
基于深度迁移学习的肺结节分割方法
2020-08-06 08:29马金林马自萍
计算机应用 2020年7期
马金林,魏 萌,马自萍
(北方民族大学计算机科学与工程学院,银川 750021)
(*通信作者电子邮箱624160@163.com)
0 引言
肺癌是全世界发病率和死亡率最高的恶性肿瘤之一,但是肺癌的筛查和预防仍然存在很大的挑战。在进行肺癌诊断时,需要精确的肺结节数据来进行判断,影像科医生需要反复逐层地检查三维计算机断层扫描(Computed Tomography,CT)图像,来寻找肺结节区域,然后再对肺结节进行良恶性的诊断,因此CT图像中肺结节的分割是对肺癌进一步定量分析的关键。但是肺结节在CT 图像上表现为一种体积小、密度高,直径只有3~30 mm的阴影,给肺结节图像分割造成很大困难。
近年来,肺结节的分割方法有很多。常见的分割方法分为两类:基于传统的无监督分割方法[1]和基于机器学习的分割方法[2]。基于传统的无监督分割方法中常用方法包括形态学方法、阈值分割法、聚类法等。尽管这些方法既快速又简单,但是仍然存在诸如分割不足或者过度分割的问题。形态学方法[1]可以去除肺结节的边缘毛刺,但操作中涉及的参数不容易被控制。阈值分割法[2]在进行血管粘连性肺结节分割时效果并不理想。孙申申等[3]使用最大期望(Expectation-Maximization,EM)算法和均值漂移法提取肺结节,获得了较好效果,但是,对于附着结节的数量大于或等于2 的情况,该方法的分割效果并不理想。除此之外,其他的传统方法也有不足,如Armato等[4]提出的灰度阈值方法,虽然提高了分割精度,但是这种方法费时,受限并且使用不便;Kanazawa 等[5]使用模糊聚类算法提取肺和肺血管区域,但是丢失了3D空间特征信息;Miwa 等[6]提出一种称为变量N-Quoit 滤波器的算法,用于病理阴影候选者的自动识别,这种方法要求过多的手动操作,自动化程度低。
与传统的分割方法相比,基于机器学习的方法很明显地提高了分割性能,有效解决了肺结节辅助诊断的问题。但是,机器学习的方法需要人为确定代表性特征,这相当浪费时间和精力。另外,大多数基于机器学习的方法需要人工干预,这在很大程度上破坏了计算机辅助诊断(Computer Aided Diagnosis,CAD)系统的目的,并且为了获得最佳性能,大多数技术都需要大量的迭代和参数调整,这也减慢了整个计算过程。如Messay 等[7]提出了选择性回归神经网络(Recurrent Neural Network,RNN)的辅助诊断方法,具有全自动和半自动化选项。使用该方法进行的特征学习过程可以根据学习到的特征自动为每个结节设置参数。但这样的方法仅在特定类型的肺结节上(例如孤立性肺结节)或相对较小的数据集上表现良好,不能满足肺结节的多样性和复杂性。
近年来,深度学习在计算机视觉方面取得了长足的进步,这使得一些研究者尝试使用深度学习来解决肺结节检测的问题[8-9]。深度学习可以从训练数据中自动提取特征,与传统的精细分割方法相比,深度学习可以产生更少的错误判断。在深度学习领域,最开始的卷积网络末端都使用全连接层(Fully Connected layers,FC),因此最流行的分割方法就是补丁式方法,即逐像素地抽取周围像素对中心像素进行分类。随后卷积神经网络在医学图像处理上得到了很大的应用,但是在卷积和池化的过程中会丢失部分图像细节,并且最后只得到了一个一维的概率向量,尤其是在病灶的具体轮廓方面,深度卷积神经网络的效果不够理想,导致早期恶性结节诊断错误,不能及时地干预治疗,使得患者病情恶化加快。