
运用三维人体测量的青年男性上半身体型分类
2020-09-15 01:04:56袁惠芬汪东升孟晓东
河南工程学院学报(自然科学版) 2020年3期
阮 婷, 袁惠芬, 汪东升, 孟晓东, 夏 威
(1.安徽工程大学 纺织服装学院,安徽 芜湖 241000;2.安徽工程大学 纺织面料安徽省高校重点实验室,安徽 芜湖 241000;3.安徽红爱实业股份有限公司,安徽 安庆 246500)
随着生活水平的提高,消费者对服装舒适性和合体度的要求越来越高,现有的国标号型标准已不能满足部分特殊体型人群的需要,服装市场迫切需要更完备、更细致的人体体型分类。高磊等[1]利用手工测量和三维人体测量提取了男性下体部位及男性第一性征的数据,通过主成分分析提取了围度形态因子、纵向形态因子、丰满因子、性征形态因子和腰胯形态因子进行下半身体型分类,研究结果为男性内裤的纸样设计提供了建议。张中启等[2]首先通过因子分析提取了反映下体体型特征的5个主要因子,再通过R型聚类提取了能够反映男大学生下体体型特征的15个特征指标,最后利用层次聚类将男大学生下体体型分为5类,研究结果为设计合体男性裤装提供了基础数据。齐静等[3]通过因子分析和K-means聚类分析将西部地区青年男性的体型分为7类,研究结果为制订新的男性服装号型标准提供了理论支持。黄灿艺等[4]选取身高、胸围、总肩宽、颈根围、颈中围、后颈根围、颈长和肩颈点宽8个尺寸,运用K-means聚类分析,把青年男性颈部按照粗细分为7个类型,研究结果为男装领型的结构设计提供了尺寸参考。