
基于内容和语义的三维模型检索综述
2020-08-06 08:28裴焱栋顾克江
计算机应用 2020年7期
裴焱栋,顾克江
(1.南京理工大学计算机科学与工程学院,南京 210094;2.中石化华东石油工程有限公司,南京 210019)
(*通信作者电子邮箱jsflow@sina.com)
0 引言
目前人类对现实世界描述从一维的文本、声音,到二维的图像等信息,发展到了三维模型和三维场景的领域。三维模型技术是物体的多边形表示方法,是使用多媒体技术描述现实的三维世界的方式。三维模型描述的物体更直观,更符合人类的感知方式,可以提供更能满足人类视觉需要的信息。与其他计算机应用技术相似,三维模型技术也存在着模型查找和复用的需求。与耗费时间创造一个新的模型相比,检索并利用已有模型更具有效率。因此,近年来三维模型检索技术已成为多媒体技术领域一个新的研究热点[1]。
一般而言,三维模型检索首先需要对模型进行特征提取,然后对所提取的特征采用相似度匹配算法进行形状比较计算。检索系统的逻辑示意图如图1。这里的特征是指能够唯一确定模型的某种属性,如棱角、边等几何特征,或基于变换域的特征分量等。特征提取的结果一般是一个高维向量,或者一个图结构[2]。提取特征的算法称为特征提取子,特征的表示方式通常称作描述子。相似度计算与匹配过程是计算查询模型和各个待检索模型的特征空间距离并排序的过程,距离较近的一类模型被看作是相似的,而距离较远的一类模型被视作非相似的[3]。
早期的三维模型检索使用文本信息标注模型,通过检索文本实现模型检索。因为文本信息很难精确描述三维模型所包含的丰富内容,所以一种关注模型物理性质的数学表达的检索方法快速发展。这类方法关注对模型物理性状的描述和模型的特征空间匹配计算,被称为基于内容的三维模型检索技术[4]。常见模型形状包括几何特征(Geometric Properties)、视觉外观(Visual Shapes)、拓扑结构(Topological Structure)等方面。常用的空间距离度量方式有欧氏距离(Euclidean Distance)、曼哈顿距离(Manhattan Distance)、Hausdorff 距离、马氏距离(Mahalanobis Distance)等[5-7]。现实中,人类对物体的分类除了依赖于物理形状特征,还会综合考虑物体的内涵、功能等高级信息[8]。外形相似的模型可能属于不同的类别[9]。基于内容的检索技术无法提取这种特征信息,因此在检索效果的提高上遇到瓶颈。因为这些信息一般是语义学概念(Semantic Meaning)上的,所以该现象被称为语义鸿沟(Semantic Gap)[10-11]。因此,基于语义的三维模型检索技术开始成为热点,常见方法包括用户反馈、本体技术等。本文将分别介绍这两种检索技术。
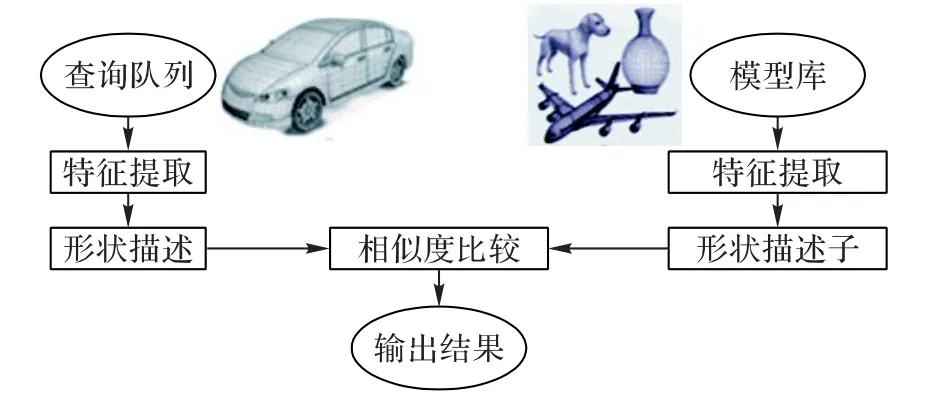
图1 三维模型检索系统逻辑示意图Fig.1 Logic diagram of 3D model retrieval system
1 基于内容的三维模型检索
基于内容的检索技术主要关注模型的物理性状,可供选择的物理性状特征很多。早期曾选择颜色、大小、材质等特征属性,并归档建库的方法进行模型检索[12]。该类方法对模型描述精准程度较为粗糙,检索结果错误率较高。提取的特征需要能充分描述模型的性状。目前,按照所提取的特征类型,基于内容的检索算法大致可分为4类:1)基于统计数据,将物理特征用统计学表示;2)基于几何外形,主要侧重外形的函数表达以及函数变换;3)基于拓扑结构,发掘模型的骨干以及模型不同部位的空间关系;4)基于视觉特征,研究模型的二维平面投影。
