
改进粗糙集属性约简结合K-means聚类的网络入侵检测方法
2020-08-06 08:28王磊
计算机应用 2020年7期
王 磊
(苏州大学信息化建设与管理中心,江苏苏州215006)(*通信作者电子邮箱wanglei01005@163.com)
0 引言
网络安全问题一直是全社会关注的焦点,随着网络环境的日益复杂,包括防火墙、安全路由及数据加密等静态网络安全保护方法已很难满足人们对于网络安全性能的需求。
入侵检测系统(Intrusion Detection System,IDS)作为一种网络安全主动防御技术,能够对防火墙等传统安全保护体系起到辅助作用[1],通过监控流经某个节点的流量,实现对入侵行为的检测,并生成报警信号发送至系统管理员,典型的IDS通常包括事件采集、事件分析和事件响应三个核心环节,其检测方法主要可分为两种类型:误用IDS 和异常IDS。现有IDS均或多或少存在有效性低、适应性不强、误报率高以及可扩展性不高等问题。其中:误用IDS 根据已知攻击和系统弱点的参数识别入侵,然而它无法识别新的或不熟悉的攻击类型;异常IDS 则基于正常行为的参数,并使用它们来识别任何与正常行为相差甚远的行为[2]。误用入侵检测的机制是训练现有的入侵模式,并将考虑用于检查的数据,与先前的模式相匹配,以识别入侵。IDS 一般挂接在所有所关注流量都必须流经的链路上,而所关注流量则是指来自高危网络区域的访问数据和需要进行统计、监视的网络报文数据。即无论是误用IDS还是异常IDS,都离不开对数据的挖掘与处理。
利用数据挖掘技术开发的IDS 通常具有检测网络入侵的优异性能和泛化能力,从而使其具有高效的入侵检测性能。然而,实现和安装这种系统的过程是复杂的,系统的固有复杂性可以根据准确性、能力和可用性的参数,组织成单独的问题集[3]。与使用数据挖掘技术构建的IDS 相关联的一个关键问题主要是基于异常检测的那些技术,与先前基于手工签名的检测技术相比,其误报率更高[4]。因此,对于这些技术来说,审计数据的处理和在线入侵的检测比较困难,并且需要大量的训练数据。文献[5]提出了一种结合了统计技术和自组织映射来检测网络中异常的分类方法(Statistical Techniques and Self-organizing Maps,STSM),其中主成分分析(Principal Component Analysis,PCA)和Fisher判别比用于特征选择和噪声消除,概率自组织映射用于将网络事务分类为正常或异常。文献[6]提出了一种结合数据挖掘方法的混合技术(Hybrid Technique that combines Data Mining Approaches,HT-DMA)。该方法中,K-means聚类算法用于减少与每个数据点相关联属性的数量,再将支持向量机(Support Vector Machine,SVM)的径向基函数(Radial Basis Function,RBF)用于异常网络入侵检测。文献[7]提出了基于距离和的SVM 混合学习(Distance Sum-based SVM,DSSVM)方法,用于建模有效的IDS。在DSSVM中,获得基于每个数据样本与数据集中的聚类中心特征维度之间的相关性的距离和,并将SVM用作分类器。
然而现有方法需要大量的训练数据,并且与系统的学习过程相关的复杂性很高。因此提出一种基于改进粗糙集属性约简和K-means 聚类的网络入侵检测方法(Improved Rough Set Attribute Reduction and optimizedK-means Clustering Approach for Network Intrusion Detection,IRSAR-KCANID)。所提方法首先基于改进模糊粗糙集属性约简对数据集进行预处理,优化异常的入侵检测特征,然后利用改进K-means 聚类算法进行入侵检测特征分析和入侵范围估计阈值估计,并对网络特征进行分类;再根据用于特征优化的线性规范相关性,从所选择的最优特征探索关联影响尺度,形成特征关联影响量(Feature Association Impact Scale,FAIS)表,完成对异常网络入侵的快速准确检测。主要创新体现在以下几个方面:
1)现有方法在入侵检测数据训练方面耗时较多,提出的方法利用改进模糊粗糙集属性约简对数据集进行了预处理,优化异常的入侵检测特征,避免了对大量数据的训练,缩短了入侵检测时间;
2)现有大多数入侵检测方法仅仅是发现攻击行为,没有对攻击进行有效的分类,提出的方法在数据预处理的基础上,利用改进K-means 聚类算法进行入侵检测特征分析和入侵范围估计阈值估计,并对网络特征进行分类。
3)在聚类结果的基础上,根据用于特征优化的线性规范相关性,从所选择的最优特征探索关联影响尺度形成关联影响量表,从而完成对异常网络入侵的检测。
特征相关性实验结果表明,特征优化聚类后的最小化测量特征关联影响量表能在保证最大预测精度的前提下,最小化入侵检测过程的复杂度并缩短完成时间。
1 基于改进粗糙集属性约简的数据集预处理
由于原始数据往往包含隐含信息[8-9],本文利用改进粗糙集属性约简(Improved Rough Set Attribute Reduction,IRSAR)将这些隐含信息提取出来,在保留原始特征的同时更好地表现数据特征。将网络连接记录表示为四元组FS=(U,At,V,f),其中:U为整个网络数据集;At是一个非空的有限属性集,t表示属性集数量;表示属性a域 集合;f=U×At表示信息函数。
由于传统的粗糙集理论只能处理离散属性集,无法很好地处理包含大量连续值的网络连接数据[10-11],因此引入模糊理论,利用模糊粗糙集的信息增益率对网络连接数据特征进行自动选取。
将引入模糊理论的网络连接记录表示为FIS=(U,C∪D,V,f),设B⊆C,∀a∈C-B,C为条件属性集,B为约简的属性集,D为决策属性集,属性a的信息增益率为:

其中,GainRatlo表示增益率,GainRatlo(a,B,D)可用于衡量属性a的重要程度,可以通过每次选择增益率最大的特征进行属性选取,最终获得的属性集即为约简的本征属性集。IRSAR 的数据集预处理主要步骤如下,其中输入为数据集X、条件属性集C、决策属性集D,输出为约简的属性集B:
1)清空B集合,计算GainRatlo(a,B,D),并筛选其最大值;
2)如 果 maxGainRatlo(a,B,D) >0,则B←B∪{a},返回1);
3)集合B为属性约简后的属性集合。
模糊等价关系是模糊粗糙集的核心,假如给定非空有限数据集X,X上的模糊等价关系R可以用关系矩阵Mr表示为:

其中rij∈[0,1]是xi与xj的关联值;xi和xj分别表示不同数据在同一属性上的值,xi,xj∈X,模糊等价关系需要满足自反、对称和传递性,能够实现信息增益率对网络连接数据特征属性集进行自动筛选,以获得约简的本征属性集,从而有效提高入侵检测算法的稳定性。相较于经典粗糙集理论只能处理离散属性集的短板,改进粗糙集属性能够获得保留原始特征辨别能力的属性子集,能够很好地处理包含大量连续值的网络连接数据。
2 特征分析与影响尺度阈值估计方法
2.1 K-means 聚类及其改进
K-means 聚类算法采用评价指标来度量距离的相似性[12-13],其主要思想体现为以下三点:
1)在样本数据中,样本数量为k,且为任意设设定,设定的样本代表一个簇的初始中心或者均值;
2)数据样本与每个聚类中心之间的距离通常用欧氏距离公式计算,每个数据样本根据计算结果被分配到最近的类;
3)调整聚类中心并对得到的新类进行再次计算,聚类准则函数收敛的条件是聚类中心不再变化,即可终止对样本数据的聚类调整,从而结束算法。
改进K-means 算法则针对初值选取敏感问题,算法中簇心的初始位置在算法开始时通过临时指定,再通过样本数据各维度的最大值和最小值计算,结合多次迭代来选取最佳的簇心,期间采用随机梯度下降的方法来取代批量梯度下降以防止K-means 算法陷入局部最优。假定h(θ)为所需要拟合的函数,J(θ)为损失函数,其函数形式分别表示为:其中:m表示训练集的数量,θ表示多次迭代计算所需要求取的值,X和Y为数据集,i表示迭代计数,t为损失因子,参数个数表示为j。当求解出θ时最终要拟合的函数h(θ)的值也相应求得。

