
融合章节信息的信息技术教育试题推荐算法
2020-09-15 03:44张啸晨王华彬
安徽大学学报(自然科学版) 2020年5期
田 钰, 张啸晨,王华彬
(1.合肥市教育科学研究院 信息技术应用研究中心,安徽 合肥 230071; 2.安徽大学 计算机科学与技术学院,安徽 合肥 230039)
随着题库规模的不断增加,学生从海量试题中及时、准确地寻找到适合自身学习情况的试题越发困难.针对此种情况,云平台利用了个性化试题推荐系统给学生推送适合的题目[1].个性化推荐技术近年来发展迅速,它在电子商务、社交网络、风险评估和在线教育等行业展示了一定价值.
在教育个性化推荐领域,协同过滤(collaborative filtering,简称CF)技术不仅可以提高教学效果,还可以提高学生的学习自主性,使学生学习效率更高.该技术通过学习相似学生偏好特征从而得到目标学生的预测偏好.协同过滤技术中以记忆为基础的协同过滤依赖于较为完整的用户-项目评分矩阵完成预测[2].另一种以模型为基础的协同过滤技术[3],引入了隐因子的分解模型.
矩阵分解(matrix factorization,简称MF)是基于模型的协同过滤算法[4-5],当今国内外大型教育资源平台都会使用MF算法为用户提供个性化内容[5].在该算法中,学生对教学资源的评分信息用学生-资源评分矩阵表示,使用机器学习的方法,从该学生-资源评分矩阵中分解出学生和资源的潜因子特征向量(隐藏因子),再在潜因子特征空间(低维空间)上将学生和资源进行重表示,两者的低维向量内积代表了他们之间的关联性[6].非负矩阵分解推荐(nonnegative matrix factorization,简称NMF)被用来对非负矩阵进行多维分析,它与MF算法区别在于:NMF将学生-资源评分矩阵分解为两个潜因子矩阵相乘,评分矩阵里的每一项都不能为负数[7].奇异值分解算法在NMF的基础上,用奇异值涵盖了数据集的特征值,并且依据特征值的重要程度排序,忽略掉排名靠后的特征向量可以实现数据的降维[8-9].但奇异值分解(singular value decomposition,简称SVD)算法受到系统数据高稀疏性影响,容易造成过拟合,影响到推荐精度降低[10].而后SVD方法被Simon Funk改进,缩减了分解因子矩阵的个数,称之为Funk-SVD[11].LFM(latent factor model)潜因子模型在KDDCup[12]和Netflix[13]比赛中被证明比传统方法推荐精度更高.然而一般的推荐场景以及教育推荐系统中的数据有着高度稀疏和分布不均匀等性质,它们会降低算法在教育资源推荐中的精度[14].
为了消除数据稀疏和分布不均带来的影响,科研工作者在模型中引入了隐式外部信息.类似于在线视频教育网站上有学生的课程历史浏览记录和评论信息[15-16],利用这些信息能推测出学生间社交关联信息[17].该方法明显提高了系统推荐准确性.
1 相关工作
在电子教学和在线学习等领域,推荐系统被视为解决教育资源信息过载问题的一个方案,它担负着向学生推荐相关学习与教育资源的重要职责.论文通过所使用的技术的不同来对推荐系统进行分类,目前在在线教育和编程学习平台使用较多的推荐技术有:协同过滤推荐、上下文感知推荐(context-aware recommender,简称CA)以及基于知识推荐(knowledge-based recommender,简称KB)[18]等.
协同过滤(CF)是依据有相似兴趣的用户的决策来提供项目推荐.一种隐含的推测是假设用户在过往的选择中有相似的兴趣,他们在往后也将保持这种兴趣的相似性.依据用户评分、购买次数或者做题提交次数等,算法计算得到不同用户兴趣的相似度.基于此种规则,计算用户或者项目之间的相似度是CF算法的核心原则.图1展示了CF中的计算流程.
协同过滤可分成user-based和item-based两种技术[19].user-based技术应用在智慧教学云平台中,首先根据Jaccard相似度计算出两个学生之间学习进度或知识点掌握情况的相似度.设N(u)为学生u多次练习提交的试题集合,N(v)为学生v多次练习提交的试题集合,则Jaccard相似度为
(1)
根据Jaccard相似度计算得到学生做编程题的偏好相似度矩阵S,从该矩阵中找出目标学生u最相似的k个学生,用集合S(u,k) 表示.将S(u,k)中所有学生偏好多次练习的试题全部取出,并除去学生u的偏好多次练习的试题.对于每个候选试题i,学生u对它的偏好程度或学习愿望有下述表达式
(2)
其中:rvi表示学生v对试题i的学习愿望程度,这样就能计算出所有学生对题库里所有试题的偏好程度或学习愿望,将偏好学习程度排序后,取排名前列的试题推荐给学生便完成了user-based推荐过程.
item-based类似地会计算题库中题目被学生偏好并被学习的相似度矩阵,得到题库中所有试题被学生偏好学习的程度列表,再将试题推荐给列表中前列的学生.虽然协同过滤目前被广泛使用,但是新用户和新项目(新注册学生和新添加试题)问题仍降低了它的推荐精度.由于最初缺乏对新学生或试题的评分或者提交次数而无法得出精确的预测,协同过滤的其他缺点包括可伸缩性和数据稀疏性敏感问题,表现在智慧教学云平台中即某些试题只有很少的学生会去练习,所以这些试题几乎没有提交做题记录,这导致它们几乎难以被推荐系统预测评分.
在推荐系统中上下文指的是用来描述一个实体的信息[20].实体可以是与用户和应用程序之间的交互相关的人、对象或位置,它包括用户、算法或应用系统本身.在编程教育平台或在线学习网站的语境中,学生语境信息包括知识水平和学习目标.当学生获得更多的知识时,这些语境特征会随着学生知识掌握水平的变化而变化.在线学习或电子教育平台中的情境感知推荐系统分析学生所处的学习情境,向目标学生推荐学习和教育资源.在上下文感知场景中,预测评分的数学模型包含用户、项目和上下文的功能,有
R:User×Item×Context→Prediction,
其中:User和Item为用户集合和项目集合的域,Prediction为预测集合的域,Context为与推荐环节相关的上下文信息.上下文感知推荐系统中的评级矩阵样例如表1所示.

