
基于非自回归方法的维汉神经机器翻译
2020-08-06 08:28朱相荣杨雅婷
计算机应用 2020年7期
朱相荣,王 磊*,杨雅婷,董 瑞,张 俊
(1.中国科学院新疆理化技术研究所,乌鲁木齐 830011;2.中国科学院大学,北京 100049;3.中国科学院新疆理化技术研究所新疆民族语音语言信息处理实验室,乌鲁木齐 830011)
(*通信作者电子邮箱wanglei@ms.xjb.ac.cn)
0 引言
编码器-解码器架构是神经机器翻译(Neural Machine Translation,NMT)的核心思想[1]。基于神经网络的编码器-解码器架构在机器翻译中取得了很好的性能,并提出了不同的网络结构,例 如:Sutskever 等[2]提出的循环神经网络(Recurrent Neural Networks,RNN),Gehring 等[3]提出的卷积神经网络(Convolutional Neural Network,CNN)以及Vaswani等[4]提出的基于注意力机制的Transformer。虽然它们都取得了不错的翻译性能,但由于解码器均采用自回归解码影响了翻译速度的提升。如图1 所示,在自回归解码过程中目标句子根据源句子表示和目标翻译历史从左到右逐字翻译生成,即第t标记yt遵循条件分布p(yt|x,y<t),其中y<t表示yt之前生成的所有标记。由于每次只执行一个步骤,根据之前生成的序列生成下一个序列,使得解码不容易并行化。尤其对于支持并行的现代硬件来说很不友好,产生的解码延迟严重阻碍了NMT 系统的翻译速度,限制了现实场景中的应用。相反,非自回归模型并行生成目标标记,没有可用的目标翻译信息使得翻译效果不是很好,但它能显著减少解码时间,使得图形处理器(Graphics Processing Unit,GPU)的计算能力得到充分发挥。因此,有效地提升模型解码速度变得尤为重要。
近年来为了减少自回归解码带来的解码延迟,研究人员们尝试了各种方法。Schwenk[5]提出一个连续空间翻译模型来估计给定源短语在目标短语上的条件分布,同时丢弃目标标记之间的条件依赖性,然而仅限于不超过7 个单词的短语对。Kaiser 等[6]研究了应用GPU 的神经机器翻译,评估自回归和非自回归方法,发现非自回归方法明显落后于自回归翻译方法。Gu 等[7]提出一种非自回归翻译(Non-Autoregressive Translation,NAT)模型。如图1 所示,该模型抛弃了自回归机制,并行生成目标端所有单词,显著地减少了解码延迟,但与自回归翻译(Autoregressive Translation,AT)模型相比,它的准确性严重下降。NAT模型与AT模型具有相同的编码器-解码器架构,只是NAT 模型的解码器删除了目标侧句子间的顺序依赖性,丢弃了自然语言句子中的内在依赖性,在很大程度上牺牲了翻译质量。由于先后生成单词之间的依赖关系,对于一个长为n的目标句子,自回归模型需要O(n)次循环生成它。而非自回归模型通过减少生成句子的循环次数来提高翻译速度。根据循环复杂度,可将非自回归模型分为三类:O(1)即只要一次循环,如Gu等[7]、Wang等[8]和Guo等[9]提出的非自回归模型,在去除生成目标语句时单词之间的依赖关系之后,通过解码器的输入和预测目标句子的长度来缓解重复翻译和不完整翻译;O(k)即需要常数次循环,如Lee 等[10]提出的基于迭代优化,Ghazvininejad 等[11]提出的基于条件遮掩语言模型的非自回归模型;O(<n)即O(logn)和O(n/k)等循环复杂度的情况,如Stern 等[12]提出的通过插入操作灵活生成目标序列非自回归模型和Wang 等[13]提出的半自回归神经机器翻译模型。因此,一方面要保证模型的翻译质量,另一方面要提升模型的解码速度,成为一个新的严峻挑战。
本研究借鉴Lee 等[10]提出基于迭代优化的非自回归序列模型,将解码器输出作为下一次迭代的输入反馈,对翻译结果进行迭代优化来提升翻译效果。该模型由一个潜在变量模型和一个条件去噪自动编码器组成,除了在解码器中删除目标侧句子的依赖性之外,与自回归模型Transformer 具有相同的编码器-解码器架构,均采用相同的Adam 方法和warm up 学习率调节策略。本文通过优化该模型的学习率策略,改变学习率调节方法,将训练中学习率调节方法warm up 换成linear annealing;然后将模型在全国机器翻译研讨会(China Workshop on Machine Translation,CWMT)2017 维汉平行语料上采用不同的学习率调节方法进行实验验证;最终得到在linear annealing 上效果优于warm up,与自回归模型Transformer 的实验结果对比之后得到当解码速度提升1.74倍时,翻译性能达到自回归翻译模型Transformer 的95.34%。因此,本文发现使用liner annealing 学习率调节方法可以有效提升维汉机器翻译的质量和速度。
1 迭代优化的非自回归序列模型
本文提出的学习率调节方法是基于Lee 等[10]提出的基于迭代优化的非自回归序列模型,因此下面将简要介绍该模型。该模型采用编码器-解码器架构,可以看作由一个潜在变量模型和一个条件降噪自动编码器组成。
1.1 潜在变量模型
Lee 等[10]在提出的序列模型中通过引入潜在变量(latent variable)来隐式地捕获目标变量之间的依赖关系。可以把潜在变量看成解码器的输入,通过引入L个中间随机潜在变量,然后将其边缘化。