1.1 基于统计数据的检索方法
该类方法要求先对三维模型的特征进行取样,然后用直方图等统计方法存储、比较。常见的统计特征包括:距离、角度、法向量等[12],顶点的曲率分布[13]、各类数学矩[14]和数学变换的系数[15]等。早期学者研究了三种不同的直方图表示方法[16],分别为同心球格子划分(Shell Bins)、扇形格子划分(Sector Bins)和组合格子划分(Combine Bins),如图2。这三种方法对三维噪声有较好的鲁棒性,但对网格细分和网格简化的鲁棒性不足。李海生等[16]提出一种基于模型内二面角分布直方图的特征描述方法,对内二面角直方图统计特征进行了定义并对其性质进行探讨;Lian 等[17]提出基于模型表面关键点间测地距离的分布直方图特征(Geodesic Distances,GD);Pickup 等[18]提出基于模型表面积的分布直方图特征(Surface Area,SA)。张开兴等[19]提出一种基于模型内二面角分布直方图的非刚性三维模型检索,首先对内二面角直方图统计特征进行了定义并对其性质进行探讨;然后提出基于融合特征的非刚性三维模型检索算法。Schmitt 等[20]利用扫描得到的深度信息,估算得到厚度信息,然后建立联合直方图进行计算,该方法计算量较大。
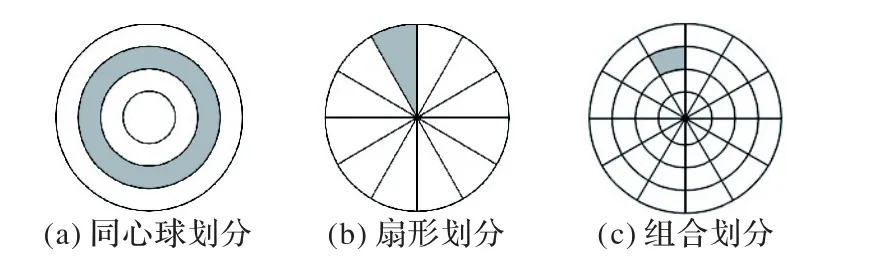
图2 三维模型空间分割方法Fig.2 Spatial segmentation methods of 3D model
高斯噪声干扰、网格简化等对模型表面有较大影响的变换时,直方图向量会发生较大变化,从而降低检索效率。
另一部分学者研究模型的几何矩表示,几何矩是模型的形状密度函数在核函数下的积分。几何矩系列算法要求在特征计算前对模型的二阶矩矩阵进行奇异值分解,保证三维模型有相同的方向。相应的,一些无需保证模型方向的算法出现了,如三维Zernike 矩[21]。Hosny[22]提出一种快速计算三维Legendre 矩的方法,利用对称性分析,采用加速算法,有效地减少了三维Legendre矩的计算量。文献[23]将仅能取整数阶的传统Zernike 矩推广为分数阶Zernike 矩,提出一种分数阶Zernike 矩构造算法。该算法可构造出比传统Zernike 矩重构性能好、抗噪性能强的分数阶Zernike 矩。文献[24]提出一种W-系统矩及其快速算法,通过计算体素模型的W-系统矩和物体运动不变量,提高了构造效率和检索准确率。
基于统计数据的检索方法对三维模型进行统计学分析计算完成对模型的匹配和检索,计算简单,对有较多噪声的模型有较强的适应性;缺点是对模型的描述较为粗糙,基于统计的特征之间相似性强度普遍较低[25],对局部特征描述不足,特征较为接近的模型区分准确度较低检索效果不够直观。
1.2 基于几何外形的检索方法
基于几何外形的特征提取子主要研究模型的几何外形和外形函数表达等特征,包含了表面特性的直观描述、球谐函数投影分解等多类方法。几何外形模型的高层信息具有完整的描述,一般会将模型建模的多面体表达方式转换为由若干个较小规模的元模型组合成的物体。根据对模型的几何外形的描述方法,该类算法也可以分成了若干子类,如网格化、体素描述、点云等。