表1 上下文感知推荐系统中评级矩阵样例
将学生的语境信息融合到推荐算法过程中,能为具有相似兴趣或学习意向的学生提供更精确的学习教育资源推荐.在推荐过程中融入学生学习过程中产生的上下文信息,这种混合上下文情境感知的推荐系统能为学生提供更加个性化的教育资源推荐.但是CA依赖上下文信息,当数据稀疏度较大或冷启动等情况,预测精度不能保证.
KB是考虑用户偏好的领域内专业知识,利用其关联性向用户推荐项目[21].基于知识的推荐系统使用到了3类知识:用户知识、项目知识、项目与用户需求的匹配程度知识.依靠网络学习的背景、基于知识的算法将学生和学习资源的知识匹配融合应用于推荐过程.相较于协同过滤和基于内容的推荐,基于知识的推荐系统避免了快速/冷启动问题或评级稀疏问题,该算法的预测不依赖于评分记录而是利用专业领域知识.因此,以知识为基础的技术适合与其他推荐技术混合使用.
2 融合章节信息的矩阵分解算法
2.1 智慧教育平台
信息技术智慧教学云平台是一个能进行智慧编程教学的智能信息化系统,它支持多种人工智能编程语言来进行智慧教学.目前系统可以对用户提交的程序代码进行编译、链接、执行,最后将执行结果与数据库中存储的标准结果进行比较,从而判断程序的正确与否.
2.2 学生-题目提交次数矩阵
将学生对题目提交次数的数据计入数据集,构成学生-题目提交次数矩阵.矩阵由学生对每道题目的提交次数和未做过该题目的情况构成,样例如表2所示.

表2 学生-题目提交次数矩阵样例
若要求出推荐给学生的题目列表,首先需要对如表2所示数据做矩阵补全,之后对任意一个学生预测出所有未做过题目的提交次数,并按提交次数从高到低的顺序将对应的题目推荐给学生.传统SVD在做较大的矩阵分解时效率较低,而FunkSVD缩减了分解因子矩阵的个数,提高了算法性能.
2.3 FunkSVD
FunkSVD方法在应用于智慧教学云平台时,将学生-题目提交次数矩阵分解为学生和题目两个因子矩阵相乘.学生-题目提交次数矩阵中的真实提交次数与矩阵W(学生因子矩阵)和H(题目因子矩阵)的关系为
(3)

2.4 BiasSVD
BiasSVD[22]加入了平均评分μ、用户偏差bu与项目偏差bi信息,预测模型为
(4)
其中:μ为数据集里全部记录的评分算出的全局平均数,即训练数据集的总体评分概况;bu为用户偏置项,即用户的评分偏好中和物品无关的因子;-bi为物品偏置项,即物品受到的评分中和用户无关的因子.
2.5 SVD++
SVD++[23]算法在BiasSVD算法上做了增强,预测模型为
(5)