金娟凤等[5]借助IMAGEWAGE 12.0与MATLAB R2012b软件,通过分析肩点横截面形态特征,提取了曲线曲率半径及矢额径比作为分类指标,对比曲率半径均值,确定了5个特征点角度,运用K-means聚类分析及方差分析将肩部形态划分为4类,研究结果为肩部结构设计提供了参考。随着科技的进步,人体测量方式已逐渐从传统手工测量转向更高效客观的非接触三维扫描人体测量。与传统手工测量方式不同,三维人体测量方式的测量部位更多、数据量更大,根据三维人体测量数据来进行体型分类是该领域研究的热点和难点。本研究以青年男性大学生群体为对象,通过三维人体测量技术采集其上半身数据并通过因子分析提取特征参数,结合聚类分析实现青年男性上半身体型的分类,以期为提高青年男性上衣的合体性提供有价值的参考。
1 实验方法
1.1 测试仪器
北京博维恒信3D Camega非接触三维人体扫描仪。
1.2 测试要求
参照GB/T 23698—2009《三维扫描人体测量方法的一般要求》[6],实验环境需要符合裸体测量环境要求,实验温度为(25±2)℃,相对湿度为(65±5)%。测试需穿着三维人体测量专用的紧身衣,赤足,戴头套,不得佩戴手表、眼镜等饰品。测试者按测量要求自然站立,双手握拳距离大腿5~8 cm,测量时保持正常呼吸频率,避免因晃动造成的测试误差。同时,为了提高测量精确度,对同一个人进行3次三维人体测量后取平均值。
1.3 测量项目
参照GB/T 16160—2017《服装用人体测量的尺寸定义与方法》[7],选取27个三维人体测量项目,另补充1个手动测量项目——体重,共计28个项目,具体如表1所示。