文献[26]中,作者率先提出基于表面特征的算法,将模型的表面模糊拟合为微小的三角形平面集合,然后计算每个三角形面片的法向量(Normal)作为模型的特征。针对该算法,一般存在两种优化方向:一种优化策略以体积距离作为重点,文献[27]假设一个模型存在一个外接球(Bounding Sphere),然后计算模型表面和外接球的距离,用一个透视图(Penetration Map)记录映射模型到边界球而必须被压缩到一个面元中的面片数量[28];另一种优化策略关心模型表面的几何性质。文献[29]提出了一种基于希尔伯特曲线(Hilbert Scanning Distance,HSD)的方法,通过离散小波变换和人工神经网络进行体积扫描、降维。该方法的过程如图3。文献[30]通过核密度估计法和高斯变换计算局部面积特征和相应的组合。
直接对三维模型的外形进行描述有时相对复杂,文献[31]最早提出将模型转换为最相似物体的体积元素的表示(体素化)。体素化通过将三维形体表示进行一定的边界判断处理,产生体数据集(Volume Datasets)。体素集的形状逼近于体素化之前的表面形状。体素化在将三维形体表面信息有效保留的同时,也得到了形体内部特征信息,如图4。文献[32]使用基于空间结构圆描述子(Spatial Structure Circular Descriptor,SSCD)来获取空间值。体素精度和使用的分辨率有关,也和计算复杂度有关。模型的表面元素适用高精度、低规格的体素,而模型内部的元素可以使用较大规格的体素,以减少体素数量,降低计算量。文献[33]总结了自适应体素合并的算法,实验表明,经过自适应合并后的模型体素数量可以减少大约80%。近年来部分学者考虑引入深度学习的方法,将三维物体表征为一个二值或实值的三维张量,并以此为输入,构建各种三维卷积神经网络,已取得了非常好的分类效果[34-36]。只是这类表征方式存在高维、稀疏的特点,在一定程度上影响了对应网络的分类性能。在此之上使用多尺度方法可以一定程度上提高分类效果[37-38]。

图3 使用HSD的检索方法示意图Fig.3 Schematic diagram of retrieval method using HSD
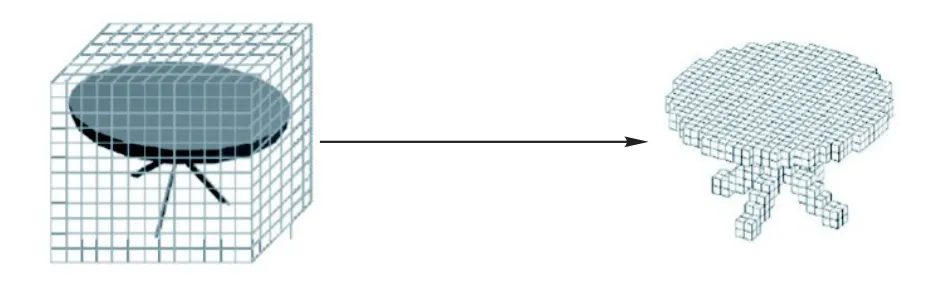
图4 三角网络模型的体素化表示Fig.4 Voxelization representation of triangular network model
另一种是基于球谐函数投影的几何形状的提取方法。球谐函数方法是傅里叶变换在球面坐标系上的拓展,在旋转不变性、效率和识别力方面有优势,因此成为三维模型特征提取的一种代表性方法。该方法最早由文献[39]中提出,作者使用两个球谐函数记录模型特征,随后用傅里叶变换得到球谐函数的系数作为特征向量。随后,研究者们对原方法进行优化,使用更复杂的变换或函数以增强效果,如修正球谐函数[40]、球谐熵函数[41]、椭球谐函数[42]等。在最近的研究中,研究人员进一步针对形状比较的效率问题进行了优化,如Wu等[43-44]利用球谐函数提取特征向量的低频分量表示,构建了一种简化的三维模型几何空间描述子,可用于三维几何形状的快速比较;此外,Wang 等[45]在傅立叶变换系统上引入了非负约束,通过采样方法极大简化了形状表示的过程。
随着雷达、激光扫描建模技术的成熟,近年来流行一种基于点云(Point Cloud)的检索方法,点云是指通过测量仪器得到的物体外观表面的点数据集合。目前在各类工程应用中,激光扫描仪等仪器极大提升了扫描精度,因此点云已成为非常普遍的建模辅助工具[46],也为三维模型检索提出了需求[47]。文献[48]使用基于低频球谐函数的点云编码方法,该方法结构紧凑,缓解了噪声带来的编码困难。文献[49]将形状空间描述为点云,而网格空间则通过黎曼度量[50]方式描述;基于这样的表示,通过测地线提出了一种对模型空间进行插值描述的方法。文献[51]提出了一种基于自适应收敛阈值的多视点云配准算法重建三维模型的框架,将迭代最近点(Iterative Closest Point,ICP)算法与运动平均算法相结合,实现了多视点云的配准。
