
基于近红外光谱的掺伪油茶籽油检测
2020-10-10 06:31:58郭文川朱德宽杜荣宇
农业机械学报 2020年9期
郭文川 朱德宽 张 乾 杜荣宇
(1.西北农林科技大学机械与电子工程学院, 陕西杨凌 712100; 2.农业农村部农业物联网重点实验室, 陕西杨凌 712100)
0 引言
油茶籽油富含油酸、亚油酸、亚麻酸等不饱和脂肪酸[1],其脂肪酸组成与橄榄油相似[2]。油茶籽油的优良品质使其市场销售价格是普通植物油的5~10倍。随着人们身体健康意识的增强,油茶籽油的市场需求量也逐渐增大。一些不法经营者为了谋取高额利润,向油茶籽油中掺入廉价的普通植物油,严重损害了消费者与合法经营者的正当权益。
目前,用于检测食用油品质的方法主要有气相色谱[3]、液相色谱[4]、低场核磁共振[5]、激发矩阵荧光光谱[6]、电子鼻[7]等方法。这些方法需要使用大型昂贵的分析仪器或大量的化学试剂,因而整个检测过程费时、繁琐,且成本较高,无法满足快速鉴别掺伪油茶籽油的要求。近红外光谱分析技术是一种无损、快速、高效且无污染的现代分析技术,已广泛应用于多种领域[8-13]。
目前,在应用近红外光谱技术检测掺伪油茶籽油方面已有一些研究报道[14-16]。但现有研究的样本量偏少,而且大多是直接利用全光谱数据建模或将吸收峰附近的光谱作为输入变量。直接利用全光谱数据建模使得模型输入变量多、模型复杂,易出现过拟合的现象,同时无关信息的引入有可能降低模型的精度,且不利于经济实用的检测仪开发。而直接以油茶籽油光谱吸收峰的位置作为建模变量,则有可能忽略其他光谱处对建模有用的信息[17]。为了开发便携式掺伪油茶籽油检测仪,有必要提取对掺伪油茶籽油敏感的特征波长,并分析其对建模效果的影响。本文以多个产地生产的油茶籽油、玉米油、花生油、菜籽油和大豆油为对象,制备掺伪油茶籽油,采用不同方法从全光谱数据中提取对掺伪油茶籽油敏感的特征波长,并基于全光谱数据和提取的特征波长建立识别掺伪油茶籽油的判别模型,对模型的综合性能进行分析,以期为基于多光谱技术的掺伪油茶籽油检测仪的研发提供基础数据。
1 材料与方法
1.1 试验材料
1.1.1试验样本
试验所用油茶籽油样品共5个,产地分别为江西省吉安市、江西省玉山市、湖南省永州市祁阳县、浙江省杭州市和广西壮族自治区河池市巴马瑶族自治县。用作掺伪的植物油为玉米油、花生油、菜籽油和大豆油,每类植物油均来自3个不同产地。故用于掺伪的植物油样品共计12个。试验所用油均购于西安市某大型超市,所购置的油茶籽油均符合GB/T 11765—2018。试验期间,所有样品均在保质期内。
