
基于Pareto解集分段预测策略的动态多目标进化算法*
2020-09-03 11:21:38马永杰陈满丽
计算机工程与科学 2020年8期
马永杰,陈满丽,陈 敏
(西北师范大学物理与电子工程学院,甘肃 兰州 730070)
1 引言
现实世界中的许多优化问题都是多属性的,不仅具有多个目标、多个约束条件、高维决策变量,而且这些优化目标、约束条件、决策变量往往随时间变化,该类问题即为动态多目标优化问题DMOPs (Dynamic Multi-objective Optimization Problems)[1]。与动态单目标问题不同,它需要对相互冲突的子目标进行折衷,因此通常有多个最优解,即Pareto最优解集。
近年来,研究人员在静态多目标算法的基础上采用各种辅助策略,使其能快速地响应环境的改变。王洪峰等[2]总结了已有研究中的环境变化后的主要响应策略:
(1)增加种群的多样性[3,4]。如Deb等[3]提出的DNSGA(Dynamic Non-dominated Sort Genetic Algorithm)系列算法,通过随机引入部分个体的DNSGA-A和对其中部分个体进行变异的DNSGA-B,即为2种适应不同环境变化程度的动态多目标优化算法。
(2)将动态问题转化为静态问题[5,6]。如刘淳安等[5]利用微积分思想,对时间区间进行划分,将任意的动态多目标优化问题转化为静态多目标优化问题来处理。
(3)多种群的方法[7,8]。如张世文等[7]提出的基于生态策略的动态多目标优化算法,对精英集和非精英集采取不同的进化策略来响应环境的变化。
由于动态多目标优化问题中环境的变化有规律可循,近年来对于历史信息的利用受到了研究者的广泛重视,提出了基于记忆策略[9]、基于预测策略[10 - 13]、基于动态进化环境模型[14]、基于其它智能算法[15]的动态多目标优化算法。基于记忆的策略通过重复利用之前搜索到的Pareto解集来快速响应环境的变化,这对于周期性变化的环境能取得不错的效果,但对于环境非周期变化的问题效果不佳;基于预测的方法是当检测到环境发生变化时,利用历史信息预测新的初始种群,使种群快速响应环境的变化。
对于动态优化问题,其种群多样性关系到算法的搜索能力,而种群的收敛速度关系到能否及时响应环境的变化。若种群多样性过快丧失,那么由于种群中个体的相似性,会使种群过早地收敛,无法得到高质量的解集。因此,如何平衡种群的收敛速度和多样性,是该类算法能否成功的关键。由于动态优化问题最终得到的是Pareto最优解集,因此如何抽取有效的历史信息,并准确预测下一时刻的初始种群便成为预测策略的难点。为此,本文提出一种基于Pareto解集分段预测策略的动态多目标进化算法,通过所获得的历史信息对新环境下的种群进行分段预测,并在预测解集的周围自适应地产生随机个体,进一步提高预测的准确性。
2 问题描述
动态多目标优化问题一般描述为:
minF(x,t)=(f1(x,t),f2(x,t),…,fm(x,t))
(1)
s.t.g(x,t)≤0,h(x,t)=0,x∈[L,V]
(2)
其中,t为时间变量,x=(x1,x2,…,xn)是n维变量,L=(l1,l2,…,ln),V=(v1,v2,…,vn)是搜索空间的上下边界,g(x,t)和h(x,t)分别为不等式约束和等式约束,有m个目标函数f(x,t)并随时间变化。
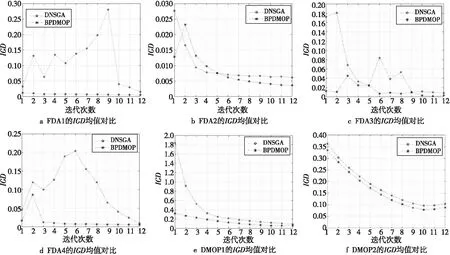
设x和y为种群中任意2个不同的个体,若满足对所有的子目标均有x不比y差,即fk(x,t)≤fk(y,t),k=1,2,…,m,且至少存在一个子目标使x比y好,即∀j∈{1,2,…,m},使fj(x,t) 根据Pareto最优解集和Pareto最优前沿随时间变化的情况,DMOPs可以分为以下4类[1]: (1)Pareto最优解集随时间变化而Pareto最优前沿不随时间变化; (2)Pareto最优解集不随时间变化而Pareto最优前沿随时间变化; (3)Pareto最优解集和Pareto最优前沿都随时间变化; (4)Pareto最优解集和Pareto最优前沿都不随时间变化。 种群的收敛速度和多样性的维持是算法能否快速适应动态环境的关键。研究者的大量实验表明,利用种群进化的历史信息对最优解的潜在区域进行预测,对于提高种群收敛速度能取得令人满意的效果。分段预测策略相当于将种群分为多种群,进而通过多种群维持种群多样性。