基于几何外形的特征提取方法对模型的高层信息具有完整的描述,但是,大多数方法需要对三维模型进行转换,例如从多边形网格模型变换为体元网格模型,而且此类方法很难有效地直接提取网格模型的特征,所以计算复杂,转换速度较慢,并且需要大量的存储空间。
1.3 基于拓扑结构的检索算法
拓扑描述了模型空间组织的相互关系,提取三维模型的主要结构特征,与人类的感知方式较为一致,是一种相对高级的表示方法。该方法主要用于描述非刚体模型的特征提取,如人体模型。文献[52]提出了一个数据集,已被广泛使用。
文献[53]提出一种多分辨率的Reeb 图像,在不同的分辨层次上表征三维模型的拓扑结构,主要思想是把连通的且具有相同的连续函数μ 函数值的区域表示为一个节点,再将互连的节点连接起来形成Reeb 图。文献[54]提出一种快速的改进方案,使用计算其最大公共子图的变型来评估两个形状之间的部分相似性。Li等[55]提出一种混合形状描述方法来形成公共子图,集成了基于测地线距离的全局特征和基于曲率的局部特征。实践证明,多分辨率Reeb 图具有旋转无关性,对分辨尺度的改变具有鲁棒性,缺乏区分模型不同部位的能力。图5是一种有代表性的三维模型及其Reeb图像。
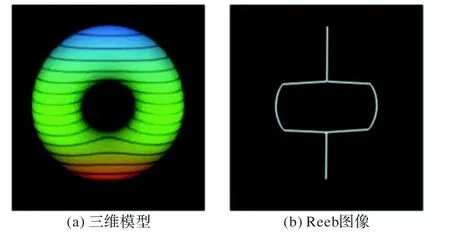
图5 利用高度函数的环面及其Reeb图Fig.5 Torus and Reeb graph using height function
另一部分研究尝试将模型表述为骨架图,以忽视外表面形状对模型检索的干扰。骨架体现了模型的形状特征和拓扑特征,模型的拓扑结构特征则由各个骨架枝之间的连接和层次关系来确定。文献[56]提出一种基于骨架填充率的检索方法,根据模型生成骨架,然后估算骨架的覆盖部分和骨架的比例关系。文献[57]根据模型的骨架端点间的路径进行匹配,文献[58]提出两层编码框架,提高形状匹配的效率,鲁棒性更好。文献[59]提出基于骨架树进行机械零件三维模型检索的方法,该算法骨架转换成骨架树并用邻接矩阵来描述骨架树的拓扑结构特征,如图6。骨架图可以提供比Reeb 图像算法更精准的局部比对,但缺点是骨架算法有较高的计算量,对模型噪声较为敏感。
对于大多数三维模型而言,计算提取三维模型的拓扑结构特征的资源耗费较大。基于拓扑结构的检索算法可以区分三维物体的主要结构和次要结构,在提取特征之前,必须进行一系列的模型归一化处理。但是目前仍然不能对三维物体进行快速准确的解构,而且解构过程对模型的噪声较为敏感。
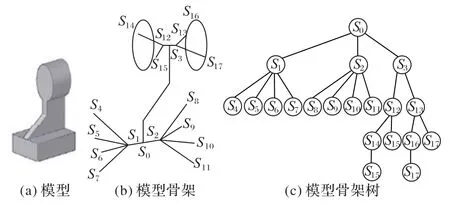
图6 模型、模型骨架图、模型骨架树Fig.6 Model,model skeleton diagram and model skeleton tree
1.4 基于视觉特征的检索算法