表1 测量项目Tab.1 Measurement items
1.4 样本容量
合理的样本容量N是进行样本抽样与分析的前提与基础。在统计学中,N<30为小样本,N>30为大样本[8]。进行人体测量分析时,N越大,分析结果越精确。按GB/T 1335.1—2008《服装号型 男子》[9]查询青年男性上半身体型中重要部位尺寸(身高、胸围、腰围、总肩宽)的最大允许误差和标准差,具体如表2所示。
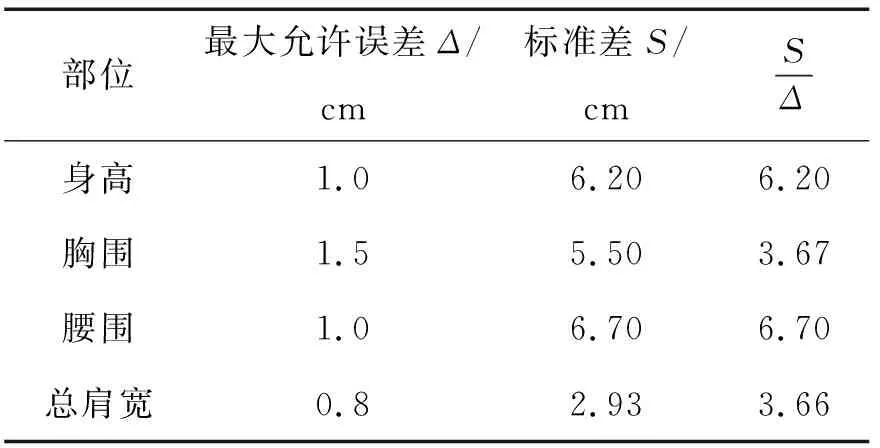
表2 成年男性部分尺寸允许的最大误差和标准差Tab.2 Maximum allowable errors and standard deviations of male adult part sizes
样本容量N计算公式[10]如下:
式中:μα表示α水平的概率;S表示总体标准差;Δ表示样本最大允许误差。
取显著性水平α=5%,根据标准正态分布函数表μα=1.96、人体腰围标准差S=6.70 cm、最大允许误差Δ=1.0 cm,得N≈173,即理论上N应不低于173。考虑到会产生无效样本,最终确定N=210。
1.5 实验对象
选取安徽工程大学210名青年男性在校大学生作为研究对象,年龄为18~25岁,身高为160~190 cm,体重为45~98 kg。
2 实验数据分析
2.1 数据的标准化处理