该求和公式内的每一个乘积项由一个神经网络建模,该神经网络以一个源语句为输入,输出每个t在目标词汇V上的条件分布。T是指目标语句的长度,Y0,Y1,…,YL分别代表输出序列每次迭代后的结果。如图2所示,L个潜在变量代表输出序列的L+1次迭代优化,则第一次迭代仅依赖源语句X生成初始翻译结果,接着每一次迭代都根据源语句X和上一轮迭代的结果生成本轮的翻译结果,分别为Y1,Y2,…,YL。
如图2 所示,潜在变量L的个数,就代表输出序列在Decoder2上的L次迭代优化和在Decoder1上的1次迭代优化,总共L+1次。

图2 潜在变量模型Fig.2 Latent variable model
对于给定的训练对(X,Y*),即最小化损失函数:

1.2 降噪自动编码器
和自编码器不同的是,降噪自编码器在训练过程中,输入的数据中部分带有“噪声”。降噪自编码器(Denoising AutoEncoder,DAE)的核心思想是,一个能够从中恢复出原始信号的神经网络表达未必是最好的,但能够对带“噪声”的原始数据编码、解码,然后还能恢复真正的原始数据,这样的特征才是最好的。Lee 等[10]提出的序列模型中,通过C(Y|Y*)引入正确输出Y*的损坏数据。Hill 等[14]提出的加入噪声的方法,最近在Artetxe 等[15]和Lample 等[16]中广泛地使用,即在目标语句中加入噪声之后再作为解码器输入,文中提出加入噪声的方法比较传统,如前后两次调换顺序、替换原词为词表中任意一词等。如图3 所示,使用加入噪声的数据随机地替代图2 所示的Decoder2 的输出结果。为了找到在给定加入噪声数据的前提下,找到原始准确翻译Y*的最大对数概率。即最小损失函数:


图3 自动降噪编码器Fig.3 Denoising autoencoder
1.3 损失函数
总体上训练模式是:除了第一次迭代,每次迭代的解码器输入要么是对目标语句加入潜在变量后的结果,要么是对目标语句加入噪声后的结果,两者之间用超参数αl控制。在模型上,如图2 或3 所示,其中解码器Decoder1 只负责第一轮的迭代,解码器Decoder2 负责之后的迭代。因此提出随机混合潜在变量模型和降噪自动编码器的损失函数见式(4),用一个超参数αl控制。用式(3)中的随机取代式(2)中的。