2014年,Long 等[10]提出全卷积神经网络(Fully Convolutional Network,FCN),实现了端到端的像素级预测,成为了生物医学图像分割的另一趋势。研究者们也快速地将全卷积网络应用到医学影像领域[11-13],全卷积网络在一些高强度的病变分割中均表现出了良好的性能。Ronneberger 等[13]在FCN 的基础上提出了针对医学图像分割的U-Net 网络。该网络更适用于小数据量生物医学图像数据处理,能够得到较好的分割结果。鉴于U-Net 在生物医学图像分割任务上的良好表现,在随后的几年内,U-Net 网络得到超过几千次的引用,并被广泛应用和改进[14-16]。Tong 等[14]将残差网络的思想引入U-Net 网络,提高肺结节的分割精度。Liu等[15]提出一种级联双路径残差网络的肺结节分割方法,分割精度略胜人类专家。张声超[16]提出基于U-Net 网络与全连接条件随机场的疑似肺结节检测算法,提高了肺结节的识别准确率。
深度学习描述了由多个处理层组成的计算模型,这些层主要学习不同级别数据的抽象表示。借助深度学习强大的特征提取功能,逐步替换基于机器学习方法人工定义的特征。总体来说,深度学习的方法在医学领域中表现出了巨大的潜力,这也加速了医学图像分析与辅助诊断领域的发展。
1 相关工作
目前,深度学习在医学图像处理领域还没有得到广泛应用,国内外专家在对肺结节早期定性诊断和治疗时,大多还是基于放射科医生逐层进行阅读,查看大量的CT图像容易使得医生疲劳,准确性也受限于医生的经验和职业能力等。因此及时有效地分割出肺结节,并进行诊断,是精准治疗肺癌的关键。然而由于医学训练数据的缺乏,神经网络仍然面临训练困难、容易拟合等问题;并且医学影像数据的标注需要专业知识并且成本昂贵,获得大规模标注的医学图像数据十分困难。因此神经网络有效地利用非常有限的医学数据,提高病灶分割结果,可以说是一项非常具有挑战性的任务。
全卷积神经网络(FCN),将末端的全连接层删除,实现了端到端的像素级预测,能够得到更加具体的分割边缘,减少了网络的学习时间。在此基础上,U-Net网络最早用作生物图像的分割。如图1 所示,为U-Net 网络结构,该网络主要是由卷积层、最大池化层、反卷积层以及ReLU 非线性激活函数组成。与FCN 相似,网络结构由收缩路径和扩张路径两部分组成,收缩路径用来获取上下文信息,扩张路径用来精确定位。与FCN 不同的是,U-Net 的编码部分与解码部分采用对称结构,并且使用skip-connection(跳跃连接)将编码与解码的特征图进行通道合并,这种操作将编码部分的特征图直接传递到解码部分,使得U-Net 在像素定位上更加准确,分割结果比FCN 更加精确,并且U-Net 网络更适用于小数据量的生物医学图像数据处理,能得到较好的分割结果,被研究者们大量应用。
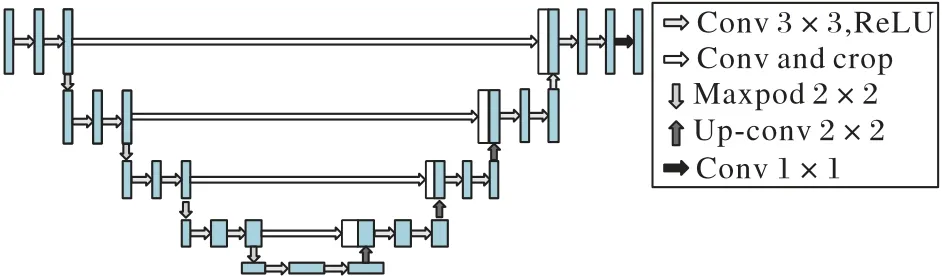
图1 U-Net网络结构Fig.1 Structure of U-Net network
迁移学习[17]是将源域学习到的成熟知识应用到其他场景。用神经网络的词语来表示,就是神经网络的节点权重从一个已经训练好的网络迁移到一个全新的网络,而不是为每个特定任务从头开始训练一个全新的神经网络。迁移学习可以较好地利用资源并且训练成本也相对较低,可以有效解决医学图像数据较少的问题。迁移学习可以具体定义为:给定源域Ds和目标域Dt以及它们各自对应的学习任务Ts和Tt,在实际任务中,一般会要求源域的规模大于目标域的规模,迁移学习的目标是利用Ds和目标域Dt的知识帮助提高在目标域Dt的预测函数ft(x)的学习效果,其中Ds≠Dt或者Ts≠Tt。Ds≠Dt代表源域与目标域的特征空间不同或者是特征的边缘概率分布不同;Ts≠Tt意味着样本标签空间不同或者是样本标签的条件分布不同,P(YS|XS) ≠P(YT|XT)。