制备样品时,向每个约20 g油茶籽油样品中按掺伪质量分数为1%、3%、6%、10%、15%和20%的梯度掺入12个用于掺伪的植物油样品,共得到360个掺伪油茶籽油样品。
为了增加纯油茶籽油样本量以保证后续试验所建模型具有普遍性,按质量分数0~90%间以10%为梯度将5个纯油茶籽油样品两两混合,共得到95个不同的纯油茶籽油样品。
1.1.2试验仪器及软件
FA2004型电子天平(上海舜宇恒平科学仪器有限公司,精度0.1 mg);MPA型傅里叶变换近红外光谱仪(德国Bruker公司,配备积分球漫反射附件,波长范围为833~2 500 nm)。
由MPA型傅里叶变换近红外光谱仪自带的光谱分析软件OPUS 6.5 (德国Bruker公司) 采集光谱数据;由Matlab2016a (美国The MathWork公司)完成光谱数据预处理、样本划分、特征波长提取和模型建立。
1.2 近红外光谱采集
利用傅里叶变换近红外光谱仪采集样本的近红外漫反射光谱。光谱扫描范围:833~2 500 nm (12 000~4 000 cm-1),扫描次数:32次;光谱分辨率:8 cm-1;采集条件:室温(23~25℃),以空比色皿为参比。采集光谱时每个样品测量3次,取平均值作为该样品的最终光谱。
1.3 光谱预处理
由于受到仪器自身或外界环境的干扰,所采集的近红外光谱会受到噪声、基线偏移等与建模无关信息的影响,因此在建模前需要对采集的原始光谱进行预处理。常见的光谱预处理方法有Savitzky-Golay (S-G)平滑、标准正态变量变换(Standard normal variate transformation, SNV)、多元散射校正(Multiple scatter correction, MSC)、一阶微分、二阶微分等。
S-G平滑法是光谱分析中常用的预处理方法,它是基于最小二乘原理的移动窗口加权平均算法,能有效地提高光谱的平滑性,并降低噪声的干扰[18]。SNV和MSC法可以消除表面散射、固体颗粒大小和光程变化对近红外漫反射光谱的影响,达到去噪的效果[19-20]。一阶微分、二阶微分等导数预处理方法能减少由系统内部引起的随机噪声,并能增强处理后信号频率的分辨率。
1.4 样品划分
基于样本光谱间欧氏距离的Kennard-Stone (K-S)样本划分方法,能有效地将光谱差异较大的样品选入校正集,将其余相近样品归入测试集,达到保证校正集样品具有代表性和均匀性的目的[21]。因而K-S方法被广泛地用在定性研究中对样本进行划分。
1.5 特征波长选择
1.5.1连续投影算法
