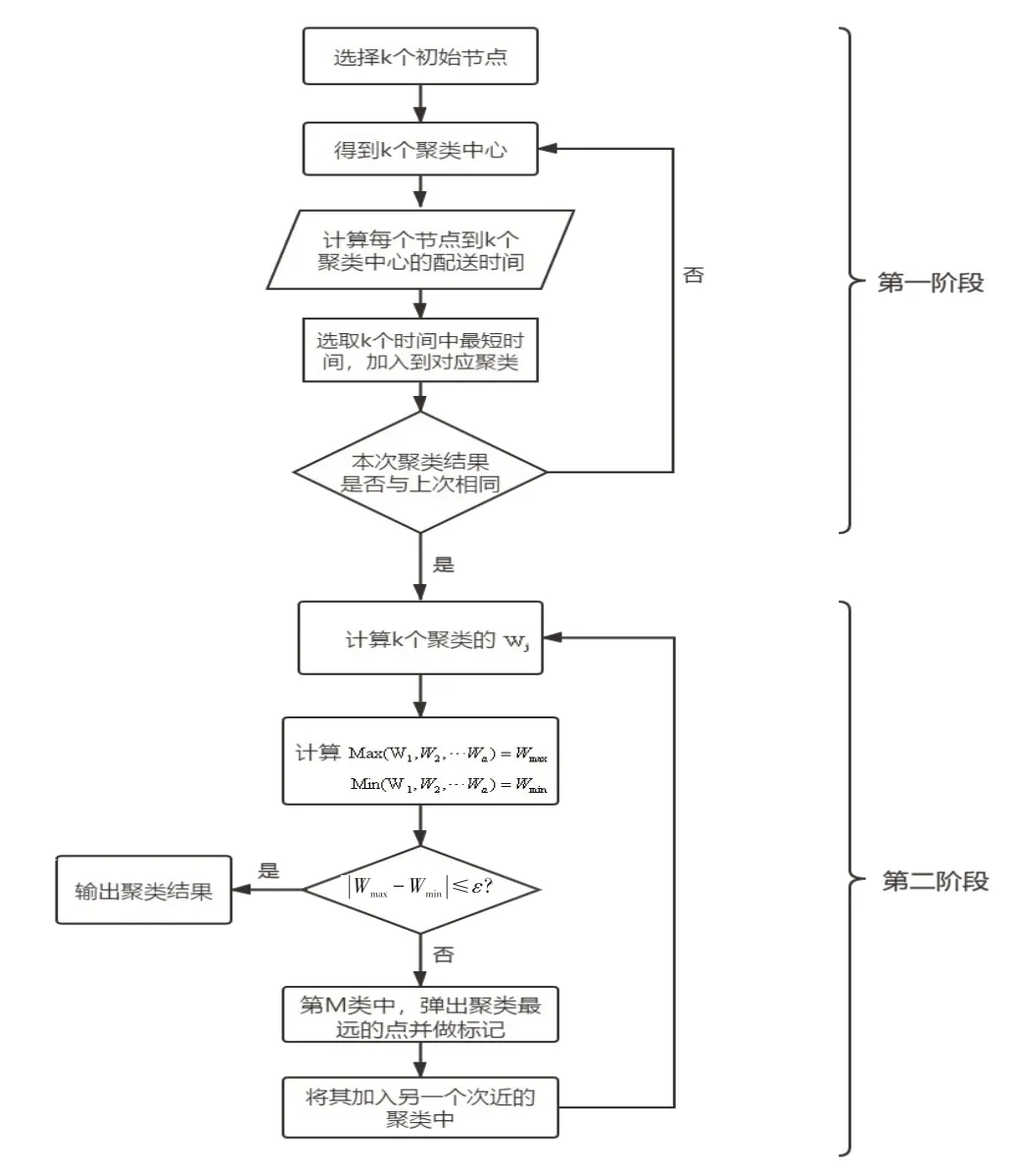
图1 改进的两阶段K-means聚类算法流程图
4 案例分析验证
4.1 案例介绍及参数设置
本文选取生鲜电商企业的一个配送中心一天的配送订单信息,包括该配送中心一天的客户点位置、配送量以及客户时间窗要求等。配送中心及其20个客户节点位置坐标及其他信息见表1,位置散点图如图2所示。
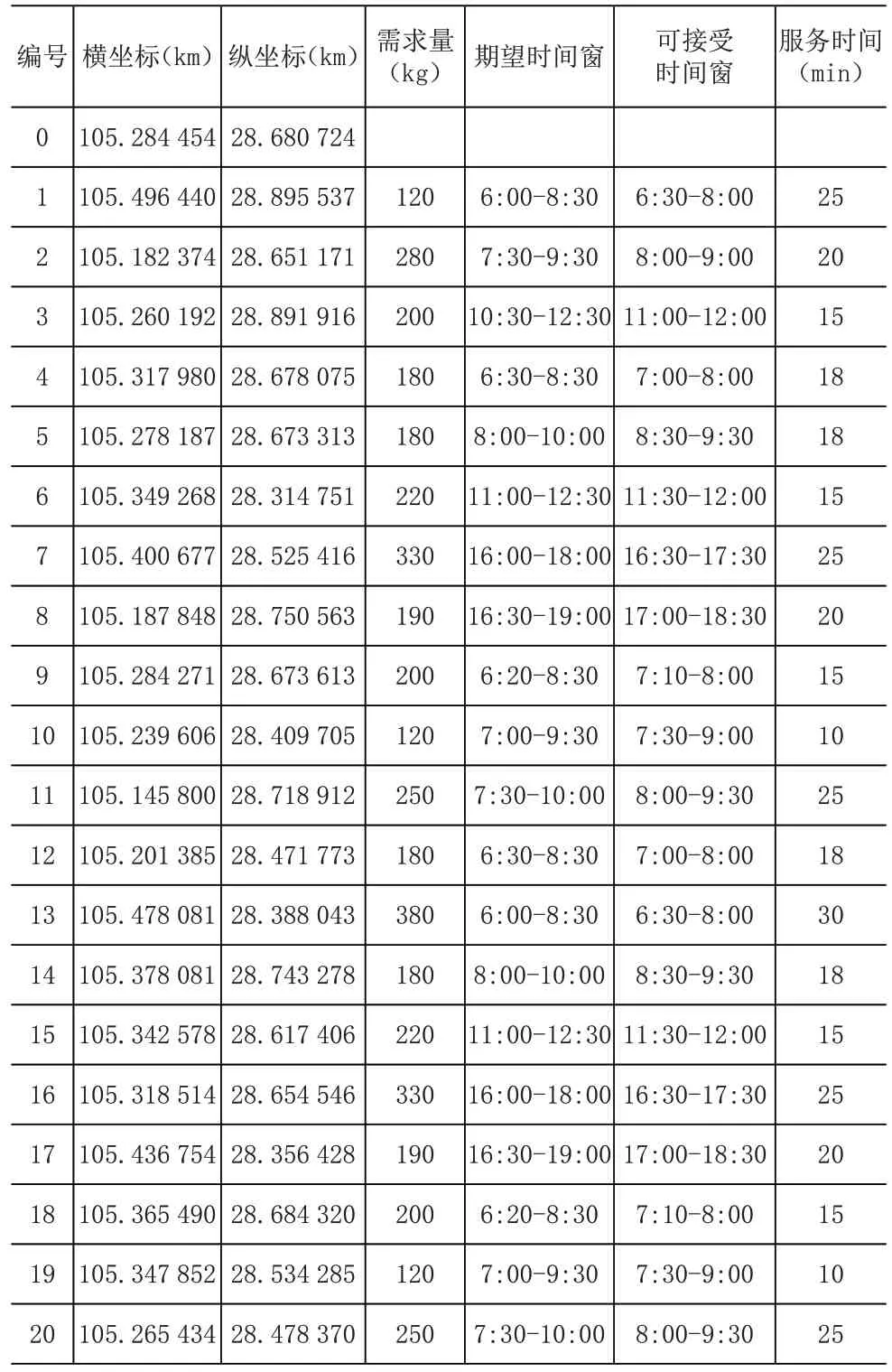
表1 配送中心及各个客户节点基本信息
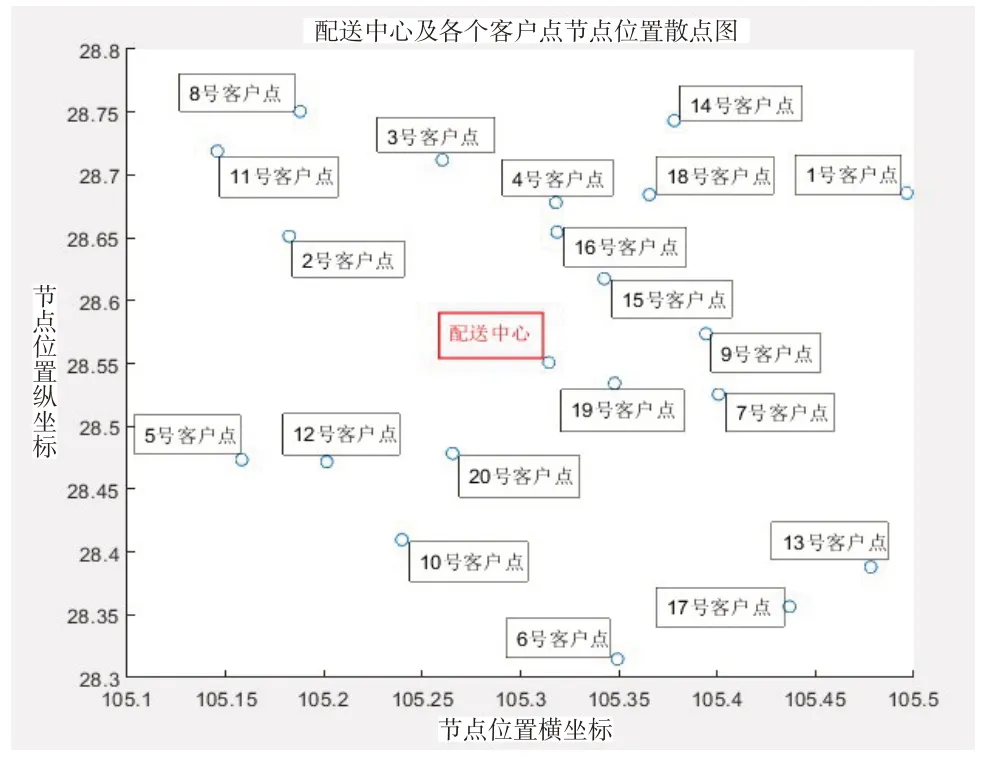
图2 配送中心及各个客户节点位置散点图
模型中各参数的取值情况见表2。
4.2 区域划分模型验证及结果分析
在第一阶段,延续传统的K-means 聚类过程,应用Matlab软件,以总配送时间最短为聚类准则,进行初始区域划分,其聚类结果如图3所示。