该类算法在特征提取时会将三维模型投影到二维平面,然后使用二维平面图形领域的技术对投影面进行处理。按照投影角度的数量划分,可以分为单方向的二维函数投影方法[60]和多视角二维视图投影方法[61]。二维函数投影方法认为若两个模型相似,那么从同一角度观察的表面形状、旋转投影[62]、切面形状[63]都应该是相似的,避免了多角度视图带来的计算复杂度问题。文献[63]还提到切面方向、切割函数等问题。多视角方法认为若两个模型相似,则不同视角观察到的影像也会是相似的,所以多视角二维视图投影需要从多个不同的角度对模型进行投影,从而得到一组投影图像,然后组合建模计算。该方法并不要求对两个模型的观察视角在方向或角度上一一对应。多视图会提升检索精度,但是也会增大计算复杂度。Gao 等[64]提出在正六面体上放置216 个虚拟摄像头的方法。Su 等[65]提出12 个视图的方法。文献[66]提到使用主成分分析(Principal Component Analysis,PCA)降低表示物体所必需的视图数量,同时解决PCA 修改后的轴对齐的问题。文献[67]提出LFD(Light Field Descriptor)方法,假设模型周围存在一个正12 面体,其20 个顶点上都存在视点,然后根据捕捉到的投影生成特征。文献[68]在LFD方法中引入深度图信息进行检索。针对LFD 的特征生成过程,学者们提出了一些有效的改进,如通过2D Zernike 矩[69]和傅里叶描述符[70]。文献[71]进行正交投影,从一组全局视角观察,然后使用傅立叶变换和二维离散小波变换来计算得到特征值。文献[72]使用基于模糊C-均值的自适应视图聚类和形状上下文进行检索。
全局特征关注整体,可以快速分类;而局部特征关注局部细节,适于精确区分,因此也有一些研究重点关注局部特征的投影。学者Lowe 提出一种不变阶特征转换(Scale-Invariant Feature Transform,SIFT)方法[73]。针对此方法,文献[74]提出一种具有局部特征旋转不变性的Volumetric-SIFT(V-SIFT),如图7。文献[75]基于投影图像的纹理,使用小波变换处理纹理图像的像素值得到特征值,该方法可以很好地避免图像分割过程中带来的误差影响。有研究引入加速特征袋的并行计算方法,将局部特征集成到整体特征向量中,但相应的计算复杂度很高[76]。
从三维模型得到二维投影是一种模糊的降维过程,会丢失表达精度。在一些应用场景中,用户也会输入二维图像搜索相似模型。因此近年来也有很多学者考虑根据二维图像还原构建三维模型,然后进行检索的方法,称为基于草图三维重建的检索方法。相较于其他三维模型检索方法,使用草图对三维模型进行检索具有简单、方便的优点。这类方法的输入是不包含三维深度信息的二维图像信息,可能是模型的草图,或只带有线条的简笔画[77],不一定是准确投影。根据输入的二维图像的数量,草图三维重建分为单视图输入和多视图输入[78]。文献[79]提出一种基于单张三维手绘草图的卷积神经网络(Convolutional Neural Networks,CNN)进行搜索,如图8。文献[80]提出一种基于多视角投影的复合卷积神经网络,且对相机位置没有约束。为了建立草图和模型之间的弱连接关系,文献[81]将模型的特征与草图特征一起整合成一个多金字塔层次的特征,并设计出相应的神经网络。基于三维草图重建的检索方法需要几何学的知识重建三维模型,计算复杂。

图7 基于面积描述的模型转换为基于体积描述的模型[74]Fig.7 Area based model transforming to volume based model[74]

图8 基于单张草图的卷积神经网络检索方法架构Fig.8 CNN retrieval method framework based on single sketch