SVD++推荐系统中,除了用户对于项目的显式评分记录之外,用户的偏好可以从他的历史浏览记录、点赞、收藏等操作信息中间接反映.这些隐式反馈信息虽不代表该用户与该项目发生了直接互动,但可以从中得出该用户对这个项目产生了关注.然而编程试题推荐系统由于业务特征的原因很难得到上述的隐式反馈信息,所以作者利用编程知识章节信息替代传统外部隐式反馈信息.
2.6 融合章节信息的SVD++
一般情况下,学生对于做错或者不熟练的题目会多次提交,下次练习中同类型或相同章节题目会有更大概率被该学生选择.这种现象与电子商务、音乐和电影等领域的用户行为模式相类似.在电影、购物和音乐网站上,用户对喜欢的项目打分较高,不喜欢的项目打分相对较低.类似地,在信息技术智慧教学云平台上,学生对已经掌握的题目编写代码很少会出现问题,一次提交即可通过编译返回提示成功,这样该学生在该道题目上提交次数会较少;对掌握不牢固的题目,编写的代码存在问题,提交会被返回提示出错,需要学生数次修改并提交代码后才能修复问题,这种情况下该学生在该道题目上提交次数便会较多.因此,对于掌握牢固的知识点,该知识点包含的题目提交次数便会较少;对于掌握不好的知识点,该知识点包含的题目提交次数便会较多.
综上分析,编程试题推荐系统使用矩阵分解技术补全学生-题目提交次数矩阵,以此预测学生做题兴趣.但编程试题推荐系统与电子商务推荐系统业务属性存在差距,智慧教学云平台难以获得学生的社交信息或评价记录,传统外部信息不适用于编程试题推荐系统.所以论文在先前介绍的矩阵分解技术基础之上,为信息技术智慧教学云平台提高试题推荐效果,在SVD++模型的基础上,融合题目的章节信息,提出了融合试题章节信息的SVD++推荐算法.如图2所示,左边是推荐系统中经典的学生-试题二部图网络,如果学生对某道试题有提交记录,就会与该题目连接,学生掌握的潜在的知识点和试题章节信息矩阵显示在图2右侧.

图2 编程平台中学生掌握的潜在知识点和试题章节知识点的概念图
一般情况下,学生做完当前章节习题后,会按固有章节顺序去做下一章节题目,所以论文将章节映射的题号作为学生做题的隐式反馈加入模型偏置项中,得到预测评分公式
(6)

最小化目标函数为
(7)
其中:‖pu‖2和‖yj‖2分别为用户偏差矩阵和章节隐式反馈矩阵所有元素的平方和.
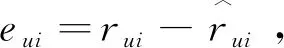
bu+γ·(eui-λ·bu)→bu,
(8)
bi+γ·(eui-λ·bi)→bi,
(9)
qi+γ·(eui·pu-λ·qi)→qi,
(10)
(11)
(12)
其中:γ为步长,λ为正则化参数.
2.7 引入编程语言隐含标签
MF方法根据隐因子找到学生的做题偏好并在智慧编程平台取得了良好的推荐效果,在实际场景中,还发现了一类隐因子,即学生和题目都有隐式的编程语言偏好.经过智慧编程平台的数据统计,在平时的训练和考试中,掌握不同编程语言的学生面对编程题目,总是优先会使用自己擅长的语言来解答,在选择做题时会潜在偏好选择适合自己强势编程语言的题目.有些题目也会被认为用某种编程语言来解答最为快捷,此种经验会在学生之间交流从而给该编程题潜在标记了某一编程语言的标签,即学生和题目都会有隐式的编程语言社团属性[24].在编程教育平台推荐系统MF方法里引入学生和题目的隐式编程语言标签相似度,可以提高该系统的推荐试题精度.下面给出推荐评分引入编程语言相似性权重(code similarity weight,简称CSW)的计算公式为
(13)
(14)
其中:式(13)中SVD_chapteru,i是引入章节信息的SVD++算法预测出的推荐分数;式(14)中kui表示学生u的编程语言书签向量和题目i的编程语言隐向量的余弦相似度(cosine similarity),其中书签向量表达为:学生或题目-平台编程语言的1行7列矩阵,学生擅长的编程语言或题目最常被使用解题的编程语言为1,学生不熟悉的编程语言或题目几乎不被使用解题的编程语言为0;μ是数据集样本里的均值;σ是范围内的标准差.
2.8 算法步骤
算法.基于SVD++的融合章节信息的协同过滤算法
输入: 学生-题目提交次数矩阵R
1. 通过R得到评分均值μ
2. 初始化偏置向量bu,bi.试题因子矩阵qi,用户因子矩阵pu和因子个数k
3. for eachuinRdo: 按用户id分组计算
4. for eachiinRdo:
5. while 误差err没有收敛 do
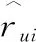
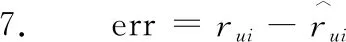
8. 按迭代公式(8)~(12)更新bu,bi,qi,pu,yj的值
9. end while
10. 根据公式(2)~(6)得到Kui,即是学生u的编程语言书签向量和题目i的编程语言隐向量的余弦相似度
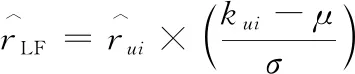
12. end for
13. end for
3 实验及结果分析
运行该次实验的计算机配置CPU为Intel Core-i3-8100-3.60GHz,内存大小为8G,搭载的操作系统为Windows10-64位.实验环境为:Python-3.7.1版本,使用的工具库包括:tensorflow-1.14.0,pandas-0.23.4,numpy-1.16.3.论文的实验数据来自信息技术智慧教学云平台数据库,从中抽取出了学生平时练习和多场竞赛考试的代码提交数据.该次实验调出了1 664个学生针对521道题目的共计24 556条做题记录.原始数据中因学生个人原因或网络延迟存在多次提交情况,导致提交次数字段数据明细偏离正常值范围,该实验对此做了规范化处理.设置提交次数范围为 1~10,1表示这道题提交过1次,10类似指提交了10次,超过10次的置为10次.数据集还包含题库信息,其中521道编程题目所属的章(chapter)和节(node) 数据,题库题目共含17章,每章均有1~4节不等.平均绝对偏差( mean absolute error,简称MAE) 和均方误差(root mean squared error,简称RMSE)作为论文衡量算法推荐精度的指标工具.MAE计算预测的学生编程试题提交次数与真实的学生提交次数的平均误差,通过误差大小衡量算法的推荐精度.MAE,RMSE的公式为
正则化参数和因子个数k是融合章节信息的SVD++算法的重要参数,对智慧教学云平台试题推荐精度有较大的影响.k值对MAE和RMSE值的影响如图3,4所示.从图3,4可以看出,在因子数等于15时,该模型效果最好.