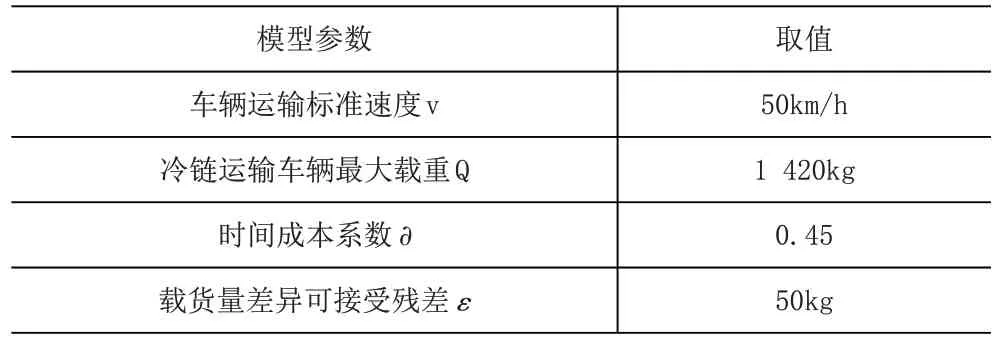
表2 模型中参数取值

图3 初始配送区域划分结果
从图3中可知,初始区域划分结果为五个配送区域,A 区域、B 区域、C 区域、D 区域以及E 区域,分别覆盖3个客户点、6个客户点、4个客户点、3个客户点以及4个客户点,各个区域覆盖的客户节点见表3。
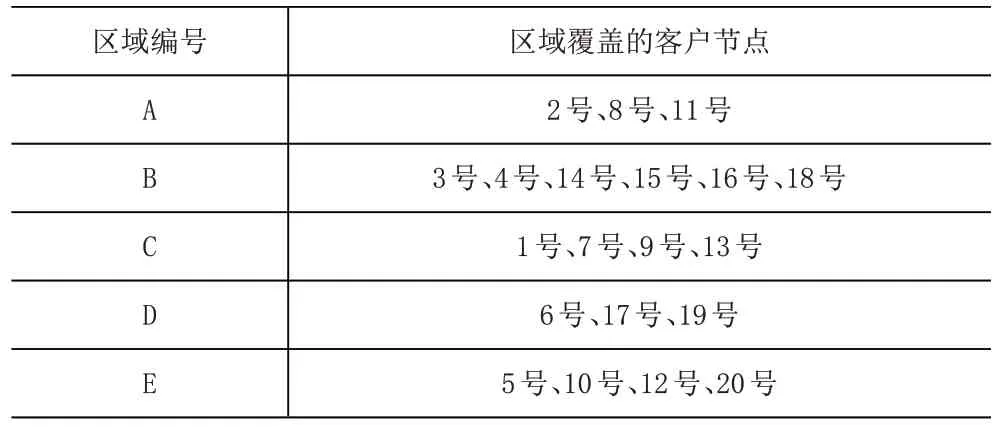
表3 初始配送区域划分及覆盖客户节点
4.3 区域调整模型验证分析
在第二阶段,引入均衡载货指标,对初始区域进行调整,使各个划分区域内的配送量达到均衡,从而保证配送效率。调整后配送区域划分结果如图4 所示。