损失函数也可以改写为:

其中cost(θ,(xt,yi))可表示为:

此处损失函数所对应的辨识训练集中每个样本数据的隶属度,对于每个样本数据的损失函数,通过对θ求偏导可以求出相应的梯度,其中θ可以根据以下公式更新:

在计算过程中θ可以通过迭代计算不断更新,但如果学习效率设置过高则可能导致振荡现象。因此可以引进学习率α进行改进,若假设f(α)=h(xk+αdk),其中当前样本点设置为xk,搜索方向设置为dk,则可得随机梯度下降过程所寻找的f(α)最小值为:

对学习率的函数导数的分析:若α=0,则有
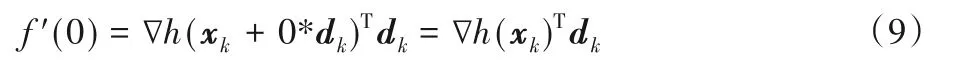
下降方向dk可以选负梯度方向dk=-∇h(xk),从而使f'(0) >0。假如找到的α足够大,并且使得f'(â)>0,则一定存在某个α,使得f'(α*) >0,其中α*即为改进设置的学习率。
改进K-means 聚类算法工作步骤如下,输入k(簇数),输出标记好的k个簇集合。
1)手动设定k个临时簇心;
2)在样本数据每个向量的维度以及各自维度最大值和最小值选取簇心;
3)根据选取的样本数据Xi找出距离它最近的簇心,并把簇心向Xi方向移动;
4)每次移动数据项时都乘以学习率α,其变化趋势随迭代次数增加而不断减小;
5)返回步骤2);
6)对簇心进行更新;
7)直到簇心位置固定不变;
8)根据数量以及标记判别该簇正常与否。
改进后的K-means 算法对于初值选取要求有所降低,相较于原始算法簇心的初始位置可以在算法开始时临时指定,无需进行繁琐的初值整定;此外,改进算法在稳定性方面也有一定的提升,因为学习率α的设置改进,可以避免因学习效率设置过高而导致的振荡现象。
2.2 入侵检测特征分析与特征关联影响尺度阈值估计
2.2.1 入侵检测特征分析
网络事务集包含的42 个特征可以分为连续和分类的值,为了便于优化,需要将所有最初字母及连续数值转换为分类。预处理的一组网络事务根据其标签进行分区,使得正常事务是一组,拒绝服务(Denial of Service,DoS)攻击事务是另一组。
将字母数字值表示为数值,并将联系续值表示为分类值,其具体步骤如下:
1)考虑具有字母数字值的每个要素,然后列出所有可能的唯一值,并使用从1开始的增量索引列出它们;
2)用适当的索引替换值;
3)考虑具有连续值的每个要素,然后将它们划分为一组具有最小值和最大值的范围,以便事件在所有这些范围内均匀分布。
考虑结果正常交易集(Normal Trade Set,NTS)中的每个特征值集合fiv(NTS) 及其覆盖百分比为fiv={fi(v1,c1),fi(v2,c2),…,fi(vj,cj)},v,c为特征量,然后,可以按照以下步骤中的描述执行每个攻击A的特征优化:
1)考虑交易集ts(Ak)表示攻击类型Ak(假设为DoS攻击)。
2)对于每个特征fi(Ak),将所有值视为集合fiv(Ak)。创建大小为的空集,并根据其覆盖百分比填充中的值,使得表示的特征值集的大小。
4)此过程应适用于攻击Ak的网络事务中设置的所有特征值。
5)找出fiv(Ak)和之间的典型相关性。如果得到的典型相关性小于给定阈值或零,那么特征fi(Ak)可以被认为是评估入侵范围规模的最佳值。
根据上述步骤中说明的过程,可以识别特定攻击Ak的最佳特征。
2.2.2 特征关联影响尺度阈值估计
通过聚合A的每一行来找到特权权重(将形成表示特权权重v),再通过A和v之间的乘法找到枢轴权重:
u=A×v(10)
那么特征分类值fivj的尺度阈值fas可以通过如下公式计算:
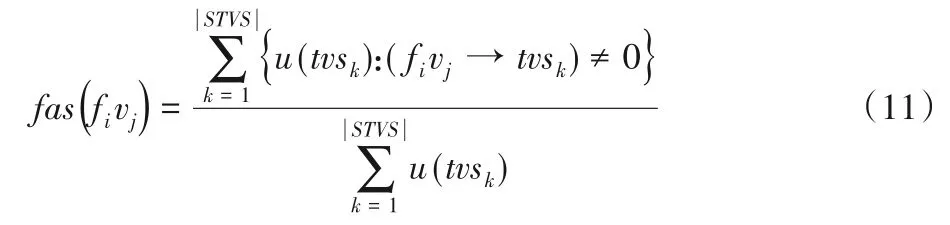
特征分类值fivj和fi'vj'之间的fas可以表示为:

其中:tvsk表示k交易价值集,|STVS|表示事务值集的总数。
另外,每个交易价值集tvsi的特征关联影响量表fais和faist阈值可以分别表示为:

其中:valj∈V表示特征差值。
每个交易价值faist的标准差需要进一步测量集合,以估计faist阈值的上下限和挑战黑洞(Challenge Collapsar,CC)阈值范围。其中,cc阈值是faist的一个临界值;下限为cc平均值与cc 标准差之间的差值,上限为cc 平均值与cc 标准差之和。阈值设定的目的在于对以上三种范围进行阈值额定,与此对应的范围分别为不相关性、弱相似性和强相似性。发现的正常记录总数为测试数据记录的总和,估算标准偏差表示如下:
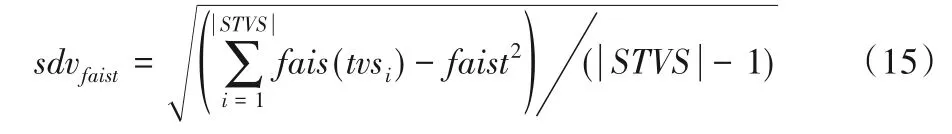
faist系列可以探索范围如下:
faist范围的下限是:

faist范围的上限是:

当且仅当fais(nt)<faistl时,网络事务nt可以说是安全的。
通过对网络中不同标注下数据进行处理,结合模糊等价关系矩阵,可获得输入信号参数入侵特征阈值的参考指标集如下:

通过上式构建Mg关联模型,并通过不断训练改变参数个数与入侵特征阈值,获取异常度量关联矩阵:

其中m表示参数个数,则有入侵检测特征关联影响阈值为:

2.3 数据集特征相关性分析并聚类
考虑两个多维数据集X和Y,并且利用基于标准统计技术的典型相关分析(Canonical Correlation Analysis,CCA),利用二阶的自协方差和互协方差矩阵,建立数据集之间的线性关系。该技术基于两个基础,每个基础用于数据集X和Y,其中互相关矩阵变为对角线,并且对角线的相关性最大化。
研究用于实现规范相关的参数,其中,X和Y应该相等;然而,假设平均值为零,数据向量x∈X和y∈Y可以具有变化的尺寸。使用特征向量方程求解规范相关计算:

这里,Cxx、Cxy、Cyy、Cyx均为交叉协方差矩阵,其中r2本征值是规范相关的平方,wx和wy是归一化CCA 基矢量。方程的解等价于非零值,其数量等于x和y,表示考虑具有较小维数值的数据向量。当时,式(21)被转换为:

这些方程描述了交叉协方差矩阵Cxy的奇异值分解:

这里U和V表示包括奇异向量ui和vi的正交平方矩阵。wx和wy表示传递规范相关性的基础向量。矩阵U和V以及ui和vi的向量维度通常根据x和y数据向量的维度变化而变化。