基于向量投影分析的连续投影(Successive projections algorithm, SPA)算法能够在光谱矩阵中充分寻找含有最低限度冗余信息的变量组,使变量之间的共线性达到最小。同时能极大地减少建模所用特征波长的数量,提高建模的速度和效率[22]。
对于定性分析问题,文献[23]提出提取的波长数量可以由G值确定。G值定义为
(1)
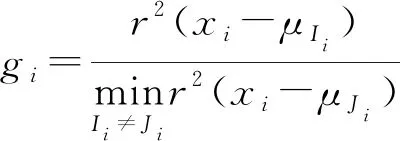
(2)
式中n——总样品数
xi——SPA选定波长下第i个样品的吸光度
μIi——第i个样品所属类别的平均吸光度
μJi——第i个样品对应错误类别的平均吸光度
r(xi-μIi)——xi与μIi马氏距离
Ii、Ji——第i个样品对应的正确、错误类别
gi应该尽可能小,即xi应该靠近其真实类别样本的中心,并且与错误类别样本中心相距较远。
1.5.2无信息变量消除算法
无信息变量消除(Uninformative variable elimination, UVE)算法通过引入一定数目的随机变量到光谱矩阵中,建立偏最小二乘回归(Partial least squares regression, PLS)交互验证模型,根据各波长稳定性指数,即回归系数向量的均值与标准偏差的商的绝对值,决定光谱变量是否被选取[24]。
1.5.3竞争性自适应重加权算法
竞争性自适应重加权(Competitive adaptive reweighted sampling, CARS)算法是将每个波长作为一个单独的个体,利用自适应加权采样技术筛选出PLS模型中回归系数绝对值大的波长点,淘汰回归系数绝对值小的波长点,利用交互验证选出均方根误差(Root mean square error of cross validation, RMSECV)最低的波长变量子集作为优选波长变量子集[25]。
1.6 建模方法及评价指标
1.6.1支持向量机
支持向量机(Support vector machine, SVM)是一种以结构风险最小化为基础思想的有监督学习模式识别算法[26]。该算法将原始数据映射到高维空间以构建最优的分类超平面,然后假设分类器误差与平行超平面间的距离成反比关系,从而解决常规空间里数据间线性不可分的问题[27]。SVM在解决小样本、非线性和高维模式识别问题中表现出许多特有的优势,并在很大程度上克服了“维数灾难”和“过学习”等问题。
1.6.2随机森林
随机森林(Random forest, RF)是一种用于分类和回归的机器学习方法。该方法组合多个决策树算法对相同现象产生重复的预测结果。RF算法对每棵决策树进行自助法重采样,使误差估计的计算能够基于袋外样本数据。该算法的优点体现在对数据集中的噪声有较强的鲁棒性,不需要另外预留部分数据做交叉验证[28]。