由图4 可知,配送区域仍被划分为五个区域,但是各个区域覆盖的客户节点有所调整,C区域初始覆盖范围由1 号、7 号、9 号、13 号客户点调整为1 号、7号、9号、19号客户点,D区域初始覆盖范围由6号、17号、19号客户点调整为6号、13号、17号客户点,调整后的配送区域及各个区域覆盖的客户节点见表4。
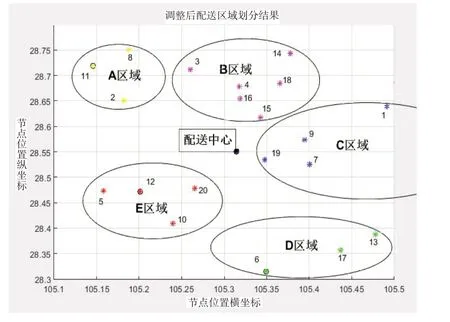
图4 调整后的配送区域划分结果图
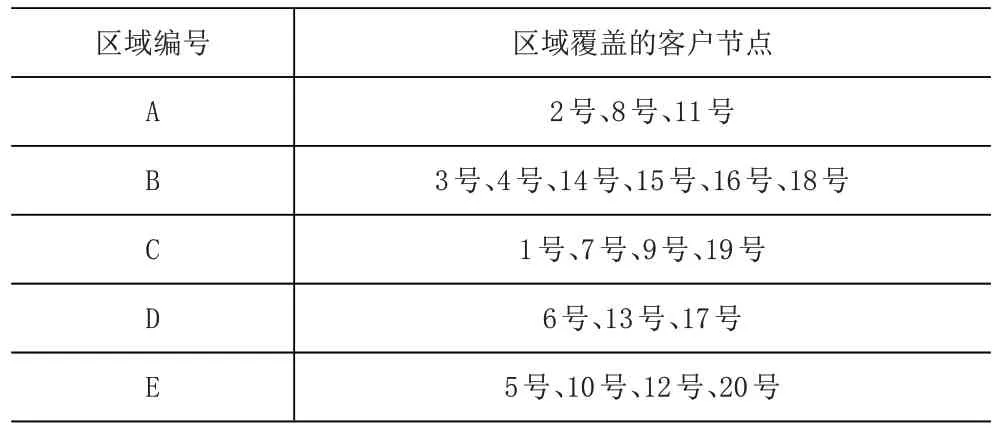
表4 调整后的配送区域划分及覆盖客户节点
从调整后的配送区域可以看出,划分的各个区域不仅考虑到配送时间因素,而且加入了对车辆载货量均衡的考虑,从而保证在快速响应的前提下,使各个划分区域内的配送任务量达到均衡,提高配送效率。
5 结语
本文构建了生鲜冷链配送“区域划分+区域调整”两阶段模型,首先进行初始区域划分,延续传统K-means 聚类过程,以配送时间最短为聚类准则,可以保证生鲜配送的快速响应,在此基础上,引入均衡载货指标,对初始配送区域进行调整,使各个划分区域内的配送任务量达到均衡,保证配送质量,提高配送效率。
猜你喜欢
中国储运(2022年11期)2022-12-23
物流技术与应用(2022年5期)2022-06-17
少儿科技(2021年6期)2021-01-02
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
现代计算机(2018年27期)2018-10-25
舰船电子对抗(2017年6期)2018-01-11
IT经理世界(2016年20期)2016-11-23
互联网天地(2016年1期)2016-05-04
专用汽车(2016年5期)2016-03-01