基于视觉特征的特征提取和检索方法能够借助发展较为成熟的图像特征提取技术,降低了三维模型特征提取的复杂度,获得比较好的检索效率,另外对噪声的抗干扰能力强,拥有较好的鲁棒性。三维模型的投影过程会丢失一些关于物体的结构和空间信息。单方向的二维函数投影计算量最小,但也最容易丢失信息。多视角的投影组合后,会覆盖尽可能多的三维物体表面,所以可以尽可能地保留信息,但同时会增加计算量。
另外,投影得到二维图像之后,可以利用图像处理领域非常多的较为成熟的方法,目前非常流行的深度学习方法也因此被引入了进来。先将将三维模型表征为一组二维视图的集合,并以此为基础构建深度学习模型完成特征学习及模型分类。典型工作有:基于全景视图的DeepPano 算法[82]、基于几何图像的Geometry Image 算法[83]以及多视角下的卷积神经网络(Multi-View Convolutional Neural Network,MVCNN[84-86],MVCNN 模型过程如图9)、基于成对图像的Pairwise 算法[87]等。可以预见,还会有更多深度学习方法被引入到投影检索类方法中。
基于内容的三维模型检索方法面临很多挑战:1)提取出准确的特征仍然非常困难,而且特征的精度受旋转、大小、分辨率影响[88],因此很多时候需要将模型变换到一个正则坐标系中,变换过程仍然需要大量开销。2)三维模型的描述方法多种多样,对应特征种类很多,仍然没有一个简单有效的标准格式。大多数的检索算法只针对特定的描述和数据格式。某些场合下,某些描述特征对检索结果没有足够的影响,却会极大提升计算复杂度。3)随着技术的发展,新的模型构建技术快速出现,而针对这类技术的模型检索方法发展滞后。一个关键难点是如何有效地将新技术表达的模型转变为已知的、适用于已有的模型检索方法的格式[89]。在原有的分类方法之后,深度学习的工具被引入进来。深度学习的优点在于可以弱化特征选择过程影响,而且有较好的普适性。

图9 应用多视角卷积神经网络的3D模型识别过程Fig.9 Application of MVCNN to 3D model recognition process
2 基于语义的三维模型检索
基于内容的三维模型检索技术可以解决模型本身的形状相似性问题,提取的特征是对模型的物理形状的反映,无法反映模型得内涵意义,因此最终的检索结果仅能反映模型之间形状相匹配的特性,而无法反映该模型的本质特征。例如,一支铅笔和一根筷子外形上是相近的,但对用户而言,它们是相异的物体。这就是前文提到的“语义鸿沟”现象。为解决此问题,基于语义的三维模型检索技术产生并发展起来[8]。
在基于内容检索的基础上,基于语义检索技术同时利用了模型的语义知识,构建出一个三维的语义学习框架,其中,基于内容的特征称为低层特征(Low-Level),基于语义知识的特征称为高层特征(High-Level)[90]。主要解决方法有要求人机交互的相关反馈技术(Relevance Feedback)[91],利用统计学习理论获取语义的高级信息的主动学习技术(Active Learning)[92],面向特定领域、需要建立领域内规范知识的本体技术(Ontology)[93]。
2.1 相关性反馈
相关性反馈技术是非常有效的技术,它不断将基于底层特征得到的搜索结果反馈给用户,要求用户给出是否“相关”的二值评价,然后对评价进行学习,最终返回高层语义上最相似的结果模型[94]。如图10,可以看出,该方法分为在线语义获取和离线特征提取、语义学习两个部分。搜索过程中,系统会和用户进行多次交互行为。每次返回一批检索结果,根据用户的二值化评价结果进行迭代,再次搜索并返回结果,等待用户评价,如此反复,直到符合结束条件。该方法的主要改进和优化思路是改进分类器性能,简化交互流程。