1.6.3评价指标
本研究将识别准确率、灵敏度、特异性作为油茶籽油判别模型的评价指标。识别准确率为纯油茶籽油样品和掺伪油茶籽油样品被正确判别的百分比;灵敏度是指纯油茶籽油样品被正确判别为纯油茶籽油的百分比;特异性是指掺伪油茶籽油样品被正确判别为掺伪油茶籽油的百分比。
2 结果与讨论
2.1 光谱分析
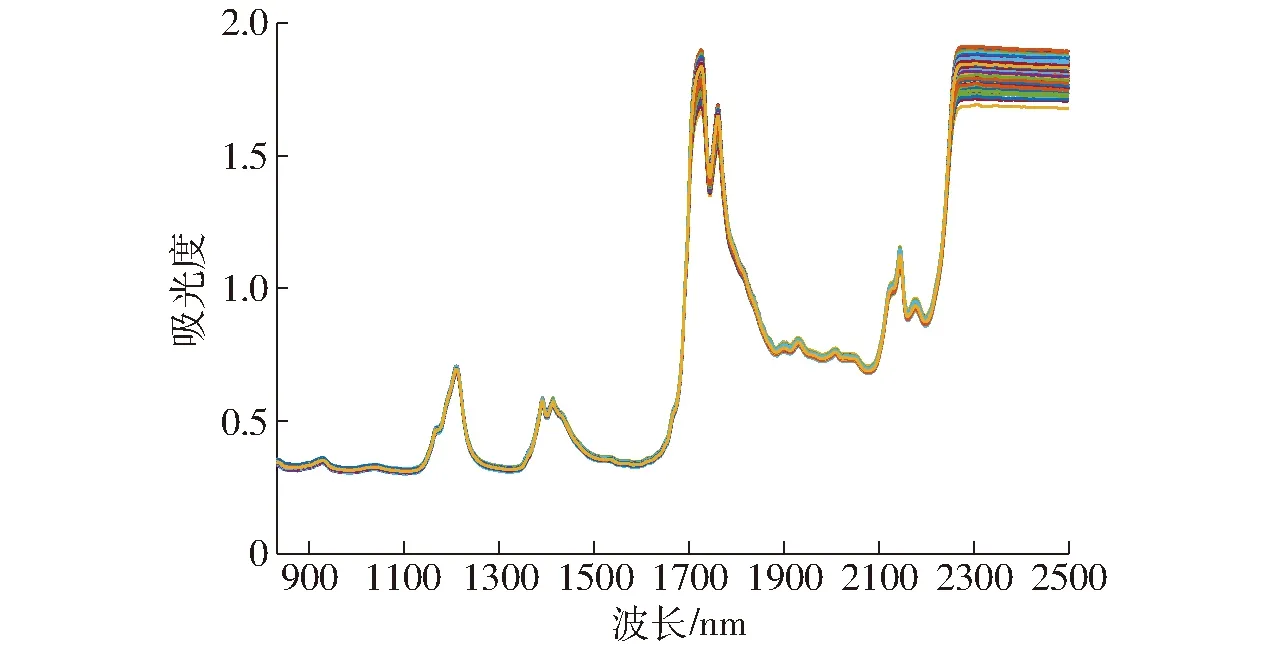
图1 所有样品的原始近红外光谱Fig.1 Original near-infrared spectra of all samples

2.2 光谱预处理和样本划分
为了减少无关因素对建模效果的影响,分别用MSC、SNV、S-G平滑、一阶微分和二阶微分共5种预处理方法对光谱进行预处理,然后使用SVM建立油茶籽油掺伪判别模型。以径向基函数作为SVM模型的核函数,并根据十折交叉验证和网格搜索法选择各模型交叉验证识别准确率最高时对应的惩罚因子和核参数作为建模参数。具体参数见表1。
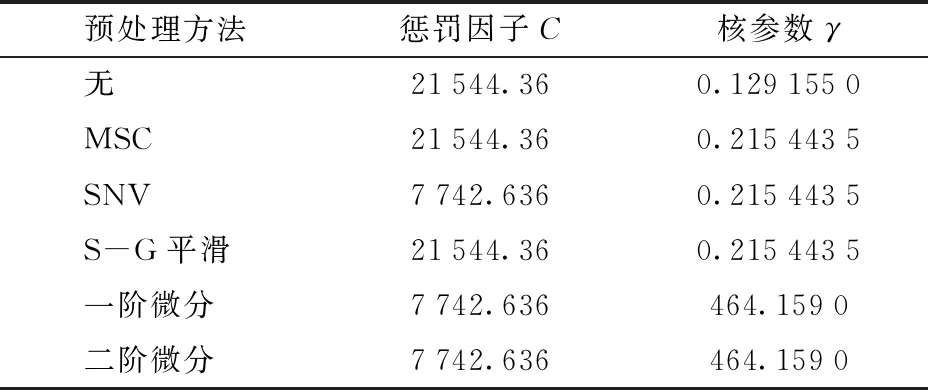
表1 不同预处理方法下SVM建模的参数Tab.1 Determined parameters of SVM models by different pretreatment methods
对比不同预处理方法下校正识别准确率和交叉验证识别准确率,确定最优的光谱预处理方法。不同预处理方法的建模结果如表2所示。由于MSC预处理方法使得建立的SVM模型具有最高的交叉验证识别准确率,因此在后续的研究中只对MSC预处理后的光谱进行分析。
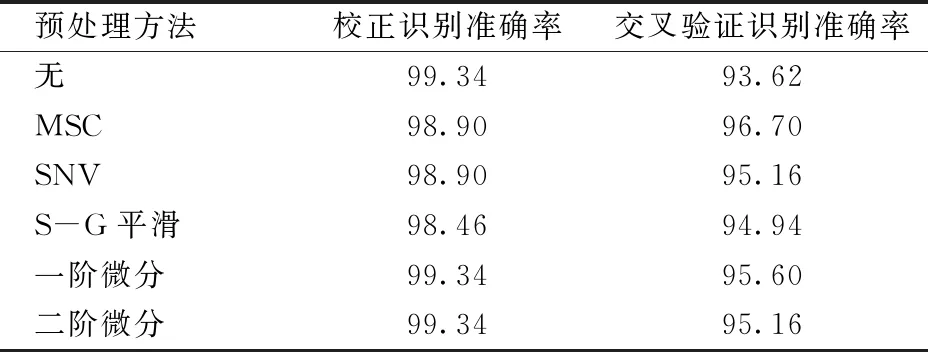
表2 不同预处理方法下SVM建模的预测结果Tab.2 Prediction results of SVM models by different pretreatment methods %
对经MSC处理后的光谱采用K-S法按2∶1的比例分别对360个掺伪油茶籽油和95个纯油茶籽油进行样本划分,得到校正集样品304个(240个掺伪油茶籽油和64个纯油茶籽油样品),测试集样品151个(120个掺伪油茶籽油样品和31个纯油茶籽油样品)。
2.3 特征波长选择
2.3.1SPA算法