根据迁移的对象和方法不同,将已有的迁移学习算法分为四种类型:实例迁移、特征迁移、模型迁移和对抗迁移。越来越多的研究者将迁移学习和深度学习相结合,并运用到各个领域。Oquab 等[18]反复使用卷积神经网络在ImageNet 数据集上训练的前几层来提取其他数据集图像的中间图像表征,卷积神经网络学习的图像表征可以有效迁移到其他训练数据量受限的视觉识别任务;杨涵方等[19]在跨领域图像分类中采用深度稀疏辨别迁移模型实现良好的分类性能;李浩波等[20]重新搭建了网络,但是进行微调以优化网络,选择最后的卷积块进行微调,而不是整个网络;李淼等[21]将深度学习和迁移学习结合进行农作物病害识别方法研究,将预训练模型的低层网络参数进行冻结,只对全连接层的参数重新进行训练和更新;徐胜舟等[22]将全卷积神经网络和迁移学习结合进行乳腺肿块图像分割,分割效果明显优于传统的分割算法。总体而言,迁移学习在深度学习中具有巨大的潜力。
在近几年,基于迁移学习策略的医学图像处理主要是两类[23]:第一类是将预训练卷积神经网络作为特征生成器,如褚晶辉等[24]利用迁移学习和深度学习进行乳腺肿瘤诊断,则是利用MRI(Magnetic Resonance Imaging)数据集对网络进行微调;第二类是将目标域数据集用来微调整个网络,如Shin等[25]将迁移学习微调网络应用于两个特定的CAD 分类任务,并在腹腔淋巴结(Lymph Node,LN)中取得了当前一流的诊断结果,表明迁移学习微调可用于医学影像任务高性能CAD 系统的设计。Tajbakhshn 等[23]也充分证明了从自然图像到医学图像的迁移是可行的,尽管源域和目标域之间存在相对较大的差异,并且在医学图像小样本的情况下,结合迁移学习的神经网络要比传统神经网络具有更好的泛化性和鲁棒性。
肺结节分割有助于肺癌筛查与治疗,但是迁移学习在肺结节分割上没有针对性的实例,并且对于肺结节这种特定的应用,无论是“浅层微调”还是“深层微调”都不一定是最佳选择。因此本文将U-Net 网络和迁移学习相结合,进行小数据集的肺结节分割,为了进一步提高分割精度、改进经典U-Net网络对小目标的分割效果,本文提出一种分块式叠加微调(Block Superimposed Fine-Tuning,BSFT)策略进行辅助诊断,并主要讨论肺结节小数据在迁移学习策略中如何微调,通过对VGG-16 网络(Visual Geometry Group Network)[26]、ResNet34网络(Residual Network)[27]、InceptionV3[28]和Densenet[29]四个神经网络的迁移学习,在敏感性、特异性和Dice 值等方面取得了很好的效果。
2 本文算法
针对小数据集医学图像存在的分割困难问题,本文利用迁移学习的方法,用VGG-16 在大数据量、粗粒度的自然图像上学习特征知识、拟合网络参数,然后将特征信息迁移至小标签样本、细粒度的肺结节图像分割任务上。具体方法为:从源域大数据集中学习特征知识进而转换为权重参数,然后在目标域的学习任务中共享模型结构和先验参数,即预训练网络。在网络搭建完成后,将预训练的权重迁移到新的网络结构的对应部分,通过在肺结节数据集上预训练新网络的权重,训练性能达到最佳时停止训练。
2.1 网络结构