为保证实验数据的合理性,在数据分析之前对数据进行标准化处理。数据标准化处理分为数据同趋化处理和无量纲化处理,前者解决不同性质数据问题,后者解决数据可比性问题。常用的数据标准化方法有最小最大标准化、Z-score标准化和按小数定标标准化等。本研究选择Z-score标准化处理,即用变量的观察值减去变量均值,再除以变量标准差。经Z-score标准化处理后,数据转化为无量纲的纯数值,可消除数据大小和单位的影响,便于不同单位或量级的指标进行比较和加权。经Z-score标准化处理后的数值应为-1~1,若数值的绝对值大于2,则认为该数值为异常值而予以剔除。预处理后,最终保留199名实验对象的测量数据。
2.2 因子分析
2.2.1Bartlett和KMO检验
因子分析能够在丢失最少信息的前提下,将原始的众多指标综合成具有代表性的因子[11]。KMO即Kaisex-Meyer-Olkin测度,可检测变量间的偏相关度是否很小;Bartlett球形检验,可检验相关矩阵是否为单位矩阵。KMO和Bartlett球形检验可用于检测数据是否适合做因子分析[12]。KMO检验结果见表3。

表3 KMO和Bartlett检验Tab.3 Test of KMO and Bartlett
根据表3可知,KMO检验结果为0.702,大于0.7,说明数据适合做因子分析。Bartlett球形检验的近似卡方值较大,为9 894.175,相应显著性概率为0.000,为高度显著,说明变量间相互独立。因此,采集的数据适合进行因子分析。
2.2.2分析过程
表4是对上半身相关部位总方差的解释。其中,前7个成分的特征值大于1,累积方差达80.541%,即提取前7个成分后,可解释总方差的80.541%。