将该算法提取的最小波长数设定为1,最大数设定为30,计算不同特征波长数下的G,结果如图2所示。由图2可见,当特征波长数小于9时,随着波长数的增加,G迅速减小,但当波长数量大于9时,G逐渐增大。以G最小处的波长数作为最佳波长数。因此本文以9个特征波长作为输入的特征变量,该9个特征波长分别是1 163.64、1 235.16、1 382.72、1 419.82、1 458.97、1 633.64、1 733.02、1 756.50、1 896.56 nm。

图2 不同特征波长数的G变化曲线Fig.2 Calculated G values at different numbers of characteristic wavelengths
2.3.2UVE算法
基于UVE算法的掺伪油茶籽油特征波长选取结果如图3所示。其中,竖线左侧为全光谱1 178个波长的稳定性指数分布曲线,右侧为相同数量的随机变量稳定性指数分布曲线。以随机变量稳定性指数最大绝对值的99%作为变量筛选的阈值,即稳定性指数在两条水平虚线以外的特征波长被选中。利用UVE算法共选择出207个特征波长,其分布如图4所示。
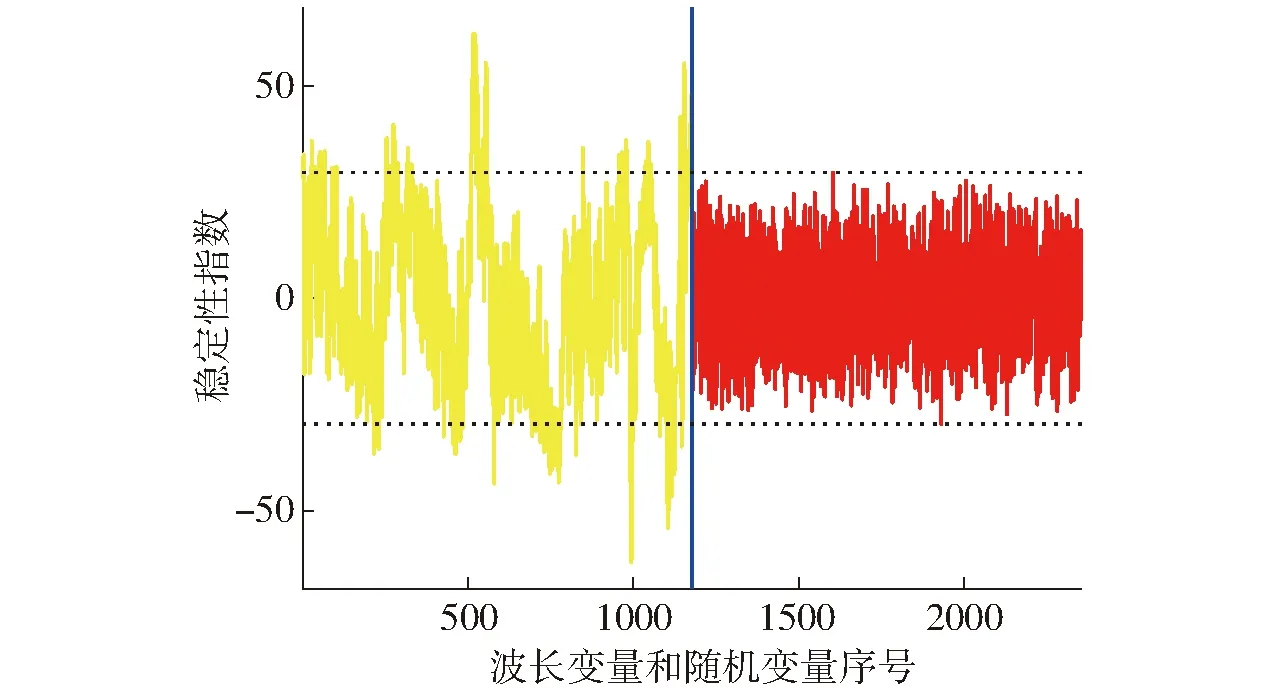
图3 各波长变量和随机变量下的稳定性指数Fig.3 Stability indices at different wavelength variables and random variables
2.3.3CARS算法
图5为应用CARS算法筛选特征波长过程中特征波长数、RMSECV以及回归系数随运行次数的变化图。由图5可见,当运行次数从1次增加到28次,特征波长数从迅速下降到缓慢下降,RMSECV逐步降低,表明在1~28次筛选过程中淘汰了较多无关变量,模型精度逐步提高。当运行次数大于28次时,随着运行次数的增加,RMSECV缓慢或快速增大,模型精度下降。在运行次数为28次时,RMSECV降到最低,此时有35个波长变量被保留下来。因此以该35个波长为特征波长,其分布如图6所示。
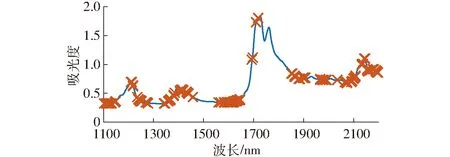
图4 基于UVE算法筛选的特征波长Fig.4 Selected characteristic wavelengths by using UVE algorithm

图5 基于CARS算法筛选特征波长的过程Fig.5 Process of selecting characteristic wavelengths by using CARS algorithm

图6 基于CARS算法筛选的特征波长Fig.6 Selected characteristic wavelengths by using CARS algorithm