本文采用U-Net 网络进行分割,它由进行下采样的编码器和上采样的解码器组成,选用VGG-16 作为U-Net 网络的编码器进行下采样,由于VGG-16 的全连接层与具体数据集密切相关,每一个输出节点都对应一个特定任务,为了符合本文网络结构要求,需要删除VGG-16 的全连接层,使用两倍于特征图大小的转置卷积,并减少一半通道数量,将卷积输出叠加到编码器的输出部分形成新的网络结构。将VGG-16 在ImageNet自然图像上学习的特征转换为权重参数作为本文模型的先验参数。图2 显示了本文的网络结构,图中上半部分是VGG-16 预训练网络,经过参数迁移后,得到下半部分网络结构。
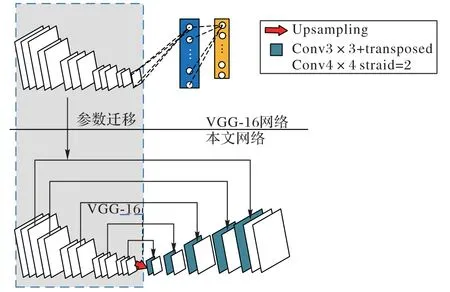
图2 肺结节分割迁移学习网络结构Fig.2 Transfer learning network structure for pulmonary nodule segmentation
2.2 分块式叠加微调策略
大规模准确的标注数据集对神经网络学习到准确、可泛化的特征至关重要,ImageNet 包含了1 000 类,1 000 万张自然图片,为深度神经网络在自然图像上的发展提供了强有力的支持。而本文所研究的肺结节数据集大小只有1 000张左右,不足ImageNet 万分之一,难以满足从零开始训练网络。这就造成利用迁移学习在医学小数据上出现训练困难、容易过拟合等问题,无法达到高要求的医学精准诊断的要求,迁移学习的效果也很差。本文将ImageNet自然图像数据集上学习的特征作为先验知识,迁移到较小的肺结节数据集上,提升其分割任务的性能。但是在ImageNet数据集中图像均为二维彩色图像,与医学图像(二维、三维和非彩色)相差很大,网络难以通过先验知识准确学习医学图像的特征,导致图像分割准确率下降。因此需要将网络在肺结节数据集上再次进行训练,使网络能够根据样本自适应地调整网络参数,提高医学图像对病理的语义概括能力,这个过程称之为网络微调。
传统的迁移学习微调策略存在两个重要的因素:目标域数据集的大小以及源域与目标域之间的相似性,微调策略遵循四个原则:1)目标域小且和源域相似,不进行微调,以防进行过拟合;2)目标域较大并与源域相似时,对整个网络进行微调;3)目标域较小且不相似时,对低层进行微调;4)目标域较大且和源域不相似时,随意训练。原则3)适用于本文的小数据集医学图像。但是这样的微调原则,使得传统的迁移学习很难在训练层和冻结层之间达到很好的平衡,没有进一步研究当目标域较小或是目标域和源域之间相似度很低时提取到的特征会如何变化,即网络微调的有效深度。本文肺结节的数据规模较小,一般不能微调太多网络层,可能会导致梯度消失或者过拟合;并且ImageNet 自然图像与肺结节的数据集相似度很低,如果仅停留在模型表面,即在低层进行微调可能使网络无法提取肺结节特征,不能学习到有用的特征信息,表达性能也很差,导致分割效果下降。利用传统的迁移学习策略很难得到一个最佳的网络,也就是网络微调的有效深度。
因此本文基于传统迁移学习微调策略存在的问题以及网络低层次特征知识具有普遍性的特点,在迁移学习的基础上提出一种分块式叠加微调策略。如表1 所示,VGG-16中有5个下采样层,为了搭建对应的U-Net 网络,解码器中也应有5个上采样层与之匹配,即需要进行5 次分块式叠加策略。作为编码器的VGG-16 网络结构中:多次使用相同大小的卷积核来提取更加复杂和更具有表达性的特征,这样也加强了网络的特征学习能力,减少了参数量。因此本文算法中,将得到相同大小特征图的卷积层归为同一个块,如在VGG-16 网络中,在进行了两次3×3卷积和一次最大池化以后,得到的特征图大小为256×256,所以将池化层前面的这两层卷积分成一块。表1中,Maxpool5 之前的所有网络层即为VGG-16 在ImageNet上进行预训练的权重迁移到新网络的部分。