Leng 等[95]提出了对特征向量进行加权的反馈技术,较好地解决了小样本问题和正负样本数目差距过大的问题。近年来,更多模式识别中的分类技术与相关性反馈技术相融合[96]。如在分类工具中非常经典的支持向量机(Support Vector Machine,SVM)[97-98]及其扩展SVM-OSS(Support Vector Machine-One Shoot Score)[99]、LibSVM(Support Vector Machine Library)[100]等。SVM 算法将用户反馈回来的二元数据用于训练,然后将未标记的样本当作测试样本分类,之后返回正相关样本,用分类计算的结果作为正负样本的相似度度量值。

图10 基于语义的检索方法架构示意图Fig.10 Architecture of semantic-based retrieval method
SVM 的性能受训练样本数量影响较大,在相关性反馈的应用中,表现为正负样本数目不对称,正相关样本数量远少于负相关样本数量(非对称问题)[101]。因此文献[66]只采用SVM 作为负样本的相似度距离值的度量,正样本仍然用欧氏距离计算。另外,SVM的参数受实际问题影响较大,难以做到不同类别场合的通用性。文献[102]采用半监督学习思想,引入基于高斯核的超限学习机算法,放宽了对标记样本数量的要求,使搜索结果更精确。引入感知机、深度学习等分类方法后,相关性反馈的应用范围和准确率都得到了提升。搭建好合适的网络结构、生成初始参数后,迭代训练[103]。
相关性反馈技术需要在检索过程中和用户进行交互,以完成整个过程。实际使用过程中,而用户未必可以忍受多轮的交互和标记行为。另外数据样本的非对称问题极大影响了分类器的效果。
2.2 主动学习
相关性反馈技术没有长期存储语义知识,每次使用过程都依赖于当前用户的反馈结果。如果用户需要多次查询同一个模型,而且用户的检索需求或语义知识保持不变,那么采用短期学习机制的算法需要用户多次经历反馈过程。一种较好的思路是引入长期学习机制,将针对某一特定类型的模型的标记结果作为参数的一部分进行保存,供下一次检索时使用[104],即主动学习(长期学习)技术。
该类方法最早使用日志记录用户的反馈结果,相关算法将挖掘历史反馈结果,调整当前输出值[105]。随后的研究倾向于和机器学习融合。实际上大部分针对图像的机器学习/主动学习的检索算法也可以用于三维模型检索,并且都能取得不错的效果。文献[106]使用半监督学习的SVM 进行聚类,并提出一种在分类中使用基于内容的搜索方法的整合策略。文献[107]提出一种基于核密度估计的分类方法。该小组另一项研究针对仅存在正向反馈的数据,提出分别估计正向反馈数据和未标记数据的概率密度,然后计算信息量的期望值[108]。该方法在一分类问题(One-class classification)中表现较好[109]。文献[110]提出基于高斯过程的一分类方法,并比较了源于高斯过程回归和近似高斯过程的各类方法。
主动学习中需要更新存储的检索记录,将其整合进新的特征向量,故特征向量维数较高。因此相关研究提出多种降维方法,如基于主成分分析(PCA)的线性降维,包括PCADAISY 描述符[111]、IKPCA[112](Improved Kernel-PCA)等和基于流型学习的非线性降维,如Isomap(Isometric Feature Mapping)[113]、拉普拉斯变换[114]等。