伪对角矩阵Q由对角矩阵D和附加零矩阵构建,这将使得矩阵Q与x,y各维度兼容。如果Cxy具有满秩,则非零奇异值基本上是非零规范相关,其数量小于x和y数据矢量维度中的任何一个。
3 特征关联影响量表的入侵检测
测量特征关联支持度量的方法是将给定训练集的网络事务记录和在这些网络事务中使用的特征分类值视为两个独立集合,并进一步构建这两者之间的双工图[14]。所提入侵检测基于以下理想性假设和操作步骤实施。
3.1 理想性假设
特征{f1,f2,…,fn∀fi={fiv1,fiv2,…,fivm}}是对特定攻击Ak是最佳的分类值,通过应用于网络事务集T(Ak)的典型相关分析来选择。这里T(Ak)是给定训练集的特定攻击Ak的网络事务记录集,使 得 :T={t1,t2,…,tn∀ti={val(f1),val(f2),…,val(fi),val(fi+1),…,val(fn)}}属于每个网络事务特征的分类值集合,称为事务值集合tvs,并且将所有事务值集合称为STVS。在上面的描述中,val(fi)可以被定义为val(fi)∈{fiv1,fiv2,…,fivm},此后,术语特征指的是特征的当前分类值。当且仅当(val(fi),val(fj))∈tvsk时,对于两个特征val(fi)和val(fj),val(fi)与val(fj)连接。
3.2 方法与步骤
本文通过示例探索该过程,将STVS要素的发散向量表示为V={val1,val2,…,val8}。在 表1 和 图2中,每个元素{val1,val2,…,val8}可以是fivj,使得{fivj∃i∈[1,2,…,n] ∧j∈[1,2,…,m]}。
在检测valk的每个特征分类值fivj与网络事务记录的关联过程中,需要在STVS和特征分类值之间建立双工图。
形成双重图可认为图关系是二分的,并且在特征和事务值集之间形成边。此图中的每个关系都表示特征对网络事务的作用[15]。当且仅当该特征f是tvs的一部分时,交易值集合tvs和特征f之间的边缘才存在可能,这可以表示为etvs←f∃f∈tvs。

表1 STVS和特征分类值之间关联的二进制表示Tab.1 Binary representation of correlation between STVS and feature classification value
图1 所示为加权无向图,其中特征值作为特征值之间的顶点和边。

图1 计数为8的分类值集示例加权图Fig.1 Weighted graph example of classification value set with counting of 8
任意两个特征val(f1),val(f2)之间的边将按如下方式加权:

在上面的等式中,ctvs表示事务计数,其中包含两个特征val(f1)、val(f2)。然后特征val(f1)、val(f2)之间的边缘重量可以如下测量:
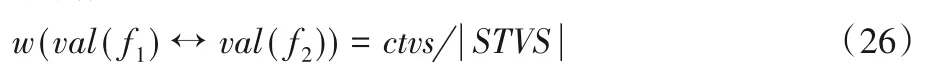
在构建加权图的过程中,本文认为当且仅当ctvs≥1时,任何两个特征之间存在边际。
在如图2 所示的双工图中,虚线表示连接元素属于双工图的相同级别,实线表示特征值和事务值集之间的关系。

图2 STVS和V之间的双工图Fig.2 Duplex diagram between STVS and V
如果在tvs1中存在称为val1的特征分类值fivj,则val1和tvs1之间的连接的权重将是val1与在加权中定义的tvs1的每个特征分类值{fivj∃fivj∈tvs1}之间边的权重的总和图形[16]。
此外,将形成矩阵A,表示交易值集和特征分类值之间的双重图的边缘权重。然后获得A',表示矩阵A的转置[17]。
将STVS视为数据库,并将其描述为双工图而不会丢失信息。设STVS={tvs1,tvs2,…,tvs6}是事务值集的列表,V={val1,val2,…,val8}是相应的特征集分类值。那么,显然STVS相当于双工图DG=(STVS,V,E)。其中,特征值分类值能够跟随通道业务变化而动态调整,从而达到辨识策略的修正,实现通信网络入侵的在线监测。
这里,E={tvsi,vali):vali∈tvsi,tvsi∈STVS,vali∈V}。
假设给定双工图的交易值集,作为枢轴并且特征分类值作为纯特权,则可以测量枢轴和特权值[18-19]。如果在交易值集合中存在特征分类值val1,那么val1和tvs1之间的连接的权重,将是val1与电视的每个特征分类值{vali∃vali∈tvs1}之间的边缘权重的总和。这些权重是边缘权重,用加权图(Weighted Graph,WG)表示。根据2.2 节所述入侵范围估计方法,对特征关联影响尺度阈值进行估计。
所提方法首先对数据集进行预处理,优化异常的入侵检测特征,然后利用改进K-means 聚类算法估计入侵范围阈值并对网络特征进行最终分类;再根据用于特征优化的线性规范相关性,从所选择的最优特征探索特征关联影响尺度,形成特征关联影响量表,完成对异常网络入侵的检测。其具体流程如图3所示。