迁移学习后,需要在肺结节数据集上采用分块式叠加微调策略,对网络进行自适应参数调整,以提高网络的语义概括能力。如图3 所示,为本文的训练过程,首先随机初始化新网络,在网络具有良好的分割能力上,逐块释放卷积层并微调可训练层,本文采用A-E方式进行5次网络微调,其中,方式A表示新网络的所有层初始化之后,释放Block5 块,冻结Block1~Block4(参数固定不变),训练网络参数;方式B-E,也以相同的方式,进行卷积块释放和冻结,参数训练,微调网络结构如图4 所示。微调过程中,定量分析各卷积块Dice 值的变化,来确定微调的有效块(网络的有效层数),训练性能达到最佳时,停止训练,保存网络结构,选取最佳诊断网络。
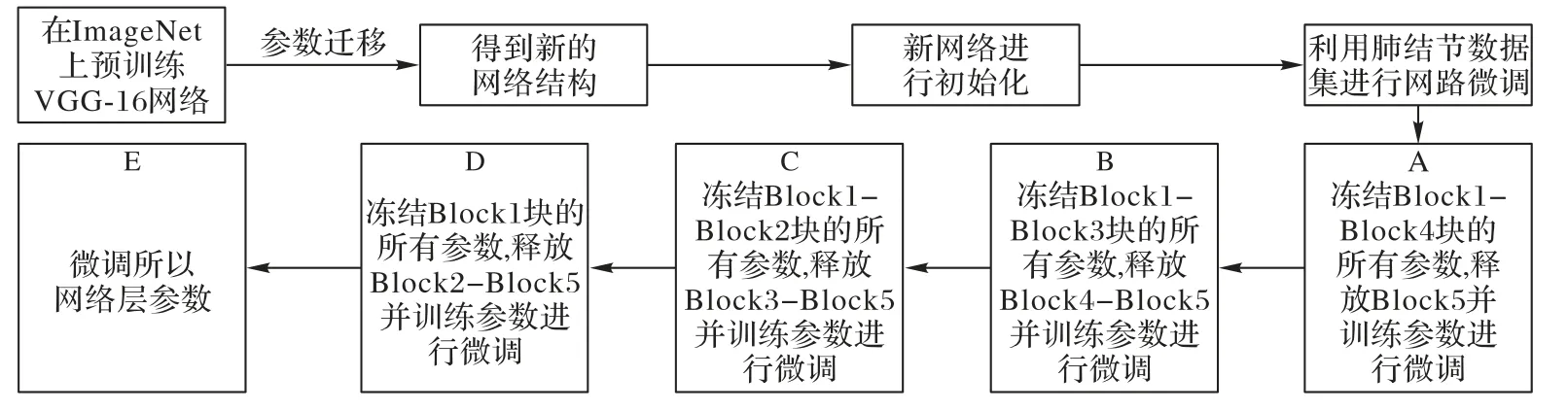
图3 微调策略流程Fig.3 Flowchart of fine-tuning strategy
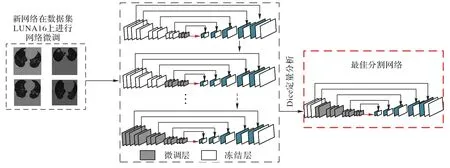
图4 分块叠加式微调策略网络结构Fig.4 Network structure of block superimposed fine-tuning strategy

表1 VGG-16网络以及对应本文的分块参数Tab.1 VGG-16 networks and corresponding block parameters in this paper
网络训练的源域为ImageNet,训练采用适应性矩估计(Adaptive moment estimation,Adam)[30]为优化函数,其默认参数遵循原论文中提供的值。本文中将不进行训练的参数称为冻结,即学习率为0,而释放即是网络中的参数从不可训练转换成可以训练。
Adam 解决非凸优化问题,能够基于训练数据调整更新神经网络的权重。Adam 方法利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率,适用于解决含有噪声或梯度稀疏的非稳态问题。
3 实验
3.1 数据集
本文选用LUNA16作为数据集,该数据集由888幅含多个512×512 切片的三维肺部图像组成,共有1 186 个结节,结节多为平均直径8.31 mm 的小结节。由于医学图像中CT 值与一般图像的像素是不同的,为了对数据集进行可视化,需要对一个二维的CT 矩阵进行预处理与归一化,即将CT 值过大或者过小的数值设置为0,并归一化得到图像矩阵。图5 将LUNA16的数据集进行可视化,并标出肺结节位置。
LUNA16 数据集提供了掩膜,用来剔除与肺部无关的区域,获得肺实质区域,如图6所示。
CT 图像为mhd 格式,用csv 文件标记肺结节的大小和位置。如表2 所示,seriesuid 是患者的标签,CoordX,CoordY 和CoordZ 为肺结节中心的坐标信息,diameter_mm 是肺结节半径,单位为mm。通过肺结节中心确定肺结节标签,如图7 所示,(a)和(b)分别为输入图像和标签,白色方框区域为肺结节位置。
在888 例患者中,标记了1 186 个肺结节。本文将数据集按8∶1∶1 的比例随机分为训练集、验证集和测试集,大小分别为949,110和127。
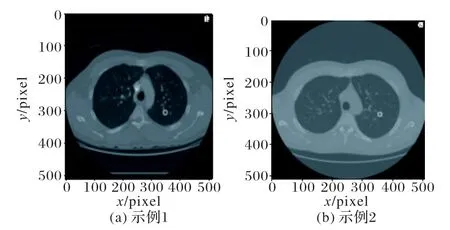
图5 LUNA16数据集图像示例Fig.5 LUNA16 dataset image examples

图6 肺实质提取示意图Fig.6 Schematic diagrams of lung parenchyma extraction

表2 肺结节标识信息Tab.2 Identification information of pulmonary nodules
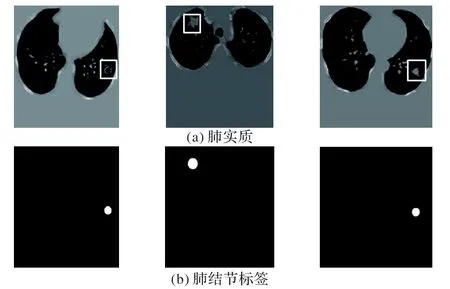