主动学习技术会记录用户的反馈数据,将记录的历史数据和最新的在线反馈结果综合加以分析,最终得到检索结果。因此,对反馈数据的记录、分析和挖掘,是该类方法的一个热点。另外,如何将主动学习技术与目前的神经网络更好地融合,也是一个难点。
2.3 本体
本体(Ontology)是某一领域内的知识和概念的一种规范的形式化表示[115]。对领域进行划分可以将待检索模型限定在一个更符合用户实际需要的子集中。本体最早是对语言学进行定义的工具,拥有一整套成熟的理论体系和表达方式OWL(Web Ontology Language),如图11。后来学者发现可以用来定义复杂的概念与属性的关系,因此该方法很快在计算机领域流行。

图11 基于本体的语义检索的过程Fig.11 Process of semantic retrieval based on ontology
本体技术依赖于事先对模型库进行的语义标注工作。在文献[116]中,将这一技术概括为三个要素:形状、动作和功能。即用户输入功能信息,本体自动推演,查找相应的动作和形状信息,然后综合计算得到符合功能的模型。对其进行的改进主要是改进其对模型特性的表达能力和改进对新模型的搜索能力。比较有代表性的工作有:文献[117]提出一种基于规则引擎的语义网规则语言(Semantic Web Rule Language,SWRL)的本体三维模型搜索方法;文献[118]对其进行了改进,使其可以更好地应用在异构模型中;文献[119]从物理性状特征中提取语义特征,并提出一种融合语义特征与物理性状特征的本体分类技术;文献[120]提出一种忽视存储、特征提取的,基于内容的本体搜索方法。本体技术与关键词关系较为紧密,结构化与非结构化的文本信息挖掘也有所提及[121]。
本体技术在三维模型检索的工业化上已经有了很多成功的范例[122]。构建正确的本体语义网络需要相关领域专家的努力,而且随着新模型的发明,原有本体语义网络的扩展工作也很重要。对本体的动态生成与维护工作也是一个研究点[123]。另外,如何在现有的产品知识规范的基础上,实现高级语义知识的自动提取和演绎推理,也是一个值得深入的重点。
3 结语
三维模型检索和图像检索类似,性能依赖于特征提取过程。基于内容的检索方法从模型的物理形状、骨架出发,最终检索出一个外形相似的模型。基于语义的检索方法在分析模型的物理性状之外,也考虑到实际物体的意义与内涵,在形状相似的基础上达到了意义相似,最终检索出一个更符合用户需求的模型。基于语义的检索方法由基于内容的检索方法的衍生,而基于内容的检索方法仍然有发展空间。因为两种检索方法都需要进行模式分类,所以与机器学习、深度学习相结合的方法也更受到重视。基于本体的语义检索方法和领域知识的关联性较强,但是受到维护技术、检索技术的制约,仍然有广阔的发展前景。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
军事文摘(2022年8期)2022-05-25
新高考·高一数学(2022年3期)2022-04-28
技术与创新管理(2020年5期)2020-10-09
科学与财富(2019年27期)2019-10-25
意林(图解作文)(2019年6期)2019-07-16
学生天地·小学低年级版(2019年5期)2019-06-05
学生天地(2019年15期)2019-05-05
科学与财富(2017年28期)2017-10-14
长江学术(2016年4期)2016-03-11