2 本文提出的方法
Lee 等[10]提出的基于迭代优化的非自回归序列模型,如图2 或者图3 所示,该模型是通过使用基于Transform 模型改进的。模型训练采用Adam 方法,使用warm up 的学习率调节方法,公式如下:
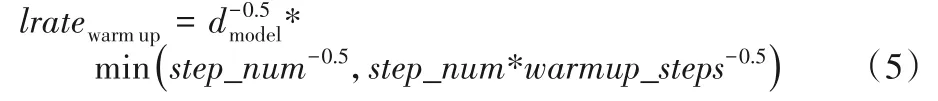
该学习率调节方法是指,需要预先设置一个warm_steps超参。当训练步数step_num小于该值时,step_num*warmup_step-0.5决定学习率,这时学习率是step_num变量斜率为正的线性函数;反之,训练步数step_num大于warm_steps时,step_num-0.5决定学习率,这时就成了一个指数为负数的幂函数。这样在规模大的平行语料下,学习率呈现“上升-平稳-下降”的规律,这尤其在深层模型和具有多层感知机(MultipLayer Perception,MLP)层的模型中比较显著。如果从模型角度来看,学习率的这种变化对应了模型“平稳-探索-平稳”的学习阶段。因此warm up 有助于减缓模型在初始阶段对小批量数据的过拟合现象,保持分布的平稳,更有助于保持深层模型的稳定性。但是当网络不够大、不够深和数据规模batch size 普遍较小的情况下,网络不够大不够深就意味着模型能够比较容易地把分布从过拟合中拉回来,数据集比较小意味着batch size 之间的方差没有那么大。所以,学习率不使用warm up 不会出现很严重的学习问题,同时warn up 学习率策略非常耗时间。
但是由于Lee 等[10]提出的该非自回归的序列模型,是在机器翻译研讨会(Workshop on Machine Translation,WMT)英德平行语料上进行的。该平行语料由于规模比较大,warm up的效果比较好。而本文中所采用的语料是维汉平行语料,该语料比较少,仅有350 000,训练过程中使用warm up 的学习率方法效果不是很好,而且对时间消耗很大,因此,本文在平行语料国际口语机器翻译评测比赛(International Workshop on Spoken Language Translation,IWSLT)2016 英-德(196 000),WMT2015 英-德(4 500 000)和CWMT2017 维-汉(350 000)上分别采用学习率调节方法warm up 和linear annealing 进行了实验(语料信息如表1 所示,实验结果如表2)。从表2 的实验结果来看,在平行语料规模比较大的WMT2015上,warm up的效果比较好;而在平行语料规模比较小的IWSLT2016 上,linear annealing 的效果比较好。同时,本文在维汉平行语料上证实了该观点,由表2 可知,使用linear annealing 的学习率调节方法比warm up 在翻译质量方面提升接近4 个双语评估替换(BiLingual Evaluation Understudy,BLEU),在解码速度方面提升接近200 Tokens/s。因此在CWMT2017 维汉语料上采用linear annealing 学习率调节方法比较好,公式如下:

训练中设置lr_end=1E-5,anneal_steps=250 000,iters实际训练步数(200 000)。linear annealing 是一种随机算法,能够快速找到问题的最优近似解,用来在一个大的搜寻空间内找寻命题最优解。这种方法区别于简单的贪心搜索算法。简单的贪心搜索算法每次从当前解的邻近解空间中选择一个最优解作为当前解,直到达到一个局部最优解;但这种方法容易陷入局部最优解,而局部最优解不一定是全局最优解。而linear annealing 算法在搜索过程中加入了随机因素,以一定概率来接受一个比当前解要差的解,因此很有可能跳出这个局部最优解,达到全局最优解。同时linear annealing 适用于数据集规模比较少、模型不是很深的环境中,能够快速地达到收敛,相较于warm up,消耗时间更少。由表2 可知,基线系统采用Lee 等[10]提出的基于迭代优化的非自回归序列模型,在相同的训练步骤200 000条件下,在维汉平行语料上采用学习率调节方法linear annealing 比warm up 得到的翻译质量和解码速度都高,使本研究的观点得到验证。因此,本文在该模型中采用学习率调节方法linear annealing 替换原模型中的warm up,实验结果见表3。最终该非自回归模型得出的结论与自回归模型Transformer对比,实验结果见表4。
3 实验与分析
3.1 数据集
数据集采用CWMT2017 发布的维吾尔语-汉语新闻政务评测语料,英-德平行语料训练集采用WMT2015(4 500 000)和IWSLT201616(190 000)。对于WMT2015采用newstest2014和newstest2013 作为测试集和开发集;对于IWSLT2016 采用newstest2013 作为测试集和开发集。对所有平行语料的所有句子都使用字节对编码(Byte Pair Encoding,BPE)算法[17]进行标记并分割成子单词单元。将学习到的规则应用于所有的训练集、开发集和测试集[18]。维汉语料和IWSLT2016 英-德语料共享大小为40 000 的词汇表,WMT2015 英-德语料共享大小为60 000的词汇表。数据集见表1所示。