图7 网络输入图像示例Fig.7 Network input image examples
3.2 实验设置
本文使用Keras 与Tensorflow 实现,训练循环次数epoch为200,batch size 为2,卷积层的激活函数选择ReLU,学习率设置为1E-4。为了更客观、全面地评估算法的诊断性能,本文使用敏感度(Sensitivity)、特异性(Specificity)、Dice 相似度系数(Dice similarity coefficient,DSC)3 个度量指标对网络性能进行评价,并将Dice 相似度系数作为与其他肺结节分割方法的主要评价指标,其值越大,两幅图像越相似,分割效果越准确。本文中的肺部图像分割主要是对结节区域的关注,所以衡量算法性能时,仅计算病灶区域的Dice 系数。敏感度、特异性和Dice值如下:


其中:TN(True Negative)、TP(True Positive)、FN(False Positive)、FP(False Negative)分别代表真阳性、真阴性、假阳性、假阴性数量;X为分割结果,Y为实际数据集标签。
3.3 实验结果分析
3.3.1 分块叠加策略性能
表3 显示了分块叠加微调策略下,各个Block 的敏感度、特异性和Dice值。
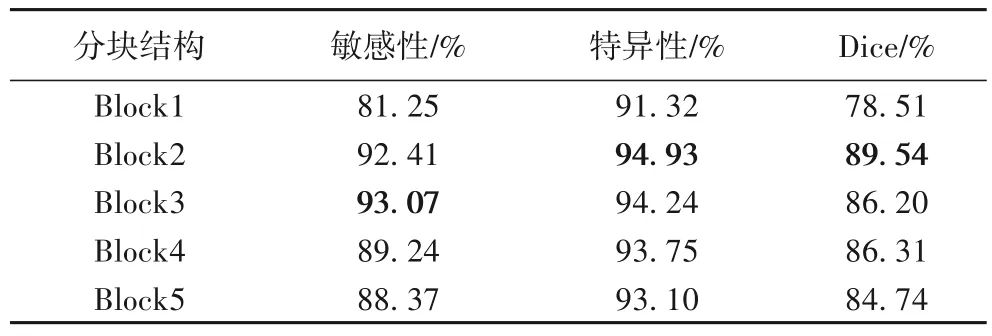
表3 分块策略性能比较Tab.3 Performance comparison of block strategies
由表3 可见,当分块叠加微调到Block2时网络最佳,即在冻结Block1 的基础上,使得网络(Block2~Block5)高层次特征知识针对肺结节病例特征自适应调整:一方面能够有效缓解肺结节小数据集带来的过拟合;另一方面可以避免因为迁移学习再次训练所造成的特征表达性差的问题。因此Block2~Block5 为网络有效微调块,即(卷积层Conv4~Conv13),后继续训练Block1,会使其学习的普遍性特殊化,又难以从小数据集中学习到准确、可泛化的新特征,过度拟合导致网络诊断性能下降。
如图8 所示,采用本文所提出的分块式微调策略,但在网络进行初始化以后,从模型的第一个块开始进行微调,即冻结Block2~Block5,微调Block1。其余四个块也是相同的操作进行冻结和微调,直至微调完整个网络。与图4 相似,只是调整了微调顺序,因此整个网络结构图在此省略,仅给出微调Block1块的网络结构。
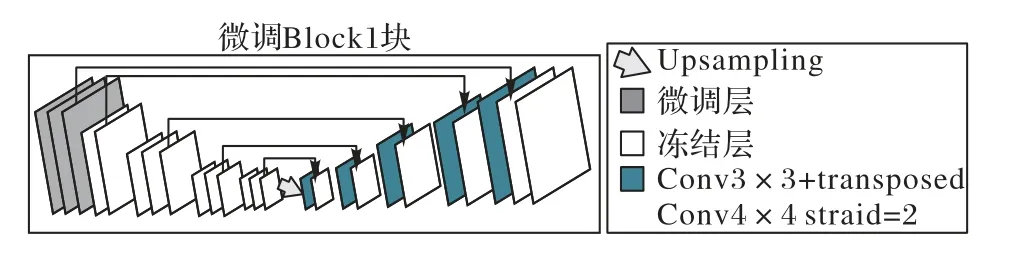
图8 微调Block1块网络结构Fig.8 Network structure of fine-tuned Block1
从第一个Block 块开始分块式微调过程中的Dice 值如图9 所示,在图中可以看到网络性能也是提升的,微调到Block5时,网络最佳,即需要微调整个网络;但从每个对应的Dice 值来看,普遍低于逐块释放微调策略的值,这是因为许多自然图像在进行训练时,低层卷积提取的特征具有普遍性,基本上是颜色、边缘等信息,不能学习到有用的特征信息,造成表达性能很差。卷积神经网络对图像的特征提取过程存在一个特征特殊化的过渡,一般到达高层才能学习到有用的信息。因此在实验中,不选择从低层开始微调的学习策略。
为了更好证明本文分块式微调策略的优越性,采用分层式叠加微调策略,主要分析Dice值,如表4所示。
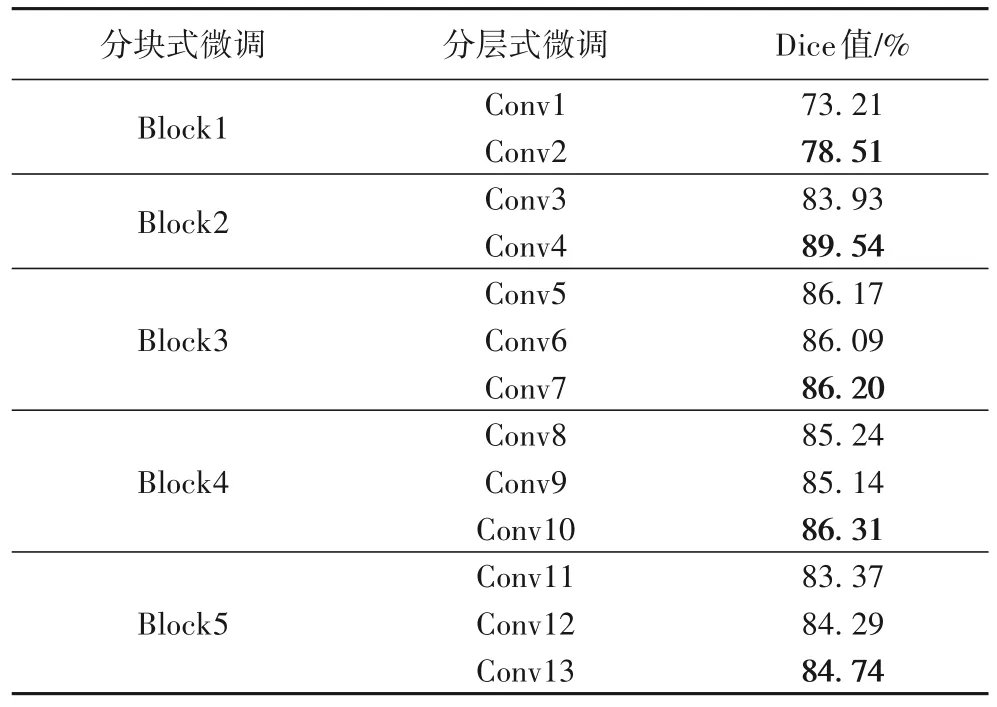