从利用SPA、UVE和CARS算法提取的特征波长看,特征波长数明显少于全光谱(1 100~2 200 nm)下的1 178个波长,分别仅是全光谱下波长数的0.936 9%、17.57%和2.971%。这说明提取特征波长对于简化模型、提高运算速度有很重要的作用。此外,从提取的特征波长看,除了吸收峰或吸收峰附近的波长外,吸收峰之间的一些波长也是对掺伪油茶籽油敏感的特征波长。
2.4 建模结果及建模方法比较
2.4.1建模参数的选择和设定
以径向基函数作为SVM模型的核函数。根据十折交叉验证和网格搜索法选取惩罚因子C和核参数γ。建立RF模型时,以不同特征波长提取方法下预测准确率最高时的决策树个数作为RF模型的决策树数量。确定的参数见表3。
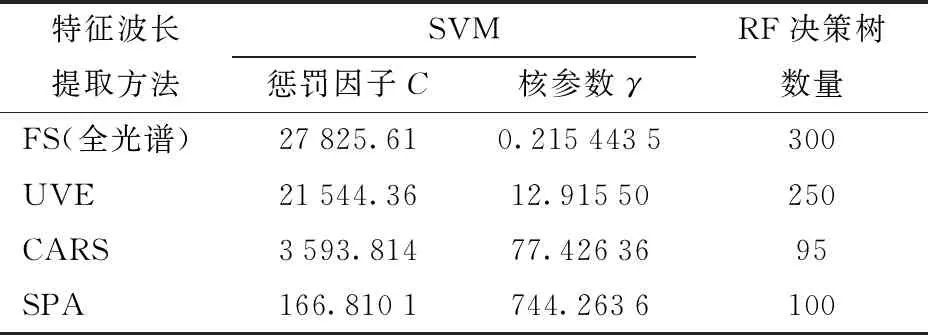
表3 不同特征波长提取方法确定的SVM和RF模型的参数Tab.3 Determined parameters of SVM and RF models by different methods of characteristic wavelength selection
2.4.2SVM模型建模结果
以不同方法所提取的特征波长作为建模输入变量时,所建立的SVM模型对校正集和测试集的纯油茶籽油和掺伪油茶籽油的判别结果见表4。由表4可以看出,基于SPA、UVE和CARS所提取的特征波长建立的SVM模型(SPA-SVM、UVE-SVM和CARS-SVM)对测试集的识别准确率分别为96.03%、96.69%和96.69%,均高于基于全光谱建立的SVM模型(FS-SVM)对测试集94.70%的识别准确率。在灵敏度方面,SPA-SVM的灵敏度与FS-SVM相同,均为96.77%,UVE-SVM和CARS-SVM的灵敏度最高,达到100%,说明UVE和CARS提高了SVM模型对纯油茶籽油样本的识别能力。在特异性方面,SPA-SVM、UVE-SVM和CARS-SVM的特异性均为95.83%,高于FS-SVM的94.17%,说明3种特征波长提取方法均提高了SVM模型对掺伪油茶籽油样本的识别能力。
所建立的SVM模型对不同掺伪质量分数油茶籽油的识别准确率如表5所示。表5说明FS-SVM、UVE-SVM和CARS-SVM对掺伪质量分数为3%以上的油茶籽油样本的识别准确率达到100%,UVE-SVM和CARS-SVM对掺伪质量分数为1%的油茶籽油样本的识别准确率为73.68%,高于FS-SVM的63.16%,说明UVE和CARS提高了SVM模型对掺伪质量分数为1%的油茶籽油样本的识别能力。而SPA方法虽然使SVM模型对掺伪质量分数为1%的油茶籽油样本的识别准确率提高到78.95%,但对掺伪质量分数为3%的油茶籽油样本的识别准确率却下降到96.43%,说明SPA方法在减少波长输入的同时也删去了对SVM建模有用的信息。