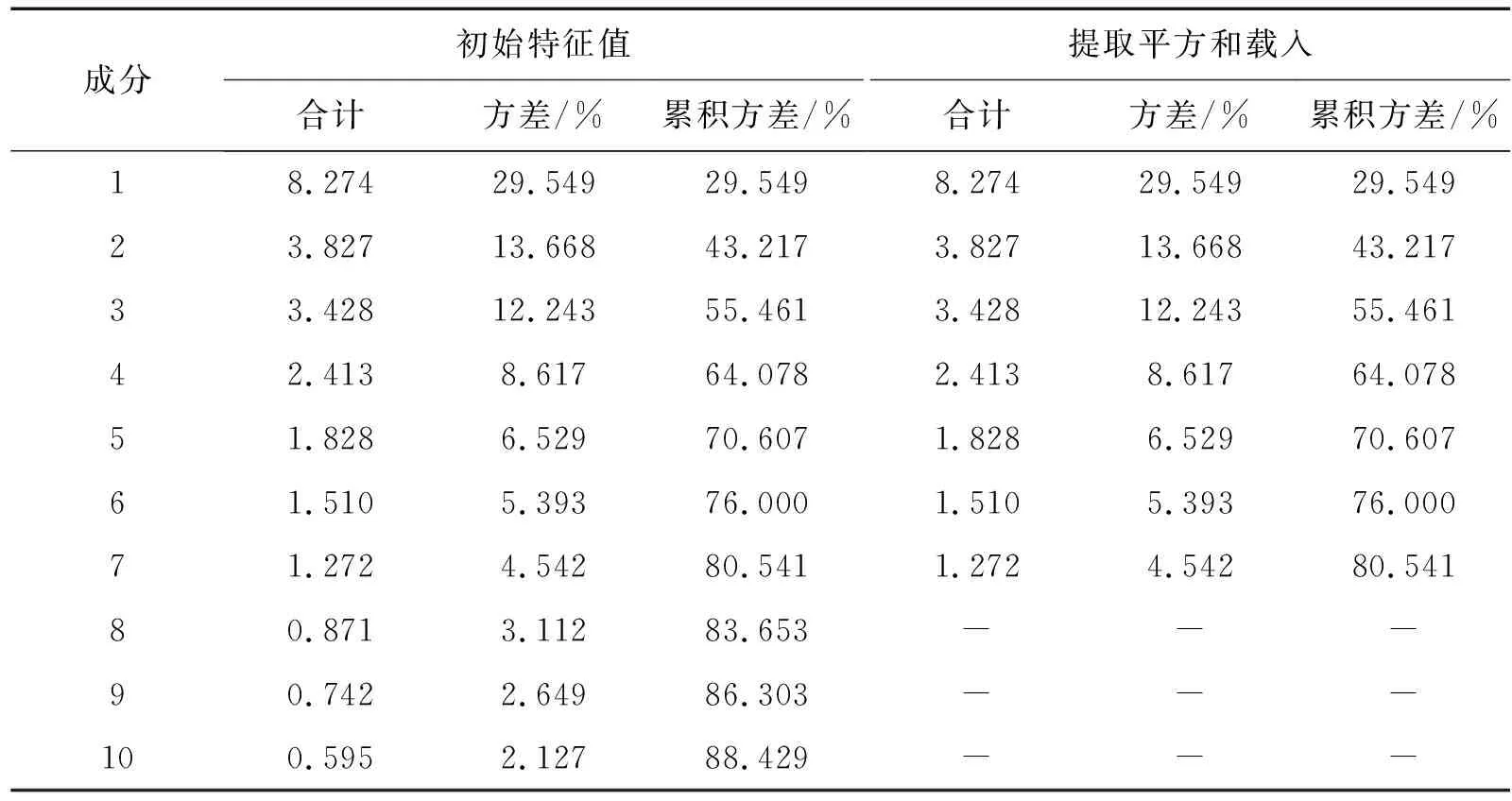
表4 上半身相关部位总方差解释Tab.4 Total variance explained for upper body
表5是因子载荷矩阵采用方差最大法经过正交旋转得到的旋转成分矩阵。结合表4,可以得到以下7个用于描述上半身特征的公因子:
(1)第1公因子为体重、颈围、胸围、腹围、腰围、上臂围、手腕围、总肩宽、前肩宽、胸围上身比、前胸宽、后背宽这12个关于上半身围度宽度的变量,称为围度宽度因子;
(2)第2公因子为肚胸凸差、胸凸、腰凹、肚凸、凸腹值这5个关于上半身曲线的变量,称为曲线因子;
(3)第3公因子为身高、后腰节长、前腰节长、前胸围线高这4个关于上半身长度的变量,称为长度因子;
(4)第4公因子为下身上身比、后腰节身高比这2个关于上半身比例的变量,称为上半身比例因子;
(5)第5公因子为肩斜左、肩斜右这2个关于肩部的变量,称为肩部形态因子;
(6)第6公因子为袖长、袖长身高比这2个关于袖长的变量,称为袖长形态因子;
(7)第7公因子为胸腰差,称为胸腰差因子。
综上,影响上半身体型特征的因子可以归纳总结为围度宽度因子、曲线因子、长度因子、上半身比例因子、肩部形态因子、袖长形态因子、胸腰差因子。其中,影响青年男性上半身体型的主要变量集中在围度宽度因子上,其次是曲线因子和长度因子。
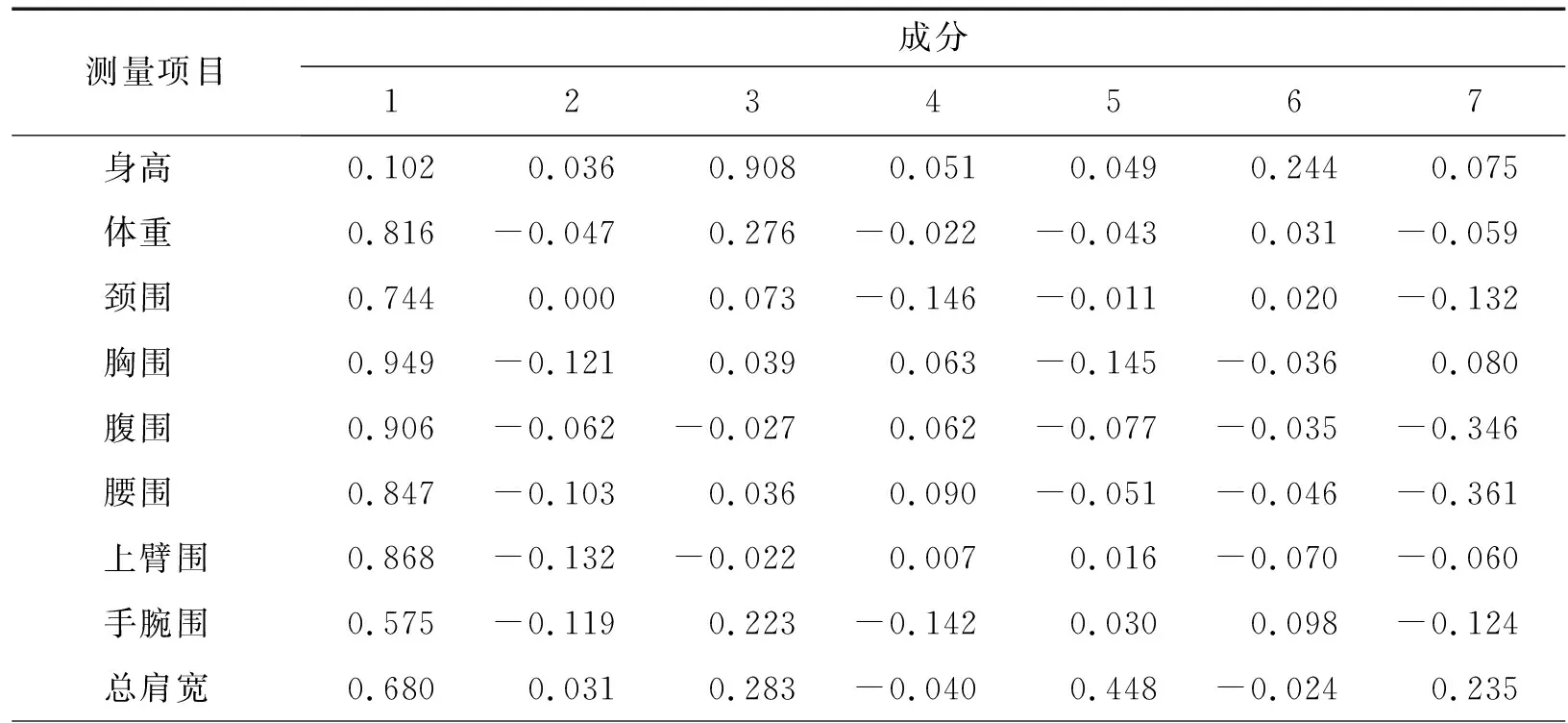
表5 旋转成分矩阵Tab.5 Rotational component matrix