表4 分块式微调策略和分层式微调策略性能比较Tab.4 Performance comparison between block fine-tuning strategy and layered fine-tuning strategy
表4 显示了按照分层式微调策略的Dice 值,尽管在分层过程中性能也得到了提升,但是从表中可以看到,卷积层Conv2、Conv4、Conv7、Conv10 和Conv13 层为Dice 的几个较高的值,对应分块结构每一块中的最后一层卷积,当网络微调到Conv4 层时网络性能最佳,对应本文中最佳微调块Block2 的最后一层;并且在后续实验中,网络ResNet34、InceptionV3 和Densenet 层数较深,甚至达到上百层,若采用分层式微调策略,费时费力,并且每微调一层需要重新和与之对应的上采样特征进行拼接,再继续进行上采样和卷积,这样降低了运算速度。因此为了算法更加准确高效,也是根据网络结构因地制宜,本文提出的分块式叠加微调策略,可以更好地训练网络,得到网络的最佳的深度;并且分块式叠加策略不仅缓解了肺结节数据集过小造成的过拟合问题,并且也不会出现在迁移学习进行训练时由于训练的层数过少,而导致无法精确学习肺结节的病理特征。
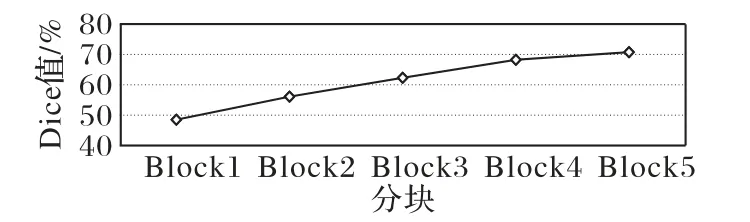
图9 分块式微调Dice图Fig.9 Dice diagram of block fine-tuning strategy
3.3.2 迁移策略对比
表5 显示了不同迁移学习策略下的性能指标,可见,相较于其他迁移学习策略的网络,分块式微调策略取得了较好的性能,有助于网络在肺结节小数据集中实现精准分割。
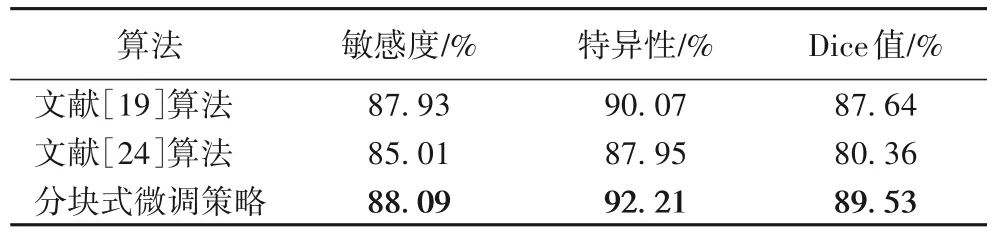
表5 不同学习策略性能比较Tab.5 Performance comparison of different learning strategies
在训练模型时,采用1-DSC作为Dice损失对模型参数进行微调训练。为了验证本文迁移学习策略优越性以及不同分块策略网络训练的稳定性,分析了微调策略变化下的Loss值,依次绘制了微调Block1~Block5块下的Loss变化趋势,并且对比了未引入迁移学习和经典U-Net网络的Loss变化,如图10所示。
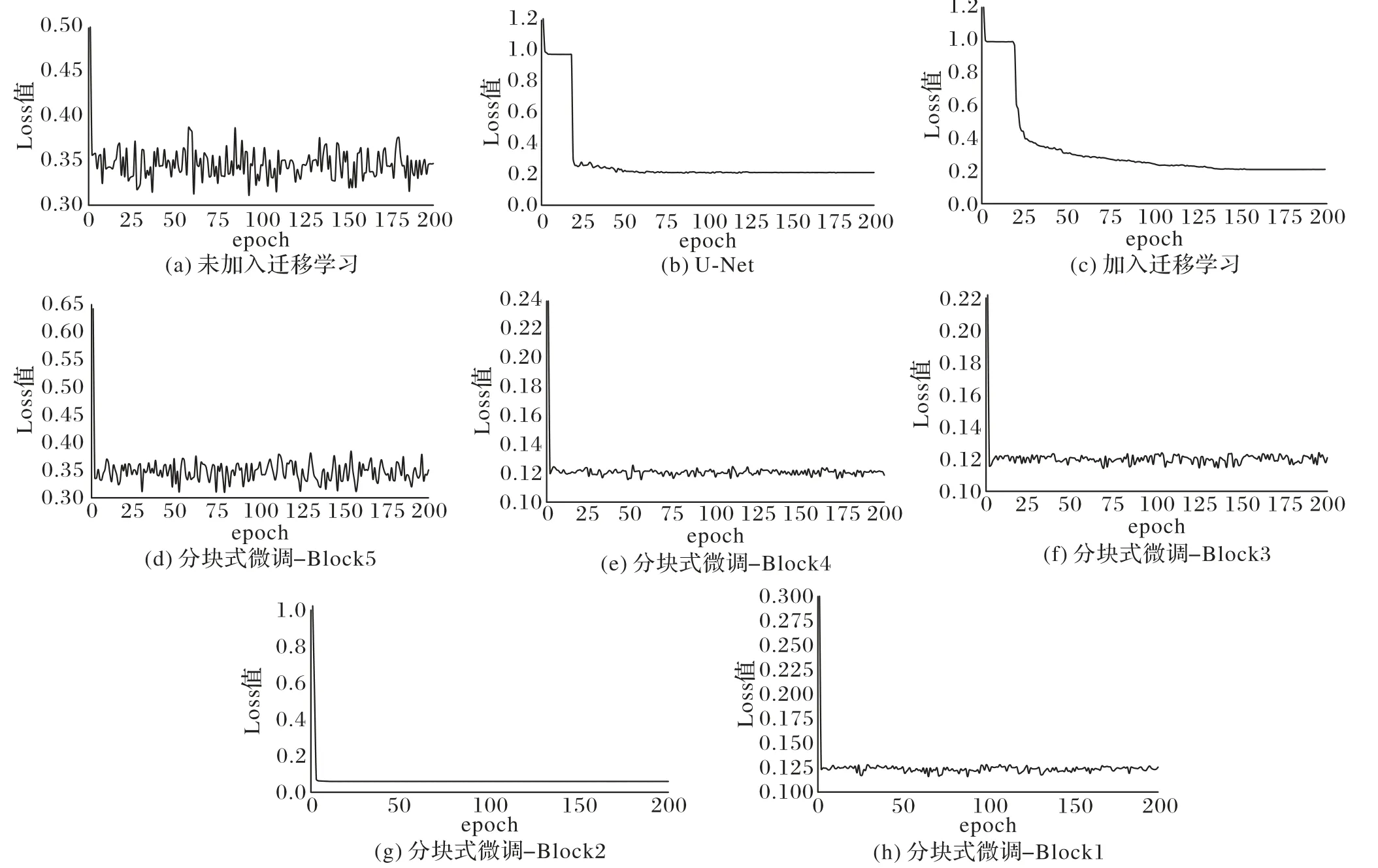
图10 本文分割方法与传统分割方法训练Loss对比Fig.10 Training Loss comparison between the proposed methods with traditional segmentation method
从图10 可以观察到,未进行迁移学习预训练的网络,即从头训练网络,有较大的Loss 值震动,模型的稳定性较差,分割精度低,如图(a)所示;在进行迁移学习后,网络性能明显更稳定、更优,如图(c)所示,并且网络性能要比经典的U-Net 网络(b)效果更好。虽然引入迁移学习,但是比起传统的冻结全部网络层进行微调策略,本文的方法更好地缓解了由于迁移学习的二次应用造成的特征表现能力差的问题,图(d)~(h)所示为本文提出的分块式微调策略的损失图,可以看出在冻结Block1,微调其余块时,网络性能达到最优,并且损失也到达最小,即图(g)所示,得到最有效的微调块,也有效提高了评估参数Dice的值。
3.3.3 肺结节分割方法对比