文献[16]的研究表明,多种群策略把种群划分成多个子种群,一部分用于进一步开发,跟踪当前的极值点,另一部分继续探索整个空间,寻找新的极值点,从而提升算法的搜索效率。通过多种群维持种群多样性的方式有助于探索有前景的搜索区域。 因此,本文提出了一种基于Pareto解集分段预测策略的动态多目标优化算法,该算法的预测机制发生在种群进化的整个过程中。当环境未发生变化的时候,通过预测策略插入若干引导个体,加快种群收敛速度;当环境发生变化的时候,由于多目标优化问题的特殊属性,得到了多个最优解,所以只需要抽取能反映Pareto最优前沿分布的特征点并进行预测。此外,为了进一步提高预测的准确性,采用分段预测策略,即在检测到环境发生变化后,将上一时刻所得到的Pareto解集按照任意一个子目标函数的函数值fj(x,t)进行排序,并按照函数值fj(x,t)的大小将Pareto解集均匀地分为3段;然后分别计算每一段Pareto解集中心点的移动方向,对每一段子集进行系统抽样得到Pareto前沿面的特征点;最后利用线性模型结合每个子集中心点移动方向分段预测下一代种群;同时,在预测的解集周围自适应地产生若干随机个体,以保持种群的多样性。 环境发生变化后,对Pareto解集进行预测的基础是使用大量的历史数据,然而,多目标优化问题得到的是Pareto最优解集,为了降低计算复杂度,需要抽取一些特征点近似描述Pareto最优前沿,那么如何抽取Pareto最优前沿中的特征点呢?彭星光等[17]提出了基于超块的Pareto解的选取方法,武燕等[18]提出了通过应用K-means求质心的方法抽取特征点,都取得了一定的效果,但也都相对较复杂。基于超块的抽取方法依赖于区间分度参数的取值,还需要计算Pareto解与超块顶端点的距离,计算复杂度较大;基于聚类求质心的方法,初始聚类中心的选择对聚类结果的影响很大且在K-means算法中K是事先给定的,这个K值是非常难以估计的,大多数情况下事先并不知道给定的数据集应该分成多少个类别才最合适。 基于以上分析,本文在目标空间利用系统抽样的方法抽取Pareto解集中的特征点。先将种群中的个体按目标函数fj(x,t)由小到大排列,并确定抽样间距k,然后在1~k随机选取一个整数i,以它作为起始单元的编号,逐个抽取样本单元,直至抽取到Pareto解的目标函数值fj(x,t)最大时为止。此外,为了确保抽取的解集更加宽广,保留边界点作为描述Pareto前沿的特征点。系统抽样实施起来相对简单且只有一个初始个体需要随机抽取,很容易得到一个在整个种群中分布均匀的子集。 李智勇等[19]提出了将Pareto解集分为PS图像的中心点和除中心点以外的所有点所形成的曲线。t时刻种群中心点定义为: (3) 因此,为了更精确地描述种群Pareto解集的移动方向,本文将种群中心点修改为: (4) 然而,Pareto解集在其目标函数空间中的表现形式并非是线性的,所以仅仅利用一个方向无法准确诠释整个种群的进化方向。因此,本文提出了在目标空间中进行分段预测的算法。 (5) 最后,对每段Pareto子集进行系统抽样得到Pareto前沿面的特征点,利用线性模型结合式(5)中所计算出的子集中心点移动方向分段预测下一代种群。 Zhou等[20]对比了二次回归模型(Quadratic Regression Model)、反向传播模型(Backpropagation Network Model)以及线性模型(Linear Model)在双目标测试函数上算法的反向代距离IGD(Inverted Generational Distance)值,其仿真实验表明,在动态环境中,线性模型比非线性模型更适合预测解集。刘若辰等[21]设计的基于预测策略的动态多目标免疫优化算法,其实验已经证明基于线性预测机制,不仅算法的复杂度低,且在动态环境中得到的解集对IGD的跟踪能力得到极大的增强。因此,为了降低预测的复杂度,本文选用线性模型进行预测[17,21]。 (6) 当环境未发生变化时,在每一代种群中插入若干引导个体,加快收敛速度。引导个体由式(7)产生: xiter+1=xiter+diter (7) 其中,iter为种群进化代数,diter为种群连续2代进化方向,可由式(8)计算获得: diter=citer-citer-1 (8) 其中 (9) PSiter为种群进化到第iter代得到的最优解集。 (10) 其中,random(a,b)函数返回一个a~b的随机数。li和vi分别是变量x第i维xi的最小值和最大值,i=1,2,…,n。 