图3 k值对MAE值影响 图4 k值对RMSE值影响
参数λ表示学生偏置项、试题偏置项和章节隐式反馈对编程平台推荐算法结果的作用.当λ设置为 0 时,该矩阵分解算法不考虑学生偏置项、编程试题偏置项和试题章节信息的反馈,只计算了学生和编程题的提交做题次数,如图5,6所示.

图5 λ值对MAE值影响 图6 λ值对RMSE值影响
由实验结果可知,当λ取0.015、步长γ取0.007而其他参数固定时,算法的MAE和RMSE值均取得了较低值.
论文分别在传统BiasSVD方法、传统基于相似性的协同过滤算法和融合了章节信息的SVD++算法上进行了实验,实验结果如表4所示.

表4 对比实验结果
在测试集/训练集分别为20%,30%和40%的比例下进行10次实验取平均值.实验先采用没有融合任何外部信息的BiasSVD方法和传统的基于相似性的协同过滤方法,得到不同测试集比例下的MAE和RMSE值;然后为验证融合外部章节信息方法和引入编程语言相似性权重方法的有效性,采用消融实验分别对传统的BiasSVD方法引入编程语言相似性权重、BiasSVD方法融合外部章节信息以及对融合了外部章节信息的SVD++方法引入编程语言相似性权重.3个实验分别独立验证SVD方法引入编程语言相似性权重、SVD方法融合外部编程章节信息以及这两种方法同时应用在编程教育推荐系统中的效果,如图7,8所示.从表4和图7,8中可以看出:(1)传统BiasSVD方法在引入了编程语言相似性权重后得到的MAE和RMSE值均有降低;(2)融合了外部章节信息的SVD++方法比传统的BiasSVD方法和基于相似性的协同过滤方法在MAE和RMSE值上有明显降低;(3)在基于融合外部章节信息的SVD++方法基础上引入编程语言相似性权重后,MAE和RMSE值进一步降低,证明了论文算法的有效性.

图7 测试集比例对MAE的影响 图8 测试集比例对RMSE的影响
4 结束语
通过研究云平台的习题推荐系统算法调优,提出了引入题目的章节知识点外部信息,融合到SVD++算法的正则项中.算法首先结合学生-题目提交次数数据建立LFM模型,进一步将章节信息融合到题目隐因子特征向量中,最后训练模型预测提交次数,将预测值高的题目列表推荐给学生.实验证明了融合编程章节知识点信息的SVD++推荐算法的合理性和可解释性.编程题目间存在知识点的前后序关联性,因此可以在后续工作中将知识图谱引入到推荐系统中,提高题目的推荐精度和可解释性.
猜你喜欢
中国新通信(2022年3期)2022-04-11
少先队活动(2021年2期)2021-03-29
汽车维修与保养(2021年8期)2021-02-16
学生天地(2020年17期)2020-08-25
数码世界(2020年3期)2020-04-07
数学大王·低年级(2020年3期)2020-03-12
福建基础教育研究(2019年11期)2019-05-28
数码世界(2018年2期)2018-12-21
科技与创新(2018年8期)2018-11-29
新高考·高三数学(2017年4期)2017-07-10