为进一步检测肺结节分割诊断方面的性能,利用分块式叠加微调策略对 VGG-16、ResNet34、InceptionV3 和Densenet121 网络模型实施微调,然后选取最佳分割网络。之后与其他基于深度学习算法的肺结节分割方法进行比较,同样以敏感度、特异性、Dice 值作为评估标准。表6 给出了不同方法的肺结节分割结果,由表可见,本文算法具有较强的特征提取能力,可以对网络进行有效微调。如表所示,Densenet121 的分割性能优于VGG-16、InceptionV3 和ResNet34,取得了89.00%的敏感度、94.89%的特异性和91.79%的Dice 值,较其他方法有较大的性能提升。由表6 可知,越深的网络模型取得越好的性能,这是因为深层网络可以提取肺结节的深层语义信息,泛化能力增强。
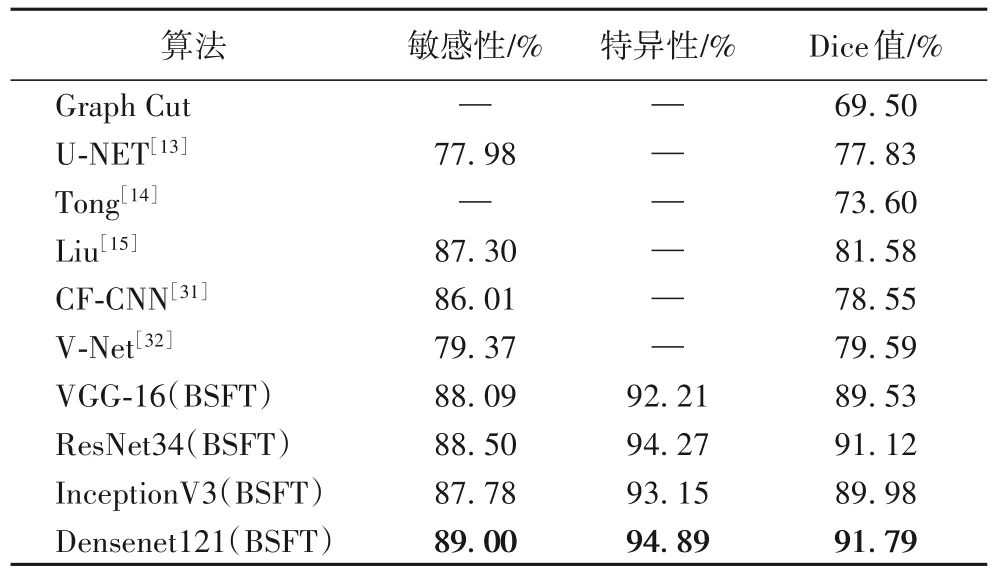
表6 不同肺结节分割方法性能比较Tab.6 Performance comparison of different segmentation methods for pulmonary nodules
图11 显示了利用分块策略的肺结节分割结果,(a)是原图像,图(b)~图(f)分别对应Block1~Block5 的分割结果,图(g)为手动分割结果。分块结果表明,深层网络可以提取更高的语义信息,有更强的局部抽象性,浅层网络的语义特征较低,所以本文也基于不改变低层次(Block1)的语义特征对深层次(Block2-Block5)的特征进行调整,得到最佳的微调网络块,更好地进行肺结节分割。
图12 显示了分别基于分块微调策略的Densenet121 网络和U-Net 网络进行肺结节分割的可视化结果。图(a)为原图像;图(b)为Densenet121(BSFT)方法分割结果;图(c)为利用ITK-SNAP软件将本文分割出的结果在原图像进行标记,以加深对预测结果的信任和理解;图(d)为U-Net 网络的分割结果。如第一、第三列所示,其肺结节的体积非常小,本文算法对于这种极小的肺结节进行了精准分割;而U-Net 网络的分割结果不够准确,在肺结节极小的情况下,U-Net 网络出现错误分割。

图11 分块微调策略分割结果对比Fig.11 Comparison of segmentation results of block fine-tuning strategies

图12 本文方法分割结果与U-Net网络分割结果对比Fig.12 Comparison of segmentation results by the proposed method and U-Net network
4 结语
针对深度网络在肺结节小数据集上分割精度低的问题,本文提出一种基于迁移学习的肺结节分割方法,首先改进了传统迁移学习微调整个网络导致分割结果不理想的问题,提出分块叠加微调策略(BSFT),该策略首先利用卷积神经网络学习ImageNet自然图像的特征信息,重新构建网络,将所学特征迁移到小数据集的肺结节图像上,接着逐块释放网络进行微调,直到网络完成最后一层叠加;最后通过定量分析,确定最佳分割网络。实验结果和对比实验表明,该方法在肺结节小数据集分割上,分割精度获得较大的提升。在以后的工作中,会对分割出的肺结节良恶性进一步判断,为医生提供更佳准确的辅助诊断。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
房地产导刊(2022年4期)2022-04-19
好日子(2021年8期)2021-11-04
乐器(2021年1期)2021-09-10
中老年保健(2021年6期)2021-08-24
中老年保健(2021年9期)2021-08-24
中老年保健(2021年9期)2021-08-24
计算机应用与软件(2020年5期)2020-05-16
新生代·下半月(2019年5期)2019-09-10
广西民族研究(2014年6期)2015-05-05