所要优化的问题越复杂,种群就越不容易收敛到最优解集;在相同的迭代次数下,问题越复杂时,得到的Pareto解集越少;动态优化问题收敛的难易程度不同,迭代得到的Pareto解集数量也不同,那么所抽取得到的特征点的数目也随之变化。因此,本文设计了自适应的多样性保持策略。种群进化过程中,种群规模保持不变。通过预测特征点产生的下一时刻解集越多,随机产生的用来维持种群多样性的个体就越少。此处,随机产生的个体由上一时刻种群经高斯变异产生,即: xt+1=gaussand(xt,δ) (11) 其中,xt为预测点,gaussand(xt,δ)产生以xt为均值、δ为方差的高斯随机数,δ用来控制邻域的大小。 为了保持种群规模,采用自适应的多样性保持策略,上一时刻种群经高斯变异产生新的随机个体。如果目标函数越难收敛,得到的最优解集越少,那么随机产生的个体就越多;目标函数越容易收敛,得到的最优解集越多,随机产生的个体就越少。 本文算法的伪代码如算法1所示。 算法1基于Pareto解集分段预测策略的多目标进化算法 if环境未变化then 插入引导个体xiter+1=xiter+diter else 边界检测; if种群规模减少then 高斯变异随机生成新个体xt+1=gaussand(xt,δ) endif endif 为了验证本文算法对于解决动态多目标优化问题的有效性,选取了FDA系列和DMOP系列测试函数对算法进行测试,并与著名的DNSGA系列算法进行比较。 动态多目标优化问题主要分为4类,本文主要研究前3种类型的动态变化,因此选用测试函数FDA1、FDA2、FDA3、FDA4、DMOP1、DMOP2。其中FDA1、FDA4属于第1类问题,FDA2、DMOP1属于第2类问题,FDA3、DMOP2属于第3类问题,能够较全面地测试本文算法的性能。 动态多目标优化算法的目标是在动态环境下尽可能地收敛到Pareto最优前沿PFt,同时需要保持解集多样性[13]。本文采用反向代距离IGD和收敛指标CM(Convergence Metric)作为评测指标。IGD是评价算法收敛速度和种群多样性性能的综合评价指标。理想的IGD值为0,IGD值越小,代表算法收敛速度越快,同时种群多样性越好。IGD的计算方式如下所示: (12) (13) 其中,PFt是t时刻真实的Pareto最优前沿中一组均匀分布的解集,Pt是t时刻种群进化得到的解集,fj(v,t),fj(u,t)为个体v和u的第j个目标值,d是v与u之间的最小欧氏距离。 为了进一步测试DMOEA的性能,Zhou等人[20]提出了一种改进的IGD评估指标MIGD(Modified Inverted Generational Distance): (14) 其中,T为一组离散的时间点。 CM是评价算法所得解集的收敛性的评价指标,表示该组近似Pareto最优解与真实Pareto最优前沿之间的距离。其值越小表示收敛能力越强。 若P*=(p1,p2,…,p3,…,p|P*|)是真正的Pareto最优前沿上的参考或目标点集合,A=(a1,a2,a3,…,a|A|)是算法获得的最终近似Pareto最优集,则ai∈A与P*的最小归一化欧氏距离为: i=1,2,…,|A|;j=1,2,…,|P*|} (15) (16) 将本文算法与DNSGA算法进行对比,都采用非劣排序遗传算法NSGA-Ⅱ作为框架。其中,种群规模为100*20,交叉概率为0.9,变异概率为0.1,交叉和变异的分布指数均为20。DNSGA算法在环境变化后随机产生20个个体。测试函数环境变化的幅度τT=10,环境变化频率nT=30,即算法运行30代环境变化一次。算法运行360代,共经历12个环境。对于每个测试问题2种算法独立运行50次。此外,本文算法中,当环境未发生变化时,在每一代种群中插入5个预测得到的引导个体,加快种群的收敛速度;当环境发生变化时,抽取Pareto最优解集特征点的抽样间距k设置为3,产生自适应随机个体的方差δ设为0.35[18]。 实验中,对2种算法运行后的每个环境所得的近似最优解集和最优前沿面进行记录,并选择其中6个不同环境的解集进行绘制。为了方便描述,记本文算法为BPDMOP。图1为BPDMOP和DNSGA算法对于6种测试函数在不同环境中求解得到的Pareto解集。由于多目标优化算法的随机性,所以每次运行多目标优化算法的效果都可能不同,即使对同一个问题进行优化,每次优化结果都可能存在着差异。因此,衡量实验效果优劣的指标必然是一个统计指标。