表1 平行语料Tab.1 Parallel corpus
3.2 评价指标
对于神经机器翻译结果,本研究采用机器翻译常用的评价指标机器双语评估替换(BLEU)[19]值来对模型的翻译质量进行评价,解码效率采用Tokens/s和Sentences/s来判定。
3.3 实验设置
基线系统(baseline) 采用Lee等[10]提出的基于迭代优化的非自回归序列模型中的自回归模型Transformer,使用小的训练模型,设 置d_moder=278,d_hidden=507,p_droput=0.1,n_layer=5和n_head=2,t_warmup=746,训练步数为200 000。分别采用warm up 和linear annealing 的学习率调节方法。训练结果见表2,在CWMT2017 维汉平行语料上采用策略warm up时,翻译质量的BLEU 值为43.33 和解码速度为873.99 Tokens/s作为基线系统(自回归模型)。
知识蒸馏(Knowledge Distillation) 知识蒸馏被广泛应用于神经机器翻译[20]。Hinton 等[21]和Kim 等[22]提出的知识蒸馏被证明是成功训练非自回归模型的关键。对于翻译任务,本文使用序列级知识蒸馏来构造蒸馏语料库,其中训练语料库的目标侧被自回归模型的输出所替代。本研究使用原始语料库训练自回归基线系统,用蒸馏语料库训练非自回归模型。