图3 基于改进K-means结合关联影响尺度分析的入侵检测方法流程Fig.3 Flowchart of intrusion detection method based on improved K-means and association impact scale analysis
4 实验结果与分析
入侵检测评估程序生成的数据用于构建原始KDD-99 数据集,包含接近4 900 000 个唯一连接向量,其中每个连接向量由41个特征组成,34个是连续特征,7个是离散的特征。此外,本文还利用CICIDS2017 通用数据集进行了对比实验,CICIDS2017 数据集是加拿大网络安全研究所于2017 年开源的入侵检测和入侵预防数据集,通过攻击本地网络来收集流量数据,在一段时间内收集正常流量和常见的攻击流量,设计真实攻击场景,具有一定的通用性和应用性。在本文的实验中模拟的攻击属于下面描述的四种类型中的任何一种。
1)DoS。DoS 攻击是一种攻击类型,攻击者通过消耗计算机或内存资源来阻止对有效用户的访问,从而使系统无法处理有效请求。DoS 攻击的例子很多,如:teardrop、neptune、ping of death(pod)、mail bomb、back、smurf和land。
2)用户到根式攻击(Users-to-Root attack,U2R)。根攻击是一种攻击类型,攻击者可以访问系统中的有效用户账户,并根据现有的系统弱点获取对系统根组件的访问权限。有几种类型的U2R攻击,例如:负载模块、缓冲区溢出、rootkit、purl。
3)远程到本地攻击(Remote-to-Local attack,R2L)。远程到本地攻击是一种攻击,其中没有账户的攻击者根据现有的计算机漏洞在本地访问合法用户账户。R2L 攻击类型有:phf、warezmaster、warezclient、spy、imap、ftp_write、multihop 和guess_passwd。
4)探测攻击(Probing attack,PROBE)。探测攻击是一种攻击类型,攻击者会避开安防系统收集网络中计算机上的数据。PROBE 攻击类型有:nmap、satan、ipsweep 和portsweep。在NSL-KDD数据集中,考虑的协议是TCP、UDP和ICMP。
本实验基于Intel Core i5-5430M CPU @ 2.70 GB,4 GB RAM 计算机平台,并在Linux 系统中采用C 程序对数据集进行预处理操作,同时采用Java执行数据分类和入侵检测,采用粗糙集工具RSES(Rough Set Exploration System)。实验通过与文献[5]和文献[7]所提方法(即STSM 和DSSVM)进行对比,从入侵检测精度以及检测完成时间等方面比较了所提入侵检测方法的可行性和先进性。同时在原始KDD-99 数据集实验基础上,增加了CICIDS2017 通用数据集的对照实验,以验证所提方法的普适性。其中,假设网络中发生的真实的攻击事件数量M,IDS漏报的事件数量为N,在基于原始KDD-99数据集的实验中,通过数据预处理得到的训练数据为54 675条,测试记录24 533 条;基于CICIDS2017 通用数据集的实验中,通过数据预处理得到的训练数据为53 687 条,测试记录23 645 条,实验数据分布类型和结果通过多次处理和测试得到。衡量系统性能最为重要的因素有检测率(True Positive,TP)、误报率(False Positive,FP)和漏报率(False Negative,FN)。异常网络入侵检测精度(Precision)是入侵检测方法的主要度量指标,分析得出了入侵检测的精确度度量方法:

其中:TP为正确识别为入侵事件与所有入侵的事件数的比值,FP为错误识别为入侵事件与所有非入侵的事件数的比值,FN为存在漏报的事件数与所有非入侵的事件数的比值。
实验将提出的方法与STSM 和DSSVM 在KDD-99 数据集上进行了对比,其结果如图4所示。