图2和图3分别给出了BPDMOP和DNSGA算法独立运行50次、在12个不同的环境下测试函数所得到的IGD值和CM值。不同环境下算法独立运行50次的IGD和CM性能指标的均值如表1所示,其中加粗字体表示IGD均值和CM均值较小,说明对应算法具有较好的收敛性和多样性。 4.4.1 与DNSGA算法的性能比较 图1a、图1c、图1e、图1g、图1i、图1k分别是BPDMOP算法在FDA1、FDA2、FDA3、FDA4、DMOP1、DMOP2测试函数上得到的在不同环境下的最优前沿分布图,图1b、图1d、图1f、图1h、图1j、图1l分别是算法DNSGA在FDA1、FDA2、FDA3、FDA4、DMOP1、DMOP2测试函数上得到的在不同环境下的最优前沿分布图,F1和F2分别为函数值。从图1中可以看出,随着迭代次数的增加,2种算法在FDA1、FDA2、DMOP1上都能收敛到最优前沿,但对于FDA3、FDA4、DMOP2函数DNSGA算法几乎得不到最优解集。 对于第1类问题,随着时间的变化,Pareto最优解集发生变化,而Pareto最优前沿不变。从图1中可以看出,BPDMOP算法在第3个环境时就收敛到了最优解集,而且随着环境的变化,Pareto前沿逐渐接近理想Pareto前沿面,这是因为BPDMOP算法在环境变化后引入预测点集,从而使得算法能够快速搜索到Pareto最优解集的可能区域。而DNSGA算法对于FDA1函数,几乎在第8个环境时才收敛到最优解集,对于FDA4几乎收敛不到最优前沿,这是因为DNSGA算法虽然引入了若干随机个体,扩大了搜索空间,但是收敛所需时间较长,影响了算法的优化效果。如表2所示,对于FDA1和FDA4函数BPDMOP算法的IGD均值和CM均值都小于DNSGA算法的。 对于第2类问题,从图1c、图1d和图1i、图1j看出,2种算法对于FDA2和DMOP1函数所获得的解集基本相似,但对于DMOP1函数2种算法在第1个环境得到的解集都不太好,导致DMOP1函数的IGD均值和CM均值都较大。而对于FDA2,2种算法的IGD性能指标相差不大,且CM指标都相对较小,如表1所示。由于第2类问题FDA2函数的特殊属性即真实PS位置是不随时间的改变而变化的,当新环境到来时,继续在上一时刻的最优PS位置进行搜索可能会加速种群的收敛速度。因此,通过预测机制在上一时刻最优PS位置附近搜索新时刻的最优解集,可能需要更多次的迭代进化。 对于第3类问题,随着时间的变化,Pareto最优解集和Pareto最优前沿均发生了变化。从图1e、图1f和图1k、图1l可以看出,不同的环境下,BPDMOP算法获得的解集比DNSGA获得的解集都要好,并且能近似收敛到最优前沿,说明引入的预测机制奏效了。如表2所示,2种算法在FDA3上的CM均值比在FDA1和FDA2上的都大,说明第3类问题较第1类和第2类问题收敛更困难。综上所述,BPDMOP在6个测试函数上得到的解集相对于DNSGA获得的解集分布更均匀且更接近最优解集。图1和表1表明,本文算法引入的预测策略和自适应多样性保持策略是有效的,提高了算法对动态环境的适应能力。 4.4.2IGD性能评价 IGD表征算法获得种群的收敛性和分布性。为比较本文算法和DNSGA算法的性能,选择FDA1、FDA2、FDA3、FDA4、DMOP1、DMOP2 6个标准测试函数,分别对2种算法运行50次,并绘制了不同测试函数在12个环境下的IGD值对比图。如图2所示,对于FDA1、FDA3、FDA4、DMOP1、DMOP2函数,本文算法的IGD值都比DNSGA算法的小,且在12个不同的环境下,IGD值波动较小,说明本文算法相对稳定。对应于它们的解集分布图,本文算法所得到的解集更接近于最优解集,且分布更均匀。但是,对于FDA2,由于FDA2函数的特殊属性,本文算法在3个环境下的IGD值比DNSGA的大。从表1可以看出,对于DMOP1、DMOP2函数,2种算法在FDA2上的IGD均值和CM均值相对于其他测试函数都稍大一点,可能是DMOP系列测试函数相对于FDA系列更难收敛。 Figure 2 Comparison of IGD mean values of the two algorithms图2 2种算法的IGD均值对比 4.4.3MIGD性能评价 为了进一步测试算法的性能,采用MIGD指标和PPS(Population Prediction Strategy)[20]、FPS(Feed-forward Prediction Strategy)[22]算法进行了对比,测试函数F5~F7是Zhou等人[20]为测试PPS新提出的函数。