表2 不同平行语料训练结果Tab.2 Training results of different parallel corpuses
训练和解码 训练的模型使用Kingma 等[23]提出的Adam[23]优化器。本文的训练和解码过程在单个Nvidia Tesla K80 GPU上。根据Lee等[10]的设置,超参数PDAE=0.5。在实验中采用Oracle 距离作为距离函数,即采用迭代次数自适应时,采用Oracle 作为距离函数,用来求得翻译质量和解码速度平衡的最优值。
3.4 结果分析
从表2 的实验结果显示,本文在基线系统上通过采用不同的学习率调节方法,很明显学习率调节方法采用liner annealing时在维汉平行语料上无论是翻译质量还是解码速度都优于warm up。尤其在翻译质量方面,使用liner annealing学习率调节方法比warm up提升4.28个BLEU值。因此,本研究在Lee 等[10]提出的非自回归序列模型中采用liner annealing学习率调节方法替换warm up,实验结果见表3。
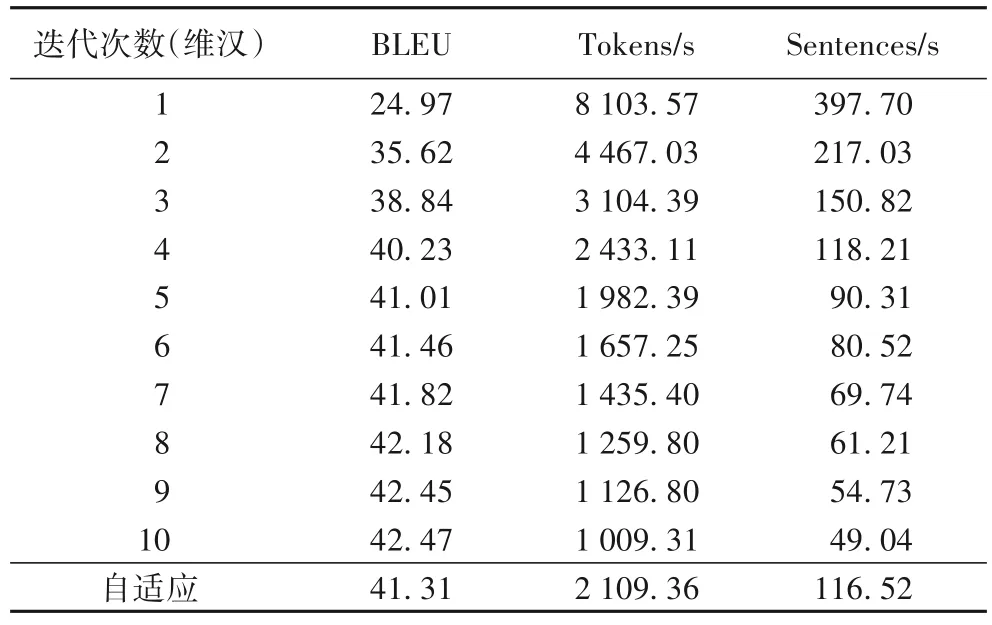
表3 非自回归模型训练结果Tab.3 Training results of non-autoregressive model
从表3 的实验结果显示,翻译质量随着迭代次数的增加而增加,而解码效率随着迭代次数的增加而下降。当iter=1时,非自回归的解码器比自回归模型提升8.37 倍,而翻译质量仅达到自回归模型的57.63%;当iter=4时,非自回归的解码器比自回归模型提升1.78 倍,翻译质量却达到自回归模型的92.85%;当iter=10时,使用liner annealing 的解码速度略高于warm up的解码速度时,它们的翻译质量相近。为了在翻译质量和解码速度方面达到更好的平衡,本文采取自适应迭代次数,即解码速度为2 109.36 Tokens/s,翻译质量的BLEU 值为
41.31 。
从表4 的实验结果显示,本文将所采用的非自回归模型与现有自回归模型Transformer 的结果进行比较,最终得到非自回归模型的解码速度比自回归模型提升1.74 倍时,翻译质量可达到自回归翻译模型的95.34%,可以实现翻译质量和解码速度之间很好的平衡。

表4 自回归和自非回归模型结果对比Tab.4 Comparison of results of autoregressive and non-autoregressive models
3.5 举例说明
图4 展示了从CWMT 2017 维汉数据集中抽取的一个翻译示例。可以看到非自回归模型倾向于重复翻译相同的单词或短语,有时候会漏掉有意义的单词。同时,随着迭代次数的增加,会整体调整句子中单词顺序,使其更接近参考翻译,翻译质量也在逐步地提高。

图4 非自回归模型翻译的例子Fig.4 Translation example of non-autoregressive model
4 结语
本文通过在Lee 等[10]提出的基于迭代优化的非自回归序列模型上采用不同的学习率调节方法,来验证学习率调节方法对该模型翻译质量和解码速度的影响。最终得到在迭代次数自适应条件下,CWMT2017 维汉语料采用liner annealing 学习率策略可得到翻译质量为41.31的BLEU 值,翻译质量可达到自回归翻译模型Transformer 的95.34%,解码速度提升1.74 倍,使其解码速度和翻译质量达到一个平衡。在下一步的工作中将研究如何改进该模型,使其在翻译质量能够达到甚至超过基线系统的基础上,解码速度能够显著地提升,让翻译质量和解码速度达到一个更好的平衡。
猜你喜欢
传感器世界(2022年4期)2022-08-05
现代计算机(2021年33期)2022-01-21
小学生必读(低年级版)(2021年10期)2022-01-18
锻压装备与制造技术(2021年5期)2021-11-13
科学技术创新(2021年5期)2021-03-17
小学生必读(低年级版)(2021年11期)2021-03-09
小学生必读(低年级版)(2021年12期)2021-03-04
——编码器
演艺科技(2020年7期)2020-08-13
长江丛刊(2019年25期)2019-11-15
电脑知识与技术(2019年23期)2019-11-03