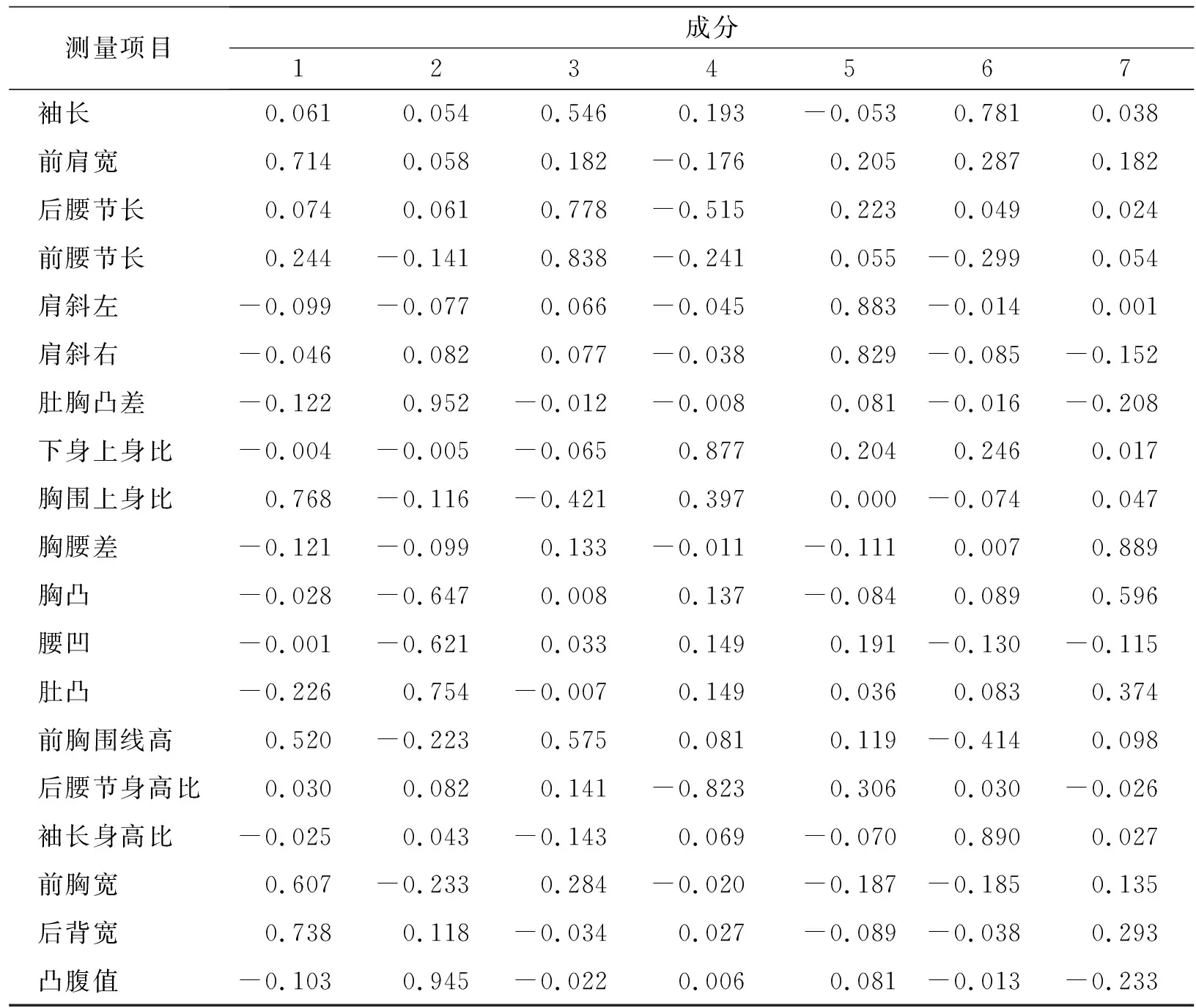
表5(续)
2.2.3特征指标的提取
为便于描述上半身体型特征,采用权重分析方法,计算比较各公因子的方差贡献率和各变量的权重,提取出各公因子的特征指标。首先通过计算因子贡献率与7个因子累计贡献率的比值得到各因子的权重,然后依据成分得分系数矩阵的系数计算得到各变量在公因子中的权重,具体结果如表6所示。
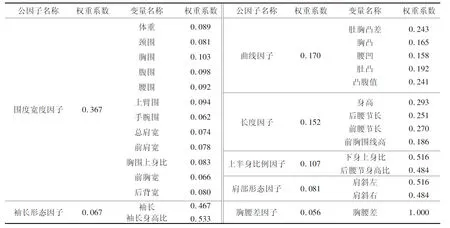
表6 因子权重值Tab.6 Factor weights
由表6可以看出,胸围、肚胸凸差、身高、下身上身比、肩斜左、袖长身高比、胸腰差在各公因子中所占比重最大,即这7个变量在各公因子对应的变量中最为重要,故将这7个变量作为青年男性上半身的特征指标。
3 K-means聚类分析
K-means聚类采用距离作为个体之间相似性的评价指标,把距离近且独立的簇作为最终目标[13]。在进行K-means分析时,首先依据专业知识和因子权重比例确定分类的特征指标,然后利用ANOVA检验确定聚类数K,最佳分类数的类间误差平方和最小,类内误差平方和最大且F值最大。最佳分类数的组内差异远小于组间差异,即最佳分类数的组内体型相似、不同组体型差异明显。
结合服装结构知识可知:围度宽度因子反映人体的宽度和躯干、上肢的厚度;曲线因子反映人体曲线凹凸程度及丰满度;长度因子反映人体高度,肩部形态因子、上半身比例因子、袖长形态因子和胸腰差因子只反映人体上半身部分结构特征。