测试结果如表2所示。 Table 2 Comparison of MIGD with PPS and FPS表2 与PPS,FPS算法的MIGD比较 从表2可以看出,PPS在F5和F6上具有明显的优势,BPDMOP在传统的测试函数上性能较好。 4.4.4CM性能评价 收敛度量CM表示算法所得近似Pareto最优解与真实Pareto最优前沿之间的距离。收敛度量值越小,表示收敛能力越强。为比较本文算法和DNSGA算法的性能,选用FDA1、FDA2、FDA3、FDA4、DMOP1、DMOP2 6个标准测试函数,2种算法独立运行50次,记录12个环境下的CM均值。如图3所示,对于第1类问题,其Pareto最优解集随时间变化而Pareto最优前沿不随时间变化,本文算法的CM值都接近于0,表明本文算法对于最优解集随时间变化而最优前沿不随时间变化的这一类型问题具有独特的优势。对于第2类问题,2种算法的CM值相差不大,且对于不同的环境,都相对稳定。但是,对于DMOP1函数2种算法的CM值稍大一点,说明DMOP1比FDA2难收敛到最优解集。对于第3类问题,2种算法的CM值比其他2类问题的CM值都大。可能是由于第3类问题的最优解集和最优前沿都随时间发生变化,收敛的难度较大,如表1所示。综上可以得到,在相同的实验条件下,BPDMOP算法对于解决动态问题更有效,种群收敛速度更快。 Figure 3 Comparison of CM mean values of the two algorithms图3 2种算法的CM均值对比 针对动态多目标优化问题的特点,本文提出了基于Pareto解集分段预测策略的动态多目标优化算法BPDMOP。通过利用历史信息进行最优解的预测,加快了种群的收敛速度并且提高了算法应对环境变化的能力。对于历史信息的提取,采用系统抽样的方法确保Pareto前沿分布的多样性,并采用分段预测,将解集分为3段进行预测,进一步减小预测误差。同时,采用自适应的多样性保持策略,提高了算法对动态环境的适应能力。本文将改进算法应用于NSGA2算法框架上,并通过FDA1~FDA4、DMOP1和DMOP2 6个标准测试函数,测试了不同环境下算法所得到的解集的收敛性和分布性,并和经典的DNSGA算法进行了比较。实验和分析结果表明,本文所提算法BPDMOP在应对动态多目标优化问题上具有一定的优势,能够有效求解动态多目标优化问题。 本文提出的改进算法能有效改善种群收敛的速度和多样性,但由于FDA系列问题的决策变量之间是线性相关的,本文的分段预测算法采用的是线性预测策略,在许多决策变量之间是非线性相关的问题上并不是很理想,无法适应更多种类的优化问题,这也是今后需要继续研究的内容。 随着社会和科技的发展,动态多目标优化必将得到更广泛的应用,但是由于动态多目标优化问题的研究尚处于理论研究阶段,如同文献[23]所述,在算法应用方面研究相对较少,因此如何结合实际生活中的动态多目标优化问题来设计算法也将是未来该领域的研究重点。3 分段预测算法
3.1 Pareto解集中特征点的抽取
3.2 种群移动方向的计算

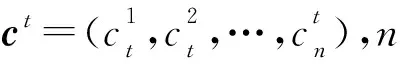
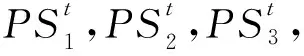
3.3 预测点集
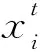


4 仿真实验结果及分析
4.1 测试函数
4.2 性能指标

4.3 参数设置
4.4 实验结果及分析


5 结束语
猜你喜欢
今日农业(2022年15期)2022-09-20 06:54:16
卫星应用(2022年7期)2022-09-05 02:36:02
卫星应用(2022年3期)2022-05-23 13:44:30
卫星应用(2022年1期)2022-03-09 06:22:20
环球慈善(2019年6期)2019-09-25 09:06:24
红土地(2018年7期)2018-09-26 03:07:38
物联网技术(2017年5期)2017-06-03 10:16:31
上海理工大学学报(2016年2期)2016-06-02 09:22:25
陕西理工大学学报(自然科学版)(2015年6期)2016-01-25 11:00:22
江苏高职教育(2014年2期)2014-07-16 07:10:04