图4 KDD-99数据集上典型发散相关阈值下IRSAR-KCANID预测精度的性能分析Fig.4 Performance analysis of IRSAR-KCANID prediction accuracy under typical divergence correlation threshold on KDD-99 dataset
从图4中可以看出,提出的方法在阈值下限和临界阈值附近对异常网络入侵的检测精度优于STSM 和DSSVM 方法,其检测精度均在97%以上,但在阈值上限处的精度则比另外两种方法稍差。
同时,在同样的实验条件下,将所提方法与STSM 和DSSVM在CICIDS2017数据集上也进行对比,三者的阈值设定为各自在训练集重构误差的均值。
由图5 可知,在阈值下限附近所提方法对入侵检测精度明显优于STSM 和DSSVM 方法,且在临界阈值条件下也保持了较好的精度优势,在阈值上限条件下,三种方法大体相同,均在99%以上。

图5 CICIDS2017数据集上典型发散相关阈值下IRSAR-KCANID预测精度的性能分析Fig.5 Performance analysis of IRSAR-KCANID prediction accuracy under typical divergence correlation threshold on CICIDS2017 dataset
在不同标记下的不同场景典型相关性实验中,对时间复杂度进行了实验分析,提出的方法实验结果如图6所示。

图6 在不同的典型相关阈值下IRSAR-KCANID的入侵检测完成时间Fig.6 Intrusion detection completion time of IRSAR-KCANID under different typical correlation thresholds
由图6可知,由于cc阈值存在变化,所需要的时间复杂度也是可缩放的。当cc 阈值较小时,所需要的完成时间较少,如cc 阈值为0.03时,仅需2.209 s便可完成入侵检测;随着cc阈值逐渐增大,所需要的完成时间逐渐延长,当cc 阈值接近0.047时,完成时间趋于稳定时间11.6 s左右。
此外,实验将所提方法与STSM 与DSSVM 在不同数据集中的不同属性数量下入侵检测时间复杂度方面的对比,其实验结果如表2所示。
如表2 所示,在不同数据集的同一属性数量水平下,不同数据集对入侵检测完成时间几乎没有影响。以KDD-99 为例,STSM 与DSSVM 方法比所提的IRSAR-KCANID 方法入侵检测时间更长。当属性数量为90时,STSM 与DSSVM 方法时间分别为0.115 s 和0.095 s,而提出的方法仅为0.06 s;当属性数量为250时,STSM 与DSSVM 方法时间分别为0.945 s 和0.935 s,提出的方法为0.324 s,大约节省60%的网络入侵检测时间;在CICIDS2017 数据集中,当属性数量为70时,STSM方法时间为0.077 s,DSSVM 与所提方法的时间为0.033 s;当属性数量为230时,STSM 与DSSVM 方法时间分别为0.943 s和0.893 s,而所提方法所需时间仅为0.535 s,相比于较快的DSSVM 方法能节省大约0.0363 s 入侵检测时间。由此可见,在不同的数据集中,入侵检测方法在属性数量越大时,所需要的入侵检测事例越多,所提方法相对于其他方法在不同数据集中对于入侵检测所节约的时间成本越明显。

表2 不同属性数量下入侵检测完成时间对比 单位:sTab.2 Comparison of intrusion detection completion time complexity with different attribute numbers unit:s
5 结语
本文提出的IRSAR-KCANID 简化了特征分析过程,使用基准数据集进行实验,同时引入IRSAR 对数据集进行预处理,采用改进K-means 聚类方法对数据特征进行聚类分析。实验结果表明,规范相关分析对于选择用于训练的网络事务的最优属性十分重要,提出的方法在特征相关聚类的基础上,结合关联影响尺度进行入侵检测,在保证最大化检测精度的前提下,最小化了过程复杂性和完成时间;但在cc 阈值上限情况下,提出的方法检测精度比其他方法略差,因此提出的方法在适用性方面还有待进一步拓展。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
重庆大学学报(2022年2期)2022-02-28
建材发展导向(2021年19期)2021-12-06
计算机仿真(2021年6期)2021-11-17
计算机与生活(2021年8期)2021-08-07
计算机应用与软件(2021年7期)2021-07-16
计算机应用(2021年4期)2021-04-20
中国传媒大学学报(自然科学版)(2021年5期)2021-02-24
智能计算机与应用(2020年4期)2020-08-31
华东师范大学学报(自然科学版)(2018年3期)2018-05-14