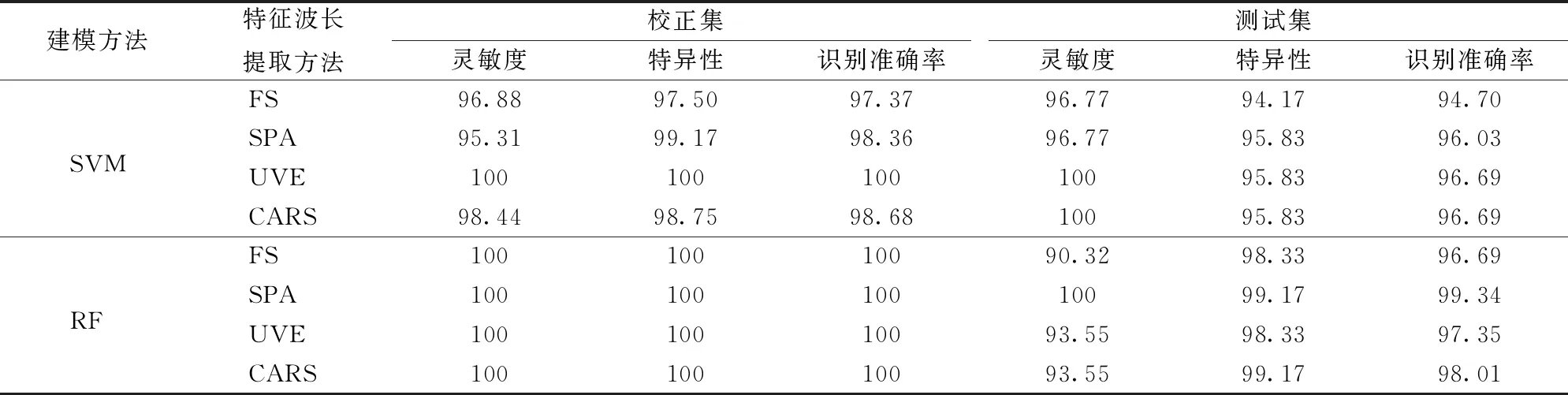
表4 不同特征波长提取方法下SVM和RF模型对纯油菜籽油和掺伪油茶籽油的识别结果Tab.4 Identification results of SVM and RF models for pure and adulterated oil-tea camellia seed oil by using different characteristic wavelength selecting methods %

表5 不同模型对不同掺伪质量分数油茶籽油的识别准确率Tab.5 Identification accuracy of different models for adulterated oil-tea camellia seed oil at different mass fractions %
2.4.3RF模型建模结果
不同特征波长提取方法下,基于所提取的特征变量建立的RF模型对校正集和测试集中纯油茶籽油和掺伪油茶籽油的判别结果见表4。由表4可见,基于SPA、UVE和CARS所提取的特征波长建立的RF模型(SPA-RF、UVE-RF和CARS-RF)的识别准确率分别为99.34%、97.35%和98.01%,均高于基于全光谱所建立的RF模型(FS-RF)。在灵敏度上,SPA-RF、UVE-RF和CARS-RF的灵敏度分别为100%、93.55%和93.55%,高于FS-RF的90.32%,说明3种特征波长提取方法均提高了RF模型对纯油茶籽油的识别能力。在特异性上,UVE-RF与FS-RF的特异性相等,为98.33%,SPA-RF和CARS-RF的特异性均为99.17%,说明利用SPA和CARS特征波长提取方法提高了RF模型对掺伪油茶籽油的识别能力。
所建立的RF模型对不同掺伪质量分数油茶籽油的识别准确率见表5。由表5可见,不管是基于全光谱,还是基于不同方法所提取的特征波长,所建立的RF模型对掺伪质量分数为1%的掺伪油茶籽油的识别准确率均为94.74%。当掺伪质量分数为3%时,SPA-RF和CARS-RF的识别准确率为100%,高于FS-RF和UVE-RF 96.43%的识别准确率。结果表明,全光谱中含有对RF模型冗余的信息,而SPA和CARS方法比UVE方法能有效地从全光谱中提取出对掺伪油茶籽油敏感的特征波长。