结合因子权重的占比可知:围度宽度因子、曲线因子和长度因子的权重共占上半身总权重的68.9%,占比较高;上半身比例因子、肩部形态因子、袖长形态因子和胸腰差因子的权重之和占上半身总权重的31.1%,占比不高。因此,不将上半身比例因子、肩部形态因子、袖长形态因子和胸腰差因子作为上半身分类依据。综上所述,选取围度宽度因子中的前肩宽、曲线因子中的肚胸凸差和长度因子中的身高作为K-means聚类分析的特征指标。
方差分析见表7。通过表7可知,从概率值来看,当显著性小于0.05时,变量是无差异的假设成立,故当分类数为4、5、6、7、8、9、10时结果可接受。比较来看,当体型分类数为4时,类间误差平方和最大,类内误差平方和最小且F检验值最大,聚类效果最佳,说明将样本分为4类较为合理。
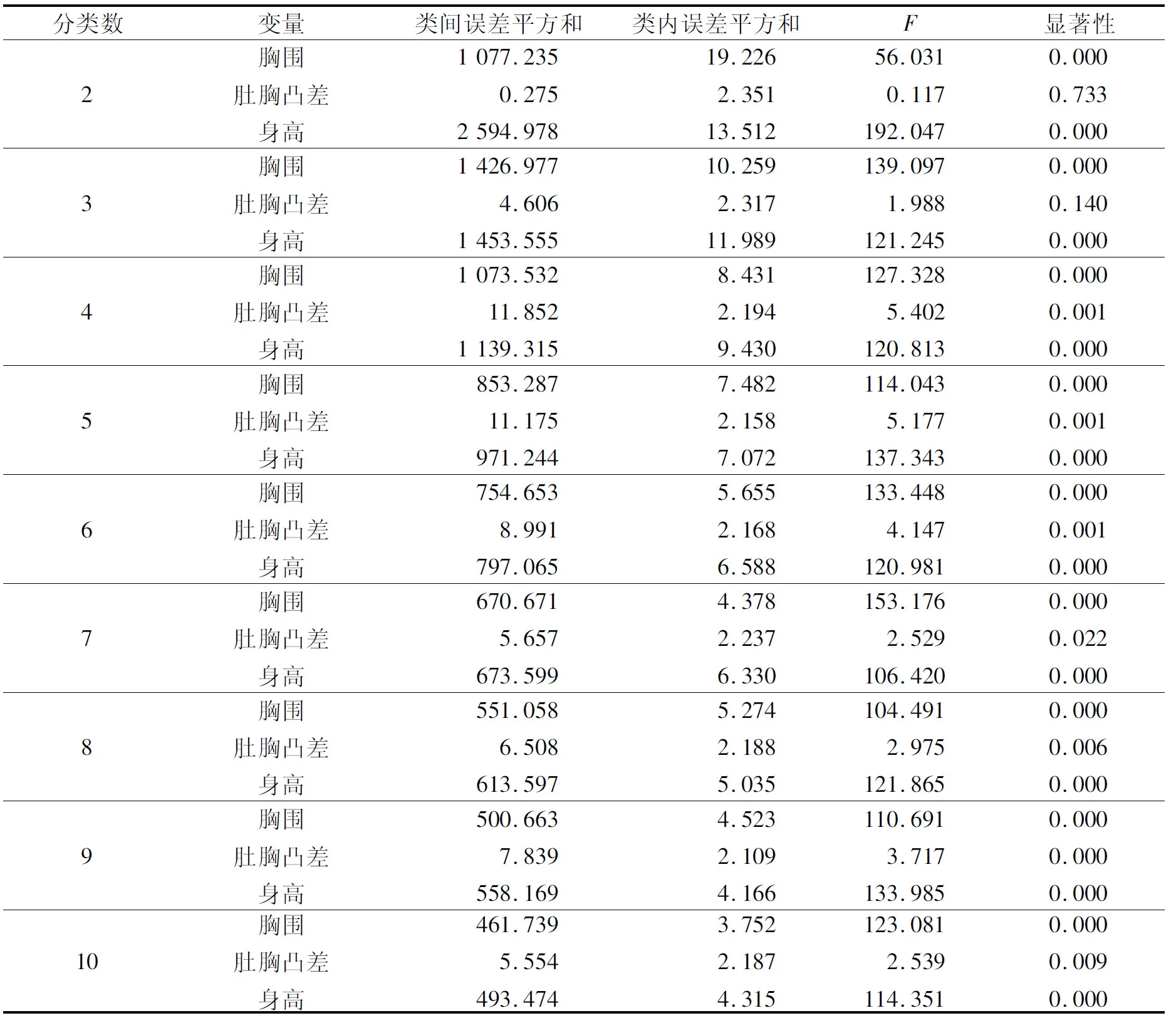
表7 方差分析Tab.7 Analysis of variance
采用胸围、肚胸凸差和身高3个指标对青年男性上半身体型进行分类,将199个样本分为4类。各项分类指标中心值及其案例数和占比见表8。由表8可知:第一类胸围最小,肚围最小,肚胸凸差较大,身高最矮,上半身体型呈现矮瘦圆台型;第二类胸围最大,肚围最大,肚胸凸差较小,身高较矮,上半身体型呈现矮胖圆台型;第三类胸围较大,肚围较大,肚胸凸差最小,身高最高,上半身体型呈现高胖圆台型;第四类胸围较小,肚围较小,肚胸凸差最大,身高较高,上半身呈现高瘦圆台型。由4类体型占比来看:第四类高瘦圆台型占比最大,为30.15%;第三类高胖圆台型占比最小,为21.61%。
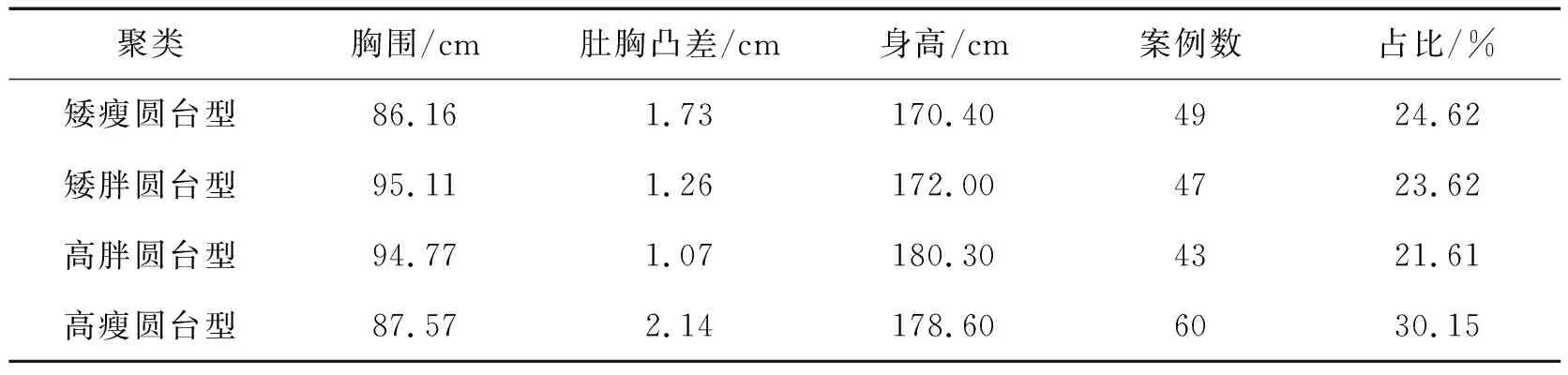