2.4.4结果比较
当对SVM和RF模型性能进行比较时,由表4可知,除SPA外,测试集其他特征波长提取方法下所建SVM模型的灵敏度均高于RF模型的灵敏度,说明SVM模型对纯油茶籽油的识别能力更强。而RF模型的特异性均高于SVM模型的特异性,说明RF模型对掺伪油茶籽油的识别能力更强。
由表5可知,RF模型对掺伪质量分数为1%的掺伪油茶籽油的识别准确率(94.74%)明显高于SVM模型的最高识别准确率78.95%。而当掺伪质量分数在3%以上时,两种模型的判别能力基本相当。
在所建立的8种掺伪油茶籽油判别模型中,测试集SPA-RF的识别准确率、灵敏度和特异性均最高,分别为99.34%、100%和99.17%(表4),且该模型对掺伪质量分数为1%和3%及以上的掺伪油茶籽油的识别准确率分别为94.74%和100%(表5)。此外,该模型的输入波长数只有9个,对于简化模型,降低运算时间和便携式掺伪油茶籽油检测仪的开发具有重要的意义。
3 结论
(1)研究了SPA、UVE和CARS 3种特征波长选择方法下SVM和RF模型对不同掺伪质量分数(0~20%)油茶籽油的识别能力。结果表明,这3种特征波长提取方法均可提高所建模型对油茶籽油的识别准确率、灵敏度和特异性,SVM模型具有较高的灵敏度,而RF模型具有良好的特异性。
(2)在所建立的8个模型中,SPA-RF模型具有最佳识别能力,其识别准确率、灵敏度、特异性分别为99.34%、100%和99.17%,对掺伪质量分数为1%的掺伪油茶籽油识别准确率达94.74%,对掺伪质量分数为3%及以上的掺伪油茶籽油的识别准确率达到100%。本研究为基于多光谱技术开发便携式掺伪油茶籽油检测仪提供了基础数据。
猜你喜欢
特产研究(2022年6期)2023-01-17 05:06:16
北京航空航天大学学报(2022年8期)2022-08-31 08:58:58
天然产物研究与开发(2018年1期)2018-02-02 07:21:24
实用口腔医学杂志(2017年6期)2017-09-19 02:51:28
发明与创新·大科技(2016年5期)2016-05-17 17:39:58
中国照明(2016年4期)2016-05-17 06:16:15
中国光学(2015年5期)2015-12-09 09:00:28
物理实验(2015年9期)2015-02-28 17:36:46
食品工业科技(2014年23期)2014-03-11 18:18:54
无机化学学报(2014年1期)2014-02-28 17:30:08