表8 分类结果Tab.8 Classification results
4 结语
使用因子分析提取出围度宽度因子、曲线因子、长度因子、上半身比例因子、肩部形态因子、袖长形态因子、胸腰差因子这7个反映青年男性上半身特征的公因子。采用权重分析方法,选取胸围、肚胸凸差和身高作为分类指标。通过方差分析,确定最佳分类数为4。运用K-means聚类分析法,将青年男性上半身体型分为矮瘦圆台型、矮胖圆台型、高胖圆台型和高瘦圆台型4种,各体型占比分别为24.62%、23.62%、21.61%和30.15%。其中,高瘦圆台型占比最高,高胖圆台型占比最低。该研究结论为企业进行青年男性上半身服装结构设计提供了有价值的参考。
猜你喜欢
中国医疗美容(2022年5期)2022-06-18 07:04:20
ELLE世界时装之苑(2022年2期)2022-02-14 18:21:41
卫星电视与宽带多媒体(2018年2期)2018-06-27 03:58:02
环球时报(2017-12-06)2017-12-06 06:46:15
中国新闻周刊(2016年33期)2016-10-27 17:56:42
系统工程与电子技术(2016年7期)2016-08-21 13:58:52
爱你(2015年17期)2015-11-17 10:06:17
浙江林业(2015年6期)2015-02-24 06:05:50
视野(2014年23期)2014-11-24 21:52:14
祝你幸福·午后版(2014年8期)2014-10-29 11:32:42
